【转载】c++对象模型:内存布局
图说C++对象模型:对象内存布局详解
正文
0.前言
文章较长,而且内容相对来说比较枯燥,希望对C++对象的内存布局、虚表指针、虚基类指针等有深入了解的朋友可以慢慢看。
本文的结论都在VS2013上得到验证。不同的编译器在内存布局的细节上可能有所不同。
文章如果有解释不清、解释不通或疏漏的地方,恳请指出。
1.何为C++对象模型?
引用《深度探索C++对象模型》这本书中的话:
有两个概念可以解释C++对象模型:
- 语言中直接支持面向对象程序设计的部分。
- 对于各种支持的底层实现机制。
直接支持面向对象程序设计,包括了构造函数、析构函数、多态、虚函数等等,这些内容在很多书籍上都有讨论,也是C++最被人熟知的地方(特性)。而对象模型的底层实现机制却是很少有书籍讨论的。对象模型的底层实现机制并未标准化,不同的编译器有一定的自由来设计对象模型的实现细节。在我看来,对象模型研究的是对象在存储上的空间与时间上的更优,并对C++面向对象技术加以支持,如以虚指针、虚表机制支持多态特性。
举个例子,下面一段代码:

1 class A
2 {
3 public:
4 void foo(){ cout << "A foo" << endl; }
5 };
6 class B
7 {
8 public:
9 void foo(){ cout << "B foo" << endl; }
10 };
oo将编译成:
1 void foo(const A* this)( cout << "A foo" << endl; } 2 void foo(const B* this)( cout << "B foo" << endl; }
调用a.foo(),编译器将转换成foo(&a)
有趣的是,A* pa = NULL; pa->foo();也没有异常退出,因为没有通过this引用任何成员变量,这个时候不过this指针为NULL而已。
静态成员函数
上面说的只是面向对象的非静态成员函数,如果说到类里面的静态成员函数,解释又是另外一个,请看下文。
1、静态数据成员
特点:
A、内存分配:在程序的全局数据区分配。
B、初始化和定义:
a、静态数据成员定义时要分配空间,所以不能在类声明中定义。
b、为了避免在多个使用该类的源文件中,对其重复定义,所在,不能在类的头文件中
定义。
c、静态数据成员因为程序一开始运行就必需存在,所以其初始化的最佳位置在类的内部实现。
C、特点
a、对相于 public,protected,private 关键字的影响它和普通数据成员一样,
b、因为其空间在全局数据区分配,属于所有本类的对象共享,所以,它不属于特定的类对象,在没产生类对象时其作用域就可见,即在没有产生类的实例时,我们就可以操作它。
D、访问形式
a、 类对象名.静态数据成员名
b、 类类型名:: 静态数据成员名
E、静态数据成员,主要用在类的所有实例都拥有的属性上。比如,对于一个存款类,帐号相对 于每个实例都是不同的,但每个实例的利息是相同的。所以,应该把利息设为存款类的静态数据成员。这有两个好处,第一,不管定义多少个存款类对象,利息数据成员都共享分配在全局区的内存,所以节省存贮空间。第二,一旦利息需要改变时,只要改变一次,则所有存款类对象的利息全改变过来了,因为它们实际上是共用一个东西。
2、静态成员函数
特点:
A、静态成员函数与类相联系,不与类的对象相联系。
B、静态成员函数不能访问非静态数据成员。原因很简单,非静态数据成员属于特定的类实例。
作用:
主要用于对静态数据成员的操作。
调用形式:
A、类对象名.静态成员函数名()
B、类类型名:: 静态成员函数名()
上面是一段精辟的分析,但是他没有说道编译器是如何实现这个调用的。下面一段代码,将解释这个过程:
1 #include <iostream>
2 using namespace std;
3
4 class A
5 {
6 public:
7 static int count;
8 void foo(){ cout << "A foo" << endl; } // 如果这样声明和定义一个成员函数,将直接产生一个 foo(A& this) 类型的函数
9 static void goo(){ cout <</* this << */"A goo"<< endl; } // 静态函数没有 this 指针
10 void too(){ cout << typeid(*this).name() << endl; }
11 };
12
13 int A::count = 0;
14
15 class B : public A
16 {
17 public:
18 // 如果静态函数只能通过域运算符来调用的话,那class在静态意义下就成了命名域的概念了
19 // 如果没有下面这个函数,A类的goo函数将会继承下来,说明作为类的命名空间,也可以继承
20 static void goo(){ cout << "B goo" << endl;} // 一个问题,静态的成员函数,是怎么区分开的呢?
21 };
22
23 int main()
24 {
25 A a , *pa;
26 pa->goo(); // 静态也跟普通函数一样,没有多态效果
27 a.goo(); // 是否是直接翻译成 A::goo() 竟然说我没引用过 a !- -
28 // a.foo(); // this 是关键字,不能拿来作为一个全局函数的参数,在转成 foo(&a) 的时候,一定是调用 foo(A& this) 这个函数
29 // A::foo(); // 这个 foo 没有带参数,只能调用静态的,静态的就直接编译成类似全局函数的不带 this 参数的类型
30 A::goo(); // 这样调用是正确的,这说明它没有 this 指针作为形参
31 system("pause");
32 return 0;
33 }
编译运行,将产生一个警告,说对象a和指针pa从来没引用过!通过对象调用静态函数,已经通过类型识别,被编译器替换成A::goo(),这个是由编译器做的,所以替换之后a就只定义了,但是没用引用过。换句话,static的成员函数,只能通过域运算符来调用,无论你是用对象调用还是用指针调用。
static的成员变量,也是如此,只能通过翻译成域运算符来调用。这样两者结合在一起,说明了“类其实除了可以定义变量,还有一个重要的作用就是它是个命名域,相当于std::cout这样。而且,这个命名域,还能继承下来。”
C++和C语言的编译方式不同。C语言中的函数在编译时名字不变,或者只是简单的加一个下划线_(不同的编译器有不同的实现),例如,func() 编译后为 func() 或 _func()。
而C++中的函数在编译时会根据命名空间、类、参数签名等信息进行重新命名,形成新的函数名。这个重命名的过程是通过一个特殊的算法来实现的,称为名字编码(Name Mangling)。
Name Mangling 是一种可逆的算法,既可以通过现有函数名计算出新函数名,也可以通过新函数名逆向推演出原有函数名。
Name Mangling 可以确保新函数名的唯一性,只要命名空间、所属的类、参数签名等有一个不同,那么产生的新函数名也不同。
C++为什么要弄出虚表这个东西?
2020.5.3有更新:补充了gdb查看虚表内容的过程;重绘了图。
如其他答主所言:虚表是编译器的实现,而非C++的语言标准。但仅指出这点,对题主而言似乎并没有太大价值,解决不了题主的疑惑。
以下正文:
回顾:从C的POD到C++的类
回顾一下C语言纯POD的结构体(struct)。
如果用C语言实现一个类似面向对象的类,应该怎么做呢?
// 写法一
#include <stdio.h>
typedef struct Actress {
int height; // 身高
int weight; // 体重
int age; // 年龄(注意,这不是数据库,不必一定存储生日)
void (*desc)(struct Actress*);
} Actress;
// obj中各个字段的值不一定被初始化过,通常还会在类内定义一个类似构造函数的函数指针,这里简化
void profile(Actress* obj) {
printf("height:%d weight:%d age:%d\n", obj->height, obj->weight, obj->age);
}
int main() {
Actress a;
a.height = 168;
a.weight = 50;
a.age = 20;
a.desc = profile;
a.desc(&a);
return 0;
}想达到面向对象中数据和操作封装到一起的效果,只能给struct里面添加函数指针,然后给函数指针赋值。然而在C语言的项目中你很少会看到这种写法,主要原因就是函数指针是有空间成本的,这样写的话每个实例化的对象中都会有一个指针大小(比如8字节)的空间占用,如果实例化N个对象,每个对象有M个成员函数,那么就要占用N*M*8的内存。所以通常C语言不会用在struct内定义成员函数指针的方式,而是直接:
// 写法二
#include <stdio.h>
typedef struct Actress {
int height; // 身高
int weight; // 体重
int age; // 年龄(注意,这不是数据库,不必一定存储生日)
} Actress;
void desc(Actress* obj) {
printf("height:%d weight:%d age:%d\n", obj->height, obj->weight, obj->age);
}
int main() {
Actress a;
a.height = 168;
a.weight = 50;
a.age = 20;
desc(&a);
return 0;
}Redis中AE相关的代码实现,便是如此。
