Mysql学习
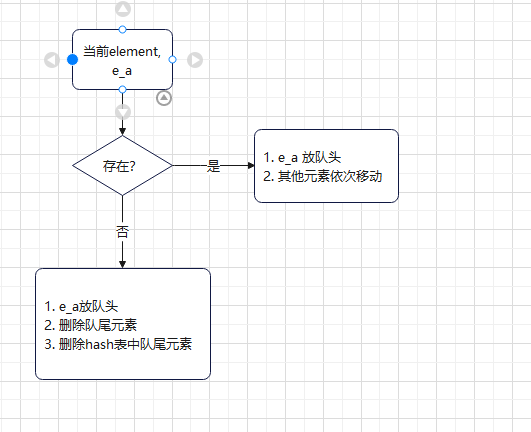
LRU算法
Least Recently Used. (最近最不可能访问算法). 就是从当前被访问时间点往前推,查找最不可能被访问的内容。(从当前位置向前找 最远未被使用的内容)。
example

使用的数据结构,HashSet, 双向链表
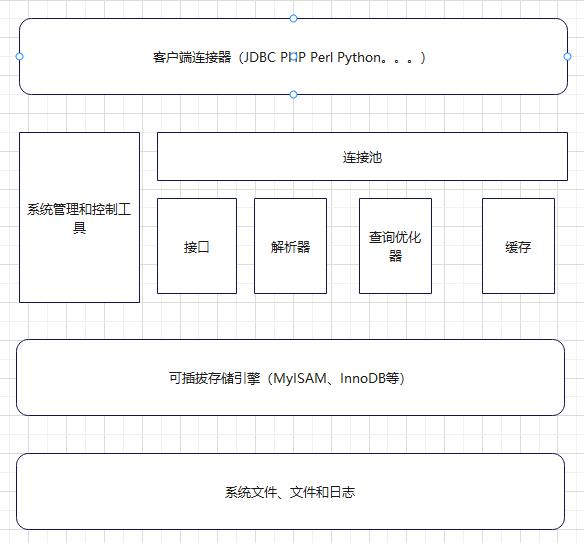
1.5 Mysql架构
1.6 日志文件
1)错误日志
2)查询日志
3)二进制文件
记录了对mysql数据库执行的更改操作并且记录了语句发生的时间,执行时长;但是不记录select、show tables等不修改数据的SQL。主要用于数据库的恢复和主从复制
4)慢查询日志
超时查询日志,long_query
1.7数据文件
frm 表结构和定义等信息
myd MyISAM存储引擎专用,村原数据的
myi MyISAM引擎专用,索引文件
ibd,存放InNoDB数据文件,包括索引
ibdata1文件,数据文件
配置文件
my.cnf, my.ini
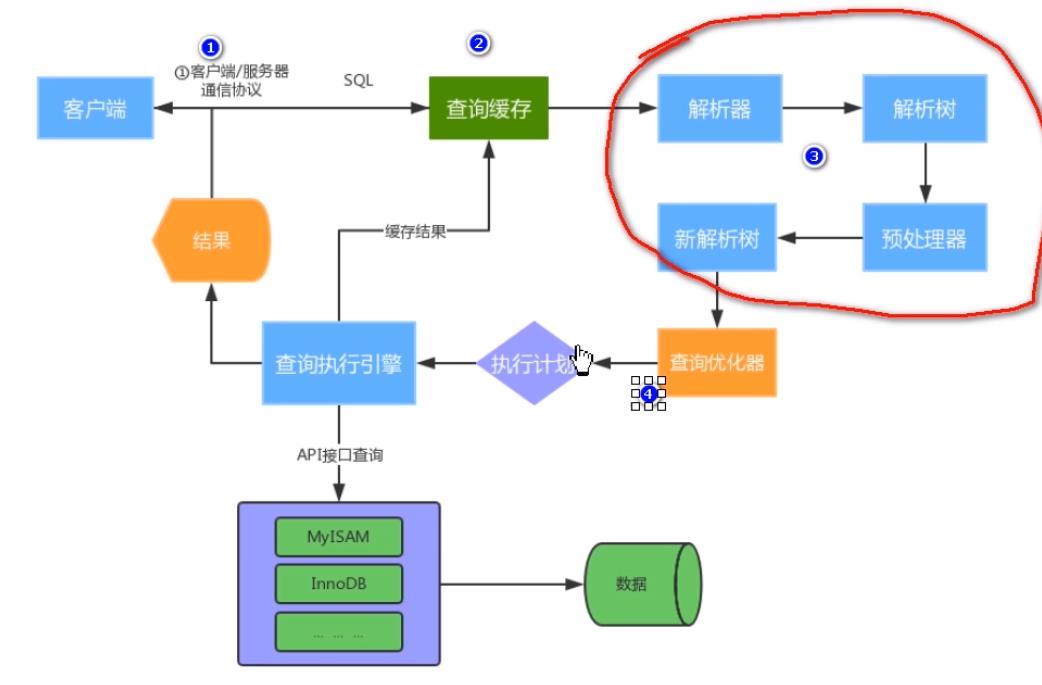
1.8 SQL运行
1.9 连接机制 (communication)
全双攻机制(full-duplex):能同时发送、接收数据
半双工机制 (half-dulex):一个时刻只能发或者接数据
单工 (simplex):只能发送数据或者接收数据
线程状态:
show processlist, 用户运行线程信息
1.10 查询缓存机制
一级缓存 (L1 Cache)、二级缓存 (L2 Cache)。缓存SQL语句和查询结果
执行select查询时,先查询缓存,判断是否存在可用的记录集,要求是否完全相同
1.11 解析和优化
- 等价变化策略:5=5 and a > 5 改成 a > 5
- a < b and a = 5
优化count、min、max
1.13 存储引擎
1) Innodb 支持事务,具有提交、回滚和崩溃处理能力,事务安全
2)MyISAM 不支持事务,不支持外键,访问速度快,有利于查询
3)Memory:利用内存创建表。默认使用了hash,而且使用Hash。一旦关闭就会丢失。
4)Archive:归档类型引擎。仅能支持insert和select语句
5)Csv:以CSV格式文件进行数据存储,由于文件限制。所有列not null,不支持索引和分区。适合做数据交换
6)BlackHole:只进不出,进来小时,所有插入数据都不会保存。
7)Federated:可以访问远端mysql数据库的表。一个本地表,不保存数据,访问远程表内容
8)Merg_MyISAM: 一组MyISAM表的组合,这些MyISAM表结构必须结构先沟通,Merge表本身没有数据。
1.14 InnoDB和MyISAM表的区别
| InnoDB | MYISAM | |
