记一次线上OOM问题分析与解决
一、问题情况
最近用户反映系统响应越来越慢,而且不是偶发性的慢。根据后台日志,可以看到系统已经有oom现象。
根据jdk自带的jconsole工具,可以监视到系统处于堵塞时期。cup占满,活动线程数持续增加,堆内存接近峰值。
二、分析情况
使用jconsole分析:
找到jdk安装路径,点击bin目录下的jconsole.exe,运行。
![]()
![]()
![]()
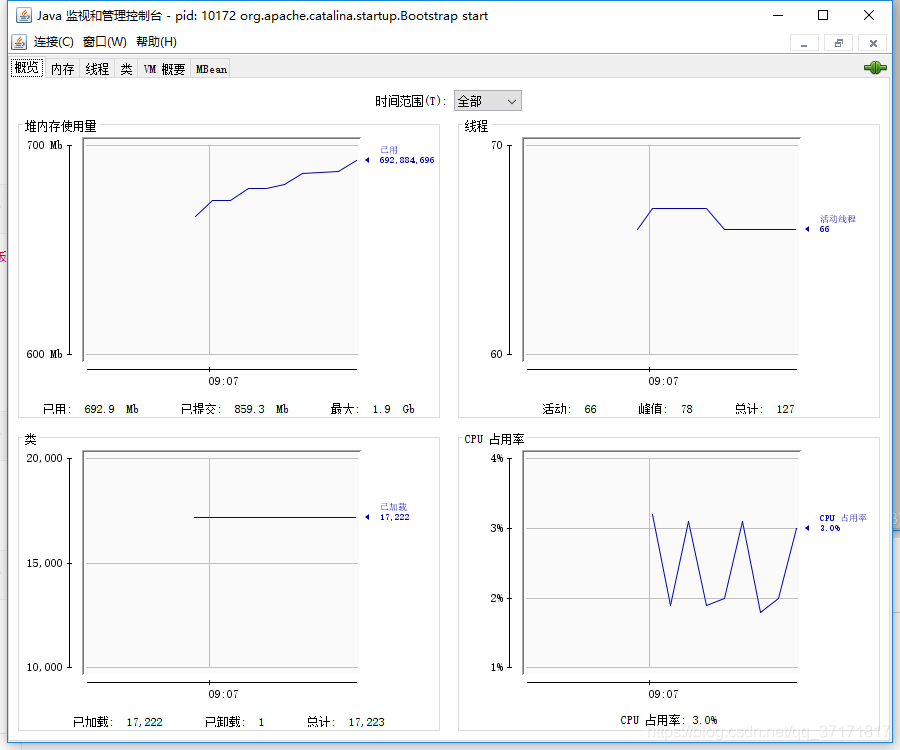
当时线上情况是堆内存使用量7个G左右,接近峰值;活动线程80个左右;CPU占用率80%左右。系统随时可能宕机。
根据用户反映的情况,系统每隔一段时间都会卡顿,且堆内存是一段时间上升,然后突然下降,再上升,所以我第一反应是:会不会是系统频繁的进行FullGC,导致系统在一段时间内不可用?
