YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss [2204.06806] - 论文研读系列(6) 个人笔记
YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss [2204.06806]
-
论文题目:YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
-
代码:
-
22年4.14文章
1、摘要简介
-
本文介绍了
YOLO-Pose,一种新的无Heatmap联合检测方法,是基于YOLOv5目标检测框架的姿态估计。 -
现有的基于
Heatmap的两阶段方法并不是最优的,因为它们不是端到端训练的,且训练依赖于替代L1损失,不等价于最大化评估度量,即目标关键点相似度(OKS)。 -
YOLO-Pose可以进行端到端训练模型,并优化OKS度量本身。该模型学习了在一次前向传递中联合检测多个人的边界框及其相应的二维姿态,从而超越了自上而下和自下而上两种方法的最佳效果。 -
YOLO-Pose不需要对自底向上的方法进行后处理,以将检测到的关键点分组到一个骨架中,因为每个边界框都有一个相关的姿态,从而导致关键点的固有分组。与自上而下的方法不同,由于所有人都是在一次推理中随姿势定位,因此取消了多个前向传播。 -
本文旨在解决无热图的姿势估计问题。目标检测和姿势估计类似,同样有尺度变换、遮挡、人体非刚性等,最新的目标检测框架试图通过在多个尺度上预测来缓解尺度变换问题,本文采用相同策略来预测多尺度人体姿势。
2、相关工作
-
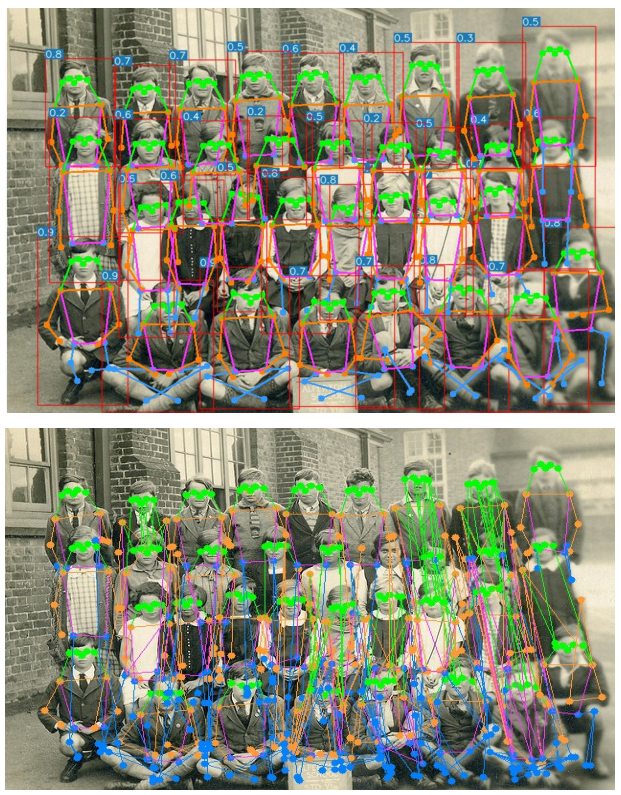
-
上图为yolo-pose的输出,下图为HighterHRNet32的输出,即使关键点位置基本正确,分组算法也很容易失败。在拥挤的场景中,自下而上的方法(例如上述的HightHRNet32)很容易出现这种分组错误。
-
自上而下的方法虽然精度高,但是模型复杂且运行时间可变,自下而上方法有稳定的运行时间,可以达到实时要求,其依赖于热图来检测单张图像中所有的关键点,然后进行复杂的后处理,将其分组为个人。但即使后处理后也可能不清晰无法区分同一类过于紧密的关键点,同时不能端到端训练,因为后处理部分是不可微的(从线性规划到启发式算法)。(总而言之后处理又慢又复杂,最好直接舍去)
- 后处理可以涉及像素级NMS、线积分、细化、分组等步骤。坐标调整和细化减少了下采样热图的量化误差,而NMS用于在热图中寻找局部最大值。
- 本文重点消除各种非标准化后处理,采用与目标检测相同的后处理。
-
简单来说,就是结合了自上而下方法中简单的后处理(通过锚分组)+ 自下而上方法恒定的运行时间(本文复杂性与图像中人数无关?),提出一种联合检测和姿态估计框架,通过目标检测网络,姿势估计部分几乎
