< AlexNet - 论文研读系列(1) 个人笔记 >
Alexnet - 论文研读系列(1) 个人笔记
论文基本信息
-
论文题目:
- ImageNet Classification with Deep Convolutional Neural Networks
-
作者:
- Krizhevsky, A., Sutskever, I., and Hinton, G. E.
-
论文原文:
一、论文架构
-
摘要:
- 简要说明了获得成绩、网络架构、技巧特点
-
1、introduction
- 领域方向概述
- 前人模型成绩
- 本文具体贡献
-
2、The Dataset
- 数据集来源,训练数据进行的一些预处理
-
3、The Architecture
- 网络模型大体组成
- ReLU
- Training on Multiple GPUs
- LRN (Local Response Normalization)
- Overlapping Pooling
- 网络模型整个具体架构
-
4、Reducing Overfitting
- Data Augmentation 数据扩充/数据增强
- Dropout
-
5、Details of learning
- 带动量的随机梯度下降
-
6、Results
- 测试集错误率
- 质量评估 - 具体图片分析,评估模型学到了什么
-
7、Discussion
二、网络结构
- AlexNet 有5个广义卷积层和3个广义全连接层。
-
广义的卷积层:包含了卷积层、池化层、
ReLU、LRN层等。 -
广义全连接层:包含了全连接层、
ReLU、Dropout层等
-

- 网络具体结构如下所示:
-
输入层会将
3@224x224的三维图片预处理变成3@227x227的三维图片- 为了使后续计算出来是整数
-
第二层广义卷积层、第四层广义卷积层、第五层广义卷积层都是分组卷积,仅采用本GPU内的通道数据进行计算
- 多GPU的设置完全是利用多GPU来提高运算的效率,下表给出都是如果只用单GPU情况下输入输出尺寸
-
第一层广义卷积层、第三层广义卷积层、第六层连接层、第七层连接层、第八层连接层执行的是全部通道数据的计算
-
第二层广义卷积层的卷积、第三层广义卷积层的卷积、第四层广义卷积层的卷积、第五层广义卷积层的卷积均采用
same填充(即:填充0,pad由核大小决定 - 卷积的三种模式:full, same, valid)-
当卷积的步长为1,核大小为3x3 时,如果不填充0,则
feature map的宽/高都会缩减 2 。因此这里填充0,使得输出feature map的宽/高保持不变。 -
第一层广义卷积层的卷积,以及所有的池化都是
valid填充(即:不填充 0,pad = 0 )
-
-
第六层广义连接层的卷积之后,会将
feature map展平为长度为 4096 的一维向量(这一层实际上看是卷积,使得向量展开成一维)
-
| 编号 | 网络层 | 子层 | 核/池大小 | 核数量 | 步长 | 激活函数 | 输入尺寸 | 输出尺寸 |
|---|---|---|---|---|---|---|---|---|
| 第0层 | 输入层 | - | - | - | - | - | - | 3@224x224 |
| 第1层 | 广义卷积层 | 卷积 | 11x11 | 96 | 4 | ReLU | 3@227x227 | 96@55x55 |
| 第1层 | 广义卷积层 | LRN | - | - | - | - | 96@55x55 | 96@55x55 |
| 第1层 | 广义卷积层 | 池化 | 3x3 | - | 2 | - | 96@55x55 | 96@27x27 |
| 第2层 | 广义卷积层 | 卷积 | 5x5 | 256 | 1 | ReLU | 96@27x27 | 256@27x27 |