首先认识一下什么是Full GC(需要一定的java内存模型知识):
含义:FullGC是发生在永久代和老年代的一种垃圾回收机制。
触发条件:老年代内存满时。
特点:执行时间长,期间系统不可用。
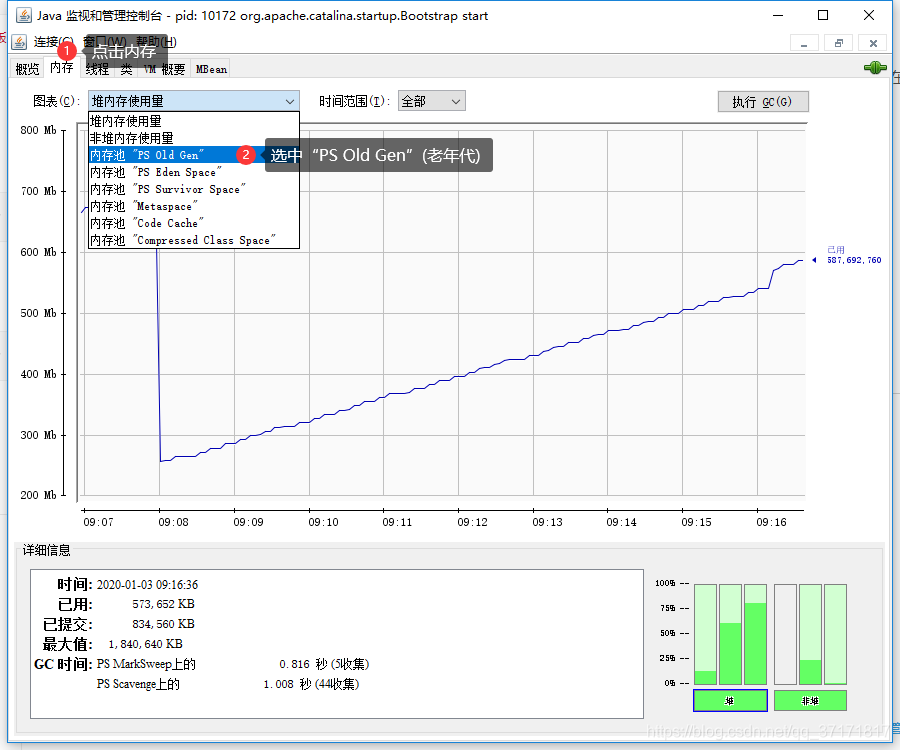
于是查看老年代占用情况:
![]()
使用期间老年代内存峰值已经达到7个G左右,接近上限。貌似有点坏气息的味道。
于是用jstat -gc pid查看gc回收情况:
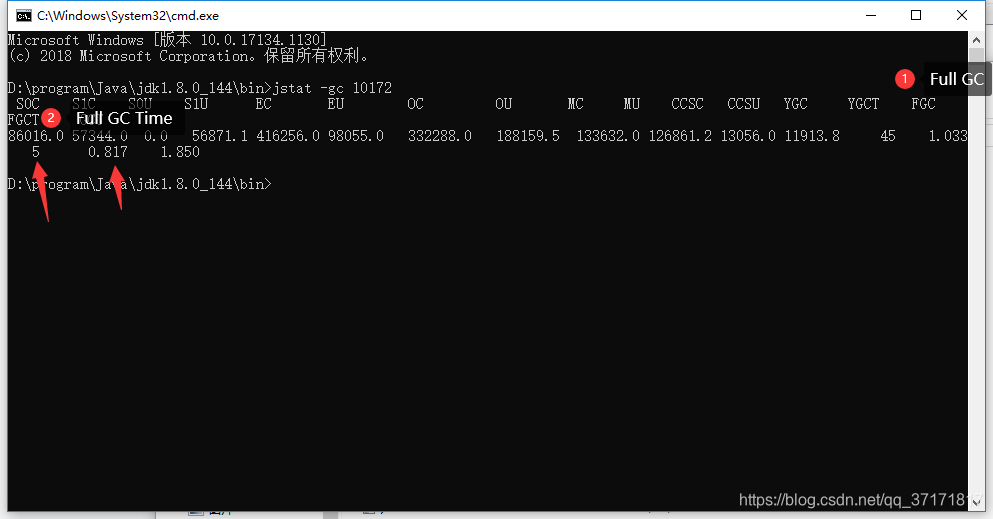
![]()
案发当时Full GC执行次数为28次,总执行时长为27秒。可以实锤是频繁Full GC导致系统线程堵塞。
上面介绍到了,老年代内存满时会触发FullGC,那么哪种情况下会进入老年代呢?
