
Bloom filter(布隆过滤器)概念与原理
写在前面
在大数据与云计算发展的时代,我们经常会碰到这样的问题。我们是否能高效的判断一个用户是否访问过某网站的主页(每天访问量上亿)或者需要统计网站的pv、uv。最直接的想法是将所有的访问者存起来,然后每次用户访问的时候与之前集合进行比较。不管是将访问信息存在内存(或数据库)都会对服务器造成非常大的压力。那是否存在一种方式,容忍一定的错误率,高效(计算复杂度、空间复杂度)的实现访问量信息的跟踪、统计呢?接下来介绍的布隆过滤器(BloomFilter)就可以满足当前的使用场景(注释:基数计数法同样能满足pv、uv的统计)。
布隆过滤器简介
布隆过滤器(BloomFilter)是1970年由布隆提出的一种空间空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并判断一个元素是否属于这个集合。使用布隆过滤器,存在第一类出错(Falsepositive),但是不会存在第二类错误(Falsenegative),因此,布隆过滤器拥有100%的召回率。也就是说,布隆过滤器能够准确判断一个元素不在集合内,但只能判断一个元素可能在集合内。因此,BloomFilter不适合“零错误”的应用场合。在能够容忍低错误的应用场合下,BloomFilter通过极少的错误换取了存储空间的极大节省。我们可以向布隆过滤器里添加元素,但是不能从中移除元素(普通布隆过滤器,增强的布隆过滤器是可以移除元素的)。随着布隆过滤器中元素的增加,犯第一类错误的可能性也随之增大。
算法描述
一个空的布隆过滤器有长度为M比特的bit数组构成,且所有位都初始化0。一个元素通过K个不同的hash函数随机散列到bit数组的K个位置上,K必须远小于M。K和M的大小由错误率(falsepositiverate)决定。

Bloom Filter的一个例子集合S{x,y,z}。带有颜色的箭头表示元素经过k(k=3)hash函数的到在M(bit数组)中的位置。元素W不在S集合中,因为元素W经过k个hash函数得到在M(bit数组)的k个位置中存在值为0的位置。
向集合S中添加元素x:x经过k个散列函数后,在M中得到k个位置,然后,将这k个位置的值设置为1。
判断x元素是否在集合S中:x经过k个散列函数后,的到k个位置的值,如果这k个值中间存在为0的,说明元素x不在集合中——元素x曾经插入到过集合S,则M中的k个位置会全部置为1;如果M中的k个位置全为1,则有两种情形。情形一:这个元素在这个集合中;情形二:曾经有元素插入的时候将这k个位置的值置为1了(第一类错误产生的原因FalsePositive)。简单的布隆过滤器无法区分这两种情况,在增强版中解决了这个问题。
设计k个相互独立的hash函数可能工作量比较大,但是一个好的hash函数是降低误判率的关键。一个良好的hash函数应该有宽输出,他们之间的冲突应尽量低,这样k个hash函数能静可能的将值hash的更多的位置。hash函数的设计是我们可以将k个不同的值( 0, 1, ..., k − 1)作为参数传入,或者将它们加入主键中。对于大的M或者k,hash函数之间的独立性对误判率影响非常大((Dillinger & Manolios (2004a),Kirsch & Mitzenmacher (2006))),Dillinger在k个散列函数中,多次使用同一个函数散列,分析对误判率的影响。
对于简单布隆过滤器来说,从集合S中移除元素x是不可能的,且falsenegatives不允许。元素散列到k个位置,尽管可以 将这k个位置的值置为0来移除这个元素,但是这同事也移除了那些散落后,有值落在这k位中的元素。因此,没有一种方法可以判断移除这个元素后是否影响其它已经加入集合中的元素,将k个位置置为0会引入二类误差(falsenegative)。
时间复杂度和空间复杂度
在falsepositives的情况下,布隆过滤器相比其它的集合(平衡二叉树、树、hash表、数组、链表)只需要少量的存储空间。布隆过滤器的添加和检查元素是否在集合内的复杂度为O(K)。Hash表的平均复杂度比布隆过滤器更低。Bloom过滤器在误差最优的情况下,平均每个元素大概是1.44bit。
错误率估计
布隆过滤器判断一个元素是否属于它表示的集合时会存在已定的错误率(falsepositiverate),接下来就估计错误率的大小。在估计误差前,我们假设kn<m(k哈希函数的个数,n集合中元素的个数,mbit数组的长度)且哈希函数之间时相互独立的,哈希函数散列的bit数组M中的位置时完全随机的。
一个长度为m的bit数组,元素在插入时经过一次哈希散列后bit数组的某个位置的值没有被置为1的概率为
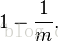