| 事务和外键 | 支持事务和外键。适合大量添加大量添加,update的操作。具有安全性和完整性 | MyISAM不支持事务和外键。提供高速存储和检索,适合大量的select查询操作。 |
| 锁机制 | 支持行级锁,锁定指定记录。基于索引加锁 | 支持表级锁,不支持整张表。 |
| 索引结构 | 聚簇索引,索引和记录一起存储,既缓存记录,也缓存索引 | 非聚簇索引,索引和记录是分开的。 |
| 并发能力 | 读写阻塞有4个隔离级别。与隔离级别有关。可以采用多版本并发控制。高并发触发能力强 | 表锁,写操作导致并发效率低,读不影响 |
| 存储文件 | 两个文件,frm表结构,idb,数据文件 最大64TB | 三个文件,frm表结构,myd,表数据,myi存储索引文件。从MYSQL 5后,最大256TB |
| 使用场景 |
|
|
绝大多数场景使用Innodb。
1.15 InnoDB存储结构
1)内存结构
Buffer Pool (由一个个page组成, page在InnoDB访问表记录和索引时会在Page页中缓存,减少IO提升效率)
- Free page: 空闲
- Clean page:被使用。数据没有被修改过(page页)
- Dirty page:被使用,数据被修改过(page页,和磁盘不一致了,需要刷盘。 例如:本来有一个clean page,但是现在有个请求对数据修改,直接改这个cleanpage 就产生了dirty page)
Change Buffer(写缓冲区,占用BufferPool空间,默认占用25%,最大可以占用50%,对于buffer pool没有的数据进行操作,会直接在change buffer进行操作,不用再去磁盘差数据。避免一次磁盘IO,下一次查询会先进行磁盘读取,然后再从change buffer中读取信息合并,最终载入buffer pool)
Log Buffer (缓冲区满了,刷到磁盘,Redo,Undo)
2)Page管理机制。(集中类型,free page,clean page,dirty page,通过三种链表结构来维护和管理。)
free list
flush list 需要刷新到磁盘的缓冲区 (dirty page)
lru list 正在使用缓冲区 (有clean page 和 dirty page)
3)改进LRU算法维护
普通LRU算法:新数据从链表头插入,释放空间从末尾淘汰
改进LRU算法:链表分为new和old,添加元素并不是从表头插入,而是从中间midpoint插入
4)磁盘结构
Tablespace
5)存储结构
现在默认是独立表空间。一个表一个idb,frm。
idb->Segment ->Extent -> Page -> Row

- Segment, 一个表至少两个segment,一个管理数据,一个管理索引。每多一个索引,多两个Segment。
- Extent(64个连续的page,大小为1M,当表空间不足,不会一页一页分,直接分配一个区)
