
Python爬取丁香人才网数据进行数据分析与可视化
Python 爬取丁香人才网数据进行数据分析与可视化
一,选题的背景
丁香人才网是丁香园旗下的专业医药生物求职招聘平台,提供全国真实的医院、药企、科研单位、生物公司的招聘信息,医学药学生物行业找工作首选丁香人才网
二,爬虫设计方案
1,爬虫名称:Python 爬取丁香人才网数据进行数据分析与可视化
三,页面的结构特征分析
2,Htmls页面解析
四,网络爬虫程序设计
1,数据爬取与采集
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 from pymongo import MongoClient 6 from pandas.io.json import json_normalize 7 8 plt.style.use('ggplot') 9 from pylab import mpl 10 mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题 11 plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点 12 plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 13 %matplotlib inline
1 conn = MongoClient(host='127.0.0.1', port=27017) # 实例化MongoClient 2 db = conn.get_database('DingXiang') # 连接到DingXiang数据库
1 erke = db.get_collection('erke') # erke 2 mon_data = erke.find() # 查询这个集合下的所有记录
1 erke_data = json_normalize([record for record in mon_data])
1 def get_data(department): 2 col = db.get_collection(department) 3 mon_data = col.find() 4 return json_normalize([record for record in mon_data])
1 neike_data = get_data('neike') 2 waike_data = get_data('waike') 3 yanke_data = get_data('yanke') 4 fuchanke_data = get_data('fuchanke')
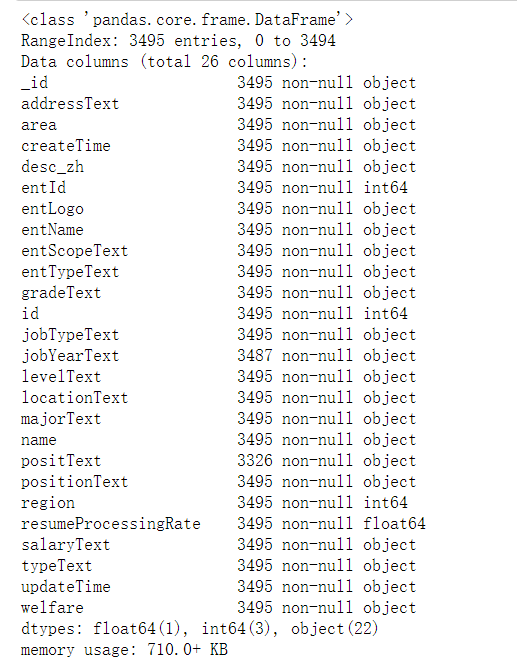
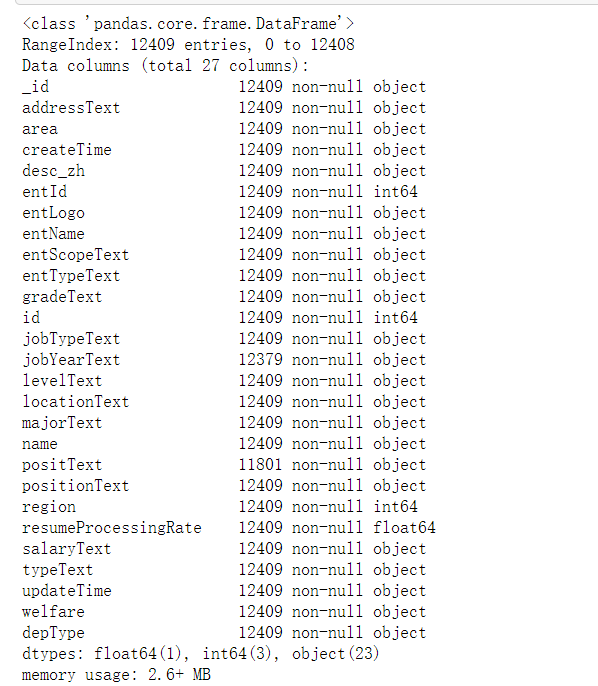
1 erke_data.info()
1 erke_data.sample(5)
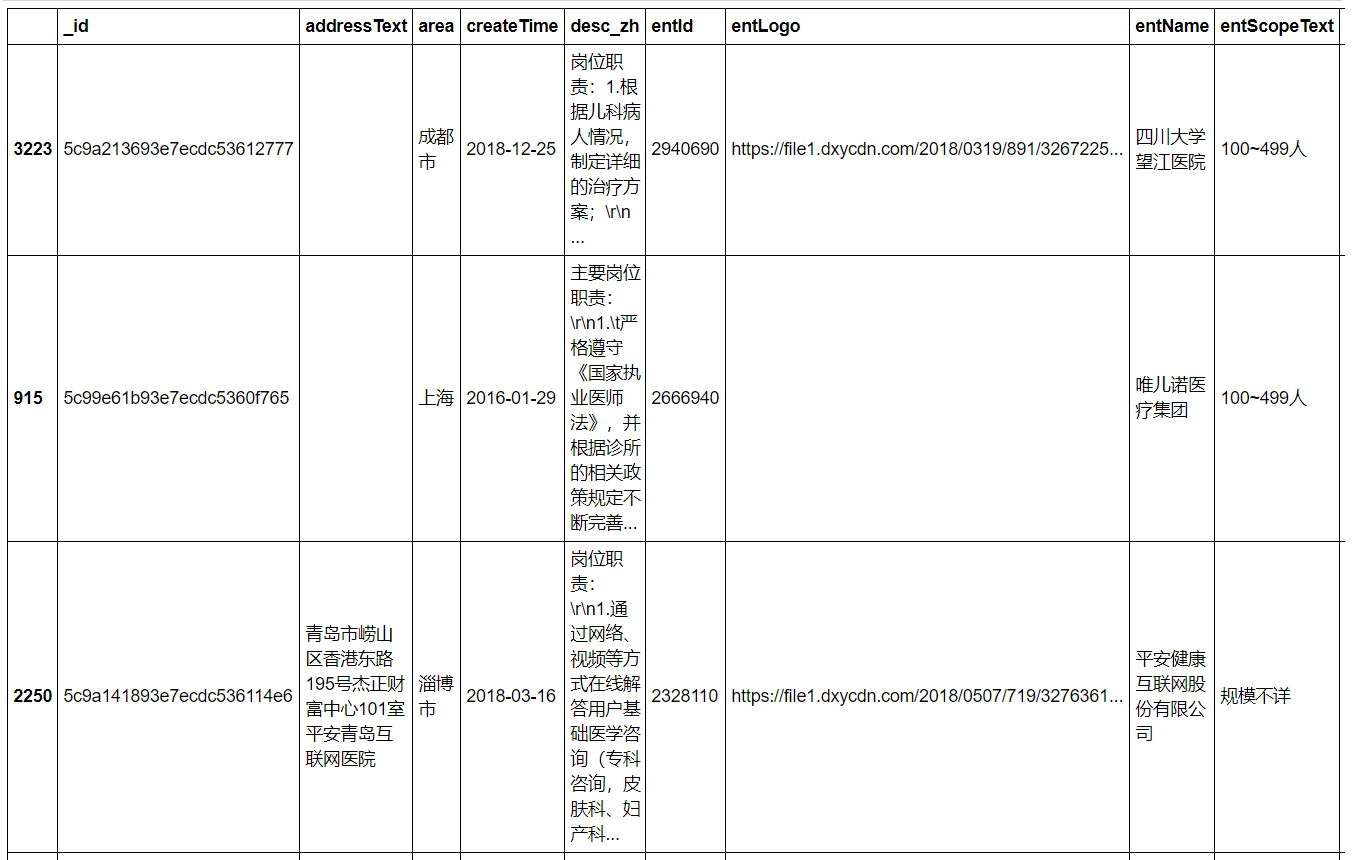
1 erke_data.iloc[754]

1 erke_data.sample(5)['name']

2,数据清洗
1 # 1.1 由于丁香人才会推荐其它科室的工作,所以需要选出属于本科室的工作 2 all_data = pd.concat([erke_data, neike_data, waike_data, yanke_data, fuchanke_data], 3 ignore_index=True) 4 5 erke_data = all_data[all_data['name'].str.contains('儿')] 6 neike_data = all_data[all_data['name'].str.contains('内')] 7 waike_data = all_data[all_data['name'].str.contains('外')] 8 yanke_data = all_data[all_data['name'].str.contains('眼')] 9 fuchanke_data = all_data[all_data['name'].str.contains('妇')] 10 11 erke_data['depType'] = '儿科' 12 neike_data['depType'] = '内科' 13 waike_data['depType'] = '外科' 14 yanke_data['depType'] = '眼科' 15 fuchanke_data['depType'] = '妇产科' 16 17 all_data = pd.concat([erke_data, neike_data, waike_data, yanke_data, fuchanke_data], 18 ignore_index=True)
1 all_data.info()
1 all_data.to_csv('all_data.csv', index=False)
1 # 1.2 把无用的字段删去 2 all_data.drop(columns=['_id', 'entLogo', 'region'], inplace=True)
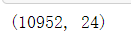
1 # 1.3 根据id去重 2 all_data.drop_duplicates(subset='id', inplace=True) 3 all_data.shape
1 # 1.4 创建时间、更新时间 数据类型转换 2 all_data['createTime'] = pd.to_datetime(all_data['createTime']) 3 all_data['updateTime'] = pd.to_datetime(all_data['updateTime'])
1 # 1.5 由于儿科的数据是按照市为单位爬取的,而其它科是按省爬取的,所以area没有参考意义,需要清理出省 2 all_data['locationText'].unique()

all_data.loc[all_data['depType'] != '儿科', 'province'] = all_data.loc[all_data['depType'] != '儿科', 'area']
all_data.loc[(all_data['locationText'].str.contains('北京|上海|天津|重庆|自治区|省'))& (all_data['depType'] == '儿科'), 'province']= all_data.loc[(all_data['locationText'].str.contains('北京|上海|天津|重庆|自治区|省'))& (all_data['depType'] == '儿科'), 'locationText'].str.split('省|自治区|市', expand=True)[0]
all_data['city'] = all_data['locationText'].str.extract(r'(.{2}市)')
1 # 1.6 工资字段很乱,需要定义一个函数处理 2 all_data['salaryText'].unique()

def process_k(data): if '千' in data: return float(data.replace('千', '')) * 1000 elif '万' in data: return float(data.replace('万', '')) * 10000 def process_salary(data): if data == '面议': return np.nan if '万以上' in data: return float(data.replace('万以上', '')) * 10000 if '千以下' in data: return float(data.replace('千以下', '')) * 1000 if '-' in data: low, high = data.split('-') return (process_k(low) + process_k(high))/2
all_data['salary'] = all_data['salaryText'].apply(process_salary)
all_data = all_data[-(all_data['salary']>100000)]
all_data.info()

all_data.iloc[2600]

