Uplift Modeling
一、背景
在促销活动,或者补贴、发红包活动中,如果我们能准确瞄准相应人群,那么即可以促进购买数量,也可以节约成本(本来就可以购买的人群不用额外发放红包)。
二、一些基础
Uplift用于筛选出这类人群。(如果对其采取了补贴,则可以转化为订单)。Uplift模型比较了treatment(投放补贴)客户与 control(不投放补贴)客户之间的差异。我们用 Y 表示 action,
Y = 1 表示购买物品,Y = 0 时表示不够买物品。W表示人群,1为treatment表示发补贴;0表示control表示不发补贴。下图 persuadable是我们要找的客户。
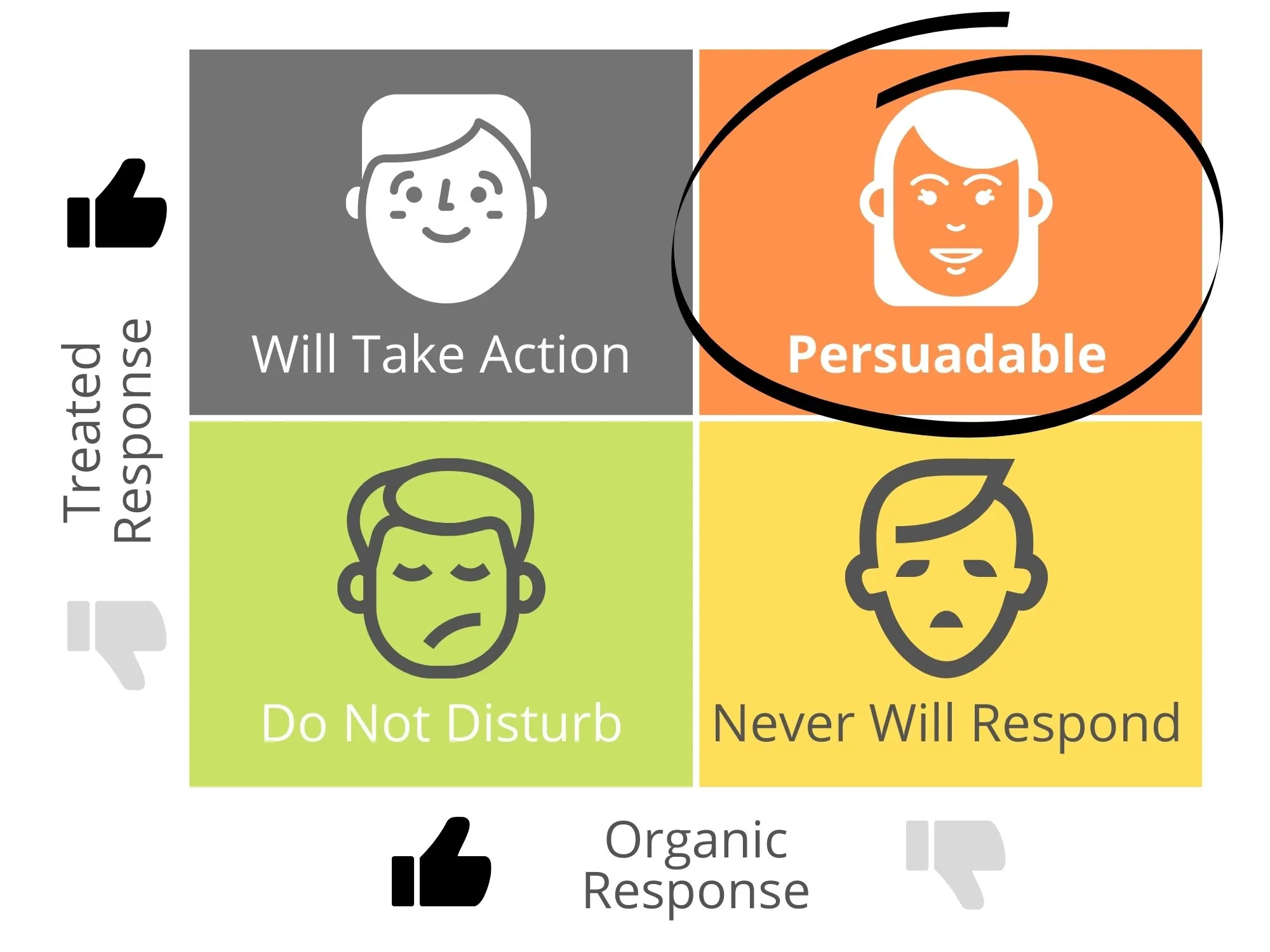
我们将客户分为4类。
- Will Take Action。会购买物品不管是否发补贴。(Y = 1 && W = 1 and Y = 1 && W = 0 )
- Persuadable.。发补贴购买物品否则不买。(Y=1 && W = 1 and Y = 0 && W = 0)
- Do Not Disturb。发补贴不买,不发补贴买。(Y = 0 && W = 1 and Y = 1 && W = 0)
- Never Will Respond。发不发补贴都不买。(Y = 0 && W = 1 and Y = 0 && W = 0)
1)上标1为treatment, 0 为control;下表 i 表示第 i 个样本
2)因果效果(Casual Effect) :$\tau _{i}=Y_{i}^{1}-Y_{i}^{0}$
3)因果效果期望:$CATE=E[Y_{i}^{1}|X_{i}]-E[Y_{i}^{0}|X_{i}]$. $X_{i}$表示i类子人群
4)不能同时用户i又发了补贴,又没发补贴。用户i的结果可以表示为: $Y_{i}^{obs} =W_{i}Y_{i}^{1}-(1-W_{i})Y_{i}^{0}$
5)由 4),CATE的估计为:$\widehat{CATE}=E[Y_{i}^{obs}|X_{i}=x,W_{i}=1] - E[Y_{i}^{obs}|X_{i}=x,W_{i}=0]$ . (注意, 在$X_{i}=x$条件下,$W_{i}$应该独立于 $Y_{i}^{obs}$, 也就是表名用户进入treatment组 或者 contrl组 是随机的。)
