individual project1 12061183
1.项目预计用时
之前大二下学期的时候学过面向对象,当时老师叫我们写过一个统计目录下单词的程序,大致的思路是一样的。于是觉得这个程序并不难写。于是就在周末还很轻松地休息着不看程序,知道别的同学提醒才开始看题
下面是我的预计用时:
---遍历文件夹,得到里面的内容,一个小时。
---将字符串按三种要求进行分割,并且存入,统计每个单词出现的次数,并排序,5个小时
---输出到文件。半个小时
2.项目实际用时
仔细看了老师的要求之后,发现完全是老师下的一个迷糊阵,这个和以前的那个程序还是有很大的出入的,字符串的匹配问题比以前困难了许多,而且还涉及到了c#,本来以为可以用java写的。(表示c#c++没一个会的)同时要考虑到程序的性能问题,那就应该在单词存储,统计,频度排序那块下手,要用到dictionary,正则表达式等等,但是这些都是不会的,需要先学。花的时间就像流水一样= =
---遍历文件夹,得到里面的内容,放在一个字符串里,差不多用了一个小时。c#中文件的处理方式和java的不同,花了一些时间在文件的处理上。
---将字符串按三种要求进行分割,并且存入,统计每个单词出现的次数,并排序。加上学习各种语法所用到的时间,肯定不少于15个小时!!!!只能说坑爹的正则表达式。还有可恶的哈希表按关键字排序竟然不行,只能又改写成dictionary
---将字符输出到文件,对命令行参数进行处理,两个小时。
---自己在很多小想法上面走了弯路,浪费了很多时间。
3.项目分析和优化
在考虑项目优化问题方面,在写代码的时候,就想着要从频度排序,单词的检索两个方向去改进。对于单词的检索和频度的统计,我采用了Directory<String,count>存储。其中String是单词的小写模式,count是自己创建的一个类,含有number和word两个变量。number存储了实际要打印出来的字符串,word存储了单词的频度。采用table.OrderByDescending(r => r.Value.getnum()).ThenBy(r => r.Value.getdanci());进行排序,然后就可以根据要求得到输出。不知道是不是电脑原因,跑得竟然那么慢。。。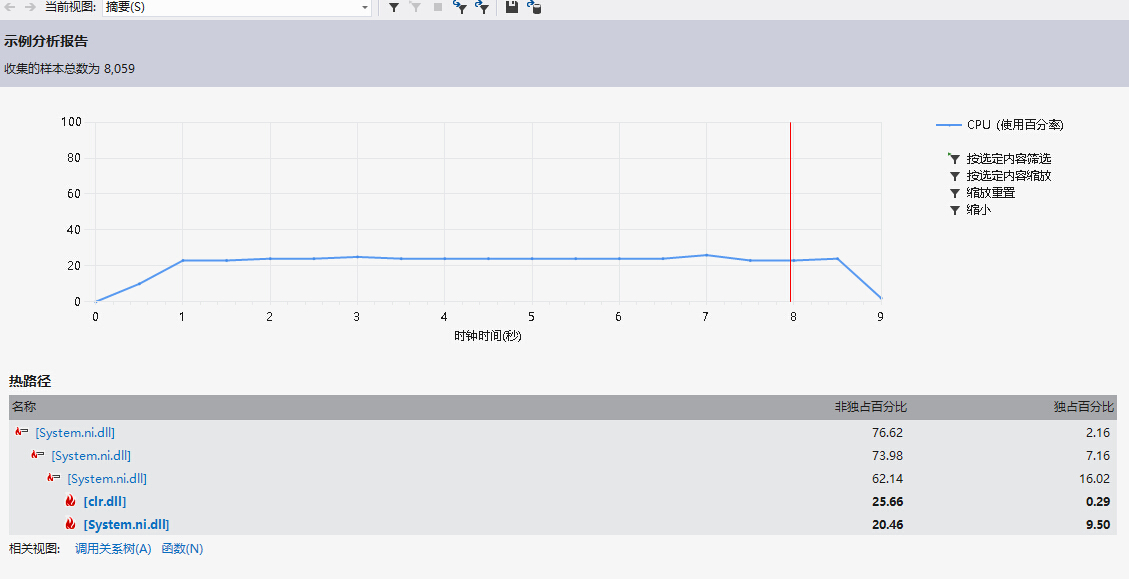 在相对较合理的时间内完成了较大文件的检索。
在相对较合理的时间内完成了较大文件的检索。
下面是有关函数的使用情况:
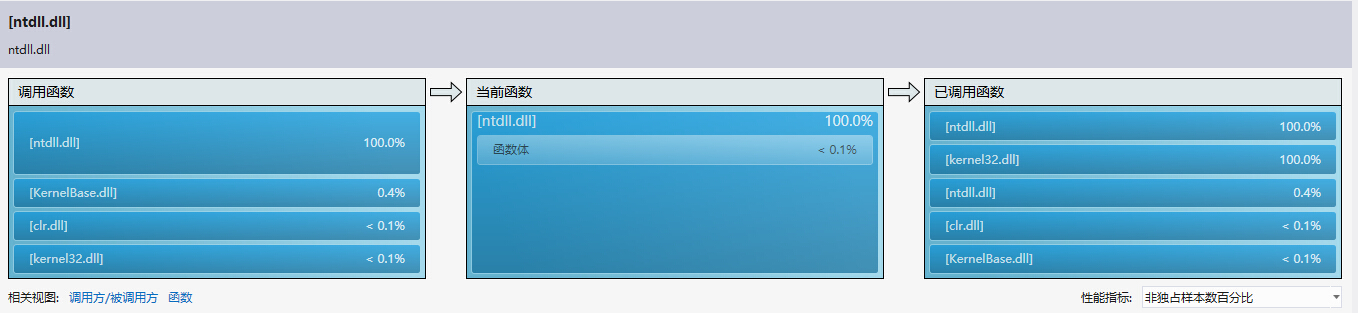
4.项目的测试用例:
a.测试能否正确分隔单词,以及是否对大小写不敏感


