System Design Interview
1 Proximity Service
1) requirements
| Functional Requirements | Non-Functional Requirements | |
| 1 |
Return all businesses based on user's location (latitute and longitute pair) and radius (5km) |
Low latency.
|
| 2 |
Business owners can use Restful API to deal with a business.
|
Data privacy
|
| 3 | Custerms can view business detail |
High availability and scalibility requirements.
|
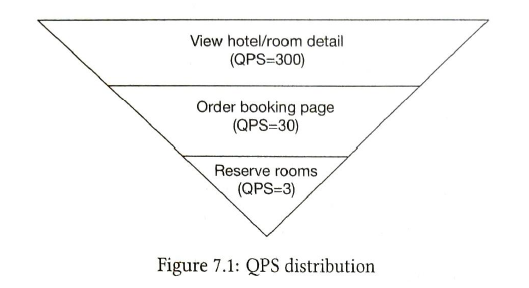
2) Basic Culculatiion
| QPS |
Seconds in a day = 24 * 60 * 60 = 86400, round it up for 10**5. the fifth power of ten Users: 100 million Searches: 5 times. QPS: 100m * 5 / 10**5 = 5000 |
5000 |
| Users | 100 million | |
| Business | 200 million |
3) High Level Design
| User API design |
Users search for business.
Parameters.
{ "radius": 10, "business": [business Object] } |
GET / search / nearby | |
| Business API design |
Restful API.
|
||
| Data model |
Read / Write Ration Read:
Write:
Schema
|
MySql. (PostgreSQL) |
|
| Algorithms to find near by business |
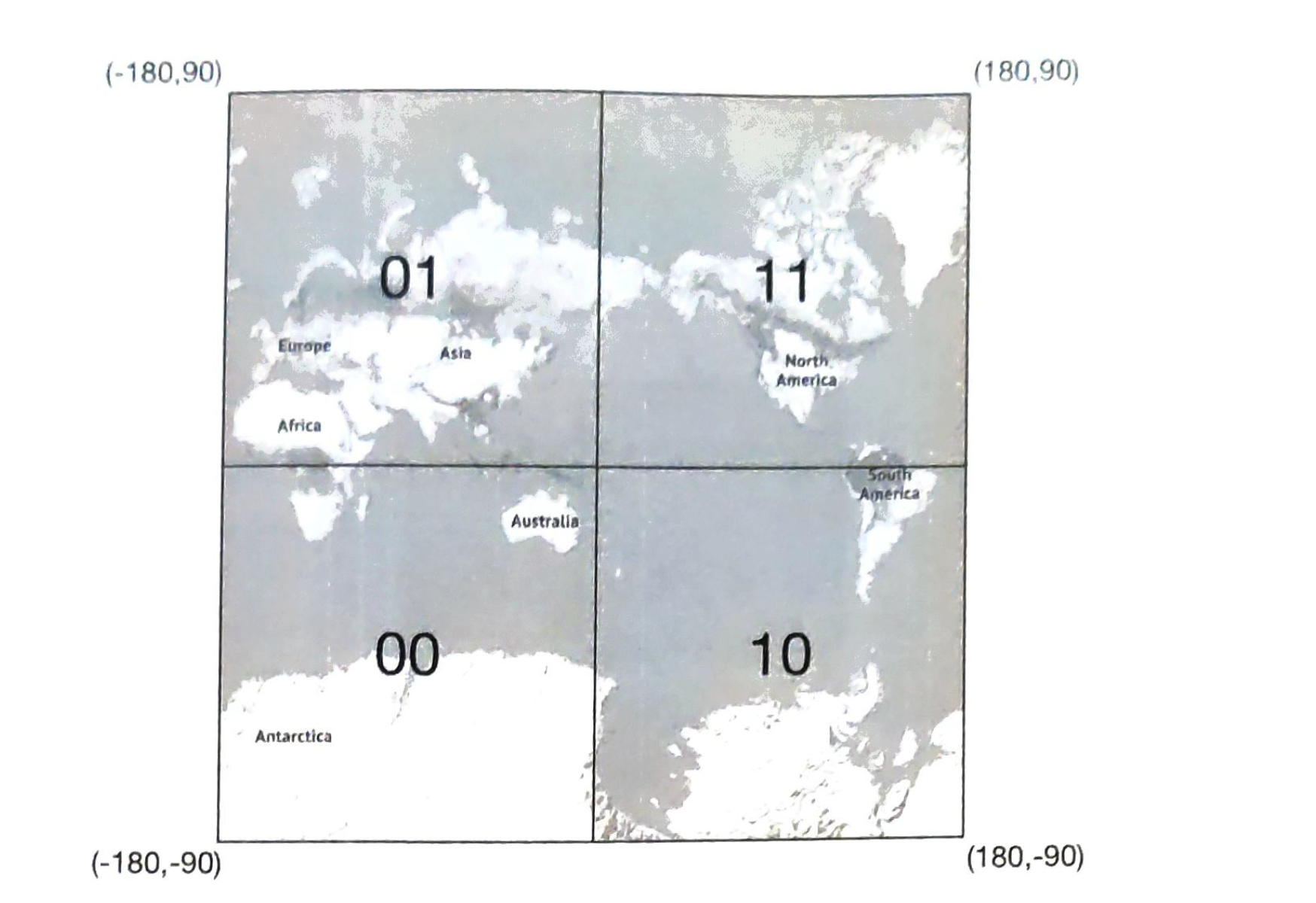
1) Geohash
problems:
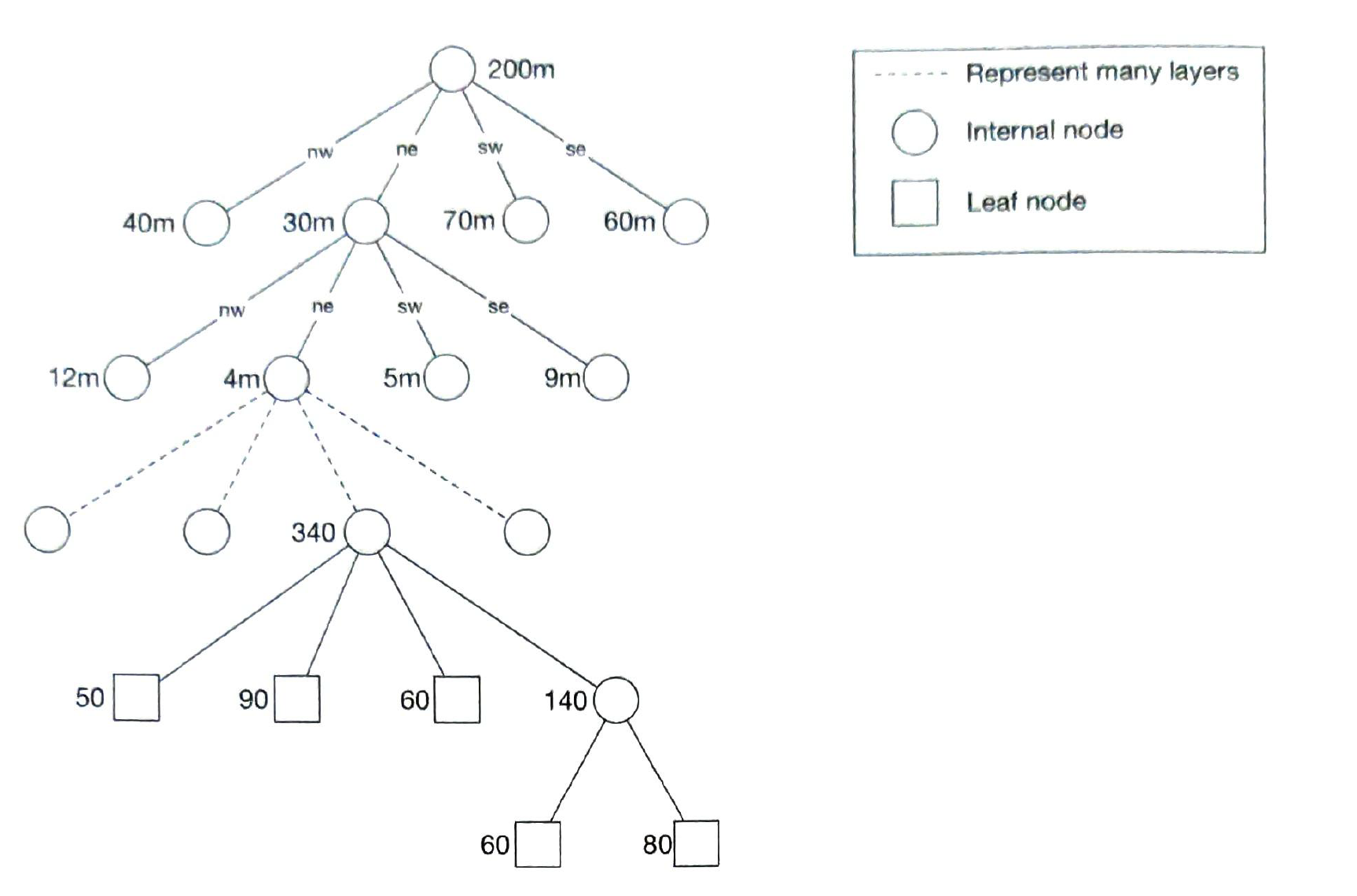
2) Quatree
|
4) design diagram
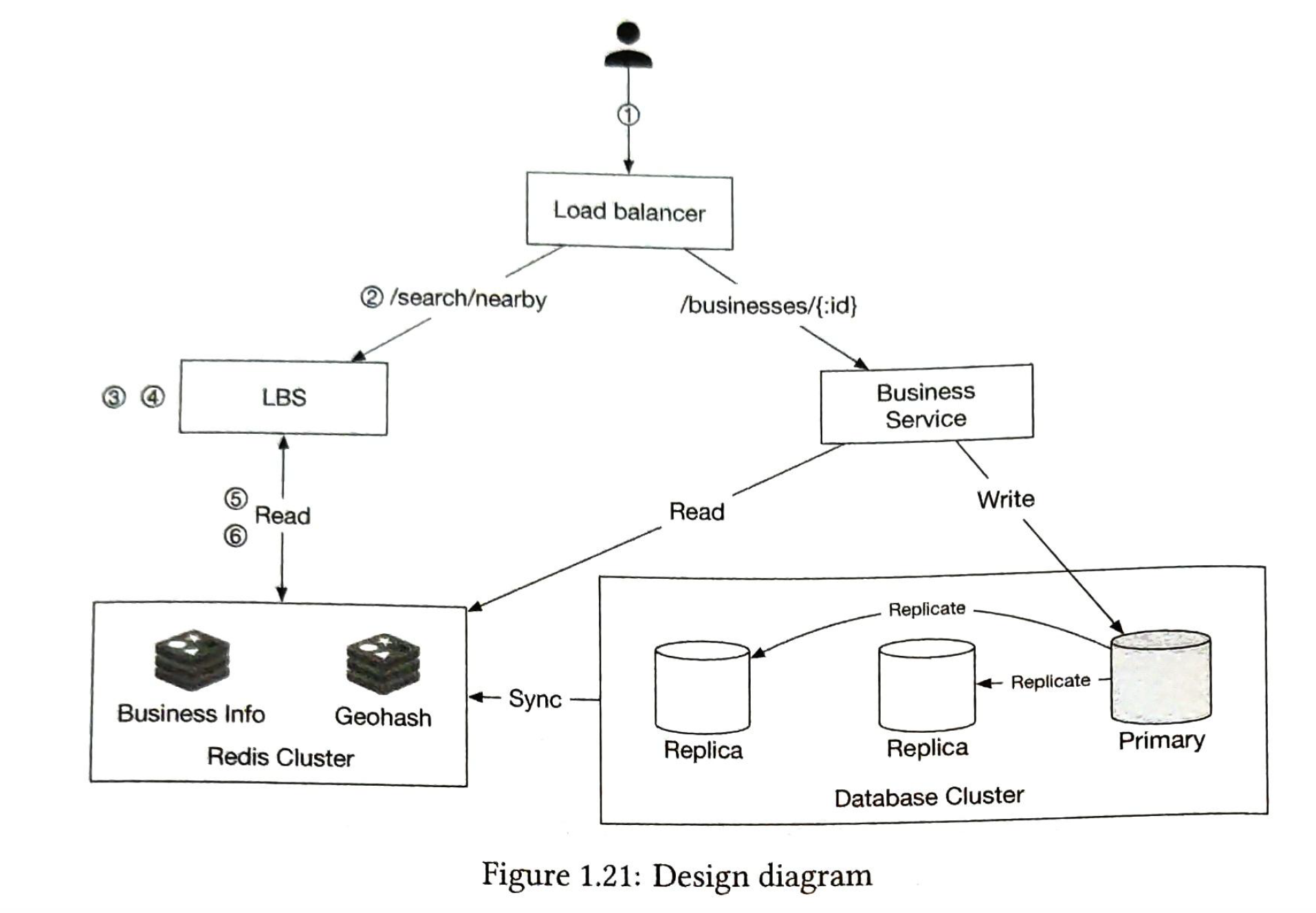
| Load Balancer |
receive requests (latitute, longitute, radius) from users |
| Location-based service |
Responsibility
characters:
it is a multi location services.
|
| Business Service |
|
| Database Cluster |
Scale: 1) Business Table
2) Geo index Table
|
|
Redis Cluster
|
Caching is not necessary. Because read geo index from database is fast enough. we can use cache to handle the spike during peak hours. We use caching to enhance the performance. |
|
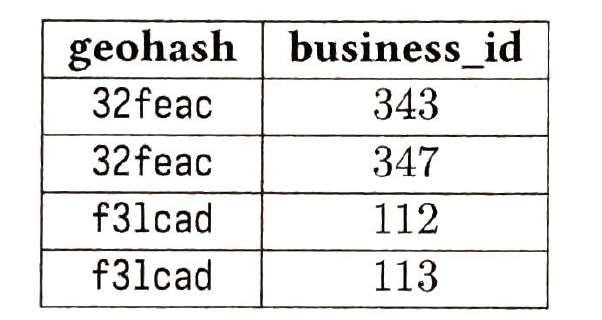
1) key: geohash, value: [business_list] storage for value: 200 m * 32 bytes * 3 precisions = 17gb storage for key: negligible.
we deploy this cache globally to ensuer high availability |
|
|
2) key: businessid, value: business_object |
2 nearyby friends
people's loocation changes a lot. business location is static.
1) requirements
| Functional requirements | Non-functional requirements |
|
each entry in the list has locaiton and timestamp. friends can see nearby friends |
low-latency
|
| nearby firend lists should be updated every 30 seconds. |
reliability
|
|
eventually consistency
|
2) back-of-the-envelope estimation
| distance | 5 miles |
| location refresh interval | 30 secs |
| users per day | 100m |
| concurrent users | 10m |
| a user's friends | 400 |
| number of people per page | 20 |
| QPS | 10 m / 30s = 334k |
3) high level design
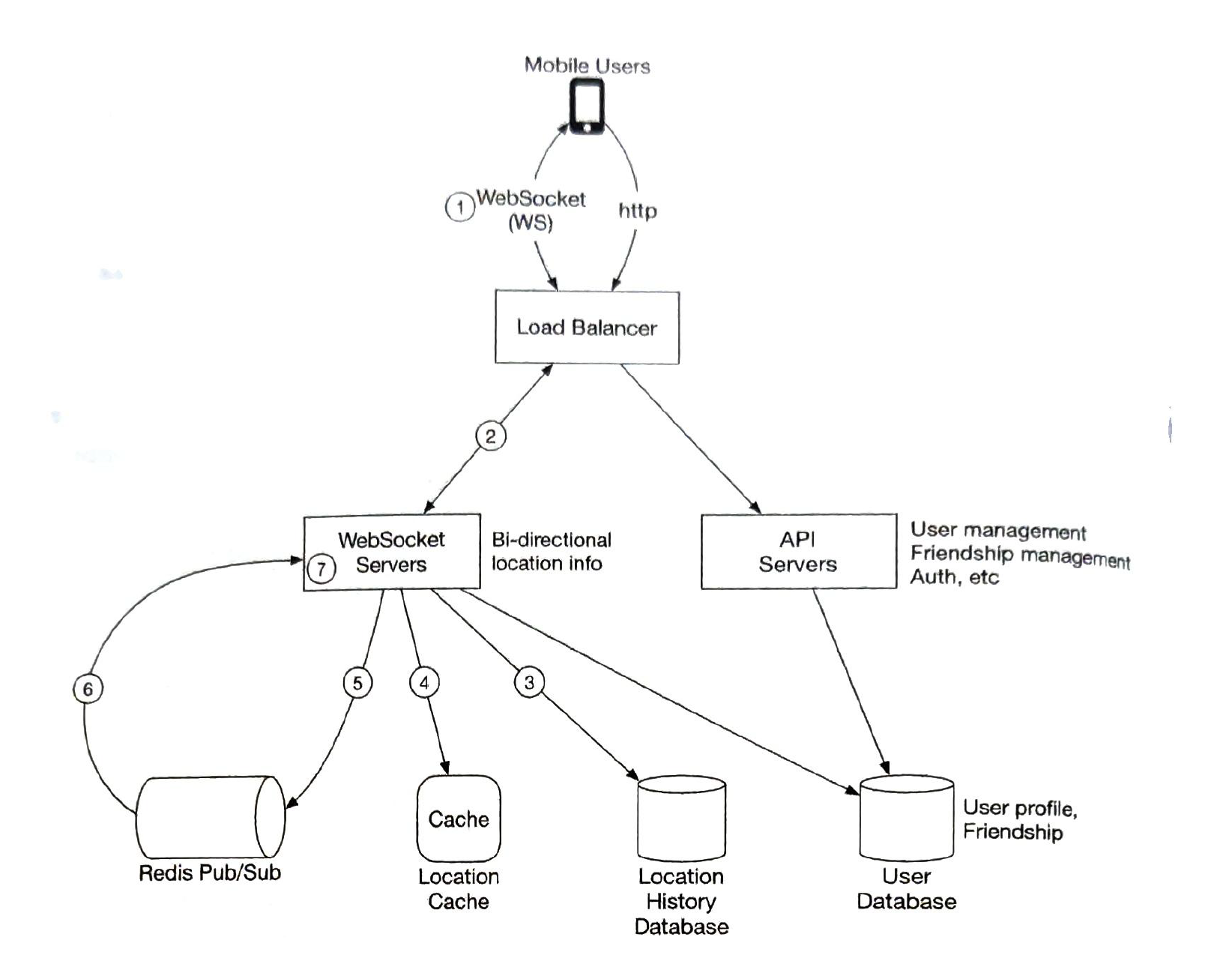
| Load Balancer | In front of Restful API and bi-direction WebSocketServers |
| Web Socket Servers |
WebSocket Servers.
Initialization for the 'nearby friends'
stateful.
|
| Restful API servers |
Friendship management A cluster of stateless HTTP servers that handles common request / response like, adding, removing, updating profile.
stateless. so we can auto-scale hardware. |
| Redis Location Cache |
Location and TTL key: userid value: latitude, longitude, timestamp
QPS is 334k. But we can shard the location server by user_id. We can spread the load among several Redis servers. 10% of 10 million are online. calls: 334k * 400 * 10% = 14 m |
| location history databse | historical location data. for data analysis |
| User database |
user & friends database {user_id, user_name, profile, url, etc}
ralational database easy to scale by sharding based on their userid. |
| Redis Pub / Sub Server | 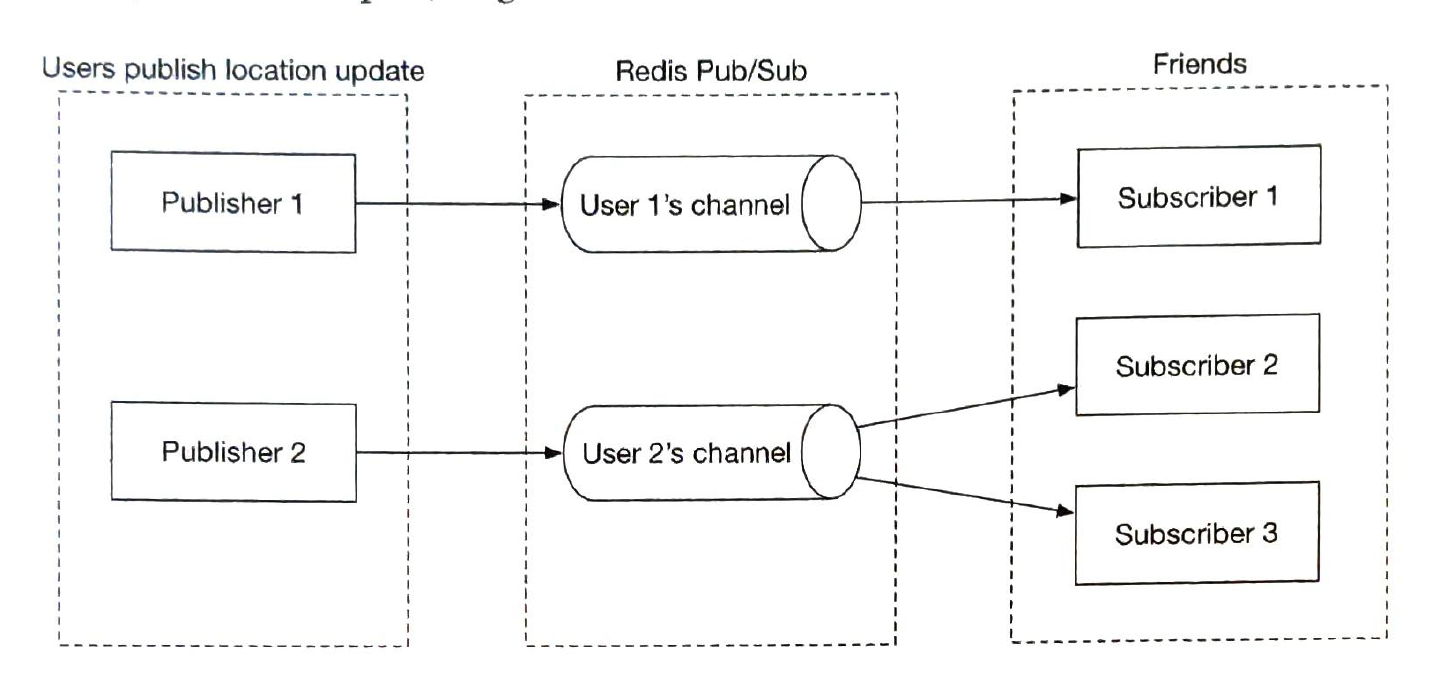
Location updates via websocket server are published to the user's own channel.
Memory Usage (100 m * 100 *20 = 200GB, 2 servers (1 server has 100GB memory))
CPU usage (14m / 10k = 140 servers)
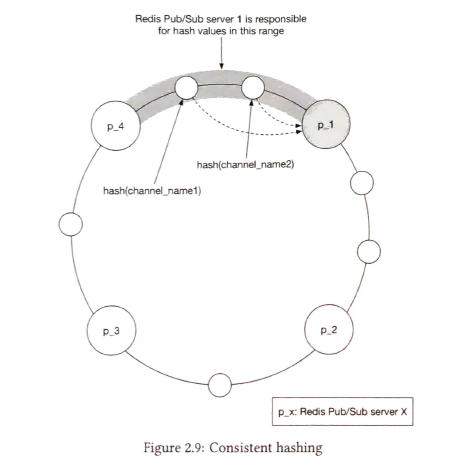
Bottleneck of Redis Pub / Sub server is the CPU usage. not the memory usage. we can use a hash ring to mark the each server to handle the calls.
scale: if a node is replaced, we should let the user subscribe the new node. so this cluster is stateful if we have to scale the cluster, we should
users with many friends 5000 at most, it is not a problem |
3 Google Maps
1) requirements
| functional requirements | non-functional requirements |
| User location update | Accuracy: users should not be given the wrong directions |
| Navigation service, including ETA service | Smooth navigation: On the client-side, users should experience very smooth map rendering. |
| Map rendering |
Data and battery usage: The client should use as little data and battery as possible. This is very important for mobile devices. |
| General availability and scalability requirements |
2) back of the envelope estimation
| Map storage |
50PB.
|
| server throughput |
1 billion DAU navigation, 35 minutes per week. 5 billion minutes per day
GPS coordinates (users update their coordinates): QPS 3million
batch GPS coordinates 3 m / 15 = 200k. (every 15secs)
peak QPS = 1 million |
3) Design
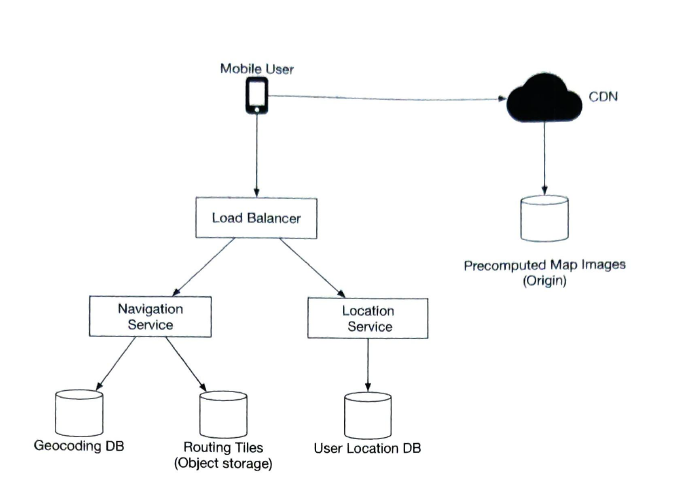
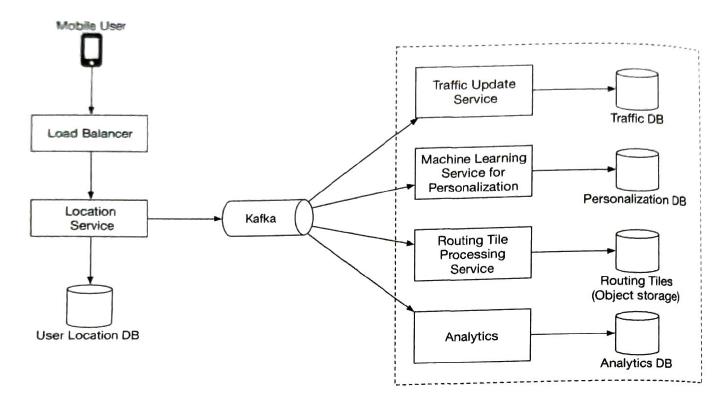
| Location Service |
save locations can use to find new roads. It is a write-heavy service. So cassandra could be a good candidate.
Prioritize availability over consistency. We could choose 2 attributes accroding CAP. -> AP.
Updater services. We can calulate new roads and remove an unused road. Impove the accuracy of our map. Use kafka
|
| navigation service |
find a reasonably fast route from point A to point B culculation speed is not important, but accuracy is critical user sends an HTTP request to the navigation service through a load balancer
Routing tiles. (路组成的图片, map 是建筑物之类的背景) This dataset contains a large number of roads and associated metadata such as names, county, longitude and latitude. We run a periodic offline processing pipeline to capure new changes oto the road data. Output is routing tiles
Shorest-path service Return top-k shortest paths without considering traffic or current conditions. This computation only depends on the structure of the roads. Caching the routes could be beneficial because the graph rarely changes. Algorithms A*.
ETA service Get the time estimate according to a list of shortest path.
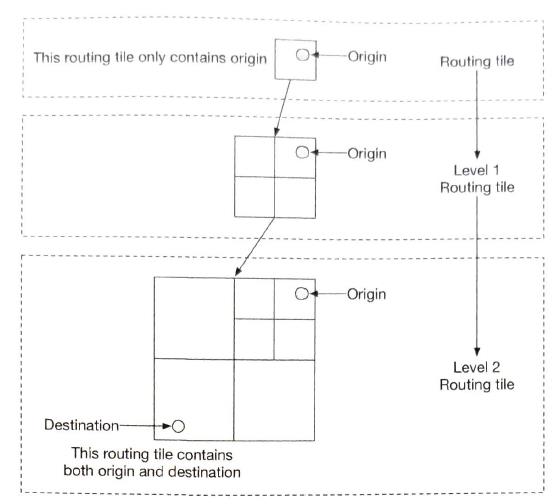
If there is an incident in a routing tile. We need find affected users. origin: r_1, r_2, ...., r_n alternative: r_1 ... super(super(r_1)). So can only check if the last routing tile is affected.
|
|
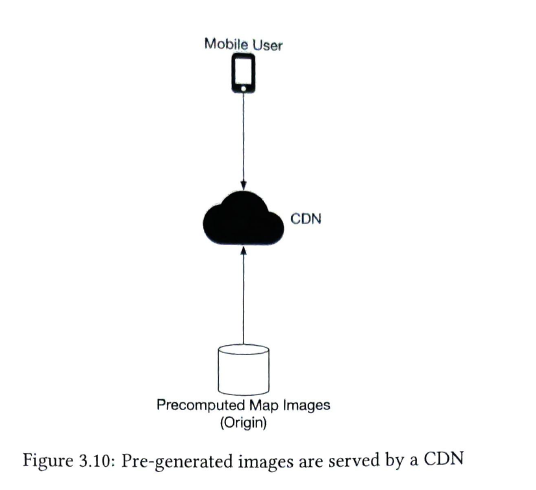
Map rendering service Precomputed Map images |
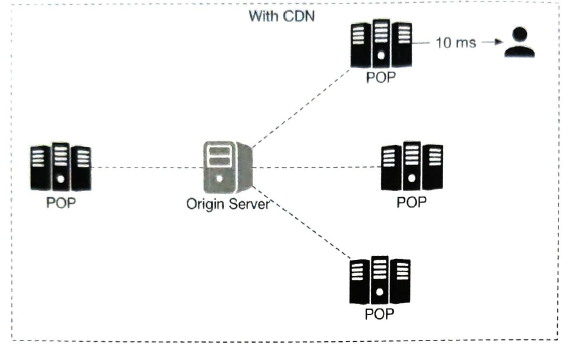
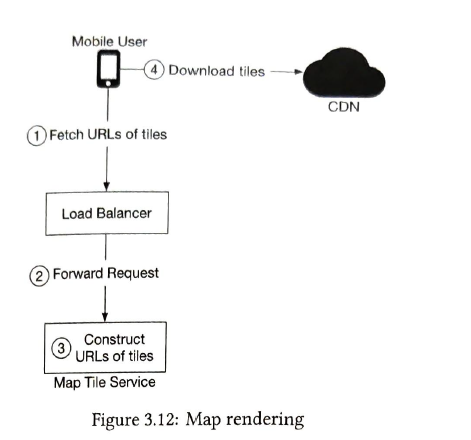
CDN (content delivery network) Map tiles are generated already in database. Calculate the geohash to get the appropriate zoom level map tiles
scenarios of updating the map tiles:
Each image is 200 * 200 square-meters. User's speed is 30km/h. An area of 1km * 1km needs 25 images. (1 / 0.04) or 2.5 MB (100kb * 25). An hour we need 30 * 2,5 data. one minute is 1.25MB of data
Traffic through CDN. 5 billion minutes DAU * 1.25 MB data per minute = 6.25 billion MB one day. 6.25 billion one day / 10**5 = 62500 MB one second. Let's assume there are 200 POPs, each POP serves 312.5 MB data per second.