free。 -
自上而下:simple baseline、(DCPose、FAMI-Pose)
-
自下而上:openPose、DEKR、HRNet(热图的方法都属于自下而上,各方法不同之处在于关键点分组策略)
3、YOLO-Pose
-
不使用热图,相反将一个人的所有关键点与锚联系起来,基于目标检测框架(YOLOX/YOLOv5)。对于姿势估计归于为一个单一类别的行人检测问题,每个人都有17个相关的关键点,并且每个关键点都用位置和置信度来识别:
{x,y,conf}。因此对于具有n个关键点的锚,整体的预测向量为: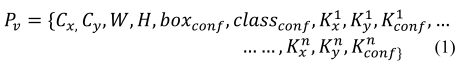
-
关键点置信度是基于关键点的可见性标志进行训练的。如果一个关键点是可见的或被遮挡的,那么
Ground Truth置信度设置为1,否则,如果关键点在视场之外,置信度设置为0。 -
在推理过程中要保持关键点的置信度大于0.5。所有其他预测的关键点都被屏蔽的。预测的关键点置信度不用于评估。然而,由于网络预测了每个检测的所有17个关键点,需要过滤掉视场之外的关键点。否则,就会有置信度第的关键点导致变形的骨架。现有的基于
Heatmap的Bottom-up方法不需要这样做,因为视野外的关键点一开始就不会被检测到。 -
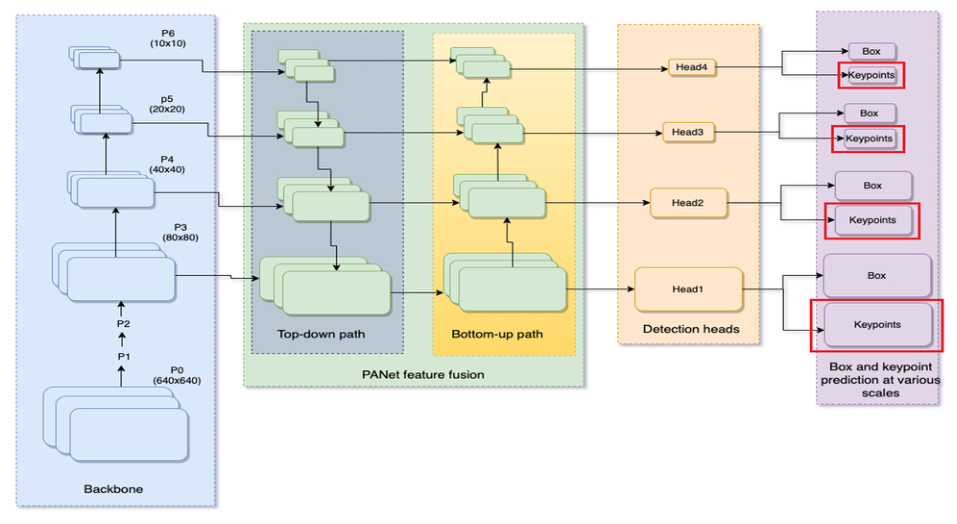
-
使用CSP-darknet53作为主干(生成各种分辨率的特征图P3P4P5P6),PANet从主干融合各种尺度的特征,四个不同分辨率的探测头,以及最后每个检测头分别预测框和关键点。本工作重点在于追求实时模型的基础上与自上而下的方法进一步缩小差距。
3.1 基于多人姿势生成的锚点
- 图像中与人匹配的锚,和姿势/边界框一起存储。边界框坐标随锚中心变换,尺寸随锚高度宽度标准化;关键点位置也会从
w,r,t转换为锚中心(锚中心的相对坐标),但尺寸不会标准化(因此能够被推广到无锚目标检测算法中)。
3.2 监督Bounding-box的IoU损失
-
大部分现在的物体检测器使用的是优化了IoU损失的变体,比如GloU、DIoU或CIoU损失,而非基于距离的损失,因为这些损失是尺度不变的,并直接优化评估指标本身。因此本文借鉴使用CIoU损失监边框回归:
-
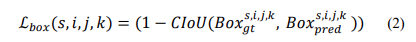
-
表示位置 (i,j) 和尺度 s 处的第 k 个锚点的预测框。本文中每个位置有三个锚(上本身中间和下半身),在四种尺度上进行预测(四种分辨率)。
3.3 人体姿势损失函数公式
-
OKS(目标关键点相似度)
