网络编程,进程线程和携程bulabula
1.网络编程
UDP介绍
每个Ip地址包括两部分:网络地址和主机地址
知名端口号:0 - 1023。不能随便用,有特殊用途。
1024到65535,随便用。

udp实现发送数据
import socket
def main():
# 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 发送的数据
content = input("请输入你要发送的内容:")
# 目标地址
desk_addr = ("127.0.0.1", 8080)
# 发数据
udp_socket.sendto(content.encode("utf-8"), desk_addr)
# 关闭套接字
udp_socket.close()
if __name__ == "__main__":
main()
udp实现接收数据
import socket
def main():
# 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 本地端口
local_addr = ("", 7788) # ip地址不写表示本机任意一个ip
# 绑定本地端口
udp_socket.bind(local_addr)
# 接收数据
rev_data = udp_socket.recvfrom(1024) # 1024表示本次接受的最大字节数
# 打印数据.(接受到的是一个元组)
rev_msg = rev_data[0] # 接收到的数据
send_addr = rev_data[1] # 发送方的地址
print("%s: %s" % (str(send_addr), rev_msg.decode("gbk"))) # windows的编码方式是gbk
udp_socket.close()
if __name__ == "__main__":
main()

单工:类似于收音机
半双工:类似于对讲机
全双工:类似于手机
socket属于全双工
TCP介绍
udp和tcp的区别:udp类似写信模型,每次通信都要带上ip地址和端口等。有可能丢数据,不安全。
tcp类似于打电话,建立连接过程比udp复杂,但是安全。

# tcp-client
import socket
def main():
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_ip = ""
server_port = 8080
# 连接服务器
tcp_socket.connect((server_ip, server_port))
send_data = input("请输入你要发送的数据")
# 发送数据
tcp_socket.send(send_data.encode("utf-8"))
# 接受数据
rev_data = tcp_socket.recv(1024)
print(rev_data.decode("gdb"))
tcp_socket.close()
if __name__ == "__main__":
main()

# tcp_server
import socket
def main():
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.bind("", 7788)
# 监听套接字,负责 等待有新的客户端进行连接
tcp_server.listen(128) # 让默认的套接字由主动变为被动
# client_addr为连接的客户端地址
# accept产生的新的套接字用来为客户端服务
new_client_socket, client_addr = tcp_server.accept()
# 接收数据
recv_data = new_client_socket.recv(1024)
print(recv_data)
# 发送数据
new_client_socket.send("hahaha".encode("utf-8"))
new_client_socket.close()
tcp_server.close()
if __name__ == "__main__":
main()
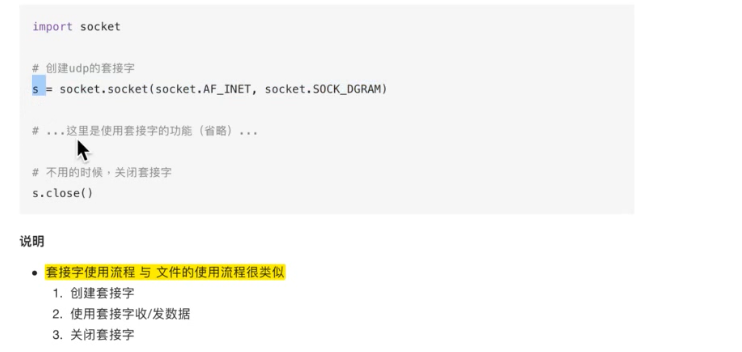
跟udp的区别就是多了监听listen,而且用accept接受连接,产生新的套接字用来为客户端服务
同时为多个客户端服务
# tcp-server
import socket
def main():
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.bind("", 7788)
# 监听套接字,负责 等待有新的客户端进行连接
tcp_server.listen(128) # 让默认的套接字由主动变为被动
# client_addr为连接的客户端地址
# accept产生的新的套接字用来为客户端服务
while True:
new_client_socket, client_addr = tcp_server.accept()
while True:
# 接收数据
recv_data = new_client_socket.recv(1024)
print(recv_data)
# 如果recv解堵塞,那么有2种方式:
# 1、客户端发送过来数据
# 2、客户端调用close()导致了这里recv解堵塞
if recv_data:
# 发送数据
new_client_socket.send("hahaha".encode("utf-8"))
else:
break
new_client_socket.close()
tcp_server.close()
if __name__ == "__main__":
main()


客户端解堵塞的情况:1、接收到数据;2、调用close()关闭连接。
可以通过数据是否为空判断是哪种类型
udp: tcp(client) tcp(server)
socket socket socket
bind conect bind
sendto/recvfrom send/recv listen
close close accept
recv/send
close
2.线程
并行:真的多任务
并发:假的多任务(任务数多于CPU内核)



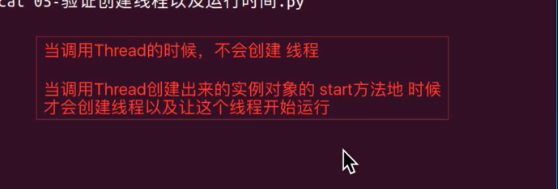
线程创建后谁先执行不确定,但可以通过延时来决定。
子线程先结束,最后才是主线程,代表整个程序结束。