(1)对象在新生代中经历固定次数minor GC,会进入老年代
可通过-XX:MaxTenuringThreshold设置,默认15
(2)当新生代中minor GC回收后,存活对象大于survivor to区容量时,进入老年代
(3)大对象直接进入老年代
可通过-XX:PretenureSizeThreshold 设置
使用jvisualvm分析:
在jdk的bin目录下,找到jvisualvm.exe,点击运行。
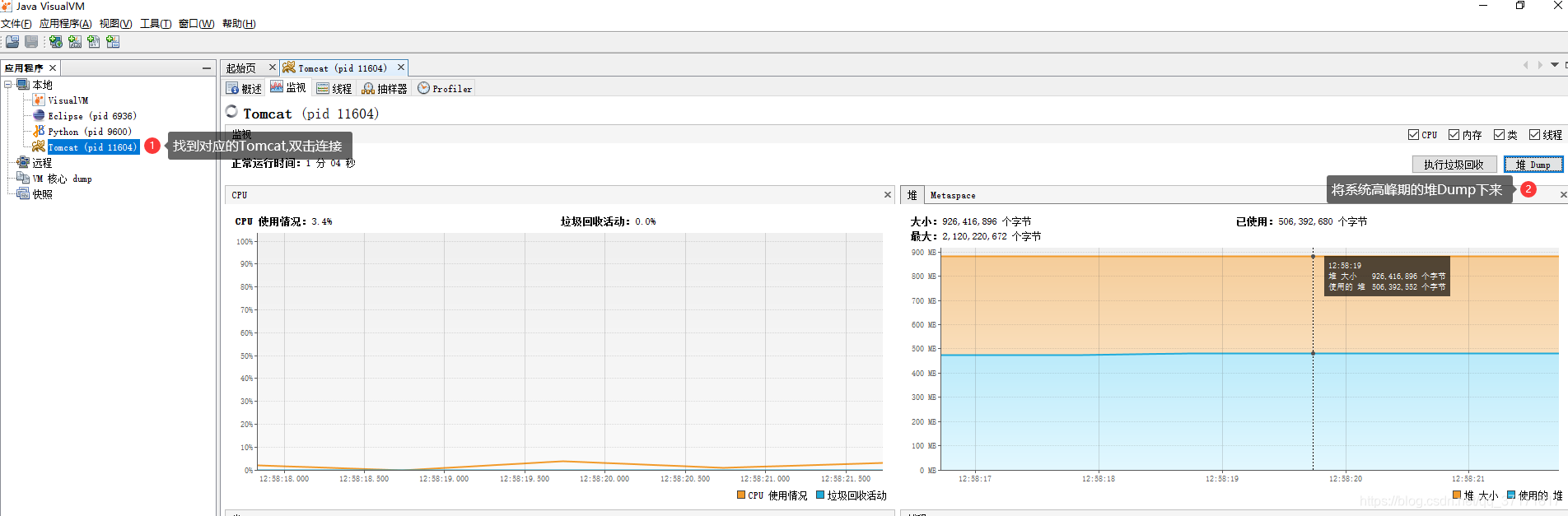
![]()
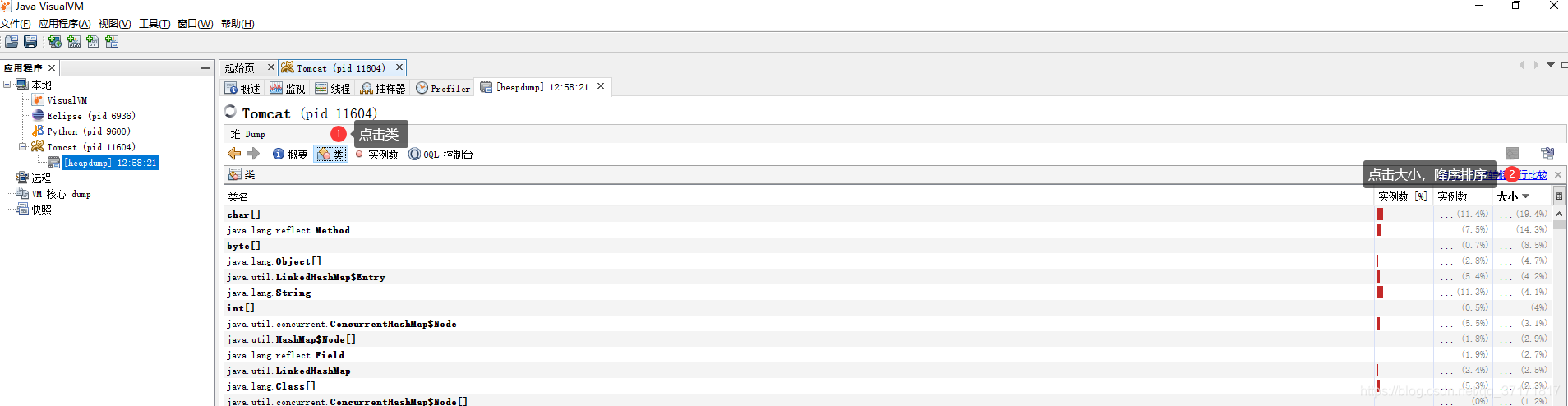
![]()
这里可以很清楚的看到堆内存的内容分布情况。当时系统是byte[]和InternalAprOutputBuffer占用内存最大,同为2.9G。
