

Java CMS GC
背景
Concurrent Mark Sweep,是一款基于并发、使用标记清除算法的垃圾回收算法,只针对老年代进行垃圾回收。CMS收集器工作时,GC工作线程和用户线程可以并发执行,以达到降低STW时间的目的。
开起VM选项-XX:+UseConcMarkSweepGC,表示对老年代的回收采用CMS。
前置知识
STW
首先,我们需要厘清一个概念,即只有标记阶段才需要STW。标记完成以后,需要清除的对象已经确定,无论此时是否产生新的垃圾,都不影响对这些对象的清理。也就是说,清除阶段是可以设计成和用户线程并发执行的。
JVM在暂停的时候,需要选准一个时机,由于JVM系统运行期间的复杂性,不可能做到随时暂停,因此引入了安全点(safepoint)的概念:程序只有在运行到安全点的时候,才可以暂停下来。HotSpot采用主动中断的方式,让执行线程在运行期轮询是否需要暂停的标志,若需要则中断挂起。HotSpot使用了几条短小精炼的汇编指令便可完成安全点轮询以及触发线程中断,因此对系统性能的影响几乎可以忽略不计。
可达性
可达性是指,如果一个对象会被至少一个程序中的可达对象通过直接或间接的方式引用,则称该对象是可达的。更详细地说,一个对象满足一下两个条件之一,即被判定为可达的。
1.本身是根对象。根(root)是指由堆以外空间访问的对象。JVM会将以下对象标记为根:a.虚拟机栈(栈帧中的本地变量表)中引用的对象;b.方法区中的类静态属性引用的对象;c.方法区中的常量引用的对象;d.本地方法栈中JNI的引用对象。
2.被一个可达的对象引用。
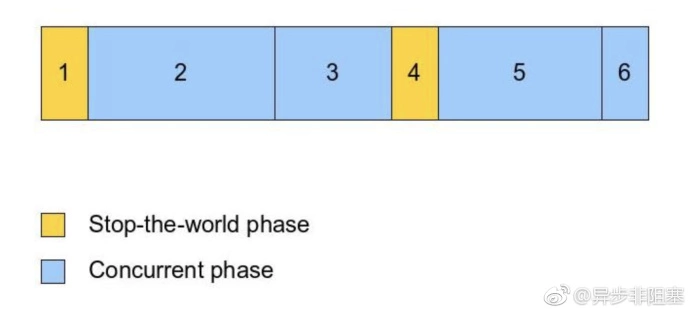
CMS的几个阶段
CMS将可达性分析分解成两个阶段:a.仅扫描与根节点直接关联的对象; b.继续向下扫描完所有对象。因此,标记阶段也被拆分成两个阶段,即初始标记和并发标记。
CMS完整的收集过程如下:
初始标记(init-mark):仅扫描与根节点直接关联的对象并标记,这个阶段必须STW, 由于跟节点数量有限,所以这个过程非常短暂。并发标记(concurrent-marking):与用户线程并发标记。这个阶段在初始标记的基础上继续向下追溯标记。在并发标记阶段,用户线程和标记线程并发执行,所以用户不会感受到停顿。并发预清理(concurrent-precleaning):与用户线程并发进行。在并发标记阶段一些对象的引用已经发生了变化,precleaning会发现这些引用关系的改变,并将存活的对象标记。举个例子:如果线程A有一个指向对象X的引用,并将该引用传递给了线程B,CMS需要记录下线程B持有了对象X,即使线程A已经不存在了。precleaning是为了减少下一阶段“重新标记”的工作量,因为remark阶段会STW。重新标记(remark):remark阶段会STW。如果应用正在并发运行且在不断地改变对象引用,CMS则不能准确地确定某个对象是否存活。所以CMS会在remark阶段STW,从而获取所有引用关系的改变。并发清理(concurrent-sweeping):清理垃圾对象,这个阶段GC线程和用户线程并发执行。并发重置(concurrent-reset):重置CMS收集器的数据结构,做好下一次执行GC任务的准备工作。
CMS 收集器
CMS 收集器是老年代经常使用的收集器,它采用的是标记-清楚算法,应用程序在发生一次 Full GC 时,典型的 GC 日志信息如下:
1
|