当然前提是指向的数值可不可变,如果是数字、字符、元组,就要加global,如果是列表这些可变的,则视情况而定。
线程可以传参数

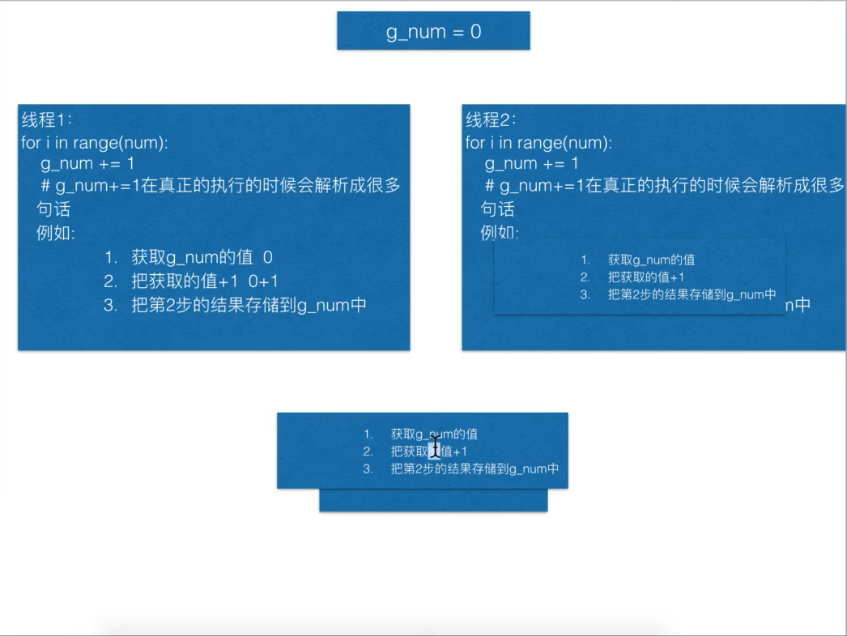
多线程容易出现资源竞争的问题




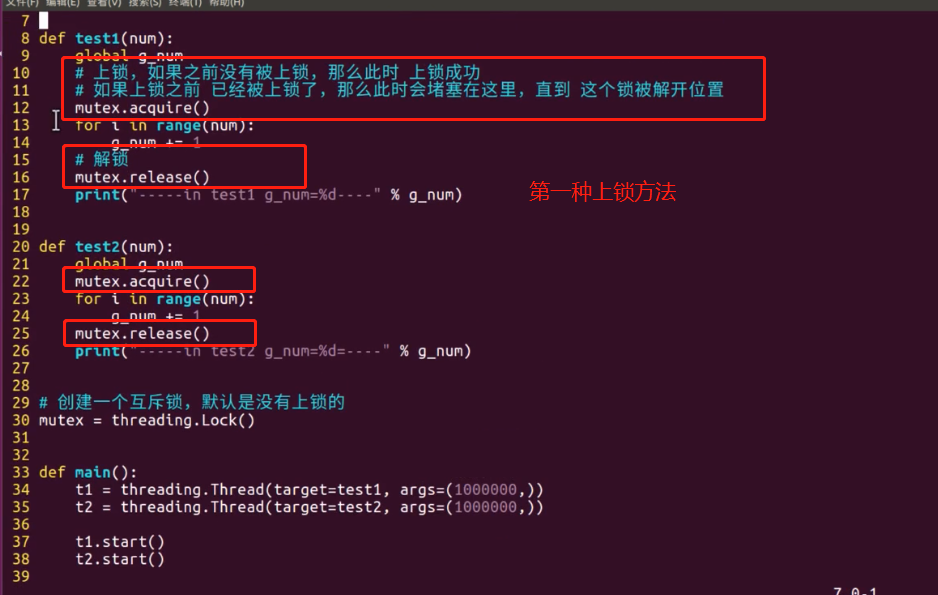
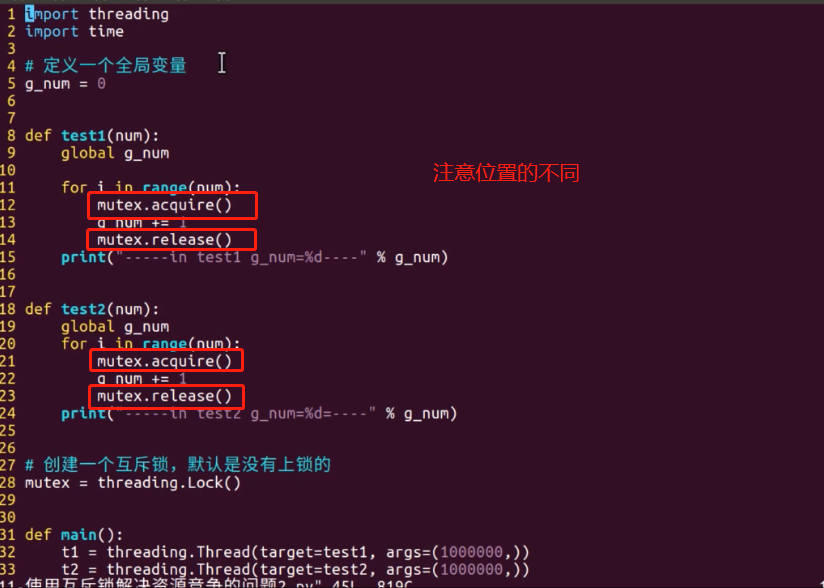
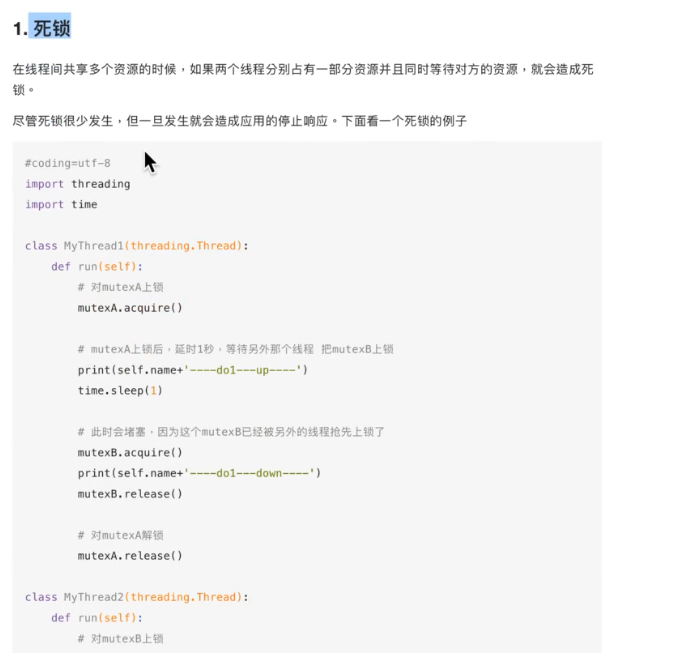

