Mask R-CNN 论文笔记
论文地址:https://arxiv.org/abs/1703.06870
Mask R-CNN在一个网络中同时实现了目标检测和实例分割,其结构可由Faster R-CNN扩展得到。
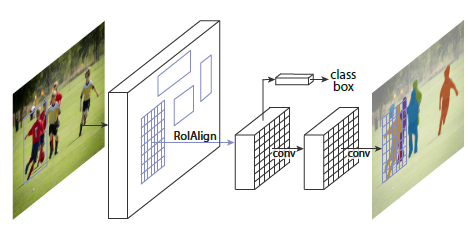
图1 Mask R-CNN网络结构
我们可以将其分为四个部分:
1. ConvNet。将输入图片经过ResNet网络得到feature map。
2. RPN。将Faster R-CNN中这里对应的RPN稍加修改,运用FCN得到更好的特征结果。
3. ROI Align。因为后续需要进行像素级的实例分割,之前Faster R-CNN中采用的ROI Pooling的两次量化操作会很大的增加误差。这里采用ROI Align对ROIs进行较为准确的pixel-to-pixel映射。
4. cls+reg+mask。在原有cls+reg基础上,增加了mask分支,由步骤3中所得特征图经卷积核大小为1*1,维度为k(k代表实例数)的卷积层得到。
ROI Align的思路就是取消ROI Pooling的两次量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作:
1、遍历每一个候选区域,保持浮点数边界不做量化;
2、将候选区域分割成k x k个单元,每个单元的边界也不做量化;
3、将每个单元均分为4个(实验表明分为4个效果较好)矩形,计算出四个矩形的中心点坐标;
4、计算出离每个中心点最近的四个整数坐标点,构成一个包含中心点的小的矩形。此时以中心点画一条垂线和水平线,可将小矩形分为4份,令左上、右上、右下、左下部分面积分别为s1、s2、s3、s4,则每个中心点像素值等于四个整数坐标点像素值与他们对应面积的乘积;
5、再对每个单元中的4个中心点做max pooling,得到固定大小的特征图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号