在此不能很直观的分析具体原因,建议使用Eclipse的Mat插件进行分析。
放上Mat插件的安装教程:https://mp.csdn.net/postedit/103815484
放上系统当时的Dump:
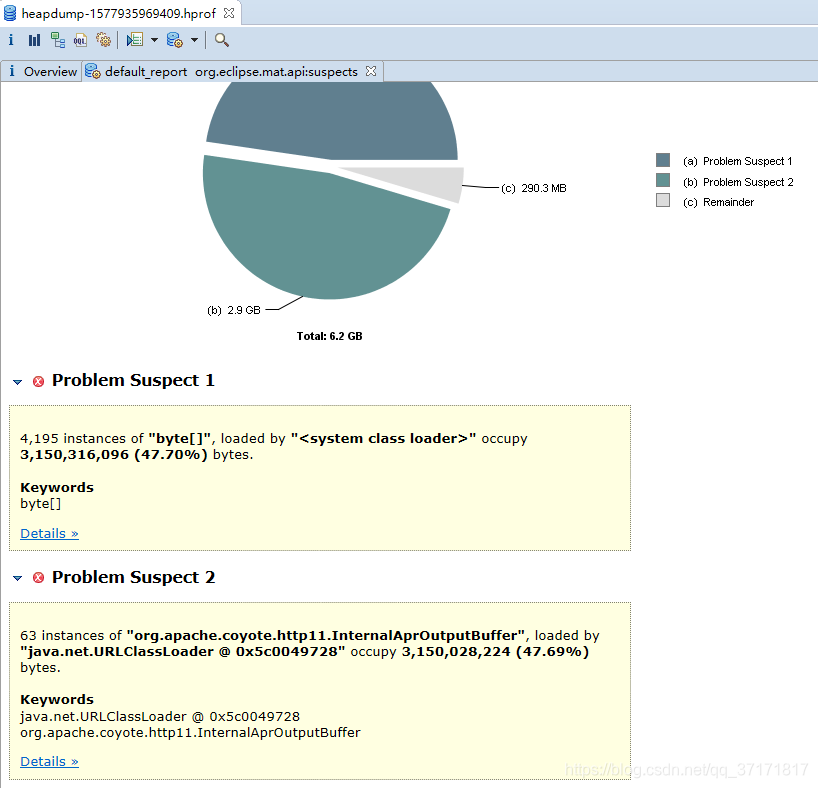
![]()
问题就在于这两处占用太多堆内存。
接着我们去查看Dominator Tree,可以查看到保持存活的最大对象集合
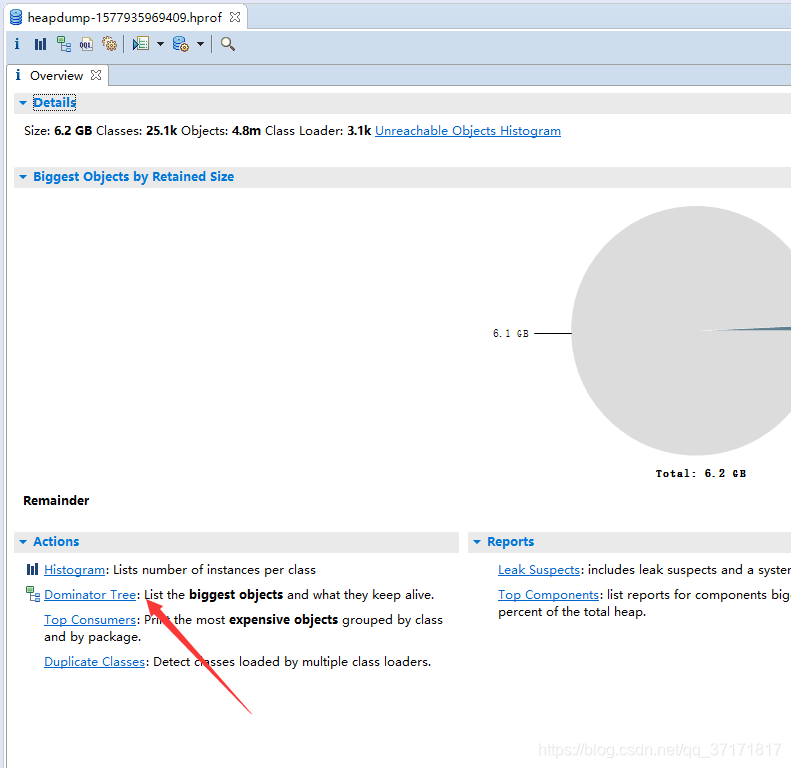
![]()
至少有一半都是InternalAprOutputBuffer对象。Shallow Heap 表示原本大小,Retained Heap表示在堆中占用内存的大小,单位bytes(1kb = 1024bytes),每个对象在堆中占约47.6兆空间,难以想象。
