空闲时间无聊写的一个软著源代码文档生成器
一个java版本 扫描源代码生成软著文档小项目
个人开发环境
java环境:Jdk1.8.0_60
编译器:IntelliJ IDEA 2019.1
框架:Freemaker + Jacob + Java8
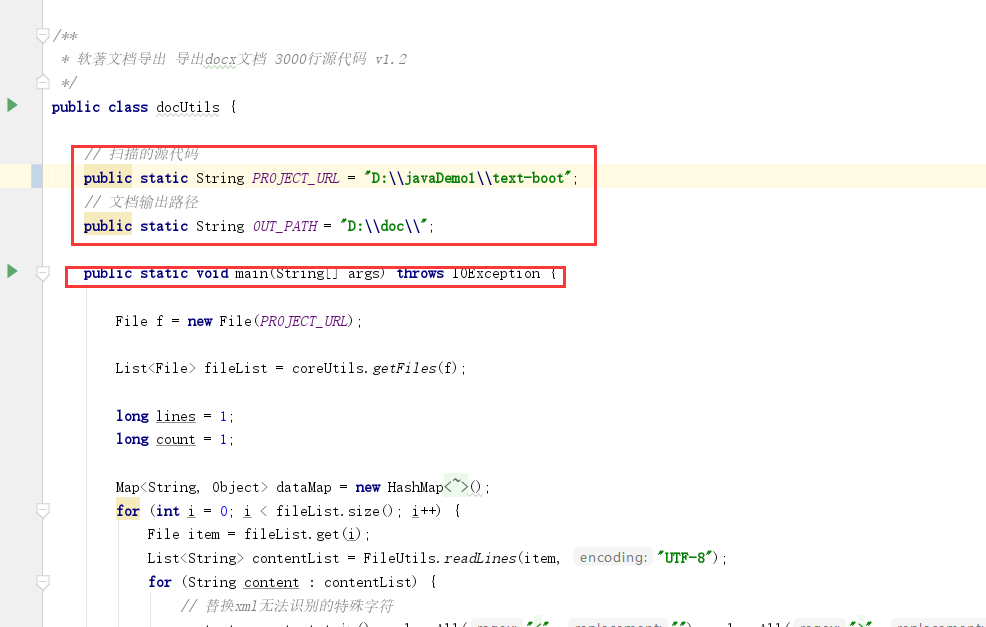
docUtils v1.2
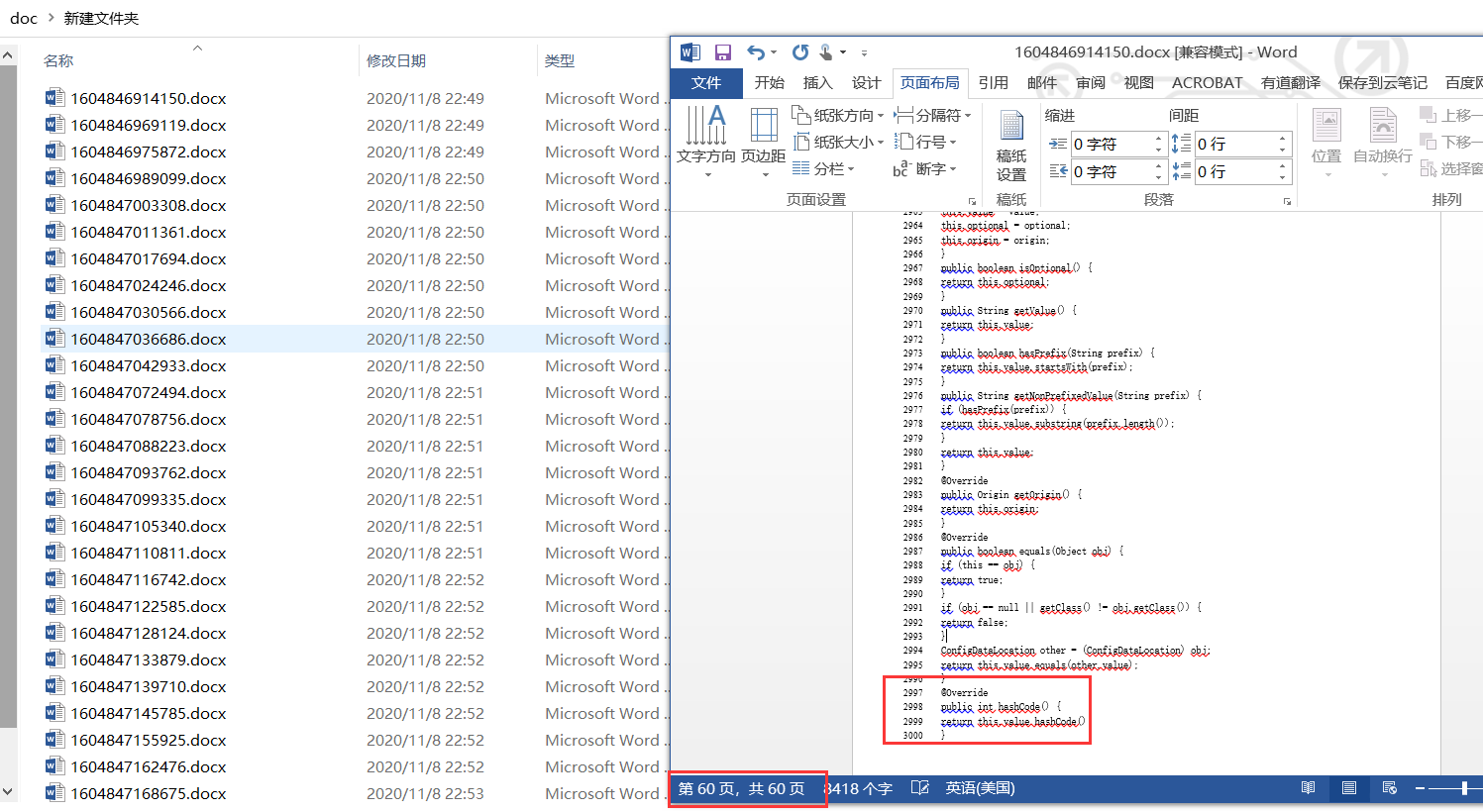
扫描源代码生成docx文档 v1.2版本,每一份3000行 60页 宋体 五号 .docx源代码
生成流程
1、递归扫描指定源代码
2、通过将已经做好的docx模板,另存为xml文件,并修改xml文件为.ftl后缀的(freemaker)模板文件,(具体可以搜索freemaker生成word模板的方法)
3、将扫描的源代码填充至ftl模板文件,生成为doc源代码文档(本质其实还是xml文件,平均一份大约1.5M)
4、为了解决文档太大问题,采用jacob将doc(本质xml)转成docx后缀文件,最终文档一份50K左右
源代码
docUtils.java
/**
* 软著文档导出 导出docx文档 3000行源代码 v1.2
*/
public class docUtils {
// 扫描的源代码
public static String PROJECT_URL = "D:\\javaDemo1\\text-boot";
// 文档输出路径
public static String OUT_PATH = "D:\\doc\\";
public static void main(String[] args) throws IOException {
File f = new File(PROJECT_URL);
List<File> fileList = coreUtils.getFiles(f);
long lines = 1;
long count = 1;
Map<String, Object> dataMap = new HashMap<String, Object>();
for (int i = 0; i < fileList.size(); i++) {
File item = fileList.get(i);
List<String> contentList = FileUtils.readLines(item, "UTF-8");
for (String content : contentList) {
// 替换xml无法识别的特殊字符
content = content.trim().replaceAll("<", "").replaceAll(">", "").replaceAll("&", "");
// 保证每一个模板字符不超过第二行
if (content.length() > 65) {
content = content.substring(0, 65);
}
// 跳过空行
if (content.length() == 0) {
continue;
}
// 跳过功能注释 跳过版权注释
if (content.contains("/") || content.contains("*")) {
continue;
}
// 填充模板字符串从 content1~content3000 保证每个模板3000行代码
dataMap.put("content" + lines, content);
