

1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
Hadoop的核心组件是HDFS、MapReduce。hadoop生态圈可以根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
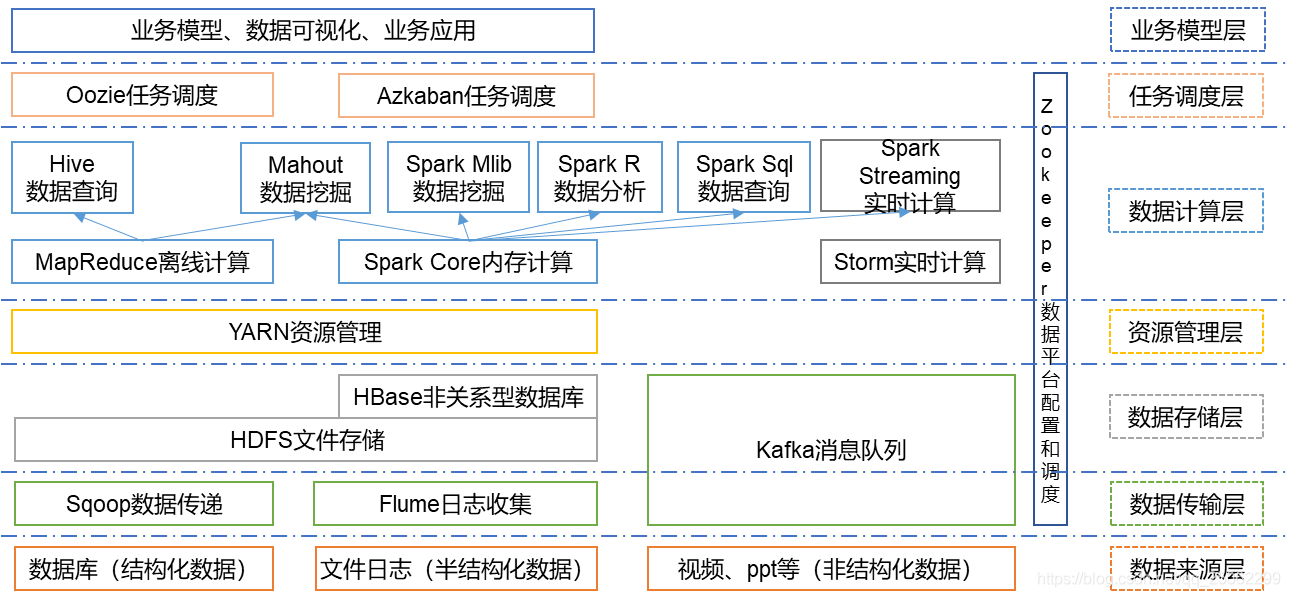
其中HDFS是整个hadoop体系的基础,负责数据的存储与管理;MapReduce是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算;Spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法;Flink是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入;Yarn是分布式资源管理器,实现在一个集群上部署一个统一的资源调度管理框架;Zookeeper用于解决分布式环境下的数据管理问题;Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据;Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析;HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库;Flume是一个可扩展、适合复杂环境的海量日志收集系统;
2.对比Hadoop与Spark的优缺点。
Spark确实速度很快(最多比Hadoop MapReduce快100倍)。Spark还可以执行批量处理,然而它真正擅长的是处理流工作负载、交互式查询和机器学习。
相比MapReduce基于磁盘的批量处理引擎,Spark赖以成名之处是其数据实时处理功能。Spark与Hadoop及其模块兼容。实际上,在Hadoop的项目页面上,Spark就被列为是一个模块。
Spark有自己的页面,因为虽然它可以通过YARN(另一种资源协调者)在Hadoop集群中运行,但是它也有一种独立模式。它可以作为 Hadoop模块来运行,也可以作为独立解决方案来运行。
MapReduce和Spark的主要区别在于,MapReduce使用持久存储,而Spark使用弹性分布式数据集(RDDS)。
3.如何实现Hadoop与Spark的统一部署?
Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署,即“Spark on YARN”,资源管理和调度深度依赖YARN,分布式存储则依赖HDFS。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通