再看一个C++普通的类:
#include <stdio.h>
class Actress {
public:
int height; // 身高
int weight; // 体重
int age; // 年龄(注意,这不是数据库,不必一定存储生日)
void desc() {
printf("height:%d weight:%d age:%d\n", height, weight, age);
}
};
int main() {
Actress a;
a.height = 168;
a.weight = 50;
a.age = 20;
a.desc();
return 0;
}
你觉得你这个class实际相当于C语言两种写法中的哪一个?
看着像写法一?其实相当于写法二。C++编译器实际会帮你生成一个类似上例中C语言写法二的形式(这也算是C++ zero overhead指导方针的一个体现)。当然实际并不完全一致,因为C++支持重载的关系,会存在命名崩坏。但主要思想相同,虽不中,亦不远矣。
You shouldn't pay for what you don't use.
看到这,你会明白:C++中类和操作的封装只是对于程序员而言的。而编译器编译之后其实还是面向过程的代码。编译器帮你给成员函数增加一个额外的类指针参数,运行期间传入对象实际的指针。类的数据(成员变量)和操作(成员函数)其实还是分离的。
每个函数都有地址(指针),不管是全局函数还是成员函数在编译之后几乎类似。
在类不含有虚函数的情况下,编译器在编译期间就会把函数的地址确定下来,运行期间直接去调用这个地址的函数即可。这种函数调用方式也就是所谓的『静态绑定』(static binding)。
再看下虚函数的用法
虚函数的出现其实就是为了实现面向对象三个特性之一的『多态』。何谓多态(polymorphism)?
#include <stdio.h>
#include <string>
using std::string;
class Actress {
public:
Actress(int h, int w, int a):height(h),weight(w),age(a){};
virtual void desc() {
printf("height:%d weight:%d age:%d\n", height, weight, age);
}
int height; // 身高
int weight; // 体重
int age; // 年龄(注意,这不是数据库,不必一定存储生日)
};
class Sensei: public Actress {
public:
Sensei(int h, int w, int a, string c):Actress(h, w, a),cup(c){};
virtual void desc() {
printf("height:%d weight:%d age:%d cup:%s\n", height, weight, age, cup.c_str());
}
string cup;
};
int main() {
Sensei s(168, 50, 20, "36D");
s.desc();
return 0;
}
上例子,最终输出显而易见:
height:168 weight:50 age:20 cup:36D
再看:
Sensei s(168, 50, 20, "36D");
Actress* a = &s;
a->desc();
Actress& a2 = s;
a2.desc();
这种情况下,用父类指针指向子类的地址,最终调用desc函数还是调用子类的。
输出:
height:168 weight:50 age:20 cup:36D
height:168 weight:50 age:20 cup:36D
这个现象称之为『动态绑定』(dynamic binding)或者『延迟绑定』(lazy binding)。
但倘若你 把父类Actress中desc函数前面的vitural去掉,这个代码最终将调用父类的函数desc,而非子类的desc!输出:
height:168 weight:50 age:20
height:168 weight:50 age:20
这是为什么呢?指针实际指向的还是子类对象的内存空间,可是为什么不能调用到子类的desc?这个就是我在第一部分说过的:类的数据(成员变量)和操作(成员函数)其实是分离的。仅从对象的内存布局来看,只能看到成员变量,看不到成员函数。因为调用哪个函数是编译期间就确定了的,编译期间只能识别父类的desc。
好了,现在我们对于C++如何应用多态有了一定的了解,那么多态又是如何实现的呢?
终于谈到虚表
C++具体多态的实现一般是编译器厂商自由发挥的。但无独有偶,使用虚表指针来实现多态几乎是最常见做法(基本上已经是最好的多态实现方法)。废话不多说,继续看代码,有微调:
#include <stdio.h>
class Actress {
public:
Actress(int h, int w, int a):height(h),weight(w),age(a){};
virtual void desc() {
printf("height:%d weight:%d age:%d\n", height, weight, age);
}
virtual void name() {
printf("I'm a actress");
}
int height; // 身高
int weight; // 体重
int age; // 年龄(注意,这不是数据库,不必一定存储生日)
};
class Sensei: public Actress {
public:
Sensei(int h, int w, int a, const char* c):Actress(h, w, a){
snprintf(cup, sizeof(cup), "%s", c);
};
virtual void desc() {
printf("height:%d weight:%d age:%d cup:%s\n", height, weight, age, cup);
}
virtual void name() {
printf("I'm a sensei");
}
char cup[4];
};
int main() {
Sensei s(168, 50, 20, "36D");
s.desc();
Actress* a = &s;
a->desc();
Actress& a2 = s;
a2.desc();
return 0;
}
父类有两个虚函数,子类覆写了这两个虚函数。
clang有个命令可以输出对象的内存布局(不同编译器内存布局未必相同,但基本类似):
clang -cc1 -fdump-record-layouts -stdlib=libc++ actress.cpp
可以得到:
*** Dumping AST Record Layout
0 | class Actress
0 | (Actress vtable pointer)
8 | int height
12 | int weight
16 | int age
| [sizeof=24, dsize=20, align=8,
| nvsize=20, nvalign=8]
*** Dumping AST Record Layout
0 | class Sensei
0 | class Actress (primary base)
0 | (Actress vtable pointer)
8 | int height
12 | int weight
16 | int age
20 | char [4] cup
| [sizeof=24, dsize=24, align=8,
| nvsize=24, nvalign=8]内存布局、大小、内存对齐都一目了然。
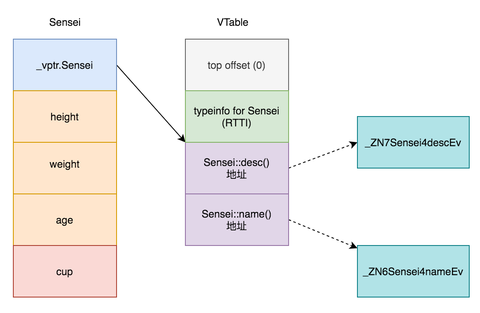
可以发现父类Actress的起始位置多了一个Actress vtable pointer。子类Sensei是在它的基础上多了自己的成员cup。
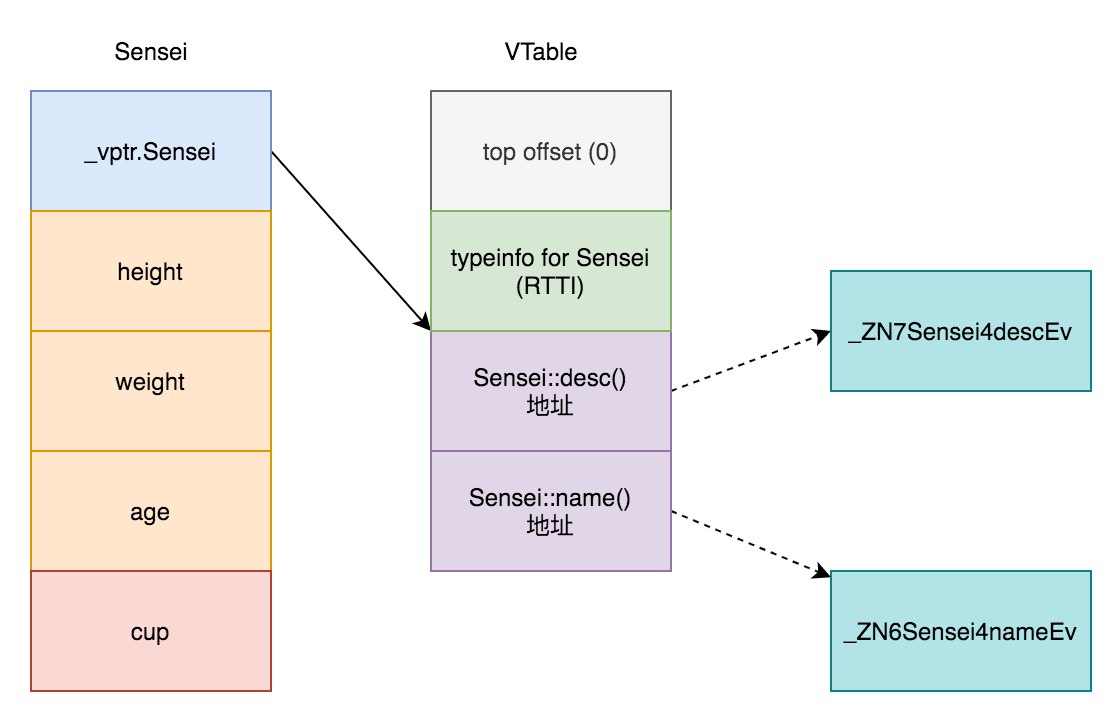
也就是说在含有虚函数的类编译期间,编译器会自动给这种类在起始位置追加一个虚表指针(称之为:vptr)。vptr指向一个虚表(称之为:vtable 或 vtbl),虚表中存储了实际的函数地址。
再看下虚表存储了什么东西。你在网上搜一下资料,肯定会说虚表里存储了虚函数的地址,但是其实不止这些!clang同样有命令:
clang -Xclang -fdump-vtable-layouts -stdlib=libc++ -c actress.cpp
g++也有打印虚表的操作(请在Linux上使用g++),会自动写到一个文件里:
g++ -fdump-class-hierarchy actress.cpp
看下clang的结果:
Vtable for 'Actress' (4 entries).
0 | offset_to_top (0)
1 | Actress RTTI
-- (Actress, 0) vtable address --
2 | void Actress::desc()
3 | void Actress::name()
VTable indices for 'Actress' (2 entries).
0 | void Actress::desc()
1 | void Actress::name()
Vtable for 'Sensei' (4 entries).
0 | offset_to_top (0)
1 | Sensei RTTI
-- (Actress, 0) vtable address --
-- (Sensei, 0) vtable address --