2. 问题
字段:创建时间、更新时间、岗位职责、招聘单位名称、规模、单位类型、学历、岗位类型、工作经验、医院等级、专业、职称要求、简历处理速度、福利、科室、省份、城市、工资
- 儿科医生的需求现状怎么样?
- 儿科的工资待遇怎么样?
- 相同工资水平下,公立与民营对医生的学历、职称等要求如何?
- 全国各区域对于儿科医生的需求
- 儿科医生的福利和职责对比图
2.1 儿科医生的需求现状怎么样?
all_data[all_data['depType']=='儿科'].shape[0]
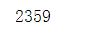
# 招聘儿科医生的单位类型占比 type_pct = all_data.loc[all_data['depType']=='儿科', 'typeText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100 from pyecharts import Bar bar = Bar("各类型单位招聘儿科岗位数百分比", width = 700,height=500) bar.add("", type_pct.index, np.round(type_pct.values, 1), is_stack=True, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=20) bar
# 公立/民营医院儿科医生招聘经验要求百分比 np.round(all_data.loc[all_data['depType']=='儿科', 'jobYearText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1)
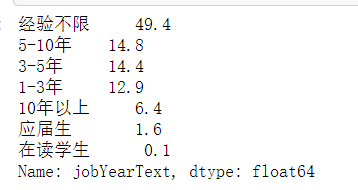
np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'jobYearText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1)

1 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'jobYearText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1)

exp = ['应届生', '1-3年', '3-5年', '5-10年', '10年以上', '经验不限'] exp1 = [1.6, 12.9, 14.4, 14.8, 6.4, 49.4] exp2 = [2.5, 9.2, 7.7, 8.1, 3.7, 68] exp3 = [0.5, 17.8, 22.3, 21.1, 9.7, 28.7] bar = Bar("公立/民营医院儿科医生招聘工作经验要求百分比", width = 600,height=500) bar.add("平均",exp, exp1, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("公立医院",exp, exp2, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("民营医院",exp, exp3, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar
# 公立/民营医院儿科医生招聘职称要求百分比 np.round(all_data.loc[all_data['depType']=='儿科', 'positText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1)
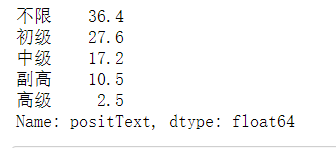
np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'positText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1)

np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'positText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1)

level = ['初级', '中级', '副高', '高级', '不限'] level1 = [27.6, 17.2, 10.5, 2.5, 36.4] level2 = [25, 8.1, 10.7, 3, 46.6] level3 = [33.2, 26.3, 10.3, 1.9, 23.7] bar = Bar("公立/民营医院儿科医生招聘职称要求百分比", width = 600,height=500) bar.add("平均",level, level1, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("公立医院",level, level2, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("民营医院",level, level3, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar
# 公立/民营医院儿科医生招聘学历要求百分比 np.round(all_data.loc[all_data['depType']=='儿科', 'gradeText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1)

np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'gradeText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1)

np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'gradeText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1)

grade = ['大专', '本科', '硕士', '博士', '学历不限'] grade1 = [15.7, 51.7, 21.6, 4.7, 6.2] grade2 = [4.1, 49.1, 34, 8.1, 4.7] grade3 = [30, 54.7, 6.1, 0.6, 8.5] bar = Bar("公立/民营医院儿科医生招聘学历要求百分比", width = 600,height=500) bar.add("平均",grade, grade1, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("公立医院",grade, grade2, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar.add("民营医院",grade, grade3, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar # 不同科室招聘持续时间 all_data['time_delta'] = pd.to_timedelta(all_data['updateTime']-all_data['createTime']) print(all_data.loc[all_data['depType']=='儿科', 'time_delta'].mean()) print(all_data.loc[all_data['depType']=='妇产科', 'time_delta'].mean()) print(all_data.loc[all_data['depType']=='眼科', 'time_delta'].mean()) print(all_data.loc[all_data['depType']=='内科', 'time_delta'].mean()) print(all_data.loc[all_data['depType']=='外科', 'time_delta'].mean())
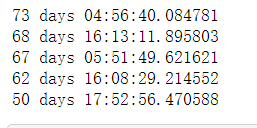
bar = Bar("各科室招聘平均已持续时间", width = 500,height=400) bar.add("", ['儿科', '妇产科', '眼科', '内科', '外科'], [73, 68, 67, 62, 50], is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30, xaxis_rotate=20) bar
2.2. 儿科的工资待遇怎么样?
mean_salary = all_data.groupby('depType')['salary'].mean().sort_values()
bar = Bar("儿科平均工资与其它科室对比", width = 600,height=400) bar.add("", mean_salary.index, np.round(mean_salary.values, 0), is_stack=True, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, ) bar
mean_slr_1 = all_data[all_data['typeText']=='公立医院'].groupby(['typeText', 'depType'])['salary'].mean()
mean_slr_2 = all_data[all_data['typeText']=='民营医院'].groupby(['typeText', 'depType'])['salary'].mean()
bar = Bar("公立/民营医院各科室平均工资", width = 600,height=600) bar.add("公立医院",['儿科', '内科', '外科', '妇产科', '眼科'], np.round(mean_slr_1.values, 0), is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar.add("民营医院", ['儿科', '内科', '外科', '妇产科', '眼科'], np.round(mean_slr_2.values, 0), is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar
fig, ax = plt.subplots(figsize=(12,6)) sns.violinplot(x="salary", y="typeText", data=all_data[(all_data['typeText'].isin(['公立医院', '民营医院']))& (all_data['depType']=='儿科')], ax=ax)

1 all_data[all_data['depType']=='儿科'].groupby('typeText')['salary'].count()
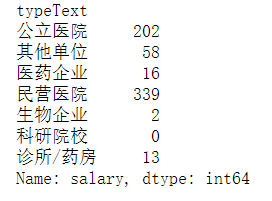
erke_srl =all_data[all_data['depType']=='儿科'].groupby('typeText')['salary'].mean().drop(index='科研院校').sort_values()
bar = Bar("各类型单位儿科平均工资", width = 600,height=500) bar.add("",erke_srl.index, np.round(erke_srl.values, 0), is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=20) bar
2.3 相同工资水平下,公立与民营对医生的学历、职称等要求如何?
all_data[(all_data['depType']=='儿科')& (all_data['salary']>8000)& (all_data['salary']<10000)& (all_data['typeText'].isin(['公立医院', '民营医院']))].groupby(['typeText', 'gradeText'])['id'].count()

grade_same1 = np.round(np.array([3, 31, 12, 1, 0]) / (3+31+12+1)*100, 1) grade_same2 = np.round(np.array([18, 21, 2, 0, 8]) / (18+21+2+8)*100, 1) bar = Bar("相同工资水平下公立/民营医院对学历的要求百分比(8k-10k)", width = 600,height=600) bar.add("公立医院",grade, grade_same1, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar.add("民营医院", grade, grade_same2, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar
all_data[(all_data['depType']=='儿科')& (all_data['salary']>8000)& (all_data['salary']<10000)& (all_data['typeText'].isin(['公立医院', '民营医院']))].groupby(['typeText', 'positText'])['id'].count()

level

level_same1 = np.round(np.array([15, 5, 2, 2, 23]) / (15+5+2+2+23)*100, 1) level_same2 = np.round(np.array([24, 6, 2, 0, 17]) / (24+6+2+17)*100, 1) bar = Bar("相同工资水平下公立/民营医院对职称的要求百分比(8k-10k)", width = 600,height=600) bar.add("公立医院",level, level_same1, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar.add("民营医院", level, level_same2, is_stack=False, xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) bar
2.4 全国各区域对于儿科医生的需求
# 对于province的处理结果还不是很满意,再处理以下 def get_province(data): province = ['北京', '天津', '河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '上海', '江苏', '浙江', '安徽', '福建', '江西', '山东', '河南', '湖北', '湖南', '广东', '广西', '海南', '重庆', '四川', '贵州', '云南', '西藏', '陕西', '甘肃', '青海', '宁夏', '新疆', '台湾', '香港', '澳门', '国外'] for i in province: if i in data: return i all_data.loc[all_data['depType']=='儿科', 'province2'] = all_data.loc[all_data['depType']=='儿科', 'locationText'].apply(get_province) demand = all_data.loc[all_data['depType']=='儿科', 'province2'].value_counts() province = list(demand.index) value = list(demand.values) province.extend(['内蒙古', '山西', '青海']) value.extend([1,1,1]) from pyecharts import Map map = Map("儿科医生全国各区域需求量", width=600, height=600) map.add( "", province, value, maptype="china", is_visualmap=True, visual_text_color="#000", ) map
2.5 儿科医生的要求和福利
from collections import Counter from pyecharts import WordCloud
all_data.iloc[888]

