判断网站CMS
1.robots.txt文件
robots.txt文件我们写过爬虫的就知道,这个文件是告诉我们哪些目录是禁止爬取的。但是大部分的时候我们都能通过robots.txt文件来判断出cms的类型
如:
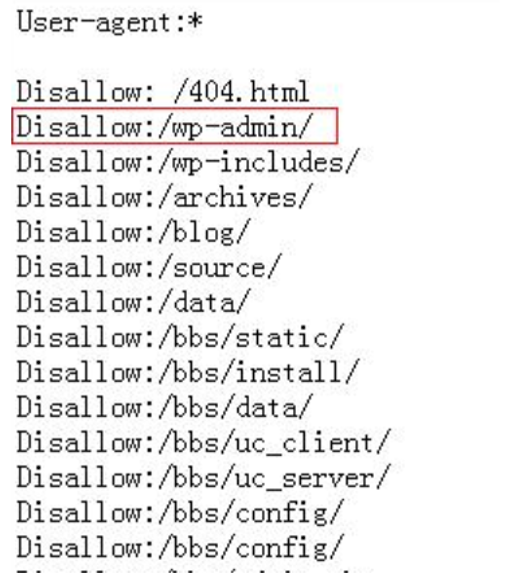
从wp路径可以看出这个是WordPress的cms
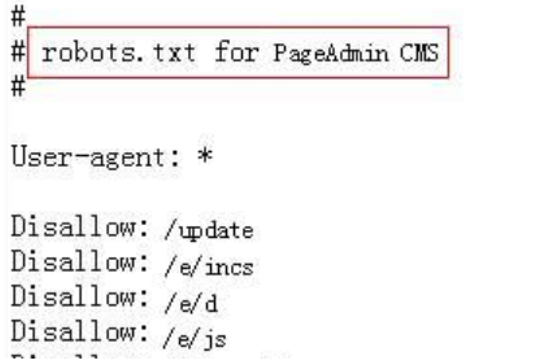
这个就比较明显了直接告诉我们是PageAdmin cms
也有些robots.txt里面写得不是很清楚。我们看看织梦的
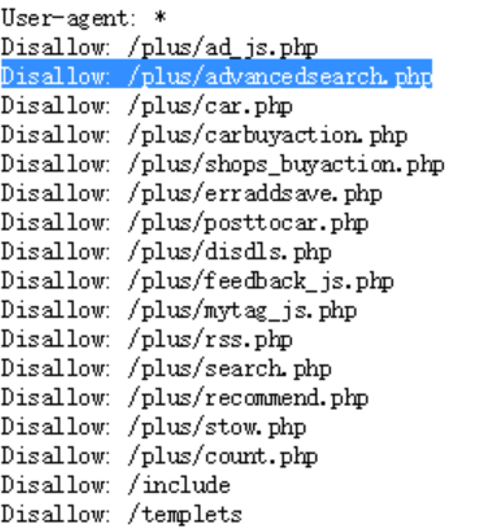
从robots.txt不能直接看出来是什么cms,我们就直接把他复制到百度去查询

这样就找到了是织梦的cms
2.通过版权信息进行查询
一般直接拉到底部查看版权信息,有些站点会显示出来,比如织梦这个

3.通过查看网页源码的方式
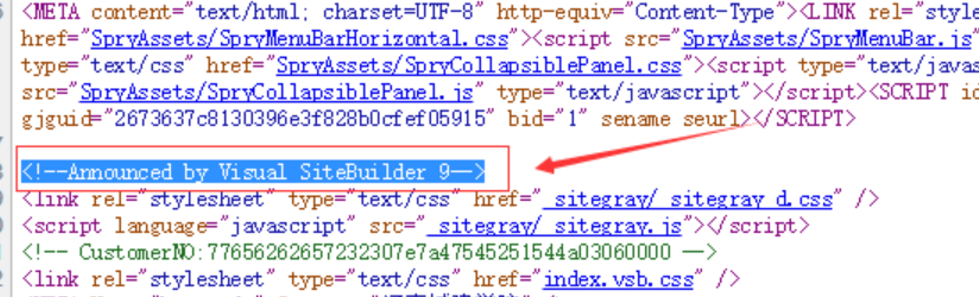
有些站点没有robot.txt,也把版本信息改了,这时候首页查看网页源码可能找得到,如图
4.通过比较网站md5值
有些cms的扫描器就是用这个原理的,先收集某个cms的某个路径的文件的md5值,要求这个文件一般不会被使用者修改的。然后访问这个网站同样的路径下是否存在这个文件,存在的话比较md5值。相同能报出cms类型。这个比较考验字典的能力。
5.很多CTF题中备案号也可以确定CMS
如下是一道设计CMS的CTF题的截图:

百度搜索一下这个备案号:
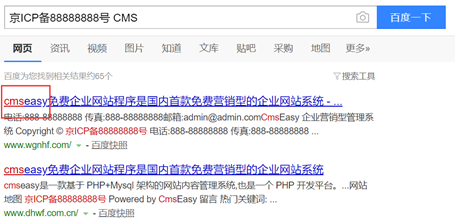
就可以确定这是一个 CmsEasy的站
常见CMS特征:

齐博CMS : http://v7.qibosoft.com/
登录界面、UI、版权声明格式:
CmsEasy:https://www.cmseasy.cn/
版权声明格式、备案号:

登录界面:
织梦CMS(dedecms):http://www.dedecms.com/
进去就是一抹绿

版权声明格式:

帝国CMS :http://www.phome.net/
EBB

登录:
蝉知CMS : https://www.chanzhi.org/


Discuz! : https://www.discuz.net/forum.php
首页:
版权声明:

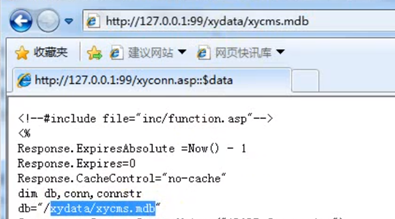
xyCMS:
数据库路径:/xydata/xycms.mdb
永远相信 永远热爱


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义