数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
import pandas as pd from sklearn.preprocessing import OneHotEncoder # 生成数据 df = pd.DataFrame({'id': [3566841, 6541227, 3512441], 'sex': ['male', 'Female', 'Female'], 'level': ['high', 'low', 'middle'], 'score': [1, 2, 3]})

方法 1 :使用 sklearn 库的 OneHotEncoder
# 获得ID列(还保留二维的形式,等一会儿还要拼回去) id_data = df[['id']] # 指定要转换的列 test_data = df.iloc[:,1:] # 建立标志转换模型对象(也称为哑编码对象) onehot_model = OneHotEncoder() df1 = onehot_model.fit_transform(test_data).toarray() # 拼接 df_all = pd.concat((id_data, pd.DataFrame(df1)), axis=1)

完成转换~
注:
1> 通过 OneHotEncoder 后,得到一个矩阵对象,
# 得到的 df1 是一个矩阵对象 <3x8 sparse matrix of type '<class 'numpy.float64'>' df1 = onehot_model.fit_transform(test_data)

2> 矩阵进行 toarray() 后,得到 array 对象, 得到的 array 要进一步转化成 DataFrame,才能使用 pd.concat 完成拼接
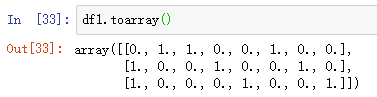
df1 = pd.DataFrame(df1.toarray())
df_all = pd.concat([id_data,df1],axis=1)
方法二:使用 pandas 的 get_dummuies
此方法只会对非数值类型的数据做转换
id_data = df.id test_data = df.iloc[:,1:] test_data_dum = pd.get_dummies(test_data) # 核心代码 df_dum = pd.concat([id_data, test_data_dum],axis=1)
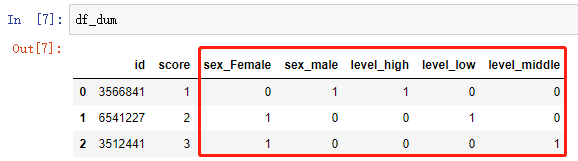
保留数值型特征 score,对非数值型的 sex 和 level 进行了转换

 浙公网安备 33010602011771号
浙公网安备 33010602011771号