2018-04-12T13:48:26.233+0800: 15578.148: [GC [1 CMS-initial-mark: 6294851K(20971520K)] 6354687K(24746432K), 0.0466580 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
|
CMS Full GC 拆分开来,涉及的阶段比较多,下面分别来介绍各个阶段的情况。
阶段1:Initial Mark
这个是 CMS 两次 stop-the-wolrd 事件的其中一次,这个阶段的目标是:标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象,标记后示例如下所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC):
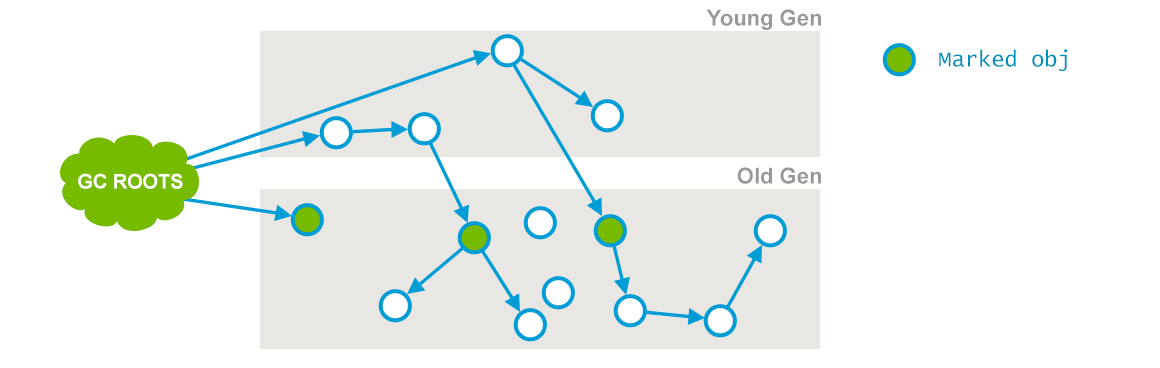 CMS 初始标记阶段
CMS 初始标记阶段
上述例子对应的日志信息为:
1
|
2018-04-12T13:48:26.233+0800: 15578.148: [GC [1 CMS-initial-mark: 6294851K(20971520K)] 6354687K(24746432K), 0.0466580 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
|
逐行介绍上面日志的含义:
2018-04-12T13:48:26.233+0800: 15578.148:GC 开始的时间,以及相对于 JVM 启动的相对时间(单位是秒,这里大概是4.33h),与前面 ParNew 类似,下面的分析中就直接跳过这个了;CMS-initial-mark:初始标记阶段,它会收集所有 GC Roots 以及其直接引用的对象;6294851K:当前老年代使用的容量,这里是 6G;(20971520K):老年代可用的最大容量,这里是 20G;6354687K:整个堆目前使用的容量,这里是 6.06G;(24746432K):堆可用的容量,这里是 23.6G;0.0466580 secs:这个阶段的持续时间;[Times: user=0.04 sys=0.00, real=0.04 secs]:与前面的类似,这里是相应 user、system and real 的时间统计。
阶段2:并发标记
在这个阶段 Garbage Collector 会遍历老年代,然后标记所有存活的对象,它会根据上个阶段找到的 GC Roots 遍历查找。并发标记阶段,它会与用户的应用程序并发运行。并不是老年代所有的存活对象都会被标记,因为在标记期间用户的程序可能会改变一些引用,如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC):
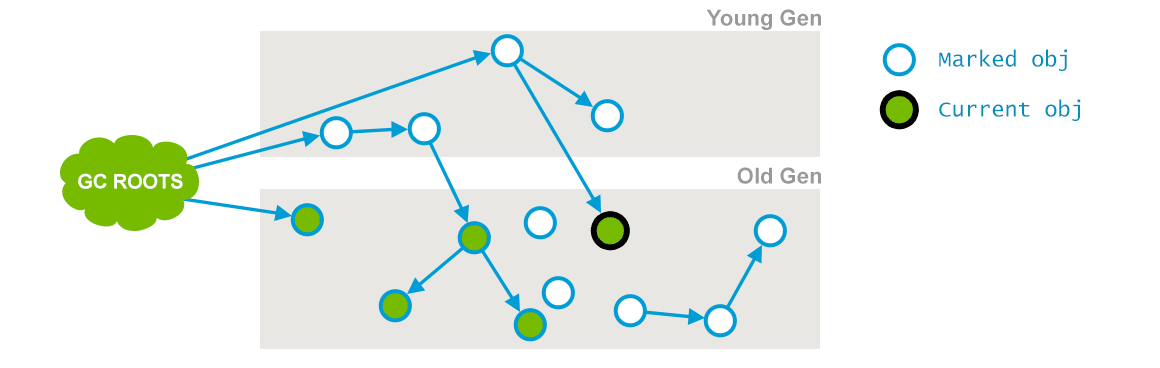 CMS 并发标记阶段
CMS 并发标记阶段
在上面的图中,与阶段1的图进行对比,就会发现有一个对象的引用已经发生了变化,这个阶段相应的日志信息如下:
1
|
2018-04-12T13:48:26.280+0800: 15578.195: [CMS-concurrent-mark-start]
|
这里详细对上面的日志解释,如下所示:
CMS-concurrent-mark:并发收集阶段,这个阶段会遍历老年代,并标记所有存活的对象;0.138/0.138 secs:这个阶段的持续时间与时钟时间;[Times: user=1.01 sys=0.21, real=0.14 secs]:如前面所示,但是这部的时间,其实意义不大,因为它是从并发标记的开始时间开始计算,这期间因为是并发进行,不仅仅包含 GC 线程的工作。
阶段3:Concurrent Preclean
Concurrent Preclean:这也是一个并发阶段,与应用的线程并发运行,并不会 stop 应用的线程。在并发运行的过程中,一些对象的引用可能会发生变化,但是这种情况发生时,JVM 会将包含这个对象的区域(Card)标记为 Dirty,这也就是 Card Marking。如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC:
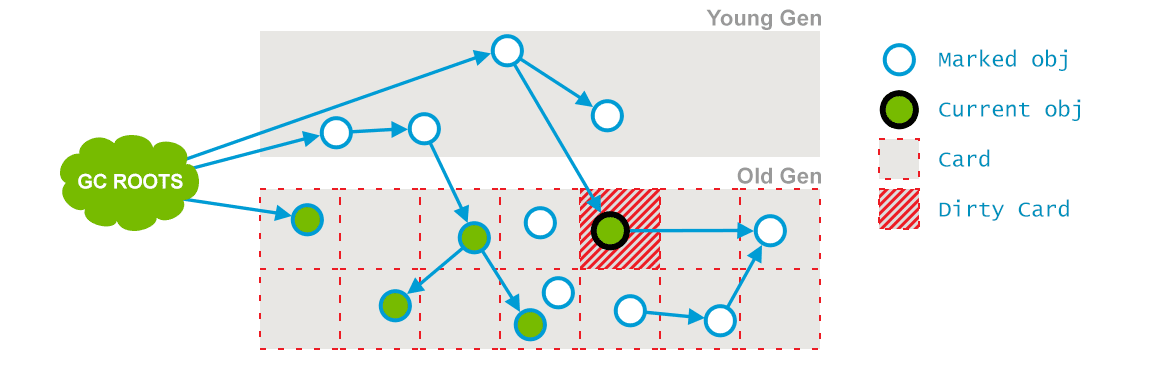 Concurrent Preclean 1
Concurrent Preclean 1
在pre-clean阶段,那些能够从 Dirty 对象到达的对象也会被标记,这个标记做完之后,dirty card 标记就会被清除了,如下(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC:
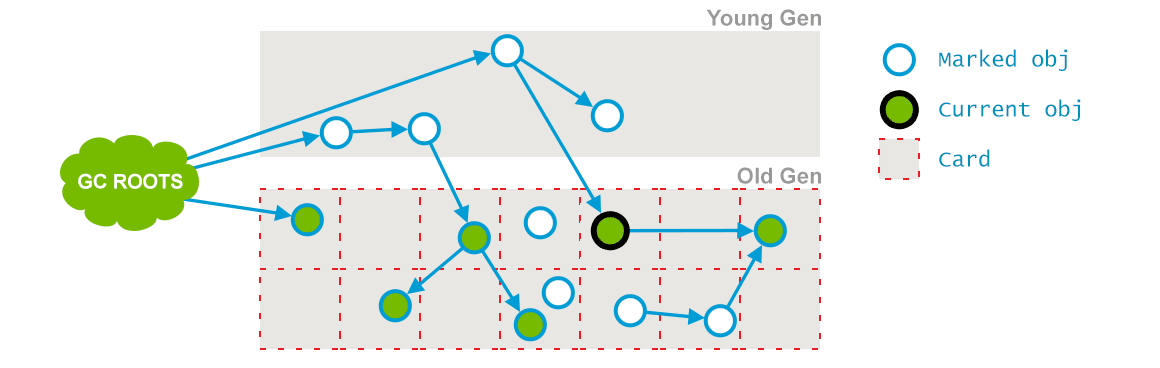 Concurrent Preclean 2
Concurrent Preclean 2
这个阶段相应的日志信息如下:
1
|
2018-04-12T13:48:26.418+0800: 15578.334: [CMS-concurrent-preclean-start]
|
其含义为:
CMS-concurrent-preclean:Concurrent Preclean 阶段,对在前面并发标记阶段中引用发生变化的对象进行标记;0.056/0.057 secs:这个阶段的持续时间与时钟时间;[Times: user=0.20 sys=0.12, real=0.06 secs]:同并发标记阶段中的含义。
阶段4:Concurrent Abortable Preclean
这也是一个并发阶段,但是同样不会影响影响用户的应用线程,这个阶段是为了尽量承担 STW(stop-the-world)中最终标记阶段的工作。这个阶段持续时间依赖于很多的因素,由于这个阶段是在重复做很多相同的工作,直接满足一些条件(比如:重复迭代的次数、完成的工作量或者时钟时间等)。这个阶段的日志信息如下:
1
|
2018-04-12T13:48:26.476+0800: 15578.391: [CMS-concurrent-abortable-preclean-start]
|
CMS-concurrent-abortable-preclean:Concurrent Abortable Preclean 阶段;3.506/3.514 secs:这个阶段的持续时间与时钟时间,本质上,这里的 gc 线程会在 STW 之前做更多的工作,通常会持续 5s 左右;[Times: user=11.93 sys=6.77, real=3.51 secs]:同前面。
阶段5:Final Remark
这是第二个 STW 阶段,也是 CMS 中的最后一个,这个阶段的目标是标记所有老年代所有的存活对象,由于之前的阶段是并发执行的,gc 线程可能跟不上应用程序的变化,为了完成标记老年代所有存活对象的目标,STW 就非常有必要了。
