

Flink (1) 安装部署
一、下载软件包
这里下载2021年最新版本的1.12
官网下载地址:官网
其他镜像源: http://mirrors.hust.edu.cn/apache/flink/flink-1.12.1/
官网下载比较慢
对于flink来说,部署方式有三种,分别是local、standalone、yarn cluster
二、部署standalone
2.1 上传到集群解压
tar zxvf flink-1.12.1-bin-scala_2.12.tgz -C /data1/hadoop/
cd /data1/hadoop/
mv flink-1.12.1/ flink
2.2 配置
配置文件主要关注以下几个
conf/flink-conf.yaml // 主要的配置文件
conf/masters // 配置master阶段localhost
conf/workers // 配置task节点,默认是localhost
这里在一台节点部署,类似于伪分布式。
# grep -Ev "^$|[#;]" conf/flink-conf.yaml
jobmanager.rpc.address: localhost // master通讯地址
jobmanager.rpc.port: 6123 // 通讯端口
jobmanager.memory.process.size: 1600m // 运行master的节点使用的内存大小
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1 // 任务slot,这个有点类似yarn的container或者spark的executor,可以理解为一个资源单位(cpu或者一块内存)。
parallelism.default: 1 // 默认的并行度,对于分布式框架来说,并行处理任务是最基本的。
jobmanager.execution.failover-strategy: region // 故障恢复的处理策略,可以是region或者full。说白了就是某一个任务失败以后,如果配置的是region,那么只是影响一部分,如果配置成full,那么影响所有的。
flink的架构跟spark其实很类似,比如jobmanager可以类比spark里面的master,taskmanager可以类比spark里面的worker。
2.3 启动flink
[hduser@hadoop4 flink]$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop4.
Starting taskexecutor daemon on host hadoop4.
[hduser@hadoop4 ~]$ jps
23188 Jps
23000 TaskManagerRunner
7001 QuorumPeerMain
22729 StandaloneSessionClusterEntrypoint
7375 Kafka
2.4 web界面
启动完以后,就可以查看web界面了