| 第2层 | 广义卷积层 | LRN | - | - | - | - | 256@27x27 | 256@27x27 |
| 第2层 | 广义卷积层 | 池化 | 3x3 | - | 2 | - | 256@27x27 | 256@13x13 |
| 第3层 | 广义卷积层 | 卷积 | 3x3 | 384 | 1 | ReLU | 256@13x13 | 384@13x13 |
| 第4层 | 广义卷积层 | 卷积 | 3x3 | 384 | 1 | ReLU | 384@13x13 | 384@13x13 |
| 第5层 | 广义卷积层 | 卷积 | 3x3 | 256 | 1 | ReLU | 384@13x13 | 256@13x13 |
| 第5层 | 广义卷积层 | 池化 | 3x3 | - | 2 | - | 256@13x13 | 256@6x6 |
| 第6层 | 广义连接层 | 卷积 | 6x6 | 4096 | 1 | ReLU | 256@6x6 | 4096@1x1 |
| 第6层 | 广义连接层 | Dropout | - | - | - | - | 4096@1x1 | 4096@1x1 |
| 第7层 | 广义连接层 | 全连接 | - | - | - | ReLU | 4096 | 4096 |
| 第7层 | 广义连接层 | Dropout | - | - | - | - | 4096 | 4096 |
| 第8层 | 广义连接层 | 全连接 | - | - | - | - | 4096 | 1000 |
-
网络计算与参数数量
-
第一层:卷积层1,输入为
3@224x224的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为3@11x11; stride = 4, stride表示的是步长, pad = 0, 表示不扩充边缘;
wide = (227 + 2 x padding - kernel_size) / stride + 1 = 55
height = (227 + 2 x padding - kernel_size) / stride + 1 = 55
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map
最终第一层卷积的输出为96@55x55 -
第二层:卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:
48@5×5; pad = 2, stride = 1; 然后做 LRN, 最后 max_pooling, pool_size = (3, 3), stride = 2。后续计算基本类似 -
网络总参数总计约 6237万。
-
第6层广义连接层的卷积的参数数量最多,约3770万,占整体六千万参数的 60%。
-
原因是该子层的卷积核较大、输入通道数量较大、输出通道数量太多。该卷积需要的参数数量为:
255x6x6x4096 = 37,748,736
-
-
| 编号 | 网络层 | 子层 | 输出 Tensor size | 权重个数 | 偏置个数 | 参数数量 |
|---|---|---|---|---|---|---|
| 第0层 | 输入层 | - | 227x227x3 | 0 | 0 | 0 |
| 第1层 | 广义卷积层 | 卷积 | 55x55x96 | 34848 | 96 | 34944 |
| 第1层 | 广义卷积层 | 池化 | 27x27x96 | 0 | 0 | 0 |
| 第1层 | 广义卷积层 | LRN | 27x27x96 | 0 | 0 | 0 |
| 第2层 | 广义卷积层 | 卷积 | 27x27x256 | 614400 | 256 | 614656 |
| 第2层 | 广义卷积层 | 池化 | 13x13x256 | 0 | 0 | 0 |
