深入理解TCP协议及其源代码
一、三次握手过程
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。如下图所示:

首先,客户端开始的时候,首先创建sock文件描述符,接着就进行connect发起连接服务器请求,阻塞等待服务器应答。
接着,服务器开始的时候,分配一个listen_sock文件描述符,接着进行bind绑定,绑定完毕之后进行listen监听,最后进行accept,此时阻塞等待客户端的连接。连接建立accept返回之后,分配一个新的文件描述符与客户端通信。
第一次握手:Client先产生一个初始序列号seq:8000,SYN标志位置1,将该数据包发送给Server端,之后Client端进入SYN_SENT状态,等待Client确认。
第二次握手:Server收到数据包后也发送自己的SYN报文作为响应,并初始化序列号seq=15000,为了确认Client的seq,Server将Client发送的seq加1作为ACK发送给Client,Server进入SYN_RCVD状态。
第三次握手:为了确认Server的SYN,Client将Server发送的seq加1作为ACK发送给Server。Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
通过这样的三次握手,客户端和服务端建立起可靠的全双工的连接,开始传送数据。三次握手的最主要目的是保证连接是全双工的,可靠更多的是通过重传机制来保证的。
TCP状态转换图:
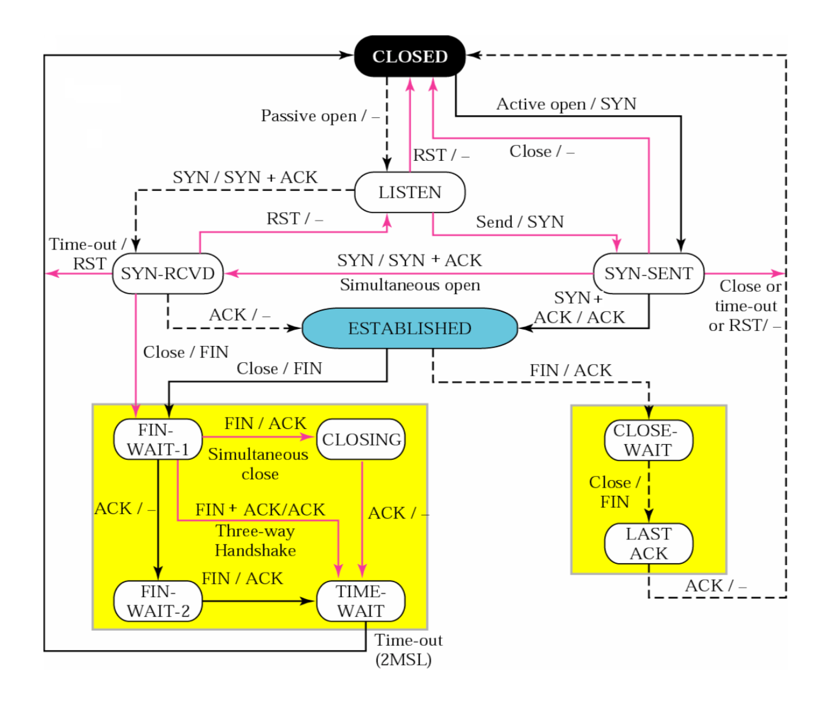
结合状态转换图来看三次握手:
CLOSED:起始点,在超时或者连接关闭时候进入此状态,这并不是一个真正的状态,而是这个状态图的假想起点和终点。
LISTEN:服务器端等待连接的状态。服务器经过socket,bind,listen函数之后进入此状态,开始监听客户端发过来的连接请求。此称为应用程序被动打开(等到客户端连接请求)。
SYN_SENT:第一次握手发生阶段,客户端发起连接。客户端调用connect,发送SYN给服务器端,然后进入SYN_SENT状态,等待服务器端确认(三次握手中的第二个报文)。如果服务器端不能连接,则直接进入CLOSED状态。
SYN_RCVD:第二次握手发生阶段,跟3对应,这里是服务器端接收到了客户端的SYN,此时服务器由LISTEN进入SYN_RCVD状态,同时服务器端回应一个ACK,然后再发送一个SYN即SYN+ACK给客户端。状态图中还描绘了这样一种情况,当客户端在发送SYN的同时也收到服务器端的SYN请求,即两个同时发起连接请求,那么客户端就会从SYN_SENT转换到SYN_REVD状态。
ESTABLISHED:第三次握手发生阶段,客户端接收到服务器端的ACK包(ACK,SYN)之后,也会发送一个ACK确认包,客户端进入ESTABLISHED状态,表明客户端这边已经准备好,但TCP需要两端都准备好才可以进行数据传输。服务器端收到客户端的ACK之后会从SYN_RCVD状态转移到ESTABLISHED状态,表明服务器端也准备好进行数据传输了。这样客户端和服务器端都是ESTABLISHED状态,就可以进行后面的数据传输了。所以ESTABLISHED也可以说是一个数据传送状态。
上面就是TCP三次握手过程的状态变迁。结合第一张三次握手过程图,从报文的角度看状态变迁:SYN_SENT状态表示已经客户端已经发送了SYN报文,SYN_RCVD状态表示服务器端已经接收到了SYN报文。
二、TCP协议源代码跟踪分析
1.TCP的三次握手从用户程序的角度看就是客户端connect和服务端accept建立起连接时背后的完成的工作。由上次的实验我们可以知道,在socket接口层这两个socket API函数分别对应着sys_connect和sys_accept4函数,课上老师说明, sys_connect和sys_accecpt是通过函数指针sock->opt->connect和sock->opt->accept调用了具体的函数来实现的,在即调用了tcp_v4_connect函数和inet_csk_accept函数,这两个函数进一步触及TCP数据收发过程tcp_transmit_skb和tcp_v4_rcv函数。
在net/ipv4/tcp-ipv4.c文件下的结构体变量struct proto tcp_prot指定了TCP协议栈的访问接口函数:
struct proto tcp_prot = { .name = "TCP", .owner = THIS_MODULE, .close = tcp_close, .pre_connect = tcp_v4_pre_connect, .connect = tcp_v4_connect, .disconnect = tcp_disconnect, .accept = inet_csk_accept, .ioctl = tcp_ioctl, .init = tcp_v4_init_sock, .destroy = tcp_v4_destroy_sock, .shutdown = tcp_shutdown, .setsockopt = tcp_setsockopt, .getsockopt = tcp_getsockopt, .keepalive = tcp_set_keepalive, .recvmsg = tcp_recvmsg, .sendmsg = tcp_sendmsg, .sendpage = tcp_sendpage, .backlog_rcv = tcp_v4_do_rcv, .release_cb = tcp_release_cb, .hash = inet_hash, .unhash = inet_unhash, .get_port = inet_csk_get_port, .enter_memory_pressure = tcp_enter_memory_pressure, .leave_memory_pressure = tcp_leave_memory_pressure, .stream_memory_free = tcp_stream_memory_free, .sockets_allocated = &tcp_sockets_allocated, .orphan_count = &tcp_orphan_count, .memory_allocated = &tcp_memory_allocated, .memory_pressure = &tcp_memory_pressure, .sysctl_mem = sysctl_tcp_mem, .sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem), .sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem), .max_header = MAX_TCP_HEADER, .obj_size = sizeof(struct tcp_sock), .slab_flags = SLAB_TYPESAFE_BY_RCU, .twsk_prot = &tcp_timewait_sock_ops, .rsk_prot = &tcp_request_sock_ops, .h.hashinfo = &tcp_hashinfo, .no_autobind = true, #ifdef CONFIG_COMPAT .compat_setsockopt = compat_tcp_setsockopt, .compat_getsockopt = compat_tcp_getsockopt, #endif .diag_destroy = tcp_abort, };
在这里,我们可以看到socket接口层里sock->opt->connect和sock->opt->accept实际调用的函数tcp_v4_connect和inet_csk_accept。
2.接下来通过MenuOS的内核调试环境设置断点跟踪tcp_v4_connect函数和inet_csk_accept函数来进一步验证三次握手的过程。
在tcp_v4_connect处打个断点:
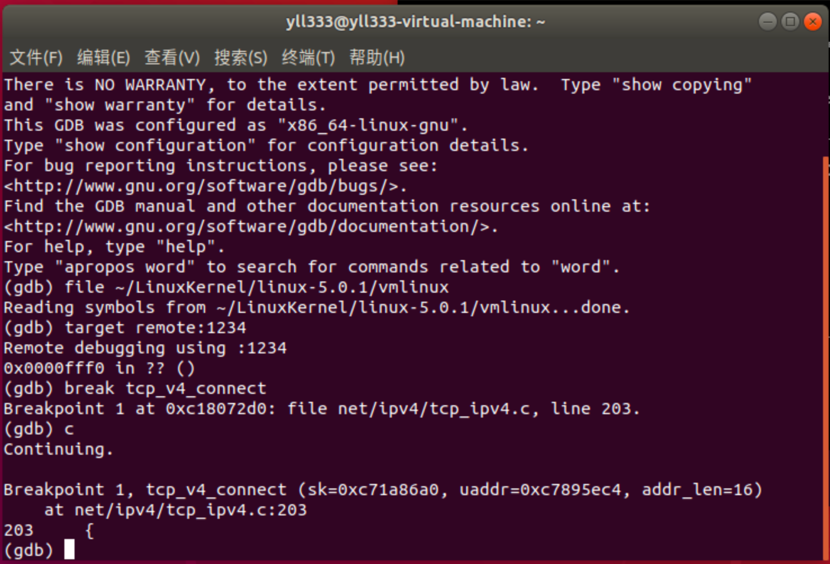
可以发现tcp_v4_connect函数在net/ipv4/tcp_ipv4.c处定义,看下代码:
/* This will initiate an outgoing connection. */ int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; struct inet_sock *inet = inet_sk(sk); struct tcp_sock *tp = tcp_sk(sk); __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4; struct rtable *rt; int err; struct ip_options_rcu *inet_opt; struct inet_timewait_death_row *tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row; if (addr_len < sizeof(struct sockaddr_in)) return -EINVAL; if (usin->sin_family != AF_INET) return -EAFNOSUPPORT; nexthop = daddr = usin->sin_addr.s_addr; inet_opt = rcu_dereference_protected(inet->inet_opt, lockdep_sock_is_held(sk)); if (inet_opt && inet_opt->opt.srr) { if (!daddr) return -EINVAL; nexthop = inet_opt->opt.faddr; } orig_sport = inet->inet_sport; orig_dport = usin->sin_port; fl4 = &inet->cork.fl.u.ip4; rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); if (err == -ENETUNREACH) IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); return err; } if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) { ip_rt_put(rt); return -ENETUNREACH; } if (!inet_opt || !inet_opt->opt.srr) daddr = fl4->daddr; if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr; sk_rcv_saddr_set(sk, inet->inet_saddr); if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { /* Reset inherited state */ tp->rx_opt.ts_recent = 0; tp->rx_opt.ts_recent_stamp = 0; if (likely(!tp->repair)) tp->write_seq = 0; } inet->inet_dport = usin->sin_port; sk_daddr_set(sk, daddr); inet_csk(sk)->icsk_ext_hdr_len = 0; if (inet_opt) inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; /* Socket identity is still unknown (sport may be zero). * However we set state to SYN-SENT and not releasing socket * lock select source port, enter ourselves into the hash tables and * complete initialization after this. */ tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure; } /* OK, now