http://192.168.1.15:8081/#/overview
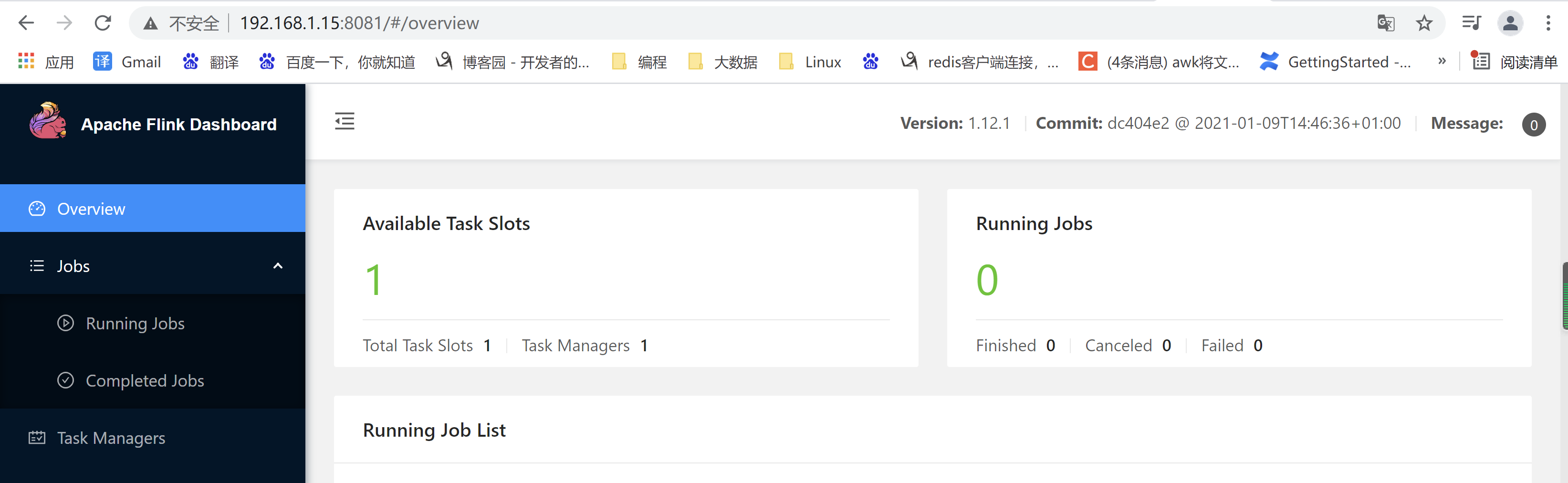
2.5 测试
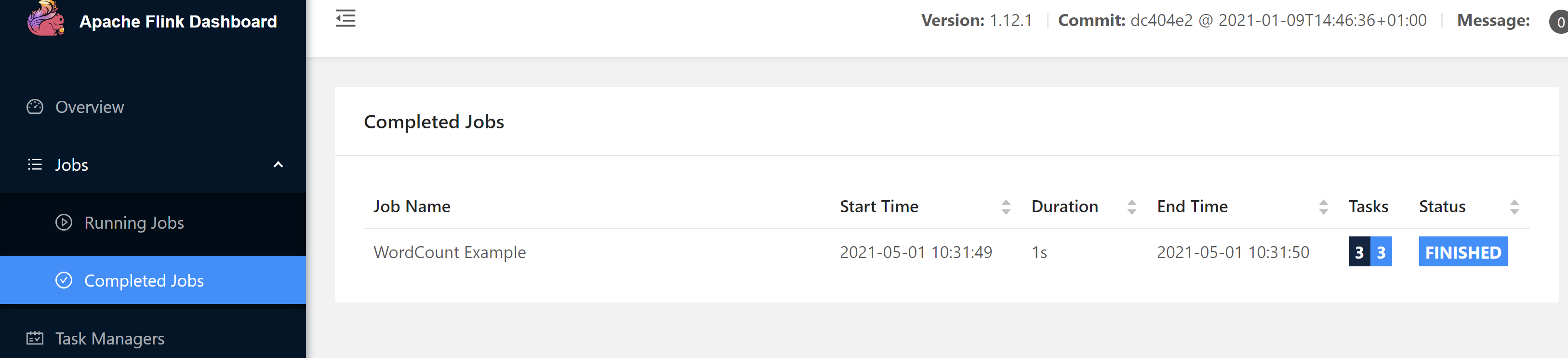
./flink run -m hadoop4:8081 ../examples/batch/WordCount.jar --input /tmp/input.txt --output /tmp/output.txt
web界面查看
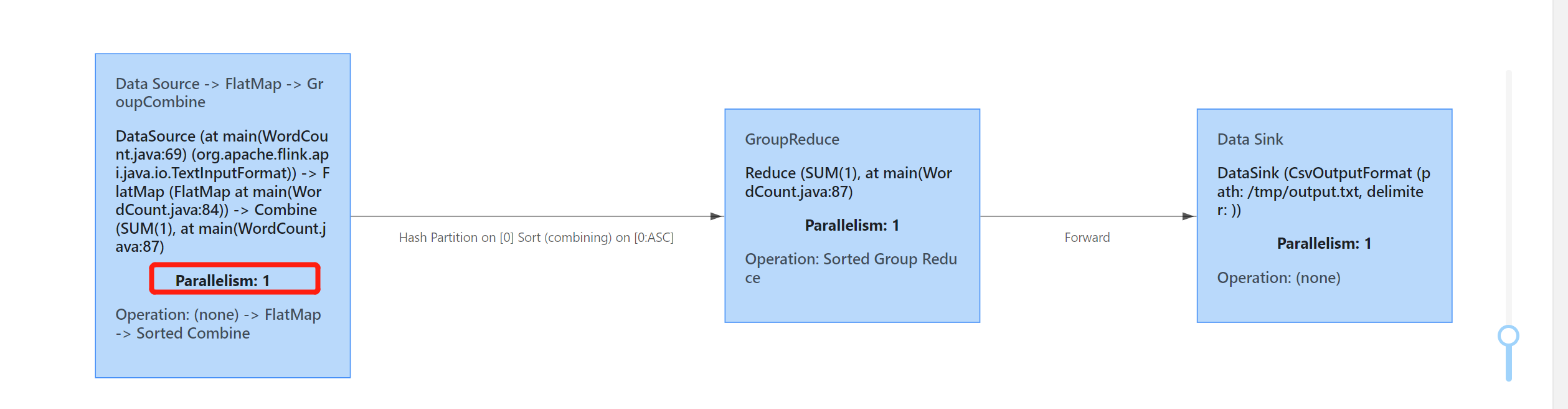
也可以看到其并发度
flink yarn对应两种模式,分别是yarn session、yarn cluster
三、yarn-session
3.1 说明
通过yarn进行资源管理,flink的任务直接提交到hadoop集群
1、hadoop集群启动,yarn需要运行起来。确保配置HADOOP_HOME环境变量。
2、flink on yarn的交互图解
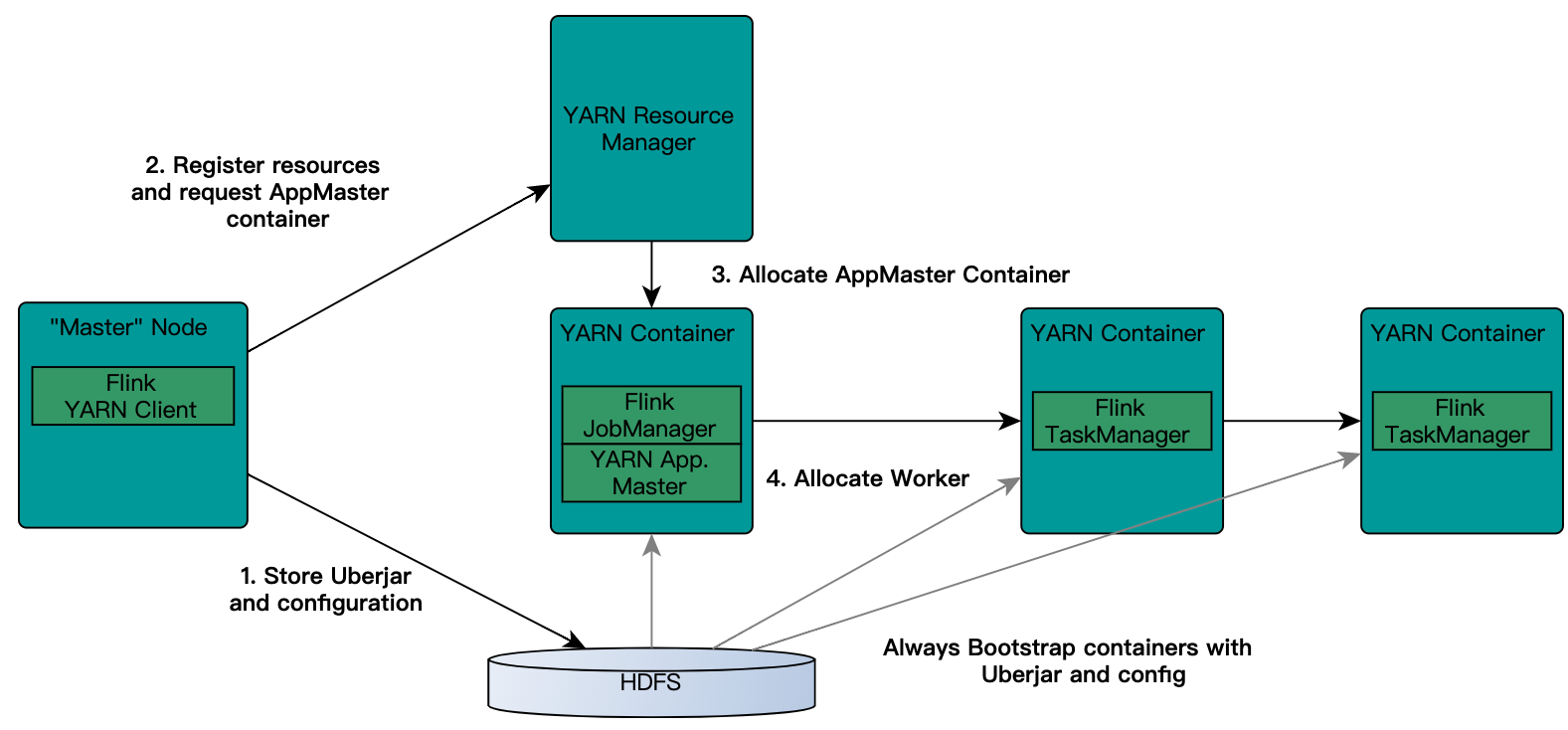
yarn seesion(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。
如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
这种方式资源被限制在session中,不能超过,比较适合特定的运行环境或者测试环境。
JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
3.2 部署
首先需要启动yarn集群
启动yarn session
[hduser@hadoop4 bin]$ ./yarn-session.sh -qu orc -n 1 -jm 1024 -tm 1024 -s 1
说明:
-n: 表示taskmanager数量
-jm: jobmanager内存大小
-tm: taskmanager内存大小
-s: taskmanager的slot数量
-qu: 队列

从上图可以看到jobmanager的地址
或者可以从yarn界面的application master界面进入
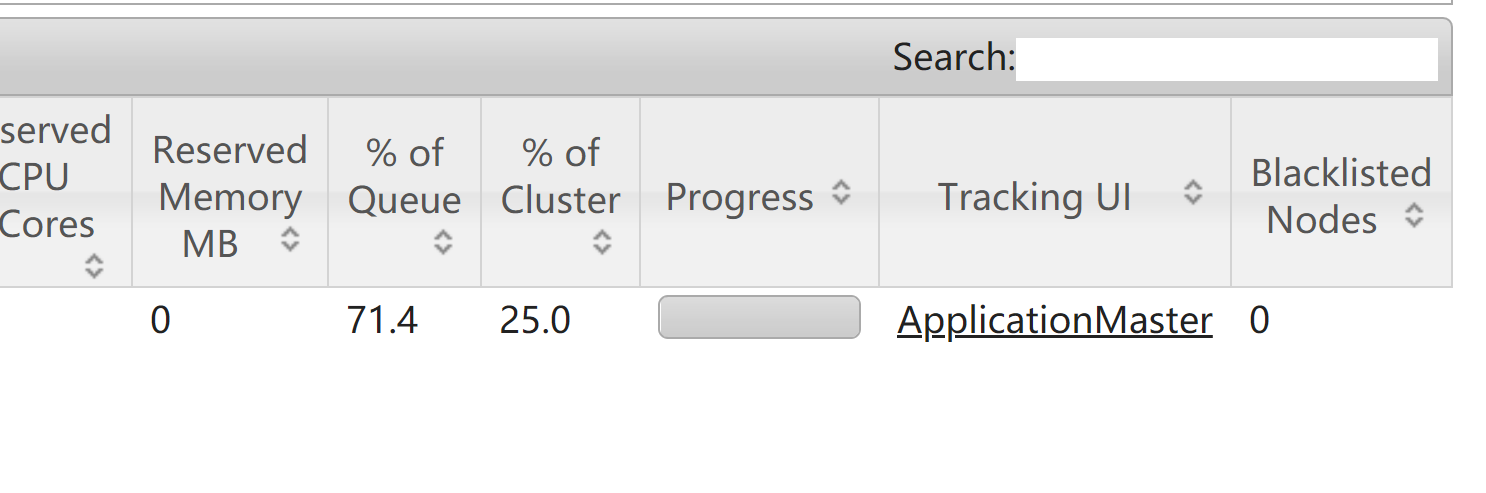
3.3 测试
[hduser@hadoop4 bin]$ ./flink run -m hadoop4:38563 ../examples/batch/WordCount.jar --input /tmp/input.txt --output /tmp/output1.txt
Job has been submitted with JobID e495084731cafc6868aba5023a16a0eb
Program execution finished
Job with JobID e495084731cafc6868aba5023a16a0eb has finished.