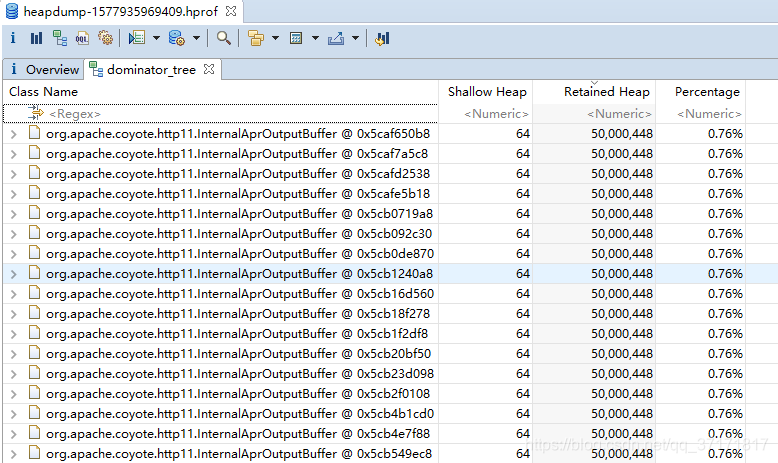
![]()
那么这些对象里都是些什么内容呢?为什么会这么多?
点开树形,发现内容就是这个容量为50000000的byte数组。
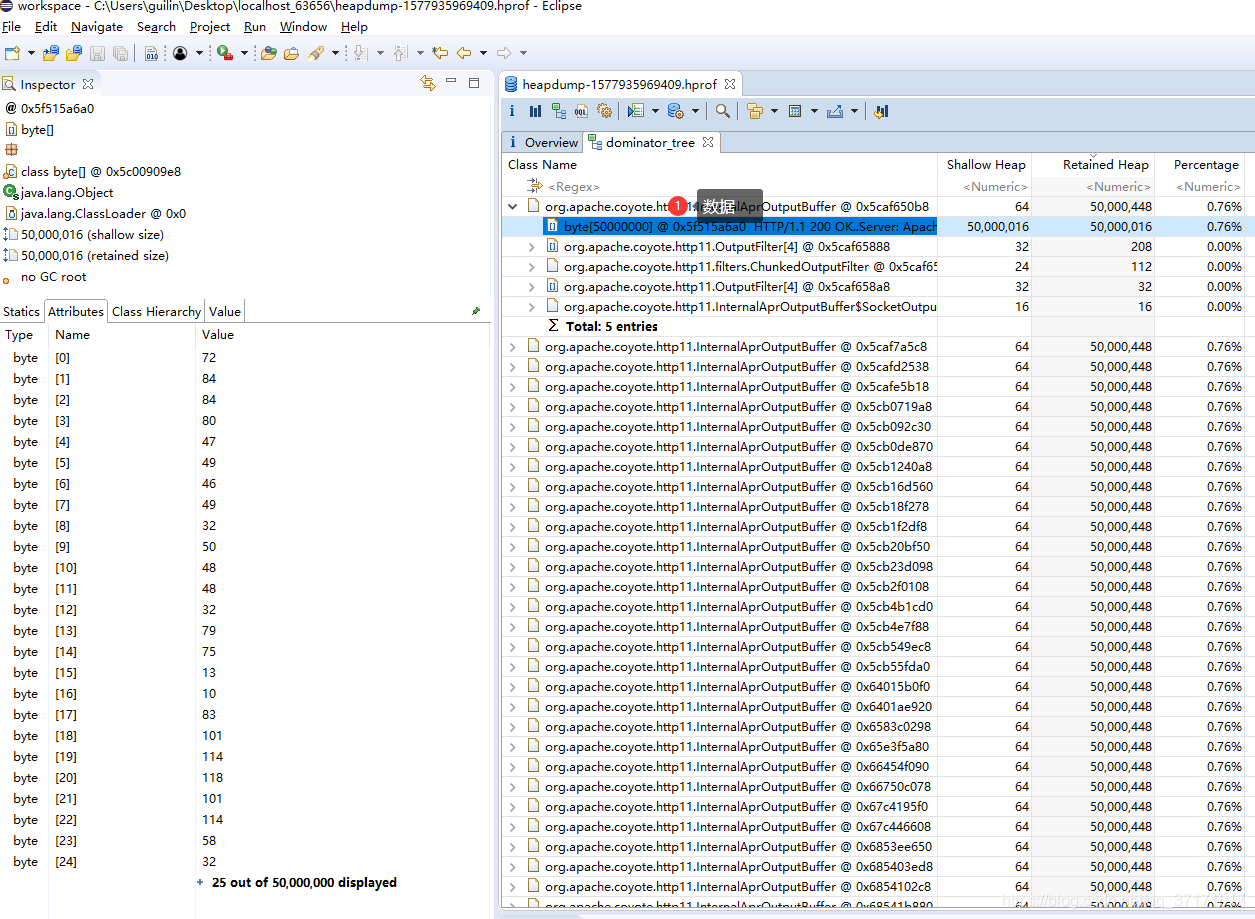
![]()
再看看左边的Attributes值,的确有50000000的长度,那里面到底存放的是那些数据呢?
点击图片右下角的加号,展开数据,发现只有前面的几百条有数据,后面的一直到50000000都是0。意思就是实际byte[]中只有311条为有效值,其余都是以0填充的,且占用了几千万个值,造成了内存的暴涨。
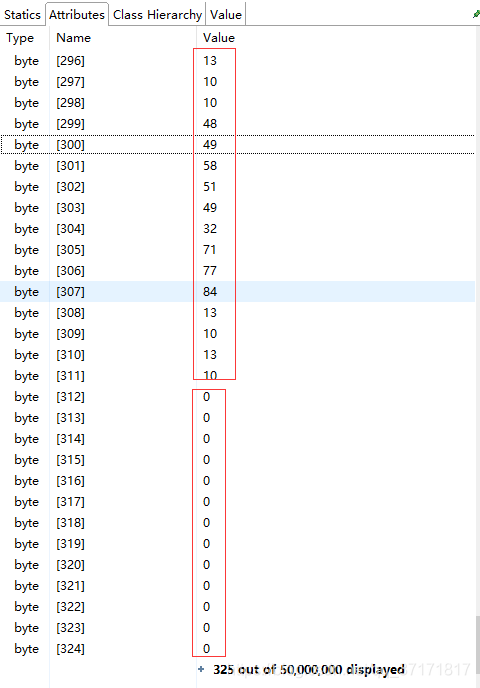
![]()