6) 倾向分 Propensity Score. $P({X_{i}}) = P(W_{i}=1|X_{i})$. 即用户进入到treatment的概率。
三、Uplift Modeling
1 Two-Model Approch
使用两个模型,一个训练 Treatment的数据,一个训练Control的数据。最后用 Prob(Treatment) - Prob(Control) 得到 uplift score。
2 The Class Transformation Approach
试用于$Y_{i}^{obs}$ 只为1、或者0的情形。构造目标函数
1)$Z_{i}=W_{i}Y_{i}^{obs}+(1-W_{i})(1-Y_{i}^{obs})$
在实验组且用户购买或者对照组用户无响应时,$Z_{i}=1$,其他情况 $Z_{i}=0$ 。 当 $P({X_{i}}) = 1/2$时候,可以证明:
2)$\tau (X_{i})=2P(Z_{i}=1 | X_{i})-1$
此时对$P(Z_{i}=1 | X_{i})$建模即可。缺点是对实验组、对照组样本分布要求严格都为1/2。当样本分布不均匀时候:
3)$Y_{i}^{*} =\frac{W_{i}}{\hat{p}(X_{i})} Y_{i}^{1}-\frac{(1-W_{i})}{(1-\hat{p}(X_{i}))}Y_{i}^{0}$
转换后可得
4)$\tau (X_{i})=E[Y_{i}^{*}|X_{i} ]$
转换后得了
5)$Z_{i}=\frac{1}{2} Y_{i}^{*}+(1-W_{i}) $
此时可得
6)$2E[Z_{i}|X_{i}]=E[Y_{i}^{*} |X_{i}]+1$
3 Modeling Uplift Directly
传统的树模型的分裂规则,例如ID3,是根据信息增益计算是否按照某个特征分裂。
1)$Gain(D|A)=H(D)-H(D|A)$
这种思想也可以引入到 Uplift Model中。
2)$Gain=D_{after\_split}(P^{T},P^{C})-D_{before\_split}(P^{T},P^{C})$
D表示两组分布的差异程度。可以用KL散度,欧式距离等。
3.1 Decesion Trees For Uplift Modeling.
以 Decesion Trees for uplift modeling. 因果树为例子学习一下。 论文下载点此处。一种分裂方法是计算 $\Delta \Delta P$.
