system design学习
DDIA
1.0 基础介绍
- Reliability
- Scalability
- Maintain
1.1 Reliability
work under failure.
Error
1) hardware error
- disk / network
2) software error
- bug
3) humen error
Solve
- access control
- sandbox -> experiment (test)
- CI-CD (continus imployment, continus deployment) + automatic test
- monitoring
- rollout feature gradually (逐渐散发特性给用户)
1.3 Scalability
scale up (better CPU)
scale out (more service)
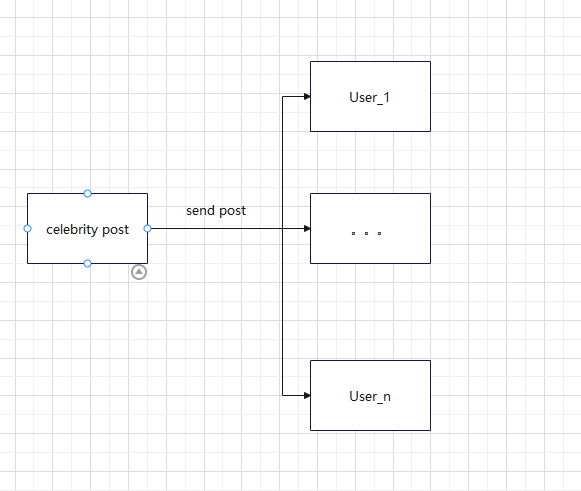
Example: Weibo
| Post |
select post from posts p join users u on p.send_id = u_id join follows f on f_follow_id = u.id where cur_id = f.follow_id
if user is a famous person, folowers are very large |
send post to followers directly
|
1) normal: method 1 : use query
2) celebrity post method : send post directly |
1) Metric
through put (Request / per sec)
Response time
latency (tail-latency need to pay attention to, because they are valuble)
1.5 Maintainability
- software, bug
- hw, cpu, disk, battery (redundancy, extra hw)
2.1 Data model
1) SQL
- Relation SQL
- IMS
2) NoSql
- Document Model (JSON, HTML)
- Graph SQL
3.1 Data structure that power database
1) hash table index
key: index
value: location (in memory)
pro:
- append log. (change location directly by key
- good performance
- concurrent
con:
- memory, (lost easily)
- can not implement range query
2) SS (sorted string) table + LSMT
| SS Table (RB Tree) | sorted string (can use merge sort to compress data) | can use binary search | one key one segment |
Pros:
Cons:
|
| LSMT Table |
B 树 B+树 一般 4层, 256 T数据.
B Tree: Point Query
con : data duplucation
B+ Tree: Range Query
3) LSMT (SS Table) VS B, B+ Tree
| PROS | CONS | |
| LSMT | Write |
Read (when compress) Read Two Part. New Tree -> Old Tree |
| B+ Tree | Read | Write (divide page) |
3.8 memory database
pros:
Read faster
Complicated datastructure
3.9 data warehouse
主表写很多数据,fact_table. (order_id, user_age)...
然后 可以根据主表 做一些snapshot 给 数据分析 DA 用 来挖掘一些价值,bendwidth有限,所以不需要实时更新
然后 select * from table 这种 内存加载内容很多,
可以把传统的 row storage 改成 column storage,这样不需要的 column 就不用加载,例如 order_id 放一个存储文件,user_id 放一个等等
4.1 Encoding & Evolution
| backward compatibility | when you release v_2, you need to think whether v_1.5 can use |
| forward compatibility | will v_2 in the future use current structure |
code
data
- memory
- disk (serialize, decode)
| method | pros | cons | |
| java |
easy to write |
|
|
| json /csv / xml | can change shceme easily | more time and space | |
| protobuf |
less space, reflect key to number don't need to spell out key name |
4.5 data flow
1) flow database
2) service calls
5.1 why distribution system
when the scale is very large, use distribution system
1) single point failure
2) work under failure
3) request
5.2 CAP
Only choose two.
1) C consistency
Pros: same data
Cons: latency
2) A avalability
asynchronized.
pros: faster, available
cons: data not the same
3) P partition Tolerance(分区容错 必须有)
must happen. make sure serivice is available.
5.3 single leader
1) problems
- can not read data from followers imediately.
solve: you can read data from the leader when data is written. read from leader or wait for follower
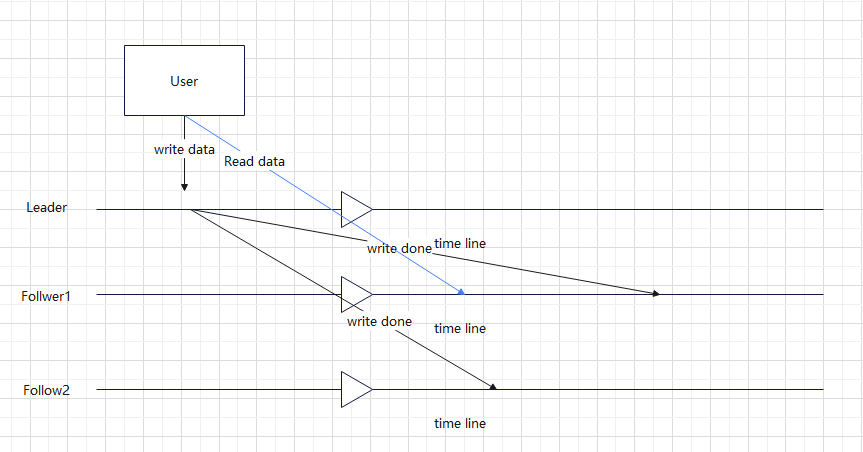
- consistence
Two message A and B, and A happened before B. How to make sure?
