异常检测 | 使用孤立森林 sklearn.ensemble.IsolationForest 分析异常流量
孤立森林
Isolation Forest(sklearn.ensemble.IsolationForest):一种适用于 连续数据 的 无监督 异常检测方法。与随机森林类似,都是高效的集成算法,相较于LOF,K-means等传统算法,该算法鲁棒性高且对数据集的分布无假设。
-
该算法对特征的要求低,不需要做离散化,不需要数值标准化
-
附:SKlearn 中其他用于异常检测的方法
-
one-class SVM(svm.OneClassSVM)
-
LocalOutlierFactor(sklearn.neighbors.LocalOutlierFactor)
本案例中
需求:分析一下通过不同渠道来到网站的访客里面是否有异常流量
数据特点:(综合数据特点,)
数据是不带标记的数据,只能用无监督式分析方法
特征维度较高,有的特征是分类型变量,有的特征是数值型变量
代码示例
1 数据预处理
1.1 填充缺失值、去除无关项(如 用户id,可能影响结果)
【此处,处理好的数据集是 df 】
不是主要代码,略
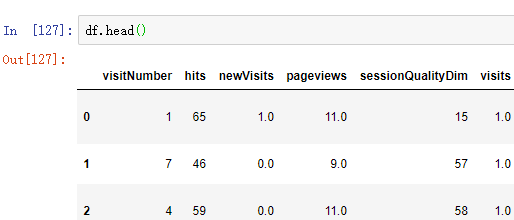
1.2 将 分类特征 转换为 数值型
【此处,处理好的数据集是feature_merge】
方法请移步 https://www.cnblogs.com/ykit/p/12440945.html
2 异常诊断
2.1 异常点检测
from sklearn.ensemble import IsolationForest # 创建模型,n_estimators:int,可选(默认值= 100),集合中的基本估计量的数量 model_isof = IsolationForest(n_estimators=20) # 计算有无异常的标签分布 outlier_label = model_isof.fit_predict(feature_merge)
得到 array 类型的 标签数据

2.2 异常结果汇总
# 将array 类型的标签数据转成 DataFrame outlier_pd = pd.DataFrame(outlier_label, columns=['outlier_label']) # 将标签数据与原来的数据合并 data_merge = pd.concat((df, outlier_pd), axis=1)
查看一下异常流量和正常流量的数量
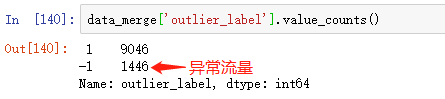
2.3 统计每个渠道的异常情况
# 创建用于返回数据集的函数 def cal_sample(df): return df.groupby(['source'], as_index=False)['visitNumber'].count().sort_values(['source'], ascending=False) # 取出异常样本 outlier_source = data_merge[data_merge['outlier_label']==-1] outlier_source_sort = cal_sample(outlier_source) # 取出正常样本 normal_source = data_merge[data_merge['outlier_label']==1] normal_source_sort = cal_sample(normal_source)

2.4 计算异常比例
# 将并异常流量与正常流量为一个 DataFrame source_merge = pd.merge(outlier_source_sort, normal_source_sort, on='source', how='outer') # 修改列名 source_merge = source_merge.rename( columns={'visitNumber_x': 'outlier_count', 'visitNumber_y': 'normal_count'}) # 计算异常比例 source_merge['total_count'] = source_merge['outlier_count'] + \ source_merge['normal_count'] source_merge['outlier_rate'] = source_merge['outlier_count'] / \ source_merge['total_count']
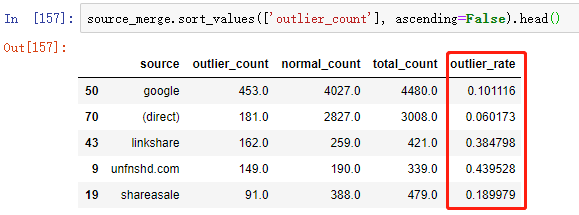
bingo~
本文仅用于学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号