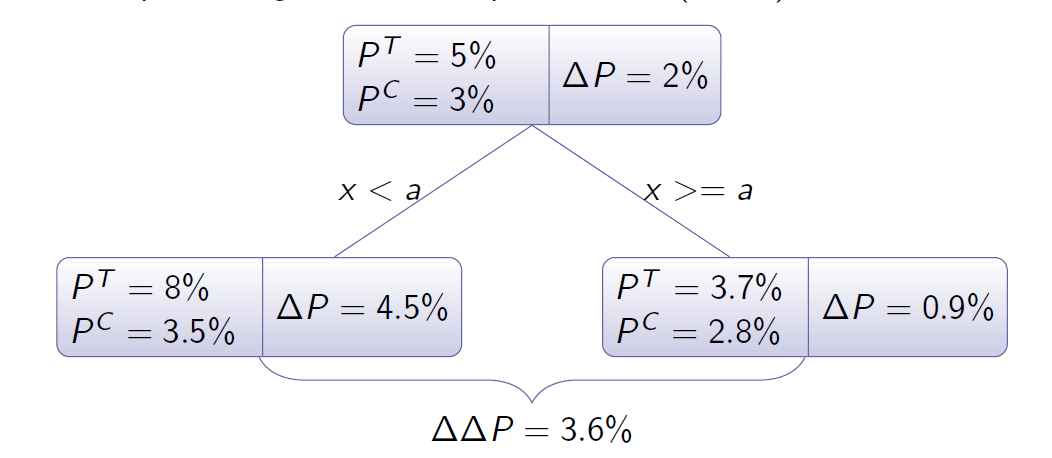
论文里使用的评判标准为 KL散度。
1)$KL(P^{T}:P^{C})=\sum P^{T}log\frac{P^{T}}{P^{C}} $
计算在一个测试集的条件KL散度
2)$KL(P^{T}:P^{C}|Test)=\sum \frac{N^{T}(a)+N^{C}(a)}{N^{T}+N^{C}} KL(P^{T}(class|a):P^{C}(class|a))$
KL散度增益
3)$KL_{gain}(Test)=KL(P^{T}:P^{C}|Test)-KL(P^{T}:P^{C})$
在测试集上,算分裂前的KL散度和分裂后的KL散度。
同样可以使用欧几里当作分裂标准。欧几里得评判标准有更好的统计特性。(有限、对称性)
4)$Euclid(P^{T}:P^{C})=\sum(P^{T}-P^{C})^{2}$
剪枝。定义
5)$Diff(Class,node)=P^{T}(Class|node)-P^{C}(Class|node)$
6)$MD(node)=max_{Class}|Diff(Class|node)|$
7)$sign(node)=sgn(Diff(Class^{*},node))$
如果子树被一个叶子结点代替后,验证集的MD值变小 并且如果MD的sign值在验证值和训练集一样则保留子树。 一个有用的Python包为 Causalml。下载使用参考链接
4 Multi-Classification Model 多分类模型
在文章开始,可以将样本分为4类。
- Control Non-Responders (CN)
- Control Responders (CR)
- Treatment Non-Responders (TN)
- Treatment Responders(TR)
然后将分类后的数据喂入模型最后计算 uplift_score. $Uplift\_Score = \frac{P(TR)}{P(T)} + \frac{P(CN)}{P(C)} - \frac{P(TN)}{P(T)} - \frac{P(CR)}{P(C)}$
四、评估
1) decile chart.