5.4 Multiple Leader
can solve single point failure. It is complex, do not prefer use it.
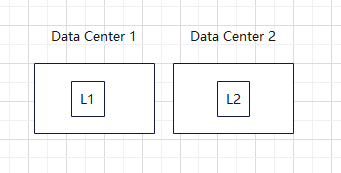
you can use data center instead. user is send to the nearest data center. and they are still multiple data centers. but there are some problems, for example, how to make sure the data are the same?
5.6 apply multiple leaders
1) case

so these devices have same data
2) problem
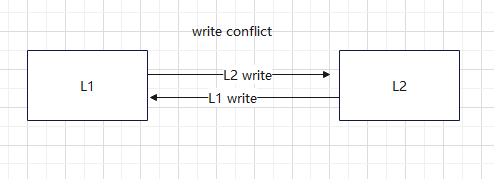
- sync (latency)
- let user decide what to write. like how to solve git conflict
- gossip
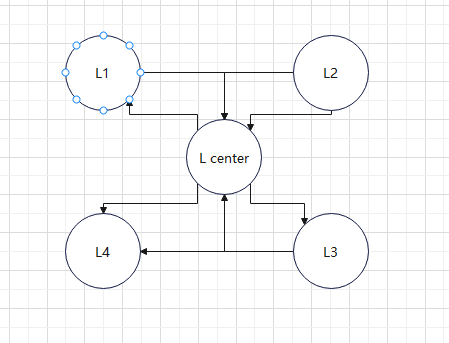
still has write conflict. last time win. set a timestamp
5-8 leaderless replication
use version to control which to read.
Eventually consistency to solve different machine has different data.
5-9 Quorum
w -> write time
r -> read time
n -> total number of services
w +r > n, so you can get the latest data
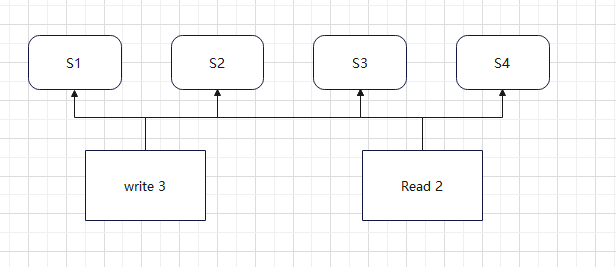
problem read old data.
sove: sloppy.
happen before. (close friends circle, then send a post)
6.1 Partition
1) partition by key.
0~100 us
101 - 200 eu.
pro: can use range query.
con: maybe has hot spot.
2) partition by hash key
pro: can solve hot spot
con: can not apply range query.
6.2 partition and secondary index
6.3 rebalance
- R/W available
就是hash算法 之前博客里写的,选hash 一致算法 或者 virtual node 方法。
6.5 client and server
how the client remember the node ?
1) heartbeat
save information in session. not good.
2) middle software
message broker
7.1 Transaction 事务
ACID (Atomic, Consislent, Isolation,Duaration)
7.3 Trasaction隔离机制
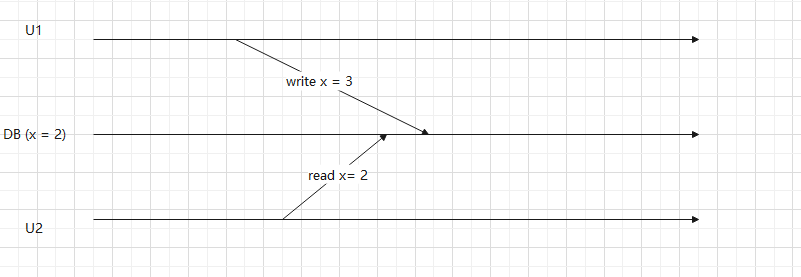
dirty read
can solve dirty read.
If U1 write is rollbacked, if U2 read things uncommited, so x will be 3, it is wrong.
dirty write
write conflict, last write win.
non reatable read
1) Read Commited
no dirty read.
others could happen
dirty write (row lock)
2) Repeatable Read
use snapshot to solve unrepeatable
3) 串行化
8.1 The Trouble with distribute system
Use super machine or algorithm to handle some common problems
8.3 how to detect a broken node
detect:
heartbeat
solve
1) load balance
traffic drain
2) Promote
follower -> leader
8.6 拜占庭问题
9.1 linerizabiling
1) eventual consistency (convergence)
CAP.
9.2 2pc
1) prepare, all prepare
2) commit then commit
10.1 Map reduce
一棵树.
10.2 Unix角度批处理
all things are files.
file -> ordered bytes.