完整代码;
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 from pymongo import MongoClient 6 from pandas.io.json import json_normalize 7 8 plt.style.use('ggplot') 9 from pylab import mpl 10 mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题 11 plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点 12 plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 13 %matplotlib inline 14 15 ⊖ 16 In [1]: 17 import pandas as pd 18 import numpy as np 19 import matplotlib.pyplot as plt 20 import seaborn as sns 21 from pymongo import MongoClient 22 from pandas.io.json import json_normalize 23 24 plt.style.use('ggplot') 25 from pylab import mpl 26 mpl.rcParams['font.sans-serif'] = ['SimHei'] #解决seaborn中文字体显示问题 27 plt.rc('figure', figsize=(10, 10)) #把plt默认的图片size调大一点 28 plt.rcParams["figure.dpi"] =mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 29 %matplotlib inline 30 In [2]: 31 conn = MongoClient(host='127.0.0.1', port=27017) # 实例化MongoClient 32 db = conn.get_database('DingXiang') # 连接到DingXiang数据库 33 In [3]: 34 erke = db.get_collection('erke') # erke 35 mon_data = erke.find() # 查询这个集合下的所有记录 36 In [4]: 37 erke_data = json_normalize([record for record in mon_data]) 38 In [5]: 39 def get_data(department): 40 col = db.get_collection(department) 41 mon_data = col.find() 42 return json_normalize([record for record in mon_data]) 43 In [6]: 44 neike_data = get_data('neike') 45 waike_data = get_data('waike') 46 yanke_data = get_data('yanke') 47 fuchanke_data = get_data('fuchanke') 48 In [7]: 49 erke_data.info() 50 <class 'pandas.core.frame.DataFrame'> 51 RangeIndex: 3495 entries, 0 to 3494 52 Data columns (total 26 columns): 53 _id 3495 non-null object 54 addressText 3495 non-null object 55 area 3495 non-null object 56 createTime 3495 non-null object 57 desc_zh 3495 non-null object 58 entId 3495 non-null int64 59 entLogo 3495 non-null object 60 entName 3495 non-null object 61 entScopeText 3495 non-null object 62 entTypeText 3495 non-null object 63 gradeText 3495 non-null object 64 id 3495 non-null int64 65 jobTypeText 3495 non-null object 66 jobYearText 3487 non-null object 67 levelText 3495 non-null object 68 locationText 3495 non-null object 69 majorText 3495 non-null object 70 name 3495 non-null object 71 positText 3326 non-null object 72 positionText 3495 non-null object 73 region 3495 non-null int64 74 resumeProcessingRate 3495 non-null float64 75 salaryText 3495 non-null object 76 typeText 3495 non-null object 77 updateTime 3495 non-null object 78 welfare 3495 non-null object 79 dtypes: float64(1), int64(3), object(22) 80 memory usage: 710.0+ KB 81 In [8]: 82 erke_data.sample(5) 83 Out[8]: 84 _id addressText area createTime desc_zh entId entLogo entName entScopeText entTypeText ... majorText name positText positionText region resumeProcessingRate salaryText typeText updateTime welfare 85 3223 5c9a213693e7ecdc53612777 成都市 2018-12-25 岗位职责:1.根据儿科病人情况,制定详细的治疗方案;\r\n ... 2940690 https://file1.dxycdn.com/2018/0319/891/3267225... 四川大学望江医院 100~499人 公立医院 ... 儿科学 儿科医生 初级 儿科 0 60.0 8千-9千 公立医院 2018-12-25 [五险一金, 带薪年假, 晋升机会, 定期体检] 86 915 5c99e61b93e7ecdc5360f765 上海 2016-01-29 主要岗位职责:\r\n1.\t严格遵守《国家执业医师法》,并根据诊所的相关政策规定不断完善... 2666940 唯儿诺医疗集团 100~499人 民营医院 ... 儿科学 儿科门诊部儿科医师 中级 儿科 0 20.0 2万-3万 民营医院 2016-01-29 [] 87 2250 5c9a141893e7ecdc536114e6 青岛市崂山区香港东路195号杰正财富中心101室平安青岛互联网医院 淄博市 2018-03-16 岗位职责:\r\n1.通过网络、视频等方式在线解答用户基础医学咨询(专科咨询,皮肤科、妇产科... 2328110 https://file1.dxycdn.com/2018/0507/719/3276361... 平安健康互联网股份有限公司 规模不详 其他单位 ... 中医学 中医(平安青岛互联网医院) 中级 中医科 0 45.0 1.5万-3万 其他单位 2018-03-16 [五险一金, 节日福利, 带薪年假, 住房补贴, 晋升机会, 定期体检, 高温补贴] 88 1278 5c99e8b693e7ecdc5360fc69 无锡市 2019-03-21 招聘单位:苏州院区\n招聘科室:儿科\n招聘岗位:主治医师\n岗位要求:1、二甲及以上医院工... 63824 https://file1.dxycdn.com/2018/0504/745/3275814... 明基医院(南京院区+苏州院区) 1000~9999人 民营医院 ... 临床医学 儿科主治医师(苏州院区) 不限 儿科 0 22.0 面议 民营医院 2019-03-24 [] 89 820 5c99e57a93e7ecdc5360f628 上海 2019-03-08 招聘岗位:呼吸科医师\n学历要求:硕士\n其他要求:儿科学相关专业 1808855 https://file1.dxycdn.com/2018/0423/399/3273732... 复旦大学附属儿科医院 1000~9999人 公立医院 ... 临床医学 呼吸科医师 不限 呼吸内科 0 20.0 面议 公立医院 2019-03-08 [] 90 5 rows × 26 columns 91 92 In [9]: 93 erke_data.iloc[754] 94 Out[9]: 95 _id 5c99bd9c93e7ecdc5360dcfd 96 addressText 亦资街道下街村 97 area 贵阳市 98 createTime 2019-01-26 99 desc_zh 专职从事新生儿科医师工作,1.具有执业医师资格证书,编外招聘,同工同酬待遇,五险一金。2.具... 100 entId 3044915 101 entLogo https://img1.dxycdn.com/2018/0817/541/32952613... 102 entName 盘州市人民医院 103 entScopeText 500~999人 104 entTypeText 公立医院 105 gradeText 本科 106 id 768820 107 jobTypeText 全职 108 jobYearText 经验不限 109 levelText 二甲 110 locationText 六盘水市盘州市 111 majorText 儿科学 112 name 新生儿科 113 positText 初级 114 positionText 儿科 115 region 0 116 resumeProcessingRate 53 117 salaryText 面议 118 typeText 公立医院 119 updateTime 2019-03-21 120 welfare [五险一金, 带薪年假, 晋升机会, 科研经费, 引进补贴, 定期体检] 121 Name: 754, dtype: object 122 In [13]: 123 erke_data.sample(5)['name'] 124 Out[13]: 125 2739 儿科医师 126 1334 儿保科医师 127 2811 儿科执业医师 128 11208 小儿外科医师 129 9214 小儿烧伤 学科带头人 130 Name: name, dtype: object 131 1. 数据清理 132 In [11]: 133 # 1.1 由于丁香人才会推荐其它科室的工作,所以需要选出属于本科室的工作 134 all_data = pd.concat([erke_data, neike_data, waike_data, yanke_data, fuchanke_data], 135 ignore_index=True) 136 137 erke_data = all_data[all_data['name'].str.contains('儿')] 138 neike_data = all_data[all_data['name'].str.contains('内')] 139 waike_data = all_data[all_data['name'].str.contains('外')] 140 yanke_data = all_data[all_data['name'].str.contains('眼')] 141 fuchanke_data = all_data[all_data['name'].str.contains('妇')] 142 143 erke_data['depType'] = '儿科' 144 neike_data['depType'] = '内科' 145 waike_data['depType'] = '外科' 146 yanke_data['depType'] = '眼科' 147 fuchanke_data['depType'] = '妇产科' 148 149 all_data = pd.concat([erke_data, neike_data, waike_data, yanke_data, fuchanke_data], 150 ignore_index=True) 151 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:11: SettingWithCopyWarning: 152 A value is trying to be set on a copy of a slice from a DataFrame. 153 Try using .loc[row_indexer,col_indexer] = value instead 154 155 See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy 156 # This is added back by InteractiveShellApp.init_path() 157 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:12: SettingWithCopyWarning: 158 A value is trying to be set on a copy of a slice from a DataFrame. 