2 | void Sensei::desc()
3 | void Sensei::name()
VTable indices for 'Sensei' (2 entries).
0 | void Sensei::desc()
1 | void Sensei::name()g++的结果(其实也比较清晰,甚至更清晰):
Vtable for Actress
Actress::_ZTV7Actress: 4u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI7Actress)
16 (int (*)(...))Actress::desc
24 (int (*)(...))Actress::name
Class Actress
size=24 align=8
base size=20 base align=8
Actress (0x0x7f9b1fa8c960) 0
vptr=((& Actress::_ZTV7Actress) + 16u)
Vtable for Sensei
Sensei::_ZTV6Sensei: 4u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI6Sensei)
16 (int (*)(...))Sensei::desc
24 (int (*)(...))Sensei::name
Class Sensei
size=24 align=8
base size=24 base align=8
Sensei (0x0x7f9b1fa81138) 0
vptr=((& Sensei::_ZTV6Sensei) + 16u)
Actress (0x0x7f9b1fa8c9c0) 0
primary-for Sensei (0x0x7f9b1fa81138)可以看出二者其实基本一致,只是个别名称叫法不同。
所有虚函数的的调用取的是哪个函数(地址)是在运行期间通过查虚表确定的。
更新:vptr指向的并不是虚表的表头,而是直接指向的虚函数的位置。使用gdb或其他工具可以发现:
(gdb) p s
$2 = {<Actress> = {_vptr.Actress = 0x400a70 <vtable for Sensei+16>, height = 168, weight = 50, age = 20}, cup = "36D"}
vptr指向的是Sensei的vtable + 16个字节的位置,也就是虚表的地址。
虚表本身是连续的内存。动态绑定的实现也就相当于(假设p为含有虚函数的对象指针):
(*(p->vptr)[n])(p)
但其实上面的图片也只是简化版,不是完整的的虚表。通过gdb查看,你其实可以发现子类和父类的虚表是连在一起的。上面gdb打印出了虚表指针指向:0x400a70。我们倒退16个字节(0x400a60)输出一下:
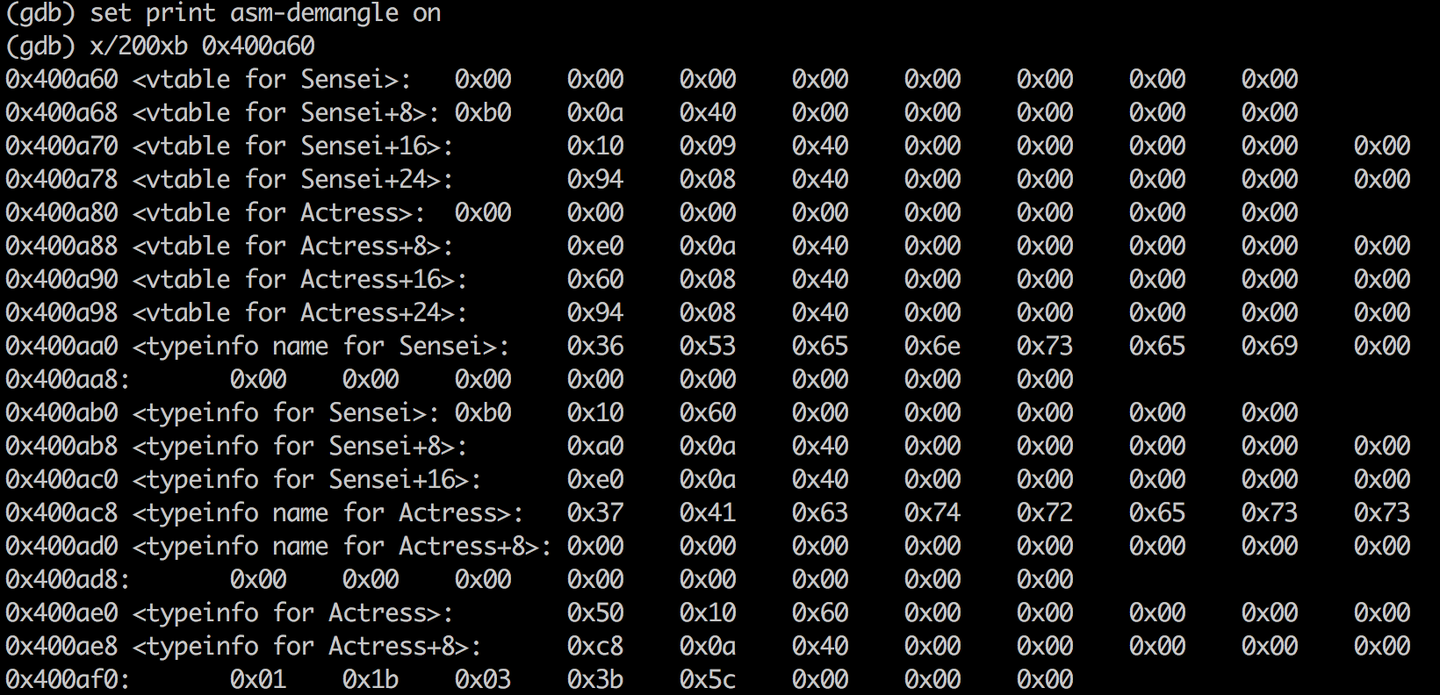
可以发现子类和父类的虚表其实是连续的。并且下面是它们的typeinfo信息也是连续的。
虚表的第一个槽位(vtable for Sensei)值为0。
虚表的第二个槽位(vtable for Sensei+8)指向的其实是0x400ab0,也就是下面的typeinfo for Sensei。
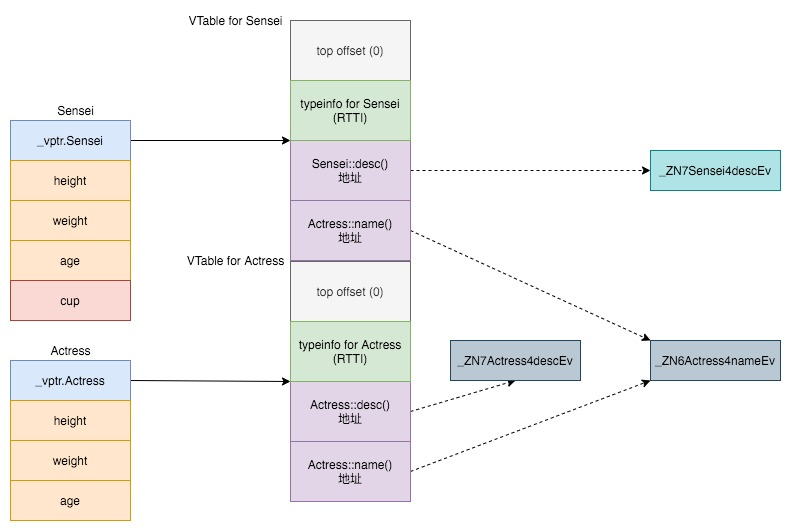
再改一下代码。我们让子类Sensei只重载一个父类函数desc。
class Sensei: public Actress {
public:
Sensei(int h, int w, int a, const char* c):Actress(h, w, a){
snprintf(cup, sizeof(cup), "%s", c);
};
virtual void desc() {
printf("height:%d weight:%d age:%d cup:%s\n", height, weight, age, cup);
}
char cup[4];
};
其他地方不变,重新用clang或g++刚才的命令执行一遍。clang的输出:
Vtable for 'Actress' (4 entries).
0 | offset_to_top (0)
1 | Actress RTTI
-- (Actress, 0) vtable address --
2 | void Actress::desc()
3 | void Actress::name()
VTable indices for 'Actress' (2 entries).
0 | void Actress::desc()
1 | void Actress::name()
Vtable for 'Sensei' (4 entries).
0 | offset_to_top (0)
1 | Sensei RTTI
-- (Actress, 0) vtable address --
-- (Sensei, 0) vtable address --
2 | void Sensei::desc()
3 | void Actress::name()
VTable indices for 'Sensei' (1 entries).
0 | void Sensei::desc()可以看到子类的name由于没有重载,所以使用的还是父类的。一图胜千言:
好了,写了这么多,不知不觉,这个回答已经类似一篇文章的长度。相信题主应该已经能理解虚表存在的意义及其实现原理。但同时我也埋下了新的坑没有填:虚表中的前两个槽位是做什么用的?关于这个问题可以阅读我另外一个回答:
多重继承中,每个虚表第一个槽中的type_info是对应base class还是全是derived class的类型?www.zhihu.com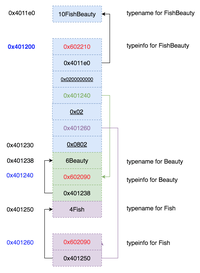
简而言之,第一个槽位存储的offset,是一种被称为thunk的技术(或者说技巧)。第二个槽位存储着为RTTI服务的type_info信息。你也可以参考:
https://www.zhihu.com/question/389546003/answer/1194780618
多重继承中,每个虚表第一个槽中的type_info是对应base class还是全是derived class的类型?
不同编译器的实现是不同的,在比较熟知的Itanium C++ABI(gcc、clang的参考标准)中,type_info是在第二个槽的。我在之前的其他回答中道出了虚表的结构。
C++为什么要弄出虚表这个东西?www.zhihu.com
那篇回答主要是通过单继承举例,解释了虚表指针、虚表与多态的关系。当时并留下来一个扣子——虚表的前两个槽中存放的东西,并未具体解释。今天我来继续解疑答惑,权且算作那篇回答的姊妹篇。以下正文:
多重继承的迷思
继承的出现增加了代码可复用性,减少了冗余。作为一门古老的面向对象编程语言,C++是支持多重继承的,而后来完全面向对象的Java则不支持多重继承,只支持单继承+接口的形式来派生类的。
各类面向对象的入门教程通常喜欢用现实世界的例子来阐述父类(基类)和子类(派生类),比如汽车啊,动物啊。今天我也用一个『现实』例子来比喻多重继承。假如有一天你流落荒岛,岛上有两种美人鱼可以陪伴你度过荒岛余生,你选择哪种?
姑且称A为美人鱼,B为鱼美人。美人鱼和鱼美人都是继承自美人类和鱼这两个class的。这便是一个典型的多重继承的例子。你会发现多重继承有个特点就行继承的类是有顺序的!
class A: public Beauty, Fish {};
class B: public Fish, Beauty {};
尽管我们在实际编程中,在使用多重继承的子类时,你可能不会觉察出继承顺序差别。但是其内部的内存布局确实大不相同的。你也许会说,这无非就是影响两个父类在内部布局中的前后顺序问题,还不都是两个父类的成员变量堆到一起嘛!
看似简单,但当涉及到多态的时候,这个继承问题就变得复杂起来。
虚表结构
定义一个鱼类:Fish,简单起见,都不包含数据成员。
class Fish {
public:
virtual ~Fish(){};
virtual void echo() {cout<<"I'm a fish"<<endl;};
};
简单回顾一下虚表的结构。探究的过程可以参考前面提到的那篇回答。
以Fish为例,虚表的结构为:
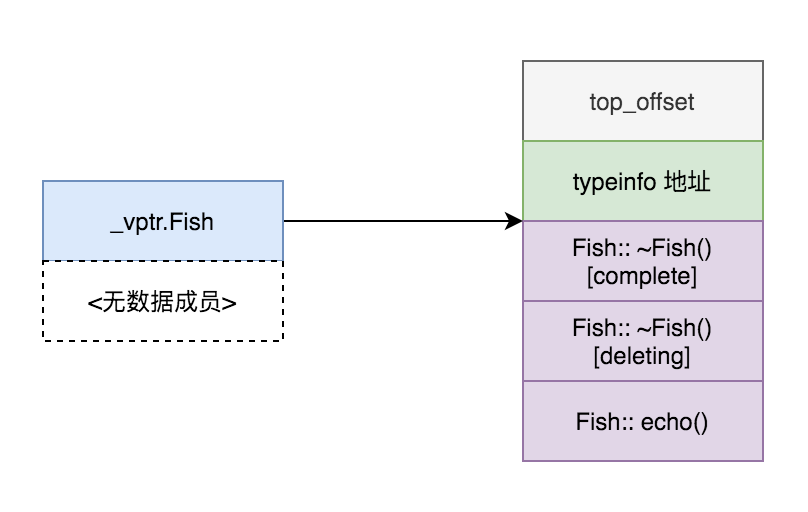
虚表指针并非指向虚表的表头,而是指向表头+16的位置。表头的前两个槽位(各占8个字节)。
虚表指针指向位置,后面有三个虚函数的函数地址。
虚析构函数有两个,一个compete destructor,另一个是deleting destructor。个中差异超出本文讨论范围,不再展开啦。
typeinfo与多重继承
再定义一个美女类:Beauty。
class Beauty {
public:
virtual ~Beauty(){};
virtual void echo() {cout<<"I'm a beauty"<<endl;};
};
再派生一个美人鱼的类:
class FishBeauty: public Beauty, public Fish {
public:
virtual ~FishBeauty(){};
virtual void echo() {cout<<"I'm a fish-beauty"<<endl;};
};
父类指针只可以指向子类对象,子类指针也可以向上转型成父类指针。在多重继承的时候,可以向上转型成多个父类。继续看个例子:
int main() {
FishBeauty fb;
Beauty b;
Fish f;
}
我们可以用gdb调试来探究:

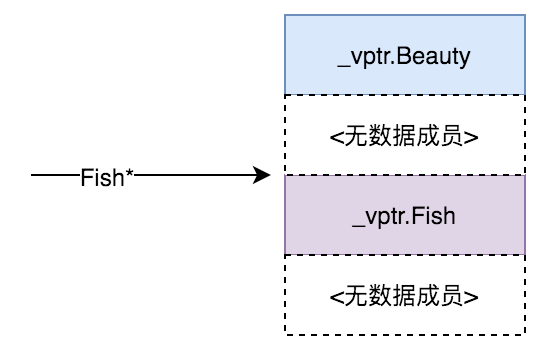
这说明FishBeauty对象的内存布局其实是这样的:
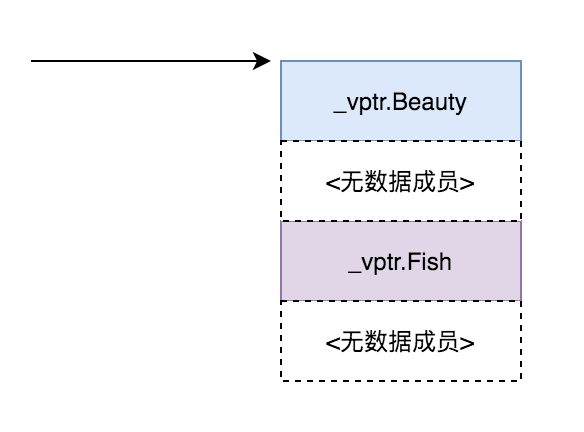
而当继承时Fish在前,Beauty在后时,这个图上下槽位的内容就要调换,也就是鱼美人和美人鱼之别……