| 第2层 | 广义卷积层 | LRN | 13x13x256 | 0 | 0 | 0 |
| 第3层 | 广义卷积层 | 卷积 | 13x13x384 | 884736 | 384 | 885120 |
| 第4层 | 广义卷积层 | 卷积 | 13x13x384 | 1327104 | 384 | 1327488 |
| 第5层 | 广义卷积层 | 卷积 | 13x13x256 | 884736 | 256 | 884992 |
| 第5层 | 广义卷积层 | 池化 | 6x6x256 | 0 | 0 | 0 |
| 第6层 | 广义连接层 | 卷积 | 4096×1 | 37748736 | 4096 | 37752832 |
| 第6层 | 广义连接层 | dropout | 4096×1 | 0 | 0 | 0 |
| 第7层 | 广义连接层 | 全连接 | 4096×1 | 16777216 | 4096 | 16781312 |
| 第7层 | 广义连接层 | dropout | 4096×1 | 0 | 0 | 0 |
| 第8层 | 广义连接层 | 全连接 | 1000×1 | 4096000 | 1000 | 4097000 |
| 总计 | - | - | - | - | - | 62,378,344 |
三、设计技巧与创新点
- AlexNet 成功的主要原因在于:
- 使用
ReLU激活函数 - 使用
dropout、数据集增强 、重叠池化等防止过拟合的方法 - 使用百万级的大数据集来训练
- 使用
GPU训练,以及的LRN使用 - 使用带动量的
mini batch随机梯度下降来训练
- 使用
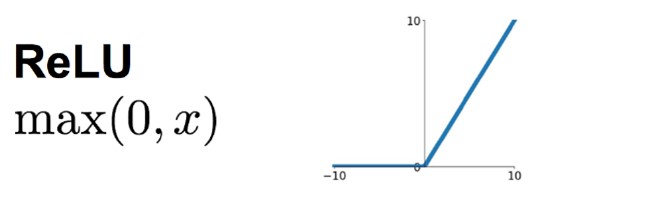
3.1 ReLU激活函数
-
Rectified Linear Unit:一种线性且不饱和的激活函数,在该论文中首次提出
-
f(x)=max(0,x) -
激活函数作用:激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
-
-
优点:
ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。- 由于
ReLU线性、非饱和的形式,在SGD(随机梯度下降)中能够快速收敛。 - 计算速度要快很多。
ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
-
缺点:
ReLU的输出不是“零为中心”(Notzero-centered output)。- 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。
-
具体解释参考:不同激活函数对比以及梯度消失、爆炸、神经元节点死亡的解释
3.2 数据集增强
-
AlexNet中使用的数据集增强手段:-
随机裁剪、随机水平翻转:原始图片的尺寸为
256x256,裁剪大小为224x224。-
训练阶段每一个
epoch中,对同一张图片进行随机性的裁剪,然后随机性的水平翻转。理论上相当于扩充了数据集(256-244)²x2=2048倍。 -
预测阶段不是随机裁剪,而是固定裁剪图片四个角、一个中心位置,再加上水平翻转,一共获得 10 张图片。
用这10张图片的预测结果的均值作为原始图片的预测结果。
-
-
PCA降噪:对RGB空间做PCA变换来完成去噪功能。同时在特征值上放大一个随机性的因子倍数(单位1加上一个N(0,0.1)的高斯绕动),也就是对颜色、光照作变换,从而保证图像的多样性。-
每一个epoch 重新生成一个随机因子。
-
该操作使得错误率下降1% 。
-
-
-
AlexNet的预测方法存在两个问题:-
这种固定裁剪四个角、一个中心的方式,把图片的很多区域都给忽略掉了。很有可能一些重要的信息就被裁剪掉。
-
裁剪窗口重叠,这会引起很多冗余的计算。