159 Try using .loc[row_indexer,col_indexer] = value instead 160 161 See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy 162 if sys.path[0] == '': 163 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:13: SettingWithCopyWarning: 164 A value is trying to be set on a copy of a slice from a DataFrame. 165 Try using .loc[row_indexer,col_indexer] = value instead 166 167 See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy 168 del sys.path[0] 169 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:14: SettingWithCopyWarning: 170 A value is trying to be set on a copy of a slice from a DataFrame. 171 Try using .loc[row_indexer,col_indexer] = value instead 172 173 See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy 174 175 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:15: SettingWithCopyWarning: 176 A value is trying to be set on a copy of a slice from a DataFrame. 177 Try using .loc[row_indexer,col_indexer] = value instead 178 179 See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy 180 from ipykernel import kernelapp as app 181 In [12]: 182 all_data.info() 183 <class 'pandas.core.frame.DataFrame'> 184 RangeIndex: 12409 entries, 0 to 12408 185 Data columns (total 27 columns): 186 _id 12409 non-null object 187 addressText 12409 non-null object 188 area 12409 non-null object 189 createTime 12409 non-null object 190 desc_zh 12409 non-null object 191 entId 12409 non-null int64 192 entLogo 12409 non-null object 193 entName 12409 non-null object 194 entScopeText 12409 non-null object 195 entTypeText 12409 non-null object 196 gradeText 12409 non-null object 197 id 12409 non-null int64 198 jobTypeText 12409 non-null object 199 jobYearText 12379 non-null object 200 levelText 12409 non-null object 201 locationText 12409 non-null object 202 majorText 12409 non-null object 203 name 12409 non-null object 204 positText 11801 non-null object 205 positionText 12409 non-null object 206 region 12409 non-null int64 207 resumeProcessingRate 12409 non-null float64 208 salaryText 12409 non-null object 209 typeText 12409 non-null object 210 updateTime 12409 non-null object 211 welfare 12409 non-null object 212 depType 12409 non-null object 213 dtypes: float64(1), int64(3), object(23) 214 memory usage: 2.6+ MB 215 In [14]: 216 all_data.to_csv('all_data.csv', index=False) 217 # 注:Gitgub上保存的数据是这个数据,所以拿到GitHub上数据的同学,请把数据读入,然后从这里开始pick up 218 In [15]: 219 # 1.2 把无用的字段删去 220 all_data.drop(columns=['_id', 'entLogo', 'region'], inplace=True) 221 In [16]: 222 # 1.3 根据id去重 223 all_data.drop_duplicates(subset='id', inplace=True) 224 all_data.shape 225 Out[16]: 226 (10952, 24) 227 In [17]: 228 # 1.4 创建时间、更新时间 数据类型转换 229 all_data['createTime'] = pd.to_datetime(all_data['createTime']) 230 all_data['updateTime'] = pd.to_datetime(all_data['updateTime']) 231 In [18]: 232 # 1.5 由于儿科的数据是按照市为单位爬取的,而其它科是按省爬取的,所以area没有参考意义,需要清理出省 233 all_data['locationText'].unique() 234 Out[18]: 235 array(['北京市', '北京市丰台区', '北京市海淀区', '北京市朝阳区', '北京市门头沟区', '北京市延庆区', '北京市通州区', 236 '北京市昌平区', '北京市房山区', '北京市大兴区', '北京市西城区', '北京市石景山区', '天津市津南区', '天津市', 237 '天津市河东区', '天津市北辰区', '天津市宁河区', '天津市滨海新区', '天津市河西区', '天津市河北区', 238 '天津市和平区', '天津市西青区', '河北省石家庄市', '石家庄市桥西区', '沧州市新华区', '河北省邯郸市', 239 '河北省', '河北省唐山市', '保定市涞水县', '秦皇岛市卢龙县', '邯郸市涉县', '廊坊市固安县', '唐山市遵化市', 240 '邯郸市邯山区', '邯郸市丛台区', '衡水市安平县', '辽宁省沈阳市', '辽宁省大连市', '沈阳市铁西区', 241 '朝阳市凌源市', '大连市西岗区', '丹东市凤城市', '沈阳市于洪区', '大连市普兰店区', '沈阳市东陵区', 242 '大连市甘井子区', '营口市盖州市', '辽宁省', '大连市沙河口区', '吉林省吉林市', '吉林市船营区', '吉林省', 243 '吉林省长春市', '白山市浑江区', '河南省南阳市', '河南省开封市', '焦作市修武县', '河南省', '商丘市睢县', 244 '商丘市永城市', '郑州市二七区', '河南省郑州市', '河南省商丘市', '安阳市北关区', '河南省濮阳市', 245 '洛阳市西工区', '洛阳市嵩县', '郑州市管城回族区', '新乡市红旗区', '周口市扶沟县', '南阳市卧龙区', 246 '郑州市金水区', '洛阳市伊川县', '河南省新乡市', '焦作市解放区', '河南省信阳市', '河南省焦作市', 247 '信阳市固始县', '河南省洛阳市', '洛阳市涧西区', '湖北省武汉市', '武汉市洪山区', '武汉市汉阳区', 248 '武汉市硚口区', '武汉市新洲区', '武汉市江汉区', '宜昌市五峰土家族自治县', '湖北省孝感市', '湖北省荆门市', 249 '湖北省黄石市', '湖北省十堰市', '湖北省', '湖北省宜昌市', '湖北省襄阳市', '黄石市下陆区', '荆州市监利县', 250 '宜昌市伍家岗区', '湖北省荆州市', '湖北省恩施土家族苗族自治州', '咸宁市赤壁市', '黄石市西塞山区', 251 '十堰市茅箭区', '武汉市武昌区', '武汉市黄陂区', '武汉市江岸区', '深圳市南山区', '成都市青白江区', 252 '成都市武侯区', '四川省成都市', '成都市锦江区', '成都市青羊区', '贵州省贵阳市', '贵阳市南明区', '贵州省', 253 '安顺市普定县', '毕节市金沙县', '贵州省钟山区', '六盘水市盘州市', '贵阳市观山湖区', '铜仁市沿河土家族自治县', 254 '贵阳市乌当区', '遵义市务川仡佬族苗族自治县', '遵义市湄潭县', '遵义市仁怀市', '贵阳市白云区', '贵州省遵义市', 255 '遵义市桐梓县', '遵义市道真仡佬族苗族自治县', '贵州省六盘水市', '毕节市七星关区', '贵州省安顺市', 256 '黔西南布依族苗族自治州普安县', '贵州省毕节市', '哈尔滨市松北区', '黑龙江省哈尔滨市', '哈尔滨市平房区', 257 '哈尔滨市南岗区', '哈尔滨市道外区', '黑龙江省', '绥化市安达市', '包头市昆都仑区', '上海市', '上海市长宁区', 258 '上海市金山区', '上海市静安区', '上海市崇明区', '上海市虹口区', '上海市杨浦区', '上海市浦东新区', 259 '上海市嘉定区', '上海市松江区', '上海市黄浦区', '上海市闵行区', '上海市徐汇区', '上海市普陀区', 260 '上海市宝山区', '南京市浦口区', '南京市高淳区', '江苏省南京市', '江苏省苏州市', '江苏省南通市', 261 '徐州市邳州市', '江苏省连云港市', '无锡市梁溪区', '江苏省扬州市', '江苏省泰州市', '江苏省淮安市', 262 '江苏省徐州市', '江苏省无锡市', '淮安市洪泽区', '南通市海门市', '江苏省常州市', '镇江市扬中市', 263 '江苏省镇江市', '江苏省', '扬州市宝应县', '扬州市高邮市', '盐城市阜宁县', '徐州市泉山区', '泰州市靖江市', 264 '宿迁市宿城区', '泰州市姜堰区', '扬州市广陵区', '连云港市连云区', '苏州市昆山市', '泰州市兴化市', 265 '南通市启东市', '常州市武进区', '淮安市涟水县', '江苏省宿迁市', '泰州市海陵区', '无锡市惠山区', 266 '常州市天宁区', '苏州市姑苏区', '南京市建邺区', '南京市秦淮区', '南京市江宁区', '南京市鼓楼区', 267 '南京市雨花台区', '徐州市云龙区', '南通市崇川区', '无锡市新吴区', '苏州市张家港市', '宿迁市沭阳县', 268 '江苏省盐城市', '扬州市江都区', '苏州市吴中区', '徐州市鼓楼区', '无锡市滨湖区', '南通市如皋市', 269 '宿迁市泗阳县', '无锡市江阴市', '南京市六合区', '常州市新北区', '杭州市余杭区', '浙江省杭州市', 270 '杭州市下城区', '杭州市淳安县', '杭州市江干区', '杭州市临安区', '杭州市拱墅区', '杭州市富阳区', '浙江省', 271 '金华市兰溪市', '金华市永康市', '嘉兴市海宁市', '浙江省金华市', '宁波市北仑区', '宁波市鄞州区', 272 '浙江省嘉兴市', '嘉兴市海盐县', '浙江省台州市', '绍兴市上虞区', '湖州市长兴县', '浙江省绍兴市', 273 '浙江省宁波市', '衢州市开化县', '宁波市余姚市', '浙江省衢州市', '温州市苍南县', '丽水市遂昌县', 274 '台州市玉环市', '衢州市衢江区', '宁波市镇海区', '浙江省舟山市', '丽水市松阳县', '嘉兴市桐乡市', 275 '金华市义乌市', '湖州市安吉县', '绍兴市柯桥区', '丽水市缙云县', '金华市磐安县', '嘉兴市南湖区', 276 '金华市东阳市', '杭州市西湖区', '杭州市萧山区', '杭州市上城区', '舟山市普陀区', '宁波市慈溪市', 277 '嘉兴市嘉善县', '浙江省温州市', '嘉兴市秀洲区', '温州市乐清市', '湖州市吴兴区', '温州市瑞安市', 278 '宁波市海曙区', '杭州市滨江区', '宁波市象山县', '浙江省湖州市', '衢州市柯城区', '安徽省合肥市', 279 '合肥市蜀山区', '安徽省淮南市', '安徽省', '安徽省黄山市', '安徽省蚌埠市', '安庆市大观区', '蚌埠市龙子湖区', 280 '芜湖市鸠江区', '蚌埠市蚌山区', '阜阳市颍上县', '合肥市巢湖市', '合肥市肥西县', '合肥市瑶海区', 281 '合肥市庐阳区', '安徽省淮北市', '宿州市埇桥区', '亳州市谯城区', '淮南市谢家集区', '安徽省滁州市', 282 '六安市裕安区', '淮南市田家庵区', '宿州市灵璧县', '福建省福州市', '福州市连江县', '福州市鼓楼区', 283 '宁德市福安市', '泉州市安溪县', '厦门市湖里区', '漳州市龙文区', '南平市松溪县', '福建省漳州市', 284 '南平市延平区', '福建省', '福建省厦门市', '厦门市翔安区', '福州市仓山区', '福州市晋安区', '福建省泉州市', 285 '厦门市思明区', '厦门市同安区', '泉州市丰泽区', '泉州市惠安县', '上饶市弋阳县', '吉安市吉州区', 286 '江西省九江市', '江西省南昌市', '赣州市章贡区', '南昌市东湖区', '南昌市青山湖区', '南昌市西湖区', '江西省', 287 '宜春市袁州区', '抚州市临川区', '赣州市瑞金市', '济南市历城区', '济南市槐荫区', '济南市历下区', 288 '山东省烟台市', '山东省济宁市', '淄博市张店区', '山东省', '临沂市兰陵县', '山东省青岛市', '烟台市牟平区', 289 '淄博市淄川区', '淄博市博山区', '山东省潍坊市', '滨州市滨城区', '青岛市市北区', '威海市环翠区', 290 '济南市天桥区', '山东省菏泽市', '烟台市招远市', '长沙市长沙县', '长沙市开福区', '湖南省长沙市', 291 '湖南省衡阳市', '湘西土家族苗族自治州花垣县', '湖南省怀化市', '衡阳市石鼓区', '湖南省株洲市', '湖南省常德市', 292 '株洲市攸县', '岳阳市岳阳楼区', '怀化市新晃侗族自治县', '湖南省', '长沙市岳麓区', '长沙市雨花区', 293 '长沙市宁乡市', '长沙市天心区', '长沙市望城区', '湖南省岳阳市', '邵阳市双清区', '湖南省益阳市', 294 '广州市天河区', '惠州市惠城区', '深圳市宝安区', '湛江市坡头区', '广州市黄埔区', '广东省惠州市', 295 '深圳市龙岗区', '广州市越秀区', '广州市从化区', '广东省广州市', '广州市海珠区', '广州市白云区', 296 '广州市荔湾区', '广州市花都区', '广东省', '深圳市龙华区', '江门市台山市', '惠州市惠阳区', '广东省东莞市', 297 '广东省中山市', '广东省深圳市', '广东省佛山市', '广东省汕头市', '深圳市坪山区', '佛山市南海区', 298 '广州市番禺区', '河源市源城区', '佛山市三水区', '韶关市乐昌市', '阳江市阳春市', '珠海市斗门区', 299 '珠海市香洲区', '汕头市金平区', '广东省潮州市', '广东省珠海市', '佛山市顺德区', '江门市新会区', 300 '江门市开平市', '湛江市霞山区', '广东省湛江市', '广东省茂名市', '梅州市梅江区', '梅州市五华县', 301 '梅州市平远县', '肇庆市四会市', '汕头市潮阳区', '深圳市福田区', '揭阳市榕城区', '湛江市徐闻县', 302 '河源市连平县', '广东省梅州市', '清远市佛冈县', '深圳市罗湖区', '广东省清远市', '阳江市阳东区', 303 '梅州市梅县区', '惠州市博罗县', '南宁市隆安县', '广西南宁市', '南宁市良庆区', '广西桂林市', '广西柳州市', 304 '柳州市融安县', '贺州市富川瑶族自治县', '北海市海城区', '桂林市恭城瑶族自治县', '桂林市阳朔县', '广西百色市', 305 '柳州市柳南区', '崇左市凭祥市', '广西', '柳州市城中区', '南宁市青秀区', '河池市大化瑶族自治县', 306 '桂林市荔浦县', '桂林市兴安县', '贺州市八步区', '桂林市象山区', '海南省海口市', '海口市龙华区', 307 '海口市琼山区', '海南省琼中黎族苗族自治县', '海南省琼海市', '海南省乐东黎族自治县', '海南省儋州市', 308 '三亚市天涯区', '三亚市吉阳区', '海南省三亚市', '海南省', '海南省万宁市', '重庆市永川区', '重庆市沙坪坝区', 309 '重庆市綦江区', '重庆市', '重庆市石柱土家族自治县', '重庆市酉阳土家族苗族自治县', '重庆市九龙坡区', 310 '重庆市开州区', '重庆市巴南区', '重庆市渝北区', '成都市成华区', '成都市彭州市', '成都市简阳市', 311 '四川省绵阳市', '四川省泸州市', '南充市营山县', '绵阳市涪城区', '眉山市东坡区', '四川省', '自贡市自流井区', 312 '自贡市大安区', '成都市金牛区', '攀枝花市东区', '成都市双流区', '泸州市江阳区', '资阳市安岳县', 313 '自贡市富顺县', '乐山市峨眉山市', '南充市仪陇县', '泸州市合江县', '四川省乐山市', '凉山彝族自治州越西县', 314 '德阳市什邡市', '雅安市汉源县', '巴中市南江县', '乐山市沙湾区', '绵阳市江油市', '成都市金堂县', 315 '乐山市马边彝族自治县', '成都市温江区', '凉山彝族自治州甘洛县', '雅安市雨城区', '南充市顺庆区', '南充市蓬安县', 316 '乐山市市中区', '昆明市安宁市', '云南省昆明市', '云南省', '昆明市五华区', '昆明市西山区', '昆明市盘龙区', 317 '西藏那曲市', '西安市雁塔区', '西安市未央区', '陕西省西安市', '西安市新城区', '汉中市汉台区', 318 '陕西省安康市', '商洛市商州区', '陕西省咸阳市', '铜川市王益区', '西安市碑林区', '西安市莲湖区', 319 '西安市鄠邑区', '陕西省', '兰州市西固区', '甘肃省兰州市', '西宁市城西区', '宁夏', '固原市西吉县', 320 '塔城地区沙湾县', '新疆', '重庆市江北区', '日照市东港区', '许昌市魏都区', '佛山市禅城区', '重庆市渝中区', 321 '吕梁市岚县', '绍兴市诸暨市', '舟山市定海区', '黄山市屯溪区', '永州市宁远县', '昌都市卡若区', 322 '北京市顺义区', '北京市东城区', '天津市武清区', '天津市南开区', '天津市宝坻区', '石家庄市井陉县', 323 '河北省秦皇岛市', '石家庄市裕华区', '石家庄市无极县', '邢台市桥东区', '廊坊市香河县', '张家口市桥东区', 324 '秦皇岛市北戴河区', '保定市竞秀区', '廊坊市三河市', '保定市高碑店市', '河北省廊坊市', '衡水市桃城区', 325 '唐山市滦南县', '沧州市任丘市', '唐山市路南区', '廊坊市安次区', '邯郸市鸡泽县', '廊坊市广阳区', 326 '承德市平泉市', '廊坊市文安县', '河北省衡水市', '衡水市深州市', '河北省邢台市', '唐山市玉田县', 327 '太原市尖草坪区', '山西省大同市', '山西省', '临汾市尧都区', '呼和浩特市赛罕区', '大连市旅顺口区', 328 '沈阳市和平区', '沈阳市沈北新区', '铁岭市昌图县', '大连市金州区', '辽宁省阜新市', '丹东市振兴区', 329 '丹东市振安区', '吉林市昌邑区', '四平市梨树县', '长春市榆树市', '齐齐哈尔市铁锋区', '七台河市桃山区', 330 '绥化市明水县', '哈尔滨市香坊区', '黑龙江省鸡西市', '哈尔滨市道里区', '上海市奉贤区', '上海市青浦区', 331 '苏州市相城区', '扬州市邗江区', '连云港市灌南县', '镇江市丹阳市', '常州市溧阳市', '常州市金坛区', 332 '南京市玄武区', '徐州市铜山区', '苏州市虎丘区', '南京市栖霞区', '南通市通州区', '苏州市常熟市', 333 '南通市港闸区', '宿迁市泗洪县', '苏州市吴江区', '南通市如东县', '泰州市泰兴市', '盐城市亭湖区', 334 '徐州市沛县', '无锡市宜兴市', '盐城市东台市', '盐城市滨海县', '绍兴市嵊州市', '浙江省丽水市', 335 '杭州市建德市', '舟山市岱山县', '台州市温岭市', '台州市椒江区', '宁波市江北区', '宁波市宁海县', 336 '温州市瓯海区', '衢州市江山市', '丽水市莲都区', '绍兴市越城区', '阜阳市阜南县', '滁州市定远县', 337 '安徽省亳州市', '泉州市鲤城区', '莆田市荔城区', '龙岩市新罗区', '泉州市晋江市', '福州市台江区', 338 '厦门市集美区', '漳州市芗城区', '福州市平潭县', '厦门市海沧区', '淄博市临淄区', '泰安市岱岳区', 339 '山东省济南市', '山东省日照市', '山东省淄博市', '十堰市张湾区', '武汉市东西湖区', '武汉市蔡甸区', 340 '黄冈市麻城市', '随州市随县', '武汉市青山区', '株洲市荷塘区', '长沙市芙蓉区', '河南省安阳市', 341 '河南省许昌市', '郑州市新密市', '濮阳市华龙区', '周口市鹿邑县', '河南省鹤壁市', '周口市淮阳县', 342 '南阳市邓州市', '信阳市平桥区', '新乡市获嘉县', '邵阳市武冈市', '岳阳市平江县', '株洲市株洲县', 343 '永州市道县', '邵阳市新邵县', '张家界市永定区', '广州市南沙区', '惠州市惠东县', '广东省江门市', 344 '南宁市西乡塘区', '南宁市兴宁区', '南宁市武鸣区', '海口市秀英区', '重庆市合川区', '重庆市南岸区', 345 '重庆市奉节县', '重庆市南川区', '重庆市北碚区', '四川省南充市', '四川省自贡市', '成都市郫都区', 346 '乐山市夹江县', '成都市崇州市', '德阳市旌阳区', '巴中市恩阳区', '攀枝花市仁和区', 347 '黔西南布依族苗族自治州兴义市', '贵阳市云岩区', '贵阳市花溪区', '黔东南苗族侗族自治州黄平县', 348 '红河哈尼族彝族自治州建水县', '红河哈尼族彝族自治州石屏县', '迪庆藏族自治州香格里拉市', '昭通市昭阳区', 349 '红河哈尼族彝族自治州绿春县', '西安市灞桥区', '安康市汉滨区', '西安市长安区', '西安市临潼区', '青海省西宁市', 350 '石嘴山市大武口区', '巴音郭楞蒙古自治州若羌县', '国外', '内蒙古', '温州市鹿城区', '安徽省宿州市', 351 '蚌埠市五河县', '九江市浔阳区', '青岛市李沧区', '郑州市中原区', '湖南省永州市', '长沙市浏阳市', 352 '石家庄市新华区', '吕梁市汾阳市', '晋城市城区', '太原市小店区', '呼和浩特市回民区', '赤峰市松山区', 353 '大连市瓦房店市', '大连市中山区', '吉林市丰满区', '长春市二道区', '徐州市睢宁县', '南京市溧水区', 354 '杭州市桐庐县', '台州市天台县', '铜陵市铜官区', '滁州市来安县', '合肥市包河区', '宣城市旌德县', 355 '池州市东至县', '芜湖市弋江区', '滁州市明光市', '漳州市龙海市', '福州市福清市', '福建省宁德市', 356 '福建省莆田市', '三明市梅列区', '鹰潭市贵溪市', '九江市柴桑区', '上饶市余干县', '景德镇市珠山区', 357 '江西省萍乡市', '萍乡市安源区', '江西省上饶市', '潍坊市奎文区', '威海市乳山市', '烟台市芝罘区', 358 '济宁市兖州区', '青岛市平度市', '烟台市莱山区', '青岛市即墨区', '菏泽市牡丹区', '济宁市微山县', 359 '枣庄市滕州市', '青岛市城阳区', '烟台市福山区', '青岛市崂山区', '烟台市莱阳市', '德州市德城区', 360 '淄博市桓台县', '洛阳市瀍河回族区', '河南省周口市', '周口市太康县', '周口市郸城县', '安阳市林州市', 361 '黄冈市团风县', '孝感市孝南区', '荆州市沙市区', '黄石市黄石港区', '武汉市江夏区', '娄底市双峰县', 362 '湘潭市岳塘区', '阳江市江城区', '钦州市钦北区', '云南省昭通市', '唐山市路北区', '河北省保定市', 363 '石家庄市栾城区', '内蒙古呼伦贝尔市', '镇江市丹徒区', '金华市婺城区', '', '安徽省阜阳市', '三明市永安市', 364 '泉州市永春县', '泉州市石狮市', '三明市三元区', '江西省新余市', '南昌市新建区', '江西省抚州市', 365 '江西省赣州市', '开封市祥符区', '十堰市房县', '揭阳市揭西县', '汕尾市城区', '潮州市湘桥区', '揭阳市普宁市', 366 '云浮市云城区', '茂名市茂南区', '柳州市柳北区', '贵港市港北区', '海口市美兰区', '海南省澄迈县', 367 '重庆市巫溪县', '重庆市万州区', '重庆市铜梁区', '资阳市雁江区', '黔东南苗族侗族自治州从江县', '临沧市临翔区', 368 '丽江市古城区', '楚雄彝族自治州大姚县', '甘肃省', '新疆乌鲁木齐市', '伊犁哈萨克自治州伊宁市', '澳门', 369 '梅州市兴宁市', '湖北省咸宁市', '石家庄市长安区', '廊坊市霸州市', '金华市浦江县', '湖州市南浔区', 370 '金华市武义县', '滁州市琅琊区', '黄山市徽州区', '福州市罗源县', '赣州市会昌县', '南昌市湾里区', 371 '青岛市市南区', '泰安市东平县', '商丘市梁园区', '郑州市新郑市', '衡阳市衡山县', '清远市清城区', 372 '湛江市麻章区', '梅州市大埔县', '三亚市海棠区', '眉山市仁寿县', '四川省雅安市', '铜仁市德江县', 373 '咸阳市渭城区'], dtype=object) 374 In [19]: 375 all_data.loc[all_data['depType'] != '儿科', 'province'] = all_data.loc[all_data['depType'] != '儿科', 'area'] 376 In [20]: 377 all_data.loc[(all_data['locationText'].str.contains('北京|上海|天津|重庆|自治区|省'))& 378 (all_data['depType'] == '儿科'), 'province']= all_data.loc[(all_data['locationText'].str.contains('北京|上海|天津|重庆|自治区|省'))& 379 (all_data['depType'] == '儿科'), 'locationText'].str.split('省|自治区|市', expand=True)[0] 380 In [21]: 381 all_data['city'] = all_data['locationText'].str.extract(r'(.