TransReID: Transformer-based Object Re-Identification [2102.04378v2] - 论文研读系列(3) 个人笔记
TransReID: Transformer-based Object Re-Identification [2102.04378v2]
- 论文题目:TransReID: Transformer-based Object Re-Identification
- 论文地址:http://arxiv.org/abs/2102.04378v2
- 代码:https://github.com/heshuting555/TransReID
- 21年2月文章
1、摘要简介
-
构建了一个基于transformer的强baseline
-
为了进一步增强鲁棒特征,设计了两个新模块:
- 提出``jigsaw patch module`JPM,通过shift和shuffle操作对patch(?)的嵌入进行重排列从而生成鲁棒特征
- 引入侧信息嵌入SIE,通过插入可学习嵌入来融合非视觉线索,从而减轻对视图变化的特征偏差
-
基于CNN的论文有两个问题没有得到很好的解决:
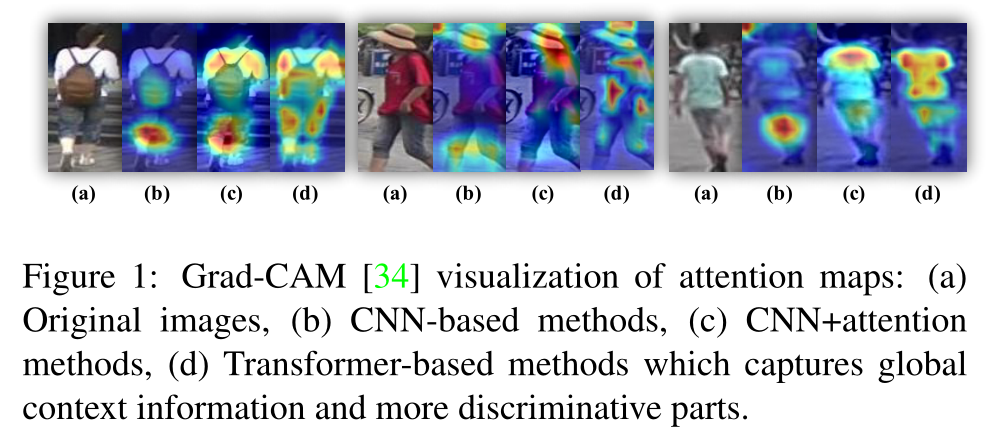
- (1)CNN由于有效接受域的高斯分布,主要针对较小的识别区域(时序关系不好处理)。本文前的注意力方法偏爱大面积的连续区域,难以提取多个多样的判别部分
![]()
- (b)基于CNN,(c)基于CNN+注意力,(d)基于transformer
- (2)细粒度特征很重要,CNN的下采样池化和跨步卷积
stride convolution降低了输出特征图的空间分辨率。 - Transformer的多头自注意捕获长距离依赖,并驱动模型参与不同的人体部位,无需下采样操作,Transformer可以保留更详细的信息。(本文通过设计,再去之前的Transformer work里寻找原因)
- 局部特征和侧面信息是增强特征鲁棒性的重要方面
- 对部分/条纹聚合特征对遮挡和失调具有鲁棒性,但CNN中设计的全局序列分裂成几个独立子序列会破坏长期依赖关系;
- 可以通过构造不变特征空间来减小侧面信息变化带来的偏差。基于CNN构建的侧面信息设计不能直接应用在Trans上,需要单独设计。
- 因此首先要设计Trans的框架baseline专用于Reid,其次再在扩展长期依赖上针对局部特征和侧面信息设计单独模块。
2、相关论文
