

分布式mongodb分片集群
本博客先简单介绍mongodb入门以及单实例以及mongodb的主从(主从官网是不提倡用的,原因后续介绍),副本集,分片。
第一:nosql介绍:
数据库分为关系型数据库与非关系型数据库,及具代表性的关系型数据库:mysql ,非关系型数据库:mongodb。
今天就先单说mongodb,后续博客会有相关mysql的知识
1:数据量大。可以避免mysql中的单表过大,超过存储量级(我第一家公司的dba经常喊今天晚上又要拆这个库,分那个表的)
2:高扩展性:没有关系特性,易于横向扩展,摆脱了以往的只能纵向扩展的特性
3:高性能:nosql是通过k-v的形式存储,易于获取数据,非常快速【建议:mongodb所有集合都要建索引,进行分片】如果不建索引,一旦数据量写入慢慢增多,数据会越来越慢。
4:灵活的数据模型:NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
5:高可用:mongos mongo 分片可以很快配合
第二:先来一个单实例
安装前准备:首先安装一个supervisor
单实例一般用于开发和测试环境,应用程序直接连接即可。
1.规划目录
软件目录 mkdir /data/mongodb/soft -p 数据目录 mkdir /data/mongodb/data -p 日志目录 mkdir /data/mongodb/log -p mongo的启动文件以及配置 mkdir /data/mongodb/mongo -p
2.下载解压并安装
我是下载公司内网的不在此提供链接了,需要的去官网下载
tar xf mongodb-linux-x86_64-ubuntu1604-3.4.10.tgz -C /data/mongodb/mongo/ mv mongodb-linux-x86_64-ubuntu1604-3.4.10/* . rm mongodb-linux-x86_64-ubuntu1604-3.4.10
3.配置管理:
新建:mkdir /data/mongodb/mongo/etc
cat mongo.conf net: bindIp: xx.xx.xx.xx,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 27017 processManagement: fork: false systemLog: destination: file path: /data/mongodb/log/mongo.log logAppend: true storage: dbPath: /data/mongodb/data/ journal: enabled: true
配置supervisor管理
cat /etc/supervisor/conf.d/mongo.conf [program:mongo] command=/data/mongodb/mongo/bin/mongod -f /data/mongodb/mongo/etc/mongo.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/mongo.log stderr_logfile=/var/log/supervisor/mongo_error.log
重载supervisor,新增mongo配置
检查是否正常运行:

登录也要验证
第三,主从配置
官网建议:
采用主从配置当然要比单实例要好一些,但是主从配置有很多缺点:
1.当主节点down机后,从节点目前不能接管服务
2.当主节点的写压力大的时候,主从不能够解决该问题
3.从节点需要全量copy主节点的数据
因此这种方式开发环境与线上的环境都不提倡使用,在此不再详谈。
感兴趣的,参考官网:https://docs.mongodb.com/manual/core/master-slave/index.html
第四:副本集
一.副本集理论分析
一个副本集ReplicaSet一般由一组mongod实例组成,这组mongod实例协调配合工作,共同向外提供高可用的数据库访问服务。
一组mongod实例角色一般分为三种:主节点、副本节点和仲裁者节点。
主节点:负责所有的数据库写操作,默认情况下,主节点也负责处理所有的数据库读操作;(做了读写分离则不需要读的操作)
副本节点:负责同步主节点的数据操作日志更新本地数据库,从而保证副本节点的数据和主节点上的数据的一致性;
仲裁节点:投票选举的
除了上面三个角色的节点外,还有其他不常用的几个:
Secondary-Only:和副本节点一样保存了主节点的数据副本,但是在任何情况下都成为不了Primary主节点;
Hidden:这种类型的节点对于客户端程序是不可见的,同样不能成为Primary主节点,但是可以参与投票;
Delayed:这种类型的节点可以通过人为的设置,可以指定一个时间来延迟从主节点同步数据,Delayed成员主要用于从一些误操作中恢复旧数据,并且肯定不能成为主节点而且是Hidden的;
Non-Voting:没有选举权的secondary节点,纯粹的备份数据节点。
如图:来自官网
一个最小化的副本集:

在上图中,副本集中的主节点负责处理来自应用程序的所有读写操作,并将所有的修改数据库的操作以日志Oplog的方式记录在本地;副本节点按照一定的频率主动异步的从主节点从不操作日志并作用于自己本机的数据库上,从而保证副本节点和主节点的数据一致性。副本集中的各个节点之间每2秒进行一个心跳请求,看看副本集中的其他节点的状态。

正常情况下,读写操作是操作在主节点上,写操作我们是无法进行控制的,只能作用在主节点上,但是对于读操作我们确实可以控制的(从副本节点上读取数据,从而达到读写分离),这时候我们就需要了解下ReadPreference了,下面简单列下都有哪些模式可以供我们选择:
(1)primary:默认方式,所有的读操作都从主节点获取;
(2)primaryPerferred:在大多数场景下直接从主节点进行读操作,如果主节点读操作不可用时,则从副本节点进行读取;
(3)secondary:所有的读操作都只从副本节点进行读取;
(4)secondaryPreferred:在大多数场景下,读操作都从副本节点进行读操作,如果副本节点不可用,那么考虑从主节点进行读取;
(5)nearest:所有的读操作从网络延迟最小的节点上进行读操作;
如果主节点不可用或者直接down机了,主节点会怎样?
(1)如果主节点发现自己和副本集中大多数节点无法连接时,为了保证数据一致性,会将自己降级为副本节点,从而阻止有操作对数据库进行修改;
(2)如果主节点崩溃了不可用了,那么副本集会内会进行一次选举操作,重新选举产生一个主节点;
重要问题来了, 选举主节点的时候是怎么选举的呢?
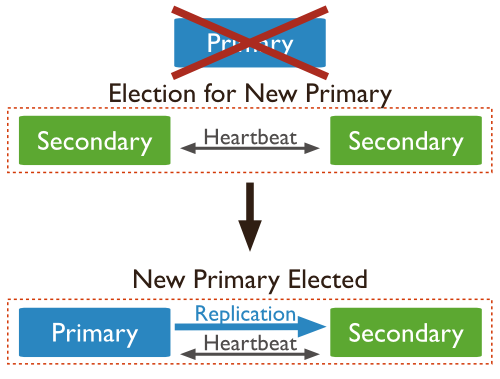
前面提到正常的检查机制--->(正常情况下,每个节点每2秒跟其他节点进行一次心跳测试,如果在10s内未收到对方节点的回复,那么认为对方节点不可用),假设主的down机了,主节点没有回复后,有资格成为主节点的副本节点就会向其他节点发起一个选举提议,基本的意思就是“我要成为主节点了,可不可以?”,而其他节点在收到选举提议后会判断下面几个条件:
(1)副本集中是否存在primary了?
(2)自己的数据是否更加的新?
(3)副本集中其他节点的数据是否比请求成为主节点的副本节点的数据更加的新?
如果上面三个条件中只要有一个条件满足,那么都会认为对方的提议不可行,于是返回一个返回包给请求节点说“不可以,你还嫩!”,请求节点只要收到其他任何一个节点返回不合适,都会立刻停止选举,并将自己保持在secondary角色;但是如果上面三个条件都不满足,那么就会在返回包中回复说“你当吧,大哥”,那么此时请求包就会进入选举的第二阶段。请求节点会向其他节点发送一个确认的请求包,基本意思就是“我宣布了我是主节点,还有不服的嘛?”,如果在这次确认过程中其他节点都没人反对,那么请求节点就将自己升级为primary节点,所有节点在30秒内不再进行其他选举投票决定;如果有节点此时认为请求节点不适合做primary,那么请求节点在收到反对回复后会保持自己的节点角色依然是secondary。
官网是这样说选举的:

翻译:
- 得到每个服务器节点的最后操作时间戳。每个mongodb都有oplog机制会记录本机的操作,方便和主服务器进行对比数据是否同步还可以用于错误恢复。
- 如果集群中大部分服务器down机了,保留活着的节点都为 secondary状态并停止,不选举了。
- 如果集群中选举出来的主节点或者所有从节点最后一次同步时间看起来很旧了,停止选举等待人来操作。
- 如果上面都没有问题就选择最后操作时间戳最新(保证数据是最新的)的服务器节点作为主节点。
但是现在如果时间戳相同怎么办?
谁快选谁,也就是结合上面的谁先问选谁
二:副本集部署
准备三台机器,每台机器都启动27017端口:
xx.xx.xx.173,xx.xx.xx.186,xx.xx.xx.182
第一:分别在三台机器上执行安如下操作的操作。
规划目录:
mkdir /data/mongodb/soft -p mkdir /data/mongodb/data -p mkdir /data/mongodb/log -p mkdir /data/mongodb/mongo -p
配置mongo的副本集配置文件:
cat /data/mongodb/mongo/etc/mongo.conf net: bindIp: xx.xx.xx.173,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 27017 processManagement: fork: false replication: replSetName: shard systemLog: destination: file path: /data/mongodb/log/mongo.log logAppend: true storage: dbPath: /data/mongodb/data/ journal: enabled: true
配置supervisor文件:
cat /etc/supervisor/conf.d/mongo.conf [program:mongo] command=/data/mongodb/mongo/bin/mongod -f /data/mongodb/mongo/etc/mongo.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/mongo.log stderr_logfile=/var/log/supervisor/mongo_error.log
启动mongo:
supervisorctl start mongo
检查三台机器的 mongo启动情况



第二:选择mongo1配置主节点:

查看状态:rs.status()
测试下副本集的复制功能:
主的上面写入数据:
在其中一个节点查看是否可以读取,由于SECONDARY的节点是默认不允许读的需要先设置为允许:

副本集的功能成功
如果设置读写分离的话,需要客户端的写程序连接primary,读的程序从secondary来读取就可以了。前提secondary必须设置可读
第五:mongo集群
mongo集群是有route config shard三个组成
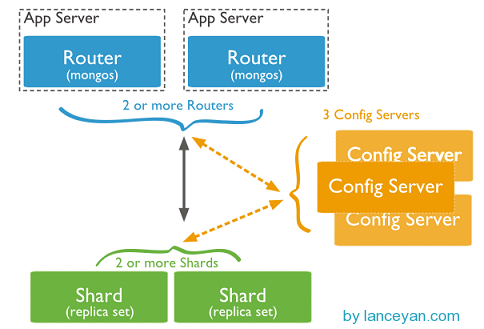
mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,这个可不能丢失!就算挂掉其中一台,只要还有存货, mongodb集群就不会挂掉。
shard,即存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replication Set。为了实现每个Shard内部的auto-failover(自动故障切换),MongoDB官方建议每个Shard为一组Replica Set。
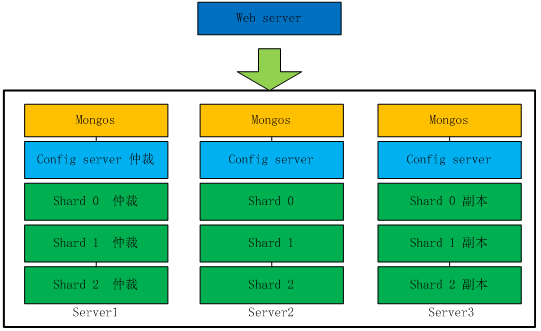
用三台服务器,每台服务器上起5个端口来模拟分片集群
mongos :20000 config server:21000 shard01:22000 shard02:23000 shard03:24000
第一步:规划目录
mkdir /data/soft -p #软件放置的地方 mkdir /data/data -p #数据目录 mkdir /data/data/shard01 #分片01的数据目录 mkdir /data/data/shard02 #分片02的数据目录 mkdir /data/data/shard03 #分片03的数据目录 mkdir /data/data/config #config的数据目录 mkdir /data/log -p #日志目录 touch /data/log/mongos.log #mongos日志文件 touch /data/log/config.log #config日志文件 touch /data/log/shard01.log #分片01日志文件 touch /data/log/shard02.log #分片02日志文件 touch /data/log/shard03.log #分片03日志文件 mkdir /data/mongo -p #mongo的配置和启动文件目录
第二步:配置规划
mkdir /data/mongo/etc #配置目录 root@mongo1:/data/mongo/etc# cat * #config配置 net: bindIp: xx.xx.xx.173,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 21000 processManagement: fork: false replication: replSetName: mos storage: dbPath: /data/data/config journal: enabled: true sharding: clusterRole: configsvr systemLog: destination: file path: /data/log/config.log logAppend: true #mongos配置 net: bindIp: xx.xx.xx.173,127.0.0.1 port: 20000 http: enabled: false maxIncomingConnections: 65536 processManagement: fork: false sharding: configDB: mos/xx.xx.xx.182:21000,xx.xx.xx.186:21000,xx.xx.xx.173:21000 systemLog: destination: file path: /data/log/mongos.log logAppend: true #shard01配置 net: bindIp: xx.xx.xx.173,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 22000 processManagement: fork: false replication: replSetName: s1 storage: dbPath: /data/data/shard01 journal: enabled: true sharding: clusterRole: shardsvr systemLog: destination: file path: /data/log/shard01.log logAppend: true #shard02配置 net: bindIp: xx.xx.xx.173,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 23000 processManagement: fork: false replication: replSetName: s2 storage: dbPath: /data/data/shard02 journal: enabled: true sharding: clusterRole: shardsvr systemLog: destination: file path: /data/log/shard02.log logAppend: true #shard03配置 net: bindIp: xx.xx.xx.173,127.0.0.1 http: enabled: false maxIncomingConnections: 65536 port: 24000 processManagement: fork: false replication: replSetName: s3 storage: dbPath: /data/data/shard03 journal: enabled: true sharding: clusterRole: shardsvr systemLog: destination: file path: /data/log/shard03.log logAppend: true
第三:supervisor管理设置
config配置 [program:config] command=/data/mongo/bin/mongod -f /data/mongo/etc/config.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/config.log stderr_logfile=/var/log/supervisor/config_err.log mongos配置 [program:mongos] command=/data/mongo/bin/mongos -f /data/mongo/etc/mongos.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/mongos.log stderr_logfile=/var/log/supervisor/mongos_err.log 分片01配置 [program:shard01] command=/data/mongo/bin/mongod -f /data/mongo/etc/shard01.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/shard01.log stderr_logfile=/var/log/supervisor/shard01_err.log 分片02配置 [program:shard02] command=/data/mongo/bin/mongod -f /data/mongo/etc/shard02.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/shard02.log stderr_logfile=/var/log/supervisor/shard02_err.log 分片03配置 [program:shard03] command=/data/mongo/bin/mongod -f /data/mongo/etc/shard03.conf autostart=true user=root autorestart=false starttretries=5 stdout_logfile=/var/log/supervisor/shard03.log stderr_logfile=/var/log/supervisor/shard03_err.log
重载supervisor配置
第五:配置分片规则
配置shard01
/data/mongo/bin/mongo xx.xx.xx.173:22000
use admin config = { _id:"s1", members:[ {_id:0,host:"xx.xx.xx.173:22000"}, {_id:1,host:"xx.xx.xx.186:22000"}, {_id:2,host:"xx.xx.xx.182:22000",arbiterOnly:true} ] } rs.initiate(config)
配置shard02
/data/mongo/bin/mongo xx.xx.xx.173:23000
use admin config = { _id:"s2", members:[ {_id:0,host:"xx.xx.xx.173:23000"}, {_id:1,host:"xx.xx.xx.186:23000"}, {_id:2,host:"xx.xx.xx.182:23000",arbiterOnly:true} ] } rs.initiate(config)
配置shard03
/data/mongo/bin/mongo xx.xx.xx.173:24000
use admin config = { _id:"s3", members:[ {_id:0,host:"xx.xx.xx.173:24000"}, {_id:1,host:"xx.xx.xx.186:24000"}, {_id:2,host:"xx.xx.xx.182:24000",arbiterOnly:true} ] } rs.initiate(config)
配置config server
/data/mongo/bin/mongo xx.xx.xx.173:21000
use admin config = { _id:"mos", members:[ {_id:0,host:"xx.xx.xx.173:21000"}, {_id:1,host:"xx.xx.xx.186:21000"}, {_id:2,host:"xx.xx.xx.182:21000"} ] } rs.initiate(config)
第四:启动supervisor下的所有服务
/etc/init.d/supervisor restart
第五:依次检查所有端口与进程是否启动
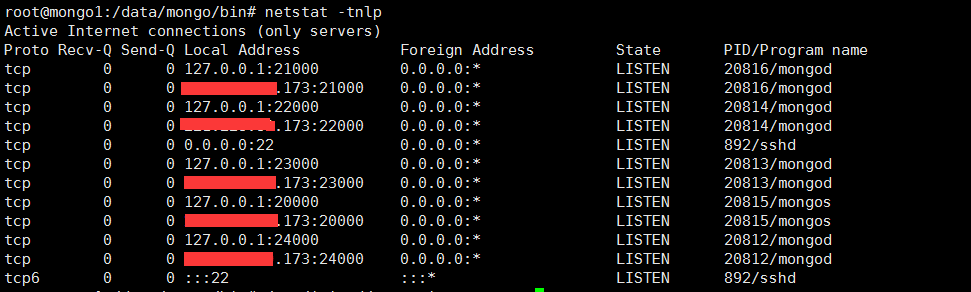
查看:
此时搭建了mongodb配置服务器、路由服务器,各个分片服务器,不过应用程序连接到 mongos 路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
mongos> use admin switched to db admin mongos> db.runCommand({addshard : "s1/xx.xx.xx.182:22000,xx.xx.xx.186:22000,xx.xx.xx.173:22000"}) { "shardAdded" : "s1", "ok" : 1 } mongos> db.runCommand({addshard : "s2/xx.xx.xx.182:23000,xx.xx.xx.186:23000,xx.xx.xx.173:23000"}) { "shardAdded" : "s2", "ok" : 1 } mongos> db.runCommand({addshard : "s3/xx.xx.xx.182:24000,xx.xx.xx.186:24000,xx.xx.xx.173:24000"}) { "shardAdded" : "s3", "ok" : 1 }