线程-----》引出:资源竞争------》解决办法:互斥锁-----》导致:死锁------》解决办法:1、银行家算法;2、设置超时时间;
3.进程
程序在没运行起来之前是死的,程序运行起来后就是进程,进程跟程序之间的区别就是进程拥有资源,例如登陆QQ之后,QQ可以调用声卡、摄像头等。


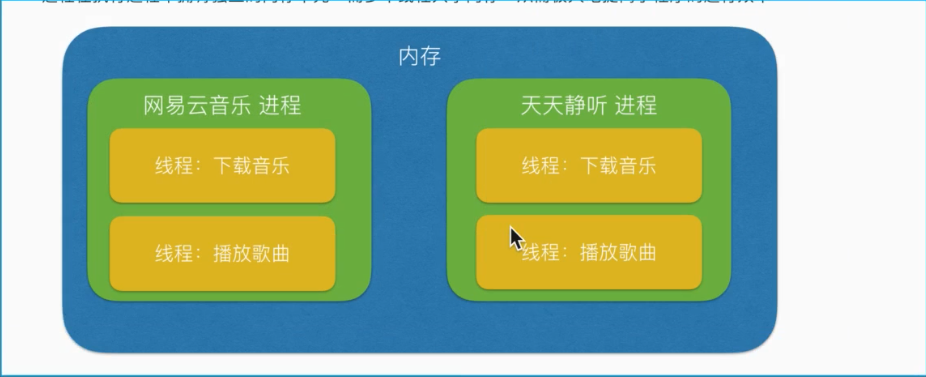
两个进程之间的通信,利用队列Queue,放到内存里,一个写,一个读。缺点就是队列只能在同一个程序或者电脑中运行,要在多台电脑之间进行,用到缓存redis。
import multiprocessing
def download_data(q):
# 下载数据
data = [11, 22, 33, 44]
for i in data:
q.put(i)
def analysis_data(q):
while True:
data = q.get()
print(data)
if q.empty():
break
def main():
q = multiprocessing.Queue(4)
p1 = multiprocessing.Process(target=download_data, args=(q, ))
p2 = multiprocessing.Process(target=analysis_data, args=(q, ))
p1.start()
p2.start()
if __name__ == "__main__":
main()
进程池
进程池里面有预先指定好的进程数,当很多任务一起过来时,如果进程被调用完,其他任务就一直等着,等待完成任务的进程来调用它们。好处就是减少了进程的创建和销毁所花的时间和资源。
4.协程
1、迭代器
在原来的基础上去得到一个新的东西,这就是迭代。
# 判断是否可迭代
>>> from collections import Iterable
>>> isinstance([11, 22, 33], Iterable)
True
from collections import Iterable
class Classmatename():
def __init__(self):
self.names = list()
def add(self, name):
self.names.append(name)
def __iter__(self):
"""如果想要一个对象称为一个 可以迭代的对象,既可以使用for,那么必须实现__iter__方法"""
pass
classmatename = Classmatename()
classmatename.add("张三")
classmatename.add("李四")
classmatename.add("王五")
print(isinstance(classmatename, Iterable)) # ------》 True
但如何循环打印列表里面的值呢?
首先先想一下当我们循环打印列表的时候发生了什么,每次循环,就会打印一个值,下一次循环打印下一个值,由此我们应该可以猜想有一个东西,在记录着我们打印到哪了,这样才可以在下一次打印接下来的值。对于我们上面创建的类,现在它已经是可以迭代了,但是还没有一个东西来记录它应该打印什么,打印到了哪里。
for item in xxx_obj:
pass
1、判断xxx_obj是否是可以迭代;
2、在第一步成立的前提下,调用iter函数,得到xxx_obj对象的__iter__方法的返回值;
3、__iter__方法的返回值是一个 迭代器
什么是迭代器?一个对象里面有“iter”方法,我们称之为 可以迭代。如果"iter"方法返回的对象里面既有“iter”又有"next"方法,那么我们称这个对象为 迭代器。
所以为了可以打印,这里需要两个条件:1、有iter值;2、iter值返回一个对象引用。这个对象里面除了iter方法外还有一个next方法。
因此大体过程就是for循环调用,首先判断这个对象是不是可迭代的(有"iter",是),接下来自动用iter方法调用"iter",获取返回的“对象引用”。接下来for循环调用这个对象里面的“next”方法,调一次,next方法返回什么,就输出什么给item打印。
from collections import Iterator
classmate_Iterator = iter(classmatename) # 用iter获取迭代器
# 判断是否是迭代器
print(isinstance(classmate_Iterator, Iterator))
import time
class Classmatename():
def __init__(self):
self.names = list()
self.current_num = 0
def add(self, name):
self.names.append(name)
def __iter__(self):
"""如果想要一个对象称为一个 可以迭代的对象,既可以使用for,那么必须实现__iter__方法"""
# 创建实例对象
return ClassIterator(self) # self指向这个类本身,然后传给类ClassIteratorclass ClassIterator():
def __init__(self, obj):
self.obj = obj # self.obj指向实例对象Classmatename
self.current_num = 0
def __iter__(self):
pass
def __next__(self):
if self.current_num < len(self.obj.names):
ret = self.obj.names[self.current_num]
self.current_num += 1 # 注意这里的self.current_num=0要放在__init__下,如果current_num=0放在__next__下,则for循环每次调用__next__时,current_num都会被重新记零
return ret
else:
raise StopIteration # 抛出异常,告诉for循环可以结束了
classmatename = Classmatename()
classmatename.add("张三")
classmatename.add("李四")
classmatename.add("王五")
for item in classmatename:
print(item)
time.sleep(1)
另一种办法,写在一起
import time
class Classmatename():
def __init__(self):
self.names = list()
self.current_num = 0
def add(self, name):
self.names.append(name)
def __iter__(self):
"""如果想要一个对象称为一个 可以迭代的对象,既可以使用for,那么必须实现__iter__方法"""
# 创建实例对象
return self # 返回自身给for循环调用里面的__next__
def __next__(self):
if self.current_num < len(self.names):
ret = self.names[self.current_num]
self.current_num += 1
return ret
else:
raise StopIteration # 抛出异常,告诉for循环可以结束了
classmatename = Classmatename()
classmatename.add("张三")
classmatename.add("李四")
classmatename.add("王五")
for item in classmatename:
print(item)
time.sleep(1)
迭代器的优点
优先我们先来了解下Python2中的range和xrange区别
>>> range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> xrange(10)
xrange(10)
由上图可知,range和xrange的区别就是range会直接返回生成的结果,而xrange返回的是生成这个结果的方式,什么时候需要调用里面的值,它才会去生成,所以xrange占用的内存空间要小很多。(这个问题在Python3已经解决了,Python3的range相当于Python2里面的xrange)
迭代器也是一样,生成的是调用值的方式,什么时候要调用值,才去生成,因此占用很少的内存空间。
# 用迭代器的方法生成斐波那契数列
class Fibonacci(object):
def __init__(self, all_num):
self.all_num = all_num
self.current_num = 0
self.a = 0
self.b = 1
def __iter__(self):
return self
def __next__(self):
if self.current_num < self.all_num:
ret = self.a
self.a, self.b = self.b, self.a+self.b
self.current_num += 1
return ret
else:
raise StopIteration
fibo = Fibonacci(10)
for num in fibo:
print(num)