- page 默认16k,用于存储多个Row。包含很多page类型。
- Row 事务ID用于回滚操作,Roll Pointer
1.27 Undo Log
1)介绍
以回滚为目的。 Undo Log 在事务开始之前产生,事务在提交时候,并不会立刻删除Undo Log。Innodb会将该事务对应的Undo Log放入到删除列表中。
例如我们执行一个delete,Undo会记录一个insert,执行一个update,Undo会记录一个相反的update。
采用段的方式管理和记录。在Innodb文件中包含rollback segment,内部包含1024个Undo Log。
2)作用
- 实现实物的原子性。保证实物一致性。如果需要RollBack 可以利用Undo对实物恢复
- 实现多版本并发控制MVCC。其他事物要读、同时另一个事物要写,读Undo读快照信息。
1.28 Redo Log
1)介绍
随着事物的生成,会产生Redo Log。脏页写入了磁盘,则Redo Log删除。在数据库发生意外时,重做. 比较像 WAl。因为Redo Log 是顺序写,所以比较快,但是db里磁盘中的数据不是顺序的。所以不直接写入DB。
2)工作原理
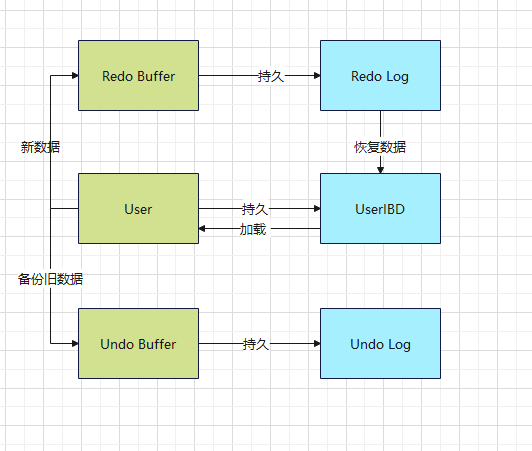
RedoLog 是连续的记录快,磁盘的User非连续。直接写磁盘会影响IO。
RedoLog 是一个循环写的模式写入文件。一个WritePos,一个Checkpoint
1.29 Binlog日志写入模式和文件结构
1)使用场景:
主从复制:主库开启。可以主库数据binlog传递给从库。达到主从数据一致。
数据恢复:删库,删表了后可以恢复。通过mysqlbinlog恢复数据
2)文件记录模式:
- Row。记录每一行的修改情况。比较安全。但是会产生大量日志。如果有足量的空间可以使用。能完全实现主从数据同步和恢复。
- Statement。每一条sql语句会记录。sql语句的复制。日志量少。有时候不安全,UUID,时间Now,如果SQL语句带这些函数,则可能不能完全记录。
- Mixed。混合
3)Binlog文件结构
不同的操作有不同的log event
1.30 Binlog 日志记录机制
操作以事件记录,封装成log_event结构。保存类型,保存到一个binlog_cache_mngr数据结构中。不同log event是以串行方式写入binlog。
1.31 Binlog日志分析和数据恢复
1)mysqlbinlog 命令
mysqlbinlog --start-datetime='' --stop-datetime=''
2)mysqldump, 定期备份数据
3)可以删除binlog
1.31 Redo Log 和binlog区别
- Redo Log属于InnoDB引擎,binlog属于mysql Server的,层次不同
- Redo Log是属于物理日志,记录数据页更新状态内容,binlog记录更新过程
