

Tesseract Ocr文字识别
一、安装python模块
pip install pytesserac
二、安装tesseract orc 下载地址:https://github.com/UB-Mannheim/tesseract/wiki 点击“tesseract-ocr-w64-setup-v4.1.0-beta.1.2019xxxx.exe”下载安装。
三、将安装的软件填入环境中
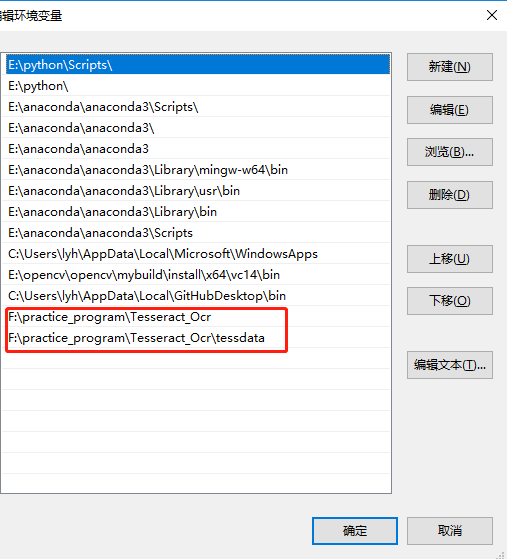
四、在python配置环境中E:\anaconda\anaconda3\envs\tensorflow\Lib\site-packages\pytesseract找到pytesseract.py 文件
tesseract_cmd = 'tesseract'
修改为
r'F:\practice_program\Tesseract_Ocr\tesseract.exe'或者('F:/practice_program/Tesseract_Ocr/tesseract.exe')
五、代码
from PIL import Image import pytesseract path = "img\\20190403110159.png" text = pytesseract.image_to_string(Image.open(path), lang='chi_sim') print(text)
若报错没有语言包chi_sim
六、下载语言包
语言包的下载:https://github.com/tesseract-ocr/tessdata
将下载的语言包放入
F:\practice_program\Tesseract_Ocr\tessdata中