对用户计算相应 uplift_score之后,然后对用户进行排序(按照uplift_score由高到低)。然后按照排序结果根据需求按照百分位进行分组,最后计算每个分组的平均uplift_score。无法比较模型之间的好坏。
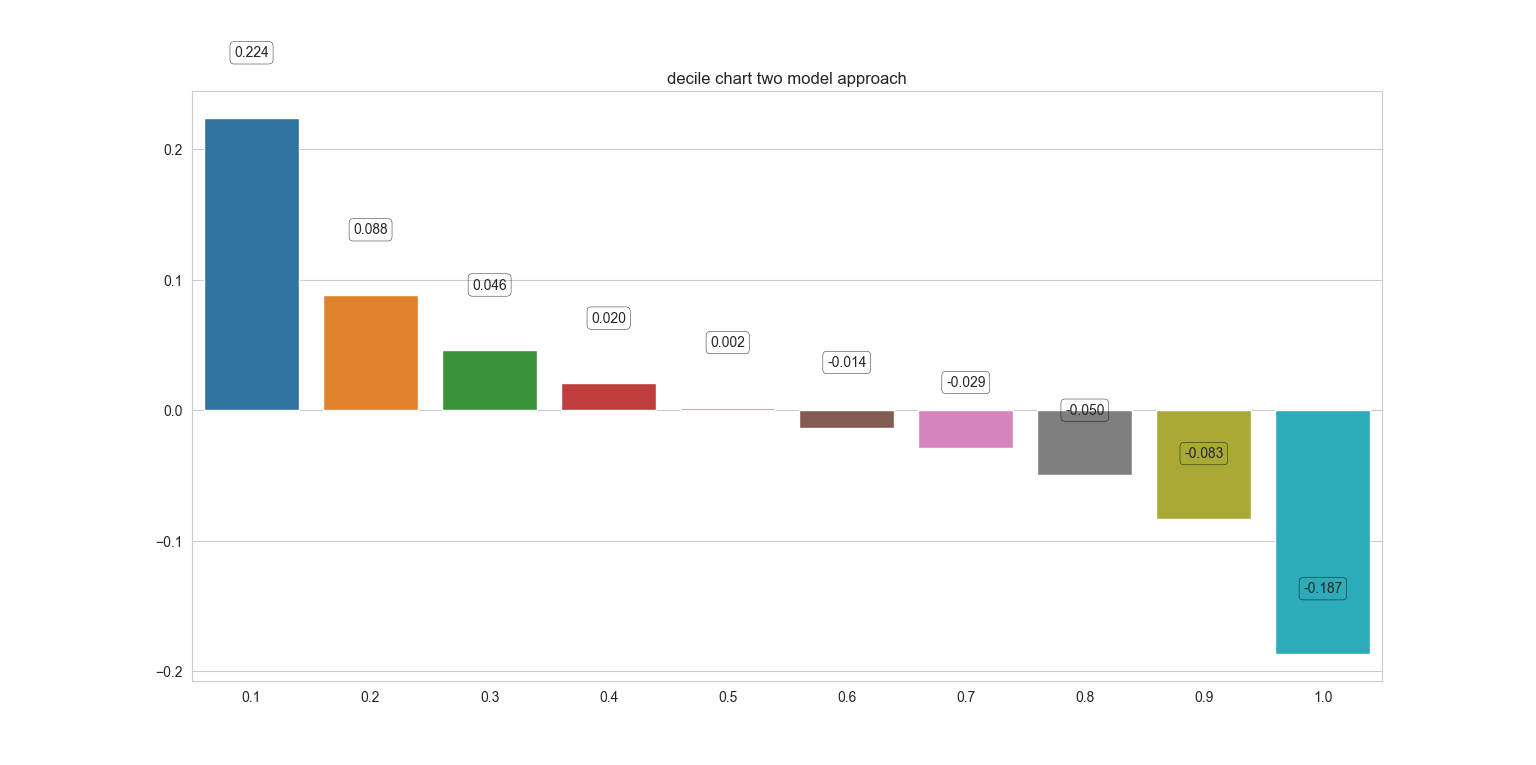
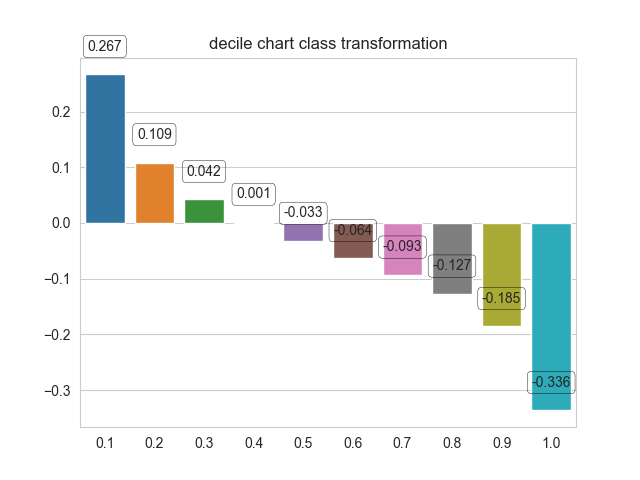
2) AUUC
最常用的评估方式为AUUC。$G(i)=(\frac{N_{y=1,t=1}}{N_{t=1}}-\frac{N_{c=1,t=1}}{N_{c=1}})*(N_{t=1}+N_{c=1})$
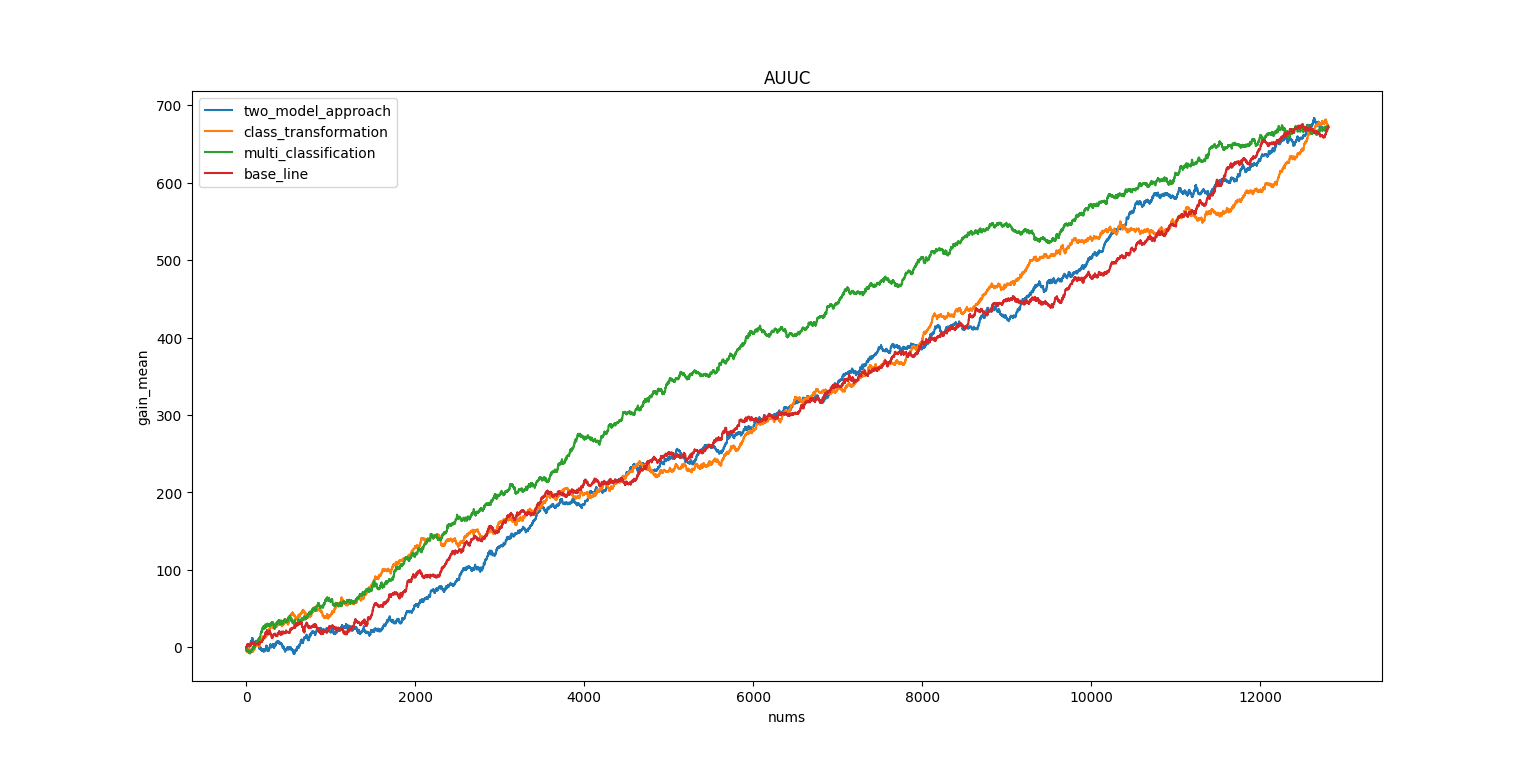
用五的例子分别算了各种模型的AUUC。可以看出 TWO-MODEL最差,MultiClassification 最好。
五、Example
选取 Kaggle一篇关于促销活动当作学习例子。https://www.kaggle.com/datasets/davinwijaya/customer-retention
CODE:
from scipy.spatial import distance from sklearn.neighbors import NearestNeighbors from sklearn.cluster import DBSCAN import numpy as np from math import * from scipy.spatial.distance import pdist, squareform from sklearn.cluster.tests.common import generate_clustered_data import matplotlib.pyplot as plt import pandas as pd import seaborn as sns, warnings warnings.filterwarnings('ignore') data_raw = pd.read_csv("C:\\Users\\nan.wu2\\PycharmProjects\\job\\study\\data\\data.csv") df_model = data_raw.copy() """ ['recency', 'history', 'used_discount', 'used_bogo', 'zip_code', 'is_referral', 'channel', 'offer', 'conversion'] """ # Rename target column df_model = df_model.rename(columns={'conversion': 'target'}) # Rename & Label encode treatment column df_model = df_model.rename(columns={'offer': 'treatment'}) df_model.treatment = df_model.treatment.map({'No Offer': 0, 'Buy One Get One': -1, 'Discount': 1}) df_model = pd.get_dummies(df_model) df_model_bogo = df_model.copy().loc[df_model.treatment <= 0].reset_index(drop=True) df_model_discount = df_model.copy().loc[df_model.treatment >= 0].reset_index(drop=True) def declare_tc(df: pd.DataFrame): # CN df['target_class'] = 0 # CR df.loc[(df.treatment == 0) & (df.target != 0), 'target_class'] = 1 # TN: df.loc[(df.treatment != 0) & (df.target == 0), 'target_class'] = 2 # TR: df.loc[(df.treatment != 0) & (df.target != 0), 'target_class'] = 3 return df df_model_bogo = declare_tc(df_model_bogo) df_model_discount = declare_tc(df_model_discount) from sklearn.model_selection import train_test_split import xgboost as xgb def uplift_split(df: pd.DataFrame): df.treatment = df.treatment.map({-1: 1, 0: 0}) df['Z'] = df['treatment'] * df['target'] + (1 - df['treatment']) * (1 - df['target']) X = df.copy() y = df.Z X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) return X_train, X_test, y_train, y_test def uplift_class_transformation_method(X_train, X_test, y_train, y_test): uplift_model = xgb.XGBClassifier().fit(X_train.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1), y_train) result = pd.DataFrame(X_test.copy()) result['Z_prob'] = uplift_model.predict_proba( X_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1))[:, 0] result['uplift_score'] = 2 * result['Z_prob'] - 1 return result def uplift_split_two_model_approach(X_train, X_test, y_train, y_test): df_treatment_train = X_train.copy().loc[X_train.treatment != 0].reset_index(drop=True) df_control_train = X_train.copy().loc[X_train.treatment == 0].reset_index(drop=True) df_treatment_test = X_test.copy().loc[X_test.treatment != 0].reset_index(drop=True) df_control_test = X_test.copy().loc[X_test.treatment == 0].reset_index(drop=True) Xt_train = df_treatment_train.copy() yt_train = df_treatment_train.target Xt_test = df_treatment_test.copy() yt_test = df_treatment_test.target Xc_train = df_control_train.copy() yc_train = df_control_train.target Xc_test = df_control_test.copy() yc_test = df_control_test.target return Xt_train, Xt_test, yt_train, yt_test, Xc_train, Xc_test, yc_train, yc_test def uplift_two_model_approach_model(X_train: pd.DataFrame, y_train: pd.DataFrame): uplift_model = xgb.XGBClassifier().fit(X_train.copy(), y_train) return uplift_model def uplift_multi_classification_model(X_train, X_test, y_train, y_test): result = pd.DataFrame(X_test.copy()) y_train = X_train.target_class uplift_model = xgb.XGBClassifier().fit(X_train.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1), y_train) uplift_prob = uplift_model.predict_proba(X_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1)) result['prob_CN'] = uplift_prob[:, 0] result['prob_CR'] = uplift_prob[:, 1] result['prob_TN'] = uplift_prob[:, 2] result['prob_TR'] = uplift_prob[:, 