commit destination to socket. */ sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); rt = NULL; if (likely(!tp->repair)) { if (!tp->write_seq) tp->write_seq = secure_tcp_seq(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port); tp->tsoffset = secure_tcp_ts_off(sock_net(sk), inet->inet_saddr, inet->inet_daddr); } inet->inet_id = tp->write_seq ^ jiffies; if (tcp_fastopen_defer_connect(sk, &err)) return err; if (err) goto failure; err = tcp_connect(sk); if (err) goto failure; return 0; failure: /* * This unhashes the socket and releases the local port, * if necessary. */ tcp_set_state(sk, TCP_CLOSE); ip_rt_put(rt); sk->sk_route_caps = 0; inet->inet_dport = 0; return err; }
分析代码,可以看出tcp_v4_connect函数的主要作用就是发起一个TCP连接,从这个函数中可以看到它调用了IP层提供的一些服务,比如ip_route_connect和ip_route_newports,同时在tcp_v4_connect函数中,调用了tcp_set_state函数,它设置了TCP_SYN_SENT,并进一步调用了tcp_connect(sk)来实际构造SYN并发送出去。
tcp_connect函数具体负责构造一个携带SYN标志位的TCP头并发送出去,同时还设置了计时器超时重发。这个函数定义在net/ipv4/tcp_output.c文件中,看看代码:
/* Build a SYN and send it off. */ int tcp_connect(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *buff; int err; tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0, NULL); if (inet_csk(sk)->icsk_af_ops->rebuild_header(sk)) return -EHOSTUNREACH; /* Routing failure or similar. */ tcp_connect_init(sk); if (unlikely(tp->repair)) { tcp_finish_connect(sk, NULL); return 0; } buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true); if (unlikely(!buff)) return -ENOBUFS; tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); tcp_mstamp_refresh(tp); tp->retrans_stamp = tcp_time_stamp(tp); tcp_connect_queue_skb(sk, buff); tcp_ecn_send_syn(sk, buff); tcp_rbtree_insert(&sk->tcp_rtx_queue, buff); /* Send off SYN; include data in Fast Open. */ err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); if (err == -ECONNREFUSED) return err; /* We change tp->snd_nxt after the tcp_transmit_skb() call * in order to make this packet get counted in tcpOutSegs. */ tp->snd_nxt = tp->write_seq; tp->pushed_seq = tp->write_seq; buff = tcp_send_head(sk); if (unlikely(buff)) { tp->snd_nxt = TCP_SKB_CB(buff)->seq; tp->pushed_seq = TCP_SKB_CB(buff)->seq; } TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS); /* Timer for repeating the SYN until an answer. */ inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX); return 0; } EXPORT_SYMBOL(tcp_connect);
其中tcp_transmit_skb函数将tcp数据发送出去。
这边,客户端的一个tcp数据包发送出去了,服务端将做出什么反应呢,下面来看看服务端的inet_csk_accept函数,首先在inet_csk_accept处打上断点:
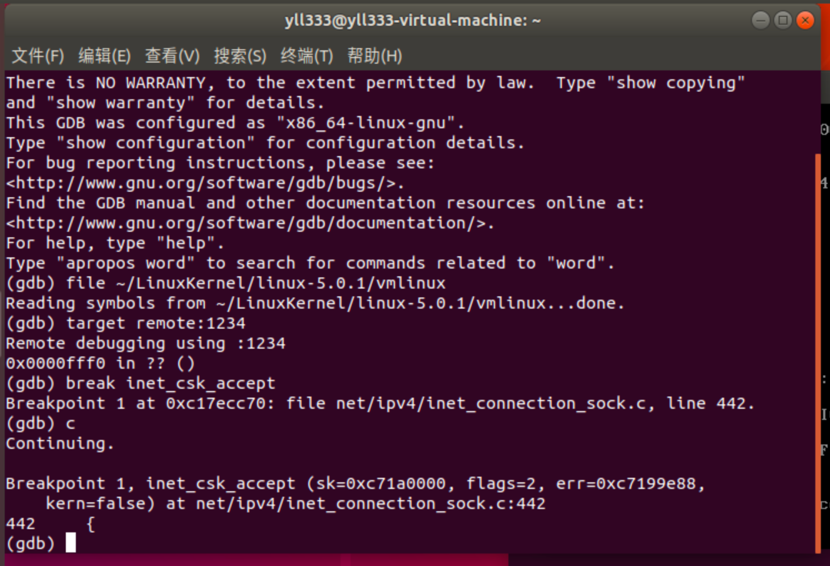
inet_csk_accept函数在net/ipv4/inet_connection_sock.c文件中:
/* * This will accept the next outstanding connection. */ struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) { struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock_queue *queue = &icsk->icsk_accept_queue; struct request_sock *req; struct sock *newsk; int error; lock_sock(sk); /* We need to make sure that this socket is listening, * and that it has something pending. */ error = -EINVAL; if (sk->sk_state != TCP_LISTEN) goto out_err; /* Find already established connection */ if (reqsk_queue_empty(queue)) { long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); /* If this is a non blocking socket don't sleep */ error = -EAGAIN; if (!timeo) goto out_err; error = inet_csk_wait_for_connect(sk, timeo); if (error) goto out_err; } req = reqsk_queue_remove(queue, sk); newsk = req->sk; if (sk->sk_protocol == IPPROTO_TCP && tcp_rsk(req)->tfo_listener) { spin_lock_bh(&queue->fastopenq.lock); if (tcp_rsk(req)->tfo_listener) { /* We are still waiting for the final ACK from 3WHS * so can't free req now. Instead, we set req->sk to * NULL to signify that the child socket is taken * so reqsk_fastopen_remove() will free the req * when 3WHS finishes (or is aborted). */ req->sk = NULL; req = NULL; } spin_unlock_bh(&queue->fastopenq.lock); } out: release_sock(sk); if (req) reqsk_put(req); return newsk; out_err: newsk = NULL; req = NULL; *err = error; goto out; } EXPORT_SYMBOL(inet_csk_accept);
服务端的inet_csk_accept函数会从请求队列中取出一个连接请求,如果队列为空则通过inet_csk_wait_for_connect阻塞住等待客户端的连接。
inet_csk_wait_for_connect函数定义在net/ipv4/inet_connection_sock.c文件中:
static int inet_csk_wait_for_connect(struct sock *sk, long timeo) { struct inet_connection_sock *icsk = inet_csk(sk); DEFINE_WAIT(wait); int err; for (;;) { prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE); release_sock(sk); if (reqsk_queue_empty(&icsk->icsk_accept_queue)) timeo = schedule_timeout(timeo); sched_annotate_sleep(); lock_sock(sk); err = 0; if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) break; err = -EINVAL; if (sk->sk_state != TCP_LISTEN) break; err = sock_intr_errno(timeo); if (signal_pending(current)) break; err = -EAGAIN; if (!timeo) break; } finish_wait(sk_sleep(sk), &wait); return err; }
观察函数恍然大悟,所谓的队列为空则阻塞住等待客户端的连接,就是指的函数中的for循环,一旦有请求进来则跳出循环。
根据代码可以分析出整个三次握手的过程为:客户端通过tcp_v4_connect函数调用到tcp_connect函数,将请求发送数据包出去,服务器端则通过inet_csk_accept函数调用inet_csk_wait_for_connect函数中的for循环进入阻塞,直到监听到请求才跳出循环。connect启动到返回和accept返回之间就是所谓三次握手的时间。
3.三次握手中携带SYN/ACK的TCP头数据的发送和接收
以上分析了用户程序调用socket接口、通过系统调用陷入内核进入内核态的socket接口层代码,然后根据创建socket时指定协议选择适当的函数指针进入协议处理代码中。那么网卡接收到数据后是如何通知上层协议来接收并处理数据的呢。其实在TCP/IP协议栈的初始化过程中,协议栈将handler赋值为tcp_v4_rcv的函数指针,也就是TCP协议中负责接收处理数据的入口,接收TCP连接请求及进行三次握手处理过程也都是从这里开始。
内核在处理接收到的TCP报文时使用了4个队列容器,分别为receive、out_of_order、prequeue、backlog队列。当网卡接收到报文并判断为TCP协议后,将会调用到内核的tcp_v4_rcv方法。tcp_v4_rcv方法会把这个报文直接插入到receive队列中。
在该函数定义在net/ipv4/tcp_ipv4.c文件中:
/* * From tcp_input.c */ int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); int sdif = inet_sdif(skb); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; if (skb->pkt_type != PACKET_HOST) goto discard_it; /* Count it even if it's bad */ __TCP_INC_STATS(net, TCP_MIB_INSEGS); if (!pskb_may_pull(skb, sizeof(struct tcphdr))) goto discard_it; th = (const struct tcphdr *)skb->data; if (unlikely(th->doff < sizeof(struct tcphdr) / 4)) goto bad_packet; if (!pskb_may_pull(skb, th->doff * 4)) goto discard_it; /* An explanation is required here, I think. * Packet length and doff are validated by header prediction, * provided case of th->doff==0 is eliminated. * So, we defer the checks. */ if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); lookup: sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, sdif, &refcounted); if (!sk) goto no_tcp_socket; process: if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; if (sk->sk_state == TCP_NEW_SYN_RECV) { struct request_sock *req = inet_reqsk(sk); bool req_stolen = false; struct sock *nsk; sk = req->rsk_listener; if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) { sk_drops_add(sk, skb); reqsk_put(req); goto discard_it; } if (tcp_checksum_complete(skb)) { reqsk_put(req); goto csum_error; } if (unlikely(sk->sk_state != TCP_LISTEN)) { inet_csk_reqsk_queue_drop_and_put(sk, req); goto lookup; } /* We own a reference on the listener, increase it again * as we might lose it too soon. */ sock_hold(sk); refcounted = true; nsk = NULL; if (!tcp_filter(sk, skb)) { th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); tcp_v4_fill_cb(skb, iph, th); nsk = tcp_check_req(sk, skb, req, false, &req_stolen); } if (!nsk) { reqsk_put(req); if (req_stolen) { /* Another cpu got exclusive access to req * and created a full blown socket. * Try to feed this packet to this socket * instead of discarding it. */ tcp_v4_restore_cb(skb); sock_put(sk); goto lookup; } goto discard_and_relse; } if (nsk == sk) { reqsk_put(req); tcp_v4_restore_cb(skb); } else if (tcp_child_process(sk, nsk, skb)) { tcp_v4_send_reset(nsk, skb); goto discard_and_relse; } else { sock_put(sk); return 0; } } if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) { __NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP); goto discard_and_relse; } if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) goto discard_and_relse; if (tcp_v4_inbound_md5_hash(sk, skb)) goto discard_and_relse; nf_reset(skb); if (tcp_filter(sk, skb)) goto discard_and_relse; th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); tcp_v4_fill_cb(skb, iph, th); skb->dev = NULL; if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk); tcp_segs_in(tcp_sk(sk), skb); ret = 0; if (!sock_owned_by_user(sk)) { ret = tcp_v4_do_rcv(sk, skb); } else if (tcp_add_backlog(sk, skb)) { goto discard_and_relse; } bh_unlock_sock(sk); put_and_return: if (refcounted) sock_put(sk); return ret; no_tcp_socket: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) goto discard_it; tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) { csum_error: __TCP_INC_STATS(net, TCP_MIB_CSUMERRORS); bad_packet: __TCP_INC_STATS(net, TCP_MIB_INERRS); } else { tcp_v4_send_reset(NULL, skb); } discard_it: /* Discard frame. */ kfree_skb(skb); return 0; discard_and_relse: sk_drops_add(sk, skb); if (refcounted) sock_put(sk); goto discard_it; do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { inet_twsk_put(inet_twsk(sk)); goto discard_it; } tcp_v4_fill_cb(skb, iph, th); if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev), &tcp_hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb), sdif); if (sk2) { inet_twsk_deschedule_put(inet_twsk(sk)); sk = sk2; tcp_v4_restore_cb(skb); refcounted = false; goto process; } } /* to ACK */ /* fall through */ case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; case TCP_TW_RST: tcp_v4_send_reset(sk, skb); inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; case TCP_TW_SUCCESS:; } goto discard_it; }
tcp_v4_rcv函数只要做以下几个工作:
(1) 设置TCP_CB
(2) 查找控制块
(3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理
(4) 接收TCP段
以上完成了将接收数据放入accept队列中,之后服务端接收客户端发来的tcp报文,并发送回SYN+ACK。
这里用到的是tcp_v4_do_rcv函数,其定义在net/ipv4/tcp_ipv4.c文件中:
/* The socket must have it's spinlock held when we get * here, unless it is a TCP_LISTEN socket. * * We have a potential double-lock case here, so even when * doing backlog processing we use the BH locking scheme. * This is because we cannot sleep with the original spinlock * held. */ int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb) { struct sock *rsk; if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */ struct dst_entry *dst = sk->sk_rx_dst; sock_rps_save_rxhash(sk, skb); sk_mark_napi_id(sk, skb); if (dst) { if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif || !dst->ops->check(dst, 0)) { dst_release(dst); sk->sk_rx_dst = NULL; } } tcp_rcv_established(sk, skb); return 0; } if (tcp_checksum_complete(skb)) goto csum_err; if (sk->sk_state == TCP_LISTEN) { struct sock *nsk = tcp_v4_cookie_check(sk, skb); if (!nsk) goto discard; if (nsk != sk) { if (tcp_child_process(sk, nsk, skb)) { rsk = nsk; goto reset; } return 0; } } else sock_rps_save_rxhash(sk, skb); if (tcp_rcv_state_process(sk, skb)) { rsk = sk; goto reset; } return 0; reset: tcp_v4_send_reset(rsk, skb); discard: kfree_skb(skb); /* Be careful here. If this function gets more complicated and * gcc suffers from register pressure on the x86, sk (in %ebx) * might be destroyed here. This current version compiles correctly, * but you have been warned. */ return 0; csum_err: TCP_INC_STATS(sock_net(sk), TCP_MIB_CSUMERRORS); TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS); goto discard; } EXPORT_SYMBOL(tcp_v4_do_rcv);
