
Hadoop mapreduce过程分析
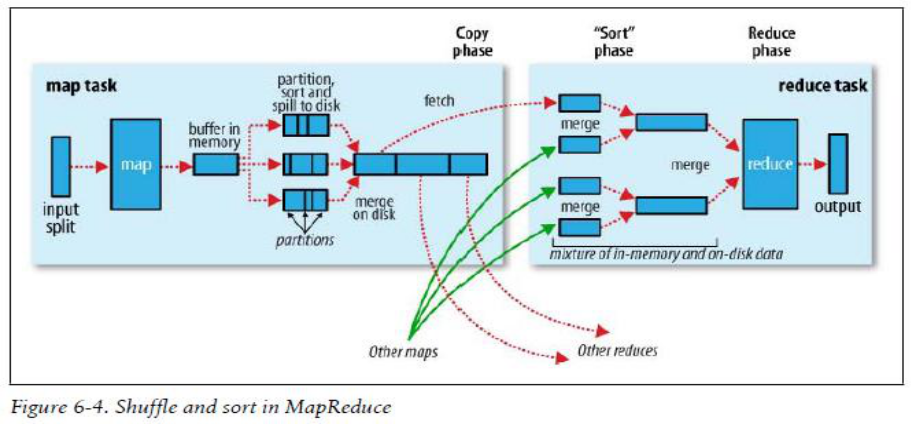
原理图:
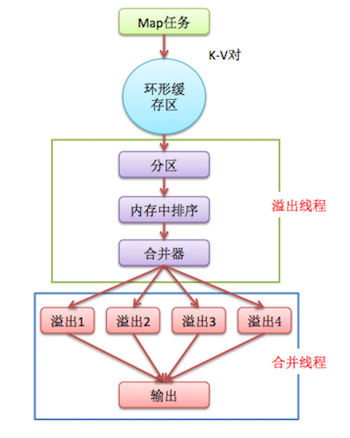
中间结果的排序与溢出(spill)流程图
map分析:
(1)、输入分片(input split):在进行mapreduce之前,mapreduce首先会对输入文件进行输入分片(input split)操作,每一个输入分片针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,对于输入文件的分片大小,通常跟hdfs的块大小有关系,例如:hdfs的块大小为64MB,假如输入三个文件,1MB、98MB的文件,mapreduce就会对1MB的文件当作一个input split,对98MB的文件做两个input split(可以通过修改参数mapreduce.input.fileinputformat.split.minsize,使其大于块容量;由于CPU的约束,有时可以减少fileinputformat.split.minsize属性值,使它小于HDFS的块容量,从而提高资源的利用率。)。针对这三个分片操作,就有三个map任务要执行,但是这里每一个map任务执行的数据大小并不均匀,这里也是一个调优的重点。
(2)、map阶段就是通过程序员定义好的map函数输出键值<k1,v1>对了。每一个map task有一个环形内存缓冲区,用于存放map task的输出,也就是键值对<k2,v2>,已经被序列化,但没有排序。环形缓冲区默认大小100MB(mapreduce.task.io.sort.mb属性),一旦达到阀值0.8(mapreduce.map.sort.spill.percent属性),一个后台线程就把溢出(spill)内容写到Linux本地磁盘中的指定目录(mapreduce.cluster.local.dir)下的新建的一个溢出写文件,当超过阈值时,Map任务不会因为缓存溢出而被阻塞。但如果达到硬限制,Map任务会被阻塞,直到溢出行为结束。缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。
♥ 线程会将记录基于键进行分区(通过 mapreduce.job.partitioner.class设置分区算法的类),在内存中将每个分区的记录按键排序(通过map.sort.class指定排序算法,默认快速排序org.apache.hadoop.util.QuickSort),然后写入一个文件。每次溢出,都有一个独立的文件存储。
♥ Map任务完成后,缓存溢出的各个文件会按键排序后合并到一个输出文件(通过mapreduce.cluster.local.dir指定输出目录,值为${hadoop.tmp.dir}/mapred/local)。合并文件的流的数量通过mapreduce.task.io.sort.factor指定,默认10,即同时打开10个文件执行合并。
说白点就是:在写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
根据上面步骤,最好仅在Map任务结束的时候才能缓存写到磁盘中。
可以采用以下方法提高排序和缓存写入磁盘的效率:
- 调整mapreduce.task.io.sort.mb大小,从而避免或减少缓存溢出的数量。当调整这个参数时,最好同时检测Map任务的JVM的堆大小,并必要的时候增加堆空间。
- mapreduce.task.io.sort.factor属性的值提高100倍左右,这可以使合并处理更快,并减少磁盘的访问。
- 为K-V提供一个更高效的自定义序列化工具,序列化后的数据占用空间越少,缓存使用率就越高。
- 提供更高效的Combiner(合并器),使Map任务的输出结果聚合效率更高。
- 提供更高效的键比较器和值的分组比较器。
注:
如果指定了Combiner,可能在两个地方被调用。
