
roc_auc_score
roc_auc_score(Receiver Operating Characteristics(受试者工作特性曲线,也就是说在不同的阈值下,True Positive Rate和False Positive Rate的变化情况))
我们只考虑判为正的情况时,分类器在正例和负例两个集合中分别预测,如果模型很好,在正例中预测,百分百为正例,而在负例中预测,百分0为正例,说明模型分类能力很强,因为对于不同的例子进行了区别对待,正确识别了。
如果模型很差,在正负例两个集合中,全都一般判为正,一半判为负,则说明这个分类器啥也没干。
TPR(预测为正的在正例中的比例) = TP/P = TP/(TP+FN)
FPR(预测为正的在正例中的比例) = FP/N = FP/(FP+TN)
并且通过调整阈值,一定存在两个点:
1、全部样本都判正,则TPR=1, FPR=1
2、全部样本都判负,则TPR=0, FPR=0
所以,如果分类器啥也没干,则为中间虚线,AUC=AUCmin=0.5
如果分类器真正有识别能力,则TPR>FPR,也就是在正例中更倾向于判正,负例中倾向于判负,为图中实线。
如果在某一阈值下,TPR为1,FPR=0,则这个分类器经过点(0,1),AUC=AUCmax=1
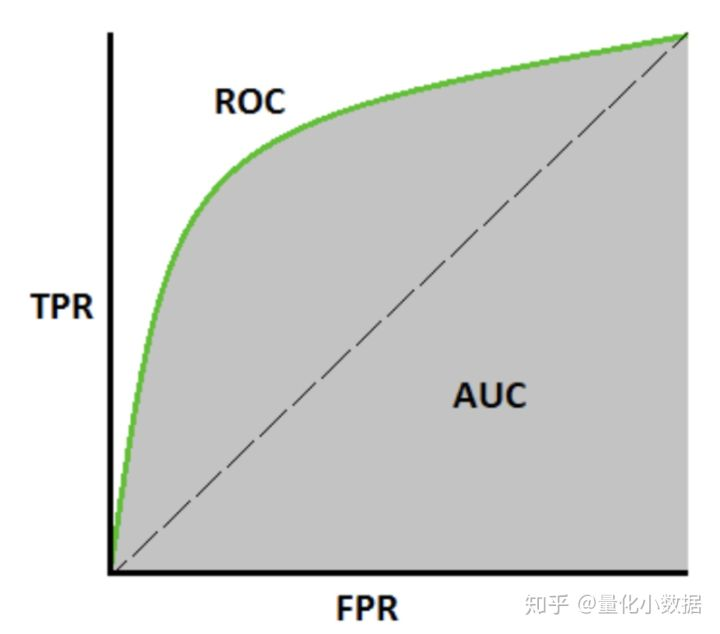
实际模型判定时,通常令thresh=0.5,即高于0.5判正,低于0.5判负。但考虑到样本不均的问题,我们应该使用不同的thresh,然后去计算auc。这个过程可以让sklearn帮我们完成。
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
0.75
auc就是曲线下面积,这个数值越高,则分类器越优秀