可以看出子类有名为vptr.Beauty和vptr.Fish的指针,但是和Beauty与Fish类指向的虚表指针还是有不同的!
fb的vptr.Beauty倒退16字节查看一下虚表内容:

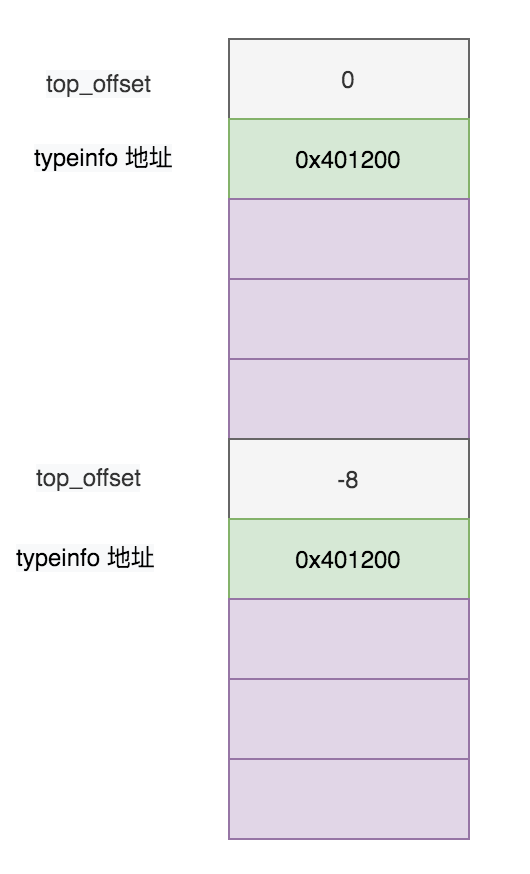 虚表结构
虚表结构
对于FishBeauty,不管转成Fish指针还是还是Beauty指针,倒退8个字节的位置都是typeinfo的地址,他们指向相同位置:0x401200。
使用相同的方法查看Beauty和Fish类,其虚表的第二个槽位的typeinfo地址分别为:0x401240和0x401260。
其实到这里题主的问题已经可以回答了。在虚表的第二个槽中的type_info是子类的。
感兴趣的话,我们可以再研究一下具体typeinfo是什么个结构:
继续用x命令查看内存内容可以画出这样的图(可以从标蓝的0x401200看起):
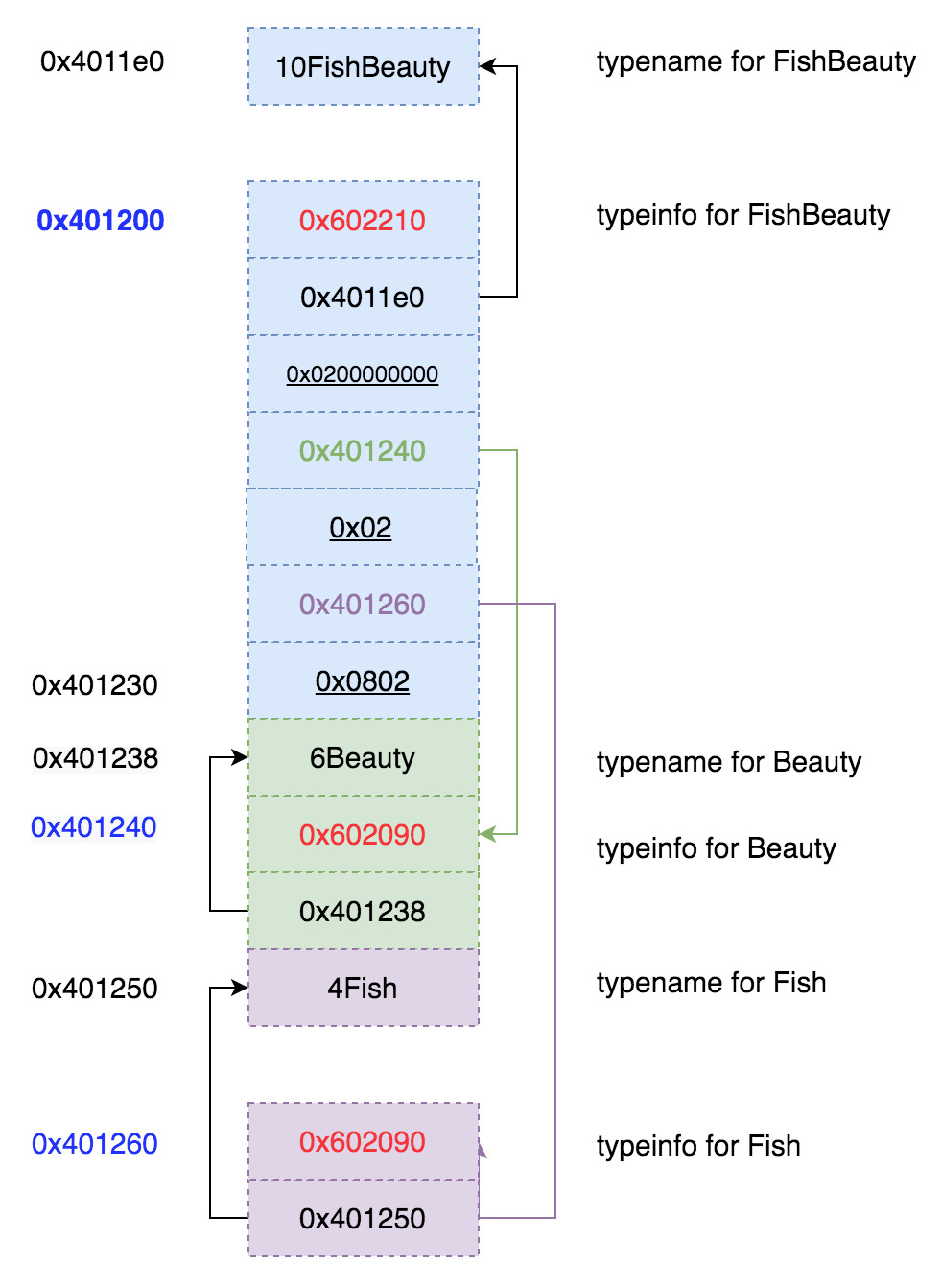 typeinfo表结构
typeinfo表结构
typeinfo也是一个表结构,第一个槽位(标红的地址)指向的是相关汇编指令。可以用disas /m 来查看内容。第二个槽位指向的是typename字符串的地址。并且子类的typeinfo中有槽位分别指向各个父类的typeinfo地址。
当然也有一些未解之谜,比如图中下划线的几个magic number我也不得其解。不过也不想再继续探究下去了。已经太细枝末节了。
top_offset 与多重继承
既然第二个槽位是type_info的地址,那么第一个槽位是什么呢?其实我前面的虚表结构图已经剧透了:虚表第一个槽中存放的top offset。这个又是什看代码:
void fish_echo(Fish* fish) {
cout<<fish<<endl;
fish->echo();
}
void beauty_echo(Beauty* beauty) {
cout<<beauty<<endl;
beauty->echo();
}
int main() {
FishBeauty fb;
Beauty b;
Fish f;
cout<<&fb<<endl;
fish_echo(&fb);
beauty_echo(&fb);
}
输出结果:
0x7ffd7239fc80
0x7ffd7239fc88
I'm a fish-beauty
0x7ffd7239fc80
I'm a fish-beauty
fish_echo和beauty_echo 会将子类FishBeauty的指针分别转型成Fish指针和Beauty指针。
并且转型成Beauty指针的时候,指针指向的地址和子类相同(0x7ffd7239fc80)。而转成Fish指针的时候,地址向后偏移了8个字节(0x7ffd7239fc88)。这主要是和继承时,两个父类的顺序有关。
尽管Fish指针,对象地址已经变化(指向了一个父类布局的内存空间)。但是执行虚函数的调用的时候依旧不会有问题(会调用子类的对应函数)。这就是top_offset的作用。它在调用虚函数之前对this指针进行了调整。伪码:
p = this + top_offset // p = this - 8
call echo(p)这个技巧就是所谓的『thunk』。
2.文章内容简介
这篇文章主要来讨论C++对象在内存中的布局,属于第二个概念的研究范畴。而C++直接支持面向对象程序设计部分则不多讲。文章主要内容如下:
- 虚函数表解析。含有虚函数或其父类含有虚函数的类,编译器都会为其添加一个虚函数表,vptr,先了解虚函数表的构成,有助对C++对象模型的理解。
- 虚基类表解析。虚继承产生虚基类表(vbptr),虚基类表的内容与虚函数表完全不同,我们将在讲解虚继承时介绍虚函数表。
- 对象模型概述:介绍简单对象模型、表格驱动对象模型,以及非继承情况下的C++对象模型。
- 继承下的C++对象模型。分析C++类对象在下面情形中的内存布局:
- 单继承:子类单一继承自父类,分析了子类重写父类虚函数、子类定义了新的虚函数情况下子类对象内存布局。
- 多继承:子类继承于多个父类,分析了子类重写父类虚函数、子类定义了新的虚函数情况下子类对象内存布局,同时分析了非虚继承下的菱形继承。
- 虚继承:分析了单一继承下的虚继承、多重基层下的虚继承、重复继承下的虚继承。
- 理解对象的内存布局之后,我们可以分析一些问题:
- C++封装带来的布局成本是多大?
- 由空类组成的继承层次中,每个类对象的大小是多大?
至于其他与内存有关的知识,我假设大家都有一定的了解,如内存对齐,指针操作等。本文初看可能晦涩难懂,要求读者有一定的C++基础,对概念一有一定的掌握。
3.理解虚函数表
3.1.多态与虚表
C++中虚函数的作用主要是为了实现多态机制。多态,简单来说,是指在继承层次中,父类的指针可以具有多种形态——当它指向某个子类对象时,通过它能够调用到子类的函数,而非父类的函数。
class Base { virtual void print(void); }
class Drive1 :public Base{ virtual void print(void); }
class Drive2 :public Base{ virtual void print(void); }Base * ptr1 = new Base;
Base * ptr2 = new Drive1;
Base * ptr3 = new Drive2;ptr1->print(); //调用Base::print()
prt2->print();//调用Drive1::print()
prt3->print();//调用Drive2::print()
这是一种运行期多态,即父类指针唯有在程序运行时才能知道所指的真正类型是什么。这种运行期决议,是通过虚函数表来实现的。
3.2.使用指针访问虚表
如果我们丰富我们的Base类,使其拥有多个virtual函数:
class Base
{
public:
Base(int i) :baseI(i){};
virtual void print(void){ cout << "调用了虚函数Base::print()"; }
virtual void setI(){cout<<"调用了虚函数Base::setI()";}
virtual ~Base(){}
private:
int baseI;
};
当一个类本身定义了虚函数,或其父类有虚函数时,为了支持多态机制,编译器将为该类添加一个虚函数指针(vptr)。虚函数指针一般都放在对象内存布局的第一个位置上,这是为了保证在多层继承或多重继承的情况下能以最高效率取到虚函数表。
当vprt位于对象内存最前面时,对象的地址即为虚函数指针地址。我们可以取得虚函数指针的地址:
Base b(1000);
int * vptrAdree = (int *)(&b);
cout << "虚函数指针(vprt)的地址是:\t"<<vptrAdree << endl;我们运行代码出结果:

我们强行把类对象的地址转换为 int* 类型,取得了虚函数指针的地址。虚函数指针指向虚函数表,虚函数表中存储的是一系列虚函数的地址,虚函数地址出现的顺序与类中虚函数声明的顺序一致。对虚函数指针地址值,可以得到虚函数表的地址,也即是虚函数表第一个虚函数的地址:
typedef void(*Fun)(void);
Fun vfunc = (Fun)*( (int *)*(int*)(&b));
cout << "第一个虚函数的地址是:" << (int *)*(int*)(&b) << endl;
cout << "通过地址,调用虚函数Base::print():";
vfunc();- 我们把虚表指针的值取出来: *(int*)(&b),它是一个地址,虚函数表的地址
- 把虚函数表的地址强制转换成 int* : ( int *) *( int* )( &b )
- 再把它转化成我们Fun指针类型 : (Fun )*(int *)*(int*)(&b)
这样,我们就取得了类中的第一个虚函数,我们可以通过函数指针访问它。
运行结果:
同理,第二个虚函数setI()的地址为:
(int * )(*(int*)(&b)+1)同样可以通过函数指针访问它,这里留给读者自己试验。
到目前为止,我们知道了类中虚表指针vprt的由来,知道了虚函数表中的内容,以及如何通过指针访问虚函数表。下面的文章中将常使用指针访问对象内存来验证我们的C++对象模型,以及讨论在各种继承情况下虚表指针的变化,先把这部分的内容消化完再接着看下面的内容。
4.对象模型概述
在C++中,有两种数据成员(class data members):static 和nonstatic,以及三种类成员函数(class member functions):static、nonstatic和virtual:

现在我们有一个类Base,它包含了上面这5中类型的数据或函数:
class Base
{
public:
Base(int i) :baseI(i){};
int getI(){ return baseI; }
static void countI(){};
virtual ~Base(){}
virtual void print(void){ cout << "Base::print()"; }
private:
int baseI;
static int baseS;
};
那么,这个类在内存中将被如何表示?5种数据都是连续存放的吗?如何布局才能支持C++多态? 我们的C++标准与编译器将如何塑造出各种数据成员与成员函数呢?
4.1.简单对象模型
说明:在下面出现的图中,用蓝色边框框起来的内容在内存上是连续的。
这个模型非常地简单粗暴。在该模型下,对象由一系列的指针组成,每一个指针都指向一个数据成员或成员函数,也即是说,每个数据成员和成员函数在类中所占的大小是相同的,都为一个指针的大小。这样有个好处——很容易算出对象的大小,不过赔上的是空间和执行期效率。想象一下,如果我们的Point3d类是这种模型,将会比C语言的struct多了许多空间来存放指向函数的指针,而且每次读取类的数据成员,都需要通过再一次寻址——又是时间上的消耗。
所以这种对象模型并没有被用于实际产品上。

4.2.表格驱动模型
这个模型在简单对象模型的基础上又添加一个间接层,它把类中的数据分成了两个部分:数据部分与函数部分,并使用两张表格,一张存放数据本身,一张存放函数的地址(也即函数比成员多一次寻址),而类对象仅仅含有两个指针,分别指向上面这两个表。这样看来,对象的大小是固定为两个指针大小。这个模型也没有用于实际应用于真正的C++编译器上。
4.3.非继承下的C++对象模型
概述:在此模型下,nonstatic 数据成员被置于每一个类对象中,而static数据成员被置于类对象之外。static与nonstatic函数也都放在类对象之外,而对于virtual 函数,则通过虚函数表+虚指针来支持,具体如下:
- 每个类生成一个表格,称为虚表(virtual table,简称vtbl)。虚表中存放着一堆指针,这些指针指向该类每一个虚函数。虚表中的函数地址将按声明时的顺序排列,不过当子类有多个重载函数时例外,后面会讨论。
- 每个类对象都拥有一个虚表指针(vptr),由编译器为其生成。虚表指针的设定与重置皆由类的复制控制(也即是构造函数、析构函数、赋值操作符)来完成。vptr的位置为编译器决定,传统上它被放在所有显示声明的成员之后,不过现在许多编译器把vptr放在一个类对象的最前端。关于数据成员布局的内容,在后面会详细分析。
另外,虚函数表的前面设置了一个指向type_info的指针,用以支持RTTI(Run Time Type Identification,运行时类型识别)。RTTI是为多态而生成的信息,包括对象继承关系,对象本身的描述等,只有具有虚函数的对象在会生成。
在此模型下,Base的对象模型如图:
先在VS上验证类对象的布局:
Base b(1000);
可见对象b含有一个vfptr,即vprt。并且只有nonstatic数据成员被放置于对象内。我们展开vfprt:

vfptr中有两个指针类型的数据(地址),第一个指向了Base类的析构函数,第二个指向了Base的虚函数print,顺序与声明顺序相同。
这与上述的C++对象模型相符合。也可以通过代码来进行验证:
void testBase( Base&p)
{
cout << "对象的内存起始地址:" << &p << endl;
cout << "type_info信息:" << endl;
RTTICompleteObjectLocator str = *((RTTICompleteObjectLocator*)*((int*)*(int*)(&p) - 1));
string classname(str.pTypeDescriptor->name);
classname = classname.substr(4, classname.find("@@") - 4);
cout << "根据type_info信息输出类名:"<< classname << endl;
cout << "虚函数表地址:" << (int *)(&p) << endl;
//验证虚表
cout << "虚函数表第一个函数的地址:" << (int *)*((int*)(&p)) << endl;
cout << "析构函数的地址:" << (int* )*(int *)*((int*)(&p)) << endl;
cout << "虚函数表中,第二个虚函数即print()的地址:" << ((int*)*(int*)(&p) + 1) << endl;
//通过地址调用虚函数print()
typedef void(*Fun)(void);
Fun IsPrint=(Fun)* ((int*)*(int*)(&p) + 1);
cout << endl;
cout<<"调用了虚函数";
IsPrint(); //若地址正确,则调用了Base类的虚函数print()
cout << endl;
//输入static函数的地址
p.countI();//先调用函数以产生一个实例
cout << "static函数countI()的地址:" << p.countI << endl;
//验证nonstatic数据成员
cout << "推测nonstatic数据成员baseI的地址:" << (int *)(&p) + 1 << endl;
cout << "根据推测出的地址,输出该地址的值:" << *((int *)(&p) + 1) << endl;
cout << "Base::getI():" << p.getI() << endl;
}Base b(1000);
testBase(b);
结果分析:
- 通过 (int *)(&p)取得虚函数表的地址
- type_info信息的确存在于虚表的前一个位置。通过((int)(int*)(&p) - 1))取得type_infn信息,并成功获得类的名称的Base
- 虚函数表的第一个函数是析构函数。
- 虚函数表的第二个函数是虚函数print(),取得地址后通过地址调用它(而非通过对象),验证正确
- 虚表指针的下一个位置为nonstatic数据成员baseI。
- 可以看到,static成员函数的地址段位与虚表指针、baseI的地址段位不同。
好的,至此我们了解了非继承下类对象五种数据在内存上的布局,也知道了在每一个虚函数表前都有一个指针指向type_info,负责对RTTI的支持。而加入继承后类对象在内存中该如何表示呢?
5.继承下的C++对象模型
5.1.单继承
如果我们定义了派生类
class Derive : public Base
{
public:
Derive(int d) :Base(1000), DeriveI(d){};
//overwrite父类虚函数
virtual void print(void){ cout << "Drive::Drive_print()" ; }
// Derive声明的新的虚函数
virtual void Drive_print(){ cout << "Drive::Drive_print()" ; }
virtual ~Derive(){}
private:
int DeriveI;
};继承类图为:
一个派生类如何在机器层面上塑造其父类的实例呢?在简单对象模型中,可以在子类对象中为每个基类子对象分配一个指针。如下图:
简单对象模型的缺点就是因间接性导致的空间存取时间上的额外负担,优点则是类的大小是固定的,基类的改动不会影响子类对象的大小。
在表格驱动对象模型中,我们可以为子类对象增加第三个指针:基类指针(bptr),基类指针指向指向一个基类表(base class table),同样的,由于间接性导致了空间和存取时间上的额外负担,优点则是无须改变子类对象本身就可以更改基类。表格驱动模型的图就不再贴出来了。
在C++对象模型中,对于一般继承(这个一般是相对于虚拟继承而言),若子类重写(overwrite)了父类的虚函数,则子类虚函数将覆盖虚表中对应的父类虚函数(注意子类与父类拥有各自的一个虚函数表);若子类并无overwrite父类虚函数,而是声明了自己新的虚函数,则该虚函数地址将扩充到虚函数表最后(在vs中无法通过监视看到扩充的结果,不过我们通过取地址的方法可以做到,子类新的虚函数确实在父类子物体的虚函数表末端)。而对于虚继承,若子类overwrite父类虚函数,同样地将覆盖父类子物体中的虚函数表对应位置,而若子类声明了自己新的虚函数,则编译器将为子类增加一个新的虚表指针vptr,这与一般继承不同,在后面再讨论。

我们使用代码来验证以上模型
typedef void(*Fun)(void);
int main()
{
Derive d(2000);
//[0]
cout << "[0]Base::vptr";
cout << "\t地址:" << (int *)(&d) << endl;
//vprt[0]
cout << " [0]";
Fun fun1 = (Fun)*((int *)*((int *)(&d)));
fun1();
cout << "\t地址:\t" << *((int *)*((int *)(&d))) << endl;
//vprt[1]析构函数无法通过地址调用,故手动输出
cout << " [1]" << "Derive::~Derive" << endl;
//vprt[2]
cout << " [2]";
Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2);
fun2();
cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl;
//[1]
cout << "[2]Base::baseI=" << *(int*)((int *)(&d) + 1);
cout << "\t地址:" << (int *)(&d) + 1;
cout << endl;
//[2]
cout << "[2]Derive::DeriveI=" << *(int*)((int *)(&d) + 2);
cout << "\t地址:" << (int *)(&d) + 2;
cout << endl;
getchar();
}运行结果:
这个结果与我们的对象模型符合。
5.2.多继承
5.2.1一般的多重继承(非菱形继承)
单继承中(一般继承),子类会扩展父类的虚函数表。在多继承中,子类含有多个父类的子对象,该往哪个父类的虚函数表扩展呢?当子类overwrite了父类的函数,需要覆盖多个父类的虚函数表吗?
- 子类的虚函数被放在声明的第一个基类的虚函数表中。
- overwrite时,所有基类的print()函数都被子类的print()函数覆盖。
- 内存布局中,父类按照其声明顺序排列。
其中第二点保证了父类指针指向子类对象时,总是能够调用到真正的函数。
为了方便查看,我们把代码都粘贴过来
class Base
{
public:
Base(int i) :baseI(i){};
virtual ~Base(){}
int getI(){ return baseI; }
static void countI(){};
virtual void print(void){ cout << "Base::print()"; }
private:
int baseI;
static int baseS;
};
class Base_2
{
public:
Base_2(int i) :base2I(i){};
virtual ~Base_2(){}
int getI(){ return base2I; }
static void countI(){};
virtual void print(void){ cout << "Base_2::print()"; }
private:
int base2I;
static int base2S;
};
class Drive_multyBase :public Base, public Base_2
{
public:
Drive_multyBase(int d) :Base(1000), Base_2(2000) ,Drive_multyBaseI(d){};
virtual void print(void){ cout << "Drive_multyBase::print" ; }
virtual void Drive_print(){ cout << "Drive_multyBase::Drive_print" ; }
private:
int Drive_multyBaseI;
};继承类图为:

此时Drive_multyBase 的对象模型是这样的:

我们使用代码验证:
typedef void(*Fun)(void);
int main()
{
Drive_multyBase d(3000);
//[0]
cout << "[0]Base::vptr";
cout << "\t地址:" << (int *)(&d) << endl;
//vprt[0]析构函数无法通过地址调用,故手动输出
cout << " [0]" << "Derive::~Derive" << endl;
//vprt[1]
cout << " [1]";
Fun fun1 = (Fun)*((int *)*((int *)(&d))+1);
fun1();
cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl;
//vprt[2]
cout << " [2]";
Fun fun2 = (Fun)*((int *)*((int *)(&d)) + 2);
fun2();
cout << "\t地址:\t" << *((int *)*((int *)(&d)) + 2) << endl;
//[1]
cout << "[1]Base::baseI=" << *(int*)((int *)(&d) + 1);
cout << "\t地址:" << (int *)(&d) + 1;
cout << endl;
//[2]
cout << "[2]Base_::vptr";
cout << "\t地址:" << (int *)(&d)+2 << endl;
//vprt[0]析构函数无法通过地址调用,故手动输出
cout << " [0]" << "Drive_multyBase::~Derive" << endl;
//vprt[1]
cout << " [1]";
Fun fun4 = (Fun)*((int *)*((int *)(&d))+1);
fun4();
cout << "\t地址:\t" << *((int *)*((int *)(&d))+1) << endl;
//[3]
cout << "[3]Base_2::base2I=" << *(int*)((int *)(&d) + 3);
cout << "\t地址:" << (int *)(&d) + 3;
cout << endl;
//[4]
cout << "[4]Drive_multyBase::Drive_multyBaseI=" << *(int*)((int *)(&d) + 4);
cout << "\t地址:" << (int *)(&d) + 4;
cout << endl;
getchar();
}运行结果:
5.2.2 菱形继承
菱形继承也称为钻石型继承或重复继承,它指的是基类被某个派生类简单重复继承了多次。这样,派生类对象中拥有多份基类实例(这会带来一些问题)。为了方便叙述,我们不使用上面的代码了,而重新写一个重复继承的继承层次:

class B
{
public:
int ib;
public:
B(int i=1) :ib(i){}
virtual void f() { cout << "B::f()" << endl; }
virtual void Bf() { cout << "B::Bf()" << endl; }
};
class B1 : public B
{
public:
int ib1;
public:
B1(int i = 100 ) :ib1(i) {}
virtual void f() { cout << "B1::f()" << endl; }
virtual void f1() { cout << "B1::f1()" << endl; }
virtual void Bf1() { cout << "B1::Bf1()" << endl; }
};
class B2 : public B
{
public:
int ib2;
public:
B2(int i = 1000) :ib2(i) {}
virtual void f() { cout << "B2::f()" << endl; }
virtual void f2() { cout << "B2::f2()" << endl; }
virtual void Bf2() { cout << "B2::Bf2()" << endl; }
};
class D : public B1, public B2
{
public:
int id;
public:
D(int i= 10000) :id(i){}
virtual void f() { cout << "D::f()" << endl; }
virtual void f1() { cout << "D::f1()" << endl; }
virtual void f2() { cout << "D::f2()" << endl; }
virtual void Df() { cout << "D::Df()" << endl; }
};这时,根据单继承,我们可以分析出B1,B2类继承于B类时的内存布局。又根据一般多继承,我们可以分析出D类的内存布局。我们可以得出D类子对象的内存布局如下图:
D类对象内存布局中,图中青色表示b1类子对象实例,黄色表示b2类子对象实例,灰色表示D类子对象实例。从图中可以看到,由于D类间接继承了B类两次,导致D类对象中含有两个B类的数据成员ib,一个属于来源B1类,一个来源B2类。这样不仅增大了空间,更重要的是引起了程序歧义:
D d;
d.ib =1 ; //二义性错误,调用的是B1的ib还是B2的ib?
d.B1::ib = 1; //正确
d.B2::ib = 1; //正确尽管我们可以通过明确指明调用路径以消除二义性,但二义性的潜在性还没有消除,我们可以通过虚继承来使D类只拥有一个ib实体。
6.虚继承
虚继承解决了菱形继承中最派生类拥有多个间接父类实例的情况。虚继承的派生类的内存布局与普通继承很多不同,主要体现在:
- 虚继承的子类,如果本身定义了新的虚函数,则编译器为其生成一个虚函数指针(vptr)以及一张虚函数表。该vptr位于对象内存最前面。
- vs非虚继承:直接扩展父类虚函数表。
- 虚继承的子类也单独保留了父类的vprt与虚函数表。这部分内容接与子类内容以一个四字节的0来分界。
- 虚继承的子类对象中,含有四字节的虚表指针偏移值。
为了分析最后的菱形继承,我们还是先从单虚继承继承开始。
6.1.虚基类表解析
在C++对象模型中,虚继承而来的子类会生成一个隐藏的虚基类指针(vbptr),在Microsoft Visual C++中,虚基类表指针总是在虚函数表指针之后,因而,对某个类实例来说,如果它有虚基类指针,那么虚基类指针可能在实例的0字节偏移处(该类没有vptr时,vbptr就处于类实例内存布局的最前面,否则vptr处于类实例内存布局的最前面),也可能在类实例的4字节偏移处。
一个类的虚基类指针指向的虚基类表,与虚函数表一样,虚基类表也由多个条目组成,条目中存放的是偏移值。第一个条目存放虚基类表指针(vbptr)所在地址到该类内存首地址的偏移值,由第一段的分析我们知道,这个偏移值为0(类没有vptr)或者-4(类有虚函数,此时有vptr)。我们通过一张图来更好地理解。

虚基类表的第二、第三...个条目依次为该类的最左虚继承父类、次左虚继承父类...的内存地址相对于虚基类表指针的偏移值,这点我们在下面会验证。
6.2.简单虚继承
如果我们的B1类虚继承于B类:
//类的内容与前面相同
class B{...}
class B1 : virtual public B
根据我们前面对虚继承的派生类的内存布局的分析,B1类的对象模型应该是这样的:
我们通过指针访问B1类对象的内存,以验证上面的C++对象模型:
int main()
{
B1 a;
cout <<"B1对象内存大小为:"<< sizeof(a) << endl;
//取得B1的虚函数表
cout << "[0]B1::vptr";
cout << "\t地址:" << (int *)(&a)<< endl;
//输出虚表B1::vptr中的函数
for (int i = 0; i<2;++ i)
{
cout << " [" << i << "]";
Fun fun1 = (Fun)*((int *)*(int *)(&a) + i);
fun1();
cout << "\t地址:\t" << *((int *)*(int *)(&a) + i) << endl;
}
//[1]
cout << "[1]vbptr " ;
cout<<"\t地址:" << (int *)(&a) + 1<<endl; //虚表指针的地址
//输出虚基类指针条目所指的内容
for (int i = 0; i < 2; i++)
{
cout << " [" << i << "]";
cout << *(int *)((int *)*((int *)(&a) + 1) + i);
cout << endl;
}
//[2]
cout << "[2]B1::ib1=" << *(int*)((int *)(&a) + 2);
cout << "\t地址:" << (int *)(&a) + 2;
cout << endl;
//[3]
cout << "[3]值=" << *(int*)((int *)(&a) + 3);
cout << "\t\t地址:" << (int *)(&a) + 3;
cout << endl;
//[4]
cout << "[4]B::vptr";
cout << "\t地址:" << (int *)(&a) +3<< endl;
//输出B::vptr中的虚函数
for (int i = 0; i<2; ++i)
{
cout << " [" << i << "]";
Fun fun1 = (Fun)*((int *)*((int *)(&a) + 4) + i);
fun1();
cout << "\t地址:\t" << *((int *)*((int *)(&a) + 4) + i) << endl;
}
//[5]
cout << "[5]B::ib=" << *(int*)((int *)(&a) + 5);
cout << "\t地址: " << (int *)(&a) + 5;
cout << endl;运行结果:

这个结果与我们的C++对象模型图完全符合。这时我们可以来分析一下虚表指针的第二个条目值12的具体来源了,回忆上文讲到的:
第二、第三...个条目依次为该类的最左虚继承父类、次左虚继承父类...的内存地址相对于虚基类表指针的偏移值。
在我们的例子中,也就是B类实例内存地址相对于vbptr的偏移值,也即是:[4]-[1]的偏移值,结果即为12,从地址上也可以计算出来:007CFDFC-007CFDF4结果的十进制数正是12。现在,我们对虚基类表的构成应该有了一个更好的理解。
6.3.虚拟菱形继承
如果我们有如下继承层次:
class B{...}
class B1: virtual public B{...}
class B2: virtual public B{...}
class D : public B1,public B2{...}类图如下所示:
菱形虚拟继承下,最派生类D类的对象模型又有不同的构成了。在D类对象的内存构成上,有以下几点:
- 在D类对象内存中,基类出现的顺序是:先是B1(最左父类),然后是B2(次左父类),最后是B(虚祖父类)
- D类对象的数据成员id放在B类前面,两部分数据依旧以0来分隔。
- 编译器没有为D类生成一个它自己的vptr,而是覆盖并扩展了最左父类的虚基类表,与简单继承的对象模型相同。
- 超类B的内容放到了D类对象内存布局的最后。
菱形虚拟继承下的C++对象模型为:

下面使用代码加以验证:
int main()
{
D d;
cout << "D对象内存大小为:" << sizeof(d) << endl;
//取得B1的虚函数表
cout << "[0]B1::vptr";
cout << "\t地址:" << (int *)(&d) << endl;
//输出虚表B1::vptr中的函数
for (int i = 0; i<3; ++i)
{
cout << " [" << i << "]";
Fun fun1 = (Fun)*((int *)*(int *)(&d) + i);
fun1();
cout << "\t地址:\t" << *((int *)*(int *)(&d) + i) << endl;
}
//[1]
cout << "[1]B1::vbptr ";
cout << "\t地址:" << (int *)(&d) + 1 << endl; //虚表指针的地址
//输出虚基类指针条目所指的内容
for (int i = 0; i < 2; i++)
{
cout << " [" << i << "]";
cout << *(int *)((int *)*((int *)(&d) + 1) + i);
cout << endl;
}
//[2]
cout << "[2]B1::ib1=" << *(int*)((int *)(&d) + 2);
cout << "\t地址:" << (int *)(&d) + 2;
cout << endl;
//[3]
cout << "[3]B2::vptr";
cout << "\t地址:" << (int *)(&d) + 3 << endl;
//输出B2::vptr中的虚函数
for (int i = 0; i<2; ++i)
{
cout << " [" << i << "]";
Fun fun1 = (Fun)*((int *)*((int *)(&d) + 3) + i);
fun1();
cout << "\t地址:\t" << *((int *)*((int *)(&d) + 3) + i) << endl;
}
//[4]
cout << "[4]B2::vbptr ";
cout << "\t地址:" << (int *)(&d) + 4 << endl; //虚表指针的地址
//输出虚基类指针条目所指的内容
for (int i = 0; i < 2; i++)
{
cout << " [" << i << "]";
cout << *(int *)((int *)*((int *)(&d) + 4) + i);
cout << endl;
}
//[5]
cout << "[5]B2::ib2=" << *(int*)((int *)(&d) + 5);
cout << "\t地址: " << (int *)(&d) + 5;
cout << endl;
//[6]
cout << "[6]D::id=" << *(int*)((