URL: Geohash. https://cdn.map-provider.com/tiles/9q9hvu.png
Instead of using a hardcoded client-side algorithm to convert a latitue/longitude (lat/lng) pair and zoom level to a tile url, we could introduce a service as an intermediary whose job is to construct the tile URLS. It returns 9 URLS (8 surrounding tiles)
|
4 Distributed Message Queue
1) requirements
| functional requirements | non-functional-requirements |
| Producers send messages to a message queue | high throughput or low latency, configurable based on use cases. |
| Consumers consume messages from a message queue | Scalable. The system should be distributed in nature. It should be able to support a sudden surge in message volume. |
| Messages can be consumed repeatedly or only once | Persistent and durable. Data should be persisted on disk and replicated across multiple nodes |
| Historical data can be truncated | |
| Message size is in the kilobyte range | |
| Ability to deliver messages to consumers in the order they were added to the queue | |
| Data delivery semantics (at-least once, at-most once, or exactly once) can be configured by users |
2) Design
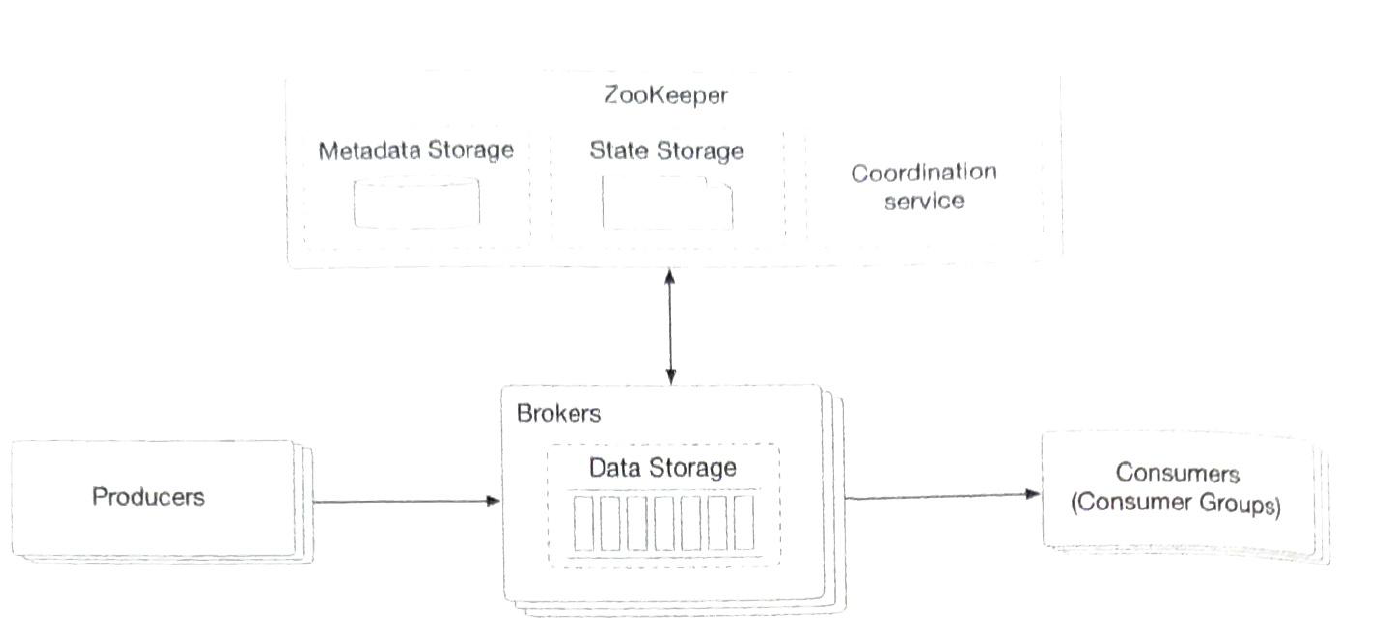
| Brokers |
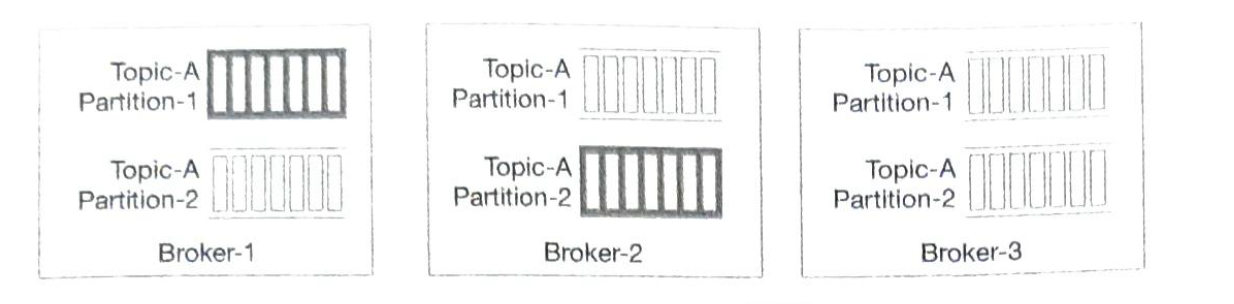
When data volume is too larg. We divide a topic into partitions (sharding). These servers hold partitions are called brokers (not one partition).
|
| Consumer Group | 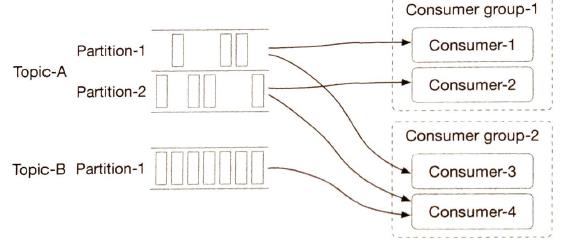
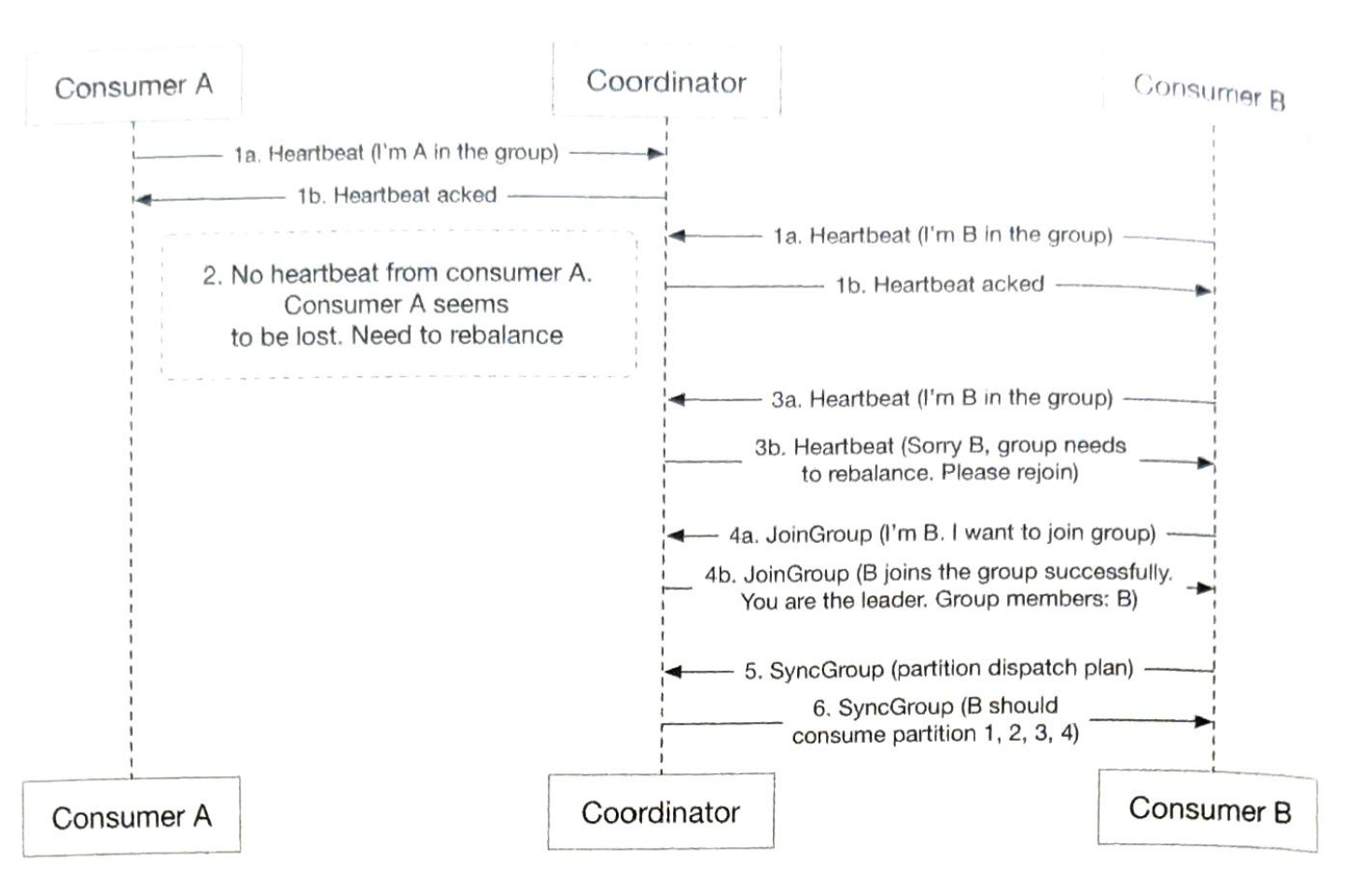
We can group consumers by use cases, one group for billing and the other for accounting. A single partition can only be consumed by one consumer. |
| coordination service |
service discovery: which brokers are alive leader election: one of the brokers is selected as the active controller. Only one controller is responsible for assigning partitions |
| data storage |
WAL.
Disk performance of sequential access is very good
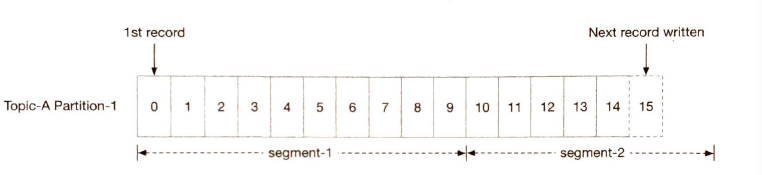
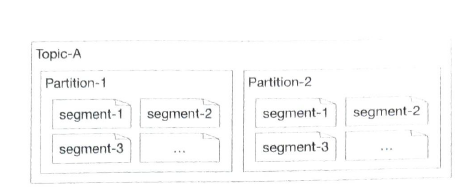
Divide a file into segments. With segments, new messages are appended only to the active segment file.
Use RAID. hundred MB / sec of read and write speed
Message data structure
Batching.
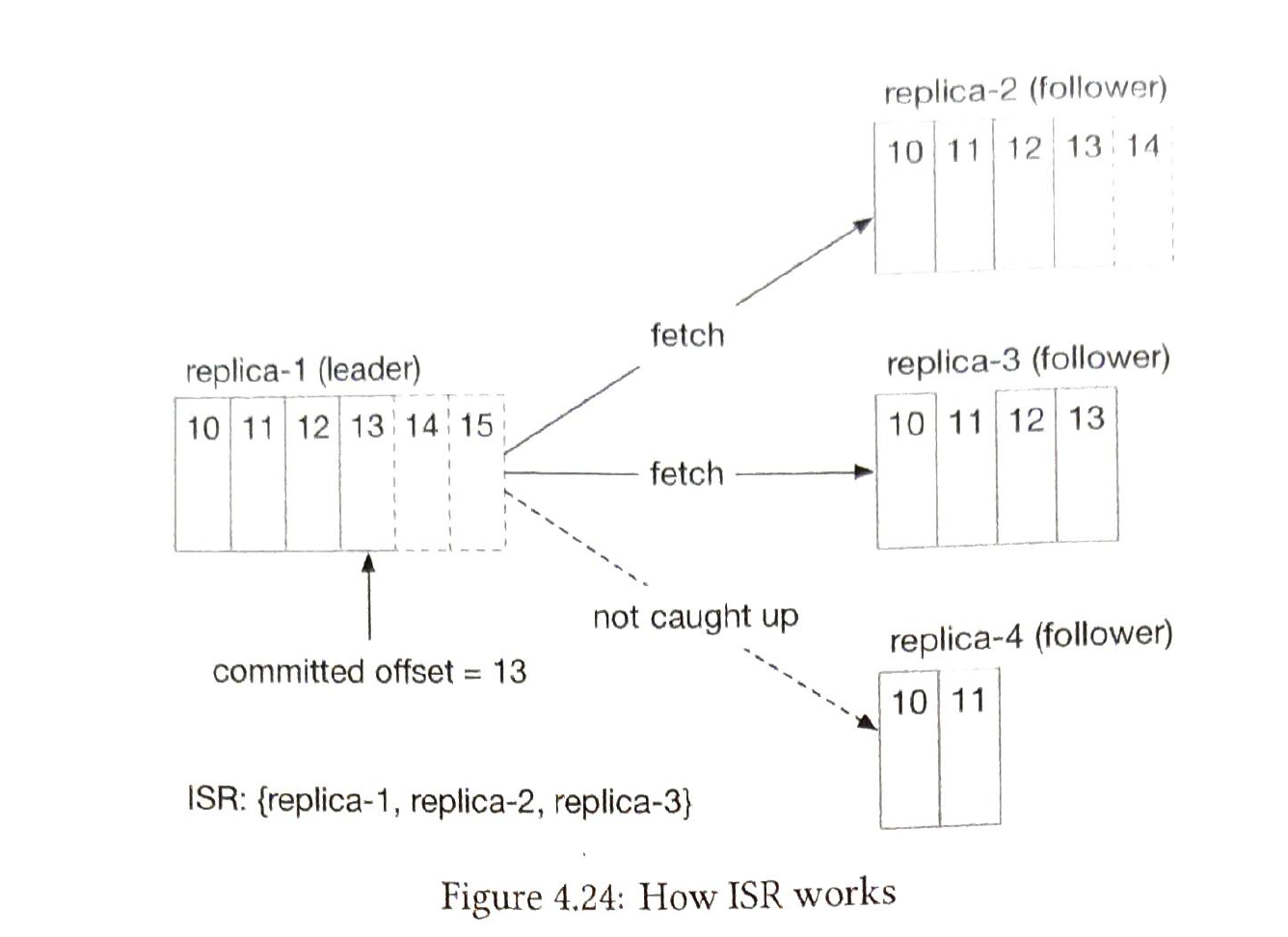
Each partition has multiple replicas.
In-sync replicas (ISR). ISR reflets the trade-off between performance and durability.
The numebr of replicas of a partition is also a trade-off
Add one broker. |
| Producer | 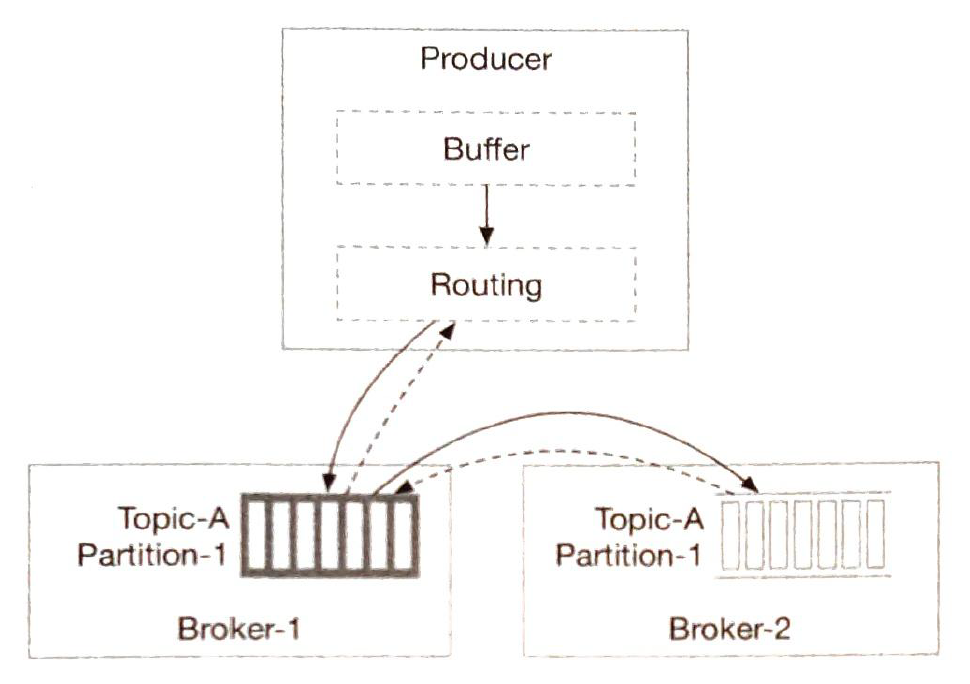
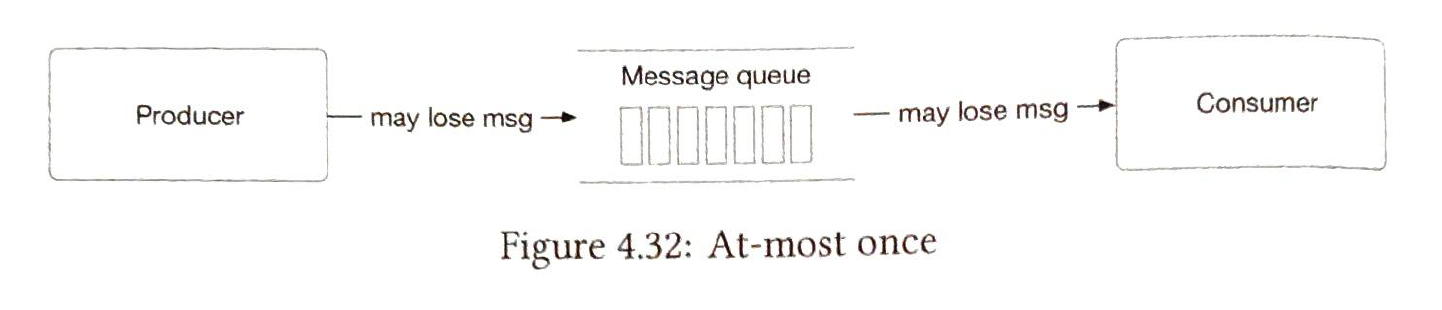
Messages delivery policy. 1) At-most-once
ACK = 0
2) At-least-once ACK = 1 or ACK = all
3) Exactly once Has a high cost for the system. (financial-related use cases.)
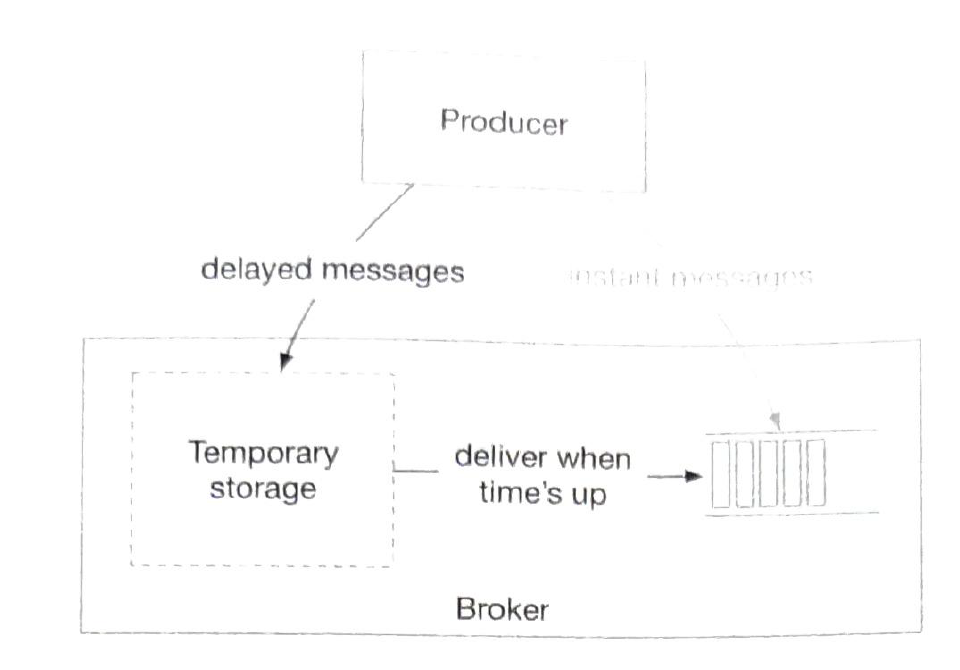
Delayed message
|
| Consumer |
Push vs Pull (whether a broker should push data to a consumer or consumer pull data from a broker? Push:
Pull:
We prefer pull model.
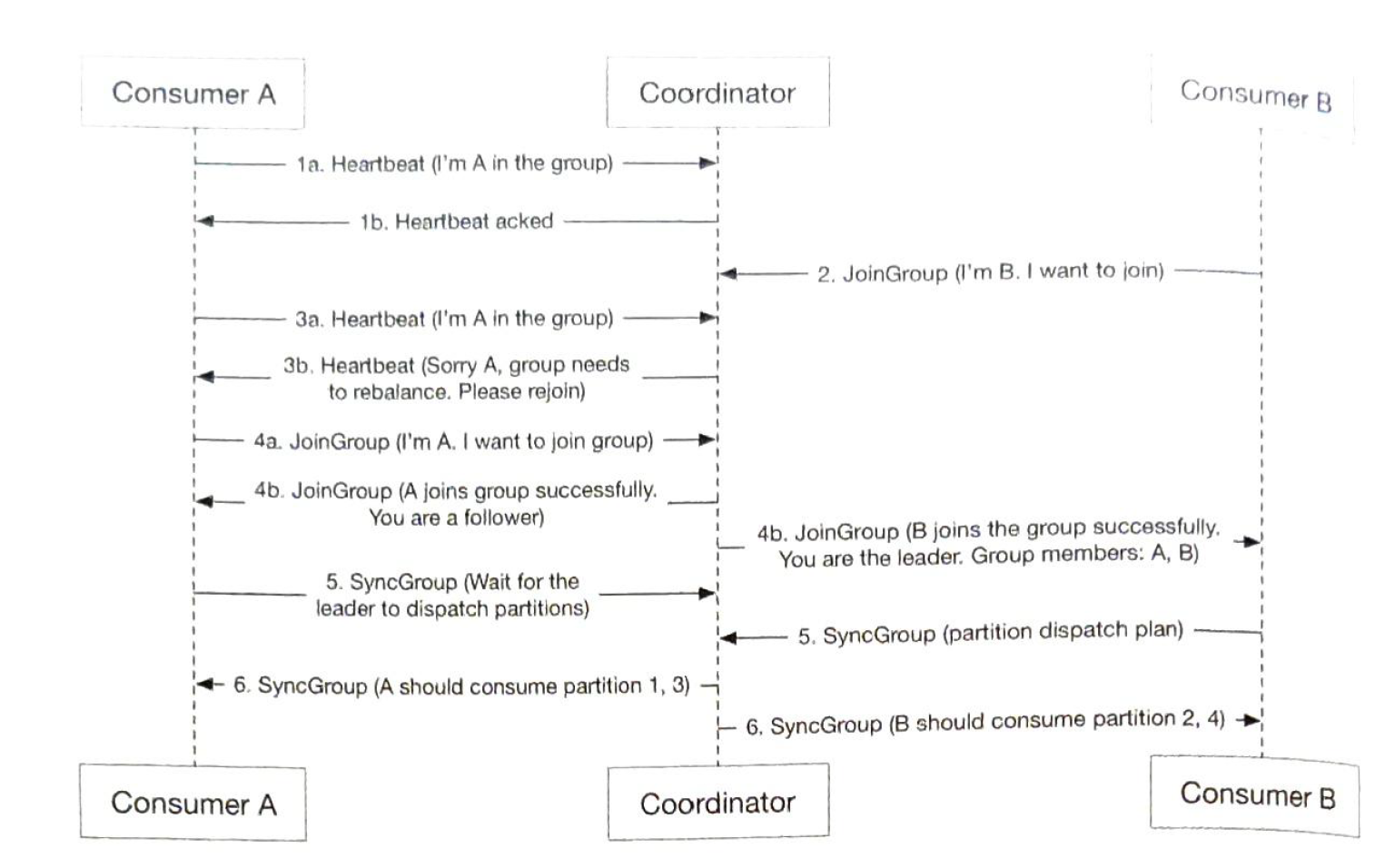
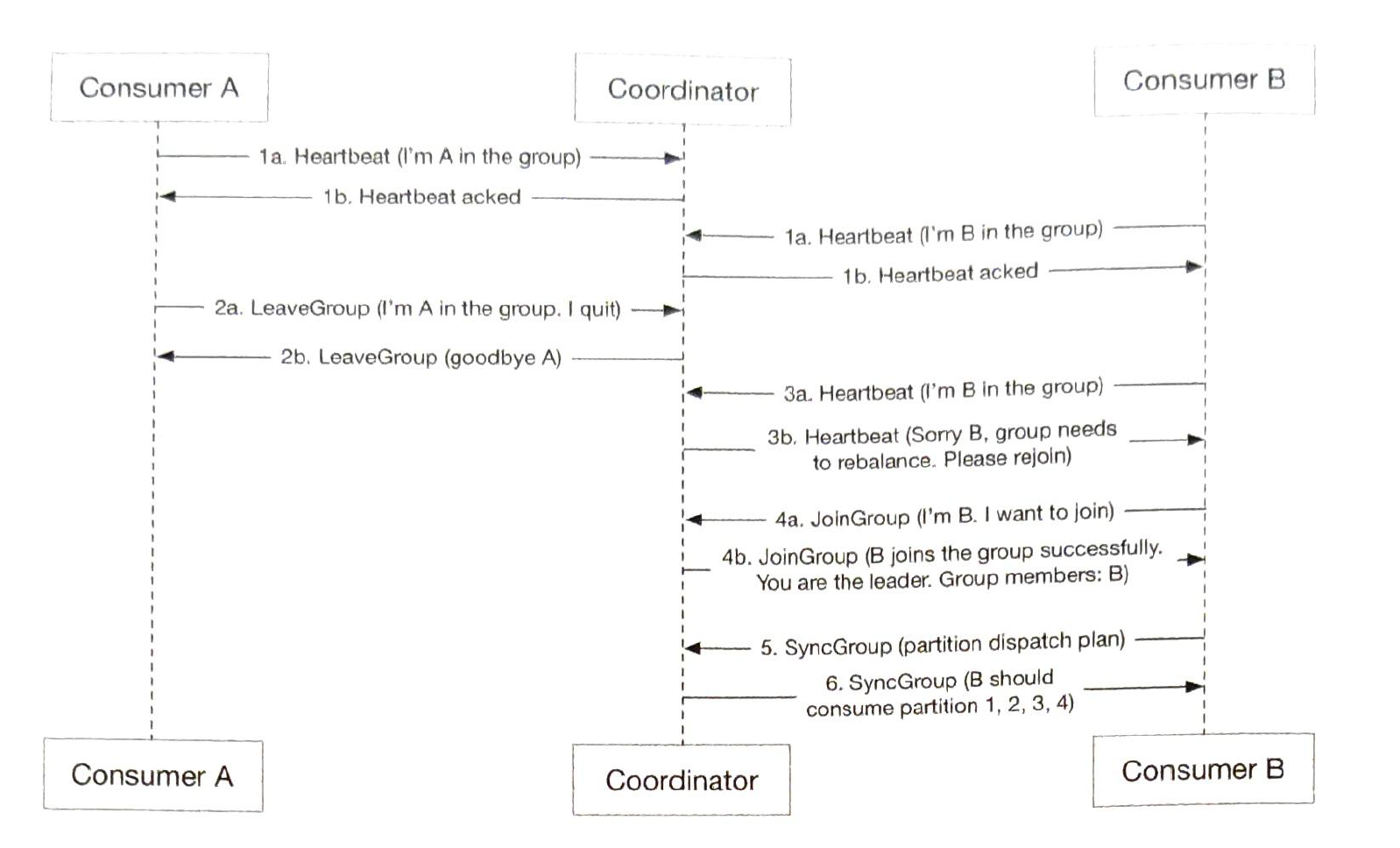
New consumer joins.
Existing consumer leaves.
