分布式系统原理-CAP/2PC/3PC
1、CAP理论
CAP是分布式系统、特别是分布式存储领域中被讨论最多的理论,“什么是CAP定理?”在Quora 分布式系统分类下排名 FAQ 的 No.1。CAP在程序员中也有较广的普及,它不仅仅是“C、A、P不能同时满足,最多只能3选2”,以下尝试综合各方观点,从发展历史、工程实践等角度讲述CAP理论。
CAP定理
CAP由Eric Brewer在2000年PODC会议上提出[1][2],是Eric Brewer在Inktomi[3]期间研发搜索引擎、分布式web缓存时得出的关于数据一致性(consistency)、服务可用性(availability)、分区容错性(partition-tolerance)的猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
该猜想在提出两年后被证明成立[4],成为我们熟知的CAP定理:
- 数据一致性(consistency):如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性(strong consistency) (又叫原子性 atomic、线性一致性 linearizable consistency)[5]
- 服务可用性(availability):所有读写请求在一定时间内得到响应,可终止、不会一直等待
- 分区容错性(partition-tolerance):在网络分区的情况下,被分隔的节点仍能正常对外服务
Partition字面意思是网络分区,即因网络因素将系统分隔为多个单独的部分,有人可能会说,网络分区的情况发生概率非常小啊,是不是不用考虑P,保证CA就好[8]。要理解P,我们看回CAP证明[4]中P的定义:
In order to model partition tolerance, the network will be allowed to lose arbitrarily many messages sent from one node to another.
现实情况下我们面对的是一个不可靠的网络、有一定概率宕机的设备,这两个因素都会导致Partition,因而分布式系统实现中 P 是一个必须项,而不是可选项。
对于分布式系统工程实践,CAP理论更合适的描述是:在满足分区容错的前提下,没有算法能同时满足数据一致性和服务可用性:
In a network subject to communication failures, it is impossible for any web service to implement an atomic read/write shared memory that guarantees a response to every request.
CAP定理证明中的一致性指强一致性,强一致性要求多节点组成的被调要能像单节点一样运作、操作具备原子性,数据在时间、时序上都有要求。如果放宽这些要求,还有其他一致性类型:
- 序列一致性(sequential consistency)[13]:不要求时序一致,A操作先于B操作,在B操作后如果所有调用端读操作得到A操作的结果,满足序列一致性
- 最终一致性(eventual consistency)[14]:放宽对时间的要求,在被调完成操作响应后的某个时间点,被调多个节点的数据最终达成一致
可用性在CAP定理里指所有读写操作必须要能终止,实际应用中从主调、被调两个不同的视角,可用性具有不同的含义。当P(网络分区)出现时,主调可以只支持读操作,通过牺牲部分可用性达成数据一致。
工程实践中,较常见的做法是通过异步拷贝副本(asynchronous replication)、quorum/NRW,实现在调用端看来数据强一致、被调端最终一致,在调用端看来服务可用、被调端允许部分节点不可用(或被网络分隔)的效果。
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。
当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。
要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
Ref: https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem/
二、2PC
wiki:https://en.wikipedia.org/wiki/Two-phase_commit_protocol
two-phase commit protocol (2PC) is a type of atomic commitment protocol (ACP). It is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit or abort (roll back) the transaction (it is a specialized type of consensus protocol).
在分布式系统中,每一个机器节点虽然都能明确的知道自己执行的事务是成功还是失败,但是却无法知道其他分布式节点的事务执行情况。因此,当一个事务要跨越多个分布式节点的时候,为了保证该事务可以满足ACID,就要引入一个协调者(Cooradinator)。其他的节点被称为参与者(Participant)。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务进行提交。
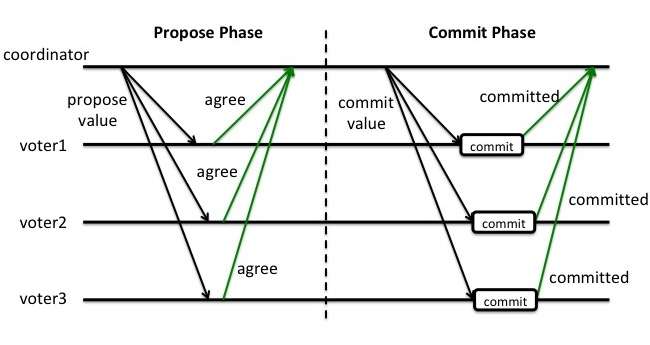
图1: 2PC, coordinator提议通过, voter{1,2,3}达成新的共识
PC1: Commit request phase[edit]
or voting phase
- The coordinator sends a query to commit message to all cohorts and waits until it has received a reply from all cohorts.