if (dataMap.size() == 3000) {
// 生产doc
coreUtils.genDoc(dataMap, OUT_PATH);
System.out.println("生成第" + count + "份文档");
// 清理数据生成下一份
dataMap.clear();
count++;
lines = 1;
break;
}
lines++;
}
}
System.out.println("文档已生成完成");
}
}
coreUtils.java
public class coreUtils {
/**
* docx 格式
*/
private static final int DOCX_FMT = 12;
public static List<File> fileList = new ArrayList<File>();
/*
* 通过递归得到某一路径下所有的目录及其文件
*/
public static List<File> getFiles(File root) {
File[] files = root.listFiles();
for (File file : files) {
if (file.exists() && file.isDirectory()) {
getFiles(file);
} else {
String filename = file.getName();
String suffix = filename.substring(filename.lastIndexOf(".") + 1);
if (suffix.equals("java")) {
fileList.add(file);
System.out.println("addFile " + file);
} else {
System.out.println("notFile " + file);
}
}
}
return fileList;
}
public static void genDoc(Map<String, Object> dataMap, String outPath) {
// Map<String, Object> dataMap = new HashMap<String, Object>();
try {
// Configuration 用于读取ftl文件
Configuration configuration = new Configuration(new Version("2.3.0"));
configuration.setDefaultEncoding("UTF-8");
/**
* 以下是两种指定ftl文件所在目录路径的方式,注意这两种方式都是 指定ftl文件所在目录的路径,而不是ftl文件的路径
*/
// 指定路径的第一种方式(根据某个类的相对路径指定)
configuration.setClassForTemplateLoading(coreUtils.class, "/");
// 指定路径的第二种方式,我的路径是C:/a.ftl
// configuration.setDirectoryForTemplateLoading(new File("D:/"));
long name = System.currentTimeMillis();
// 输出文档路径及名称
String filePath1 = outPath + name + ".doc";
String filePath2 = outPath + name + ".docx";