- 当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
- 缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用Combiner。
1、获取中间输出结果(Map侧)
Reducer需要通过网络获取Map任务的输出结果,然后才能执行Reduce任务,可以通过下述Map侧的优化来减轻网络负载:
- 通过压缩输出结果,mapreduce.map.output.compress设置为true(默认false),mapreduce.map.output.compress.codec指定压缩方式。
- Reduce任务是通过HTTP协议获取输出分片的,可以使用mapreduce.tasktracker.http.threads指定执行线程数(默认40)
reduce阶段:
Reduce任务是一个数据聚合的步骤。数量默认为1,而使用过多的Reduce任务则意味着复杂的shuffle,并使输出文件的数量激增。mapreduce.job.reduces属性设置reduce数量,也可以通过编程的方式,调用Job对象的setNumReduceTasks()方法来设置。一个节点Reduce任务数量上限由mapreduce.tasktracker.reduce.tasks.maximum设置(默认2)。
可以采用以下探试法来决定Reduce任务的合理数量:
# 每个reducer都可以在Map任务完成后立即执行
0.95 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)另一个方法是
# 较快的节点在完成第一个Reduce任务后,马上执行第二个
1.75 * (节点数量 * mapreduce.tasktracker.reduce.tasks.maximum)2. 获取中间输出结果(Reduce侧)
Reduce任务在结束时都会获取Map任务相应的分区数据,这个过程叫复制阶段(copy phase)。一个Reduce任务并行多少个Map任务是由mapreduce.reduce.shuffle.parallelcopies参数决定(默认5)。
由于网络问题,Reduce任务无法获取数据时,会以指数退让(exponential backoff)的方式重试,超时时间由mapreduce.reduce.shuffle.connect.timeout设置(默认180000,单位毫秒),超时之后,Reduce任务标记为失败状态。
3. 中间输出结果的合并与溢出
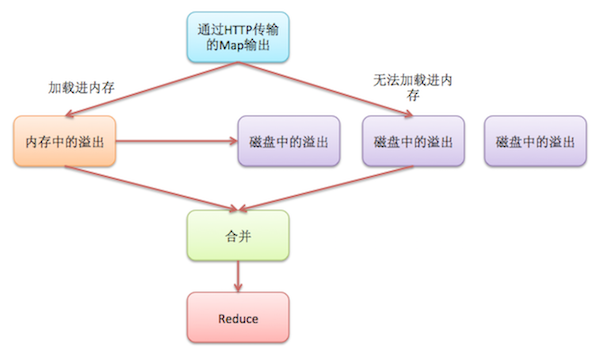
Reduce任务也需要对多个Map任务的输出结果进行合并,过程如上图,根据Map任务的输出数据的大小,可能将其复制到内存或磁盘。mapreduce.reduce.shuffle.input.buffer.percent属性配置了这个任务占用的缓存空间在堆栈空间中的占用比例(默认0.70)。
mapreduce.reduce.shuffle.merge.percent决定缓存溢出到磁盘的阈值(默认0.66),mapreduce.reduce.merge.inmem.threshold设置了Map任务在缓存溢出前能够保留在内存中的输出个数的阈值(默认1000),只要一个满足,输出数据都将会写到磁盘。
在收到Map任务输出数据后,Reduce任务进入合并(merge)或排序(sort)阶段。同时合并的文件流的数量由mapreduce.task.io.sort.factor属性决定(默认10)。
Map任务输出数据的所有压缩操作,在合并时都会在内存中进行解压缩操作。
借鉴:https://blog.csdn.net/u013980127/article/details/52807360
链接:https://blog.csdn.net/u012151684/article/details/72589302

