初识百度天工
百度天工服务分为物接入IOT Hub、物解析IOT Parser、物管理IOT Device、时序数据库TSDB、规则引擎Rule Engine还有物可视IOT Visualization,目前物可视在官方公测阶段,需要开发者在物可视界面申请。
一、物接入IOT Hub
1、概述
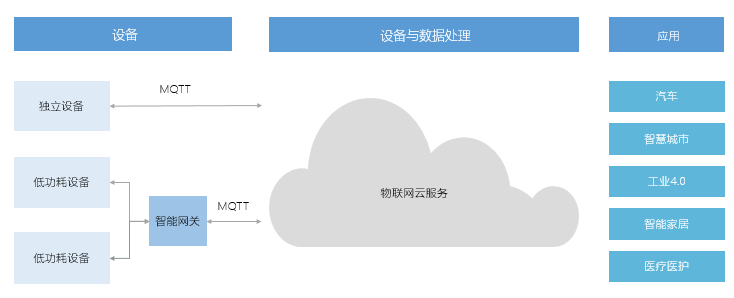
物接入IoT Hub 是全托管的云服务,通过主流的物联网协议(如MQTT)通讯,可以在智能设备与云端之间建立安全的双向连接,快速实现物联网项目。支持亿级并发连接和消息数,建立海量设备与云端安全可靠的双向连接,无缝对接天工平台和百度云的各项产品和服务。
物接入资源分为两类:物接入、物接入(SIM版),本文主要讲解物接入方式,SIM版读者有兴趣可以试试。
MQTT概述
MQTT(Message Queuing Telemetry Transport)是一个客户端服务端架构的发布/订阅模式的消息传输协议。它的设计思想是轻巧、开放、简单、规范,易于实现。这些特点使得它对很多场景来说都是很好的选择,特别是对于受限的环境如机器与机器的通信(M2M)以及物联网环境(IoT)。
支持MQTT底层传输协议的相关设备有:
- 客户端--使用它连接服务端。
- 服务端--全托管的云服务,帮助建立设备与云端之间安全可靠的双向连接,以支撑海量设备的数据收集、监控、故障预测等各种物联网场景。
MQTT客户端
使用MQTT的程序或设备,推荐您使用MQTT.fx。客户端总是通过网络连接到服务端。它可以
- 发布应用消息给其它相关的客户端。
- 订阅以请求接受相关的应用消息
- 取消订阅以移除接受应用消息的请求。
- 从服务端断开连接。
MQTT服务端
全托管的云服务,帮助建立设备与云端之间安全可靠的双向连接,以支撑海量设备的数据收集、监控、故障预测等各种物联网场景。
- 接受来自客户端的网络连接
- 接受客户端发布的应用消息
- 处理客户端的订阅和取消订阅请求。
- 转发应用消息给符合条件的客户端订阅。
更详细的MQTT协议介绍请参考MQTT官网。
名词解释

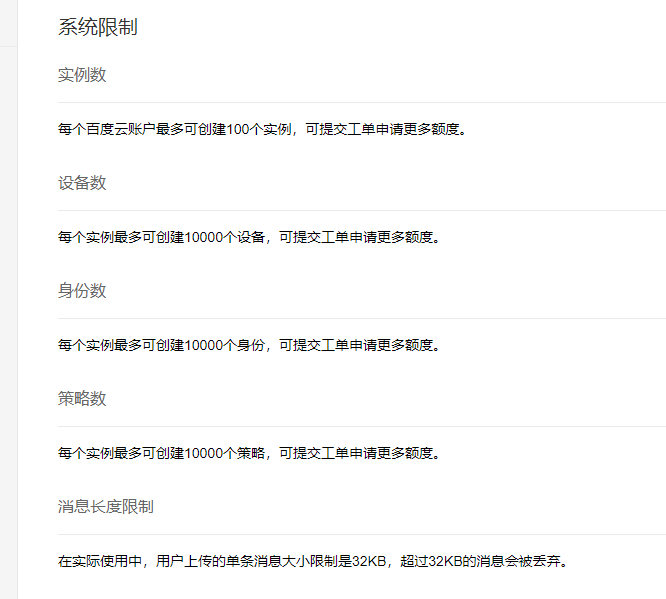
系统限制
2、快速接入IOT Hub
步骤一:注册并登录IoT Hub
在使用IoT Hub服务前,您需要创建一个百度云账号,请按照下述步骤进行注册和登录。
步骤二:创建计费套餐
注意
对于产品公测期间已开通免费物接入服务的用户,系统会自收费开始日起(具体日期以公告为准)创建一个3个月的免费配置(可发布、订阅100万条消息/月)订单,请在3个月内登录控制台升级或续费套餐。
在创建实例之前应先创建计费套餐并设定每个月收发消息的额度,系统将根据额度自动计算每个月的服务费用。每个用户只能创建一个计费套餐,所有实例将共享该套餐的额度。
