
权重初始化
1.全0初始化或者同一层的初始化为同一个值。
这样的初始化导致前向传播得到相同的值,反向传播也得到相同的梯度,这样就失去了神经元的不对称性
2.
3.xavier初始化
首先明确均匀分布:数学期望:E(x)=(a+b)/2
方差:D(x)=(b-a)²/12
https://zhuanlan.zhihu.com/p/27919794
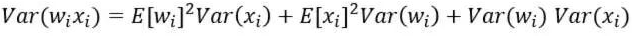
若E(xi)=E(wi)=0,则:
如果随机变量xi和wi再满足独立同分布的话:
试想一下,根据文章《激活函数》,整个大型前馈神经网络无非就是一个超级大映射,将原始样本稳定的映射成它的类别。也就是将样本空间映射到类别空间。试想,如果样本空间与类别空间的分布差异很大,比如说类别空间特别稠密,样本空间特别稀疏辽阔,那么在类别空间得到的用于反向传播的误差丢给样本空间后简直变得微不足道,也就是会导致模型的训练非常缓慢。同样,如果类别空间特别稀疏,样本空间特别稠密,那么在类别空间算出来的误差丢给样本空间后简直是爆炸般的存在,即导致模型发散震荡,无法收敛。因此,我们要让样本空间与类别空间的分布差异(密度差别)不要太大,也就是要让它们的方差尽可能相等。
因此为了得到Var(z)=Var(x),只能让n*Var(w)=1,也就是Var(w)=1/n。
同样的道理,正向传播时是从前往后计算的,因此 ,反向传播时是从后往前计算的,因此
。然而
和
往往不相等啊,怎么办呢?所以就取他们的均值就好啦~即:
令
因为均匀分布,所以Nin = -Nout,所以:
4.He初始化
normal:正态分布
uniform:均匀分布
MSRA这篇是kaiming出的初始化的方式