- Redo Log是一个循环系统(两个日志,日志空间固定),binlog是增量写入,不会覆盖使用
- Redo Log是服务器异常(宕机,数据恢复自动使用),binlog可以作为主从复制或数据恢复,需要手动恢复
2.2 索引类型
1)普通索引
2)唯一索引
- 可以空
3)主键索引
- 不允许空
4)复合索引 compound index
- 可以替代多个单一索引,节省开销
5)全文索引 fulltext index
- 有最大最小内容长度限制,可以改
- 有切词方法
- 效率比like高
- 有单独的语法格式, match against。(默认等值匹配)
- 全文索引必须在字符串,文本上建立
2.4 索引原理
索引是:存储一引擎用于快速查找记录的数据结构,需要额外开辟空间和维护。
- 索引是物理数据存储,在数据文件中(InnoDB, .ibd文件),利用数据页(page)存储
- 降低增删改操作,加快检索速度
1)二分查找
- 如果数是有序的,则查找效率高
2)hash索引
- Memory引擎
- Innodb引擎,在内存结构中有hash索引,一次性查找就能定位数据,等值查询效率由于B+Tree。当查询某一个值特别频繁,会生成一个hash索引。会根据热点来创建。
3)B+树
B 树
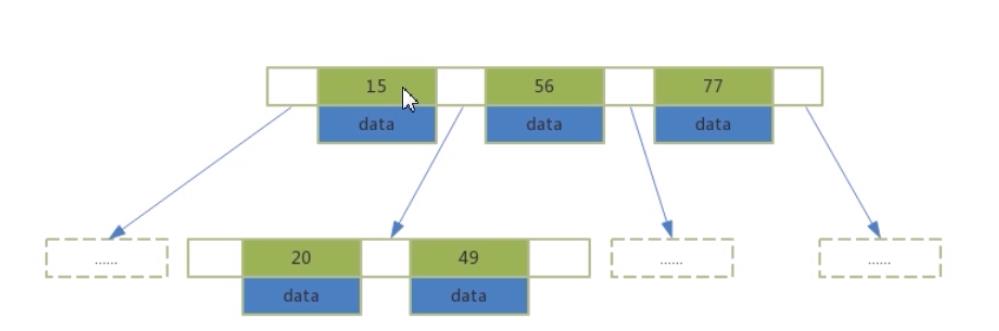
- 索引值和data数据在整棵树中
- 每个节点可以存放多个索引以及data数据
- 树节点是从左到右升序排列
B+树
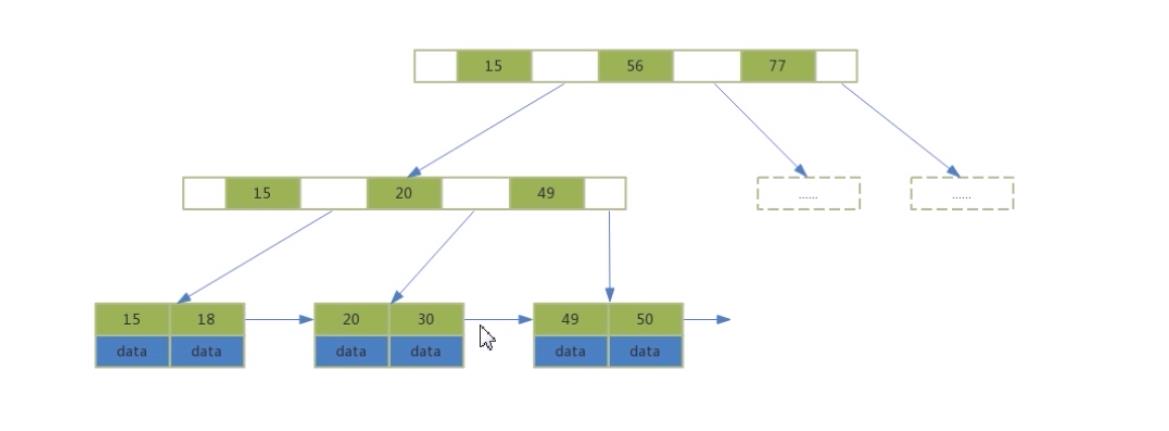
- data数据全在叶子节点
- 非叶子节点只有索引,可以存更多索引值,有利于区间查找
- 叶子节点包含了所有的索引值和data数据
- 叶子节点用指针链接,提高了区间访问的性能
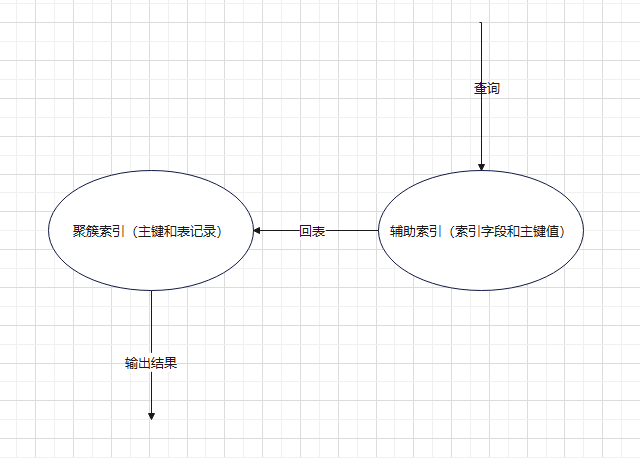
2.7 聚簇索引和辅助索引
1)聚簇索引
索引是主键索引
叶子结点是行值
InnoDB必须有聚簇索引。
- 定义了主键,则自动有主键索引,
- 如果没有主键,则第一个非空的unique作为聚簇索引
- 如果都没有,则自己创建一个row-id 作为聚簇索引
2)辅助索引
二级索引,占用空间比主键小,提升查询效率。辅助索引存的是主键的值和索引值。就相当于对不是主键其他列做搜索。可以有多个辅助索引。非主键就是辅助索引
2.8 Explain查询分析
|
字段 |
说明 |
|
Select_type |
表示查询类型,SIMPLE,PRIMARY,UNION,DEPNEDENT,UNION RESULT, SUBQUERY.... |
|
type |
|
|
possible_keys |
并不一定会真正使用 |
|
keys |
查询时候真正走的索引 |
|
rows |
估算需要扫描的行数 |
|
key_len |
表示查询使用的字节数量,是否全部使用了组合做引 |
|
Extra |
|
2.11 索引优化