a = (11, 22, 33)
list(a) # 首先生成一个空列表,然后循环调用a里面的迭代器,把值一个个放到列表中去
[11, 22, 33]
生成器(是一种特殊的迭代器)
生成生成器的第一种方式
>>> nums1 = [x*2 for x in range(10)]
>>> nums1
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> nums2 = (x*2 for x in range(10))
>>> nums2
<generator object <genexpr> at 0x00AF5180>
其中,num2就是生成器。可以通过for循环遍历里面的值。num1和num2的区别就是前面说的,num2不占用空间,值在需要时才会被生成。
生成生成器的第二种方式
# 用普通函数生成斐波那契数列
def create_num(all_num):
a, b = 0, 1
current_num = 0
while current_num < all_num:
print(a)
a, b = b, a+b
current_num += 1
create_num(10)
用生成器的方法生成斐波那契数列,添加yield
# 生成器
def create_num(all_num):
a, b = 0, 1
current_num = 0
while current_num < all_num:
yield a # 如果一个函数中有yield语句,那么这个就不再是函数,而是一个生成器的模板
a, b = b, a+b
current_num += 1
# 如果在调用create_num的时候,发现这个函数有yield,那么不在是调用函数,而是创建一个生成器对象
obj = create_num(10)for num in obj: # for循环调用过程。首先创建obj,当开始执行for循环时,程序开始向下走, print(num) # 当到达yield a的时候停止,把a的值传给num,打印出来。然后for继续调用,于是从停止的位置也就是yield那里继续向下执行,而不会从函数的开头重新运行了。
用 "ret = next(obj)" 可以一次调用一个值用来验证下。
def create_num(all_num):
a, b = 0, 1
current_num = 0
while current_num < all_num:
yield a
a, b = b, a+b
current_num += 1
return ".....ok....."
obj = create_num(10)
while True:
try:
ret = next(obj)
print(ret)
except Exception as ret:
print(ret.value) # 这个value就是return返回的值
break
第二中调用生成器的方法:send() (一般不用做第一次启动,如果非要,send()里面只能传递None)
def create_num(all_num):
a, b = 0, 1
current_num = 0
while current_num < all_num:
ret = yield a
print(">>>>>>>>ret>>>>>>>", ret)
a, b = b, a+b
current_num += 1
obj = create_num(10)
ret = next(obj)
print(ret)
ret = obj.send("hahaha") # 首先程序运行到"yield a"时停止,把“a=0”传给ret打印出来。接下来运行"send("hahaha")”,从“ret=yield a“开始,此时"yield a"并没有返回值给等号左边的ret,那么就把"hahaha"
print(ret) # 传给ret,由"print(">>>>>>>>>ret>>>>>>>>>", ret)"打印出来。再继续执行接下来的步骤。
# 结果返回
0
>>ret>>>>>>> hahaha
1
总结:迭代器特点是占用内存空间小,什么时候用,什么时候生成;
生成器有迭代器的特点,而且它最大的特点就是可以执行到一半时暂停,返回结果,然后再继续在原来基础上继续执行。
用yield实现多任务
import time
def task_1():
while True:
print("--------1---------")
time.sleep(0.1)
yield
def task_2():
while True:
print("--------2---------")
time.sleep(0.1)
yield
def main():
t1 = task_1()
t2 = task_2()
while True:
next(t1)
next(t2)
if __name__ == "__main__":
main()
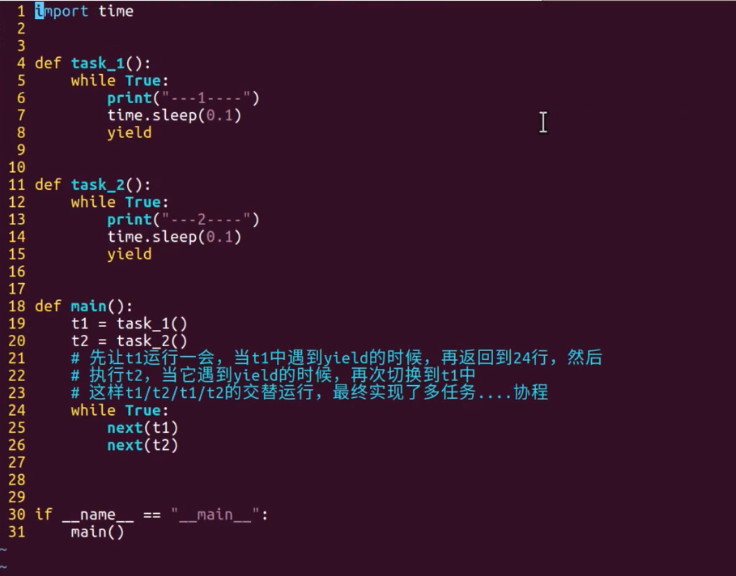

协程(单进程单线程)最大的意义,把原本等待的时间利用起来去做别的事情。
协程依赖于线程,线程依赖于进程。

有时程序写了很多行了,用的是time.sleep(),这时不想用gevent里面的gevent.sleep()方法,可以给程序打补丁

小案例,用gevent实现图片下载
import urllib.request
import gevent
from gevent import monkey
monkey.patch_all()
def download_img(file_name, url):
img = urllib.request.urlopen(url)
img_content = img.read()
with open(file_name, "wb") as f: # 这里没有用time模块是因为网络下载过程中本来就会延时,相当于我们前面实例的time.sleep()
f.write(img_content)
def main():
gevent.joinall([
gevent.spawn(download_img, "1.jpg", "https://rpic.douyucdn.cn/live-cover/appCovers/2018/08/31/3279944_20180831104533_small.jpg"),
gevent.spawn(download_img, "2.jpg", "https://rpic.douyucdn.cn/live-cover/appCovers/2018/11/14/910907_20181114154402_small.jpg")
])
if __name__ == "__main__":
main()
三者对比