-
登录百度云官网,点击右上角的“管理控制台”,快速进入控制台界面。
-
选择“产品服务>物接入IoT Hub”,进入服务页面。
-
点击“实例列表”,选择一种计费方式,物接入或者物接入(SIM)版,关于产品的定价和费用计算方法,请参看产品定价。
完成配置后,点击“下一步”进入在线支付页面进行支付。支付成功后,用户可进入“实例列表”,创建物接入实例。
步骤三:创建实例
连接IoT Hub服务需要创建一个实例(endpoint),一个endpoint表示一个完整的IoT Hub服务。登录IoT Hub控制台页面,点击“创建实例”,填写需要创建IoT Hub服务的实例名称。
说明:
- 目前每个账户能创建100个endpoint,且每个实例的名称是全局唯一的,不能重名。每个endpoint下可创建10000个thing、10000个policy和10000个principal。如果需要更多配额,请提交工单申请。
创建实例时,IoT Hub默认提供三种地址,选择不同的地址,意味着您可以通过不同的方式连接到百度云IoT Hub。
-
tcp://yourendpoint.mqtt.iot.gz.baiduce.com:1883,端口1883,不支持传输数据加密,可以通过MQTT.fx客户端连接。
-
ssl://yourendpoint.mqtt.iot.gz.baiduce.com:1884,端口1884,支持SSL/TLS加密传输,MQTT.fx客户端连接,参考配置MQTT客户端。
-
wss://yourendpoint.mqtt.iot.gz.baidubce.com:8884,端口8884,支持Websockets浏览器方式连接,同样包含ssl加密,参考Websockets Client。
步骤四:配置实例
成功创建IoT Hub实例后,点击实例名称,进入配置IoT Hub实例页面,创建设备、身份和策略。具体操作步骤如下:
1、创建设备:选择设备列表,点击“创建设备”,输入需要连接IoT Hub服务的设备名称。为了便于灵活连接IoT Hub服务,每一台设备thing都需要绑定相应的身份principal。
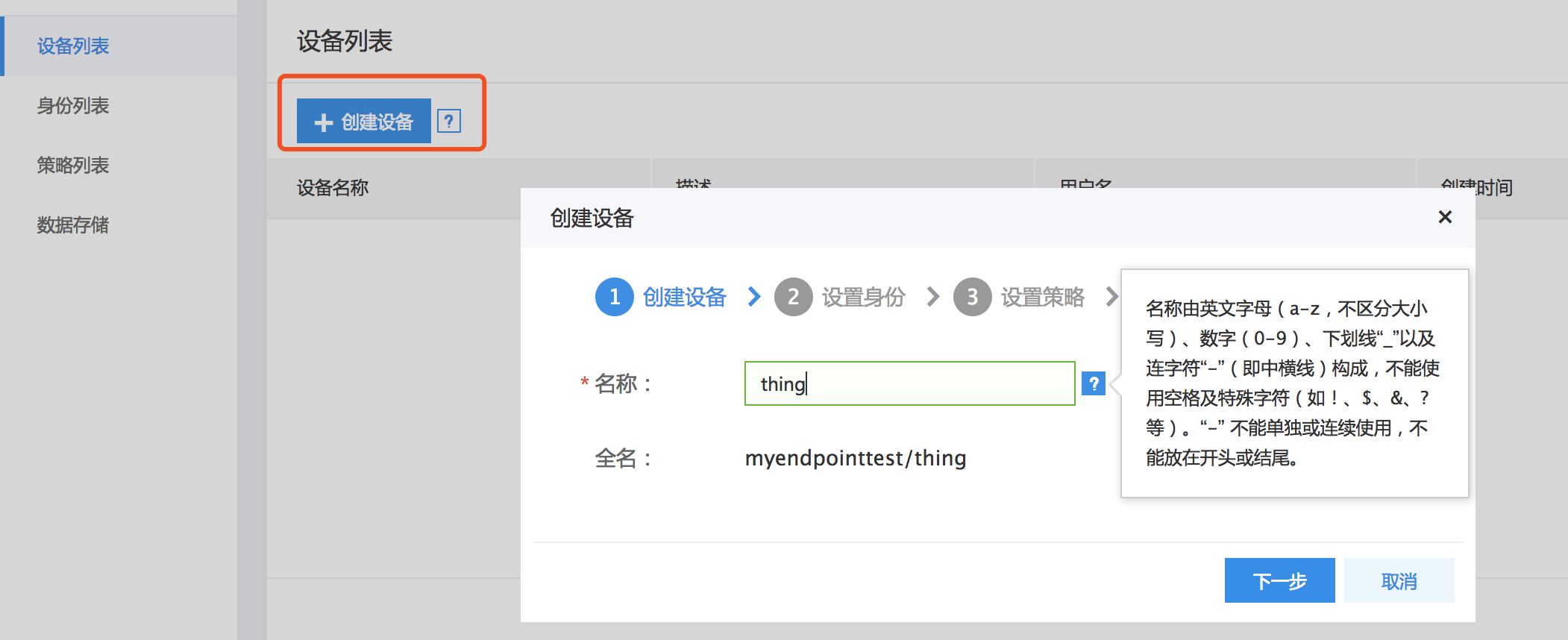
2、创建身份:在身份输入框内点击“创建”,快速创建身份principal。输入principal名称,以及为每个身份授权的策略policy。
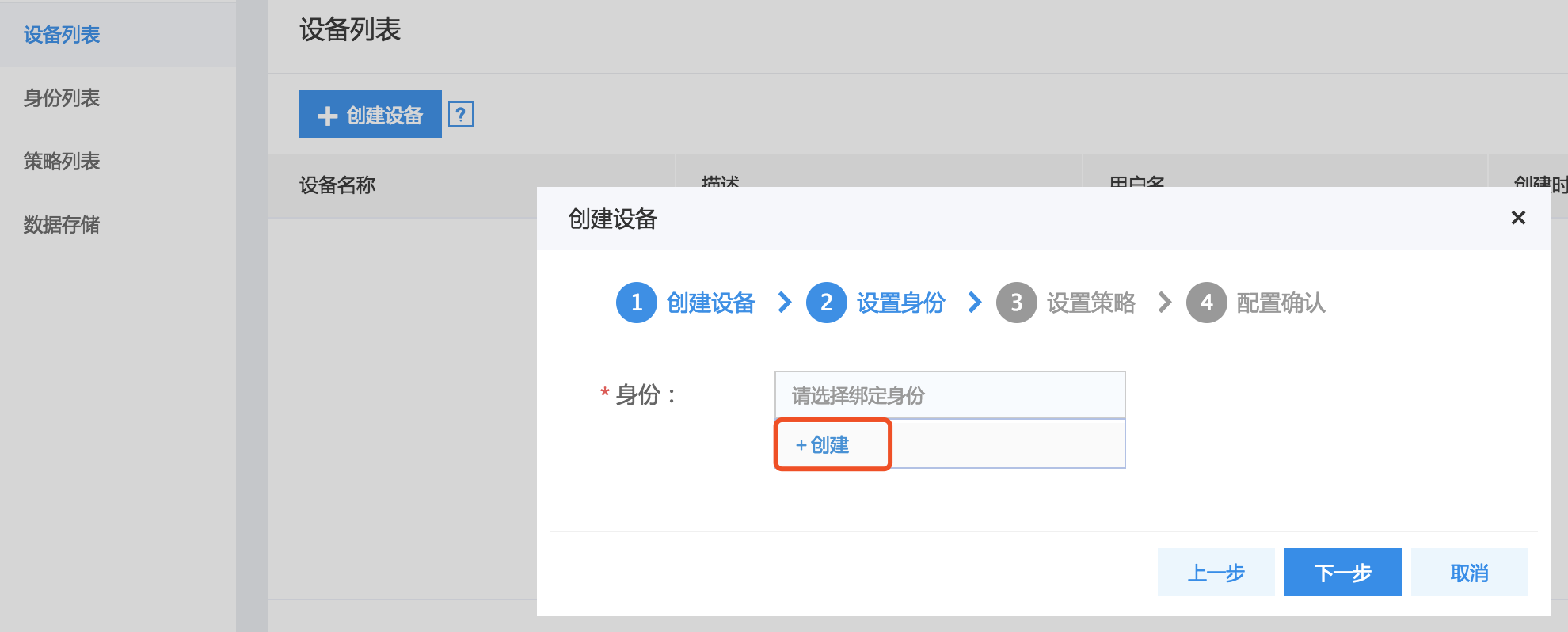
3、创建策略:在策略输入框内点击“创建”,快速创建策略policy。输入policy名称,主题topic,选择该身份拥有的权限:发布消息(publish)、订阅消息(subscribe)。
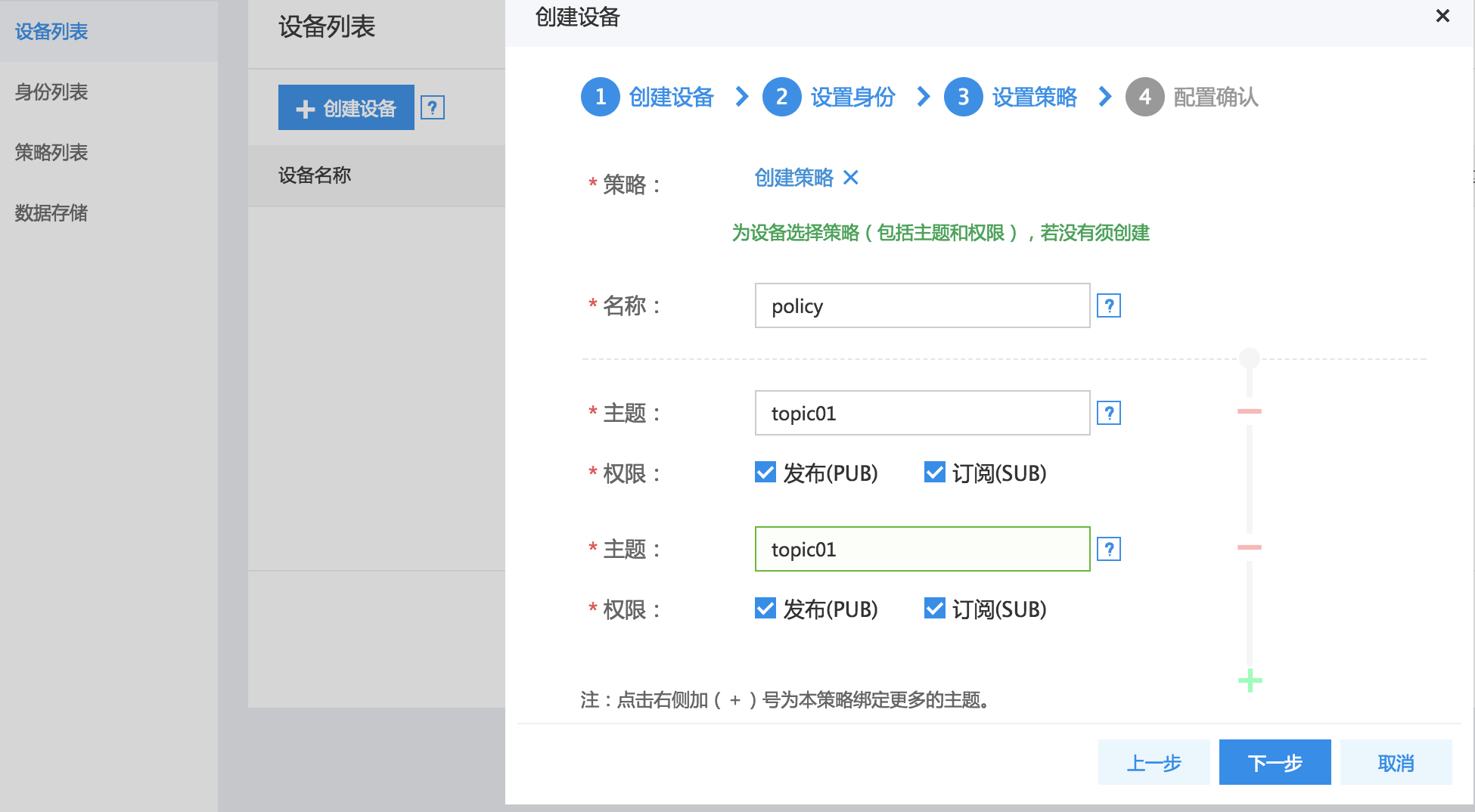
说明:
每个policy可以创建多个主题topic,在创建策略弹框右侧,点击“+”可以绑定更多的主题。
4、成功创建身份principal后,返回密码,在配置客户端时会用到,需要复制保存,如下图所示:
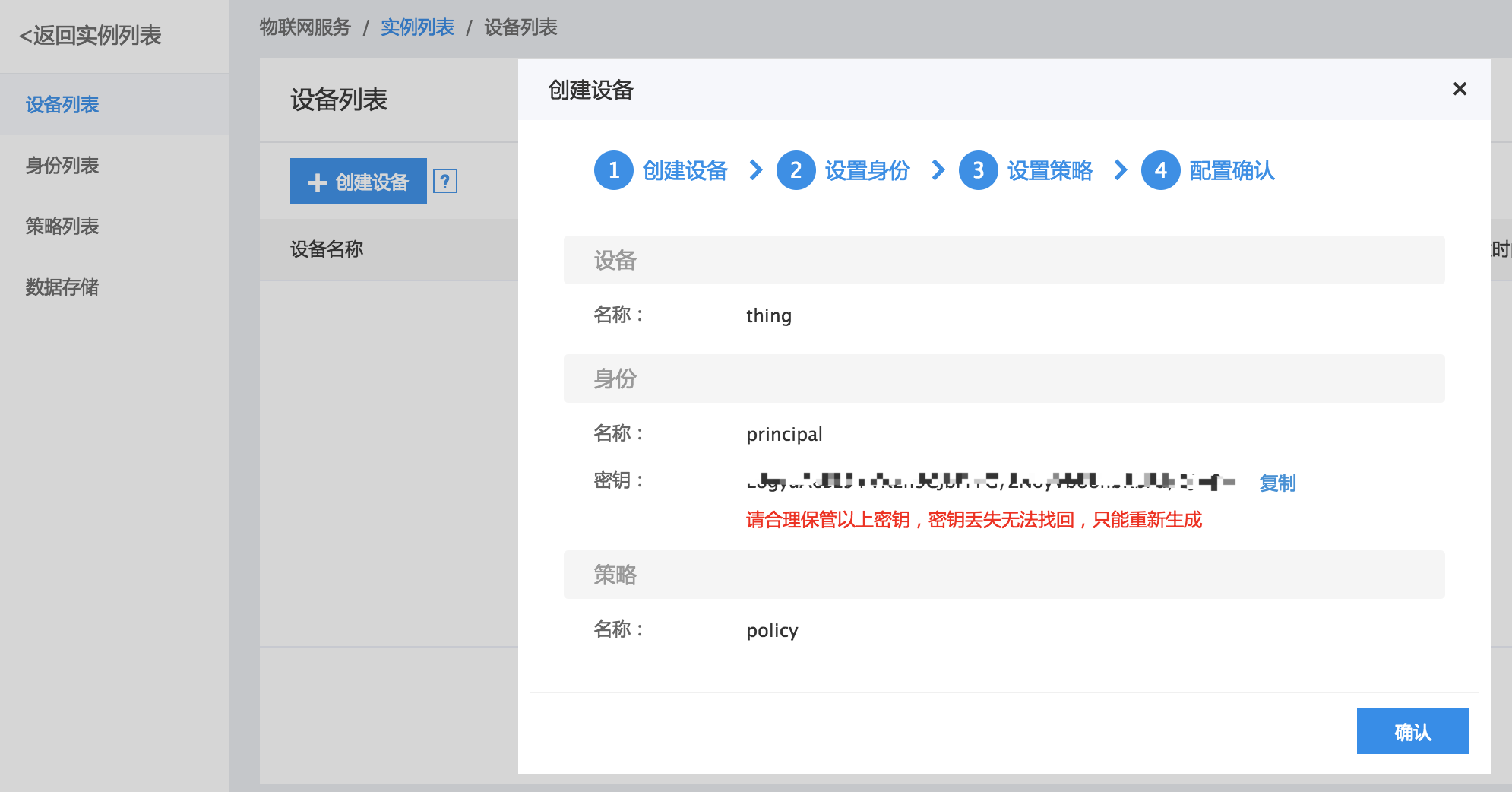
5、至此,成功配置了 IoT Hub 实例中的相关参数。
步骤五:配置MQTT客户端
配置MQTT的应用客户端,可以快速验证是否可以实现与物接入服务交流发送或者接收消息。
前提条件:登录MQTT.fx官网,找到适合的版本下载并安装MQTT.fx客户端。
操作步骤
1、打开MQTT客户端的设置页面,点击“+”按键,创建一个新的配置文件。
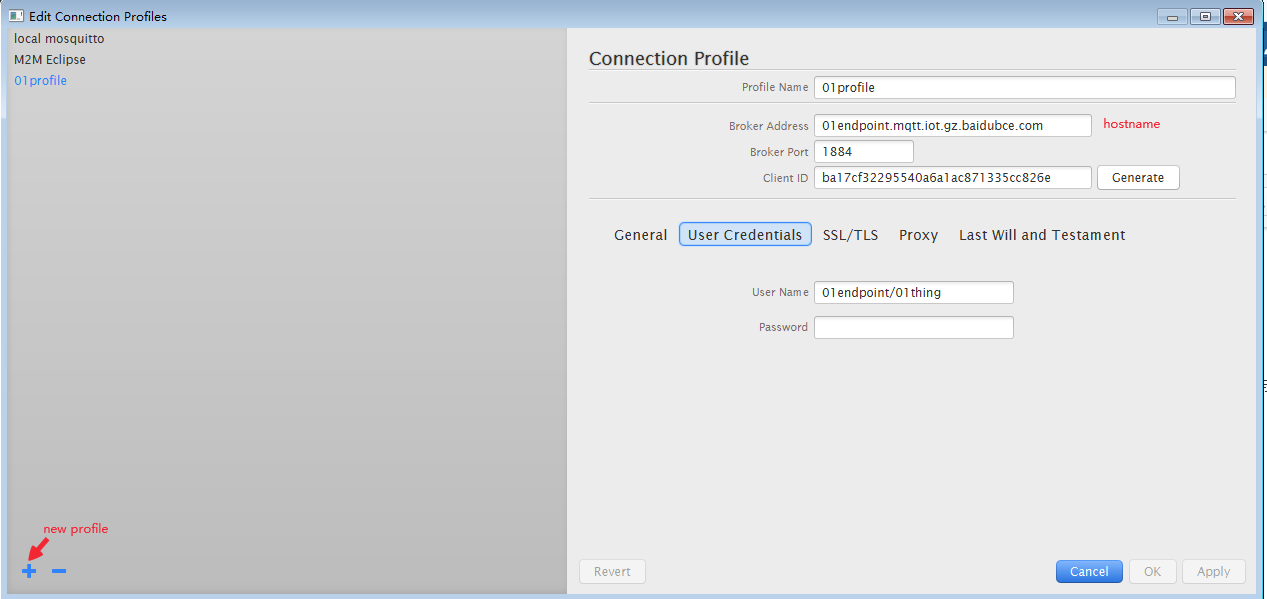
a、填写Connection profile相关信息:
| 参数名称 | 说明 |
|---|---|
| profile name | 配置文件名称 |
| Broker Address | 创建endpoint后返回的hostname |
| Broker Port | 1884 |
| Client ID | 客户端ID,支持“a-z”,“0-9”,“_”,“-”字符, 且不能大于128bytes,UTF8编码 |
b、选择User Credential,输入创建 IoT Hub 服务返回的username/password,参考配置实例。
c、配置SSL/TLS安全认证,勾选 Enable SSL/TLS,选择CA signed server certificate认证。
d、点击“Apply”按键,完成客户端配置。
2、返回MQTT客户端界面,选择新创建的配置文件,点击“connect”按键连接服务。
3、成功连接后,即可开始订阅消息。
打开Subscribe标签,填写主题topic,创建设备时自己定义的主题,选择默认的QoS 0,点击“Subscribe”进行订阅操作。
4、发布消息。
打开Publish标签,填写主题topic,创建设备时自己定义的主题,选择默认的QoS 0,点击“Publish”进行发布操作。
5、返回Subscribe界面,即可看到已接收的订阅消息。
二、规则引擎 Rule Engine
1、概述
规则引擎并不是一个全新的概念,在传统软件业中已经有相关的产品。在传统商业管理软件中,由于市场要求业务规则变化频繁,IT系统必须依据业务规则的变化而快速、低成本的更新。为了达到该目的,要求业务人员能够直接管理IT系统中的规则而不需要开发人员的参与,这就是规则引擎曾经在传统软件中的功能。
类似地,在物联网中,由于数据量巨大,业务规则可能多种多样,也需要将规则的设置变得简单和友好以适应业务规则的多样和变化。大量的数据往往对应着不同的应用分析场景,如监控厂区的温度湿度监控点,每十分钟都会有温度和湿度数据传往云端;对于这些数据,我们往往希望它们发挥不同的作用,例如以下应用场景:
-
实时告警异常的数据;
-
两个小时内的温度最大最小和均值等;
-
将全部的数据做冷备份以便查询;
-
对去除异常数据之后的正常数据做数据分析和预测。
规则引擎就是通过灵活的设定规则,将设备传上云端的数据,送往不同的数据目的地(如时序数据库TSDB、Kafka、对象存储BOS等)以达到不同的业务目标。
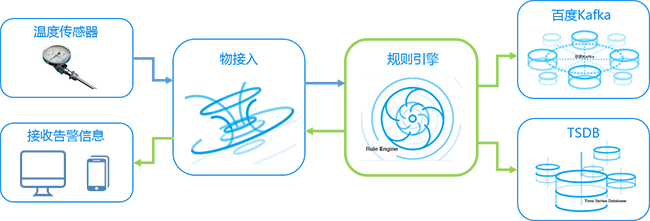
优势:
-
多种服务支持
支持将消息转发到时序数据库、Kafka、对象存储,无缝对接MapReduce、机器学习、云推送等各种服务。
-
灵活易用
规则设置灵活简单,一键启停规则,支持各种事件和动作。
-
多场景支持
支持设备与云端之间的转发,设备与设备之间的转发,设备与第三方服务的转发。
-
强大的API
提供开放标准的API,可通过调用API实现控制台操作,方便第三方应用快速集成云端服务。
例:城市路灯管理属于一个典型的物联网场景,该场景可以复制到很多其它的领域。
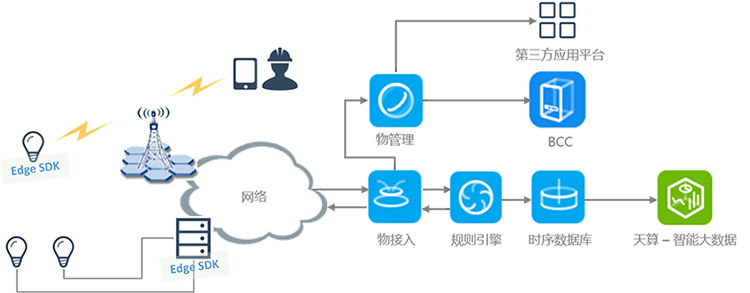
传统情况下,路灯管理基本上靠人力,例如:巡查、维护,甚至是靠人工控制路灯开关;而城市路灯数量巨大,分布复杂,对于管理部门来说可能已经投入了大量的人力成本,但仍然会出现故障发现和抢修不及时的情况。同时在传统情况下,由于缺少路灯的运行环境(例如:电压、温度),使用寿命等数据,很难有针对性改进使用方法,进而延长使用寿命,也很难指定准确的维护策略和备件策略。
路灯接入可以采用多种方式,例如:3G/4G,电力载波,LPWAN等,无论采用哪种方式,用户只需在接入设备中预装Edge SDK,都能轻松打通路灯和百度云之间的双向安全通道,实现将路灯接入百度云的物接入服务。路灯可以实时将设备状态、电压电流、环境温度、地理坐标等信息发送至物接入服务。同时在工程师的智能终端上预装APP对接百度云,可实时上报工程师的地理位置坐标。
物接入接收到路灯上送的消息后,可将消息分别转发至物管理和规则引擎服务。用户可在规则引擎上制定策略,实现以下操作:
-
当路灯下线或电压电流超过阈值时,检索距离现场最近的维护工程师,并自动发送告警、路灯坐标等信息给指定的维护工程师。工程师的智能终端可对接百度地图服务,自动在地图上显示待维修路灯的位置。
-
将电压电流、环境温度等信息转发至时序数据库,并对接天算大数据平台,用于后续的数据挖掘。
2、快速创建规则引擎
操作流程介绍:

2.1、创建数据源:规则引擎需要通过物接入获取设备端发往云端的消息,因此在配置规则引擎之前,需先配置物接入IoT Hub打通云端和设备端之间的双向通道。物接入主要用于在智能设备与云端之间建立安全的双向连接,实现从设备到云端以及从云端到设备的消息传输。