{2}市)') 382 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/ipykernel_launcher.py:1: FutureWarning: currently extract(expand=None) means expand=False (return Index/Series/DataFrame) but in a future version of pandas this will be changed to expand=True (return DataFrame) 383 """Entry point for launching an IPython kernel. 384 In [22]: 385 # 1.6 工资字段很乱,需要定义一个函数处理 386 all_data['salaryText'].unique() 387 Out[22]: 388 array(['8千-1万', '5千-8千', '面议', '1.5万-2万', '1.5万-3万', '1万-1.5万', '7千-1.5万', 389 '1.5万-2.5万', '1万-2万', '8千-1.5万', '2.5万以上', '7千-1万', '3千-8千', 390 '2千-1万', '5千-1万', '4千-1万', '5千-6千', '3千-5千', '2万-2.5万', '6千-1万', 391 '4千-7千', '1万-3万', '2万-3万', '2万-4万', '5千-1.2万', '2.5万-4万', 392 '5千-1.5万', '4千-8千', '4千-6千', '2千-4千', '2千-3千', '5千-2万', '3千-1万', 393 '2千-8千', '8千-1.2万', '2万-2.2万', '2.5万-4.5万', '2万-5万', '6千-1.2万', 394 '3万-3.5万', '1.2万-2万', '2万-3.5万', '3万-4万', '8千-10千', '5千-7千', 395 '5千-9千', '5千-9.5千', '80万-200万', '2.5万-3.5万', '8千-3万', '8千-1.6万', 396 '8千-2.5万', '6千-8千', '1万-1.3万', '5万-8万', '3千-6千', '6千-2万', 397 '1万-1.8万', '1.2万-3万', '1万-2.5万', '6千-9千', '2.5万-3万', '6千-1.5万', 398 '8千-1.1万', '8千-2万', '7千-2万', '1.8万-3万', '1.8万-2.5万', '4千-9千', 399 '6.5千-8千', '9千-1.2万', '4.5千-8千', '1.9万-4.9万', '1.2万-1.5万', 400 '7千-1.2万', '1.3万-1.8万', '8千-9千', '5万-10万', '3千-7千', '8千-1.4万', 401 '1.4万-2万', '7千-1.4万', '2.5万-8万', '1.2万-2.5万', '1.6万-5万', '1.5万-5万', 402 '1.2万-2.4万', '6千-7千', '4.5千-7千', '1.5万-3.5万', '1.3万-2万', '1.5万-4万', 403 '2千以下', '3千-4千', '7千-8千', '1.2万-1.4万', '1.6万-2.8万', '1.6万-3万', 404 '4千-5千', '1万-1.2万', '5.2千-1.5万', '4.5千-1.3万', '9.6千-3万', 405 '5.6千-7.4千', '3千-3千', '5.9千-2万', '7千-9千', '1.4万-4万', '4千-5.5千', 406 '3.8千-5千', '2千-6千', '2万-3.1万', '8千-1.3万', '4万-8万', '5.5千-1.5万', 407 '3万-5万', '4千-4.5千', '9千-1.5万', '6万-10万', '3千-4.5千', '3万-10万', 408 '1.2万-1.6万', '4千-1.5万', '9千-1.6万', '9千-1.8万', '3.5万-4万', '12万-15万', 409 '3.5千-6千', '4.5千-1.5万', '3.5千-5千', '4千-1.2万', '5万以上', '3万-6万', 410 '4.5千-6千', '2.5千-3.5千', '1万-1.1万', '1.2万-3.3万', '8千-2.6万', '5万-6万', 411 '6.5千-3万', '4.5千-7.5千', '8.5千-4万', '1.3万-6.5万', '2.5万-5万', '4万-4万', 412 '1.6万-2.5万', '4万-5万', '2万-2.8万', '5千-2.5万', '1万-5万', '3.5千-8千', 413 '1.8万-2.2万', '1.5千-2千', '4.5万-9.1万'], dtype=object) 414 In [23]: 415 def process_k(data): 416 if '千' in data: 417 return float(data.replace('千', '')) * 1000 418 elif '万' in data: 419 return float(data.replace('万', '')) * 10000 420 421 422 def process_salary(data): 423 if data == '面议': 424 return np.nan 425 if '万以上' in data: 426 return float(data.replace('万以上', '')) * 10000 427 if '千以下' in data: 428 return float(data.replace('千以下', '')) * 1000 429 if '-' in data: 430 low, high = data.split('-') 431 return (process_k(low) + process_k(high))/2 432 In [24]: 433 all_data['salary'] = all_data['salaryText'].apply(process_salary) 434 In [25]: 435 all_data = all_data[-(all_data['salary']>100000)] 436 In [26]: 437 all_data.info() 438 <class 'pandas.core.frame.DataFrame'> 439 Int64Index: 10950 entries, 0 to 12408 440 Data columns (total 27 columns): 441 addressText 10950 non-null object 442 area 10950 non-null object 443 createTime 10950 non-null datetime64[ns] 444 desc_zh 10950 non-null object 445 entId 10950 non-null int64 446 entName 10950 non-null object 447 entScopeText 10950 non-null object 448 entTypeText 10950 non-null object 449 gradeText 10950 non-null object 450 id 10950 non-null int64 451 jobTypeText 10950 non-null object 452 jobYearText 10928 non-null object 453 levelText 10950 non-null object 454 locationText 10950 non-null object 455 majorText 10950 non-null object 456 name 10950 non-null object 457 positText 10410 non-null object 458 positionText 10950 non-null object 459 resumeProcessingRate 10950 non-null float64 460 salaryText 10950 non-null object 461 typeText 10950 non-null object 462 updateTime 10950 non-null datetime64[ns] 463 welfare 10950 non-null object 464 depType 10950 non-null object 465 province 9864 non-null object 466 city 9988 non-null object 467 salary 3237 non-null float64 468 dtypes: datetime64[ns](2), float64(2), int64(2), object(21) 469 memory usage: 2.3+ MB 470 In [27]: 471 all_data.iloc[2600] 472 Out[27]: 473 addressText 474 area 天津 475 createTime 2019-03-13 00:00:00 476 desc_zh 聘用科室:心血管内科\n职位名称:心血管内科医师\n拟聘人数:2\n专业要求:心血管内科专业... 477 entId 2821301 478 entName 中国人民解放军第464医院 479 entScopeText 500~999人 480 entTypeText 公立医院 481 gradeText 本科 482 id 779607 483 jobTypeText 全职 484 jobYearText 1-3年 485 levelText 三甲 486 locationText 天津市 487 majorText 心血管病学 488 name 心血管内科医师 489 positText 初级 490 positionText 心血管内科 491 resumeProcessingRate 20 492 salaryText 面议 493 typeText 公立医院 494 updateTime 2019-03-13 00:00:00 495 welfare [] 496 depType 内科 497 province 天津 498 city 天津市 499 salary NaN 500 Name: 2981, dtype: object 501 2. 问题 502 字段:创建时间、更新时间、岗位职责、招聘单位名称、规模、单位类型、学历、岗位类型、工作经验、医院等级、专业、职称要求、简历处理速度、福利、科室、省份、城市、工资 503 504 儿科医生的需求现状怎么样? 505 儿科的工资待遇怎么样? 506 相同工资水平下,公立与民营对医生的学历、职称等要求如何? 507 全国各区域对于儿科医生的需求 508 儿科医生的福利和职责对比图 509 2.1 儿科医生的需求现状怎么样? 