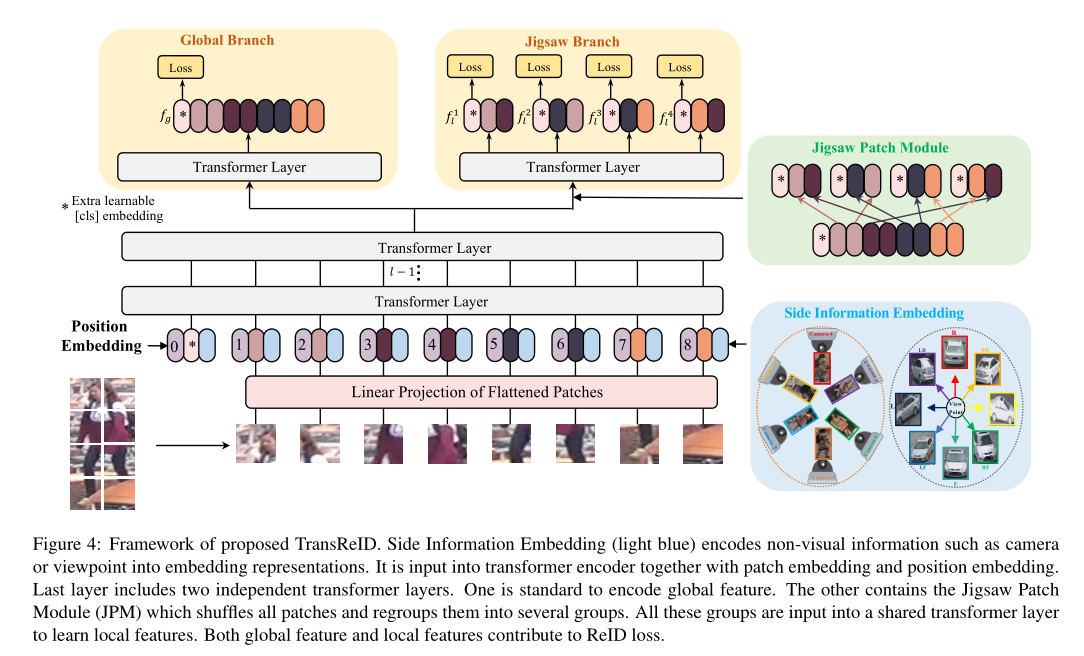
3、TransReid
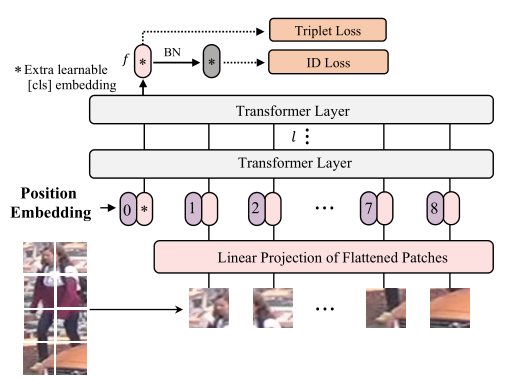
3.1 Trans baseline(全局特征)
-
![]()
-
分为特征提取和监督学习两个阶段。
- 分割N个固定大小patch,一个额外可学习的嵌入标记
[cls]被前置到输入序列。输出的[cls]标记作为一个全局特征表示f。 - 输入序列为:
Z_0 = [x_cls;F(x1_p);F(x2_p);...F(xn_p)] + P。p表示位置嵌入,F是将patch映射到D维的线性投影。使用l个Trans层学习特征表示。由于所有Trans层都有一个全局接受域,解决了基于cnn方法的接受域有限问题,并且没有下采样操作。 ![]()
- 分割N个固定大小patch,一个额外可学习的嵌入标记
-
第一步Overlapping Patches:不重叠的patch会使得周围局部邻近信息丢失,因此使用滑窗生成像素重叠的patch。patch大小设为P,步长S,分割N个patch,N越大性能越好但是计算成本也大:
![]()
-
第二步Position Embedding:由于Reid任务分辨率和原始图像分辨率不同,因此不能直接加载预训练好的位置嵌入,因此引入双线性2D插值来帮助处理任何给定的输入分辨率。与VIT类似位置嵌入可学习。 (embedding简单来说就是编码。)
-
第三步监督学习:通过构造全局特征的ID损失和三重损失来优化网络。ID损失Lid是没有标签平滑的交叉熵损失,输出的
f经过了BNNeck计算。对于三元组{a,p,n}具有软合并的三元组损失LT:after present next![]()
-
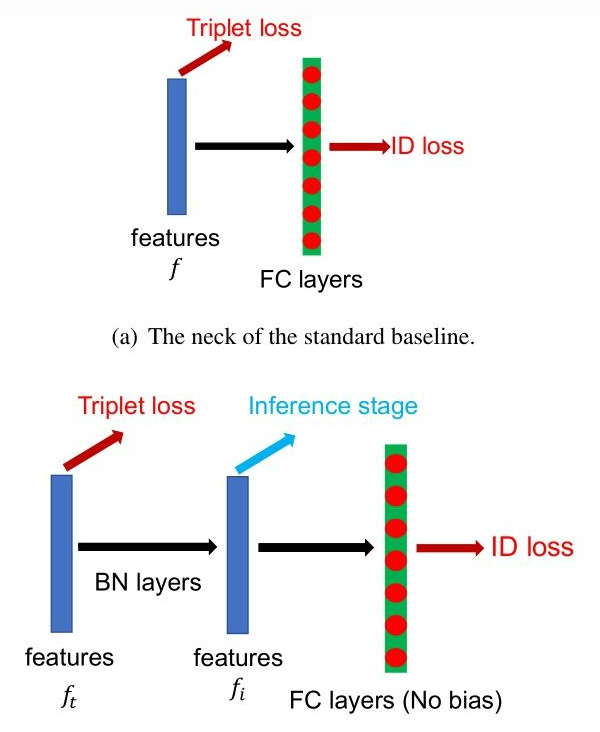
BNNeck:批量归一化
- 在行人重识别模型中,有很多工作都是融合了ID loss和Triplet loss来进行训练的,但是这种loss函数的目标并不协调,对于ID loss,特别在行人重检测,consine距离比欧氏距离更加适合作为优化标准,而Triplet loss更加注重在欧式空间提高类内紧凑性和类间可分性。因此两者关注的度量空间不一致,这就会导致一个可能现象就是当一个loss减小时另外一个在震荡或增大。