2.2、创建目的地:规则引擎可根据预先设置的规则将消息转发至百度云的其它服务,例如时序数据库、百度Kafka或物接入主题。在配置规则引擎前,建议您先创建好需要用到的其它服务。
百度Kafka是基于Apache Kafka的分布式、高可扩展、高通量、多分区和多副本的消息托管服务。百度Kafka封装了Kafka集群细节,并以托管服务形式提供,您可以直接使用百度Kafka创建主题来集成大规模分布式应用,而无需考虑集群运维,仅按照使用量支付处理数据的费用。
TSDB是用于管理时间序列数据的专业化数据库。区别于传统的关系型数据库,TSDB针对时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别适用于物联网应用场景。
物接入主题
物接入主题是物接入服务与前端设备进行消息传播的媒介。规则引擎支持将在一个主题中收到的信息,转发至另一个主题中。如将主题temperature订阅到的消息,筛选出大于阈值的消息,转发至主题alarm中,再用其他客户端订阅alarm客户端主题即可。
创建规则:设置筛选规则、消息来源主题、触发条件和数据目的地。
验证规则:构建Json格式的Payload,对已经创建的规则的筛选结果进行验证。
步骤一:创建规则
规则引擎需要通过物接入获取设备端发往云端的消息,因此在配置规则引擎之前,需先配置物接入打通云端和设备端之间的双向通道。有关物接入的配置操作,请参看物接入IoT Hub。
规则引擎从物接入获取到的消息的payload应当是Json格式的,因此在创建规则时,需要使用Json表达式引用。在执行以下操作之前,用户应对Json表达式引用方法有所了解。有关Json表达式的介绍请参看附录-Json表达式
1、登录百度云官网,点击右上角的“管理控制台”,快速进入控制台界面。
2、选择“产品服务>规则引擎>规则列表”,进入“规则列表”页面。
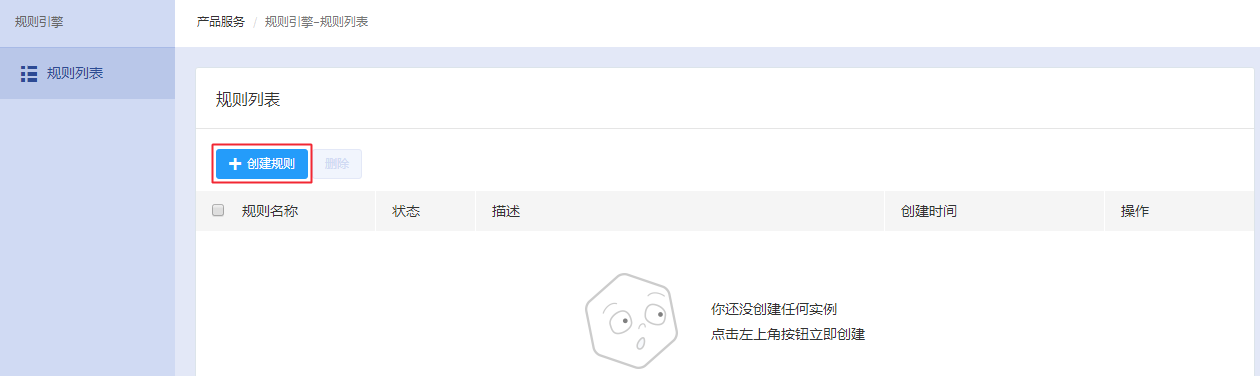
3、点击“新建规则”,进入规则创建页面,填写以下配置信息:
查询字段:从消息中筛选出来用于后续操作(如:转发至TSDB或百度Kafka)的数据。如果填写“*”,则将原样转发payload中的所有数据至目的地。
如果将消息转发至TSDB,需要预先对消息格式进行调整,具体操作请查看将消息转发至TSDB。
主题:消息来源的物接入主题。
约束条件:后续操作的触发条件。缺省情况下,转发每一条消息至目的地。
其中,查询字段和约束条件中支持的操作符如下:
| 运算符 | 语义 | 示例 |
|---|---|---|
| JSON扩展表达式 | JSON的属性访问 | info.contact.tel,关于Json表达式的更多内容,请参看附录 |
| = | 相等比较 | age = 9 |
| <> | 不等 | name <> 'abc' |