Existing consumer crashes. |
| State storage |
Stores:
|
| Metadata storage | Stores configuration and properties of topics |





5 Metrics Monitoring and Alerting System

1) requirements
| Functional | Non-functional |
| cpu usage |
scalability
|
| request count |
low latency
|
| memory usage |
reliability
|
| message count in message q |
flexibility
|
|
data retention policy
|
2) back-of-the-envelope estimation
| DAU | 100 million |
| Metrics |
10 million metrics
|
| data retention | 1 year |
3) design
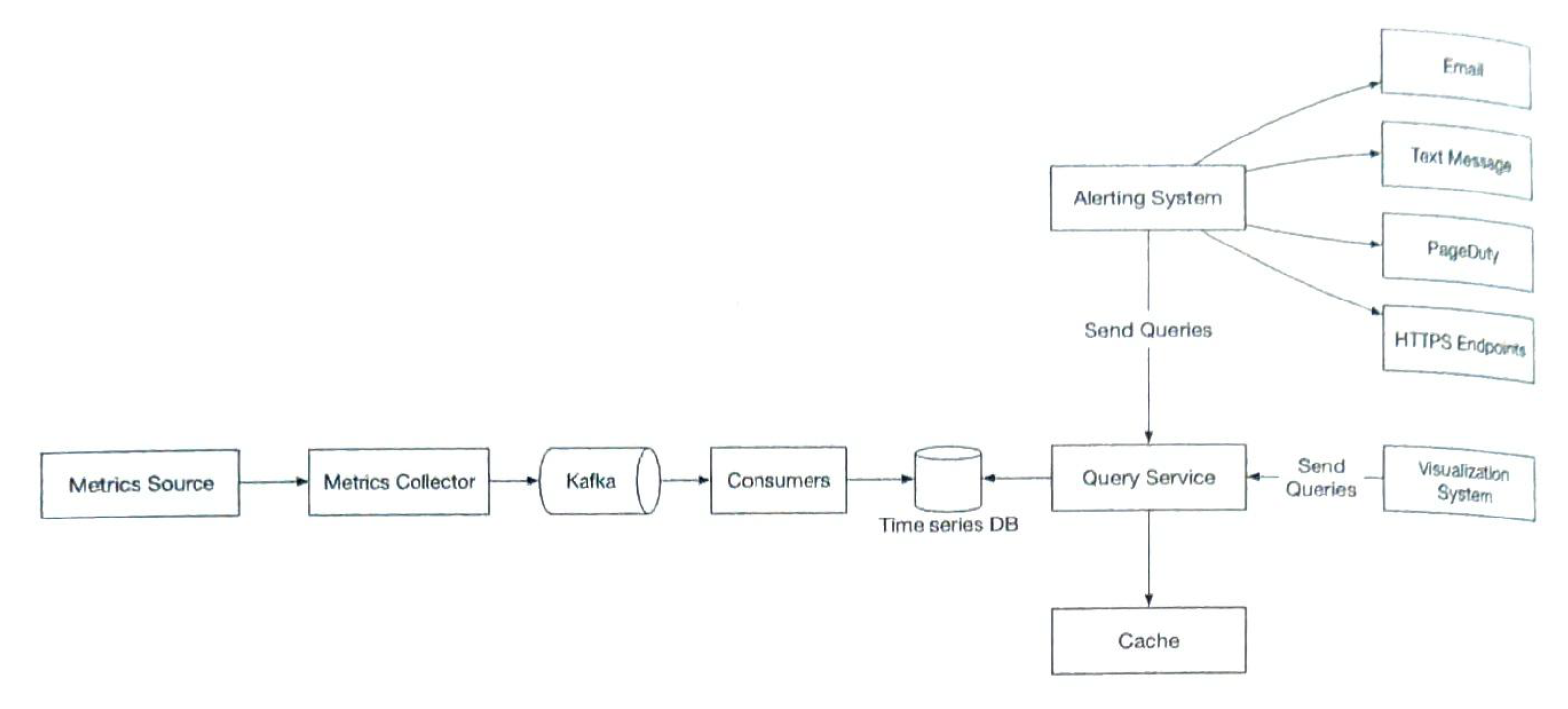
|
data storage system (time series DB) |
InfluxDB
Data encoding and compression can significantly reduce the size of the data
Modern ts DB has its own cache layer and query service. |
| Metrics sources | This can be application servers, DB, message qs, etc |
| Metrics collector |
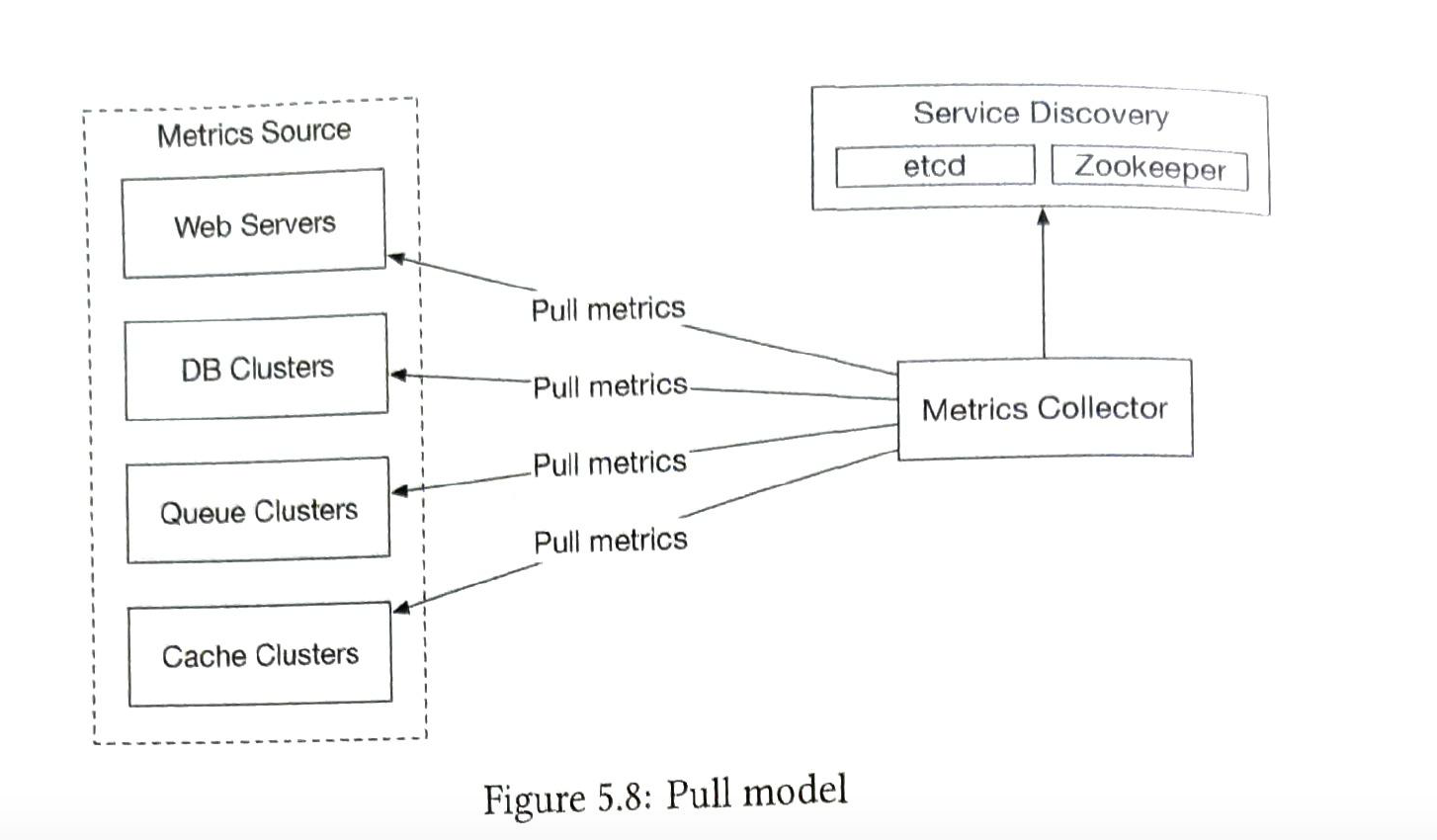
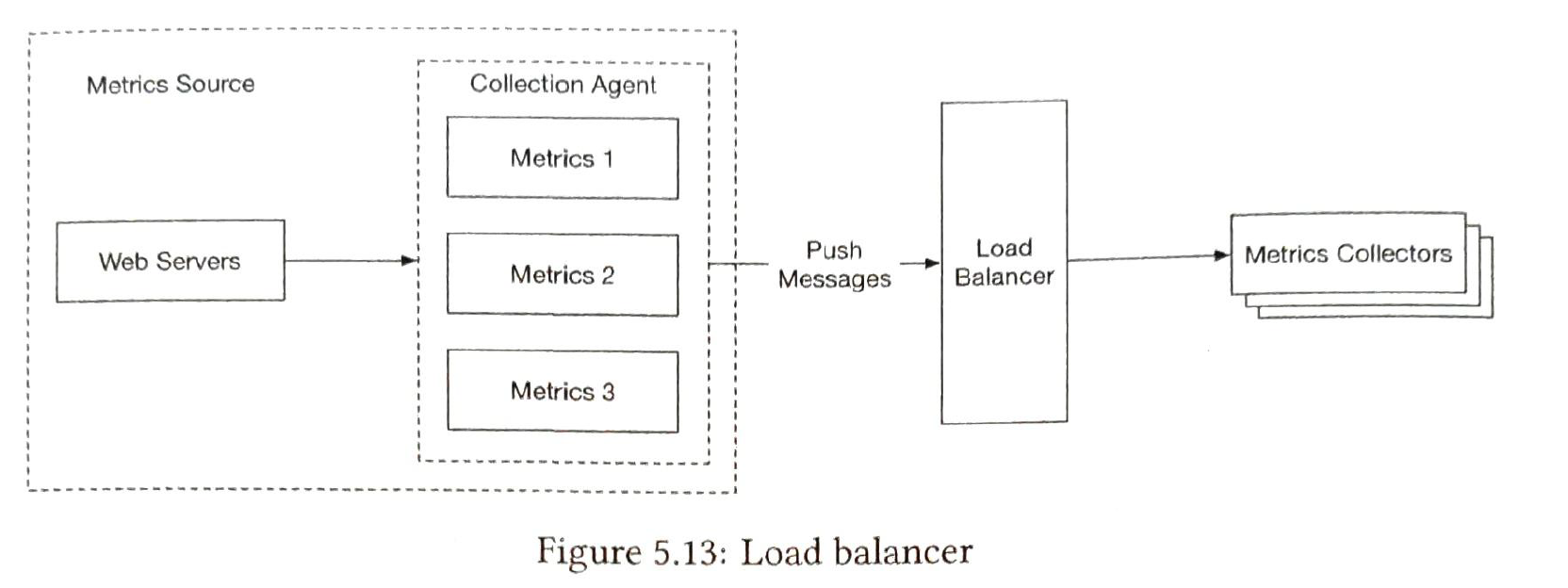
Gathers data and writes to time-series db. Collectors are from a cluster of servers. Two ways to collect metrics, pull vs push. (not an ensure answer) 1) Pull
pros
2) push
pros
|
| Query serivce |
makes it easy to query data from ts db. This is where aggregation happens
Modern ts DB has its own cache layer and query service. |
| Cache layer |
To reduce the load of the time-series database and make query service more performant. Cache layer is used to store query result.
Modern ts DB has its own cache layer and query service. |
| Alerting system | 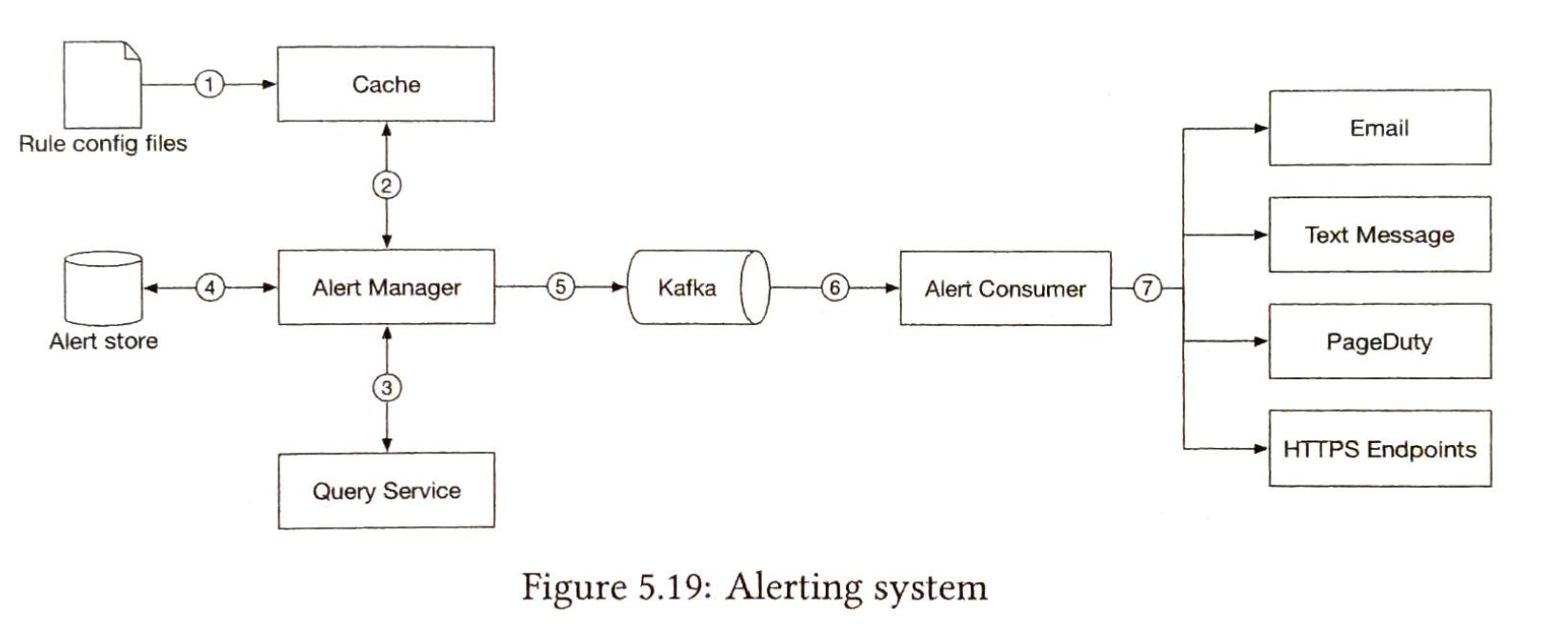
|
| Visulization system | Grafana |
| Consumers |
Saprk, Flink, Storm etc. Can decouple the data collection and data processing services. |
| Kafka |
Can decouple the data collection and data processing services.
|

6 Add Click Event Aggregation
1) requirements
| Functional | Non-functional |
| aggregate the number of clicks of ad_id in the last M minutes | correctness of the aggregation result is important |
| return 100 most clicket ad_ad every minute | properly handle delayed or duplicate events |
| support aggregation filtering by different attributes | robuness. |
| latency requirements. few minutes at most |
2) back-of-the-envelope estimation
| DAU | 1 billion |
| Daily clicks |
1 billion
|
| QPS |
10k.
|
| Peak QPS | 50k |
| Capacity of storage |
100GB
|
| Number of adds |
2 million |
| Business grows |
30% / year |
3) API Design
| API-1: Aggregate the number of clicks in last M minutes |
API:
Request:
Response:
|
| API-2: Top-N most clicked ad-ids in the last M minutes |
API:
Request:
Response:
|






3) Aggregation design

| Message |
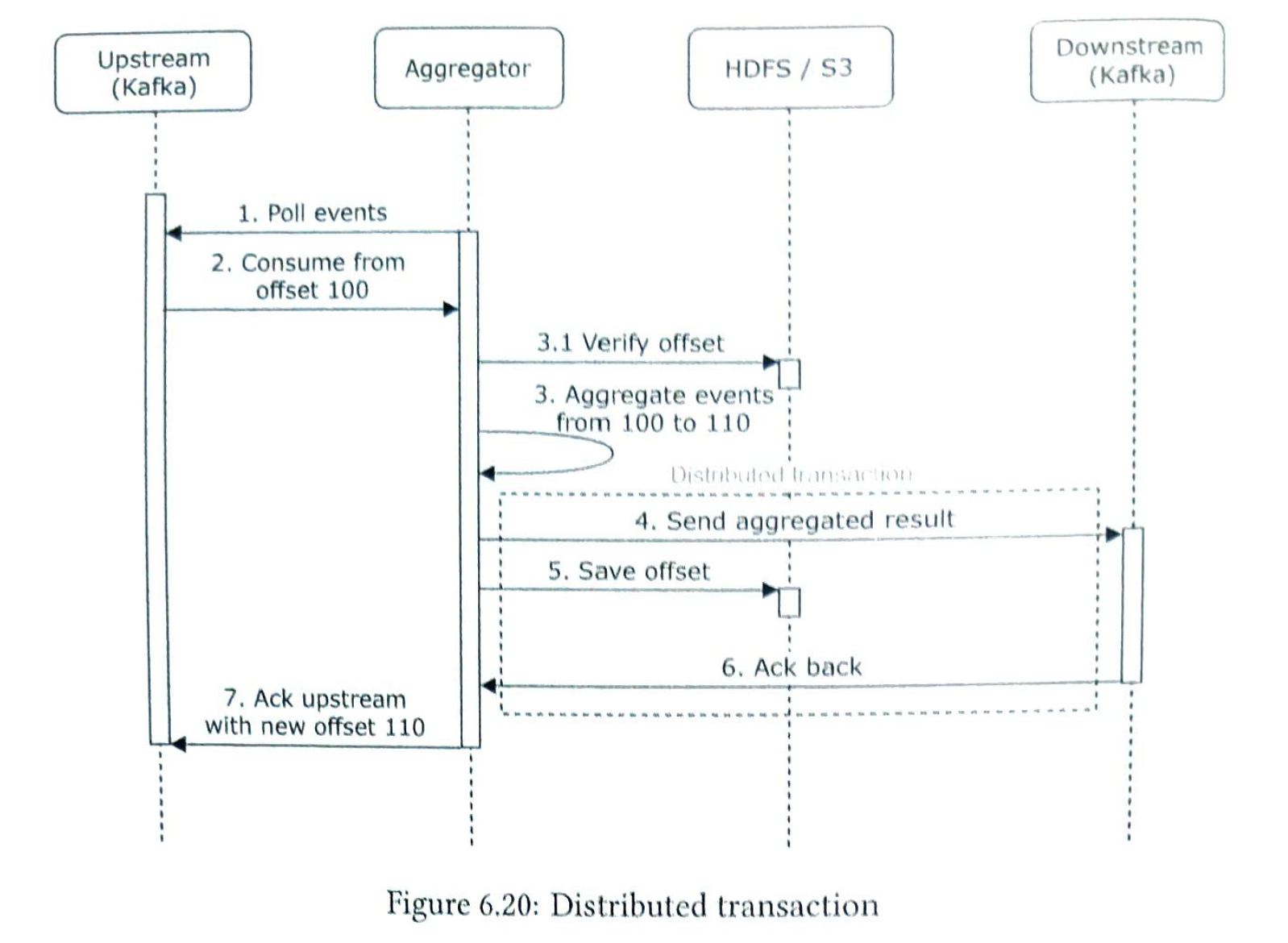
Q1 If we don't use a message q. when the traffic is heavy, aggregation service would shut down. Decouple aggregation service and the write raw data service from a message q. {ad_id, click_timestamp, uers_id, ip, country}
Q2 {ad_id, click_minute, count}
Duplicate events can result to million dollars. So the delivery method is exactly-once.
We can save offset in s3 to avlod ack fails directly.
Scaibility. 1) producer: easy 2) consumer: hundred of consumers. rebalance during off-peak. 3) brokers: it is better to pre-allocate enough partitions. |
| Raw data db |
write heavy. Cassandra or InfluxDB {ad_id, click_timestamp, uers_id, ip, country} |
| Aggregation db |
write heavy. {ad_id, click_minute, filter_id, count} |
| Aggregation service |
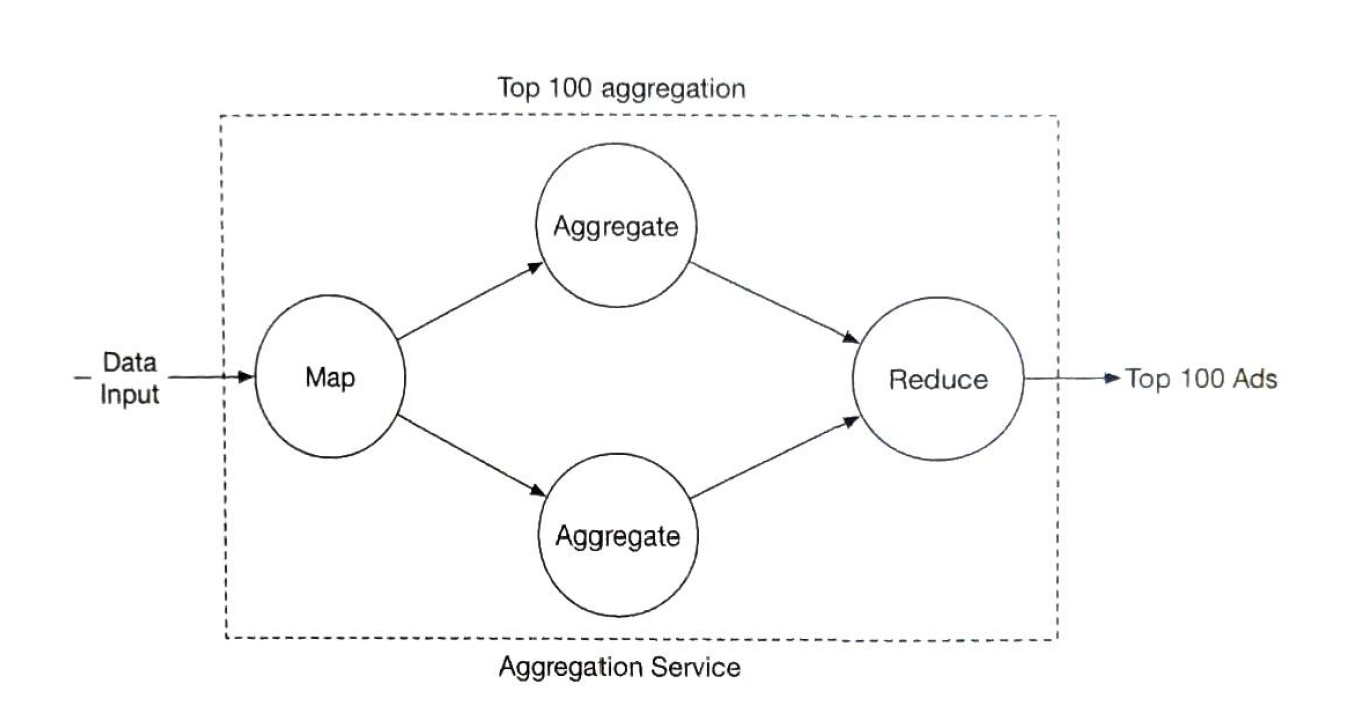
We need calculate metrics and normarise raw data so wo don't save raw data. Map node
We need map nodes because kafka may send the same ad_id to different partitions.
Aggregation Node Partition different result to different node. It is a part of reduce service
Reduce Node
We use event_ts. It is more important for business analysis. We use watermark (extended window) to handle data latency. It is a tradeoff. long watermark more accurate but more latency time
Aggregation window 4 windows. sliding (hopping), tumbling(fixed), session. we use tumbling.
Scale: Deploy aggregation service on Apache Hadoop Yarn. It is easy to add computing resources.
Hotspot: Allocate more resources to the aggregation calculation.
Fault tolerance We can use a snapshot if a node is down. If there is no snapshot we replay aggregation from kafka.
Monitoring:
|
| Batching vs Streaming |
We use both. Streaming for aggragation calculation. Batching for storing histrocal data.