5.web服务器
有个关于正则的注意点,不要随便加空格....
下面写的关于匹配邮箱的正则,原本很简单的一个题,被我在"{4,20}"之间加个空格就不行了。注意注意....
ret = re.match(r"[a-zA-Z0-9_]{4,20}@(163|qq|gmail)\.com$", 'hello@163.com').group()
分组的用法,使标签前后保持一致
>>> html_str = "<h1>hahhahaha</h1>"
>>> re.match(r"<(\w*)>.*</\1>", html_str).group()
'<h1>hahhahaha</h1>'
>>> html_str = "<h1>hahhahaha</h2>"
>>> re.match(r"<(\w*)>.*</\1>", html_str).group()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
另一种方法:起别名
>>> re.match(r"<(?P<p1>\w*)>.*</(?P=p1)>", html_str).group()
'<h1>hahhahaha</h1>'
“?”的作用是匹配0次或者1次
ret ``=` `re.match(``"[1-9]"``,``"0"``).group() ``# 报错` `ret ``=` `re.match(``"[1-9]?"``,``"0"``).group() ``#输出空字符串
提取区号和电话号码
>>> ret = re.match("([^-]*)-(\d+)","010-12345678")
>>> ret.group()
'010-12345678'
>>> ret.group(1)
'010'
>>> ret.group(2)
'12345678'
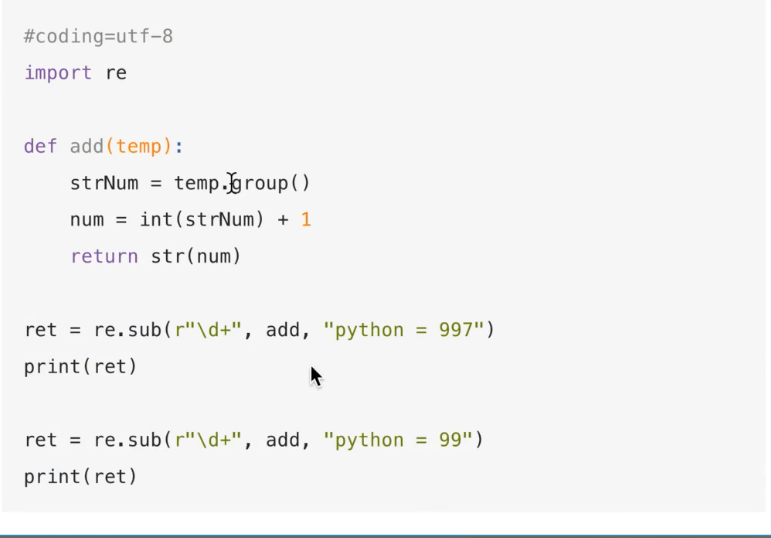
sub可以传递函数

三次握手(相当于调用connect)