| AND | 逻辑与 | age = 9 AND name <> 'abc' |
| OR | 逻辑或 | age = 9 OR name <> 'abc' |
| () | 括号 | age =9 AND (name <> 'abc' OR score > 60.0) |
| +,-,*,/ | 数值的加减乘除 | 2+3, age - 1, score * 100.0, age / 3 |
| <, <=, >, >= | 比较操作符 | age < 10, age <= 9, score > 60.0, score >= 60.0 |
| in | 集合操作 | WHERE name in ('jack', 'jim') |
| SQL函数 | 标准的SQL函数 | 如:ceil, floor等,常见SQL函数,请参看附录 |
| CURRENT_TIMESTAMP | 返回当前时间戳(毫秒),即UTC时间 | SELECT CURRENT_TIMESTAMP AS TS |
| LOCALTIMESTAMP() | 返回本地时间戳(毫秒),即UTC+8 | SELECT LOCALTIMESTAMP AS localTS |
| NEWID() | 返回一个guid(global unique identifier,全球唯一标识),规则引擎会为每一条消息新增一个guid | SELECT NEWID() AS id from t |
| clientid() | 返回消息的发送者id | SELECT clientid() FROM... |
| clientip() | 返回消息发送者的IP | SELECT clientip() FROM... |
| topic() | 返回消息所在的主题 | SELECT topic() FROM... |
| qos() | 返回消息发送所用的QoS | SELECT qos() FROM... |
4、点击“添加数据目的地”,新增一个数据目的地,此处可添加多个。
规则引擎支持将数据转发至“时序数据库TSDB”、“百度Kafka”或“其它物接入主题”。
将数据转发至“其它物接入主题”是,仅支持将数据转发至同一个endpoint(即消息来源的物接入主题所在的endpoint)下的其它主题,不支持转发至其它endpoint。
如果将数据转发至TSDB,需要对数据格式进行调整,具体操作请参看将消息转发至TSDB。
返回“规则列表”页面,查看已经创建的规则。

步骤二:验证规则
用户可以自己构建Json格式的Payload,对已经创建的规则的筛选结果进行验证。在执行以下操作前,用户应先创建规则。
1、选择“产品服务>规则引擎>规则列表”,进入“规则列表”页面,查看已经创建的规则。
2、找到指定的规则,点击规则名称,进入规则详情页面;点击“规则验证”,验证已经创建的规则。