| 优化点 | 针对情况 | 说明 |
| 覆盖索引 |
有时候查询会回表。遍历两颗树
|
只需要在一棵树上就能获取所有列的数据,无需回表, 尽量使用组合索引, |
| 最左前缀原则 | compund index 使用时,最左优先,如果从第二列开始查找则不会使用索引 |
select id from user where age = 18 and name = 'a' 如果对 age 和 name 加联合索引,则索引生效 select id from user where name = 'a' 索引不起作用,因为name是在第二列。不能放开头 |
| 索引和like |
使用 like 模糊查询时候 索引能不能起作用
|
|
| 索引和Null | 如果 某一列NULL值,索引还有效吗? | 可以用。但是不建议用。Null的索引需要更多的存储空间 |
| 索引和排序 |
|
如果有where 和order by 可以创建联合索引 带有范围查找的 即使用了组合索引也不好用 一个升序 一个降序也不行 |
2.17 查询优化
| 优化点 | 解决问题 | 说明 |
| 慢查询应用 | 有些sql慢 |
show valiable slow_query 然后看OKA-slow.log。看有哪些慢sql |
| 慢查询优化 |
所有慢查询都是没有使用索引引起的吗? 不一定。select * from user where id > 0. 也是全表扫。 |
|
| 分页查询优化 | select ... limit [offset] rows |
分页查询每次都会从第一条记录开始扫描,越往后越慢, 可以利用覆盖索引优化 利用子查询优化 |
3.1 ACID特性
| Atomicity 原子性 |
事务要么全执行,要么全不执行 修改->Buffer Poll -> 刷盘. |
|
| Consistency 一致性 | 事务开始之前,结束之后,数据库的完整性未被破坏。其他三个特性保证了数据的完整性 |
|
| Isolation 隔离性 | 一个事务的执行不被其他事务干扰 |
隔离级别
|
| Durability 持久性 |
对数据库改变是永久的。 可以通过原子性保证逻辑上的持久性 可以通过刷盘保证物理上的持久性 |

|
WAL。先写日志,再写磁盘。3个特性与WAl。原子隔离持久与WAL有关
3.2 MYSQL并发
要对事务控制。要不然会有一些问题,脏读、数据丢失、幻读等。
- 更新丢失: 多个事务更新同一行信息丢失。(回滚覆盖,提交覆盖,一个事务提交操作,把其他事务已提交数据给覆盖了)
- 脏读 dirty read:一个事务读取到了另一个事务修改但未提交的数据
- 不可重复读 not repeatable read:一个事务多次读同一行数据 结果不同
- 幻读 phantom read:一个事务中多次按相同条件查询,结果不一致。后续查询结果和前面查询结果不同,多了或少了几行数据
3.3 事务控制的演进
排队-> 排他锁 (相同事务加锁)-> 读写锁 -> MVCC
