OOP前三次作业总结
前言:
初入java,前三次作业主要是考察面向对象中最基础也是最重要的类的设计,使之遵循单一职责原则、迪米特原则。如何设计好类、以及如何好处理类与类之间的关系是实现代码合理、高效运行的关键。作业题目量不大,前两题是对java语法的考查(如正则表达式,ArrayList,Linkedlist),最后一题比较难,考查了对类的设计,从第一次作业开始,不断对题目进行迭代,训练相关思维能力。
1)第一次作业对类的设计和引用不了解,耦合性太强了,而且与单一职责和迪米特法则完全是背道而行。数据在类中的处理时,并且读入并存储方式不正确,导致代码无论从时间还是空间上都是不合理的。
2)第二次作业比第一次作业稍微好点,逻辑处理好了一点,但后面两个问题完全没有解决。
3)第三次作业取消了属性类的使用,降低了耦合性,同时更靠近了单一职责和迪米特法则,但是时间上可能并不是很友好。
分析:
<1>
设计与分析:
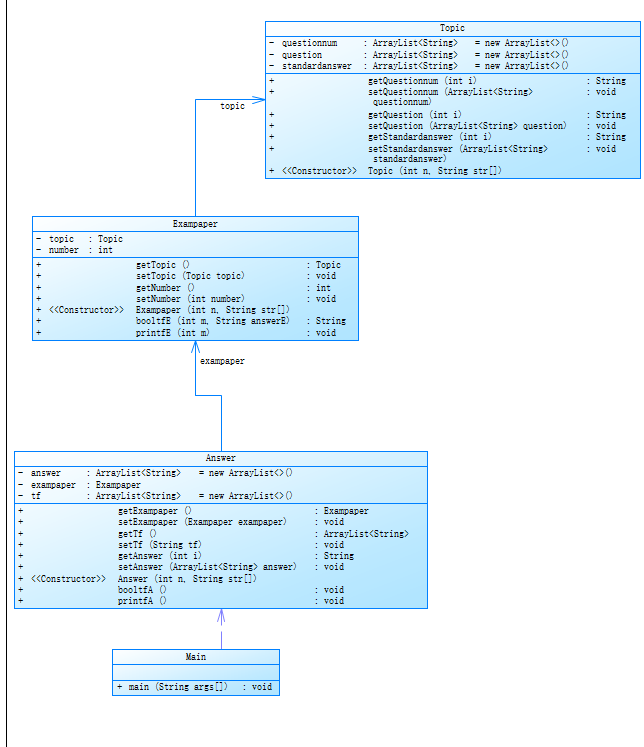
第一次作业不清楚引用,以为对象类不能作为参数传入方法中,所以设计思路是在主函数中留下一个对象类作为信标启动各种操作,然后其他的对象类则留在相应类中待调用。于是便有了将数据从主函数中读取存到答案类中再由答案类到试卷类再到题目类的顺序进行之后的一系列的操作的结构。
class Answer{
private ArrayList<String> answer = new ArrayList<>();
private Exampaper exampaper;
private ArrayList<String> tf = new ArrayList<>();
public Exampaper getExampaper() {
return exampaper;
}
public void setExampaper(Exampaper exampaper) {
this.exampaper = exampaper;
}
public ArrayList<String> getTf() {
return tf;
}
public void setTf(String tf) {
this.tf.add(tf);
}
public String getAnswer(int i) {
return answer.get(i);
}
public void setAnswer(ArrayList<String> answer) {
this.answer = answer;
}
public Answer(int n, String[] str){
String[] ans = str[n].split("\\s*#A:\\s*");
for(int i = 1; i <= n; i++)
answer.add(ans[i]);
exampaper = new Exampaper(n,str);
}
public void booltfA(){