Two architecture type. Lambda vs Kappa. Lambda
Two layers. Kappa
Only one layer. We choose Kappa |
| recalculation service. |
It reuses the aggregation service. But use raw db. |
| Reconcilition service. |
It is to check the reult between raw data and aggregation data |
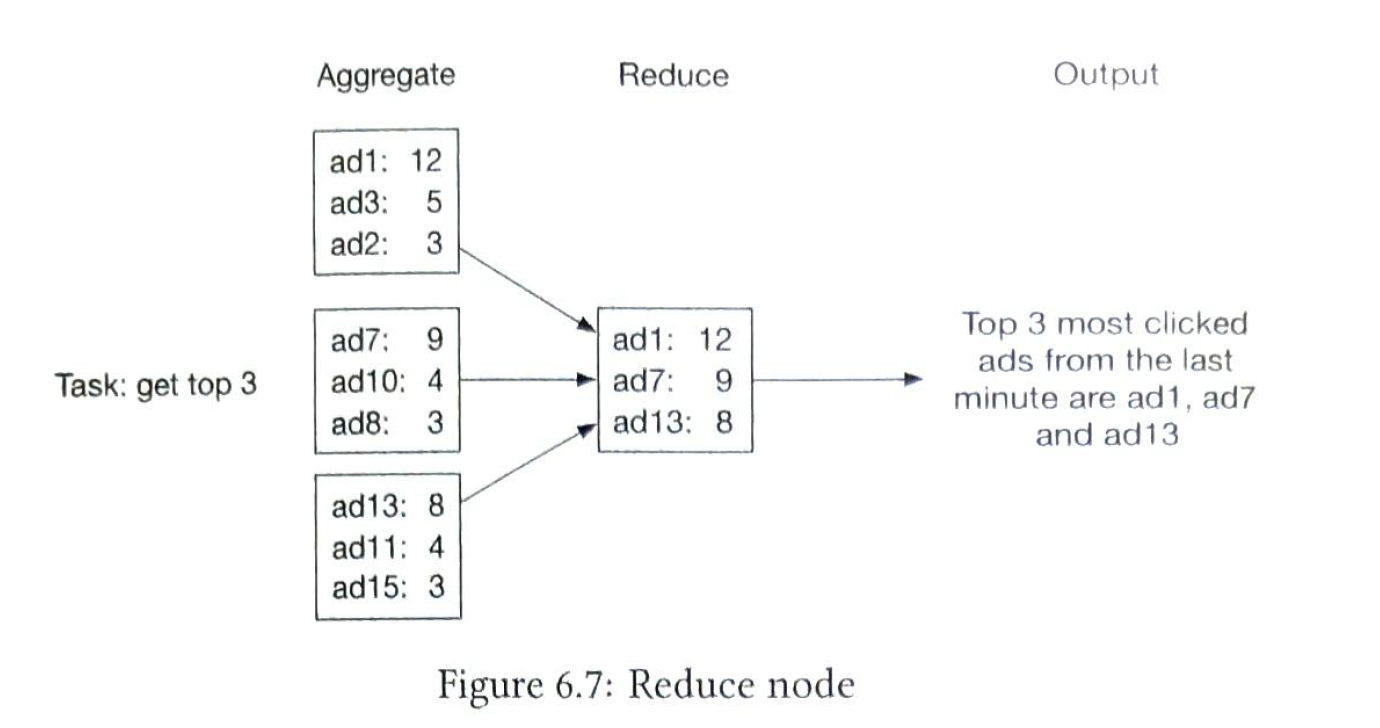
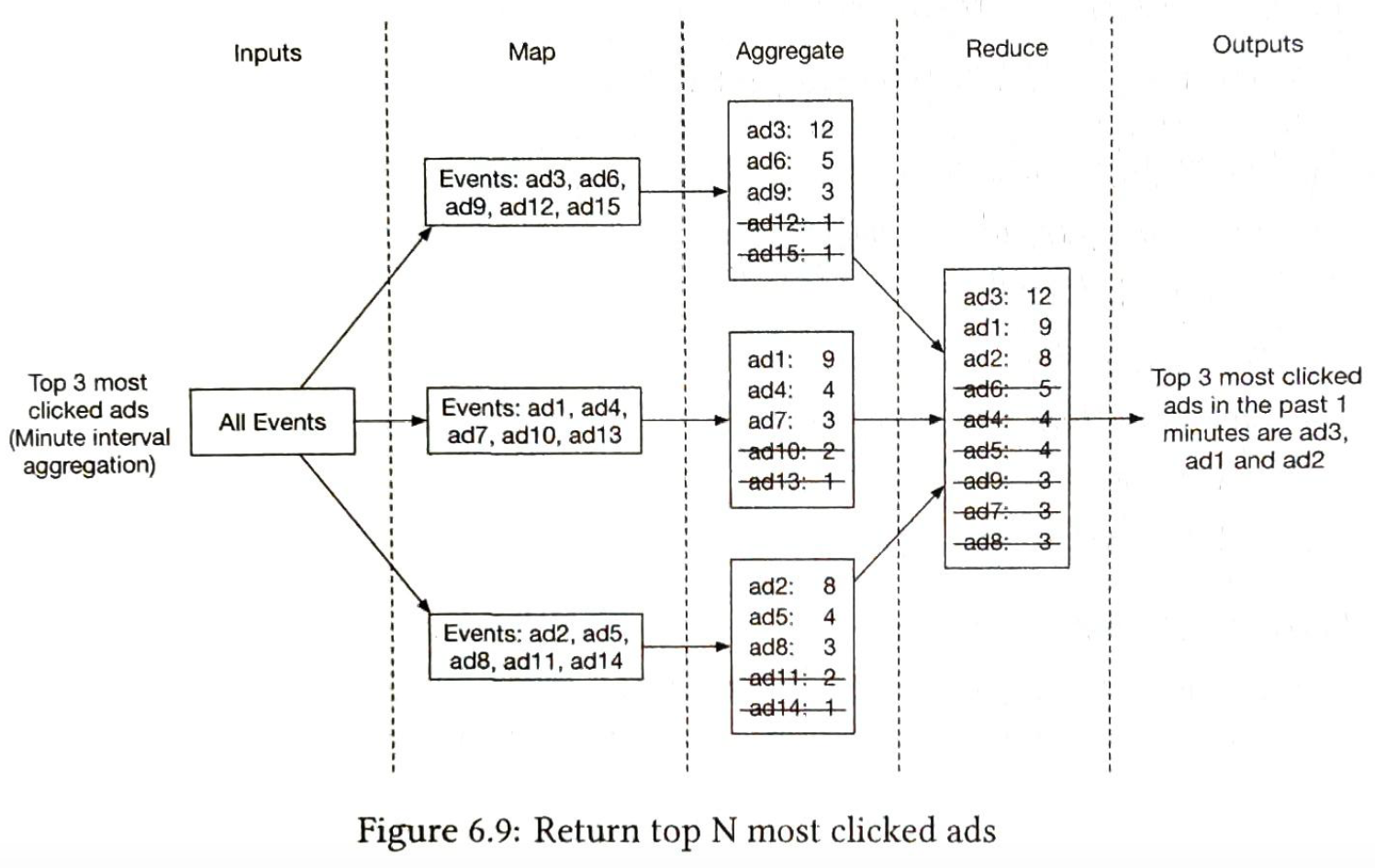

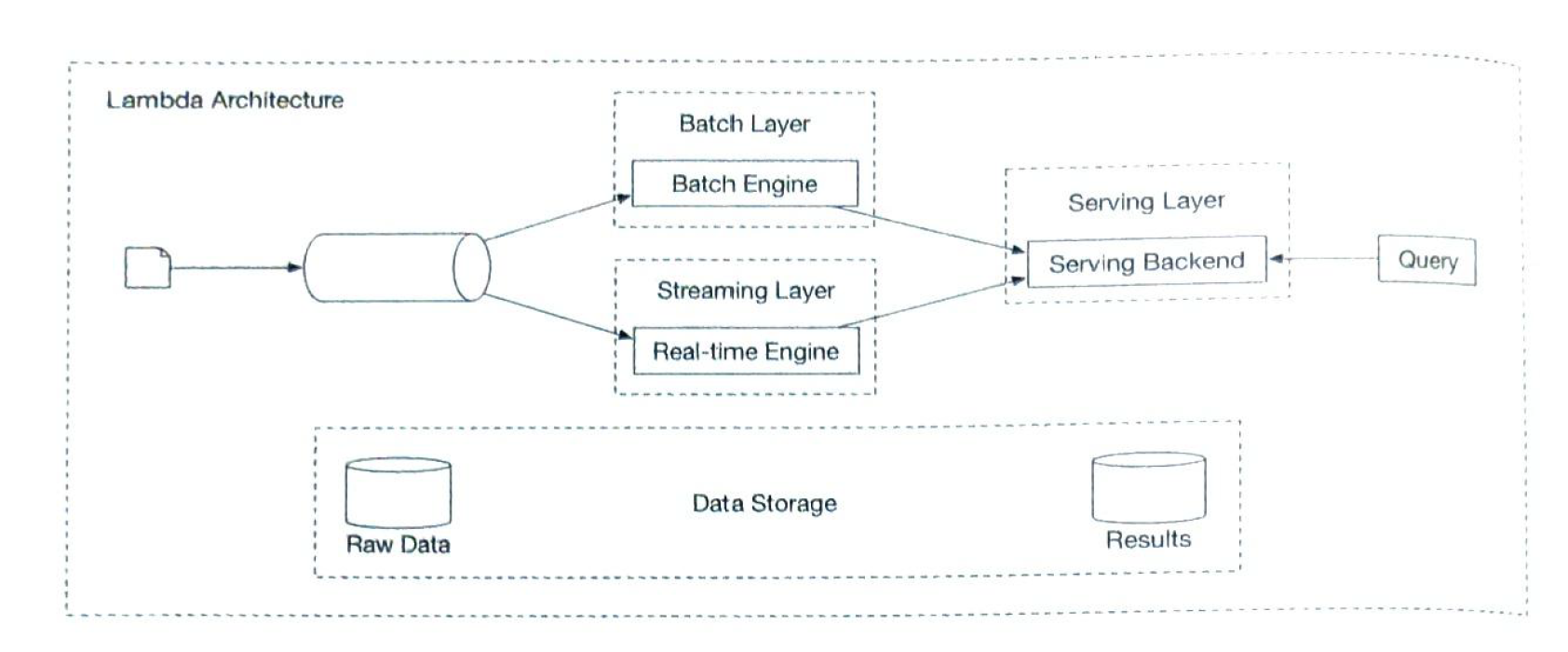
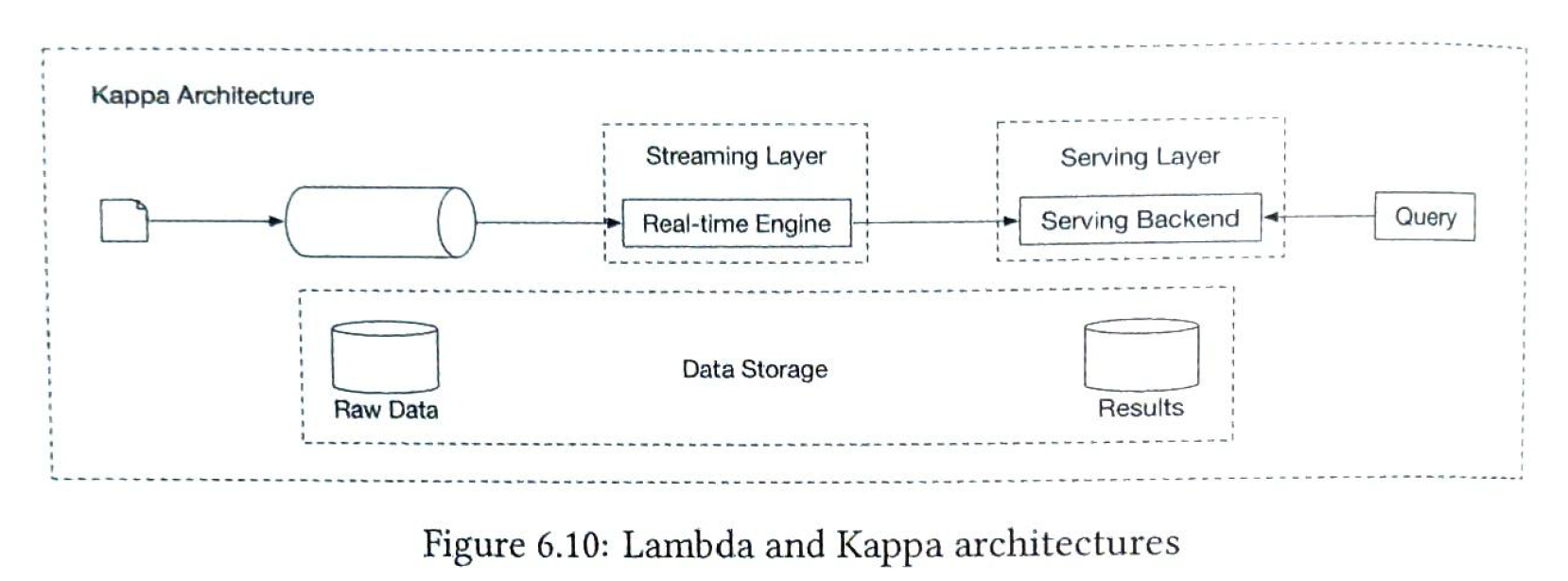
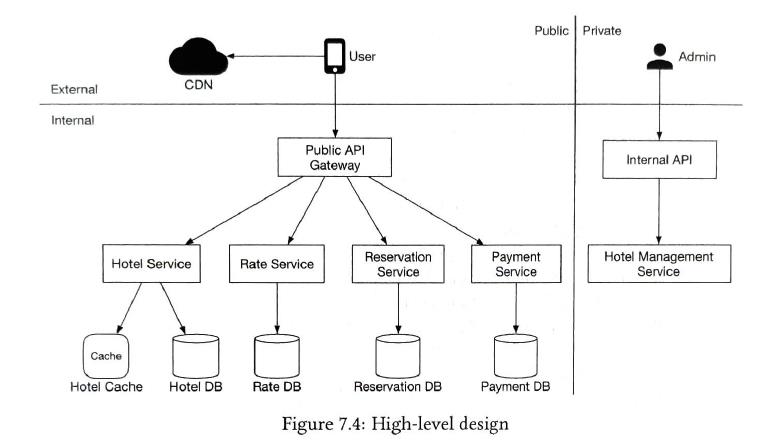
7 Hotel Reservation System
also the same topics of ticket booking system
1) requirements
| functional | non-functional |
| show the hotel-related pages | support high concurrency during some peak season. some popular hotels may have a lot of customers trying to book the same room |
| show the room-related detail page | moderate latency |
| reserve a room | |
| admin pnel to add/remove/update hotel or room info | |
| support the overbooking feature |
2) back-of-the-envelope estimation
| hotels and rooms | 5000 hotels and 1 million rooms |
| rooms occupied and average stay duration | 70% of the rooms are occupied and duration is 3 days |
| daily reservation | 1 m * 70% / 3 = 240k |
| reservation per second | 240 k / 10**5 = 3 rooms |
| QPS |
10% users reach the next step. we can work backward to see other QPS
|
3)design
| API |
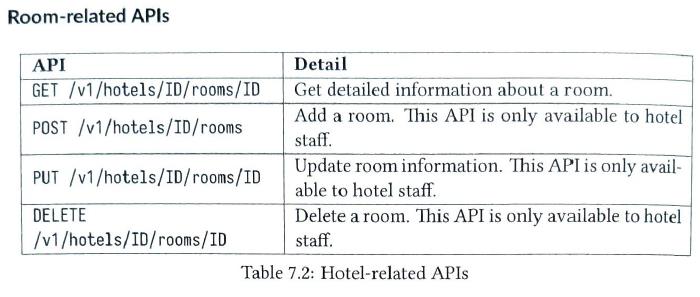
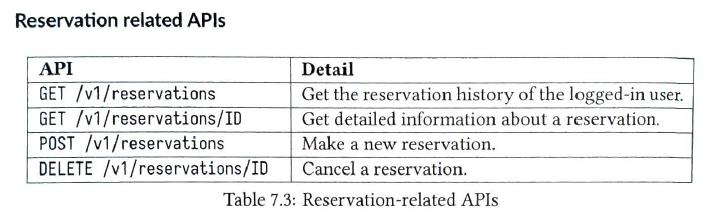
They are all RESTful APIs Hotel-related APIs
|
| data model |
we choose relational db. Because it is a read-heavy service. And a relational database provides ACID guarantees. ACID properties are important for a reservation system. 1) hotel db hotel_id, name, address, location 2) room db room_id, room_type_id, floor, number, hotel_id, name, is_available 3) rate_db hotel_id, dt, rate 4) reservation reservation_id, hotel_id, room_type_id, start_date, end_date, status, guest_id 5) room_type_inventory hotel_id, room_type_id, date, total_inventory, total_reserved
status: canceled, paid -> refunded, rejected.
If the reservation data is too large for a single database, what would you do?
when QPS is high, assume it is 30k, after database sharding, let's say it's 16 shards. Each shard handles 30k / 16 = 1.875QPS. |
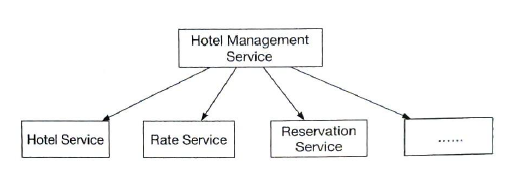
| hotel management |
It is only for hotel staff. Those are microservices, for example RPC, etc. |
| hotel reservation |
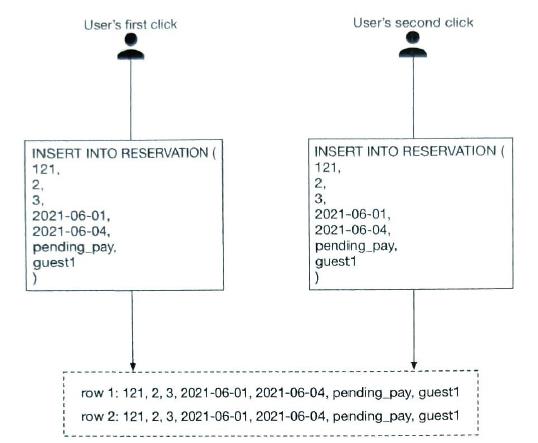
concurreny issues 1)The same user clicks on the book button multiple times.
solution: idempotent APIs. Add an idempotency key in the reservation API request.
In this service design we can use reservation_id as an idenpotency key. So reservation_id is a primary key, it can not insert into db twice.
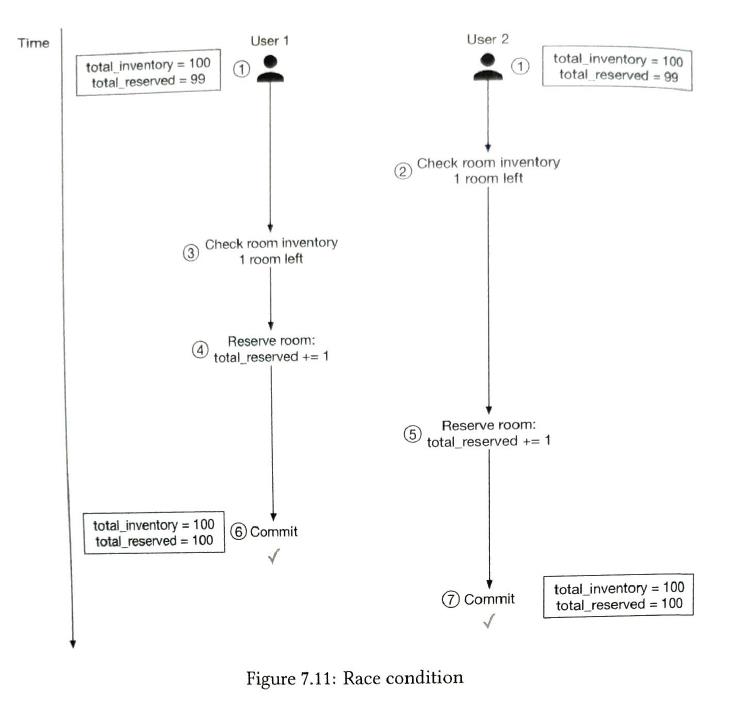
2) Multiple users try to book the same room at the same time
SQL has Two parts:
According ACID, we the isolation level is not serializable. U1 anbd U2 can book the room at the same time. So we need locking mechanism Solutions:
If scalability is an issue, we can add a cache layer. It can improve the performance. But maintaining data consistency between the database and cache is hard.
If reservation service and inventory service are from microservices. It might cause inconsistency. They have their db. If one reservation fails, inventory has to roll back.
Solution
|

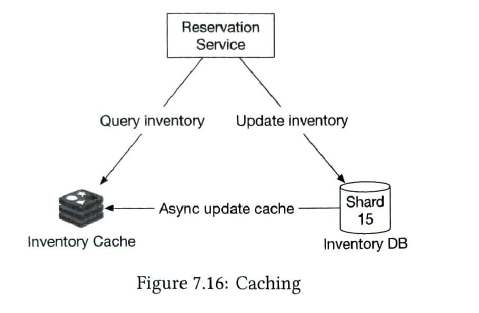

7 Distributed Email Service
1) requirements
| Functional | Non-functional |
| Authentication |
Reliability not lose email |
| Send and receive emails |
Availability Email and user data should be automatically replicated across multiple nodes |
| Fetch all emails |
Scalability As the number of users grows. The system should be able to handle the increasing number of users and emails |
| Filter emails by read and unread status |
Flexibility and extensibility Easy to add new components |
| Search emails by subjet, sender, and body | |
| Anti-spam and anti-virus |
2) Back-of-the-envelope estimation
| users | 1 billion |
| QPS |
100k.
|
| number of emails a person receives |
40. size of an emial is 50kb |
| storage of emails for 1 year | 730PB |
| storage for attachments in 1 year |
1460pb
|
3) design
traditional mail servers
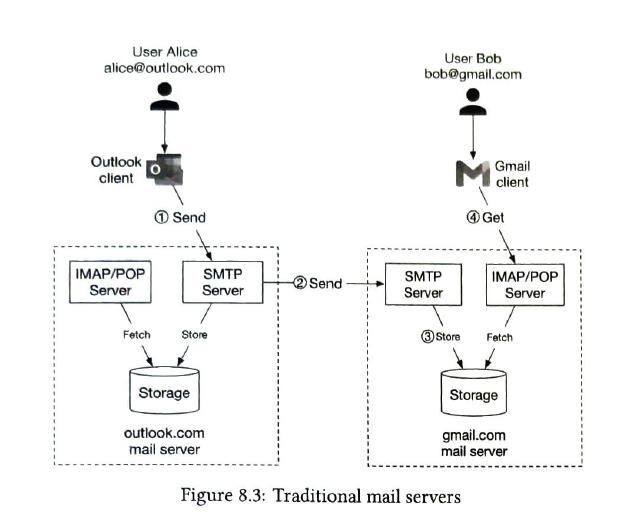
in a traditional mail server, emails were stored in local file directories and each email was stored in s separate file with a unique name. Each user maintained a user directory. It works well when the user base was small. Disk I/O becomes a bottleneck.
In this design, we focus on HTTP protocal, which we build a web-based distributed email service
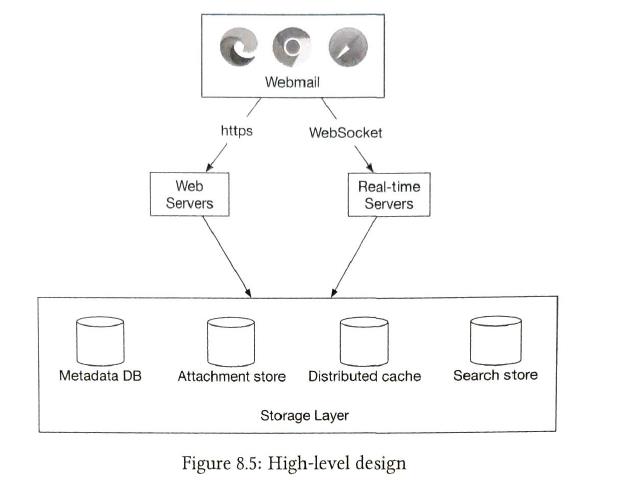
| Email protocols |
1) SMTP send emails 2) POP receive and download emails. Once emails are downloaded on your phone. They are deleted from server. 3) IMAP receive emails. not deleted. So you can access emails from different devices. 4) HTTPS. not used exluding web emails. |
| API |
GET /v1/folders/{:folder_id}/messages.
GET /v1/messages/{:message_id}
Response: {user_id, from, to, subject, body, is_read} |
| web servers |
all email API reqeusts are go through web servers.
Email sender reputation.
Email authentication
|
| real-time servers |
pushing new emial updates to clints in real-time.
|
| metadata database |
mail subject, body, from, weto. relational db is not a good choice.
NoSql
Custom Design (good choice)
support queries 1) get all folders of a user {user_id, folder_id, folder_name) one user_id is in one partiton_id
2) display all emials for a specific folder {user_id, folder_id, email_id, from, subject, preview, is_read}
3) create / delete / get a specific email {user_id, emial_id, from, to, subject, body, attachments} {email_id, filename, url}
4) fetch all read or unread emails divide emails to read_emails and unread_emails
distributed databases that rely on replication for high availability must take a fundamental trade-off between consistency and availability. In the event of a failover, the mailbox isn't accessible by clients, so their sync / update operation is paused until failover ends. It must make a fundamental take-off
Users communicate with a mail server that is physically closer to them in the network topology..
|
| attachment store | s3. we can not use NoSQL. because it's hard tu put attachments in db like Cassandra |
| distributted cache | caching recent emails in memory significantly imroves the load time. |
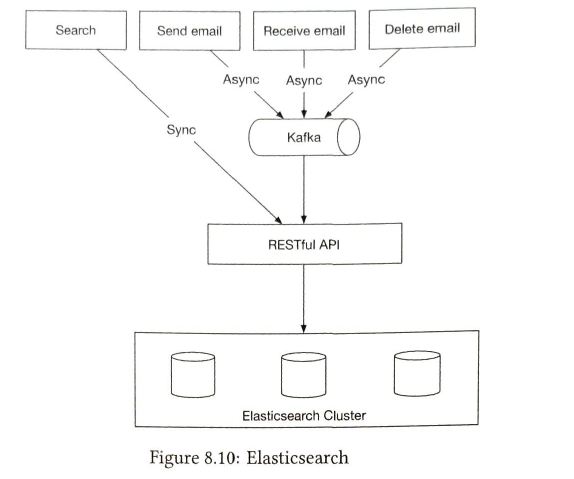
| search store |
supports full-text searches. document store.
serch has quite different characteristics compared to google search
Solution Elasticsearch and native search embedded in the database. 1) Elasticsearch
one challenge of adding elasticsearch is to keep our primary email store in sync with it.
2) custom search solution The main bottleneck of the index server is usually disk I/O. To support an email system at Gamil or OUtllok scale, it might be a good idea to have a native search embeded in the database. |
| Email sending flow | 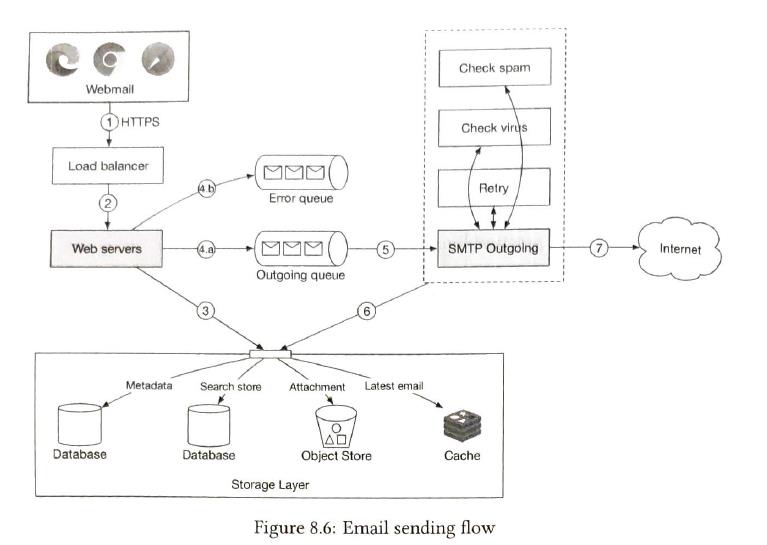
|
| Email receiving flow | 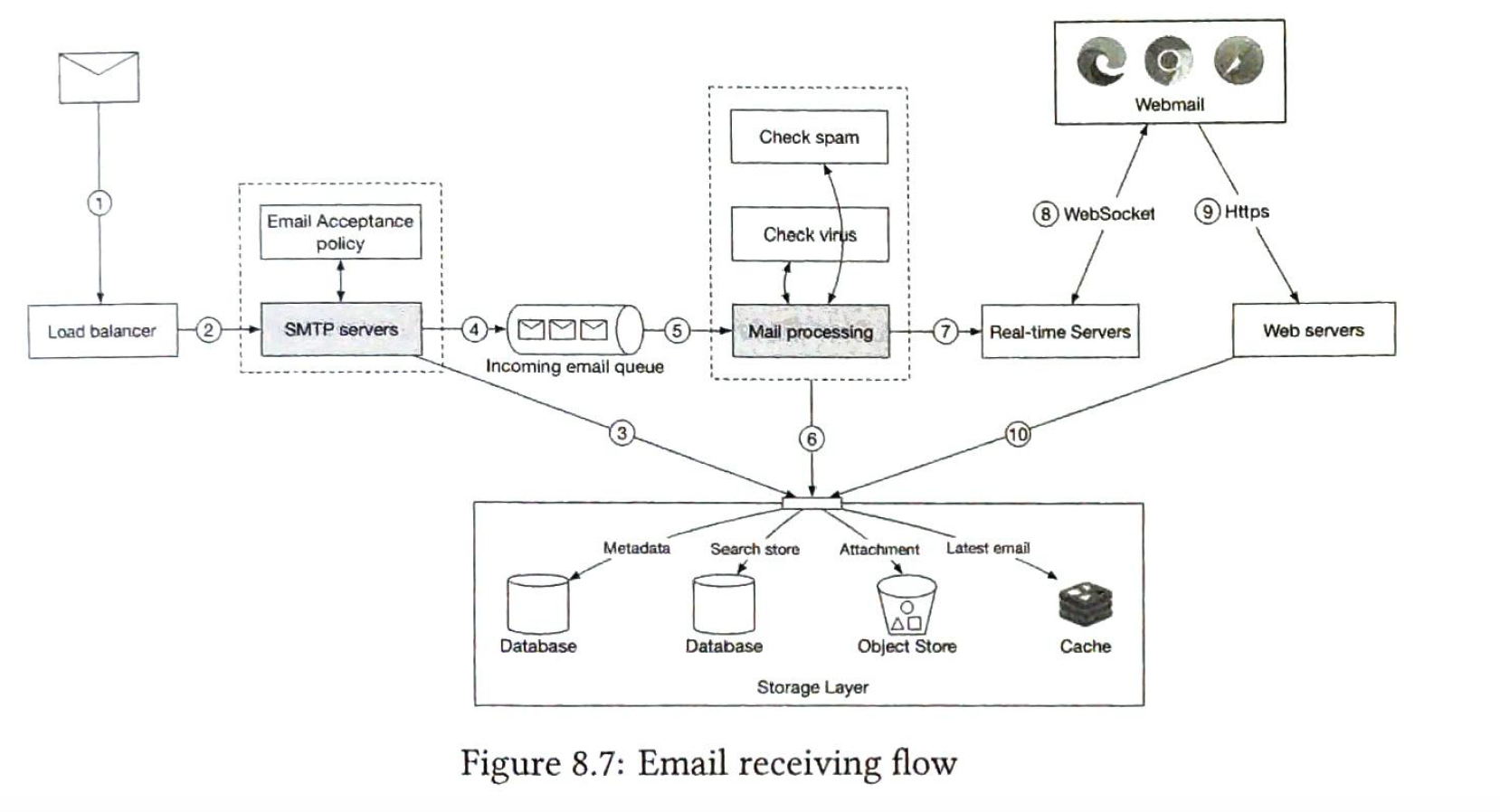
|
9 S3-like Object Storage
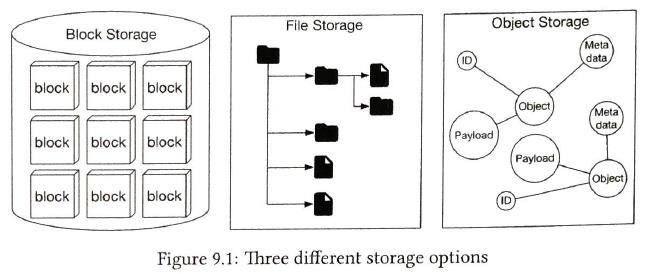
storage system fall into three broad categories
- Block storage. ( common storage devices are all considered as block storage)
- File storage. It is built on top of block storage. It provides a higher-level abstraction to make it easier to handle files and directories
- Object storage. It is mainly used for archival and backup. It sacrifice performance for high durability, vast scale, and low cost.
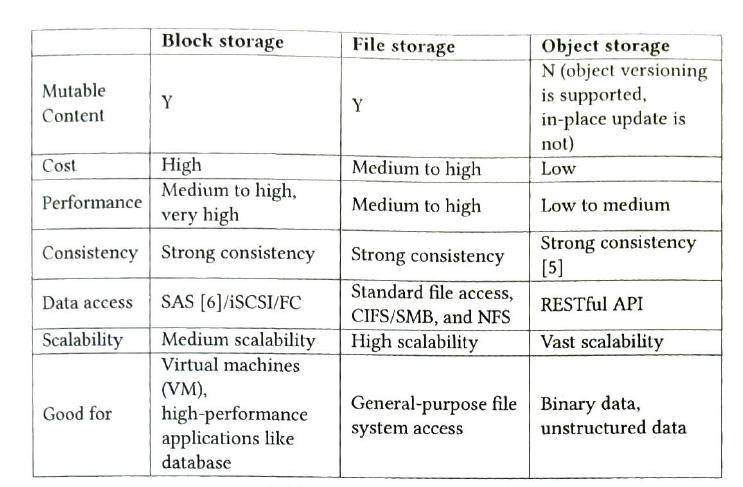
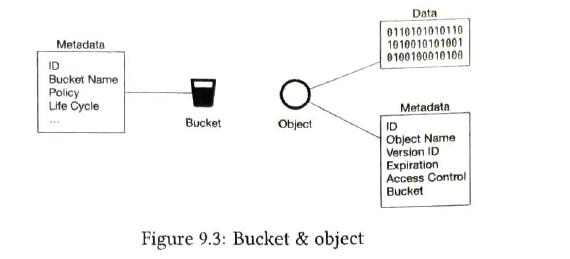
- Bucket. A logical container for objects. The bucket name is globally unique. To upload data to S3, we must first create a bucket
- Object. An individual piece of data we store in a bucket. Objects can be any swquence of bytes we want to store.
- Versionaing. A feature that keeps multiple variants of an object in the same bucket. This feature enables users to recover objects that are deleted or overwritten by accident.
- Uniform Resource Identifier(URI). The object storage provides RESTful APIs to access its resources. It is unique
- Service-level agreement (SLA). A service-level agreement is a contract between a service provider and a client.
One of the main differences between object storage and the other two types of storage systems is that the objects stored inside of object storage are immutable. We can delete and replace them. But we cannot make incremental changes.