经过k个哈希函数散列后,还未被置为1的概率为
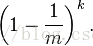
如果插入n个元素后,该位置还未被置为1的概率为
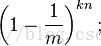
所以被置为1的概率为
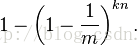
现在判断一个元素是否在结合中,经过k个函数散列到k个bit数组的不同位置。所有这些位置的值为1的概率——误判率。

这里使用了极限
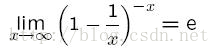
这种计算方法不严格,因为前面假设哈希函数和散列后值的分布是相互独立的。但是,这个假设随着m和n的增大误判率更接近真实的误判率。
Mitzenmacher and Upfal证明无假设情况下的误判率的期望值相同。
最优的哈希函数个数
既然布隆过滤器将集合映射到位数组中,那么选多少个hash函数才是错误率最低的情况。这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
误判率
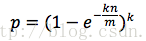
两边取自然对数,
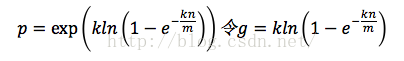
,只要g取最小值,p就能取到最小值。由于p=e^(-nk/m),我们可以将g改写为
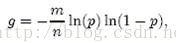
根据对称法则可以得到当p=1/2时,也就是k=ln2*(m/n)时,g取得最小值,在这种情况下,最小的错误率p=(1/2)^k≈(0.6185)^(m/n)。p=1/2对应着位数组中0和1各半。换句话说,想保持错误率低,最好让位数组有一半还空着。
位数组的大小
在给定n(集合中元素的个数)和错误率(最优函数个数k的的错误率)的情况下,位数组M的大小计算,在最优k的情况下
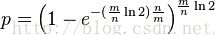
化简为
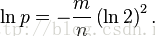
得到
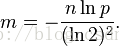
这意味着在错误率为p的情况下,布隆过滤器的长度为m才能容纳n个元素(以上计算基于n,m->∞)。
布隆过滤器中元素个数的估算
Swamidass & Baldi (2007)给出了布隆过滤器元素个数估算的方法(详细证明方式参考论文)
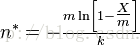
其中,n*表示布隆过滤元素个数的估算值,m表示布隆过滤器的大小,k表示哈希函数的个数,X表示布隆过滤器位值位1的个数。
布隆过滤器的并和交
布隆过滤器可以用来估算两个集合之间的并合交。一下给出两个集合之间并的计算方式:
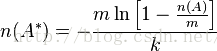
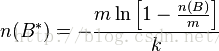
A和B之间的并集的个数为:
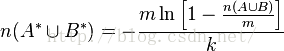
所以A*与B*之间的交集的个数为:
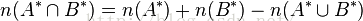
布隆过滤的特性
布隆过滤器能够容纳任意多的元素(误判率会增加),总是能向布隆过滤器中添加元素,不会报错(OutMemory等);
布隆过滤器可以很方便的通过计算机的or \and操作计算两个集合元素之间的交集(intersection)和并集(union),但是同样影响布隆过滤的准确性。
例子
Googlebigtable、apachehbase和apachecassandra使用bloom过滤器判断是否存在该行(rows)或(colums),以减少对磁盘的访问,提高数据库的访问性能;
比特币使用布隆过滤判断钱包是否同步OK。
总结
在计算机这个领域里,我们常常碰到时间换空间\或空间换时间的情况,为了达到某一方面的性能,牺牲另外一方面。BloomFilter在时间和空间着两者之间引入了另外一个概念——错误率。也就是前文提到的布隆过滤不能准确判断一个元素是否在集合内(类似的设计还有基数统计法)。引入错误率后,极大的节省了存储空间。
自从Burton Bloom在70年代提出Bloom Filter之后,Bloom Filter就被广泛用于拼写检查和数据库系统中。近一二十年,伴随着网络的普及和发展,Bloom Filter在网络领域获得了新生,各种Bloom Filter变种和新的应用不断出现。可以预见,随着网络应用的不断深入,新的变种和应用将会继续出现,Bloom Filter必将获得更大的发展。