- 传统基于热图的自下而上的方法使用L1损失来检测关键点。然而本文指出L1损失没有考虑物体的大小或者关键点的类型,因此不是最佳的。由于热图是概率图,所以在纯热图的方法中不可能使用OKS作为损失,只有要回归关键点位置的时候OKS才能作为损失函数。
- 由于本文是直接回归关键点
w.r.t锚中心,因此可以优化评估指标本身(即IoU损失)而非使用替代损失函数surrogate loss,即将IoU损失从边框推广到关键点。- surrogate loss function代理损失函数或者称为替代损失函数,一般是指当目标函数非凸、不连续时,数学性质不好,优化起来比较复杂,这时候需要使用其他的性能较好的函数进行替换。(热图的复杂后处理分组)
- 本文使用IoU损失作为OKS评估:
- OKS损失本质上应该是尺度不变的,并且对不同的关键点权重不一样,比如头部关键点比身体关键对损失的惩罚更大。(权重超参借鉴COCO作者经验)
- 普通的IoU损失在非重叠情况下会出现梯度消失,而OKS损失不会,因为选择更类似于OKS的DIoU损失。
-
对于每个边界框都存储整个姿态信息,因此如果标注框在位置和尺度上与预测框相匹配,则预测了相对于锚中心的关键点。分别计算每个关键点的OKS求和得出最终的OKS。
-
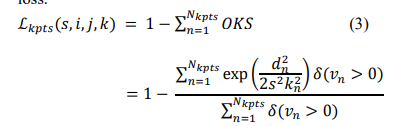
-
\(d_{n}\)表示第n个关键点预测和标注位置的欧氏距离,\(δ(v_{n})\)表示每个关键点的可见性标志(1/0)。对于每个关键点,使用关键点的可见性标志来学习一个置信参数来显示该人是否存在某关键点,在这里,关键点的可见性标志借助标注框得到:
p表示第n个关键点的置信度,BCE二分类交叉熵损失。 -
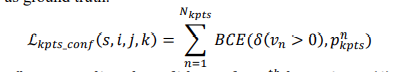
-
总损失:
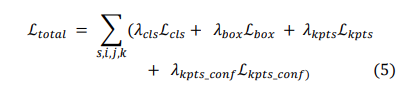
-
其中超参数均为0.5。主要是用来平衡损失。
2.5 超出边界框的关键点
top-down的方法在遮挡下表现很差。与top-down的方法相比,YOLO-Pose的优势之一是:关键点没有限制在预测的边界框内。因此,如果关键点由于遮挡而位于边界框之外,它们仍然可以被正确地识别出来。然而,在top-down的方法中,如果人的检测不正确,姿态估计也会失败。在YOLO-Pose方法中,遮挡和不正确的框检测在一定程度上减轻了这些挑战。

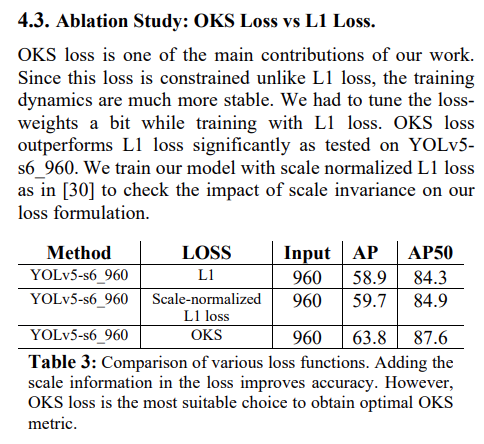
4、实验结果
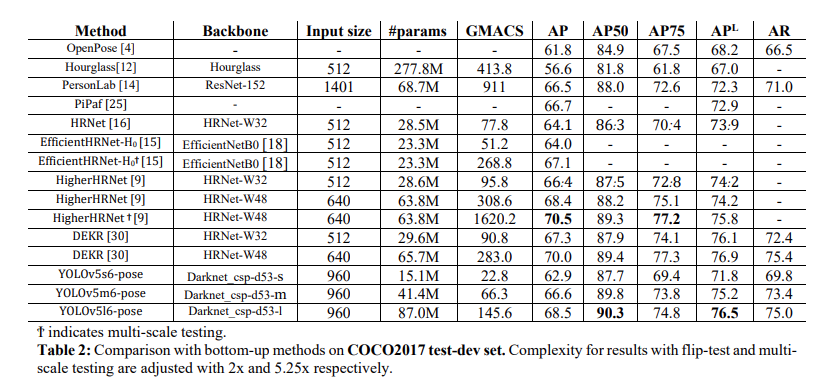
5、 总结
- 本文的方法大体看是,先用YOLO检测出人,然后以锚中心为坐标检测关键点;可以说关键点跟锚绑定而非跟检测框走。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号