510 In [86]: 511 all_data[all_data['depType']=='儿科'].shape[0] 512 Out[86]: 513 2359 514 In [69]: 515 # 招聘儿科医生的单位类型占比 516 type_pct = all_data.loc[all_data['depType']=='儿科', 517 'typeText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100 518 In [75]: 519 from pyecharts import Bar 520 521 bar = Bar("各类型单位招聘儿科岗位数百分比", width = 700,height=500) 522 bar.add("", type_pct.index, np.round(type_pct.values, 1), is_stack=True, 523 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, 524 xaxis_rotate=20) 525 bar 526 Out[75]: 527 In [100]: 528 # 公立/民营医院儿科医生招聘经验要求百分比 529 np.round(all_data.loc[all_data['depType']=='儿科', 530 'jobYearText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1) 531 Out[100]: 532 经验不限 49.4 533 5-10年 14.8 534 3-5年 14.4 535 1-3年 12.9 536 10年以上 6.4 537 应届生 1.6 538 在读学生 0.1 539 Name: jobYearText, dtype: float64 540 In [101]: 541 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'jobYearText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1) 542 Out[101]: 543 经验不限 68.0 544 1-3年 9.2 545 5-10年 8.1 546 3-5年 7.7 547 10年以上 3.7 548 应届生 2.5 549 在读学生 0.2 550 Name: jobYearText, dtype: float64 551 In [102]: 552 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'jobYearText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1) 553 Out[102]: 554 经验不限 28.7 555 3-5年 22.3 556 5-10年 21.1 557 1-3年 17.8 558 10年以上 9.7 559 应届生 0.5 560 Name: jobYearText, dtype: float64 561 In [130]: 562 exp = ['应届生', '1-3年', '3-5年', '5-10年', '10年以上', '经验不限'] 563 exp1 = [1.6, 12.9, 14.4, 14.8, 6.4, 49.4] 564 exp2 = [2.5, 9.2, 7.7, 8.1, 3.7, 68] 565 exp3 = [0.5, 17.8, 22.3, 21.1, 9.7, 28.7] 566 bar = Bar("公立/民营医院儿科医生招聘工作经验要求百分比", width = 600,height=500) 567 bar.add("平均",exp, exp1, is_stack=False, 568 xaxis_label_textsize=20, yaxis_label_textsize=14, 569 is_label_show=True, legend_top=30, xaxis_rotate=20) 570 bar.add("公立医院",exp, exp2, is_stack=False, 571 xaxis_label_textsize=20, yaxis_label_textsize=14, 572 is_label_show=True, legend_top=30, xaxis_rotate=20) 573 bar.add("民营医院",exp, exp3, is_stack=False, 574 xaxis_label_textsize=20, yaxis_label_textsize=14, 575 is_label_show=True, legend_top=30, xaxis_rotate=20) 576 bar 577 Out[130]: 578 In [114]: 579 # 公立/民营医院儿科医生招聘职称要求百分比 580 np.round(all_data.loc[all_data['depType']=='儿科', 581 'positText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1) 582 Out[114]: 583 不限 36.4 584 初级 27.6 585 中级 17.2 586 副高 10.5 587 高级 2.5 588 Name: positText, dtype: float64 589 In [115]: 590 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'positText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1) 591 Out[115]: 592 不限 46.6 593 初级 25.0 594 副高 10.7 595 中级 8.1 596 高级 3.0 597 Name: positText, dtype: float64 598 In [116]: 599 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'positText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1) 600 Out[116]: 601 初级 33.2 602 中级 26.3 603 不限 23.7 604 副高 10.3 605 高级 1.9 606 Name: positText, dtype: float64 607 In [117]: 608 level = ['初级', '中级', '副高', '高级', '不限'] 609 level1 = [27.6, 17.2, 10.5, 2.5, 36.4] 610 level2 = [25, 8.1, 10.7, 3, 46.6] 611 level3 = [33.2, 26.3, 10.3, 1.9, 23.7] 612 bar = Bar("公立/民营医院儿科医生招聘职称要求百分比", width = 600,height=500) 613 bar.add("平均",level, level1, is_stack=False, 614 xaxis_label_textsize=20, yaxis_label_textsize=14, 615 is_label_show=True, legend_top=30, xaxis_rotate=20) 616 bar.add("公立医院",level, level2, is_stack=False, 617 xaxis_label_textsize=20, yaxis_label_textsize=14, 618 is_label_show=True, legend_top=30, xaxis_rotate=20) 619 bar.add("民营医院",level, level3, is_stack=False, 620 xaxis_label_textsize=20, yaxis_label_textsize=14, 621 is_label_show=True, legend_top=30, xaxis_rotate=20) 622 bar 623 Out[117]: 624 In [126]: 625 # 公立/民营医院儿科医生招聘学历要求百分比 626 np.round(all_data.loc[all_data['depType']=='儿科', 627 'gradeText'].value_counts()/all_data[all_data['depType']=='儿科'].shape[0]*100, 1) 628 Out[126]: 629 本科 51.7 630 硕士 21.6 631 大专 15.7 632 学历不限 6.2 633 博士 4.7 634 Name: gradeText, dtype: float64 635 In [127]: 636 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院'), 'gradeText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='公立医院')].shape[0]*100,1) 637 Out[127]: 638 本科 49.1 639 硕士 34.0 640 博士 8.1 641 学历不限 4.7 642 大专 4.1 643 Name: gradeText, dtype: float64 644 In [128]: 645 np.round(all_data.loc[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院'), 'gradeText'].value_counts()/all_data[(all_data['depType']=='儿科')&(all_data['typeText']=='民营医院')].shape[0]*100,1) 646 Out[128]: 647 本科 54.7 648 大专 30.0 649 学历不限 8.5 650 硕士 6.1 651 博士 0.6 652 Name: gradeText, dtype: float64 653 In [129]: 654 grade = ['大专', '本科', '硕士', '博士', '学历不限'] 655 grade1 = [15.7, 51.7, 21.6, 4.7, 6.2] 656 grade2 = [4.1, 49.1, 34, 8.1, 4.7] 657 grade3 = [30, 54.7, 6.1, 0.6, 8.5] 658 bar = Bar("公立/民营医院儿科医生招聘学历要求百分比", width = 600,height=500) 659 bar.add("平均",grade, grade1, is_stack=False, 660 xaxis_label_textsize=20, yaxis_label_textsize=14, 661 is_label_show=True, legend_top=30, xaxis_rotate=20) 662 bar.add("公立医院",grade, grade2, is_stack=False, 663 xaxis_label_textsize=20, yaxis_label_textsize=14, 664 is_label_show=True, legend_top=30, xaxis_rotate=20) 665 bar.add("民营医院",grade, grade3, is_stack=False, 666 xaxis_label_textsize=20, yaxis_label_textsize=14, 667 is_label_show=True, legend_top=30, xaxis_rotate=20) 668 bar 669 Out[129]: 670 In [ ]: 671 # 不同科室招聘持续时间 672 all_data['time_delta'] = pd.to_timedelta(all_data['updateTime']-all_data['createTime']) 673 In [118]: 674 print(all_data.loc[all_data['depType']=='儿科', 'time_delta'].mean()) 675 print(all_data.loc[all_data['depType']=='妇产科', 'time_delta'].mean()) 676 print(all_data.loc[all_data['depType']=='眼科', 'time_delta'].mean()) 677 print(all_data.loc[all_data['depType']=='内科', 'time_delta'].mean()) 678 print(all_data.loc[all_data['depType']=='外科', 'time_delta'].mean()) 679 73 days 04:56:40.084781 680 68 days 16:13:11.895803 681 67 days 05:51:49.621621 682 62 days 16:08:29.214552 683 50 days 17:52:56.470588 684 In [131]: 685 bar = Bar("各科室招聘平均已持续时间", width = 500,height=400) 686 bar.add("", ['儿科', '妇产科', '眼科', '内科', '外科'], 687 [73, 68, 67, 62, 50], is_stack=False, 688 xaxis_label_textsize=20, yaxis_label_textsize=14, 689 is_label_show=True, legend_top=30, xaxis_rotate=20) 690 bar 691 Out[131]: 692 2.2. 儿科的工资待遇怎么样? 