


在内存中缓存数据
- Spark SQL可以通过调用Spark .catalog. cachetable(“tableName”)或datafame .cache()来使用内存中的列格式缓存表。
- Spark SQL将只扫描所需的列,并自动调整压缩,以最小化内存使用和GC压力。
- 调用spark.catalog.uncacheTable(“tableName”)来从内存中删除该表。
- 可以使用SparkSession上的setConf方法或使用SQL运行SET key=value命令来配置内存缓存。

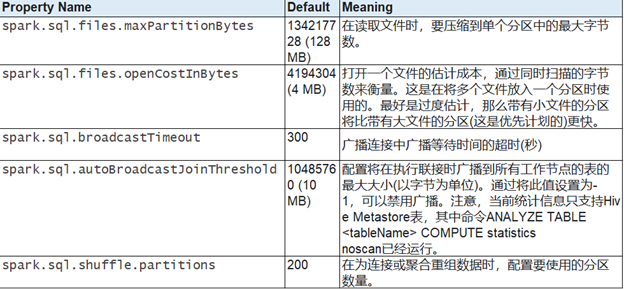
调优参数
- 还可以使用以下选项来调优查询执行的性能。在将来的版本中,随着自动执行更多的优化,这些选项可能会被弃用。
与人玫瑰-手有余香
