
个人项目:论文查重
| 这个作业属于哪个课程 | 软件工程计科国际班 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 1、学会制作PSP表格 2、熟悉Markdown的使用 3、锻炼个人编程能力 4、学会使用单元测试和性能测试 |
Github链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 1060 | 1380 |
| · Analysis | ·需求分析 (包括学习新技术) | 150 | 180 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 150 | 240 |
| · Coding | · 具体编码 | 600 | 720 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 70 | 120 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| · 合计 | 1160 | 1520 |
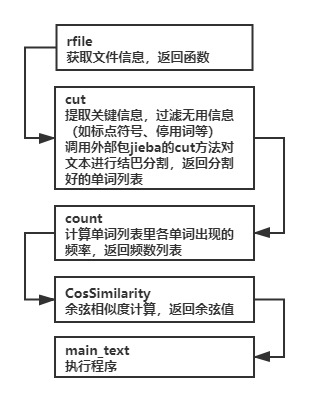
计算模块接口的设计与实现过程
该模块一共有五个函数,其关系如下流程图所示:
关键算法
- 1、jieba.lcut
采用结巴分割的算法,将文本进行分割成一个个词语
算法介绍:
结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
分词模式:
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 2、re.compile
这里采用re包里的compile方法,使用正则表达式,去除标点符号,仅对中英文文本和数字进行分割,其中中文按词语分割,英文按单词分割,数字按空格分割。
- 3、单词列表中单词出现的频数
- 4、余弦相似度计算
介绍:余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
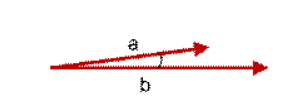
上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:
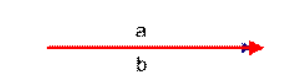
如上图二:可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向。如下图
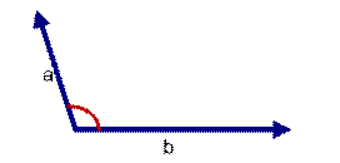
如上图三: 两个向量a,b的夹角很大可以说a向量和b向量有很低的的相似性,或者说a和b向量代表的文本基本不相似。那么是否可以用两个向量的夹角大小的函数值来计算个体的相似度呢?
向量空间余弦相似度理论就是基于上述来计算个体相似度的一种方法。下面做详细的推理过程分析。

想到余弦公式,最基本计算方法就是初中的最简单的计算公式,计算夹角的余弦定值公式为:

但是这个是只适用于直角三角形的,而在非直角三角形中,余弦定理的公式是
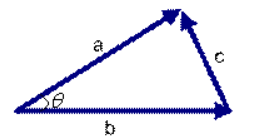
三角形中边a和b的夹角 的余弦计算公式为:
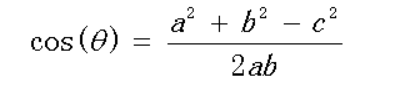
在向量表示的三角形中,假设a向量是(x1, y1),b向量是(x2, y2),那么可以将余弦定理改写成下面的形式:
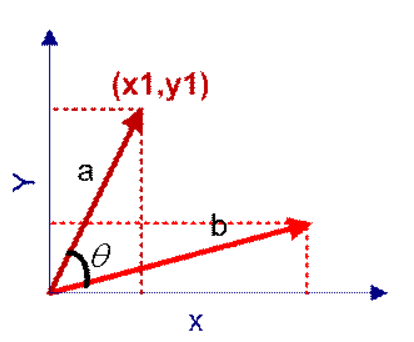
向量a和向量b的夹角 的余弦计算如下
如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。

