
Hadoop hadoop(2.9.0)---uber模式(小作业“ubertask”优化)
前言:
在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加Hadoop集群的资源消耗,并且因为创建分配Container本身的开销,还会增加这些任务的运行时延。如果能将这些小任务都放入少量的Container中执行,将会解决这些问题。好在Hadoop本身已经提供了这种功能,只需要我们理解其原理,并应用它。
Uber运行模式就是解决此类问题的现成解决方案。
uber运行模式:
Uber运行模式对小作业进行优化,不会给每个任务分别申请分配Container资源,这些小任务将统一在一个Container中按照先执行map任务后执行reduce任务的顺序串行执行。那么什么样的任务,mapreduce框架会认为它是小任务呢?
- map任务的数量不大于mapreduce.job.ubertask.maxmaps参数(默认值是9)的值;
- reduce任务的数量不大于mapreduce.job.ubertask.maxreduces参数(默认值是1)的值;
- 输入文件大小不大于mapreduce.job.ubertask.maxbytes参数(默认为1个Block的字节大小)的值;
- map任务和reduce任务需要的资源量不能大于MRAppMaster(mapreduce作业的ApplicationMaster)可用的资源总量;也就是说yarn.app.mapreduce.am.resource.mb必须大于mapreduce.map.memory.mb和mapreduce.reduce.memory.mb以及yarn.app .mapreduce.am.resource.cpu-vcores必须大于mapreduce.map.cpu.vcores和mapreduce.reduce.cpu.vcores以启用ubertask。
参数mapreduce.job.ubertask.enable用来控制是否开启Uber运行模式,默认为false。
优化:该优化在单个JVM中按顺序运行“足够小”的作业。
以WordCount例
(1)限制任务的划分数量:
hadoop自带的Wordcount程序里面,MapReduce数量已经通过Job.setNumReduceTasks(int)方法已经设置为1,因此满足mapreduce.job.ubertask.maxreduces参数的限制。所以我们首先控制下map任务的数量,我们通过设置mapreduce.input.fileinputformat.split.maxsize参数来限制。看看在满足小任务前提,但是不开启Uber运行模式时的执行情况。执行命令如下:
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 /wc.input /wc.output_2
file wc.intput为25K 参数 mapreduce.input.fileinputformat.split.maxsize=6 是以k为单位,我这里在分片的时候指定的6K,所以,最终分的片为5个,从下图可以明显的看出来,处理的总文件为1,分片数量为5,uber模式为false;还可以看到一共6个map任务,一个reduce任务。
结果如下:

web界面查看:

(2)开启uber模式
[hadoop@master hadoop-2.9.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=6 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_5
wc.input 35k
结果如下:

这里是是6个map任务和1个reduce任务,但是之前的数据本地map任务= 5一行信息已经变为当地的其他maptasks=6。此外还增加了TOTAL_LAUNCHED_UBERTASKS、NUM_UBER_SUBMAPS、NUM_UBER_SUBREDUCES等信息,如下图所示:
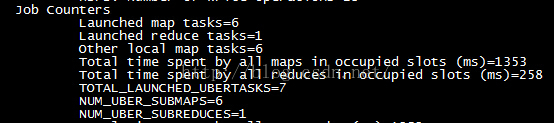
以下列出这几个信息的含义:
| 输出字段 | 描述 |
| TOTAL_LAUNCHED_UBERTASKS | 启动的Uber任务数 |
| NUM_UBER_SUBMAPS | Uber任务中的map任务数 |
| NUM_UBER_SUBREDUCES | Uber中reduce任务数 |
其他测试
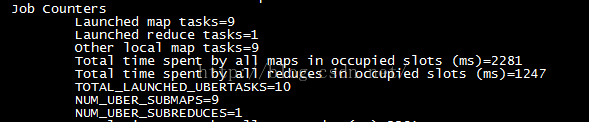
由于我主动控制了分片大小,导致分片数量是6,这小于mapreduce.job.ubertask.maxmaps参数的默认值9。按照之前的介绍,当map任务数量大于9时,那么这个作业就不会被认为小任务。所以我们先将分片大小调整为20字节,使得map任务的数量刚好等于9,然后执行以下命令:
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=20 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_6
file:wc.input 为172k

我们看到的确将输入数据划分为9份了其它信息如下
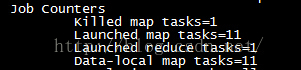
[hadoop@master hadoop-2.9.0]hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=19 -D mapreduce.job.ubertask.enable=true /wc.input /wc.output_7

我们看到的确将输入数据划分为10份了其它信息如下:
- 设置当map任务全部运行结束后才开始reduce任务(参数mapreduce.job.reduce.slowstart.completedmaps设置为1.0,默认0.05)。
- 将当前Job的最大map任务尝试执行次数(参数mapreduce.map.maxattempts)和最大reduce任务尝试次数(参数mapreduce.reduce.maxattempts)都设置为1,默认为4。
- 取消当前Job的map任务的推断执行(参数mapreduce.map.speculative设置为false)和reduce任务的推断执行(参数mapreduce.reduce.speculative设置为false),默认为。

