MySQL索引实现原理
什么是索引:
索引是一种高效获取数据的存储结构,例:hash、 二叉、 红黑。
B+树是一种平衡多路查找树, 与二叉树、红黑树等最大的差别是B+树可以拥有更多的出度(可以理解为节点的数据量), 由于B+树的渐进时间复杂度为O(H)=O(logdN)(H为树高, d为出度, N为数据量), 则一颗出度为200、数据量为200W的B+树高度为3, 这样查询一条数据最多只需要3次磁盘IO 。 另外主存和磁盘以页为单位交换数据, 在技术实践中, 我们可以使节点大小为磁盘一个页的大小,并且在新建节点时直接申请一个页大小的空间, 这样节点的物理存储位置也是在一个页里, 好处是存取一个节点只需要一次磁盘IO(在大部分操作系统中页的大小通常为4K, 如linux)。
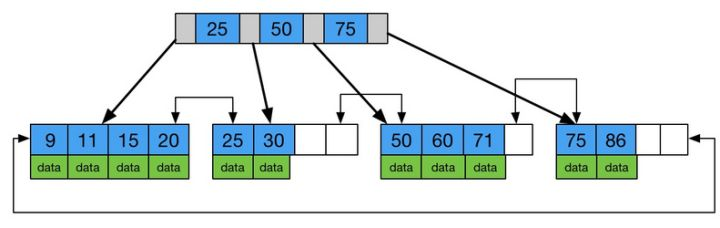
图1 索引结构
MyISAM vs InnoDB
在MySQL5.5之前, 默认的数据库引擎是MyISAM, 由早起的ISAM(Indexed Sequential Access Method)改良而成, 不过MyISAM一个最大的缺陷是不支持事务, 所以目前MySQL应用中大部分是采用InnoDB, InnoDB支持了ACID兼容的事务功能。
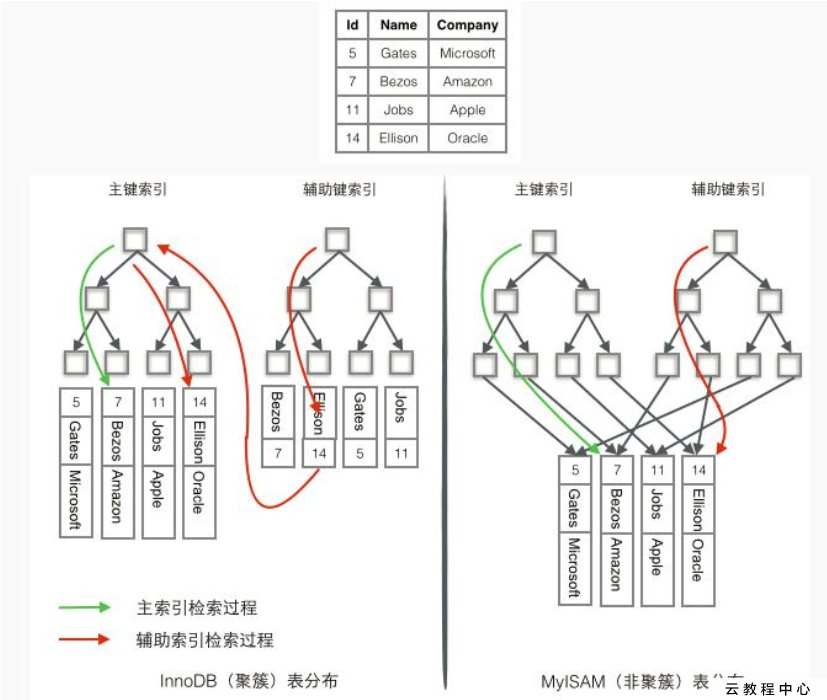
通常我们说MyISAM是非聚集索引, InnoDB为聚集索引, 主要原因是MyISAM的索引和数据是分开存储的, 每个MyISAM表在磁盘上存储为3个文件, .frm存储表定义、.MYD存储数据、.MYI存储索引; InnoDB的索引文件和数据文件就是同一个, 数据是按主键索引来聚集的。 不同的是MyISAM页节点的data域存储的是数据的地址, 而InnoDB的页节点data域存储的数据本身。 从下述InnoDB引擎的结构可以看出,每张表用主键(primary key)构建一颗B+树, 然后每个叶子节点存储行数据。
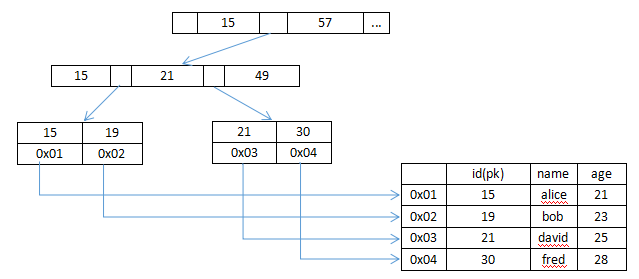
图2:MyISAM索引结构
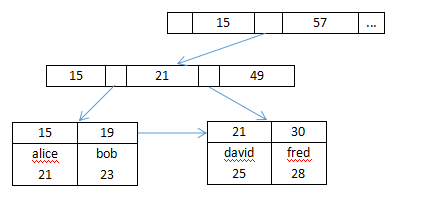
图3:InnoDB索引结构
另外在实际MySQL使用中, 除了主键之外, 还会根据我们的业务特征来建立其他的索引, 称为辅组索引。对于MyISAM来说, 辅助索引跟主索引在结构上没差别, 存储的也是数据的地址,只是主索引要求key唯一, 而辅助索引则没有要求; 对于InnoDB来说, 辅助索引的data域保存的是主key的值, 所以在InnoDB中从辅助索引查到主键key之后还需要到主索引中查询数据。
了解了索引背后的实现原理, 在日常MySQL的使用过程我们也能明白很多Tips的原因,例如:
1: MyISAM允许没有任何索引和主键的表存在,而对于InnoDB来说如果表创建者没有指定表主键的话或者唯一非空索引, 会自动生成一个6字节的rowid作为主键(用户不可见), 也就是说InnoDB表必须要有主键。
2: 对于InnoDB来说不建议使用过长的字段作为主键,这样会导致辅助索引变得过大。
3: 使用自增字段作为InnoDB表主键是个很好的选择, 这样数据的插入、删除都十分高效。 不要用随机值或者业务相关的值, 这样为了维护B+Tree特性而带来额外的分裂移动操作十分昂贵, 特别是会导致不同页之间交换数据的情况, 可能会有额外的磁盘IO。
其他一些关于MyISAM和InnoDB的差异:
1: MyISAM只支持表级锁, InnoDB支持行级锁。
2: 支持fulltext类型的全文索引, InnoDB不支持。
3: MyISAM保存有表的总函数, 用select count() from table可以直接取出改值。 而InnoDB没有保存表行数, select count() from table会需要遍历表; 另外在MyISAM中select count如果加了where就和InnoDB的处理方式一样的。
最左前缀匹配
在讲最左前缀匹配规则之前, 我们先来看看联合索引, 上边我们说的都是主键索引, 通常在实际应用中, 我们还会根据我们的查询场景采用多个列来建立索引, 这个就是联合索引, 如下所示建立联合索引的SQL:ALTER TABLE table_name ADD INDEX index_name (column_1, column_2)。 在B+树中, 所有键值都是有序的, 对于联合索引来说, 建立索引时索引列的顺序意味着索引首先按照最左列进行排序,其次再为第二列、第三列等等。所以一个联合索引各节点一定是按第一列严格排序的, 但是后边的列并不是整体完全有序, 只是局部有序(第一列键值相同的情况下)。
那么MySQL的最左前缀匹配是怎么回事呢? 我们看下边的例子:
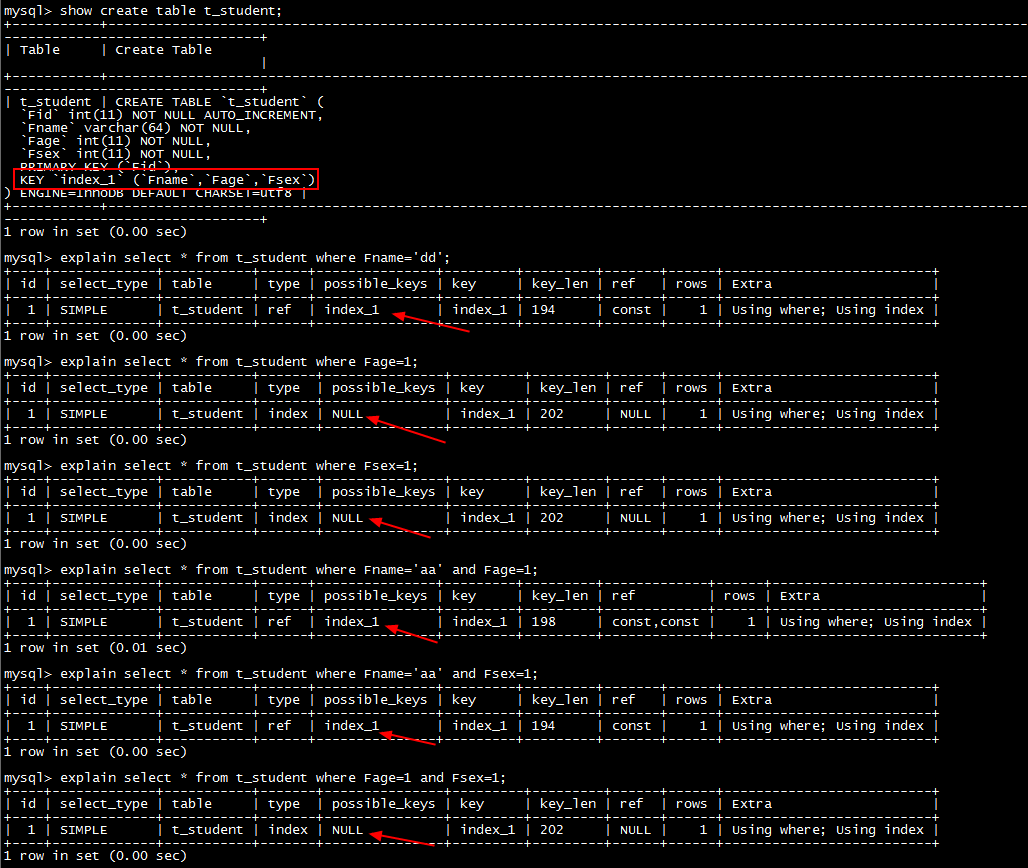
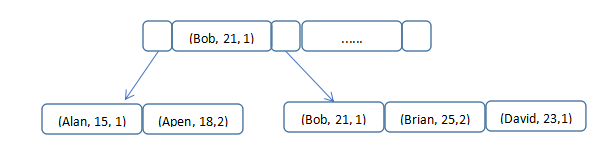
示例表t_student, 然后针对Fname、Fage、Fsex建立了联合索引。然后在下边的几种查询语句中, 只有在where条件包含Fname时采用用到索引, 其余的各种情况都用不到索引, 究其原因, 就是在构建索引的B+树时, 是先按第一列(即Fname)来组织并保证有序, 一次再是Fage、Fsex, 当查询条件中没有Fname时, 此时就不知道从哪个节点开始了, 是用不到索引的。 索引结构简单示例如下:
like问题
使用like模糊查询会导致索引失效,在数据量大的时候会有性能问题
(1)尽量少以%或者_开头进行模糊查询
通过explain执行计划,我们发现,使用like模糊查询时,如果不以%和_开头查询的话,索引还是有效的