- The cohorts execute the transaction up to the point where they will be asked to commit. They each write an entry to their undo log and an entry to their redo log.
- Each cohort replies with an agreement message (cohort votes Yes to commit), if the cohort's actions succeeded, or an abort message (cohort votes No, not to commit), if the cohort experiences a failure that will make it impossible to commit.
PC2:
Commit phase[edit]
or Completion phase
Success[edit]
If the coordinator received an agreement message from all cohorts during the commit-request phase:
- The coordinator sends a commit message to all the cohorts.
- Each cohort completes the operation, and releases all the locks and resources held during the transaction.
- Each cohort sends an acknowledgment to the coordinator.
- The coordinator completes the transaction when all acknowledgments have been received.
Failure[edit]
If any cohort votes No during the commit-request phase (or the coordinator's timeout expires):
- The coordinator sends a rollback message to all the cohorts.
- Each cohort undoes the transaction using the undo log, and releases the resources and locks held during the transaction.
- Each cohort sends an acknowledgement to the coordinator.
- The coordinator undoes the transaction when all acknowledgements have been received.
Message flow[edit]
Coordinator Cohort
QUERY TO COMMIT
-------------------------------->
VOTE YES/NO prepare*/abort*
<-------------------------------
commit*/abort* COMMIT/ROLLBACK
-------------------------------->
ACKNOWLEDGMENT commit*/abort*
<--------------------------------
end
An * next to the record type means that the record is forced to stable storage.[4]
2PC缺点:
1、同步阻塞
After a cohort has sent an agreement message to the coordinator, the Cohort will block until a commit or rollback is received.
2、单点问题
Coordinator存在单点,如果在Commit阶段Coordinate宕机,将导致Cohort block.
3、数据不一致
Coordinator在发送完部分Commit请求后出现宕机,收到commit请求的cohort执行,其他的则未执行,数据不一致。
2PC的缺陷
2PC的缺点在于不能处理fail-stop形式的节点failure. 比如下图这种情况. 假设coordinator和voter3都在Commit这个阶段crash了, 而voter1和voter2没有收到commit消息. 这时候voter1和voter2就陷入了一个困境. 因为他们并不能判断现在是两个场景中的哪一种:
(1)上轮全票通过然后voter3第一个收到了commit的消息并在commit操作之后crash了,
(2)上轮voter3反对所以干脆没有通过.
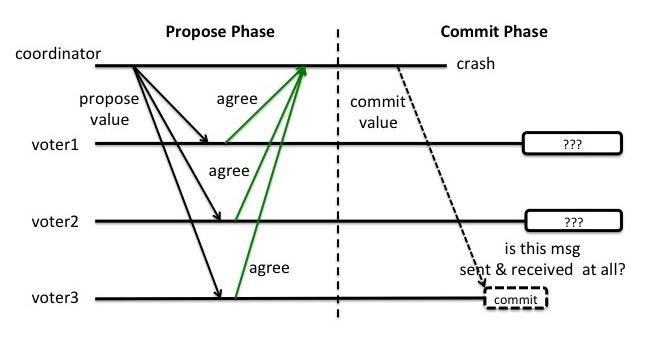
图3: 2PC, coordinator和voter3 crash, voter{1,2}无法判断当前状态而卡死
2PC在这种fail-stop情况下会失败是因为voter在得知Propose Phase结果后就直接commit了, 而并没有在commit之前告知其他voter自己已收到Propose Phase的结果. 从而导致在coordinator和一个voter双双掉线的情况下, 其余voter不但无法复原Propose Phase的结果, 也无法知道掉线的voter是否打算甚至已经commit. 为了解决这一问题, 3PC
3、3PC
除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
2PC中Commit_Request对应3PC中CanCommit+PreCommit
Commit 对应3PC中的DoCommit

1、Coordinator: sends a canCommit? message to the cohorts and moves to the waiting state.
2、Cohorts: receives a canCommit? message from the coordinator. If the cohort agrees it sends a Yes message to the coordinator and moves to the prepared state. Otherwise it sends a No message and move to abort state.
3、Coordinator: If there is a failure, timeout, or if the coordinator receives a No message in the waiting state, the coordinator aborts the transaction and sends an abort message to all cohorts. Otherwise the coordinator will receive Yes messages from all cohorts within the time window, so it sends preCommit messages to all cohorts and moves to the prepared state.