- 通过神经网络提取特征ft用于Triplet loss,然后通过一个BN层变成了fi,在训练时,分别使用ft和fi来优化这个网络,由于BN层的加入,ID loss就更容易收敛,另外,BNNeck也减少了ID loss对于ft优化的限制,从而使得Triplet loss也变得容易收敛了。因为超球体几乎是对称的坐标轴的原点,BNNECK的另一个技巧是去除分类器fc层的偏差,这个偏差会限制分类的超球面。在测试时,使用fi作为ReID的特征提取结果,这是由于Cosine距离相比欧氏距离更加有效的原因。
![]()
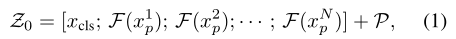

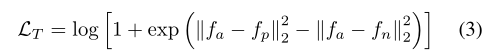
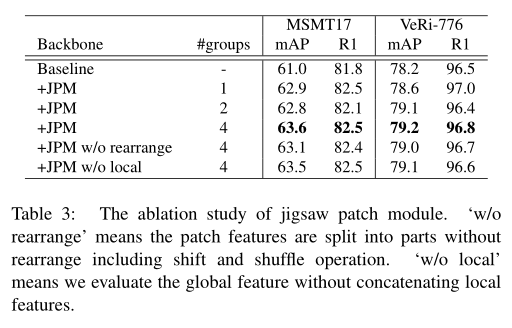
3.2 拼图patch模块 Jigsaw Patch Module
- 假设输入到最后一层的特征记为
Z_l-1,将嵌入的patch进行洗牌,重新组合成不同部分,每个部分包含多个随机的整体的patch嵌入。训练中引入额外噪声。 - 受shuffleNet启发,通过shift和shuffle操作对patch进行洗牌:
- 第一步shift:后移m个patch
- 第二步patch shuffle:特征内部进行局部置换,没改变整体的特征信息,又添加了新的变化,也是一种正则化手段。将置换后的特征分成k组编码成k个局部特征
{f1_l,f2_l..fk_l},输出到最后一层的全局特征计算和JPM局部特征计算并行进行,拼接并行结果得到最终的特征表达:{fg;f1_l;f2_l;..fk_l},因此每个特征可以编码不同的部件。整体损失定义如下:
![]()
![]()
![]()
![]()
![]()
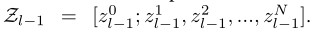

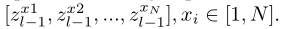
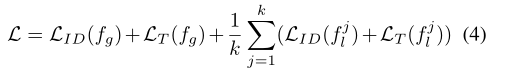

3.3 侧信息嵌入 side information embedding
-
主要针对场景偏误(不同摄像机,不同角度)提出的,将非视觉信息整合在嵌入表示中以学习不变特征。在输入嵌入时增加一维表示侧信息,即视角信息,相同视角编码相同。摄像机和视点编码为
SC(c,v),id值为r和q,SIE对每个patch来说相当于一个带超参的偏置项![]()
-
![]()
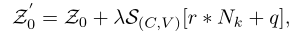
4、实验结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号