通常 CMS 的 Final Remark 阶段会在年轻代尽可能干净的时候运行,目的是为了减少连续 STW 发生的可能性(年轻代存活对象过多的话,也会导致老年代涉及的存活对象会很多)。这个阶段会比前面的几个阶段更复杂一些,相关日志如下:
1
|
2018-04-12T13:48:29.991+0800: 15581.906: [GC[YG occupancy: 1805641 K (3774912 K)]2018-04-12T13:48:29.991+0800: 15581.906: [GC2018-04-12T13:48:29.991+0800: 15581.906: [ParNew: 1805641K->48395K(3774912K), 0.0826620 secs] 8100493K->6348225K(24746432K), 0.0829480 secs] [Times: user=0.81 sys=0.00, real=0.09 secs]2018-04-12T13:48:30.074+0800: 15581.989: [Rescan (parallel) , 0.0429390 secs]2018-04-12T13:48:30.117+0800: 15582.032: [weak refs processing, 0.0027800 secs]2018-04-12T13:48:30.119+0800: 15582.035: [class unloading, 0.0033120 secs]2018-04-12T13:48:30.123+0800: 15582.038: [scrub symbol table, 0.0016780 secs]2018-04-12T13:48:30.124+0800: 15582.040: [scrub string table, 0.0004780 secs] [1 CMS-remark: 6299829K(20971520K)] 6348225K(24746432K), 0.1365130 secs] [Times: user=1.24 sys=0.00, real=0.14 secs]
|
对上面的日志进行分析:
YG occupancy: 1805641 K (3774912 K):年轻代当前占用量及容量,这里分别是 1.71G 和 3.6G;ParNew:...:触发了一次 young GC,这里触发的原因是为了减少年轻代的存活对象,尽量使年轻代更干净一些;[Rescan (parallel) , 0.0429390 secs]:这个 Rescan 是当应用暂停的情况下完成对所有存活对象的标记,这个阶段是并行处理的,这里花费了 0.0429390s;[weak refs processing, 0.0027800 secs]:第一个子阶段,它的工作是处理弱引用;[class unloading, 0.0033120 secs]:第二个子阶段,它的工作是:unloading the unused classes;[scrub symbol table, 0.0016780 secs] ... [scrub string table, 0.0004780 secs]:最后一个子阶段,它的目的是:cleaning up symbol and string tables which hold class-level metadata and internalized string respectively,时钟的暂停也包含在这里;6299829K(20971520K):这个阶段之后,老年代的使用量与总量,这里分别是 6G 和 20G;6348225K(24746432K):这个阶段之后,堆的使用量与总量(包括年轻代,年轻代在前面发生过 GC),这里分别是 6.05G 和 23.6G;0.1365130 secs:这个阶段的持续时间;[Times: user=1.24 sys=0.00, real=0.14 secs]:对应的时间信息。