四次挥手(相当于调用close())
①客户端告诉服务器不会给它发送数据了(此时全双工客户端关了一个,还剩一个用来收数据的)(关掉客户端发送)
②(1)服务器收到消息通知应用程序"recv_data = new_socke.recv()"解堵塞。(关闭服务端接收)
(2)回应客户端已收到
③(1)服务器执行new_socket.close()(关闭服务端发送)
(2)发数据包通知客户端服务端也已关闭
④(1)客户端关闭接收
(2)发消息告诉服务端已收到
为什么在四次挥手中是客户端先调用close()而不是服务端?因为谁先调用close(),谁最后就要多等两分钟(2MSL)。理由是这样的,首先客户端调用close()关闭自己的发送端,然后发消息通知服务端,服务端收到后关闭自己的接收端,返回一个收到的消息,此时客户端才真正释放"发送端口“这个资源。接下来服务端调用close()关闭自己的发送端,但是还没释放资源,它也是先发送一个通知给客户端,客户端收到后,就关闭自己的接收端,并返回一个收到的消息,此时也没有释放资源。为什么不立刻释放资源呢?是为了避免发送的包在传输过程中出现错误而不能到达对方,所以设定了超时重传,一旦超过了规定时间的话,就会重新发生数据包。所以当服务端想关闭发送端,并发送通知给客户端的时候,客户端要返回一个应答给服务端,如果这个包发送失败,服务端接收不到,超时(MSL)的话,会在重新发送一个,所以如果客户端在发送应答的数据包之后就释放资源,那么如果包发送失败了,服务端接受不到,再重新发来的包客户端就不知道,所以客户端需要先等2MSL时间,看看还有没有来自服务端的通知信息。
这也解释了前面所说的,为什么要客户端先调用close()。因为服务端是绑定端口的,客户端不绑定。谁先调用close(),谁就要多等2MSL的时间,那么如果是服务端先调用close(),会占用服务端的端口,而因为客户端端口是随机绑定的,因此即使被占用,重新连接还有别的端口。
多进程实现http服务器
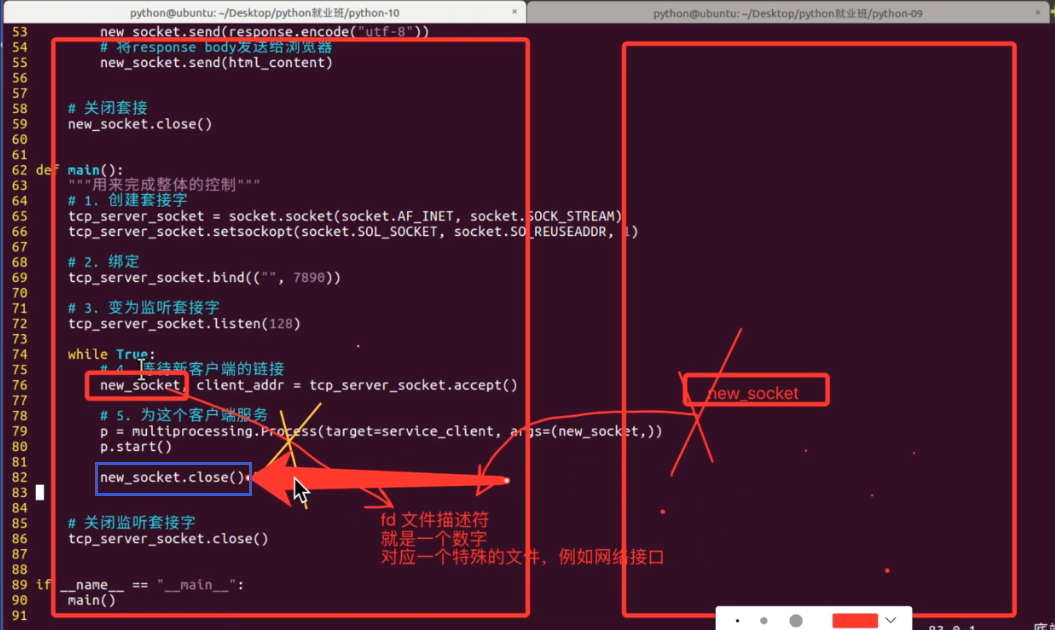
在开启多进程后,为什么还要再多调用一个new_socket.close()(蓝框那里)?
因为开多一个子进程,意味着多复制了一个资源在运行程序。同时,在linux中,一切内容皆文件。当有用户连进来时,本来主进程创建的new_socket对象,在linux底层对应一个文件描述符(fd)也就是数字,该文件描述符对应一个特殊文件,这里就是网络接口。但是当你开多一个进程,意味复制了一份new_socket,此时相当于有两个new_socket对象同时指向该文件描述符,有点像linux中硬链接的感觉,因此只关闭一个new_socket是不够的,后面四次挥手不能进行。所以需要在刚创建一个子进程后,先把主进程的new_socket给关了。
开多线程就不用这样,线程是全局资源共享,共用一个套接字。
单进程、单线程、非堵塞实现并发的原理
类似协程gevent的工作原理(要求程序尽可能快的处理发来的保存在电脑缓存中的信息,不然会使电脑卡)
import socket
def main():
tcp_server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server.bind("", 77888)
tcp_server.listen(128)
tcp_server.setblocking(False) # 设置为非堵塞
client_socket_list = list()
while True:
try:
new_socket, new_addr = tcp_server.accept()