4、Cohorts: In the prepared state, if the cohort receives an abort message from the coordinator, fails, or times out waiting for a commit, it aborts. If the cohort receives a preCommit message, it sends an ACK message back and awaits a final commit or abort.
5、Coordinator: If the coordinator succeeds in the prepared state, it will move to the commit state. However if the coordinator times out while waiting for an acknowledgement from a cohort, it will abort the transaction.
6、Cohorts: If, after a cohort member receives a preCommit message, the coordinator fails or times out, the cohort member goes forward with the commit.
通过进入增加的这一个PreCommit阶段, voter可以得到Propose阶段的投票结果, 但不会commit; 而通过进入Commit阶段, voter可以盘出其他每个voter也都打算commit了, 从而可以放心的commit.
换言之, 3PC在2PC的Commit阶段里增加了一个barrier(即相当于告诉其他所有voter, 我收到了Propose的结果啦). 在这个barrier之前coordinator掉线的话, 其他voter可以得出结论不是每个voter都收到Propose Phase的结果, 从而放弃或选出新的coordinator; 在这个barrier之后coordinator掉线的话, 每个voter会放心的commit, 因为他们知道其他voter也都做同样的计划.
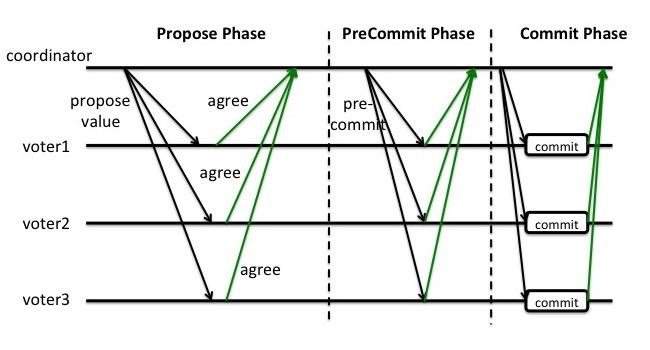
图4: 3PC, coordinator提议通过, voter{1,2,3}达成新的共识
3PC的缺陷
3PC可以有效的处理fail-stop的模式, 但不能处理网络划分(network partition)的情况---节点互相不能通信. 假设在PreCommit阶段所有节点被一分为二, 收到preCommit消息的voter在一边, 而没有收到这个消息的在另外一边. 在这种情况下, 两边就可能会选出新的coordinator而做出不同的决定.
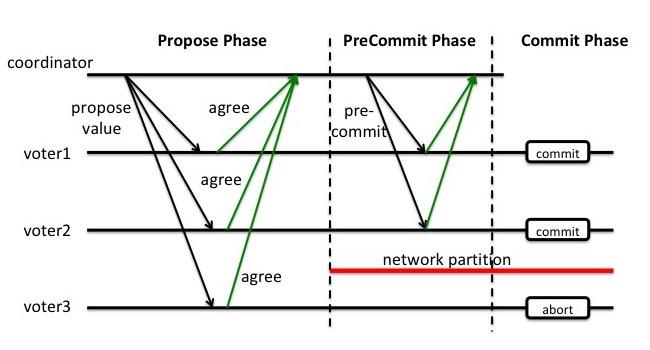
图5: 3PC, network partition, voter{1,2,3}失去共识
优缺点
优点:降低参与者阻塞范围,并能够在出现单点故障后继续达成一致
缺点:引入preCommit阶段,在这个阶段如果出现网络分区,协调者无法与参与者正常通信,参与者依然会进行事务提交,造成数据不一致。
无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
除了网络划分以外, 3PC也不能处理fail-recover的错误情况. 简单说来当coordinator收到preCommit的确认前crash, 于是其他某一个voter接替了原coordinator的任务而开始组织所有voter commit. 而与此同时原coordinator重启后又回到了网络中, 开始继续之前的回合---发送abort给各位voter因为它并没有收到preCommit. 此时有可能会出现原coordinator和继任的coordinator给不同节点发送相矛盾的commit和abort指令, 从而出现个节点的状态分歧.
这种情况等价于一个更真实或者更负责的网络环境假设: 异步网络. 在这种假设下, 网络传输时间可能任意长. 为了解决这种情况, 那就得请出下一篇的主角: Paxos
ref:
https://zhuanlan.zhihu.com/p/35298019

 浙公网安备 33010602011771号
浙公网安备 33010602011771号