Job Runtime: 46790 ms
四、yarn cluster
[hduser@hadoop4 bin]$ ./flink run -yqu orc -m yarn-cluster ../examples/batch/WordCount.jar --input /tmp/input.txt --output /tmp/output2.txt
遇到的异常:
1、找不到类异常
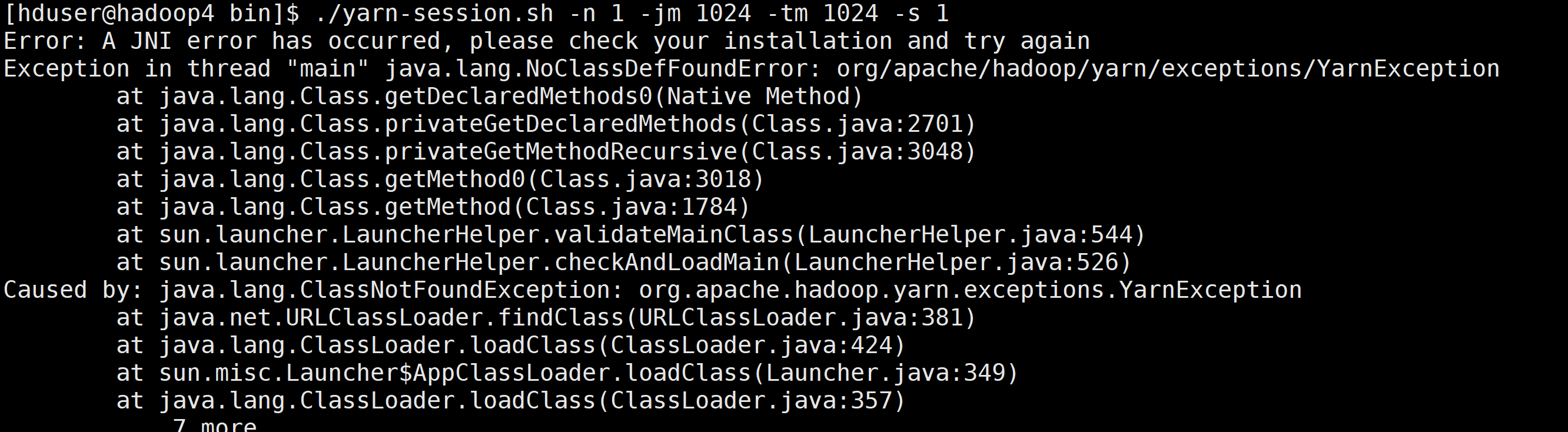
原因是在Flink1.11 之后不再提供flink-shaded-hadoop-*” jars
解决办法:
export HADOOP_CLASSPATH=`hadoop classpath`
2、cpu不足

从错误信息看是可以用的cpu个数为0,这可能是nodemanager没有正常启动导致。
3、yarn队列不能提交

这种是因为该队列没有分配资源导致
这种方式可以使用-qu指定队列的名字
借鉴:
| https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/setup_quickstart.html
| https://www.cnblogs.com/aibabel/p/10937110.html
| https://www.cnblogs.com/asker009/p/11327533.html
| https://www.cnblogs.com/infoo/p/13385069.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决