首先函数检查当前是否处于半连接状态,并调用tcp_v4_hnd_req检查报文的状态字段,再针对报文类型调用不同函数进行处理,若是SYN报文,则调用tcp_rcv_state_process函数,进入到下一阶段,客户端收到服务端的SYN+ACK,并发送ACK。
tcp_rcv_state_process函数定义在net/ipv4/tcp_input.c文件中:
/* * This function implements the receiving procedure of RFC 793 for * all states except ESTABLISHED and TIME_WAIT. * It's called from both tcp_v4_rcv and tcp_v6_rcv and should be * address independent. */ int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { case TCP_CLOSE: goto discard; case TCP_LISTEN: if (th->ack) return 1; if (th->rst) goto discard; if (th->syn) { if (th->fin) goto discard; /* It is possible that we process SYN packets from backlog, * so we need to make sure to disable BH and RCU right there. */ rcu_read_lock(); local_bh_disable(); acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0; local_bh_enable(); rcu_read_unlock(); if (!acceptable) return 1; consume_skb(skb); return 0; } goto discard; case TCP_SYN_SENT: tp->rx_opt.saw_tstamp = 0; tcp_mstamp_refresh(tp); queued = tcp_rcv_synsent_state_process(sk, skb, th); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } tcp_mstamp_refresh(tp); tp->rx_opt.saw_tstamp = 0; req = tp->fastopen_rsk; if (req) { bool req_stolen; WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV && sk->sk_state != TCP_FIN_WAIT1); if (!tcp_check_req(sk, skb, req, true, &req_stolen)) goto discard; } if (!th->ack && !th->rst && !th->syn) goto discard; if (!tcp_validate_incoming(sk, skb, th, 0)) return 0; /* step 5: check the ACK field */ acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT | FLAG_NO_CHALLENGE_ACK) > 0; if (!acceptable) { if (sk->sk_state == TCP_SYN_RECV) return 1; /* send one RST */ tcp_send_challenge_ack(sk, skb); goto discard; } switch (sk->sk_state) { case TCP_SYN_RECV: tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */ if (!tp->srtt_us) tcp_synack_rtt_meas(sk, req); /* Once we leave TCP_SYN_RECV, we no longer need req * so release it. */ if (req) { inet_csk(sk)->icsk_retransmits = 0; reqsk_fastopen_remove(sk, req, false); /* Re-arm the timer because data may have been sent out. * This is similar to the regular data transmission case * when new data has just been ack'ed. * * (TFO) - we could try to be more aggressive and * retransmitting any data sooner based on when they * are sent out. */ tcp_rearm_rto(sk); } else { tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB); tp->copied_seq = tp->rcv_nxt; } smp_mb(); tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal crossed SYN case. * Passively open sockets are not waked up, because * sk->sk_sleep == NULL and sk->sk_socket == NULL. */ if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); if (tp->rx_opt.tstamp_ok) tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; if (!inet_csk(sk)->icsk_ca_ops->cong_control) tcp_update_pacing_rate(sk); /* Prevent spurious tcp_cwnd_restart() on first data packet */ tp->lsndtime = tcp_jiffies32; tcp_initialize_rcv_mss(sk); tcp_fast_path_on(tp); break; case TCP_FIN_WAIT1: { int tmo; /* If we enter the TCP_FIN_WAIT1 state and we are a * Fast Open socket and this is the first acceptable * ACK we have received, this would have acknowledged * our SYNACK so stop the SYNACK timer. */ if (req) { /* We no longer need the request sock. */ reqsk_fastopen_remove(sk, req, false); tcp_rearm_rto(sk); } if (tp->snd_una != tp->write_seq) break; tcp_set_state(sk, TCP_FIN_WAIT2); sk->sk_shutdown |= SEND_SHUTDOWN; sk_dst_confirm(sk); if (!sock_flag(sk, SOCK_DEAD)) { /* Wake up lingering close() */ sk->sk_state_change(sk); break; } if (tp->linger2 < 0) { tcp_done(sk); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { /* Receive out of order FIN after close() */ if (tp->syn_fastopen && th->fin) tcp_fastopen_active_disable(sk); tcp_done(sk); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } tmo = tcp_fin_time(sk); if (tmo > TCP_TIMEWAIT_LEN) { inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN); } else if (th->fin || sock_owned_by_user(sk)) { /* Bad case. We could lose such FIN otherwise. * It is not a big problem, but it looks confusing * and not so rare event. We still can lose it now, * if it spins in bh_lock_sock(), but it is really * marginal case. */ inet_csk_reset_keepalive_timer(sk, tmo); } else { tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto discard; } break; } case TCP_CLOSING: if (tp->snd_una == tp->write_seq) { tcp_time_wait(sk, TCP_TIME_WAIT, 0); goto discard; } break; case TCP_LAST_ACK: if (tp->snd_una == tp->write_seq) { tcp_update_metrics(sk); tcp_done(sk); goto discard; } break; } /* step 6: check the URG bit */ tcp_urg(sk, skb, th); /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) break; /* fall through */ case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: /* RFC 793 says to queue data in these states, * RFC 1122 says we MUST send a reset. * BSD 4.4 also does reset. */ if (sk->sk_shutdown & RCV_SHUTDOWN) { if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); tcp_reset(sk); return 1; } } /* Fall through */ case TCP_ESTABLISHED: tcp_data_queue(sk, skb); queued = 1; break; } /* tcp_data could move socket to TIME-WAIT */ if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: tcp_drop(sk, skb); } return 0; } EXPORT_SYMBOL(tcp_rcv_state_process);
当前客户端处于TCP_SYN_SENT状态,并调用tcp_rcv_synsent_state_process处理SYN_SENT状态下接收到的TCP段,发送ACK报文
到这里,三次握手期间tcp接收处理数据包的过程基本完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号