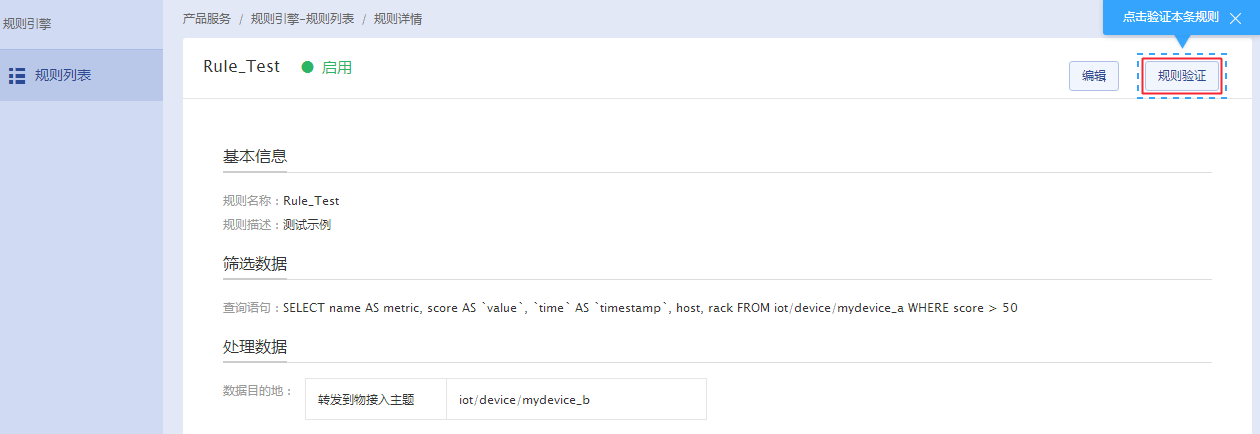
3、在“输入数据”中构建Json格式的原始数据,选择数据目的地并点击“验证”,此时系统将根据已经创建的规则自动输出筛选后的数据。
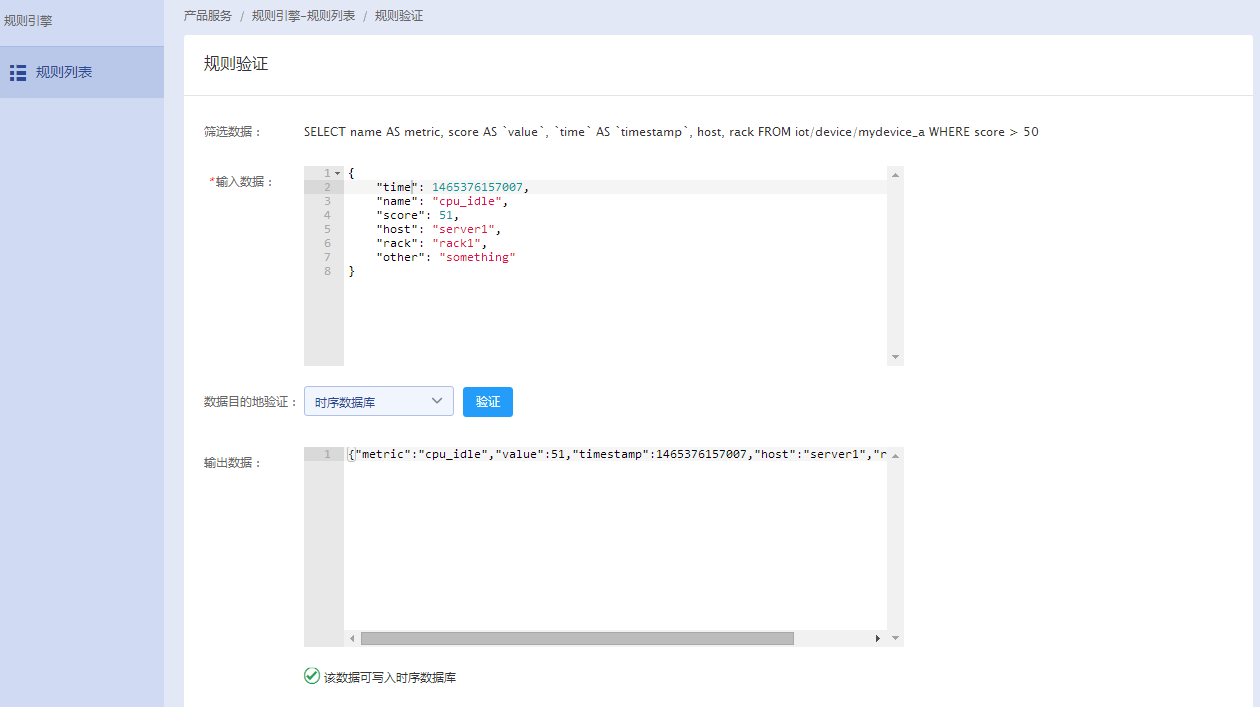
步骤三:将消息转发至数据目的地
1、存入TSDB数据库
通过简单规则调整数据格式:以下方法仅针对value存放在消息中,如果value存放在数组中,请看下面的通过"_TSDB_META"调整数据格式。
TSDB数据库要求数据必须包含metric、value和timestamp三个字段,以及额外一个或多个数据作为tag。如果原始消息中不包含这些字段,在将数据转发至TSDB前,需要对数据格式进行调整,如下所示:
原始数据:
{
"time": 1465376157007,
"name": "cpu_idle",
"score": 51,
"host": "server1",
"rack": "rack1",
"other": "something"
}
原始数据中的"score": 51为整型,数据没有放在引号""中。如果原始数据为"score": "51",此时该数据为字符串类型。字符串类型数据写入TSDB后将无法在查看面板中生成图表。
规则引擎设置
查询字段:name AS metric, score AS _value, `time` AS _timestamp, host, rack
由于time为SQL的关键字,使用时需要加反单引号(重音符)。
主题:消息来源的物接入主题。
约束条件:score > 50
输出数据:
{
"metric":"cpu_idle",
"_value":51,
"_timestamp":1465376157007,
"host":"server1",
"rack":"rack1"
}
通过"_TSDB_META"调整数据格式:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2、转发到MQTT主题
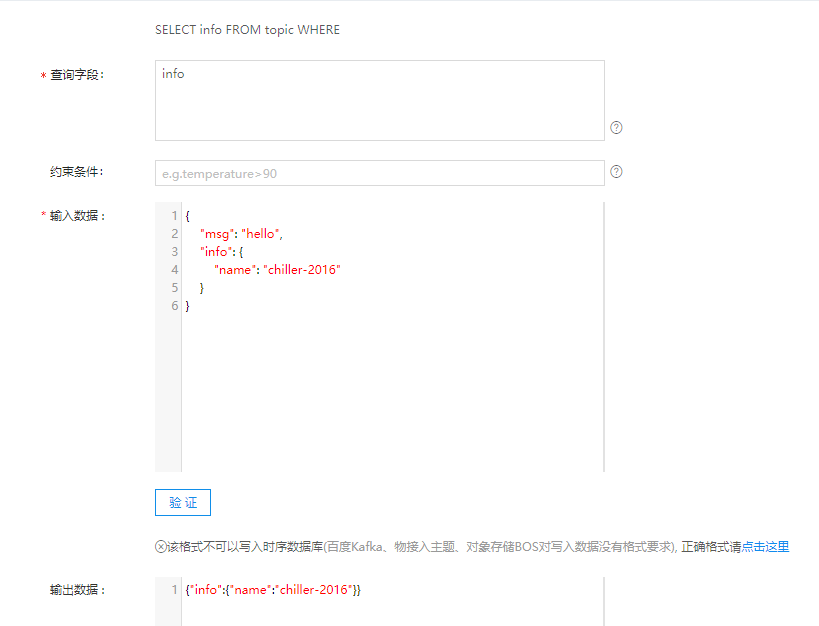
规则引擎可以从接收到的消息中自动提取MQTT主题,并将消息转发至该主题,具体操作如下所示:
原始数据:
{
"msg": "hello",
"info": {
"name": "chiller-2016"
}
}
下图是规则调试的结果
以下是规则编辑界面,查询字段和查询主题是必填项,查询主题代表需要处理的是哪个主题的消息,也可以写通配符“#”,代表所有主题消息
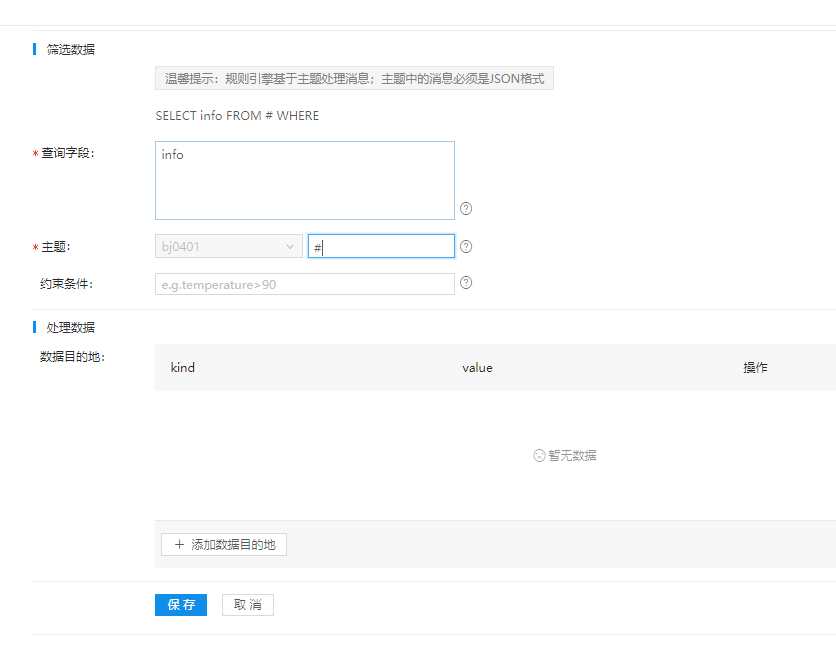
添加数据目的地:


以上是两个数据库和一个转发的主题,共3个数据目的地。
规则引擎还有很多东西,我以后实验过了再补上!!!!!!