余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,夹角等于0,即两个向量相等,这就叫"余弦相似性"。
性能分析
改进前模块占用时间及性能分析图
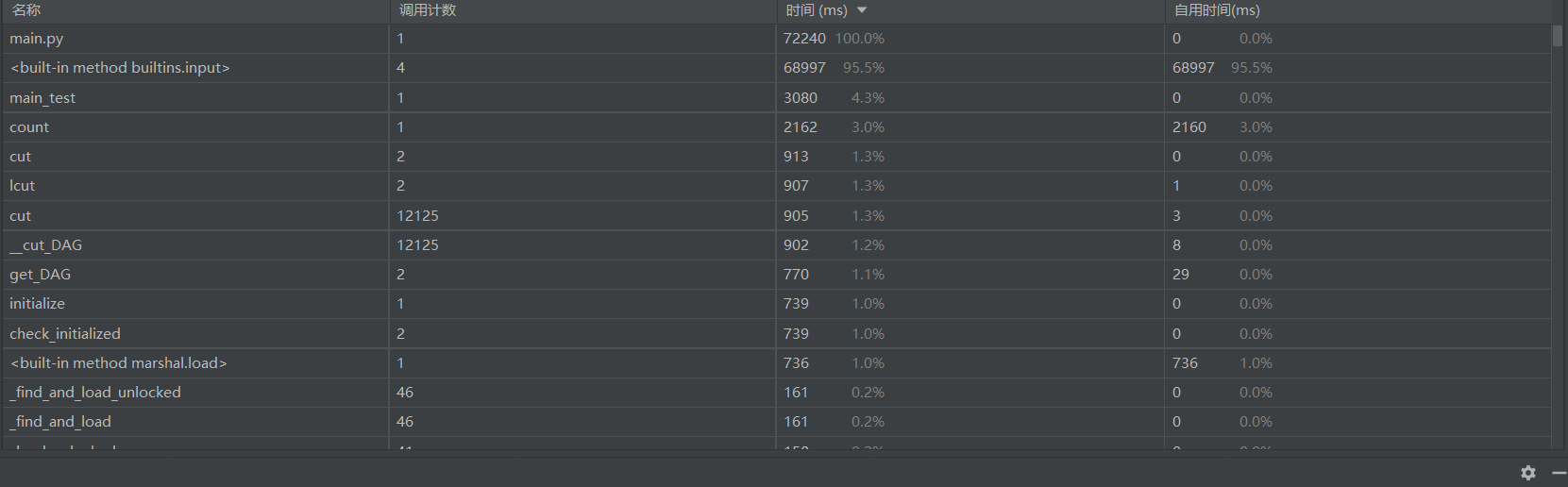
由上图可以看出耗时较多的函数是count函数,说明大部分时间花费在了分词上,因此我对count函数进行了改进。
改进后模块占用时间及性能分析图
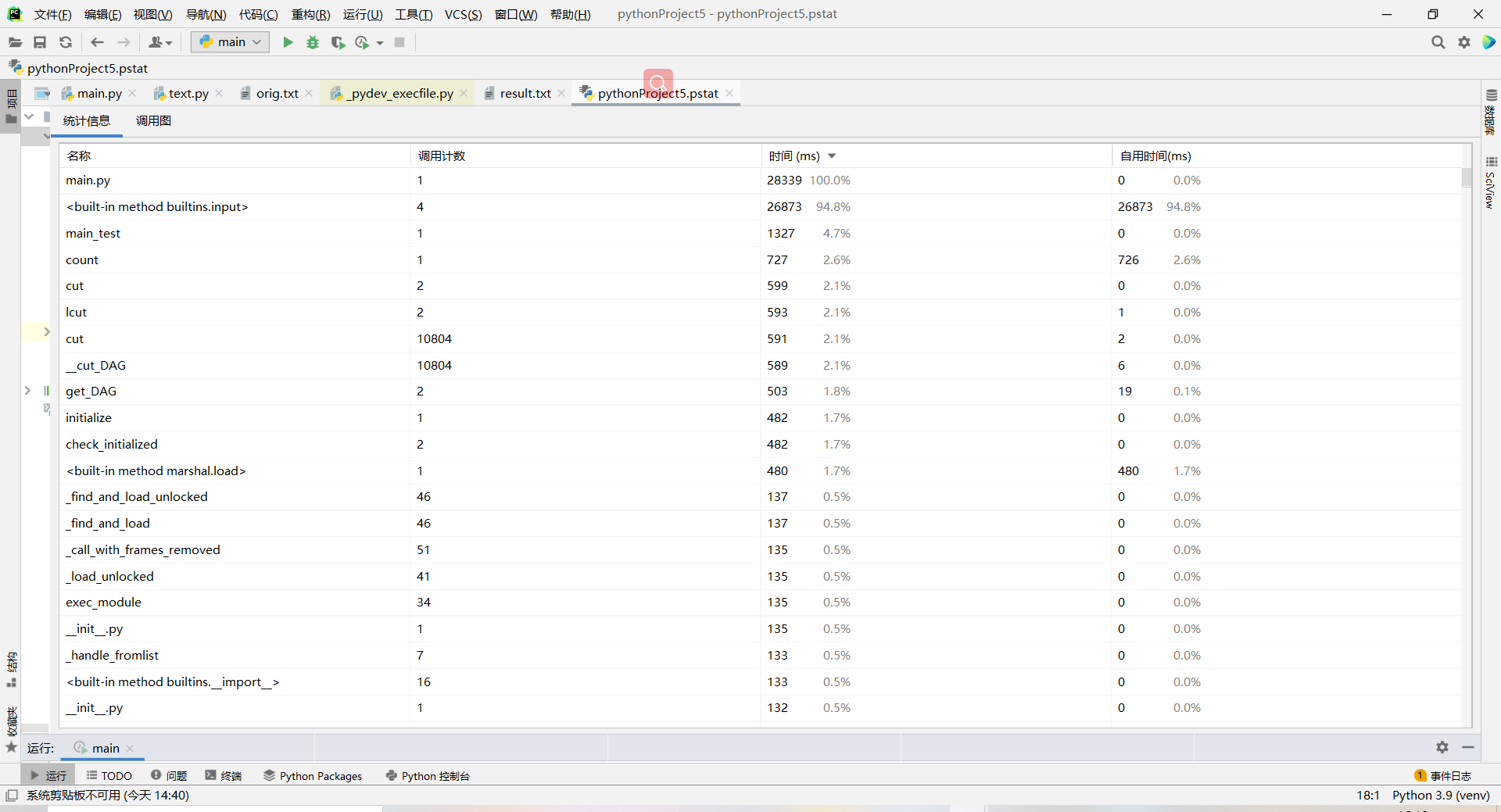
由上图可以看出改进后count的时间明显变短了
count函数改进前后代码对比
改进前:

改进后:

关系图:
覆盖率
正常情况下的程序覆盖率:(main.py的代码覆盖率为90%,剩下的10%未覆盖的代码为异常检测的代码,这部分在单元测试的时候会覆盖。)

异常情况下的程序覆盖率:

计算模块部分单元测试展示
单元测试代码:

文件输入错误的单元测试:

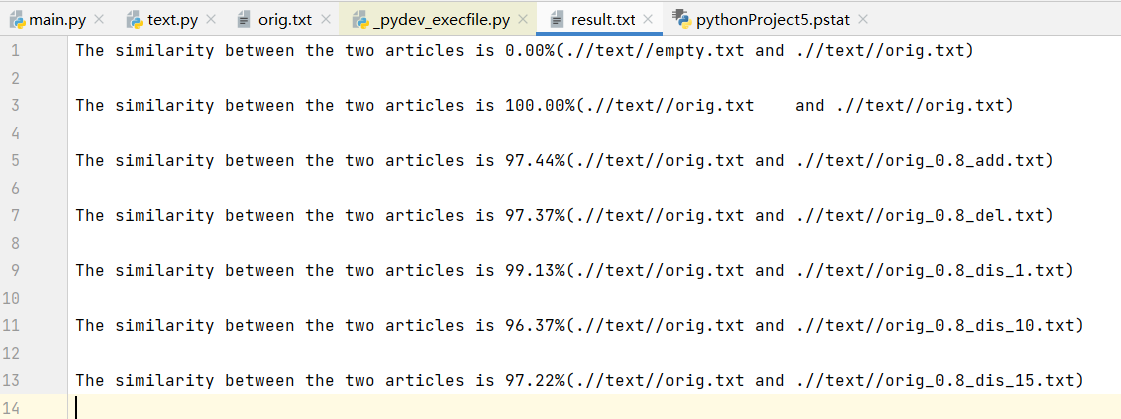
对orig.txt与orig_0.8_add.txt进行查重

对orig.txt与orig_0.8_del.txt进行查重

对orig.txt与orig_0.8_dis_1.txt进行查重

对orig.txt与orig_0.8_dis_10.txt进行查重

对orig.txt与orig_0.8_dis_15.txt进行查重

对orig_0.8_add.txt与orig_0.8_del.txt进行查重

对orig_0.8_dis_1.txt与orig_0.8_dis_10.txt进行查重

对orig.txt与orig.txt进行查重

单元测试覆盖率(单元测试代码test.py代码覆盖率为100%)

计算模块部分异常处理说明
- FileNotFoundError(当输入的文件路径为空或错误时会提示:Sorry, the text does not exist.)
代码截图:

样例截图:

- ZeroDivisionError(当处理的文件为空时,其词频为0,向量也为0,此时会出现除数为0的错误提示:Sorry, the text is blank.)
代码截图:

样例截图:

文本绝对路径:

测试结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号