再结合org.apache.coyote.http11.InternalAprOutputBuffer类是Tomcat的一个类,猜想是不是跟Tomcat的配置有关,于是打开Tomcat的server.xml一探究竟。
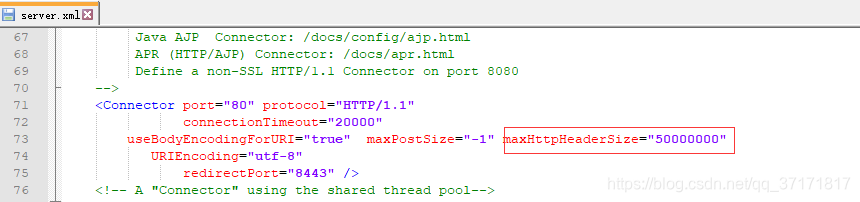
![]()
有没有觉得这50000000很眼熟?就是这个byte[]的长度。
那么为什么要设置这个参数呢?
据同事说,加这个参数是为了解决get请求中url参数过长,超大而报错的问题。
但是,各大浏览器均对url的长度有所限制,而且这个值在Tomcat中默认是4K,这里大约都是50M了,所以为了解决问题,最后把这里改成了8K,就是8192,然后再修改接口,参数过大的查询用Post去请求。
至此,问题解决,服务器运行顺畅,没有再出现卡死的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号