经历过这五个阶段之后,老年代所有存活的对象都被标记过了,现在可以通过清除算法去清理那些老年代不再使用的对象。
阶段6:Concurrent Sweep
这里不需要 STW,它是与用户的应用程序并发运行,这个阶段是:清除那些不再使用的对象,回收它们的占用空间为将来使用。如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC:
):
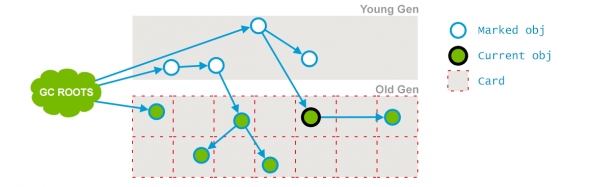 CMS Concurrent Sweep 阶段
CMS Concurrent Sweep 阶段
这个阶段对应的日志信息如下(这中间又发生了一次 Young GC):
1
|
2018-04-12T13:48:30.128+0800: 15582.043: [CMS-concurrent-sweep-start]
|
分别介绍一下:
CMS-concurrent-sweep:这个阶段主要是清除那些没有被标记的对象,回收它们的占用空间;8.193/8.284 secs:这个阶段的持续时间与时钟时间;[Times: user=30.34 sys=16.44, real=8.28 secs]:同前面;
阶段7:Concurrent Reset.
这个阶段也是并发执行的,它会重设 CMS 内部的数据结构,为下次的 GC 做准备,对应的日志信息如下:
1
|
2018-04-12T13:48:38.419+0800: 15590.334: [CMS-concurrent-reset-start]
|
日志详情分别如下:
CMS-concurrent-reset:这个阶段的开始,目的如前面所述;0.044/0.044 secs:这个阶段的持续时间与时钟时间;[Times: user=0.15 sys=0.10, real=0.04 secs]:同前面。
总结
CMS 通过将大量工作分散到并发处理阶段来在减少 STW 时间,在这块做得非常优秀,但是 CMS 也有一些其他的问题:
- CMS 收集器无法处理浮动垃圾( Floating Garbage),可能出现 “Concurrnet Mode Failure” 失败而导致另一次 Full GC 的产生,可能引发串行 Full GC;
- 空间碎片,导致无法分配大对象,CMS 收集器提供了一个
-XX:+UseCMSCompactAtFullCollection开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长; - 对于堆比较大的应用上,GC 的时间难以预估。
CMS 的一些缺陷也是 G1 收集器兴起的原因。
转自:
https://segmentfault.com/a/1190000015182001
https://matt33.com/2018/07/28/jvm-cms/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现