3.4 MVCC
Copy On Write。当有读写操作时候。可以对数据进行备份,然后对元数据加锁写。备份记录可以用于其他事务的读取。也可以进行必要数据回滚。只在Read Committed 和 Repeatable Read 两种隔离级别下工作
- Snapshot read:读取的是记录的快照版本,不用加锁 (在RR级别下,会在内部创建view视图,后面就不创建直接看第一次创建的view。在RC级别每一次生成一个view,根据最新记录。select 是快照读。)
- Current read:读取的是记录的最新版本,并且当前返回的记录,都会加锁。(当select 后面加for lock 或者 lock。是当前度,insert / delete /update 也会触发当前读)
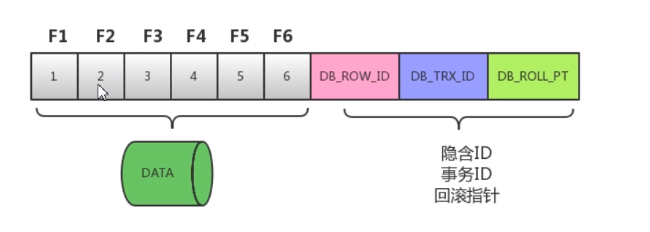
- 隐含ID :INNODB 产生聚集索引产生的值
- 事务ID :每处理一次事务 ID+1
- 回滚指针:回滚的话到哪个状态
F1~F6 为字段。1~6为值。 操作一条数据的步骤
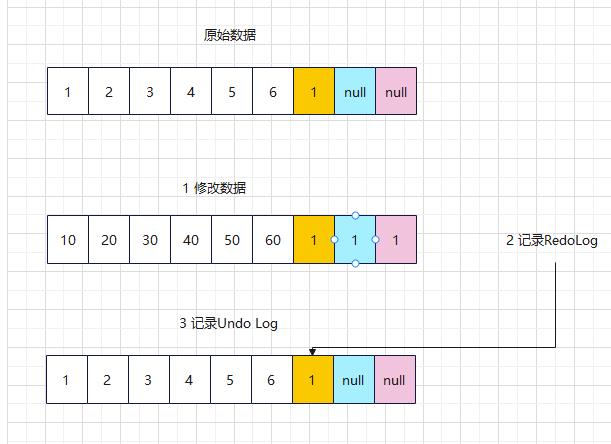
Undo Log会越来越多,有一个线程会清除UndoPage。如果要解决写、写操作可以使用。读这个Undo Log就可以实现 Snapshot Read
- 乐观锁 (谁先改谁占有)
- 悲观锁 (对记录加锁)
3.6 事物隔离级别
| 事物隔离级别 | 说明 | 回滚覆盖 | 脏读 dirty read | 不可重复度 not repeatable read | 提交覆盖 | 幻读(第一次没有的数据)phantom read |
| 读未提交 | 可能发生脏读,可能读取到其他会话中未提交事物修改的数据 | x | 可能发生 | 可能发生 | 可能发生 | 可能发生 |
| 读已提交 read commited | 只能读取到其他会话中已经提交的数据,解决了脏读,但会出现不可重复读 | x | x | 可能发生 | 可能发生 | 可能发生 |
| 可重复读 repeatable read | 确保多个实例并发并读取数据,看到同样的数据 使用snapshot,就可以解决 | x | x | x | x |
可能发生 (session B 插入,session A update 插入的数据就会出现) 使用间隙锁解决了很多 幻读问题。 |
| 串行化 serialization | 强制事物顺序执行 | x | x | x | x | x |
就是并发带来的一些问题。同一事物读的结果不一样。
Example:
两个 session
1) begin ....(一些操作,例如很多次读) commit
2) begin ... (一些操作,例如很多次写,更新) commit
例如,session 1)在查询时候 有不同结果,但是还没commit, 因为 session 2进行了不同操作