1) requirements
| Functional | Non-functional |
| Bucket creation | 100 PB of data / one year |
| Object uploading and downloading | Data durability is 6 nines. (99.9999%) |
| Object versioning | Service availability is 4 nines. |
| Listing objects in a bucket. It's mililar to the aws s3 ls command | Reduce costs while maintaining a high degree of reliability and performance |
2) back-of-the envelope estimation
| Objects |
numbers of objs = 10**11 * 0.4 / (0.2 * 0.5 + 0.6 * 32 + 0.2 * 200) = 0.68 billion objects
metadata. 1KB each object, we need 0.68TB |
3) design
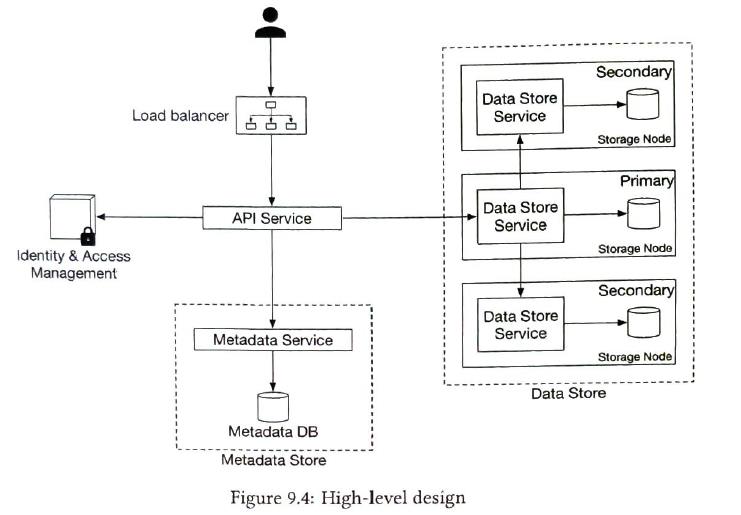
| API Service |
We could use object URI to retrieve object data. The object URI is the key and object data is value. Request: GET /bucket1/object1.txt HTTP/1.1 Response: HTTP/1.1 200 OK Content-length: 4567
It is stateless so it can be horizontally scaled.
For example when we upload a file to s3, steps are
|
| data store |
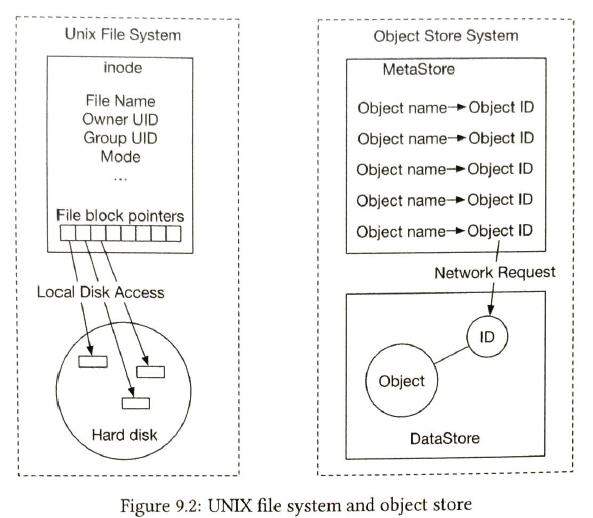
Similar to unix file system
All data-related operations are based on object ID.
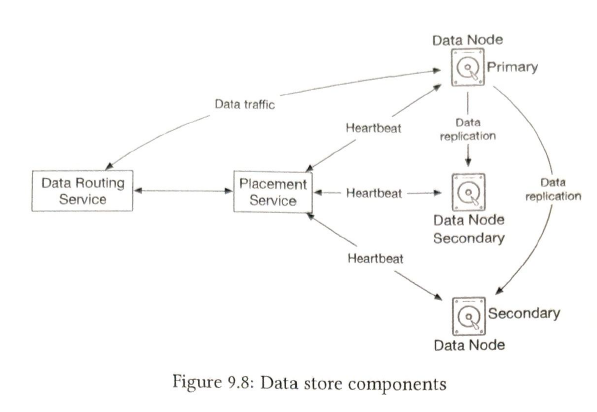
1 Data routing service
2 Placement service
3 Data routing service
4 Placement service
5 Data node
How data persisted in the data node?
Small files 1) How data is organized? If too many small size files:
Storing mall objects as individual files does not work well in practice. To Address this issues, we can merge many small objects into a larger file.It is lke a WAL. Usually it is appended to an existing read-write file. when the rw file reaches it's capacity threshould, the rw file is marked as read-only. 2) lookup object deploys relational database to support look up. read-heavy so a relational database is a good choice. Mapping data is isolated within each data node. So we could simply deploy a simple relational database on each data node. object mapping table: {object id, file_name, start_offset, object_size} |
| Identity and access management | The central place to handle authentication, authorization, and access control. |
| Metadata store |
Objects and metadata stores are just logical components, and there are different ways to implement them. |
| Durability |
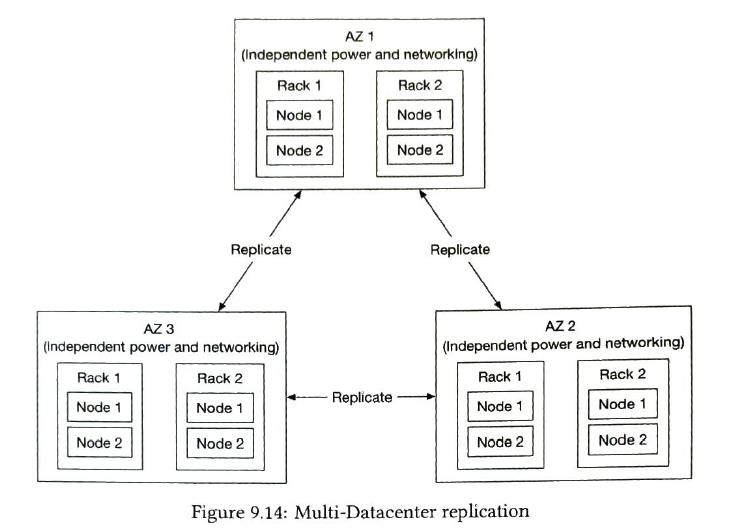
Hardware failure
Domain failure
write performance is good. Read performance is good. less compute resource
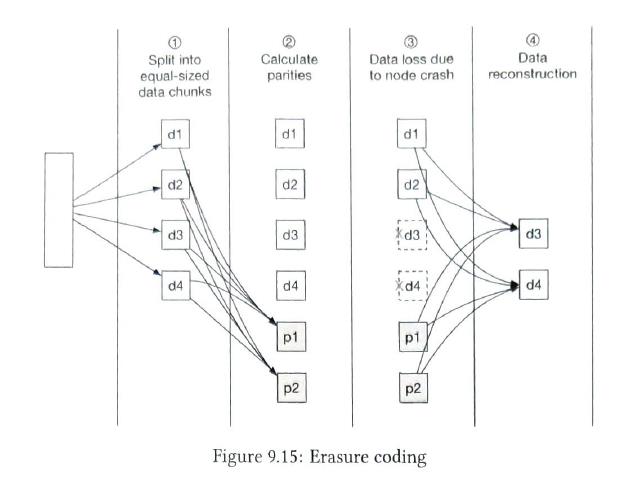
Other option. Erasure coding.
Eaxample matrix is fixed. [1,3,5] [4,6,7] we have 3 nodes, d1, d2,d3. result in p1, p2. so we can recover data when we lost 2 nodes. more duability, more storage-efficiency |
| Scalability |
1) Bucket table
That means we need 10 GB of storage space. 10 * 1m * 1kb = 10GB. Storage is not a problem. But a single db server doesn't have enough CPU or network bandwidth to handle requests. So we can spread the read load among multiple database replicas.
2) object table shard table accroding <bucket_name, object_name>.
3) distributed databases query to get objects on different partition is complicated. select * from metadata where bucket_id = "123" and object_name like 'a/b/%' order by object_name offset 10 limit 10; we have to track a lot of offsets in all shards.
we can support object listing with sub-optimal performance. we can denormalize the listing data into a separate table sharded by bucket. |
| Object versioning | metadata has a column named version |
| upload large size object |
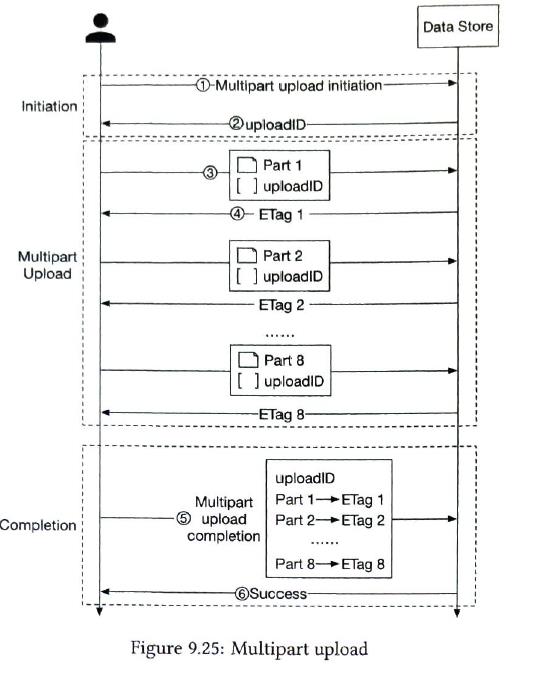
slice a large object into smaller parts and upload them independently
|
| garbage collection |
targets
The garbage collector does not remove objects from the data store, right away. Deleted objects will periodically cleaned up with a comapction mechanism. |

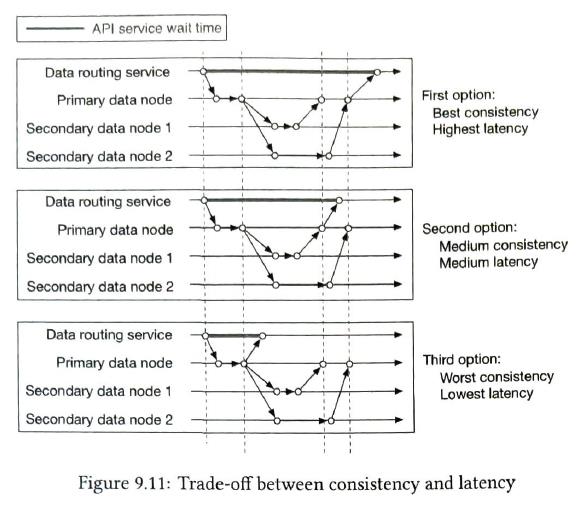
10 Real-time Gaming leaderboad
1) requirements
| Functional | Non-functional |
| display top 10 players on the leaderboard | real-time update on scores |
| show a user's specific rank | score update is reflected on the leaderboard in real-time |
| display palyers who are four places above and below the desired user | general scalability, availability, and reliability requirements |
2) back-of-the-envelope estimation
| DAU |
5 million 5 million / 10 **5 = 50 users / per_second. a peak load 500 |
3) Design
| API Design | We can build this service by ourselves or on cloud (serverless). |
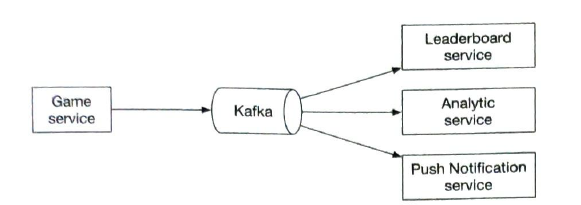
| Message Q |
If there are other needs apart from Leaderboard servce. We can use a message q.
|
| Data models |
1) relational database solution A rank operation over million users is not acceptable because this operation is not performant. select row_number() over(order by points desc) from db
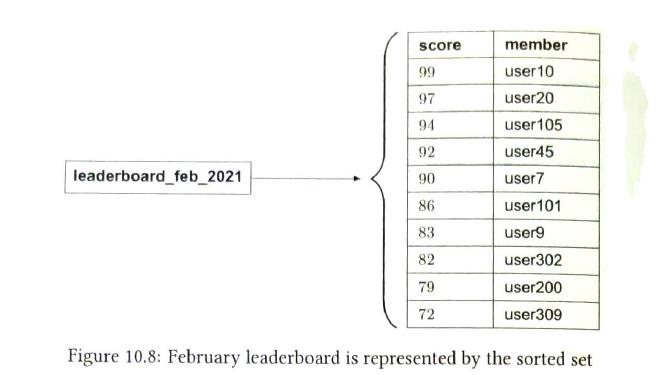
2) redis Redis provides a potential solution to our proble. Redis has a specific data type called sorted sets that are ideal for solving leaderboard system design problems.
some operations. update, query and range query
Storage requirement:
one redis server is enough more than enough to hold the data peak qps 2500 / s. one server is enough to serve for the query.
when the redis server fails, we can restore the service by relational db
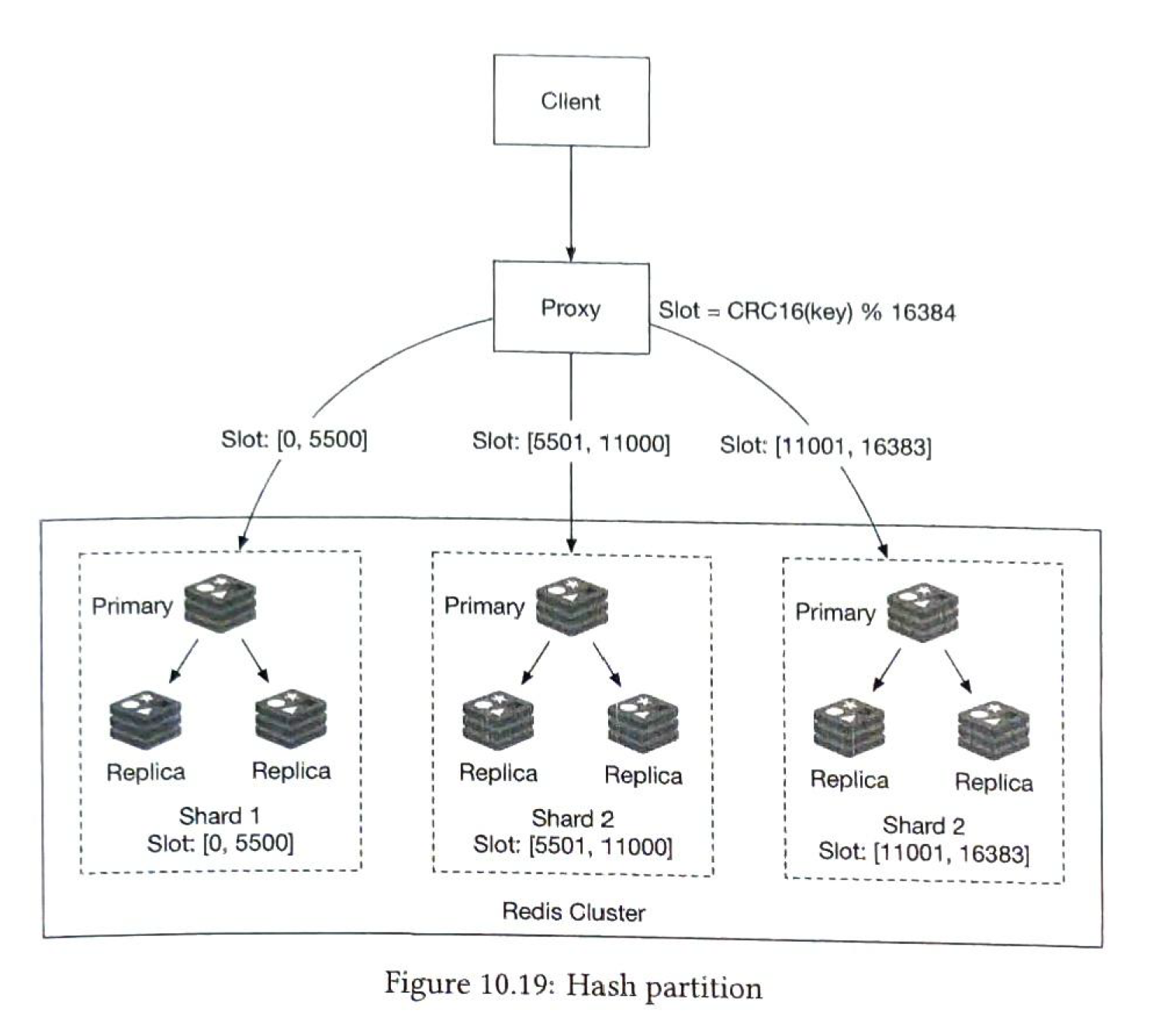
Scaling the server 1) asumtion
Data sharding.
by score range, retriving is simple. but we need to relocate the data.
by hash.
Compute the top 10 users.
This approach has some limitation. we have to wait for the lowest node.
Sizing the node allocate twice the amount of memory for write-heavy applications.
3) Nosql we can use cassandra, etc. |
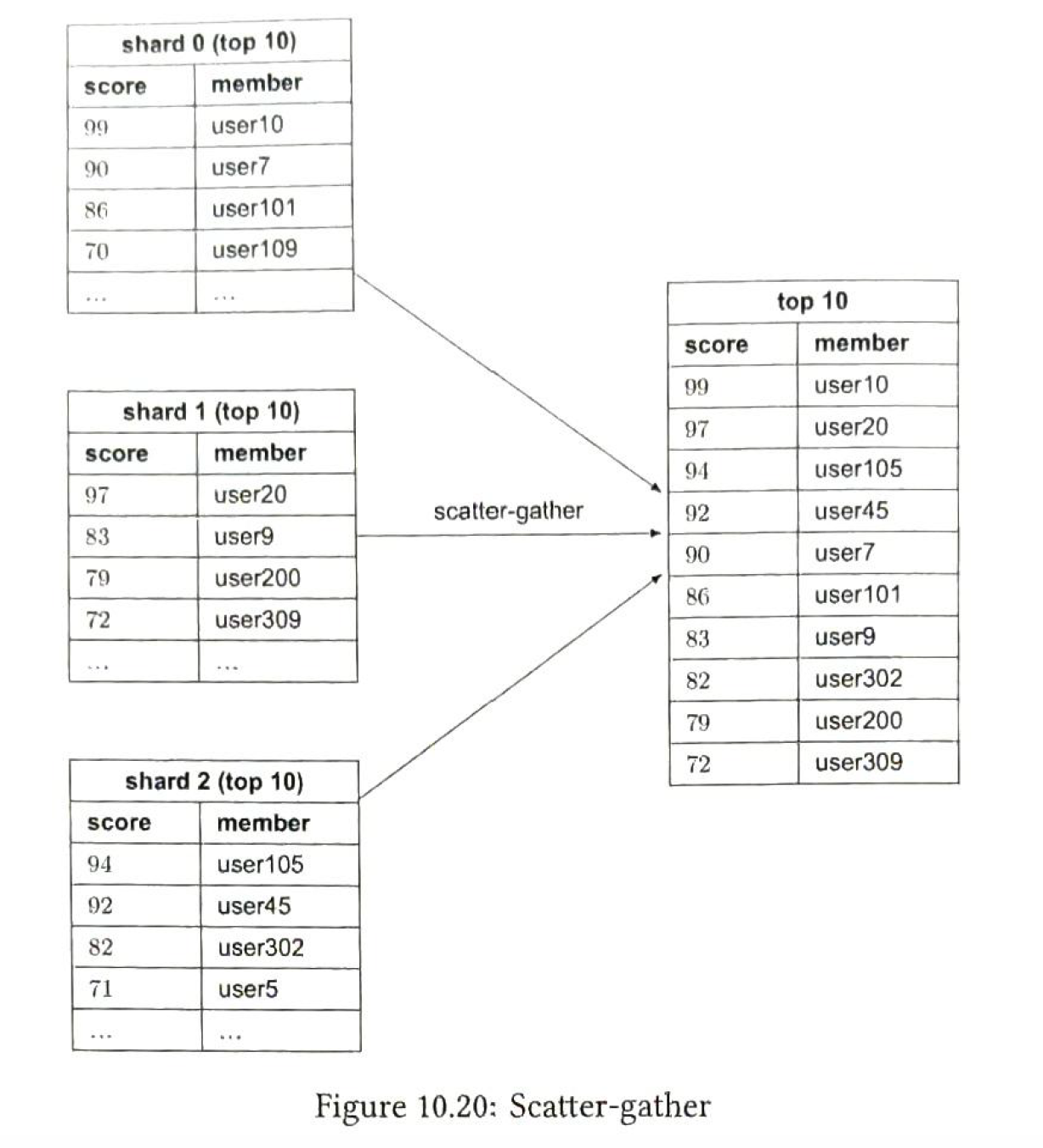
11. Payment Service
1) requirements
| Functional | Non-functional |
|
Pay-in flow: payment receives money from cutomers on behalf of sellers |
Reliability and fault tolerance. Failed payments need to be carefully handled. |
|
Pay-out flow: payment system sends money to sellers around the world |
A reconcliation process between internal and extern services. |
2) back of the envolupe estimation
| DAU | 1 million |
| QPS | 1 million / 10**5 = 10 |
3) design
pay-in flow
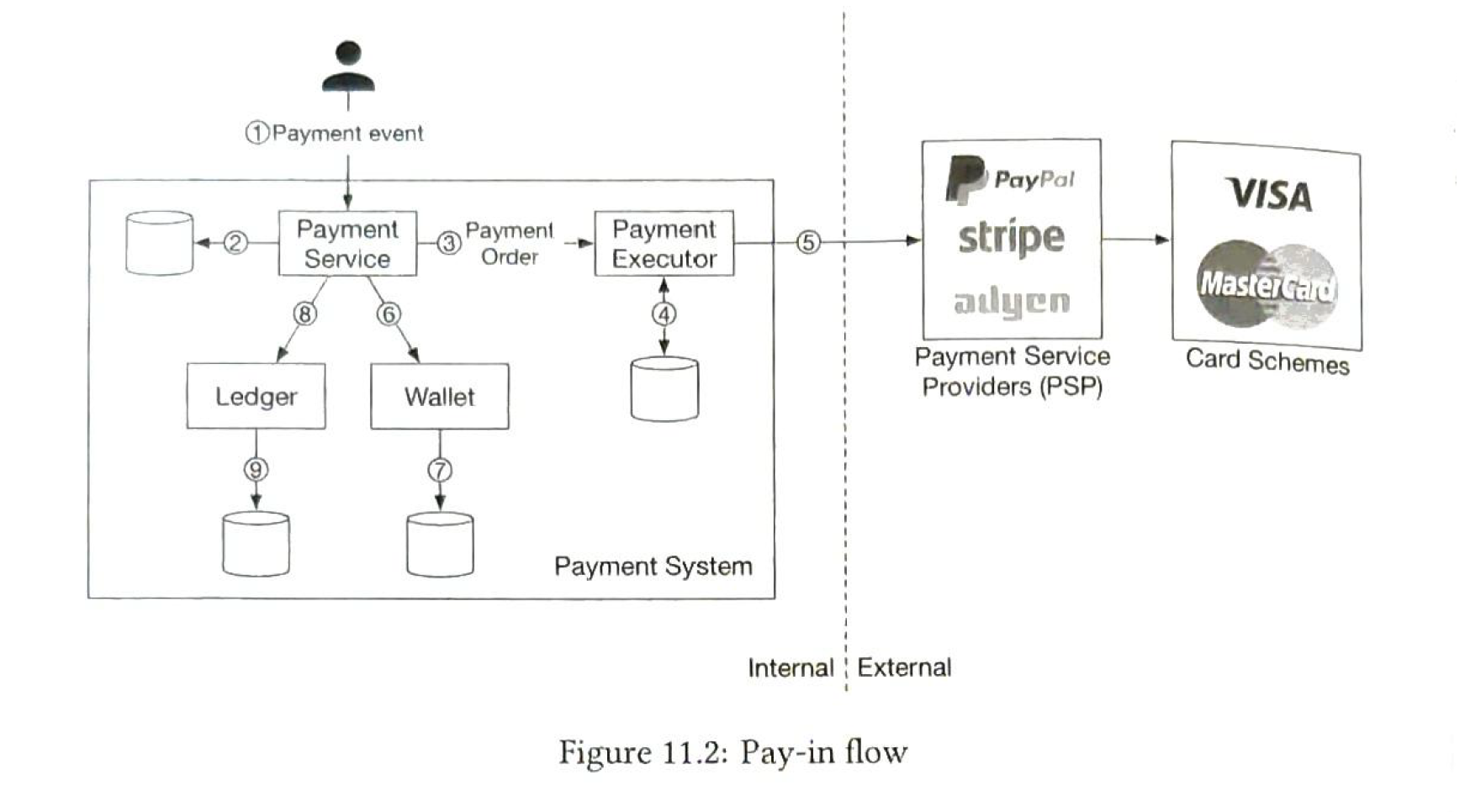
- a user clicks "place order". a payment event is generated
- payment service stores the payment event in db
- sometimes an event may have several payment orders, it calls payment executor for each payment order
- payment executor stores a payment order in db
- payment executor calls payment service
- if payment executor successfully calls payment service, payment service updates the wallet db
- after the wallet service successfuly updating the db, the payment service calls Ledger to update it
- the ledger appends the new ledger information to the db
| Payment service |
accepts payment events from users and coordinates the payment process. First thing it usually does is a risk check |
| Payment executor | Execute a single payment order via a Payment Service Provider(psp). A payment event may contain serveral payment orders |
| PSP |
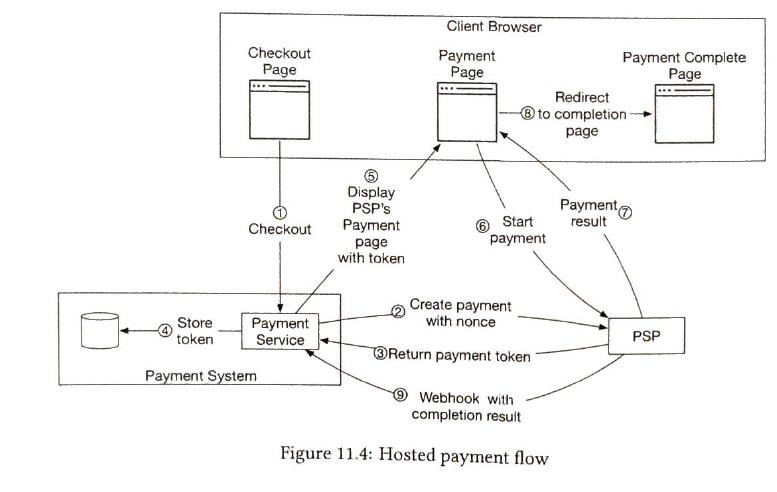
moves money from A to B. If a company can not store personal information like credit card, etc, it can choose PSP service. PSP provides a hosted payment page to collect card payment details. Hosted payment flow
When a payment is delayed. update status as PENDING, send payment service information. when the payment is completed, update status. |
| card schemes | organizations that process credit card operations |
| Ledger |
Keeps a financial record of the payment transaction. Record the debit from user and credit to the seller. Double-entry ledger system (复式记账) |
| Wallet | keeps the account balance of the merchant |
| API |
POST/v1/payments {buyer_info, checkout_id, credit_card_info, payments_orders}
GET/v1/payments{:id}
|
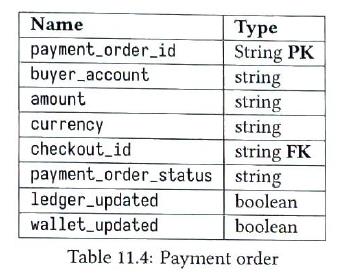
| Data Model |
We need mature db. We prefer a traditional relational database with ACID transaction support over NoSQL. 1) payment event table
2) payment order table
|
| Reconciliation | 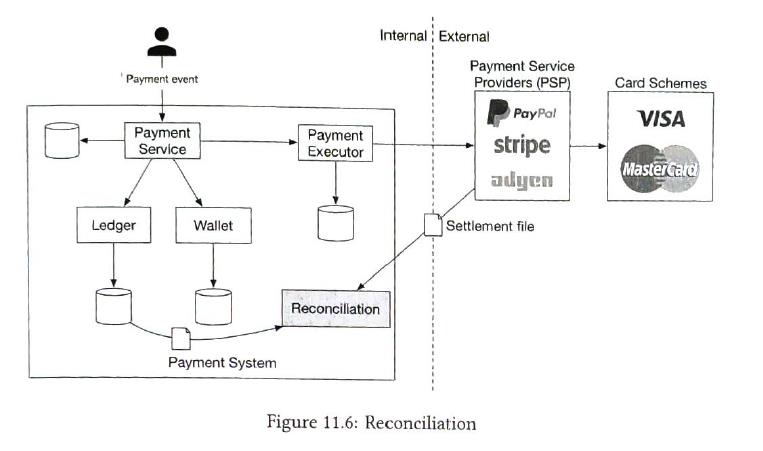
there is an ansynchronous step. But sometimes information may be lost. So reconciliation is a practice compares the states among the settlement file (from PSP) and the ledger system. To fix mismatches found during reconciliation, we usually rely on the finance team to perform manual adjustments. |
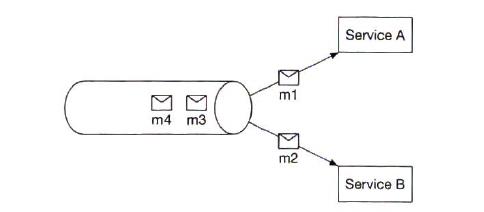
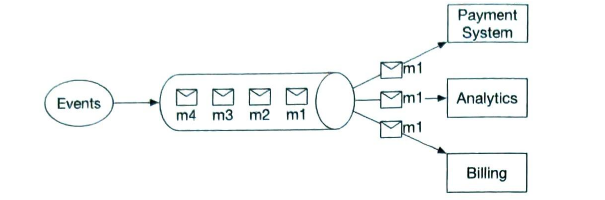
| Communication among internal services |
1) synchronous communication
2) asynchronous communication single receiver. once a message is processed, it is removed
multiple receivers
|
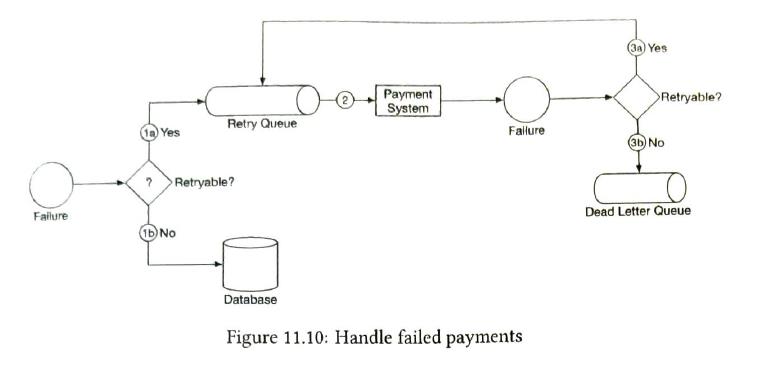
| handle failed payments |
dead letter q. it keeps the failed payment_order to analyse |
| exactly-once delivery |
one of the most serious problems a payment system can have is double charge a customer. exactly-once:
|
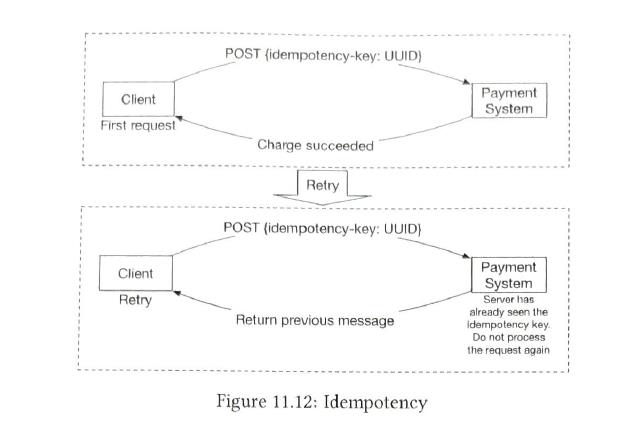
| consistency |
To ensure data consistency, idempotency and Reconciliation are techs we can use. Even if an external service supports idempotent APIs, reconciliation is still needed.