以%或者_开头查询,索引失效


(2)使用覆盖索引
当查询的的条件和查询的结果都是索引中的字段的时候,这个索引我们可以称之为覆盖索引,这个时候,使用like模糊查询索引是有效的


InnoDB中主键可以不添加进索引中
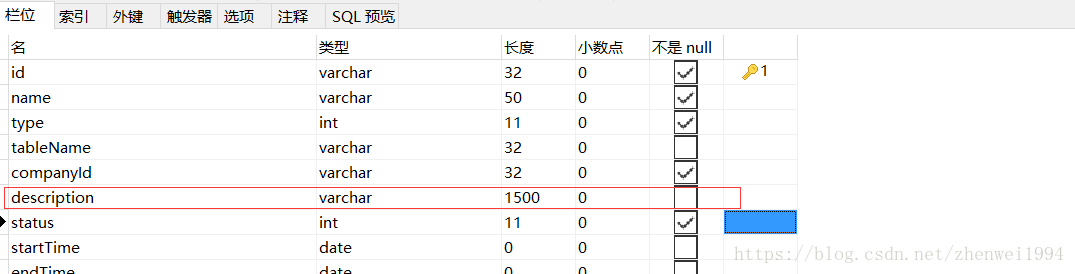
注意:使用覆盖索引,对于字段的长度是由要求限制的,一般超过长度,索引也会失效
这里如果我查询中带有descripition字段,则覆盖索引也会失效(我这里的数据库经过测试最多只支持255长度的字段)


(3)使用全文索引
给字段建立Full Text索引,然后使用match(...) against(...)进行检索


注意:这种全文索引方式只对英文单词起作用,对于中文汉字支持不够友好,需要额外去mysql的配置文件做一些配置修改,让它额外支持中文
(4)使用一些额外的全文搜索引擎来解决
Lucene,solr,elasticsearch等等
基本原理是:把mysql配置文件中的ft_min_word_len=3改为1。(没有这项就直接添加),然后新建一个字段来保持分词结果,给这个字段建立全文索引。然后实现一个分词模块,把词语“大家好”拆分为“大 大家 大家好 家 家好 好”。然后用match .. against 来代替like %%,查询出来的结果跟like的结果基本相同(如果分词合理的话),但是效率比like高至少10倍以上。
聚簇索引和非聚簇索引的差异

 浙公网安备 33010602011771号
浙公网安备 33010602011771号