3.7 事物隔离级别和锁的关系
1)事物隔离级别和锁的关系
- 事物隔离级别是SQL标准,相当于事物并发控制的解决方案。是对锁和MVCC的一种封装
- 锁是控制并发控制的基础
- 对于用户来说,首先选隔离级别,当隔离级别不能解决问题时候,再考虑手动设置锁
2)隔离级别控制
可以用命令行 输入 begin开始。
3.8 锁分类
颗粒度
- 表级锁
- 行级锁
- 页级锁
操作
- 读锁,共享锁(可以一起读追加共享锁,不能改),读不影响
- 写锁,拍它锁,会阻断其他读、写
操作性能:
- 乐观锁
- 悲观锁
3.10 Next-Lock
Innodb 主要对索引加锁,来实现对记录的锁定
- RecordLock 单行锁,RC,RR级别
- GapLock范围锁 。(比如一条记录是2,上一条数据是1,不允许往1 和 2 之间修改数据,这个是间隙锁, RR级别)
- Next-key Lock。上面两个组合,RR级别
如果SQL包含唯一索引,则Next-key Lock 降级为RecordLock。默认为Next-key Lock
1)select ... from 普通语句不加锁
2)select ... from lock in share mode 追加共享锁,会使用next-key lock。如果有唯一索引,则能降级
3)select ... from for update 会使用next-key lock。如果有唯一索引,则能降级
4) update ... where 会使用next-key lock。如果有唯一索引,则能降级
5) delete ... where 会使用next-key lock。如果有唯一索引,则能降级
3.11 锁定原理
基于索引锁记录
在唯一索引加锁,再在逐渐记录加锁
非唯一键,锁记录和间隙
无索引,锁表
例如:
DB: id = 10, 有两条记录并且id是非唯一键
session_1 ,select * from db where id = 10,
session_2, insert 10,
如果不加间隙锁,则会幻读,select * from db where id = 10, 会出现三个记录
加了间隙锁,则不能插入,阻塞
3.15 MYSQL死锁分析
1)表级死锁产生原因
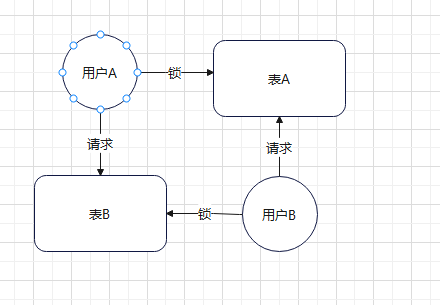
用户A、B分别锁住了表A、B。然后分别还想请求表B、A,就会阻塞在这里。
2) 表级死锁解决方案
这种死锁比较常见。属于程序上的bug。调整程序的逻辑。
3)行级别死锁原因
- 没有使用到了索引,引发全表扫描,导致锁表 用explain 检查下
- 两个事物分别想拿对方的锁,导致死锁
4)共享锁转换为排他锁
也是逻辑有问题。
4.1 集群架构设计理念
- 可用性
- 可扩展性
- 一致性
4.2 主从模式
保证可用性。数据可以从一个主节点复制到多个从节点。可以将 主库数据异步方式发给从库。
1)主从复制用途:
- 实时灾备,用于故障切换