3] result['uplift_score'] = result.eval( 'prob_CN/(prob_CN+prob_CR) + prob_TR/(prob_TN+prob_TR) - prob_TN/(prob_TN+prob_TR) - prob_CR/(prob_CN+prob_CR) ') return result def uplift_two_model_approach(Xt_train, Xt_test, yt_train, yt_test, Xc_train, Xc_test, yc_train, yc_test): t_model = uplift_two_model_approach_model( Xt_train.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1), yt_train) c_model = uplift_two_model_approach_model( Xc_train.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1), yc_train) result_t = pd.DataFrame(Xt_test.copy()) tt_prob = t_model.predict_proba(Xt_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1)) tc_prob = c_model.predict_proba(Xt_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1)) result_t['uplift_score'] = tt_prob[:, 0] - tc_prob[:, 0] result_t['target'] = yt_test result_c = pd.DataFrame(Xc_test.copy()) ct_prob = t_model.predict_proba(Xc_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1)) cc_prob = c_model.predict_proba(Xc_test.copy().drop(['treatment', 'target', 'target_class', 'Z'], axis=1)) result_c['uplift_score'] = ct_prob[:, 0] - cc_prob[:, 0] result_c['target'] = yc_test result = result_t.append(result_c) result['n'] = result.uplift_score.rank(pct=True, ascending=False) result = result.sort_values(by='n').reset_index(drop=True) return result def qini_rank(uplift: pd.DataFrame): ranked = pd.DataFrame(uplift.copy()) ranked['n'] = ranked.uplift_score.rank(pct=True, ascending=False) ranked = ranked.sort_values(by='n').reset_index(drop=True) return ranked def decile_chart(uplift_result, title): decile_list = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] res = [] last = 0.0 for decile in decile_list: decile_df = uplift_result.copy().loc[(uplift_result.n > last) & (uplift_result.n <= decile)].reset_index( drop=True) score_sum = decile_df.uplift_score.sum() score_count = decile_df.uplift_score.count() last = decile res.append(score_sum / score_count) sns.set_style('whitegrid') plt.figure() ax = sns.barplot(x=decile_list, y=res) for p in ax.patches: percentage = f'{p.get_height():.3f}' ##{:. 