python网络爬虫入门(一)
爬虫系列的第一篇文章,本篇帮助不大(只能教你利用requests库获取HTML),后续篇(二)会有案例讲解。
python版本:python 3.7.0b1
IDE:PyCharm 2016.3.2
涉及模块:requests & builtwith & whois
模块安装方法:Win+R 进入cmd, 进入文件夹Scripts
命令:pip install requests / pip install requests / pip install whois(如不能正确安装,请留言或自行百度解决)
如要在PyCharm中使用库,先添加一下(添加方法)。
话不多说,先上代码:
1 #coding : utf-8 2 import requests 3 import builtwith #引入所需python库 4 print("开始爬取") 5 url = "https://www.wenjiwu.com/doc/uqzlni.html" #爬取对象网址 6 r = requests.get(url) #requests模块get方法 7 print (r.status_code) #xxx.status_code方法,返回值若为200,则爬取成功 8 print (r.text) #xxx.text方法,得到URL对应HTML源码 9 print (builtwith.parse(url)) #builtwith模块将URL作为参数,返回该网站使用的技术
(url网址随意,baidu, imooc...都可以)
脚本运行结果:
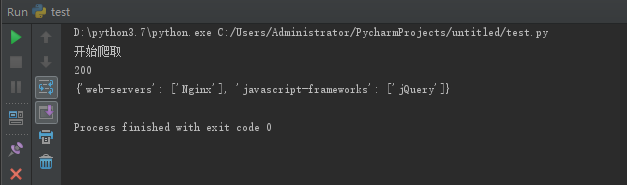
可以看到,程序正常运行,返回值200,爬取成功,builtwith模块得到了示例网站 web-servers: Nginx(服务器类型,详细了解),
使用了jQuery的javascript框架。但是碍于篇幅,其中HTML源码内容运行时注释掉了,不要惊讶!!!
r.text 结果(部分):

(内容无意中伤 Single Dog, Me too #_# )
补充:写成函数形式
1 #coding : utf-8 2 import requests 3 import whois 4 import builtwith 5 6 def download(url, x): 7 print ("downloading...") 8 ans = requests.get(url) 9 islink = ans.status_code # '''通行码''' 10 user = whois.whois(url) #'''网站所有者''' 11 pattern = builtwith.parse(url) #'''网站类型''' 12 result = ans.text #'''网站内容HTML''' 13 if islink == 200: 14 print ("successfully link!") 15 else: 16 print ("Sorry, it is no found!") 17 if x == 'y': 18 print ('owner: ', user) 19 print ('pattern: ', pattern) 20 print ('text: ', result) 21 return result 22 else: 23 return 000 24 url = "https://www.baidu.com" 25 download(url, 'y')
补充:把爬取的内容写入txt文件
1 # 写入*.txt文件 2 f = open("D:\python3.7\\testf.txt", mode='a', errors='ignore') 3 for x in ans.text: 4 f.write(x) 5 f.close()
文件地址随意,errors=‘ignore’是为了防止诸如 ...'\xe7'..., illegal multibyte sequence转码问题的出现。
转载请注明出处,欢迎留言讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号