- 读写分离,提供查询服务
- 数据备份,避免影响业务
2)主从部署条件:
- 主库开binlog
- 从库能连主库
- 主从sever-id 不同
3)异步复制原理:
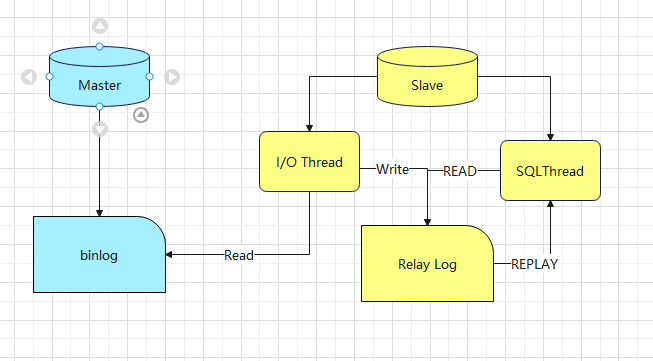
- 主库将数据库的变更记录到Binlog
- 从库读取主库的binlog日志文件信息写入到从库的relay log
- 从库读取中继信息,在从库回放,写入到从库
4)存在问题
- 有延迟 (并行复制)
- 主机宕机有可能丢失数据 (半同步复制)
5)半同步复制
在某个时间点,主库接收到Slave ACK再进行事物提交Commit 交半同步复制。
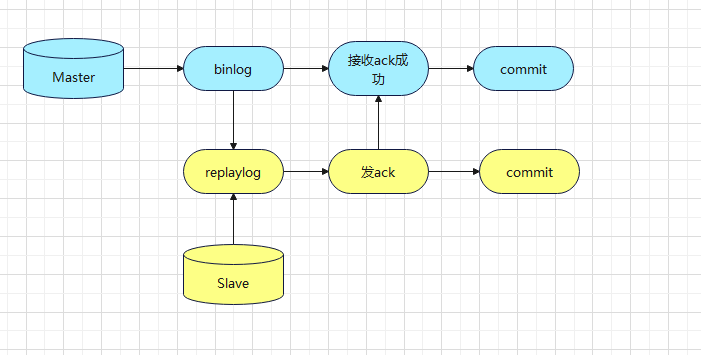
6)并行复制
IO Thread 和SQL Thread都是单线程模式。因此有了延迟问题。可以用多线程加强复制能力。让SQl Thread 使用多线程,来增加从库复制的速度。IO多线程意义不大。
也可以基于库的并行复制思想
4.12 读写分离

可以主机不加索引提升写效率,在从库追加索引,来优化查询。
延迟问题:
- 写入数据库后,某个时间段读主库,其他时间读从库
- 二次查询。先读从库,没有读主库
- 根据业务特殊处理
1)读写分离分配机制
- 基于编程配置 (应用广泛)
- 基于服务代理(内部控制数据操作的分发)
4.15 双主模式
如果是双主或者多主,提升了主库的可用性。
1)双主双写 还是双主单写?
建议使用双主单写。双主双写存在问题:
- ID冲突。比如主键(对于一台服务器A,同时写然后同步,主建会产生冲突, 同步过来的主键是1,同步有可能是2了)
- 更新丢失。(同一条记录在两个节点进行更新,会发生前面覆盖后面的更新丢失)
2)双主模式主备切换模式
可靠性优先和可用性优先。
4.20 数据库分表 垂直拆分
一个表数据量一般控制在 1000万一下。如果数据太多了,则需要NOSQL或者分库分表
1)垂直拆分
将表拆分到多个库中。
拆表。把列拆开。
优点:
- 业务明细了
- 解决字段过多
缺点:
- 数据量没少
- 表多了
2)水平拆分
一个表横着拆到多个表里面去
优点
-
解决数量过多
缺点
- 垮库join性能差
- 拆分规则不好定义
- 扩容维护难度大
4.24 扩容方式
- 数据迁移问题
- 分片规则
- 数据同步、时间点、数据一致性
1)停机扩容
- 几点几点升级。
- 改切片规则
- 数据迁移完成
- 重启服务
2)平滑扩容
要成倍的扩容。例如(2个变4个)
- 在扩容期间,对外服务不停。
- 新增数据2个数据库
- 配置双主进行数据同步
优点:
- 保证服务高可用
- 扩容器件,服务正常进行
- 相对于停机扩容,项目组压力小出错率相对低
- 扩容期间遇到问题,随时解决,不怕影响线上服务
缺点:
- 配置双主双写,
- 双主双写
- 检测数据同步性
- 服务器多的话,后期数据库扩容代价很高
使用大型网站,对高可用要求比较高