-
改进的思路是:
-
执行所有可能的裁剪方式,对所有裁剪后的图片进行预测。将所有预测结果取平均,即可得到原始测试图片的预测结果。
-
减少裁剪窗口重叠部分的冗余计算。
-
具体做法为:将全连接层用等效的卷积层替代,然后直接使用原始大小的测试图片进行预测。将输出的各位置处的概率值按每一类取平均(或者取最大),则得到原始测试图像的输出类别概率。
-
-
3.3 局部响应规范化 - LRN
-
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是
tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。 -
局部响应规范层
LRN:目的是为了进行一个横向抑制,使得不同的卷积核所获得的响应产生竞争。LRN层现在很少使用,因为效果不是很明显,而且增加了内存消耗和计算时间。- 在
AlexNet中,该策略贡献了1.2%的贡献率。
-
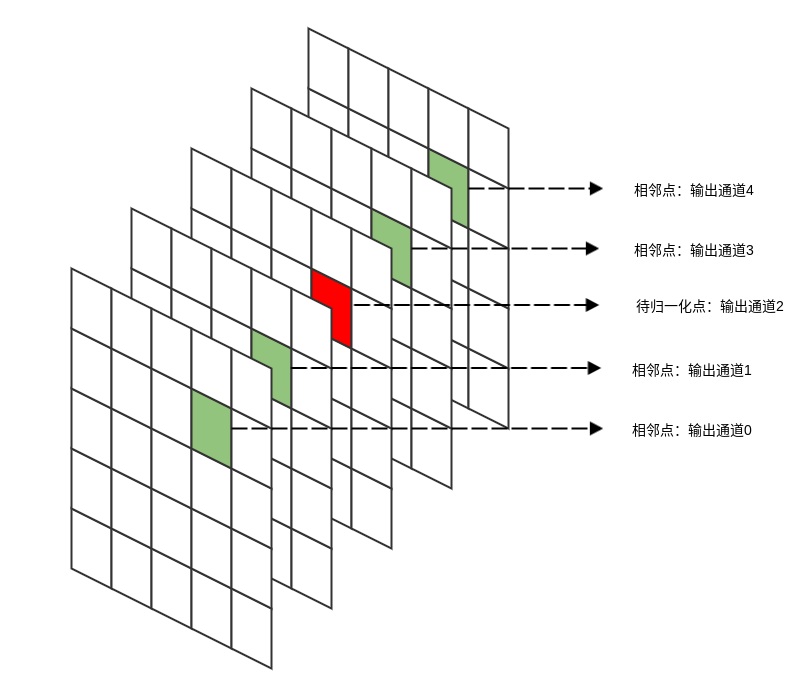
LRN的思想:输出通道i在位置(x,y)处的输出会受到相邻通道在相同位置输出的影响。
为了刻画这种影响,将输出通道i的原始值除以一个归一化因子。 -
公式为:
- 其中:\({a^{i}_x,_y}\)为输出通道
i在位置(x,y)处的原始值,\({b^{i}_x,_y}\)为归一化之后的值。n为影响第i通道的通道数量(分别从左侧、右侧n/2个通道考虑)。\(\alpha\),\(\beta\),\(k\)为超参数。
一般而言,k=2 , n=5 , α=10^−4 , β=0.75 - 功能类似于最大最小归一化:$$x_{i}=x_{i}/(x_{max}-x_{min})$$
3.4 多GPU训练
-
AlexNet使用两个GPU训练。网络结构图由上、下两部分组成:一个GPU运行图上方的通道数据,一个GPU运行图下方的通道数据,两个GPU只在特定的网络层通信。即:执行分组卷积。 -
第二、四、五层卷积层的核只和同一个
GPU上的前一层的feature map相连。 -
第三层卷积层的核和前一层所有
GPU的feature map相连。 -
全连接层中的神经元和前一层中的所有神经元相连。
3.5 Overlapping Pooling - 重叠池化
-
一般的池化是不重叠的,池化区域的大小与步长相同。
Alexnet中,池化是可重叠的,即:步长小于池化区域的大小。 -
重叠池化可以缓解过拟合,该策略贡献了
0.4%的错误率。- 为什么重叠池化会减少过拟合,很难用数学甚至直观上的观点来解答。一个稍微合理的解释是:重叠池化会带来更多的特征,这些特征很可能会有利于提高模型的泛化能力。
3.6 优化算法
-
AlexNet使用了带动量的mini-batch随机梯度下降法。 -
标准的带动量的
mini-batch随机梯度下降法为:
+
+
+ 具体细节见参考:[**随机梯度下降与动量详解**](https://blog.csdn.net/leviopku/article/details/80418672 "**随机梯度下降与动量详解**")
- 而论文中,作者使用了修正:
+
+
+ 其中 `momentum=0.9 , β=0.75 , η为学习率`
+ ${-\beta\cdot \eta w }$为权重衰减。论文指出:权重衰减对于模型训练非常重要,不仅可以起到正则化效果,还可以减少训练误差。
3.7 Dropout
- 引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。

-
Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。
-
具体细节见参考:理解Dropout

 浙公网安备 33010602011771号
浙公网安备 33010602011771号