File outFile = new File(filePath1);
// 以UTF-8的编码读取ftl文件
Template template = configuration.getTemplate("tpl.ftl", "UTF-8");
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile), "UTF-8"));
template.process(dataMap, out);
out.close();
// 将doc文档转换成docx
coreUtils.convertDocxFmt(filePath1, filePath2, 1);
outFile.delete();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 根据格式类型转换 com.yociyy.rz.text.word 文件
*
* @param srcPath 源文件
* @param descPath 目标文件
* @param fmt 所转格式
*/
public static void convertDocxFmt(String srcPath, String descPath, int fmt) throws Exception {
File file = new File(srcPath);
// 实例化ComThread线程与ActiveXComponent
ComThread.InitSTA();
ActiveXComponent app = new ActiveXComponent("Word.Application");
try {
// 文档隐藏时进行应用操作
app.setProperty("Visible", new Variant(false));
// 实例化模板Document对象
Dispatch document = app.getProperty("Documents").toDispatch();
// 打开Document进行另存为操作
Dispatch doc = Dispatch.invoke(
document,
"Open",
Dispatch.Method,
new Object[] { file.getAbsolutePath(), new Variant(false),
new Variant(true) },
new int[1]).toDispatch();
Dispatch.invoke(doc, "SaveAs", Dispatch.Method, new Object[] {
descPath, new Variant(DOCX_FMT) }, new int[1]);
Dispatch.call(doc, "Close", new Variant(false));
// return new File(descPath);
} catch (Exception e) {
throw e;
} finally {
// 释放线程与ActiveXComponent
app.invoke("Quit", new Variant[] {});
ComThread.Release();
}
}
}
pom.xml
<dependencies>
<!--Apache Commons-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.4.6</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