except Exception as f:
print("------没有新的客户端到来------")
else:
print("------只要没有产生异常,意味着来了一个新的客户------")
new_socket.setblocking(False)
client_socket_list.append(new_socket)
for client_socket in client_socket_list:
try:
client_data = client_socket.recv(1024) # 接收到数据有两种情况,一是用户发送来数据;二是用户调用close()
except Exception as f:
print("-----产生异常,说明这个客户端还没有消息传来-----")
else:
if client_data:
# 对方发送过来数据
print("-----客户端发来了数据-----")
else:
# 对方调用close(),导致 recv返回
client_socket_list.remove(client_socket)
client_socket.close()
if __name__ == "__main__":
main()
之前单进程单线程不能实现并发是因为套接字会堵塞,无论是在调用accept()等待用户接入还是调用recv()等待用户发送消息,都会造成套接字堵塞,因此只能一个一个用户服务。我们的解决办法就是给套接字解堵塞,再使用异常判断,如果没有用户接入或者没有用户发消息过来时就抛弃异常循环监听,一旦用户接入进来,就把产生的套接字放到一个列表里面然后再循环读出。
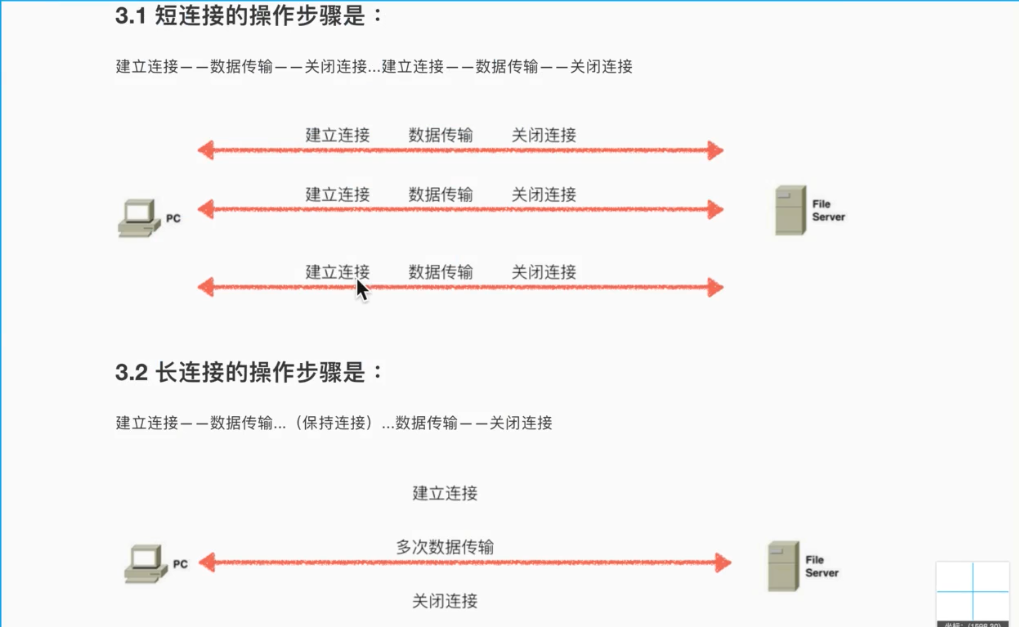
实现“单进程-单线程-长链接”的过程。有一个点需要注意就是为了实现时时链接,在关闭了套接字的close()之后,要在responce_header里面加上responce_body的长度,不然浏览器在读取服务器发送过来的数据时不会结束,会一直继续刷新等待服务器的发送,此时客户端无法继续向服务器发送请求。因此添加responce_body的长度后,浏览器根据长度截取获取到的信息,而后客户端可继续发送请求。
 View Code
View Code
epoll过程了解
上面我们写的单进程-单线程-非堵塞并发的代码如果遇到同一时间很多人访问的时候,那么列表里面就会有很多套接字,这时一个一个循环遍历检查的效率就会显得很低,这种方式称为轮询。第二个影响效率的原因就是我们创建一个列表,再往里面添加套接字,相当于应用程序在内存中单独开辟一块空间,每次轮询就是把一个套接字对应的fd(文件描述符)复制一份,送到内核态里面,交给操作系统进行检查。
而epoll就主要解决了这两种问题。首先是它开辟的内存空间用来存放套接字的地方,是直接和内核态(kernel)共用的,因此省去了复制一份套接字(fd)的过程还有取出套接字(fd)送到内核态中的过程;另一个就是它采用事件通知的方式,不一个一个进行检查询问,而是对内存中的套接字所对应的文件描述符(fd)采用事件通知,什么时候收到数据,查看是属于哪个套接字,然后操作系统通知应用程序哪个套接字可以接收了,从而达到提升效率的目的。
epoll的作用就是把原本需要应用程序去遍历列表的过程交给操作系统去做。
import socket
import select
def server_client():
# 进行数据的收发等
pass
def main():
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.bind("", 8080)