693 In [28]: 694 mean_salary = all_data.groupby('depType')['salary'].mean().sort_values() 695 In [125]: 696 bar = Bar("儿科平均工资与其它科室对比", width = 600,height=400) 697 bar.add("", mean_salary.index, np.round(mean_salary.values, 0), is_stack=True, 698 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, 699 ) 700 bar 701 Out[125]: 702 In [30]: 703 mean_slr_1 = all_data[all_data['typeText']=='公立医院'].groupby(['typeText', 'depType'])['salary'].mean() 704 In [31]: 705 mean_slr_2 = all_data[all_data['typeText']=='民营医院'].groupby(['typeText', 'depType'])['salary'].mean() 706 In [32]: 707 bar = Bar("公立/民营医院各科室平均工资", width = 600,height=600) 708 bar.add("公立医院",['儿科', '内科', '外科', '妇产科', '眼科'], np.round(mean_slr_1.values, 0), is_stack=False, 709 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 710 bar.add("民营医院", ['儿科', '内科', '外科', '妇产科', '眼科'], np.round(mean_slr_2.values, 0), is_stack=False, 711 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 712 bar 713 Out[32]: 714 In [38]: 715 fig, ax = plt.subplots(figsize=(12,6)) 716 sns.violinplot(x="salary", y="typeText", 717 data=all_data[(all_data['typeText'].isin(['公立医院', '民营医院']))& 718 (all_data['depType']=='儿科')], 719 ax=ax) 720 Out[38]: 721 <matplotlib.axes._subplots.AxesSubplot at 0x113b8d128> 722 723 In [34]: 724 all_data[all_data['depType']=='儿科'].groupby('typeText')['salary'].count() 725 Out[34]: 726 typeText 727 公立医院 202 728 其他单位 58 729 医药企业 16 730 民营医院 339 731 生物企业 2 732 科研院校 0 733 诊所/药房 13 734 Name: salary, dtype: int64 735 In [35]: 736 erke_srl =all_data[all_data['depType']=='儿科'].groupby('typeText')['salary'].mean().drop(index='科研院校').sort_values() 737 In [36]: 738 bar = Bar("各类型单位儿科平均工资", width = 600,height=500) 739 bar.add("",erke_srl.index, np.round(erke_srl.values, 0), is_stack=False, 740 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, xaxis_rotate=20) 741 bar 742 Out[36]: 743 2.3 相同工资水平下,公立与民营对医生的学历、职称等要求如何? 744 In [139]: 745 all_data[(all_data['depType']=='儿科')& 746 (all_data['salary']>8000)& 747 (all_data['salary']<10000)& 748 (all_data['typeText'].isin(['公立医院', '民营医院']))].groupby(['typeText', 'gradeText'])['id'].count() 749 Out[139]: 750 typeText gradeText 751 公立医院 博士 1 752 大专 3 753 本科 31 754 硕士 12 755 民营医院 大专 18 756 学历不限 8 757 本科 21 758 硕士 2 759 Name: id, dtype: int64 760 In [149]: 761 grade_same1 = np.round(np.array([3, 31, 12, 1, 0]) / (3+31+12+1)*100, 1) 762 In [150]: 763 grade_same2 = np.round(np.array([18, 21, 2, 0, 8]) / (18+21+2+8)*100, 1) 764 In [153]: 765 bar = Bar("相同工资水平下公立/民营医院对学历的要求百分比(8k-10k)", width = 600,height=600) 766 bar.add("公立医院",grade, grade_same1, is_stack=False, 767 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 768 bar.add("民营医院", grade, grade_same2, is_stack=False, 769 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 770 bar 771 Out[153]: 772 In [152]: 773 all_data[(all_data['depType']=='儿科')& 774 (all_data['salary']>8000)& 775 (all_data['salary']<10000)& 776 (all_data['typeText'].isin(['公立医院', '民营医院']))].groupby(['typeText', 'positText'])['id'].count() 777 Out[152]: 778 typeText positText 779 公立医院 不限 23 780 中级 5 781 初级 15 782 副高 2 783 高级 2 784 民营医院 不限 17 785 中级 6 786 初级 24 787 副高 2 788 Name: id, dtype: int64 789 In [154]: 790 level 791 Out[154]: 792 ['初级', '中级', '副高', '高级', '不限'] 793 In [155]: 794 level_same1 = np.round(np.array([15, 5, 2, 2, 23]) / (15+5+2+2+23)*100, 1) 795 level_same2 = np.round(np.array([24, 6, 2, 0, 17]) / (24+6+2+17)*100, 1) 796 In [156]: 797 bar = Bar("相同工资水平下公立/民营医院对职称的要求百分比(8k-10k)", width = 600,height=600) 798 bar.add("公立医院",level, level_same1, is_stack=False, 799 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 800 bar.add("民营医院", level, level_same2, is_stack=False, 801 xaxis_label_textsize=20, yaxis_label_textsize=14, is_label_show=True, legend_top=30) 802 bar 803 Out[156]: 804 2.4 全国各区域对于儿科医生的需求 805 In [183]: 806 # 对于province的处理结果还不是很满意,再处理以下 807 def get_province(data): 808 province = ['北京', '天津', '河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '上海', '江苏', 809 '浙江', '安徽', '福建', '江西', '山东', '河南', '湖北', '湖南', '广东', '广西', 810 '海南', '重庆', '四川', '贵州', '云南', '西藏', '陕西', '甘肃', '青海', '宁夏', 811 '新疆', '台湾', '香港', '澳门', '国外'] 812 for i in province: 813 if i in data: 814 return i 815 In [184]: 816 all_data.loc[all_data['depType']=='儿科', 'province2'] = all_data.loc[all_data['depType']=='儿科', 'locationText'].apply(get_province) 817 In [208]: 818 demand = all_data.loc[all_data['depType']=='儿科', 'province2'].value_counts() 819 In [209]: 820 province = list(demand.index) 821 value = list(demand.values) 822 province.extend(['内蒙古', '山西', '青海']) 823 value.extend([1,1,1]) 824 In [210]: 825 from pyecharts import Map 826 827 828 map = Map("儿科医生全国各区域需求量", width=600, height=600) 829 map.add( 830 "", 831 province, 832 value, 833 maptype="china", 834 is_visualmap=True, 835 visual_text_color="#000", 836 ) 837 map 838 Out[210]: 839 2.5 儿科医生的要求和福利 840 In [168]: 841 from collections import Counter 842 from pyecharts import WordCloud 843 In [199]: 844 all_data.iloc[888] 845 Out[199]: 846 addressText 847 area 无锡市 848 createTime 2018-03-13 00:00:00 849 desc_zh 岗位职责: \r\n1、完善病案 书写病历,记录,分析,检查结果及完成出院小结 \r\n2、... 850 entId 2935047 851 entName 上海九悦医疗投资管理有限公司 852 entScopeText 1000~9999人 853 entTypeText 民营医院 854 gradeText 大专 855 id 700822 856 jobTypeText 全职 857 jobYearText 1-3年 858 levelText 二级 859 locationText 江苏省常州市 860 majorText 基础医学 861 name 住院医师(内、外、儿科)- 常州 862 positText 初级 863 positionText 医院/临床医疗 864 resumeProcessingRate 67 865 salaryText 面议 866 typeText 民营医院 867 updateTime 2019-03-24 00:00:00 868 welfare [五险一金, 带薪年假, 工作餐, 提供住宿] 869 depType 儿科 870 province 江苏 871 city 常州市 872 salary NaN 873 time_delta 376 days 00:00:00 874 province2 江苏 875 Name: 889, dtype: object 876 In [201]: 877 g = all_data.loc[all_data['depType']=='儿科', 'gradeText'].value_counts() 878 In [211]: 879 y = all_data.loc[all_data['depType']=='儿科', 'jobYearText'].value_counts() 880 In [232]: 881 l = all_data.loc[all_data['depType']=='儿科', 'levelText'].value_counts() 882 n = all_data.loc[all_data['depType']=='儿科', 'name'].value_counts() 883 p = all_data.loc[all_data['depType']=='儿科', 'positText'].value_counts() 884 t = all_data.loc[all_data['depType']=='儿科', 'typeText'].value_counts() 885 886 welfare= [] 887 for i in all_data.loc[all_data['depType']=='儿科', 'welfare']: 888 if len(i) > 0: 889 welfare.extend(i) 890 w = pd.Series(Counter(welfare)) 891 all = pd.concat([g, y, l, n, p, t, w]) 892 In [241]: 893 name, value = all.index, all.values 894 wordcloud = WordCloud(width=800, height=800) 895 wordcloud.add("", name, value, word_size_range=[20, 80]) 896 wordcloud
五,总结
- 儿科医生的需求现状良好的
- 儿科的工资待遇不错的
- 相同工资水平下,公立与民营对医生的学历、职称等要求是有差距的
- 全国各区域对于儿科医生的需求不断提高
达到了预期的目标

 浙公网安备 33010602011771号
浙公网安备 33010602011771号