0%} x = p.get_x() + p.get_width() / 2 y = p.get_height() + 0.05 ax.text(x, y, percentage, ha='center', va='center', fontsize=10, bbox=dict(facecolor='none', edgecolor='black', boxstyle='round', linewidth=0.3)) plt.title(title) plt.show() def plotAuucValue(ranked_result, label): treatment = list(ranked_result['treatment']) target = list(ranked_result['target']) nt, nc, ntr, ncr = 0.0, 0.0, 0.0, 0.0 res = [] for i in range(0, len(target)): if treatment[i] == 1: nt += 1.0 if target[i] == 1: ntr += 1.0 if treatment[i] == 0: nc += 1.0 if target[i] == 1: ncr += 1.0 if nc == 0 or nt == 0: res.append(0) else: res.append((ntr / nt - ncr / nc) * (nt + nc)) plt.plot([ind for ind in range(0, len(res))], res, label=label) plt.xlabel("nums") plt.ylabel("gain_mean") plt.legend() return res X_train, X_test, y_train, y_test = uplift_split(df_model_bogo) Xt_train, Xt_test, yt_train, yt_test, Xc_train, Xc_test, yc_train, yc_test = uplift_split_two_model_approach( X_train, X_test, y_train, y_test) result_bogo_two_model_approach = uplift_two_model_approach(Xt_train, Xt_test, yt_train, yt_test, Xc_train, Xc_test, yc_train, yc_test) result_bogo_two_model_approach_ranked = qini_rank(result_bogo_two_model_approach) result_bogo_class_transformation = uplift_class_transformation_method(X_train, X_test, y_train, y_test) result_bogo_class_transformation_ranked = qini_rank(result_bogo_class_transformation) result_bogo_multi_classification = uplift_multi_classification_model(X_train, X_test, y_train, y_test) result_bogo_multi_classification_ranked = qini_rank(result_bogo_multi_classification) plt.figure() plotAuucValue(result_bogo_two_model_approach_ranked, "two_model_approach") plotAuucValue(result_bogo_class_transformation_ranked, "class_transformation") plotAuucValue(result_bogo_multi_classification_ranked, "multi_classification") plotAuucValue(X_test, "base_line") plt.title("AUUC") plt.show() # decile_chart(result_bogo_class_transformation_ranked, "decile chart class transformation") # decile_chart(result_bogo_two_model_approach_ranked, "decile chart two model approach")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号