tcp_server_socket.listen(128)
tcp_server_socket.setblocking(False)
# 创建一个epoll对象
epl = select.epoll()
# 将监听套接字对应的fd注册到epoll中
epl.register(tcp_server_socket.fileno(), select.EPOLLIN)
# 创建用于存放fd和套接字对应关系的字典
fd_event_dict = dict()
while True:
fd_event_list = epl.poll() # 默认会堵塞,知道os监测到数据到来,通过事件通知的方式告诉这个程序,此时才会解堵塞
# [(fd, event), (返回的列表里面是一个个元组 套接字对应的文件描述符,这个文件描述符到底是什么事件,例如可以调用recv接收等)]
for fd, event in fd_event_list:
# 等待新客户的链接
if fd == tcp_server_socket.fileno():
new_socket, client_addr = tcp_server_socket.accept()
epl.register(new_socket.fileno(), select.EPOLLIN)
fd_event_dict[new_socket.fileno()] = new_socket
elif event == select.EPOLLIN:
# 判断已链接的客户端是否有数据发送过来
recv_data = fd_event_dict[fd].recv(1024).decode("utf-8")
if recv_data:
server_client(fd_event_dict[fd], recv_data)
else:
fd_event_dict[fd].cloes()
epl.unregister(fd)
del fd_event_dict[fd]
一个应用程序以TCP协议正在使用一个端口例如8080,那么就不允许被其他使用TCP协议的应用程序使用8080,但是此时使用其他协议例如UDP的程序就可以也使用8080。
子网掩码的作用就是确定IP地址哪部分属于网络号哪部分属于主机号。
集线器的通信方式是广播,这样会导致占用线路,影响别的用户通信。后来改成交换机,特点就是可以广播,也可以单播。
实际地址,也就是网卡地址(mac地址),前三组数字表示生产产家,后三组数字是实际生产的网卡编码。
路由器的作用是连接两个网络,一个网络内的电脑要想发数据给另一个网络内的,必须设定网关,网关一般就是路由器。发数据的时候,目的mac地址写的是网关的mac地址,经过网关处理后,再改成目的电脑的mac地址。因此整个过程一直在变的是mac地址,目的IP不变。
为什么有了IP地址还要有mac地址。因为IP地址是在逻辑层面标注的数据要送到哪里,但是实际一层一层之间的传递,是靠的mac地址。
(https://www.zhihu.com/question/21546408)
从浏览器发起一次请求到http服务器的过程:
首先检查是否有默认网关的mac地址,如果没有,就用广播的方式获取网关的mac地址,然后根据电脑配置的DNS服务器的IP,带上要访问的域名向DNS服务器查询域名的IP,经过网关、路由器等到达后,DNS解析获取Ip,返回到客户端,然后客户端根据这个IP再经过网关等一系列的传播,和http服务器三次握手成功,传输数据,最后再四次挥手结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号