If data is replicated, replication lag could cause inconsistent data between the primary database and the replicas. There are generally tow options to solve this:
|

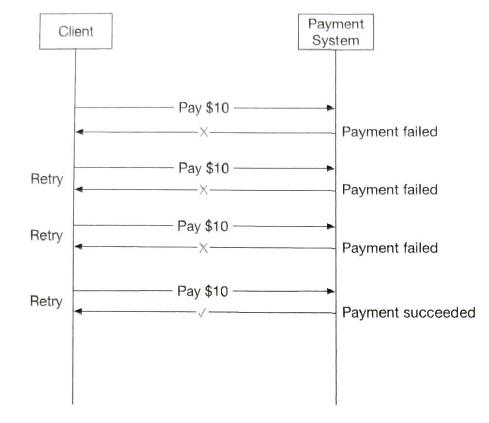
12 Digital wallet
1) requirements
- support balance transfer operation between two digital wallets
- support 1 million TPS
- reliability is at least 99.99%
- support transactions
- support reproducibility
2) estimation
| TPS | 1milliong / s |
| nodes |
each transaction has two operations.
relational db. 1000 TPS / node
total 2 million / tps 100 TPS / node -> 20k nodes 1k TPS / node -> 2k nodes 10 / node -> 200 nodes |
3) design
API:
POST/v1/wallets/balance_transfer
{from_account, to_account, amount, currency, transfer_id}
There are 3 solutions.
- in-memory,
- db-based distributed transaction solution
- event sourcing solution with reproducibility
1. In-memory of sharding solution
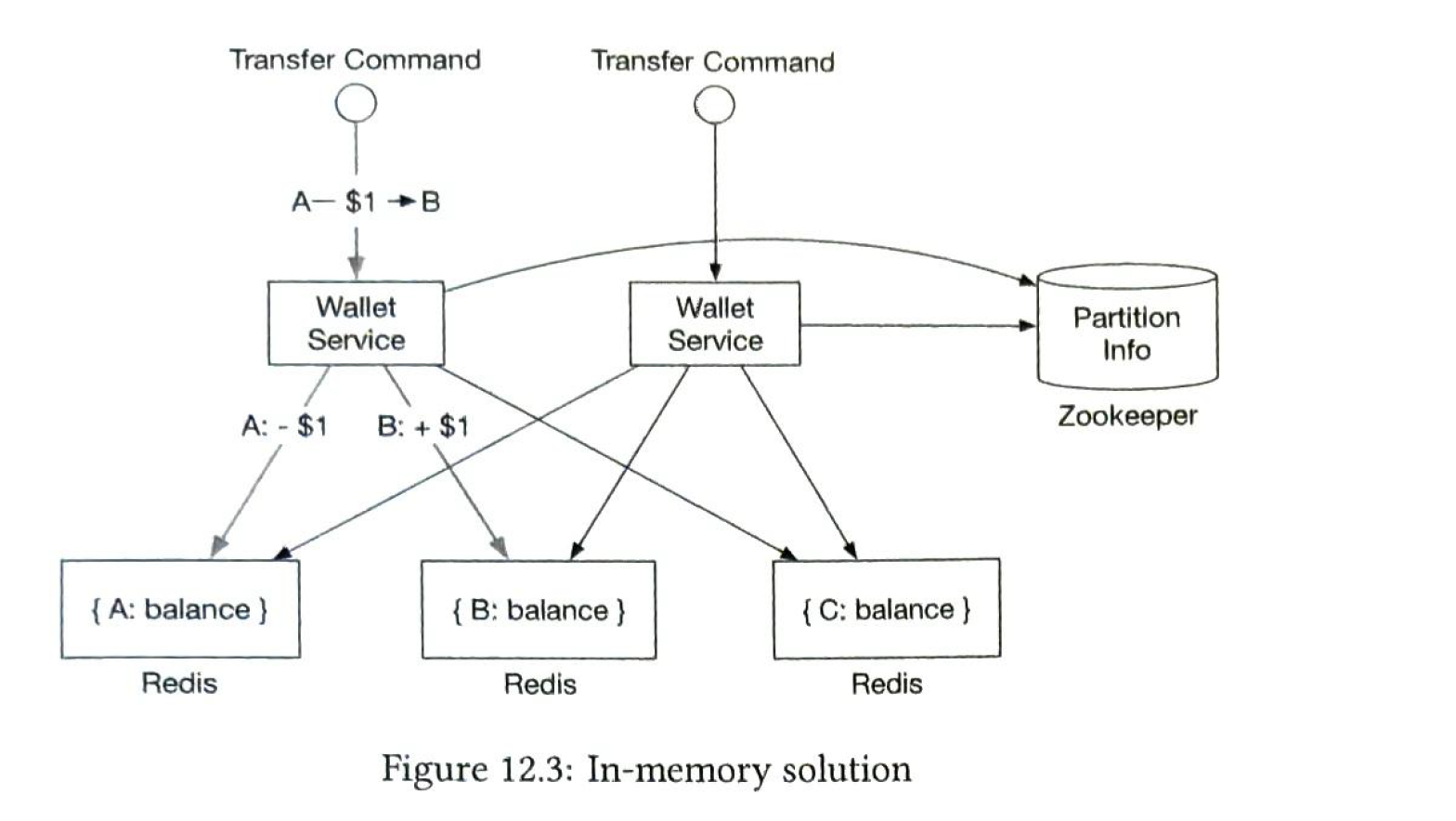
| Redis | If one node is failed, it may cause a incomplete transfer. The 2 updates (minus and add) must be an atomic transaction |
| Zookeeper |
storage of configuration maintain the sharding information |
2.1 Distributed transactions: 2pc
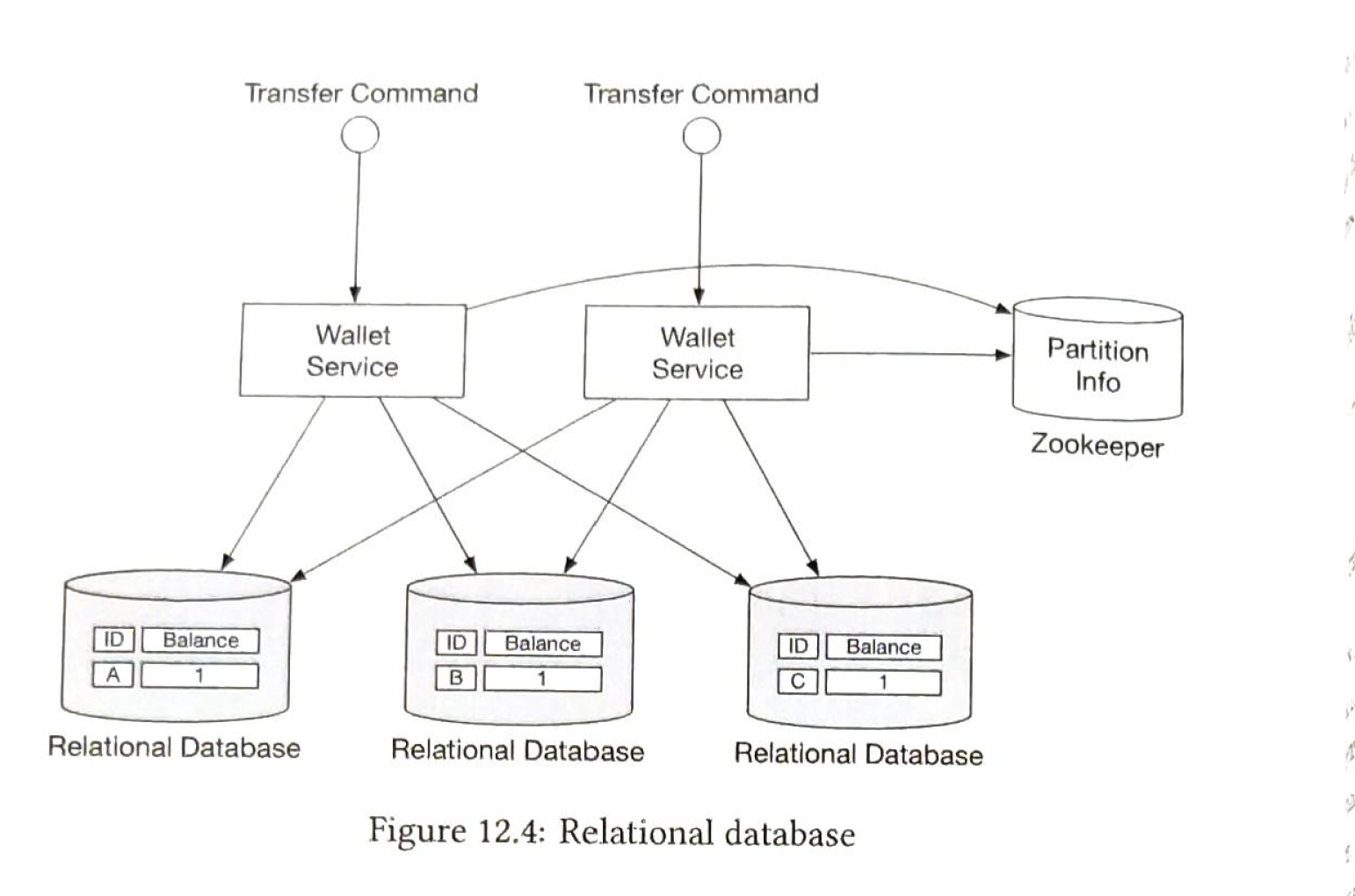
To guarante 2 updates are one atomic transaction. we can use 2-phase commit
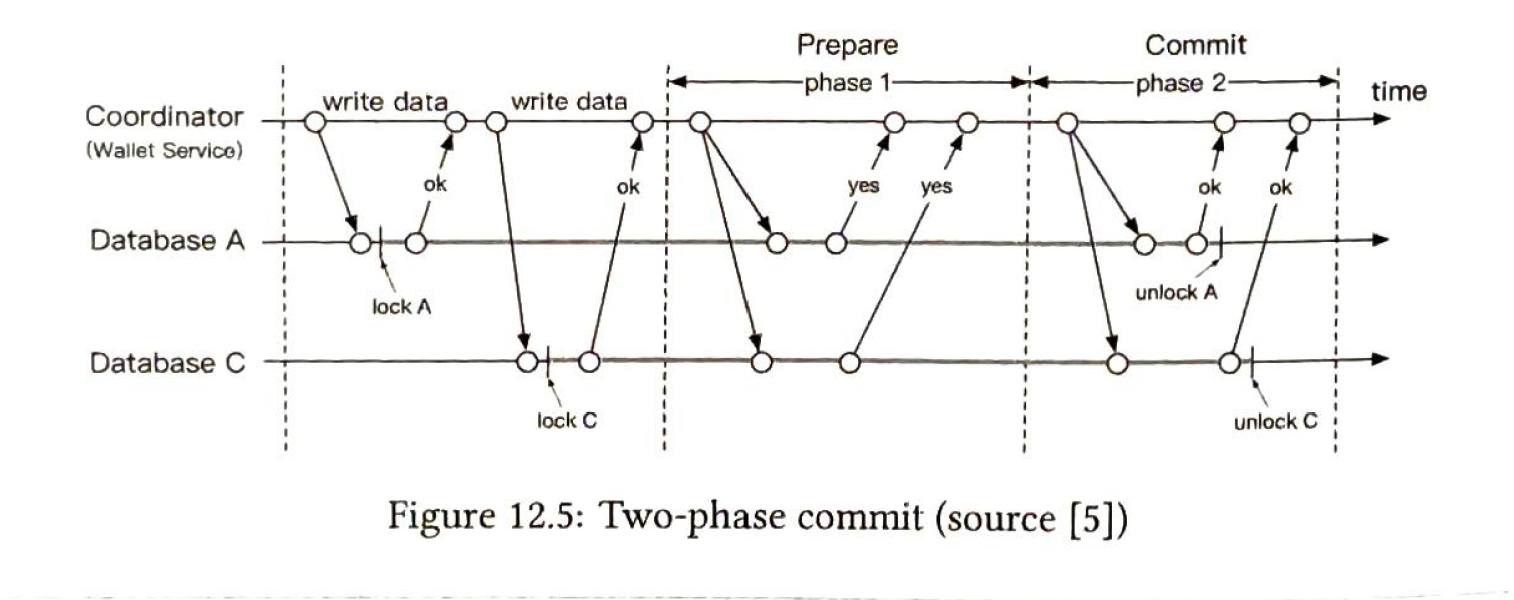
- coordinator is the wallet service, write dbs and they are locked,
- when the db is about to commit, the coordinate asks the db to prepare the transaction
- if all db reply with a yes, the coordinates asks all db to commit the transcation. Else abort.
cons:
- not performant. locks can be hold for a long time.
- single point failure. (one coordinate)
2.2.1 Distributed transaction: Try-confirm cancel (TC/C)
these are seperate operations.
first phase try: NOP. no operation.
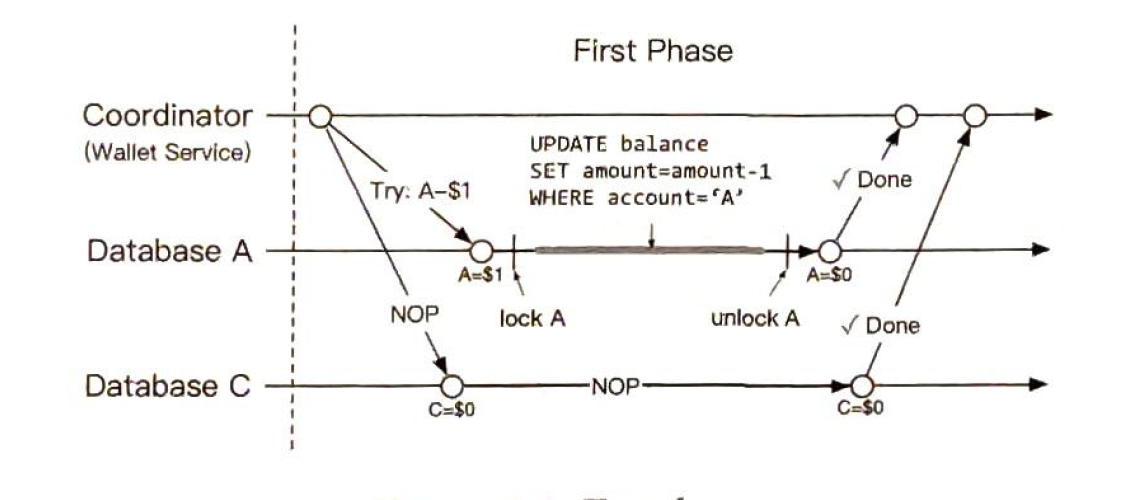
- reduce A by 1
- C NOP. reply is always a yes.
2.2.2 second phase: confirm
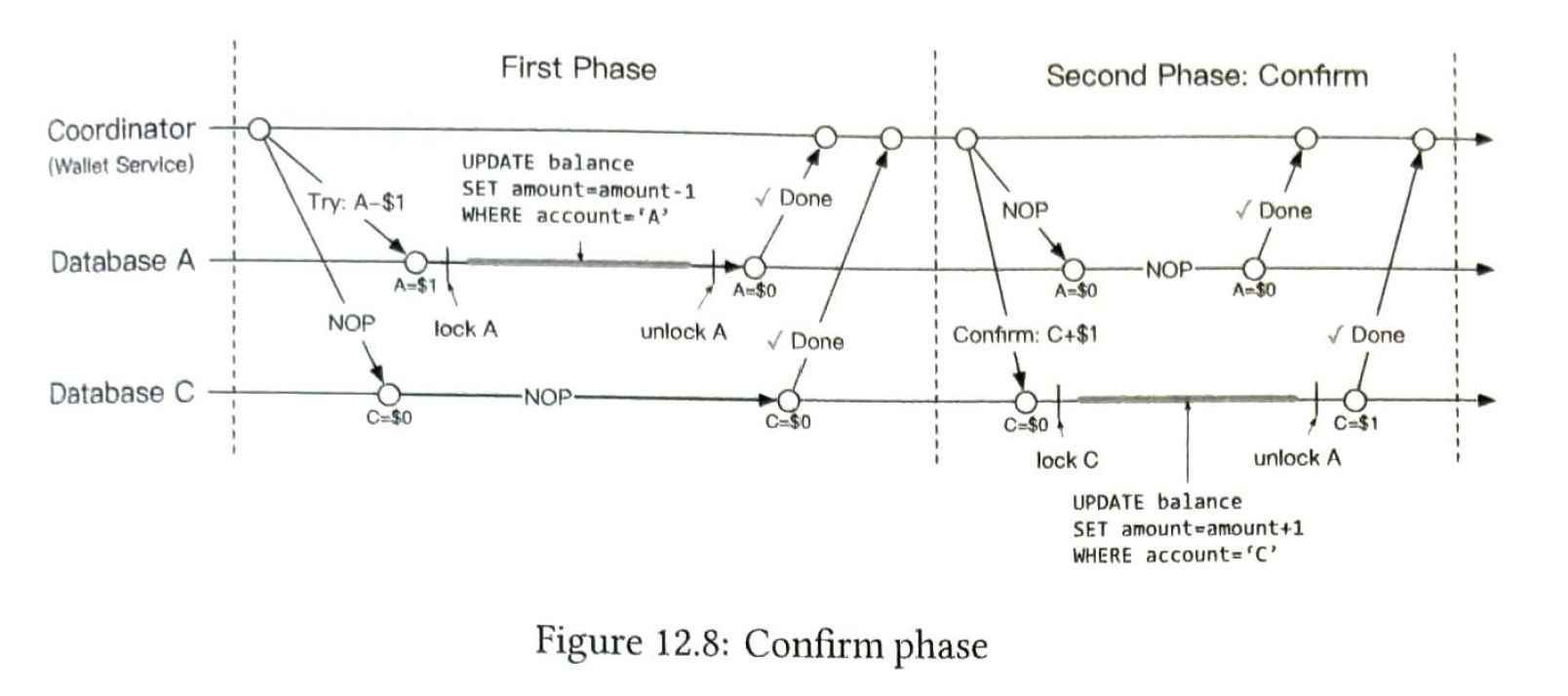
- in phase 1, if A and C are all with replies yes.
- Adds 1$ to db C.
- A NOP. reply is always a yes
2.2.3 second phase: cancel
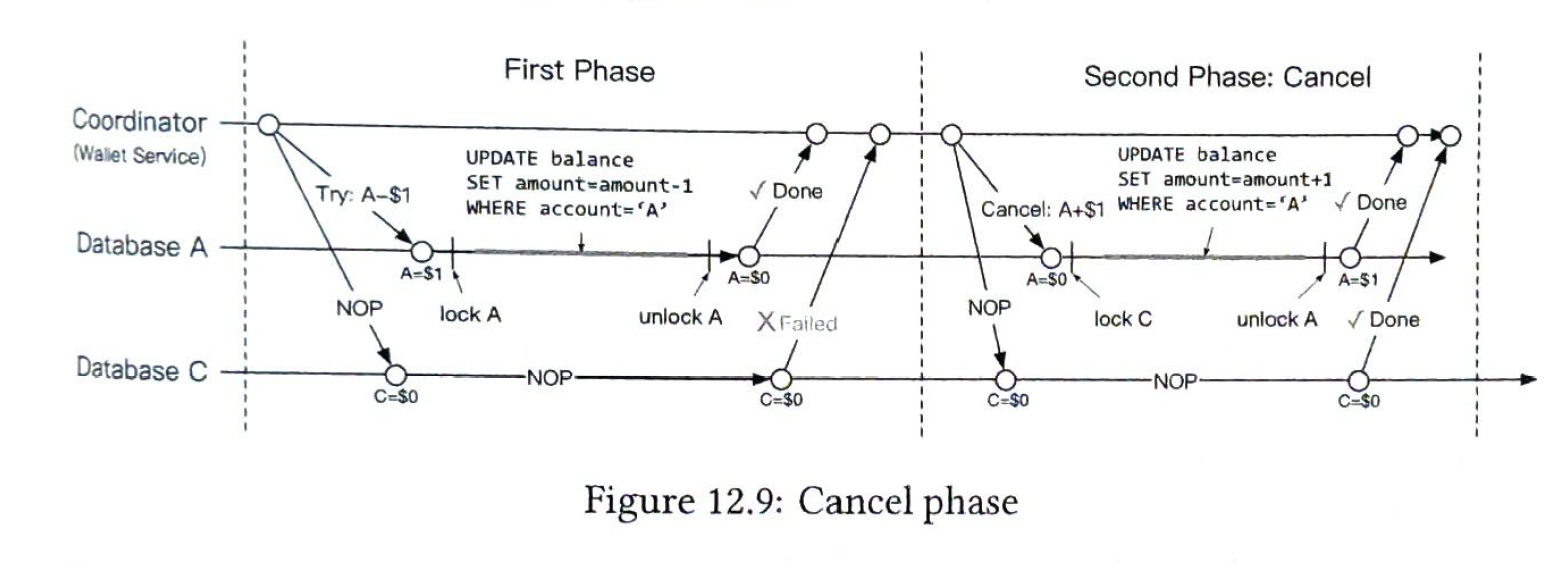
If one step is failed, add 1$ back to db A.
2.2.4 phase status table
If the coordinator restarts in the middle of the process, we need previous operation history.
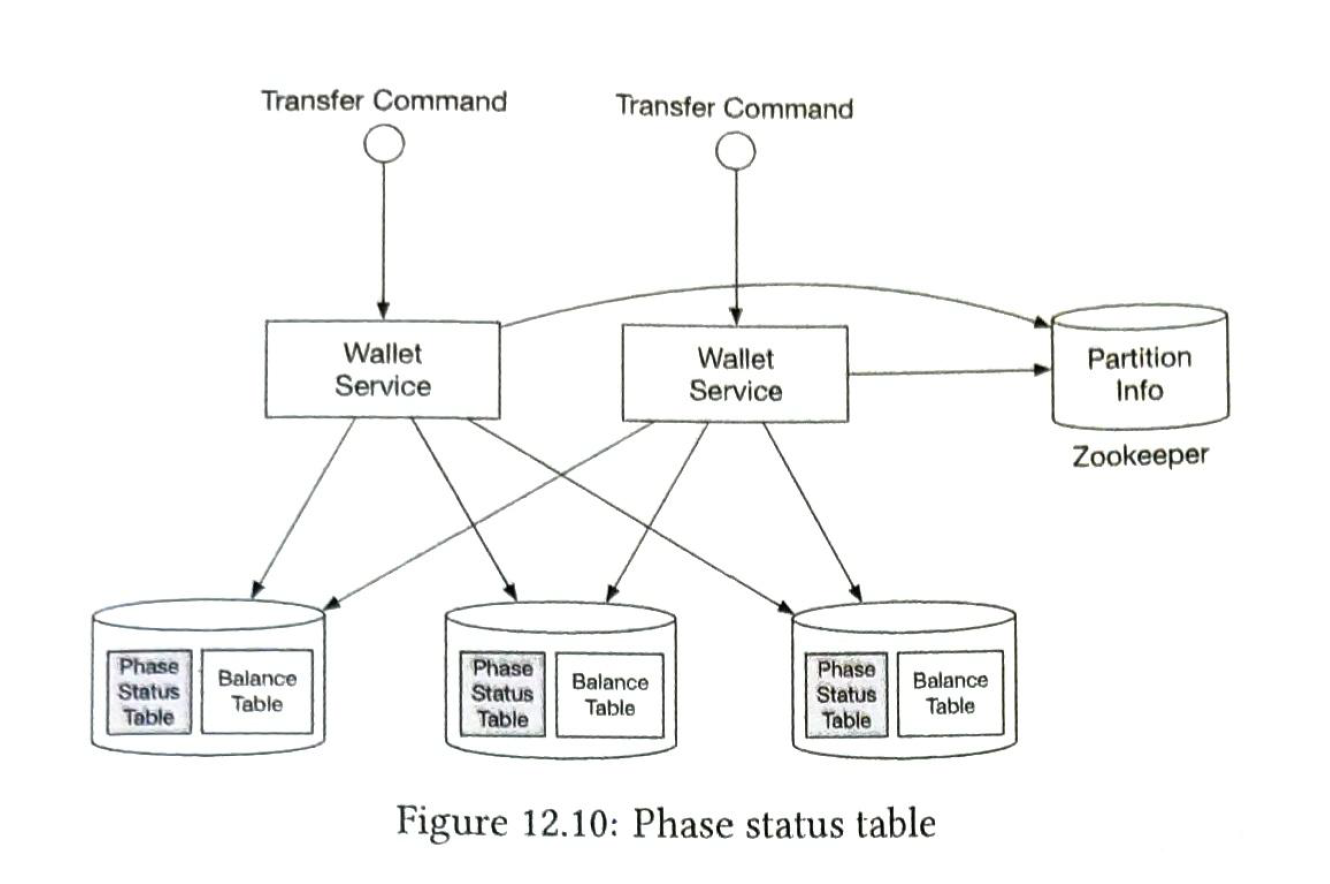
Phase status tables are stored with the local balance table.
2.2.5 Unbalanced state
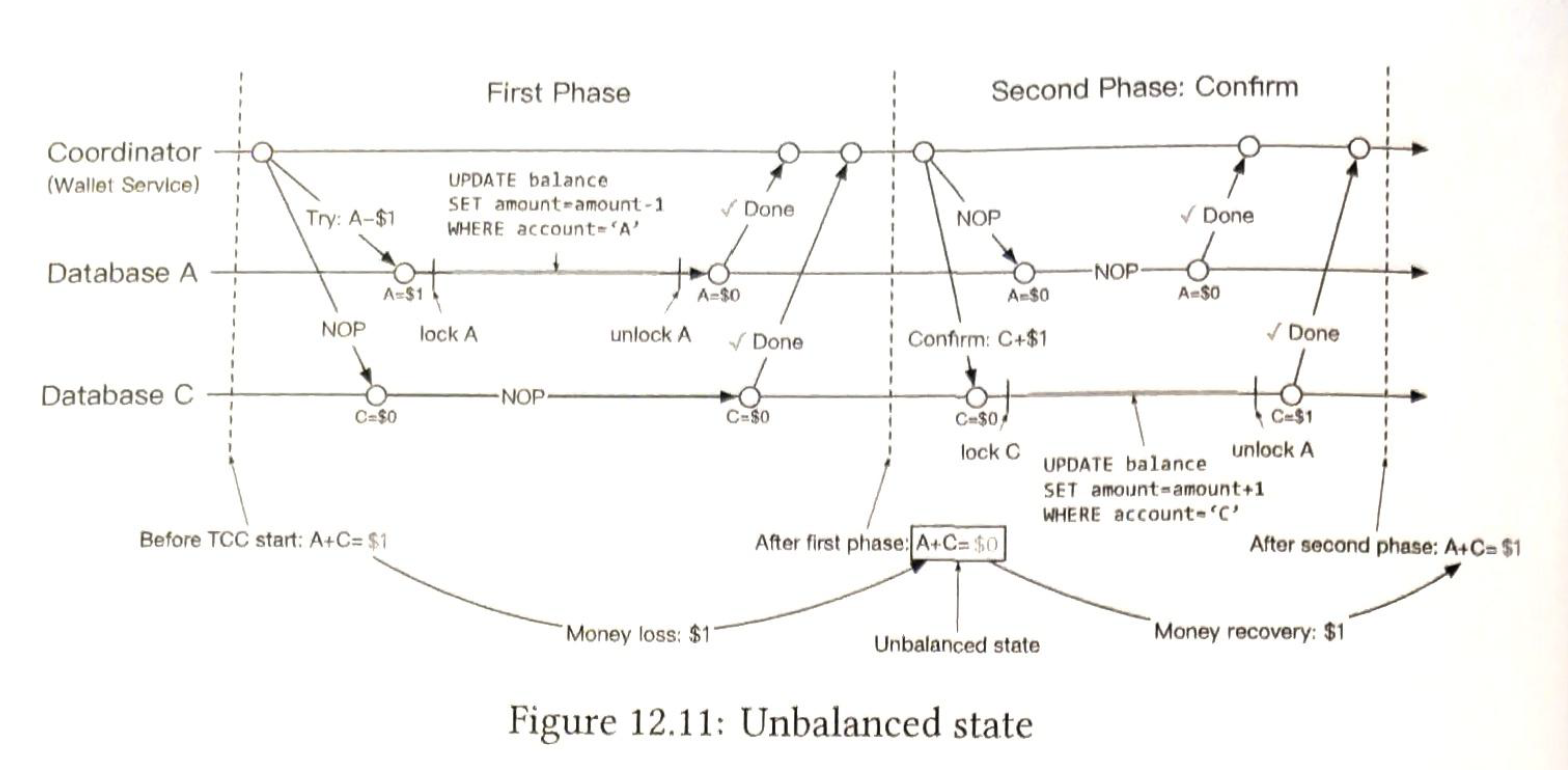
Before T/C C, A + C = 1, at the end of the first phase, A + C is 0. It violates the fundamental rule of accounting that sum should be the same.