三、时序数据库TSDB
1、概述
在物联网时代,企业需要处理各种设备产生的带有时间标签的数据,即时间序列数据。时间序列数据主要由各类型实时监测、检查与分析设备所采集或产生,涉及电力行业、化工等行业。这些工业数据的典型特点是:产生频率快、严重依赖于采集时间、测点多信息量大等。普通关系型数据库无法高效地处理此类数据。
为了更好的处理时间序列数据,时序数据库(Time Series Database,下简称TSDB)应运而生。TSDB是用于管理时间序列数据的专业化数据库。区别于传统的关系型数据库,TSDB针对时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别适用于物联网应用场景。
产品功能:
-
数据写入
支持通过REST API方式高并发写入时间序列数据,可线性扩展。
-
极速查询
支持海量时序数据的极速查询,每秒可返回1亿数据点的聚合查询结果。
-
丰富的函数
提供丰富的数据处理能力,支持多达16种聚合函数。
-
Web图表
查询的结果可以通过Web图表方式生动、灵活的展现。
名词解释:
TSDB :Time Series Database,时序数据库,用于保存时间序列(按时间顺序变化)的海量数据。
度量(metric):数据指标的类别,如发动机的温度、发动机转速、模拟量等。
域(field):在指定度量下数据的子类别。即一个metric支持多个field,如metric为wind,该metric可以有两个field:direction和speed。
时间戳(timestamp):数据产生的时间点。
数值(value):度量(metric)对应的数值,如56°C、1000r/s等(实际中不带单位)。如果有多个field,每个field都有相应的value。不同的field支 持不同的数据类型写入。对于同一个field,如果写入了某个数据类型的value之后,相同的field不允许写入其他数据类型。
标签(tag):一个标签是一个key-value对,用于提供额外的信息,如"设备号=95D8-7913"、“型号=ABC123”、“出厂编号=1234567890”等。
数据点(data point):“1个metric + 1个field(可选) + 1个timestamp + n个tag(n>=1)”唯一定义了一个数据点。当写入的metric、field、timestamp、n个tag都相同时,后写入的value会覆盖先写入的value。
时间序列 :“1个metric +1个field + n个tag(n>=1)”定义了一个时间序列。如 metric为wind,field为speed,tag为“型号=ABC123”、“出厂编号=1234567890"的数据点都属于同一个时间序列。
-
tag的key值和value值都相同才算过同一个tag,即deviceid=1和deviceid=2是两个标签。
-
请不要将时间戳作为tag,否则会导致时间序列超过限制,关于时间序列的限制请参考费率表。
分组(group):可以按标签(tag)对数据点进行分组。
聚合函数(aggregator):可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等。
数据库(database):一个用户可以有多个数据库,一个数据库可以写入多个“度量”的“数据点”。
栗子:
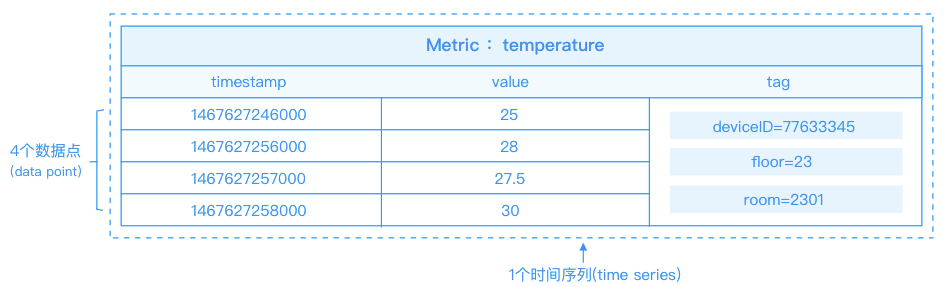
单域:
监测温度的值,把温度(temperature)作为一个度量(metric),用标签(tag)来标识每一个数据的额外信息,比如每个数据点都有3个tag,tag是一个key-value对,tag的key分别是deivceID、floor、room。
如图所示,表示对温度的时间序列监测值,共4个数据点。在该图中的4个数据点使用的metric、tag是相同的,所以是同一个时间序列。
多域:
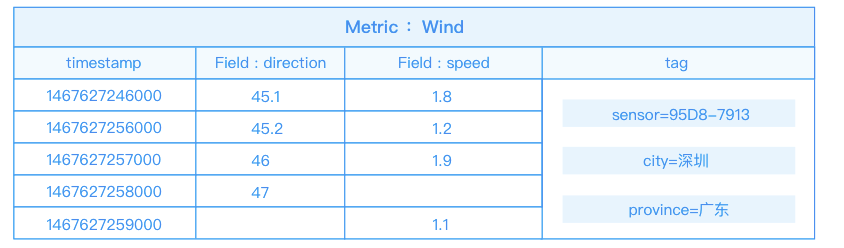
监测风力的值,把风力(wind)作为一个度量(metric),风力(wind)分为两个域:风向(direction)和速度(speed)。这些监测数据是从不同的传感器传输到云端的,用标签(tag)来标识每一个数据的额外信息,比如每个数据点有三个tag,tag是一个key-value对;tag的key分别是sensor、city、province。
为了表示在广东省深圳市传感器编号95D8-7913上传风向(direction)数据,可以将这个数据点的tag为标记为sensor=95D8-7913、city=深圳、province=广东。
如图,展示了metric为wind的两个域(speed和direction)的监测数据。当使用的是metric、field和tag是相同的时,是同一个时间序列。即图中有2个时间序列,8个数据点。

将数据采用metric+field的方式存储的优势在于,可以在同一个时间序列下联合查询。以上图为例,要查询1467627246000-1467627249000时间内风力(wind)的情况,可以联合查询多个field的值,得到下图的数据。
如果写入时没有数据,在查询时,可以采用插值方案将值补充完整,插值的使用说明见数据库操作相关文档。????????


2、快速使用TSDB

步骤一:创建数据库
1、登录百度云,点击右上角的“管理控制台”,快速进入控制台界面。
2、选择“产品服务>时序数据库TSDB”,进入“数据库列表”页面。
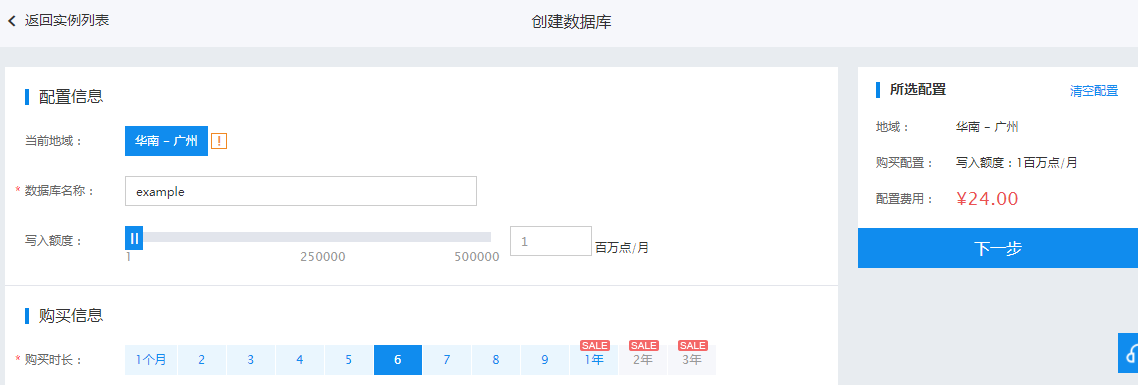
3、点击“创建数据库”,进入创建数据库页面,填写配置信息,包括:
- 数据库名称:设置数据库名称,由小写字母和数字组成,6~40个字符。
- 写入额度:目前支持1~500000百万点/月。
- 购买时长:TSDB为预付费产品,最少每次购买1个月。
4、完成配置后点击“确认订单”,完成TSDB数据库的创建

 浙公网安备 33010602011771号
浙公网安备 33010602011771号