for(int i = 0; i < exampaper.getNumber(); i++)
tf.add(exampaper.booltfE(i, answer.get(i)));
}
public void printfA(){
for(int m = 0; m < exampaper.getNumber(); m++){
exampaper.printfE(m);
System.out.printf("%s\n",answer.get(m));
}
System.out.printf("%s",tf.get(0));
for(int n = 1; n < exampaper.getNumber(); n++)
System.out.printf(" %s",tf.get(n));
}
}
但是这样设计如上面代码可见,基本上这个完整的答题判题程序代码都是靠这个答案类去完成的,其他的类只是起到辅助帮助作用,不符合类的设计原则。而且假如我想存储题目类的信息,要从主类到答案类再到试卷类最后到题目类这样子的链式结构。耗时增加。而以上引导我这样写的原因是我对java中引用的不了解。并且由于对引用不了解,所以对于每份答案,都会存一套试卷和答案,增加了代码运行所需时间和空间。
改进建议:
在主函数就把所有数据传入三个类中,用引用进行诸如将试卷类的题目对象指向main里的题目对象。再新定义一个正则表达式类进行信息的存储和判断类进行答卷的批改。
<2>
设计与分析:
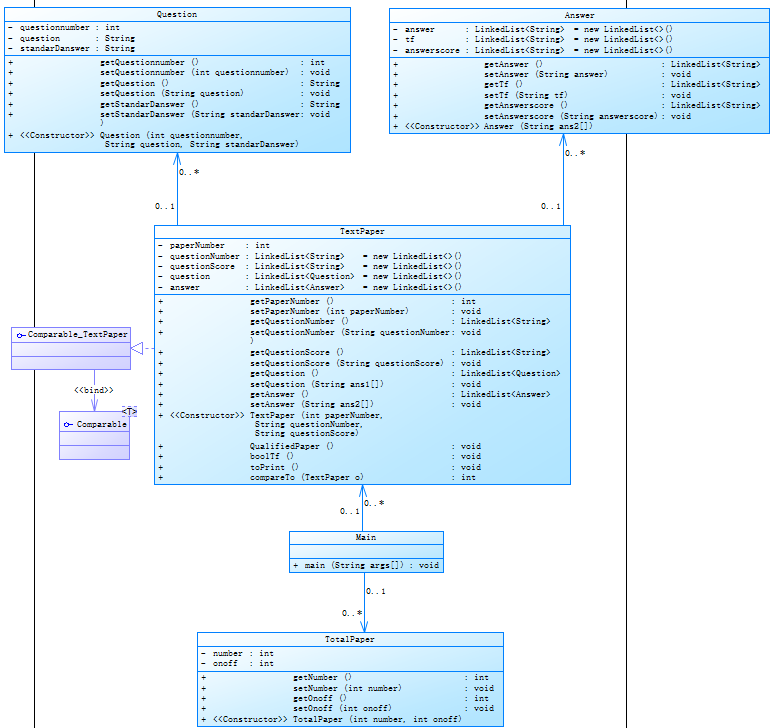
由于第一次代码结构不对,于是第二次作业相较于第一次,取消了原来以答案类为主体的链式结构代码,而因为试卷类与题目类、试卷类与答案类都是直接联系的关系,并且这也符合迪米特法则,所以采用了以试卷类为主体的树状结构,先把试卷信息全部存好,再将与试卷相匹配的数据存进相关的类对象中,虽然有点耗时,但相比原来题目和试卷都多存了来说,第二次代码只多存了题目信息,节省了数据存储的空间。并且由于所有数据在存储完之后都是已经排好序的存在,所以答案的批改十分的容易。
当然这也有一个漏洞,假如有答案号与试卷号不匹配的话,代码是处理不了这个数据的。于是,当时写完了之后为了应付这个漏洞,又加了一个新的类用来存答案卷的编号以作后面的输出操作。所以虽然这样设计非常简单无脑,但是它依旧多耗了内存,数据多了之后时间也耗的多。
采坑心得:
撇去最不应该的漏掉的答卷号与试卷号不匹配的犯错,就说当时折磨我很久的最后一个测试点,出于习惯,我给答卷类按答卷号排了序,导致答卷信息按答卷号顺序输出:


如图,s:12在s:1的前面,因为对答卷进行了排序,导致了输出结果s:12在s:1的后面。而正确的结果s:12应在s:1的前面。其实这应该是我没有想全面,题目没有特别强调,而假如是按顺序输出的话,2个s:1又是按先后输出,不太合理,所以应该是按先后输出。
改进建议:
这样子的结构耦合性依旧很高,而且试卷类在本身的功能外,还充当了一个代理类集合的角色,完全违背了单一职责原则,应该多加几个代理类分开试卷类多余的方法。在主函数就把所有数据传入三个类中,取消与试卷相匹配数据存入模式,直接存入对象类组,再新定义一个代理类正则表达式类进行信息的存储和代理类判断类进行答卷的批改。
<3>
设计与分析:
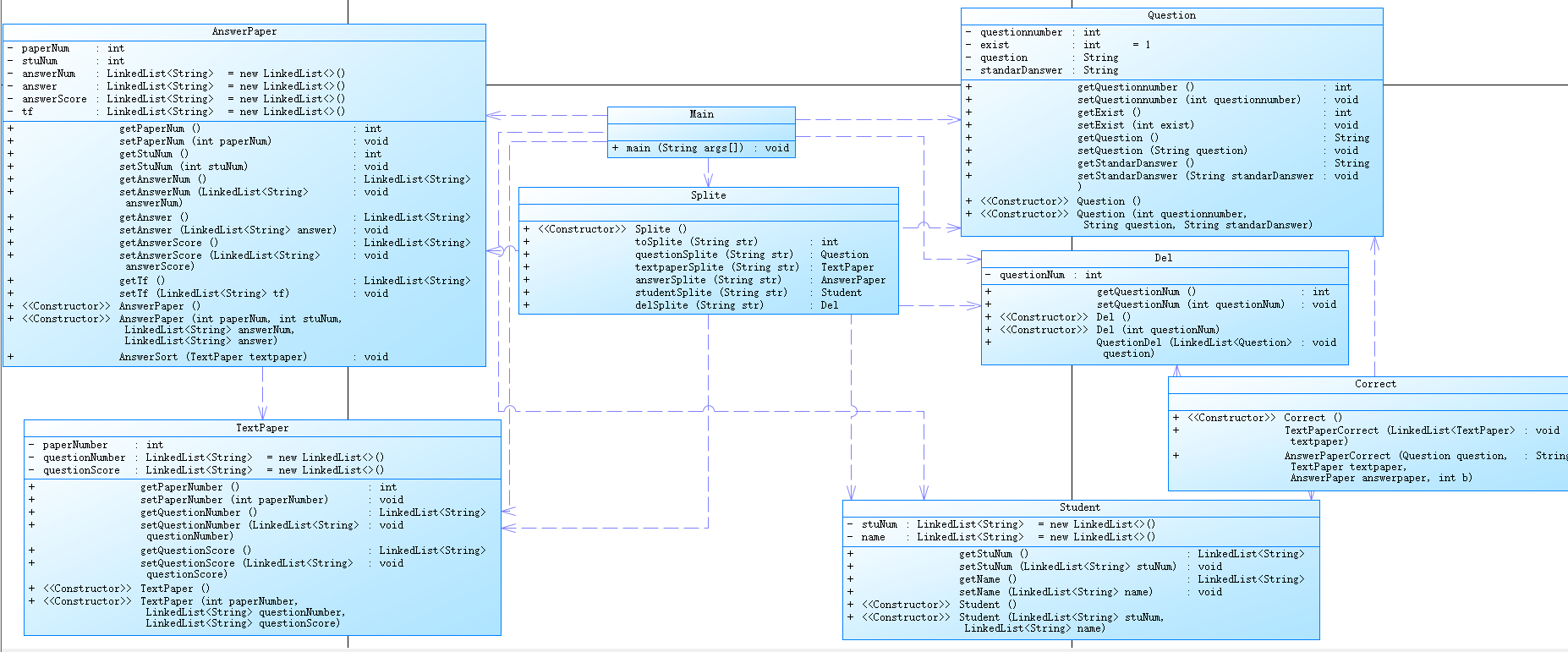
为了降低耦合性,我完全删减掉了属性类。相比上面三个类还加了正则表达式类、判断类以及题目新加的学生类、删除类。通过正则表达式类分割完不同的信息后再返回不同的值经过switch case语句来添加到相应的类中。再通过删除类中的方法删除指定题目,然后通过判断类中的方法判断试卷是否满100分,之后通过学生类中的方法对链表中数据进行排序补充,使之与试卷上的题目顺序相匹配,最后再进行输出。但是如果这样的话,过多的for循环可能导致时间效率上不高。
采坑心得:
之前有挺多小错误的,这里只挑困住我好久的2个问题。
1.正则表达式出错:
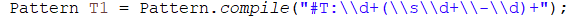

如图,因为题号后面的分数漏打“+”了,导致输出结果输出了wrong fomat,这个问题让我看了好久都没发现哪里出错,所以每写完一段正则表达式都应该停下来检查一下,趁着记忆和思路都还在,看下是否写错。不然之后可能就好找了(笑)。
2.提取的数据两端有空格:
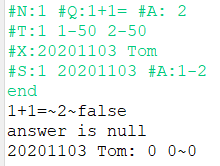
如图,1+1=2,显然是正确的,但是判断结果显示它错了,因为没有把标准答案前面的空格去掉,导致判断时是空格加2与2做判断,自然会显示false。虽然这也可以用正则表达式处理的,但我想把它单独拎出来,它应该是一个需要养成的习惯,在每个处理的数据之后都要加个trim(),确保不会出现问题。
改进建议:
虽然耦合性降低了,但是for循环写了很多。导致输出代码部分显得很臃肿。但其实可以稍微往类中加几个属性类,例如删除类中加题目类组,答卷类中加学生类之类的,这样可能会更好一些。我的正则表达式也写的不好,有些漏洞,需要改进。删除方法是想把类中的除题目号之外的属性变成null,结果忘写了,这个也得加上。
总结:
这三次作业不仅让我掌握了更多java语法,如正则表达式、ArrayList、Linkedlist、hashmap、众多时间类库函数,更重要的,我们的思维在做最后一题的类设计的时候在不断改进、不断地积累提升我们的类设计能力。同时,我也知道我的java语法水平还有待提高,我的正则表达式、我的hashmap都还没有熟练掌握,时间类库函数也还没有完全了解。语法之于面向对象技术无异于地基之于大厦,一定要打好语法基础,只有熟练掌握与应用语法,才能让之后的java之旅事半功倍。希望老师多给点机会,讲点例子让我们积累提升向七大设计原则靠齐的类设计思维能力,同时,我们应该不断思考,任何事物都可以供我们抽象,供我们使我们的思维向七大设计原则靠齐。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号