2.2.6 Out-of-order execution
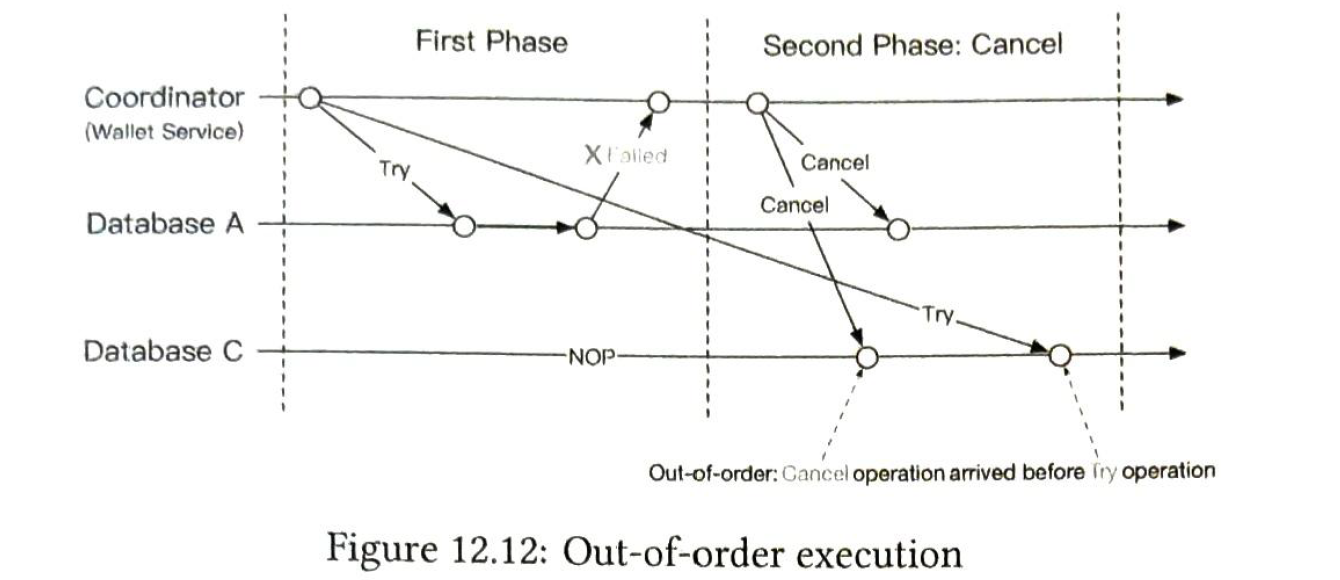
C receives cancel before try. So there is nothing to cancel.
solution: add an out-of-order flag in phase status table, try operation check the flag first
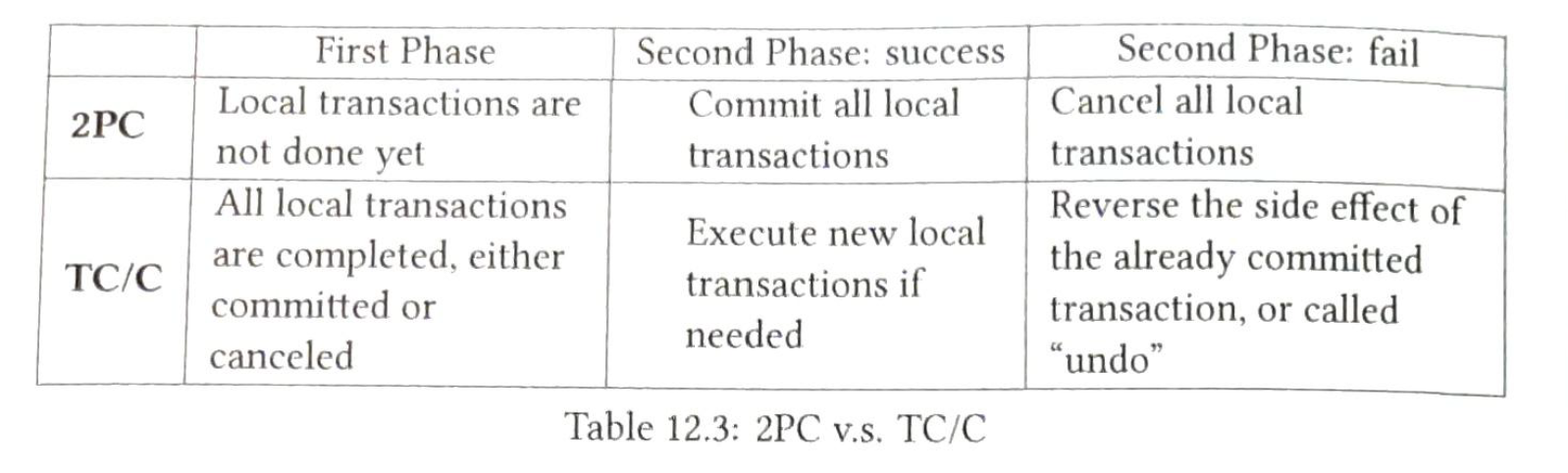
2.2.7 2PC VS TC/C
2.3 distributed transcation: saga
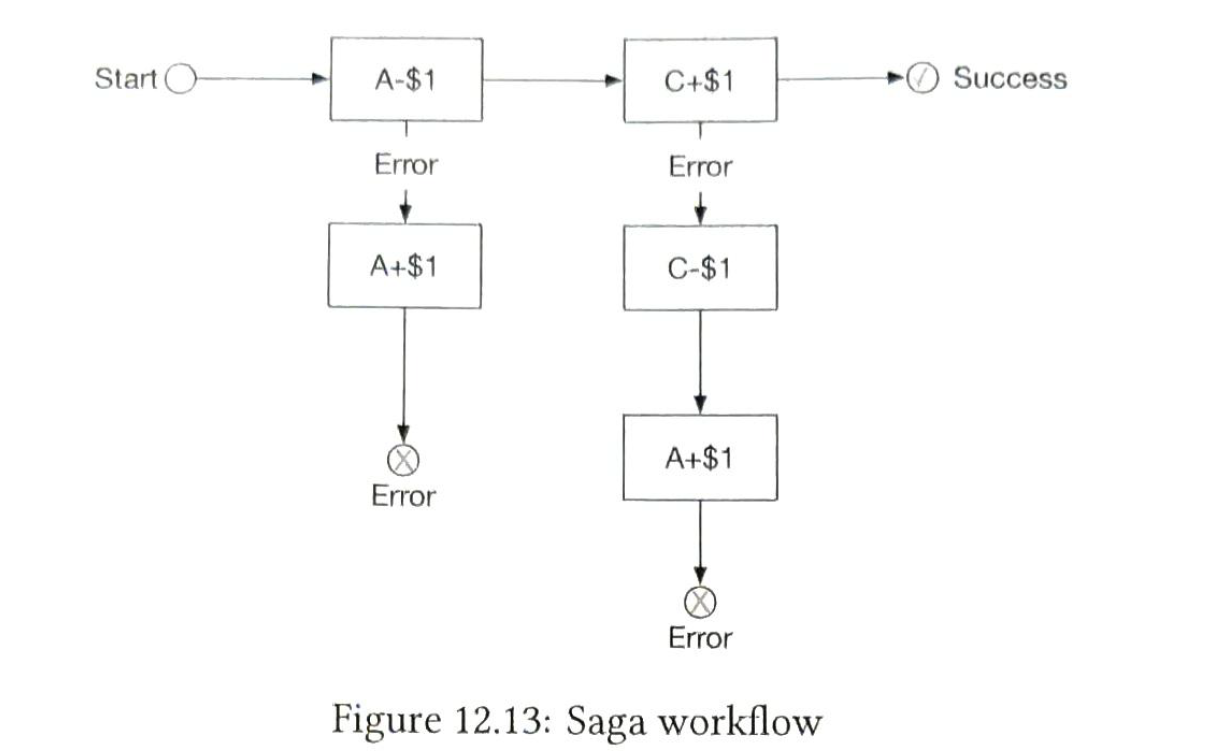
do the operation one by one. we can use only one coordinator to handle this process.
2.3.1 saga or TC/C
- microservice artritecture, saga
- latency sensitive, TC/C
3.1 event sourcing
- Do we know account balance at any time?
- How do we know the historical and current account balances are correct
- How do we prove the system's logic is correct
The design philosophy is event sourcing. 4 important terms in event sourcing
- command (A transfers 1$ to B)
- event. (paste tense, the result is fixed. exp: A transfered 1$ to B. )
- state (what will be changed when an event is applied.)
- state machine (validate commands and generate events, apply event to update states)
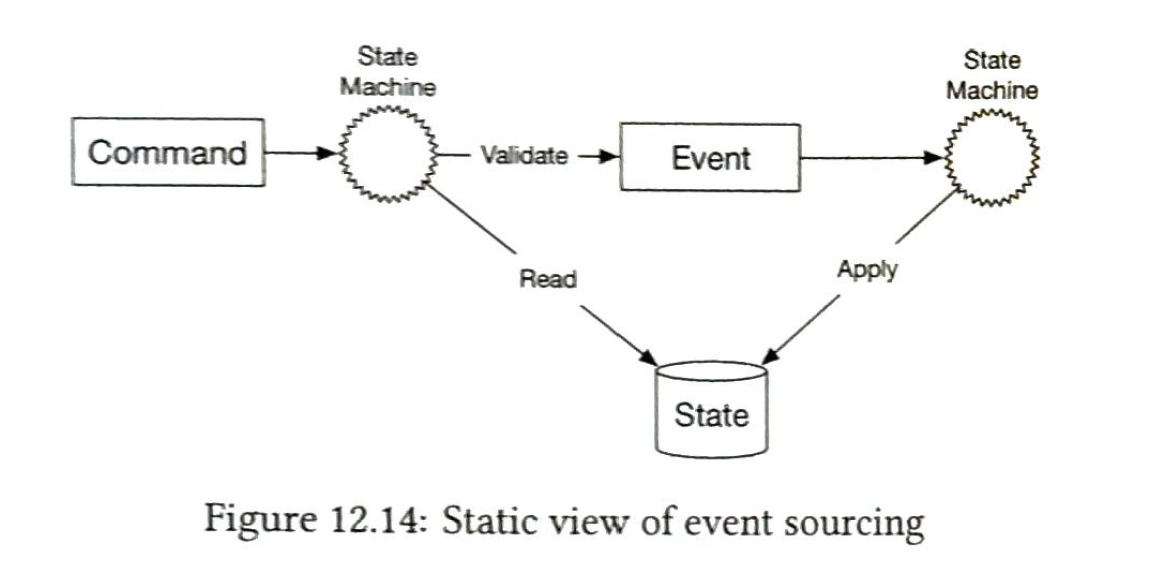
Example:
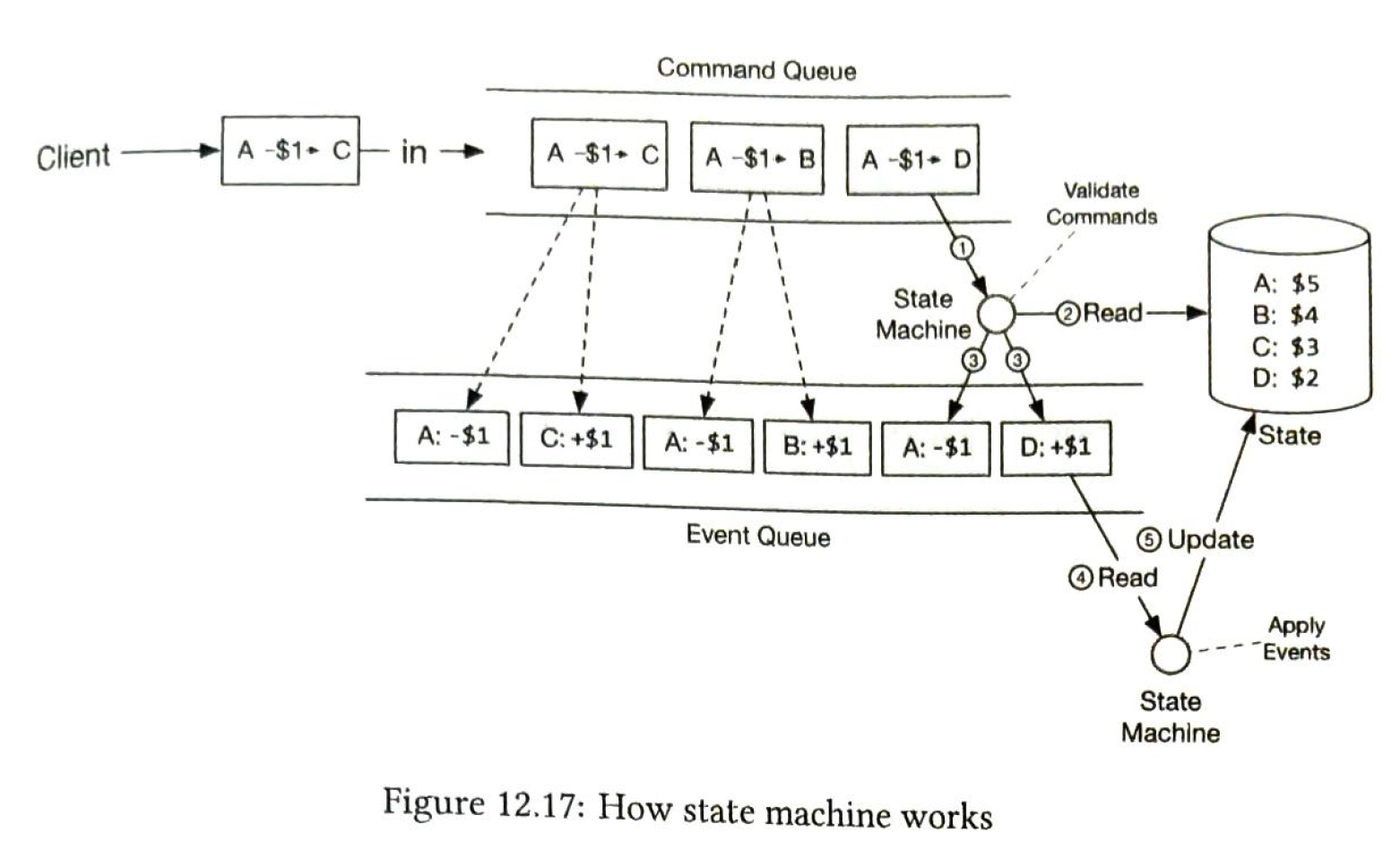
3) reproducibility
the most important advantage. We could always reconstruct historical balance states by replaying the events from the very beginning.
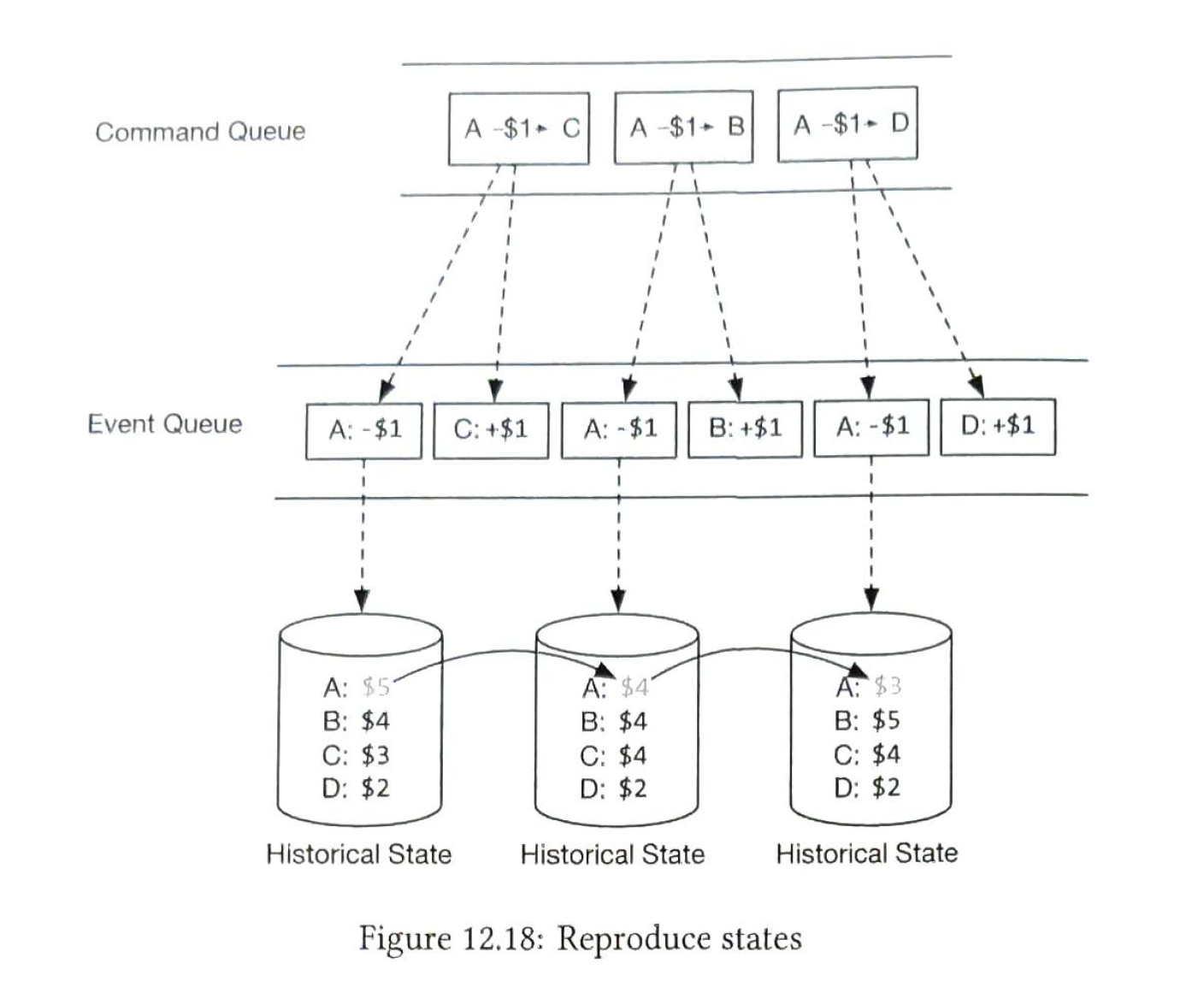
Q: Do we know the account balance at any given time?
A: We could answer it by replaying the events from the start, up to the point where we want.
Q: How do we know the historical and current account balances are correct?
A: We could verify the correctness of the account balance by recalculating it from the event first.
Q: How do we prove the system logic is correct after a code change?
A: We can run different versions of code against the events and verify that their results are identical.
Command-query responsibility segregation (CQRS)
For clients to query the balance. In CQRS, there is one state machine responsible for the write part of the state, but there can be many read-only state machines. The read-only state machines lag behind to some extent, but will always catch up. The architecture design is eventually consistent.
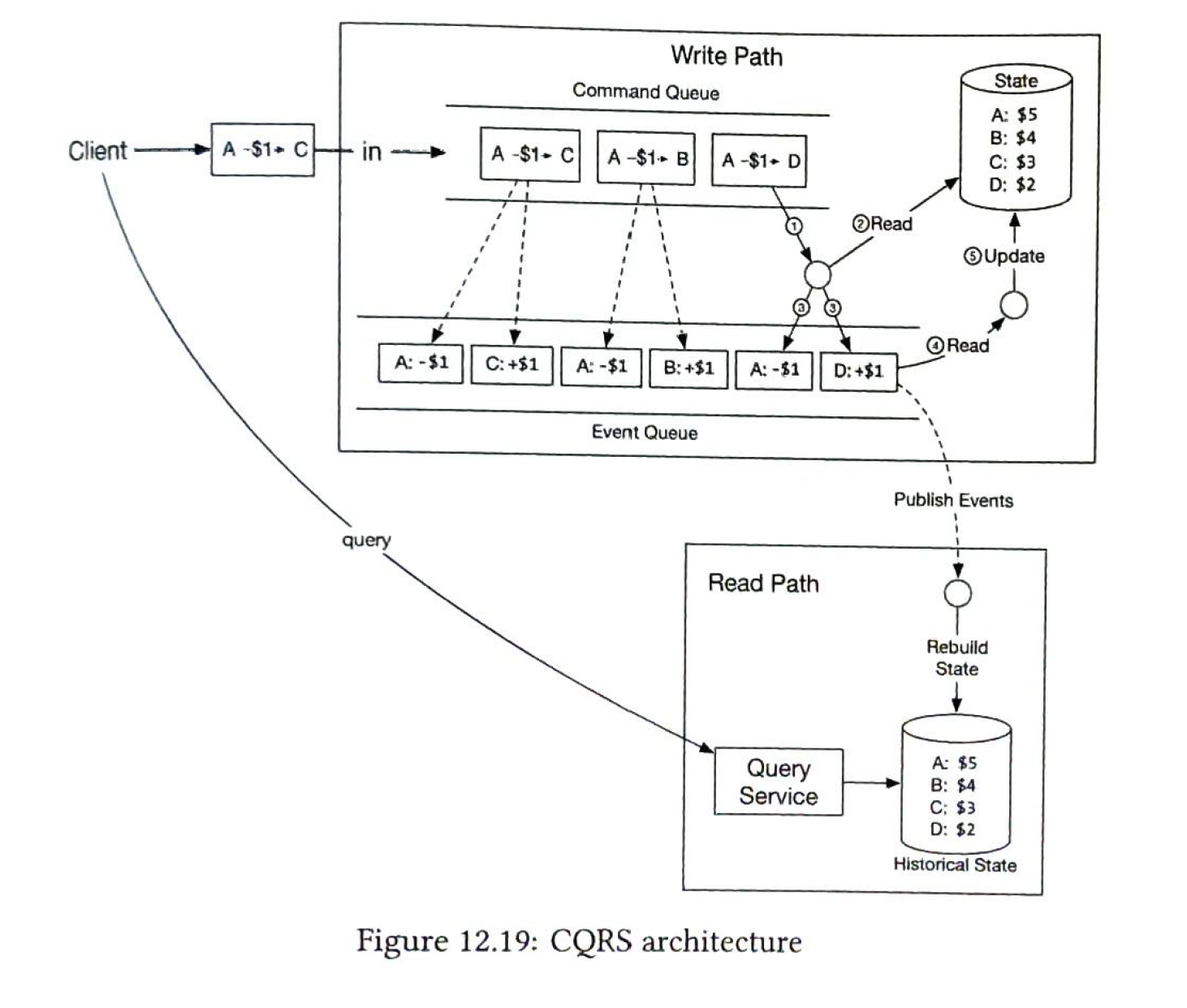
Design deep dive:
Two optimizations:
1. We can store commands and events in disk rather than kafka. Appending is a sequential write operation, which is generally very fast.
2. We may cache the recent commands and events. A technique is called MMap. It can write to a local disk and cache recent content.
We can use rocket (local file-based local relational database. )db or SQlite to improve read performance.
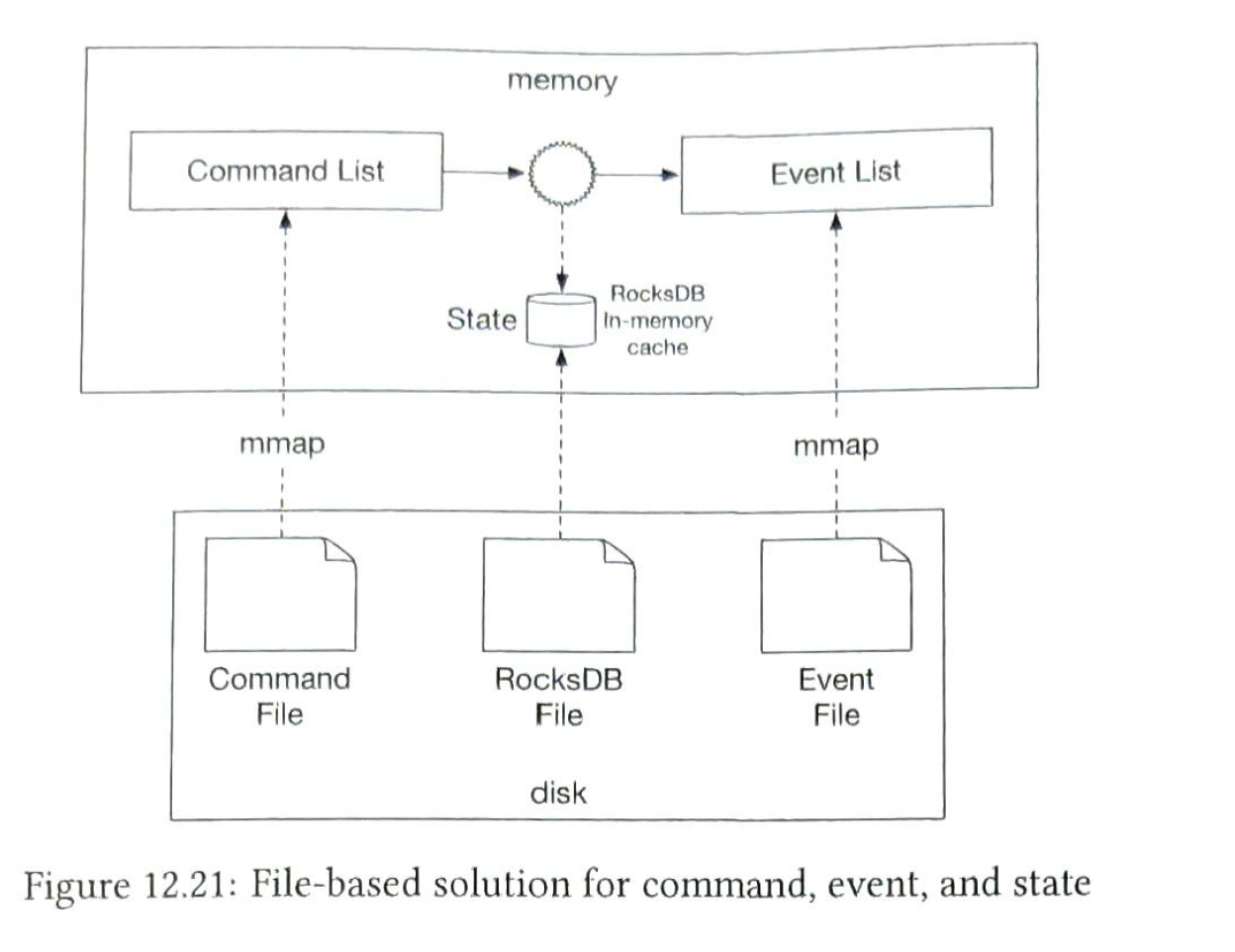
snapshot. we can use snapshot to accelerate the reproducibility. We don't have to stop the state machine and read command from the start. We the periodically stop the state machine and save the current state into a file. This is called a snapshot. A snapshot is a giant binary file. Sync snapshots from command / event files.
Their are for types of data.
- File-based command
- File-based event
- File-based state
- State snapshot
Consensus.
- No data loss
- The relative order of data within a log file remains the same order across nodes.
We can use Raft consensus algorithm.
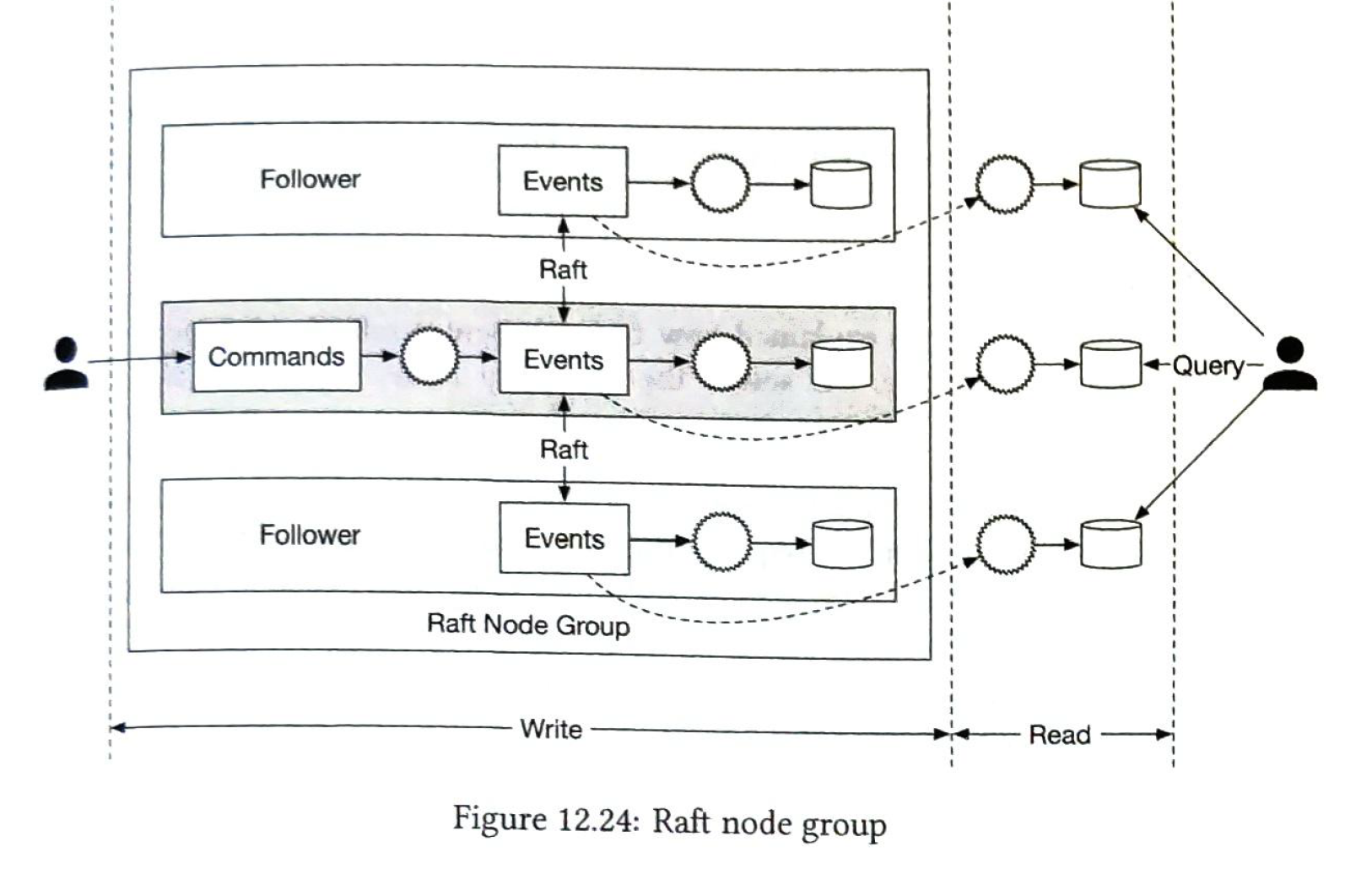
Push or Pull?
