Pandas 的 merge 方法讲解及 how= inner/ outer/ left/ right 的连接方式演示
merge 的使用
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),
copy=True, indicator=False, validate=None)
常用参数:
left:左 DataFrame
right:右 DataFrame
how:连接方式:‘inner’(默认);还有,‘outer’、‘left’、‘right’
on:用于连接的列名,必须同时存在于左右两个DataFrame对象中
连接方式演示
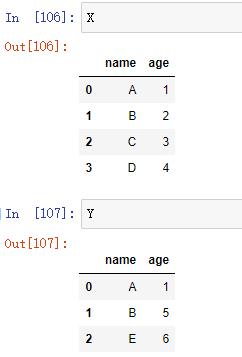
0 数据准备
import pandas as pd # 创建两个用于演示的DataFrame X = pd.DataFrame({'name':['A','B','C','D'],'age':[1,2,3,4]}) Y = pd.DataFrame({'name':['A','B','E'],'age':[1,5,6]})
其中:
A 同学在两个数据集中都存在,并且对应的 age 相同
B 同学在两个数据集中都存在,但对应的 age 不同
C D 两位同学只出现在 X 数据集中
E 同学只出现在 Y 数据集中
1 inner 内连接
merge 默认的连接方式
以 name 列为基准,保留两个数据集中同时存在的样本,这些样本的其他特征都会保留

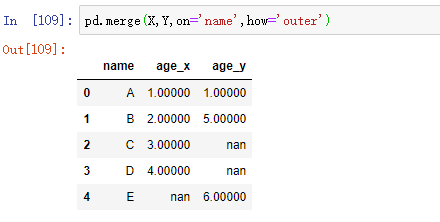
2 outer 外连接
以 name 列为基准,保留 X Y 两个数据集里 name 中出现的所有值,这些样本的其他特征都会保留,不存在的特征会自动补充 nan
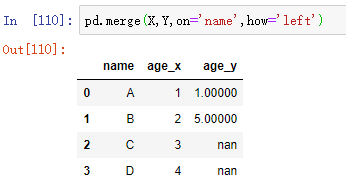
3 left 左连接
保留左 DataFrame 中,name 列出现的所有值(单独出现在右 DataFrame 的 name 里的值会被去除),这些值在右 DataFrame 里对应的值也会保留
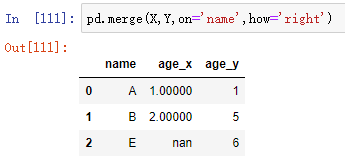
4 right 右连接
保留右 DataFrame 中,name 列出现的所有值(单独出现在左 DataFrame 的 name 里的值会被去除),这些值在左 DataFrame 里对应的值也会保留
文字有些啰嗦,看代码示例 [略~]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号