b.测试两个连续单词时,判断能否得到所有连续的两个单词,或是两个空格分隔的字符串是否为连续的两个单词等等


c.测试连续三个单词是否能够正确匹配,判断能否得到所有连续的两个单词,或是两个空格分隔的字符串是否为连续的三个单词等等

d.当有多个文件的时候,看前一个文件的最后一个词会不会和后面一个文件的前面的词构成连续的词

e:检测三个连续单词匹配统计是否正确,以及能否正确处理换行符,是否考虑重叠问题

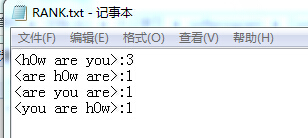
f:是否支持空文件的检索
很显然,输出文件没有字符串的输出
g:测试汉字的识别情况,是否将汉字当成分隔符
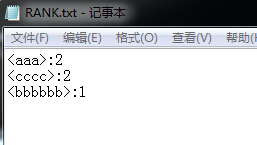
h:连续两个词的统计问题
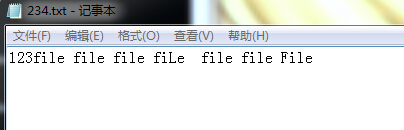

i:测试三个词的统计和分隔情况
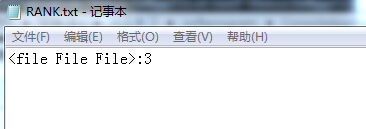
j:统计大文件,由于文件比较大就不贴出来了,但是能够不崩溃就行,就是不知道统计是否正确
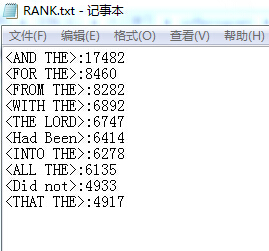
5.收获。
想起上一学年被各种科目虐的很惨,但是在学期末的时候,自己都会有点庆幸,能够有这些课鞭策自己去努力的学,充分掌握好自己的时间学到更多的东西。
刚开始写这个程序的时候,自己一点都不了解c#,于是先花了一些时间去熟悉c#,又应题目的要求,去看了一些关于正则表达式和哈希表有关方面的知识,然后开始写自己的代码。刚开始的时候以为排序要用到快排,又去把快排复习了一次。在学习新的知识的同时也巩固了以前学习的知识。很大的收获就是自己学习了正则表达式和哈希表的使用方法,这对程序的性能有很大的提高。
由于不了解c#的类库,自己开始去查相应的API文档,自己以前并没有这样的习惯。这几天发现多阅读API对自己有很大的好处,是个良好的学习习惯,希望自己在以后的编程中也能一直保持这个习惯。
计算机方面要学习的知识还真是多,只能默默说一句自己会努力地。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号