Pull: not real-time. and may overload the wallet service. But we can add a reverse-proxy. Periodicall pull.
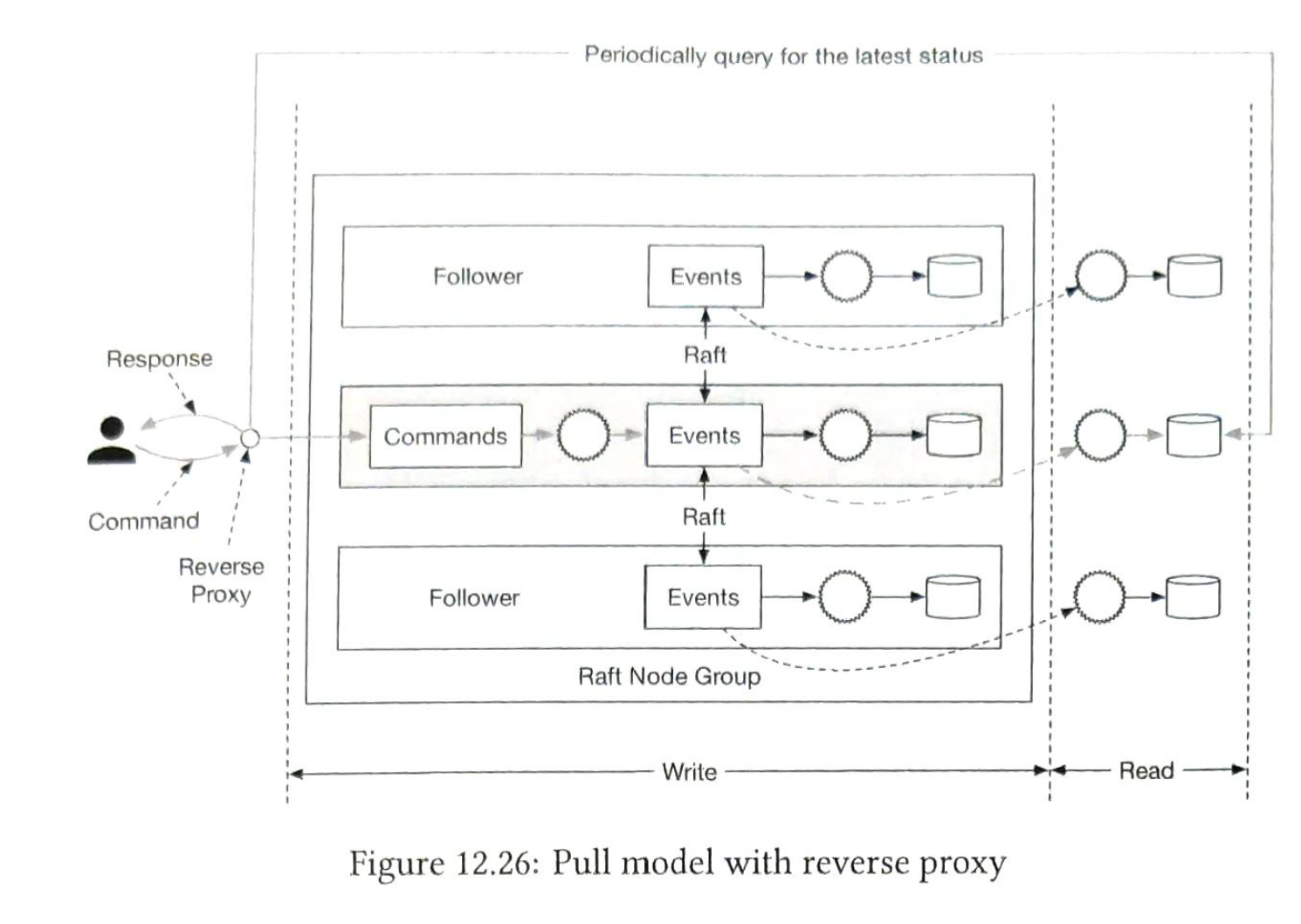
Push:
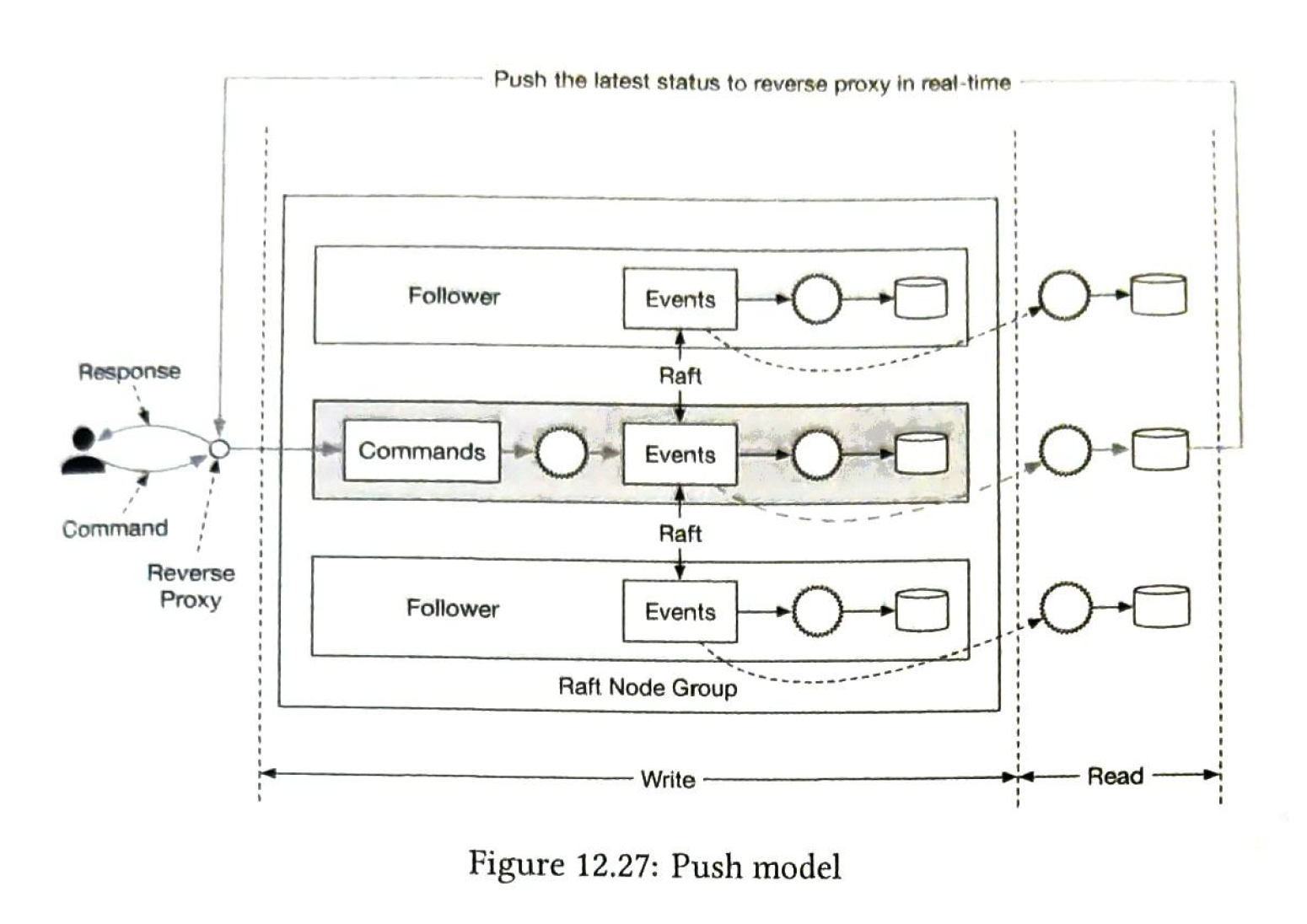
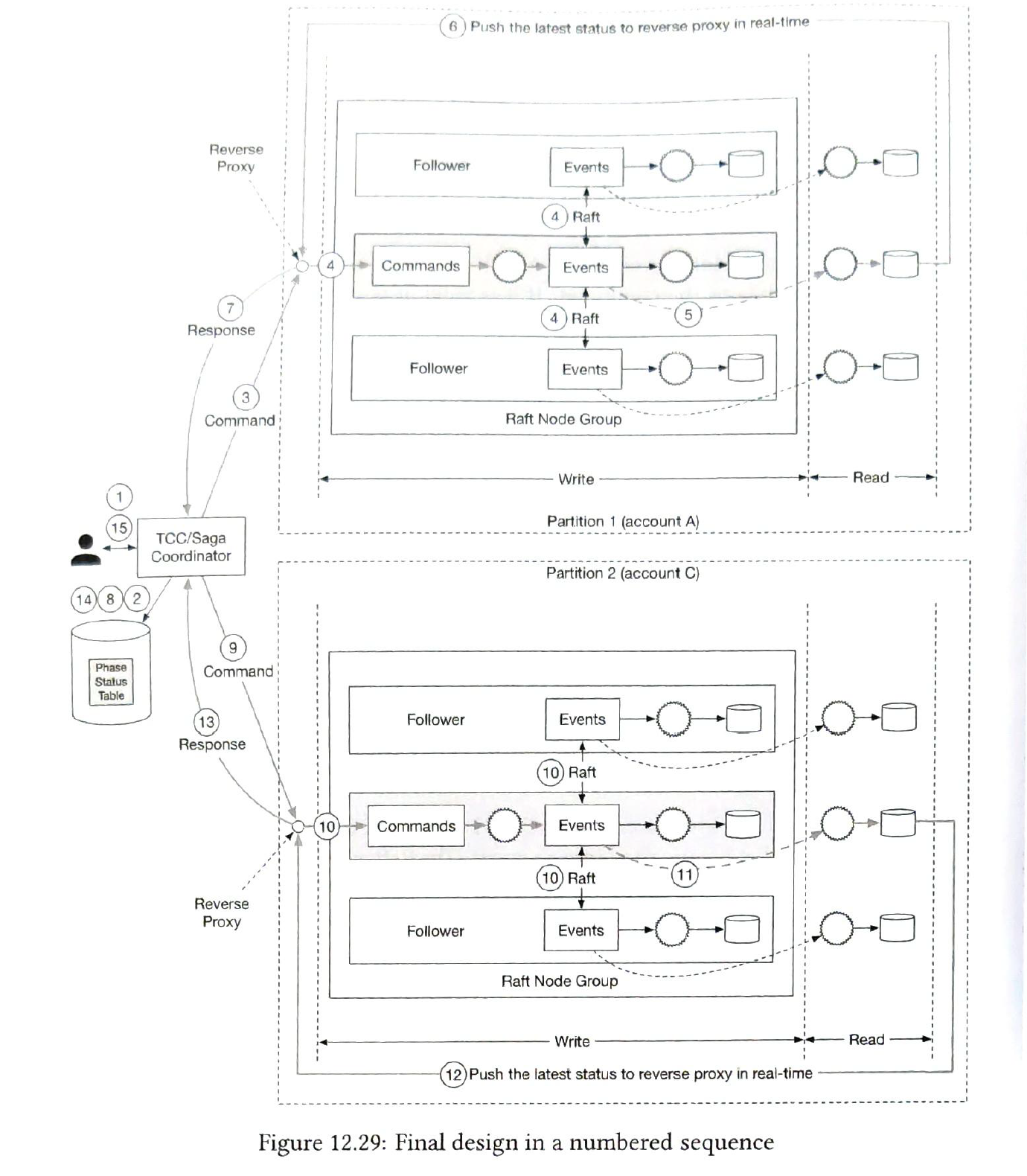
Distributted transaction.
We can use TC/C or saga as the distributed transaction solution. The phase status table is to track the transaction status. it is updated according the status.
13 Stock exchange
1) requirements
| Functional | Non-functional |
| placing a new order | availability: At least 99.99%. |
| canceling an order | fault toleranfce and a fast recovery |
| support limit order | latency. millisecond level. |
| security. prevent DDOS attacts. |
2) back-of-the envelope estimation
| symbols | 100 |
| orders | 1 billion / day |
| QPS |
9:30 ~ 4:00 pm. 6.5 hours in total. 1 billion / (6.5 * 3600) = 43000 / s |
| Peak QPS | 5 * QPS = 215000 |
some terms.
| broker | most retail clients trade with an exchange via a broker |
| institutional client | trade in large volumes using specialized trading software |
| limit number | a limit order is a buy or sell order with a fixed price. |
| market data level | L1, L2, L3. Best time to sell and buy. |
| candlestick chart | 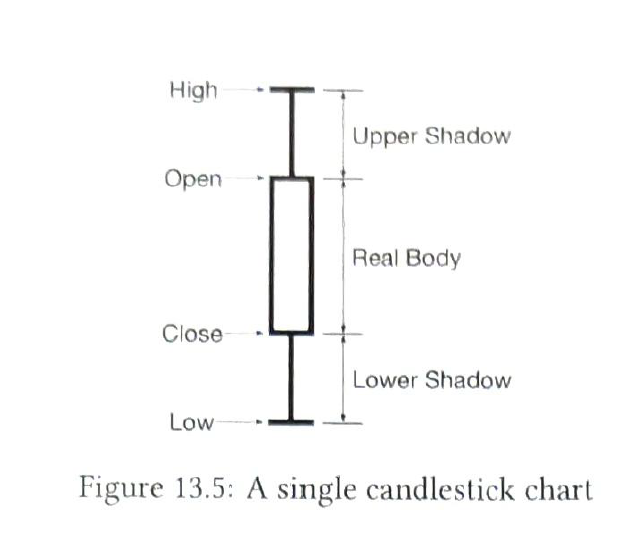
|
| FIX | Financial information exchange protocol |
3) design
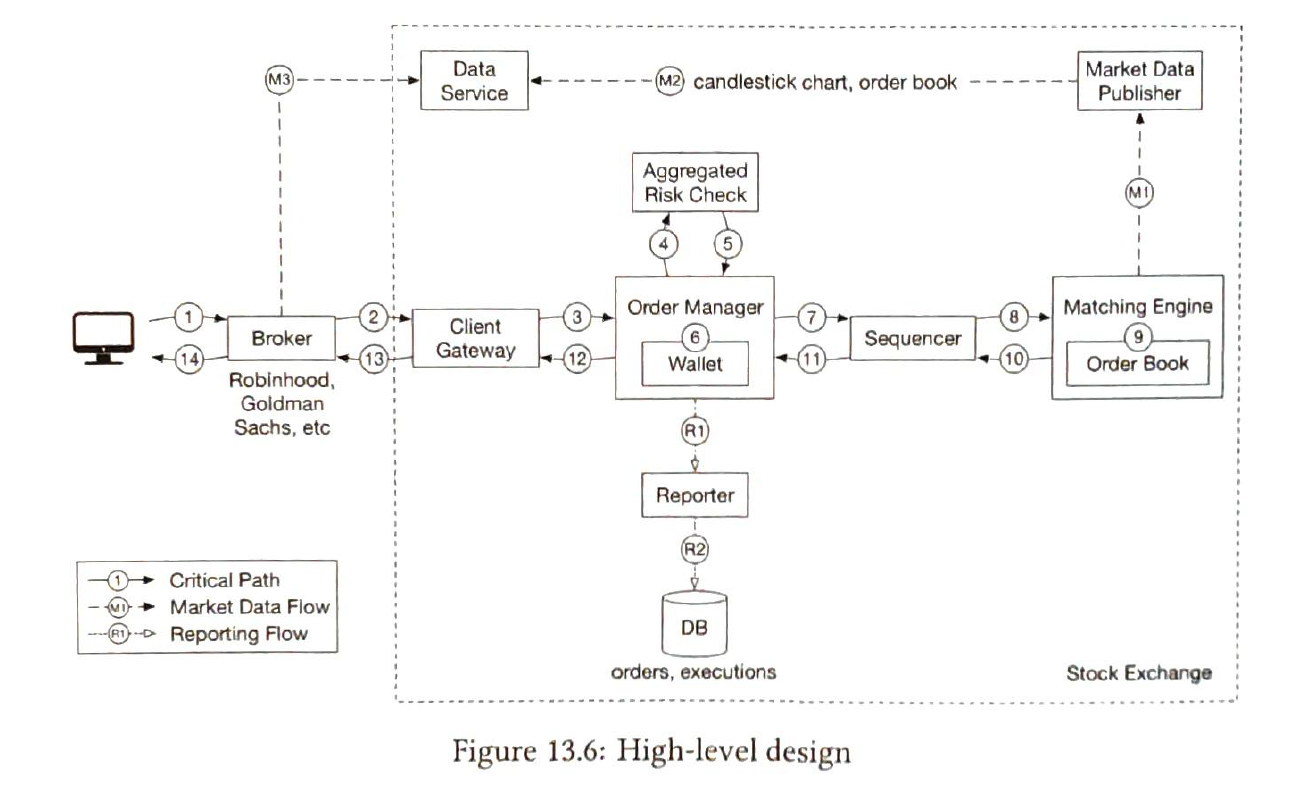
| trading flow |
|
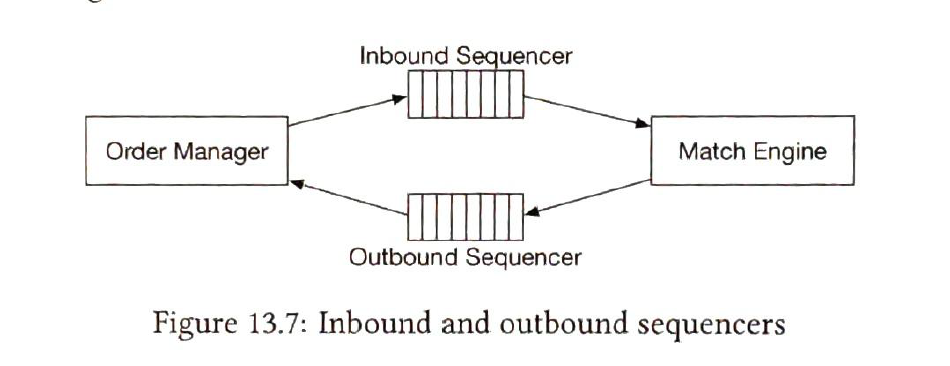
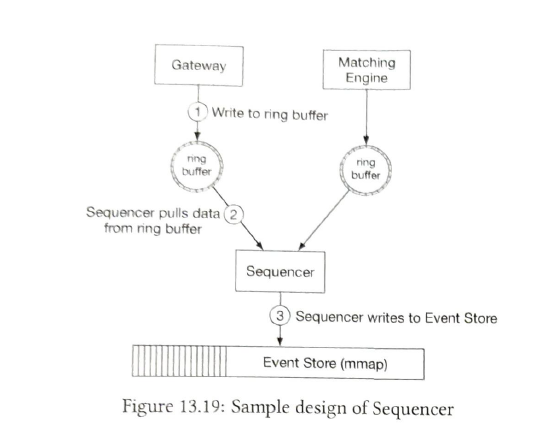
| sequencer |
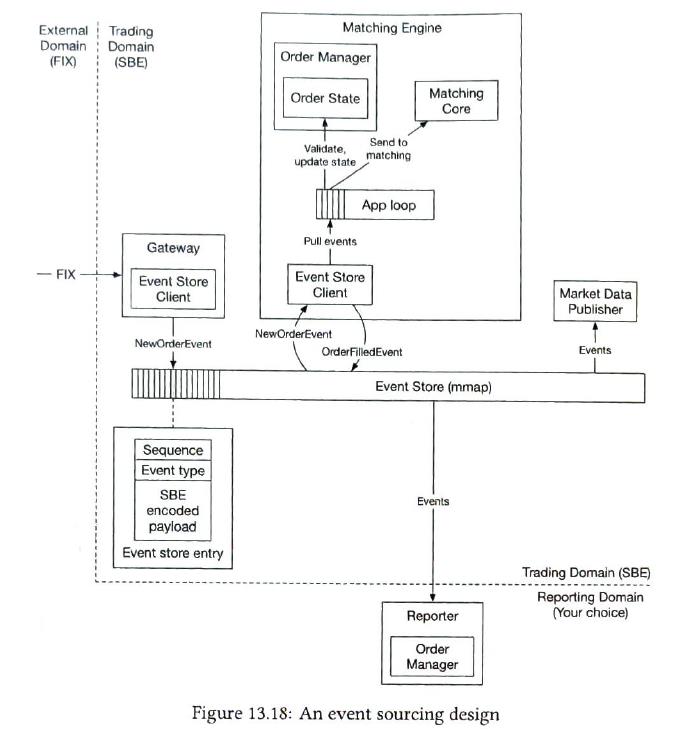
The sequencer is the key component that makes the matching engine deterministic.
|
| order manager |
receive orders on one end and receive executions on the other.
|
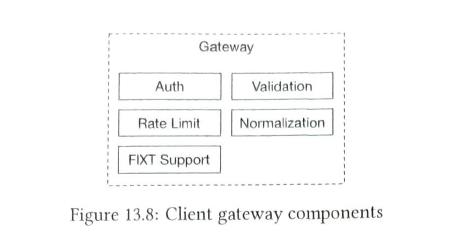
| client gateway |
it receives orders placed by clients and routes them to the order manager.
|
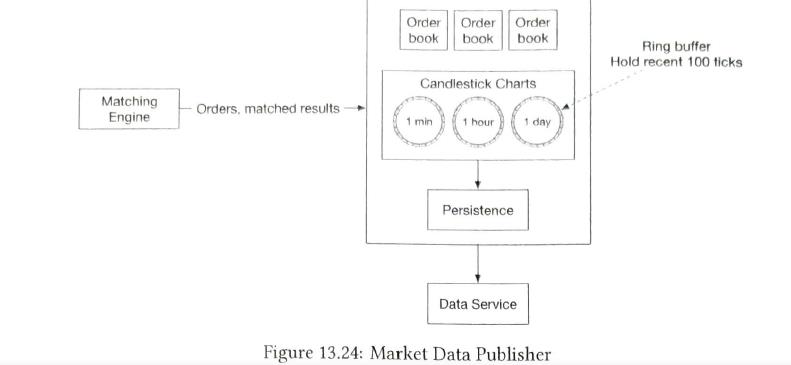
| Market data flow |
market data publisher receives executions from the matching engine and builds the order books and candlestick charts from the stream of executions.
|
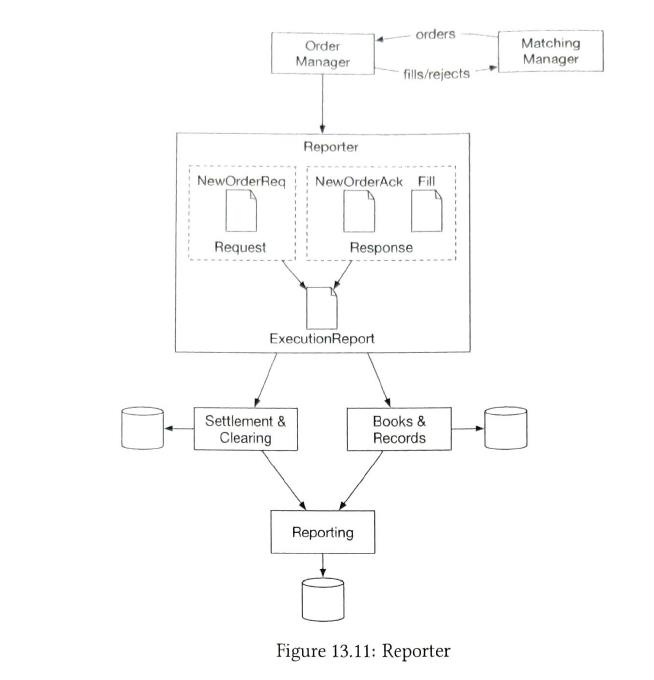
| reporting flow |
provides trading history, tax reporting, compliance reporting, etc. The reporter is less sensitive to latency. Accuracy and compliance are key factors for the reporter.
|
| API Design |
1) order
request {symbol, side, price, orderType, quantity} response {id, creationTime, filledQuantity, remainingQuantity}
request {symbol, orderId, startTime, endTime} response {id, orderId, symbol, side, price, orderType, quantity}
request {symbol, depth, startTime, endTime} response {bids, asks}
requset {symbol, resolution, startTime, endTime} response {candles, open, close, high, low} |
| data models |
Product, describes the attributes of a traded symbol. This data doesn't change frequently. Used for UI display. highly cacheable.
An order represents the inbound instruciton for a buy or sell order.
An execution represents the outbound matched result. It is also called a fill.
orders and executions are stored in memory and leverages hard disk or shared memory.
order book: it is a list of buy and sell orders for a specific or financial instrument.
adding / canceling a limit order, the time complexity O(1). So we should use double-linked list and a map. |
| performance |
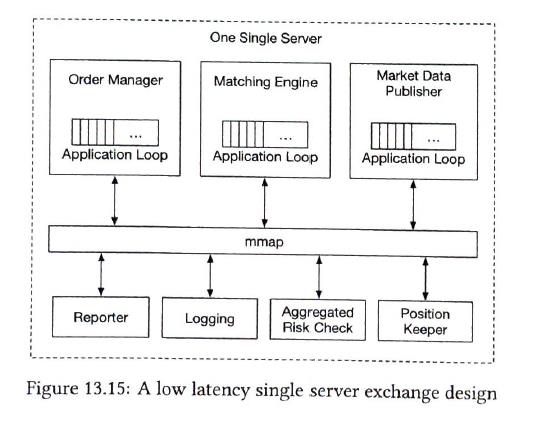
Latency = sum(executionTimeAlongCriticalPath) Two ways to reduce the latency:
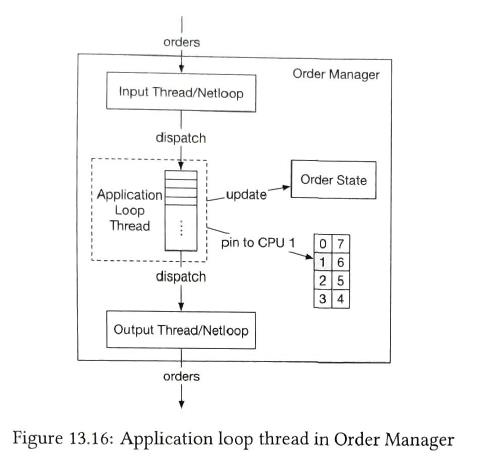
Appliction loop
use a while loop to pull order. the thread is pinned to a fixed CPU core. The tradeoff of CPU pinning is that it makes coding more complicated. mmap provides a mechanism for high-performance sharing of memory between processes. |
| Event sourcing |
Only one sequencer
The sequencer pulls events from the ring buffer that is local to each component. |
| high availability |
4 nines. 99.99%. This means the exchange can only have 8.64 seconds of downtime per day. It requires almost immediate recovery if a service goes down.
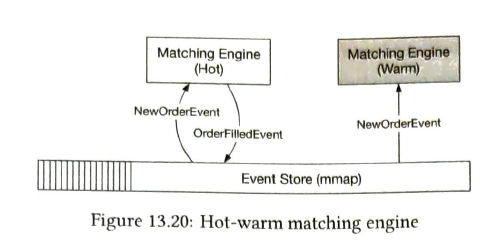
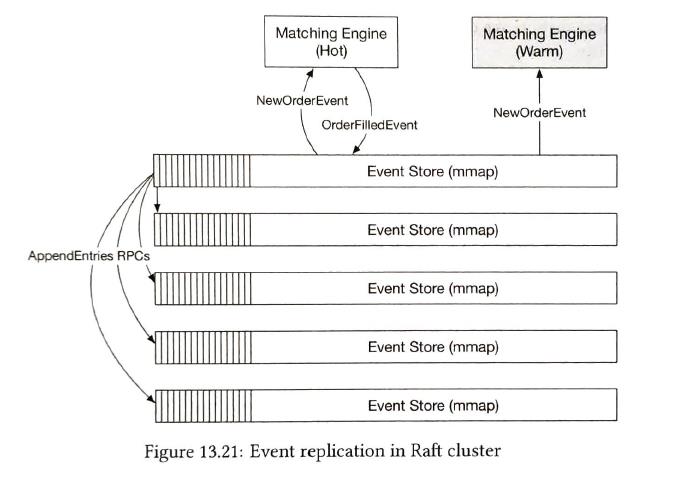
hot matching engine works as the primary instance, and the warm engine receives and processes the exact same events but does not send any event out onto the event store. The problem with this hot-warm design is that it only works within the boundary of a single server. To achieve high availability, we have to extend this concept across multiple machines or even across data centers. In this setting, an entire server is either hot or warm. |
| fault tolerance |
The system might send out false alarms, which cause unnecessary failovers. Bugs in the code might cause the primary instance to go down.
We use raft leader-election algorithms.
Recovery Time Objective(RTO) refers to the amount of time an application can be down without causing significant damage to the business. With RAFT, it guarantees that state consensus is achieved among cluster nodes. |
| Matching algorithms |
FIFO first int first out |
| Market data publisher optimizations |
MDP can receive mathced results from the matching engine and rebuild the order book and candlestick charts based on that
Clients need to pay extra to get other level data. So MDP can rebuild these data accroding to matching results.
|
| Distribution fairness of market data |
Ulticast using reliable UDP is a good solution to broadcast updates to many participants at once. |
| Network security |
DDoS:
|