<dependency>
<groupId>net.sf.jacob-project</groupId>
<artifactId>jacob</artifactId>
<version>1.14.3</version>
</dependency>
</dependencies>
使用方式 (两步)
第一步:(也可直接搜索jacob安装方式/使用方式)
(jacob,是个强依赖的项目,需要将我放在项目resource 的jacob-1.14.3-x64_jb51.net.rar解压,jacob-1.14.3-x64.dll放到本地安装jdk bin目录下即可)
第二步 v1.0版本一样,修改目录,直接启动项目
第三步 查看生成结果
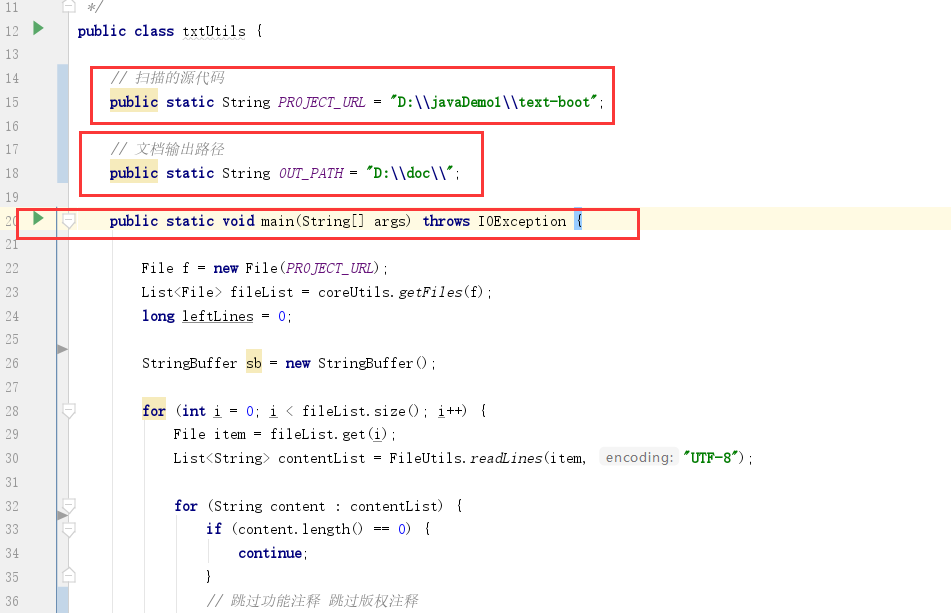
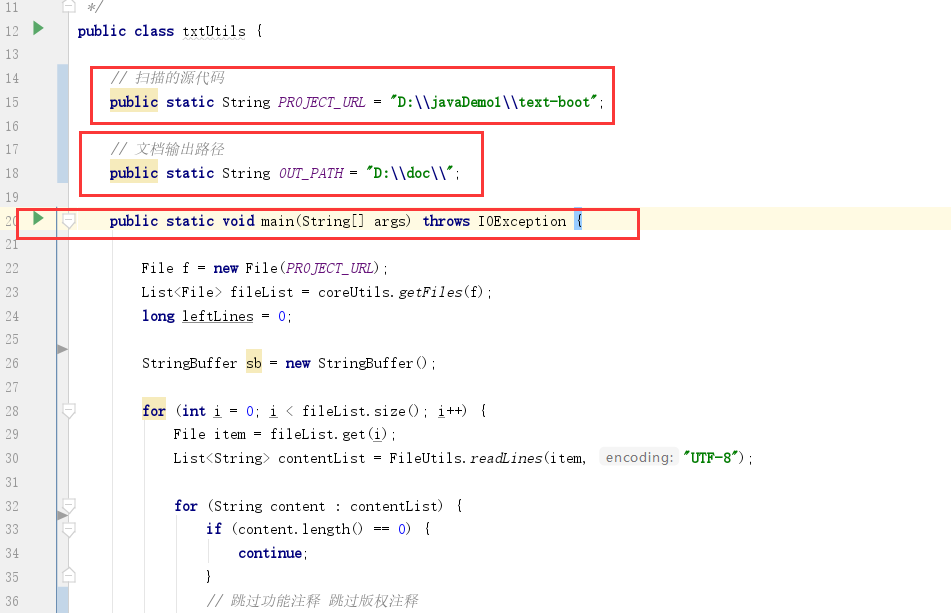
txtUtils v1.0
扫描源代码生成txt文档 v1.0版本,每一份大约3000行 60页左右
直接修改路径,启动main方法即可
使用方式
源代码
/**
* 软著文档导出 导出txt文档 大约3000行源代码 v1.0
*/
public class txtUtils {
// 扫描的源代码
public static String PROJECT_URL = "D:\\javaDemo1\\text-boot";
// 文档输出路径
public static String OUT_PATH = "D:\\doc\\";
public static void main(String[] args) throws IOException {
File f = new File(PROJECT_URL);
List<File> fileList = coreUtils.getFiles(f);
long leftLines = 0;
StringBuffer sb = new StringBuffer();
for (int i = 0; i < fileList.size(); i++) {
File item = fileList.get(i);
List<String> contentList = FileUtils.readLines(item, "UTF-8");
for (String content : contentList) {
if (content.length() == 0) {
continue;
}
// 跳过功能注释 跳过版权注释
if (content.contains("/") || content.contains("*")) {
continue;
}
// 2950行大约3000页
if (leftLines > 2950) {
FileUtils.write(new File(OUT_PATH + System.currentTimeMillis() + ".txt"), sb.toString(), "UTF-8");
leftLines = 0;
sb.setLength(0);
break;
}
sb.append(content);
sb.append("\n");
leftLines++;
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号