到此mongo集群全部部署完毕
第六:测试分片效果
首先说明:分片的功能是需要手动开启才能实现的:sh.enableSharding("库名")、sh.shardCollection("库名.集合名",{"key":1})
mongos> use admin switched to db admin mongos> db.runCommand({"enablesharding":"zdb"}) { "ok" : 1 } mongos> db.runCommand({"shardcollection":"zdb.mycollection","key":{"_id":"hashed"}}) { "collectionsharded" : "zdb.mycollection", "ok" : 1 } mongos> use zdb switched to db zdb mongos> for(i=0;i<333333;i++){ db.mycollection.insert({"Uid":i,"Name":"yingying","Age":18,"Date":new Date()}); } WriteResult({ "nInserted" : 1 })
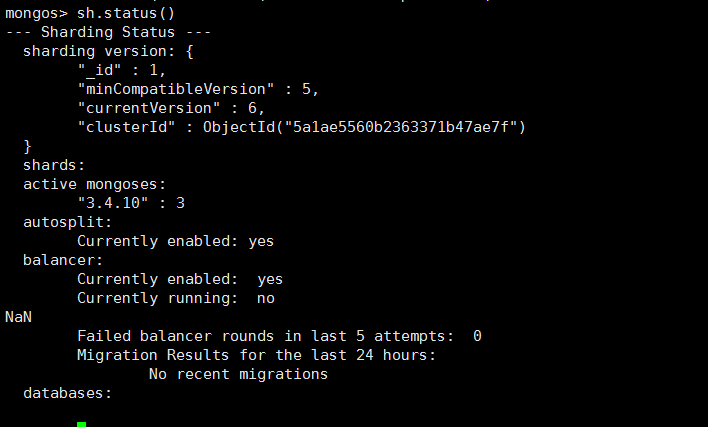
查看分片是否均衡
mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("5a1ae5560b2363371b47ae7f") } shards: { "_id" : "s1", "host" : "s1/221.228.80.173:22000,61.177.20.186:22000", "state" : 1 } { "_id" : "s2", "host" : "s2/221.228.80.173:23000,61.177.20.186:23000", "state" : 1 } { "_id" : "s3", "host" : "s3/221.228.80.173:24000,61.177.20.186:24000", "state" : 1 } active mongoses: "3.4.10" : 3 autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no NaN Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: 13 : Success databases: { "_id" : "zdb", "primary" : "s3", "partitioned" : true } zdb.mycollection shard key: { "_id" : "hashed" } unique: false balancing: true chunks: s1 14 s2 14 s3 14 too many chunks to print, use verbose if you want to force print
博尾总结:本篇博客主要写了mongodb从单实例到集群的理论知识与部署,接下来写两篇关于mongodb的必备的命令和mongodb的配置详请介绍

