
使用idea 编写spark程序
一、 创建工程或者模块
如果已经存在工程,那么可以在当前工程下创建模块。
如果不存在工程,可以直接创建一个工程。
1.1 创建maven模块

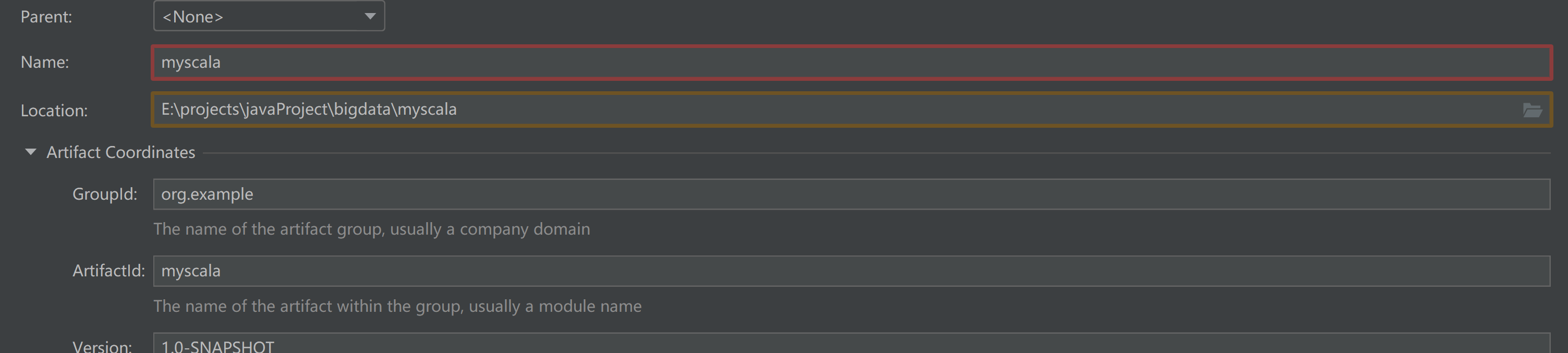
由于已经存在一个相同的模块,我这里标红了。
1.2 修改pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.asiainfo</groupId>
<artifactId>myscala</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<!-- 生成的jar中,不要包含pom.xml和pom.properties这两个文件-->
<addMavenDescriptor>false</addMavenDescriptor>
<manifest>
<!--是否要把第三方jar放到manifest的classpath中-->
<addClasspath>true</addClasspath>
<!--生成的manifest中classpath的前缀,因为要把第三方jar放到lib目录下,所以classpath的前缀是lib/-->
<classpathPrefix>lib/</classpathPrefix>
<!-- 应用的main class-->
<mainClass>ocom.asiainfo.test.WordCound</mainClass>
</manifest>
</archive>
<!-- 过滤掉不希望包含在jar中的文件-->
<excludes>
<exclude>${project.basedir}/xml/*</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<!--
<dependency>
<groupId>org.apache.tez</groupId>
<artifactId>tez-api</artifactId>
<version>0.7.0</version>
</dependency>
-->
</dependencies>
</project>
1.3 为当前项目添加对应的Scala框架
右键当前项目---> “Add Framework Support”---> 选择scala
二 代码编写
2.1 在myscala模块下的src路径下,创建一个scala目录
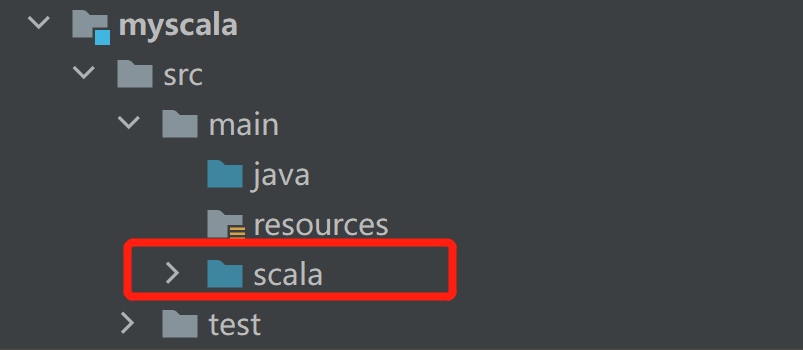
2.2 标记为源目录
邮件创建的scala
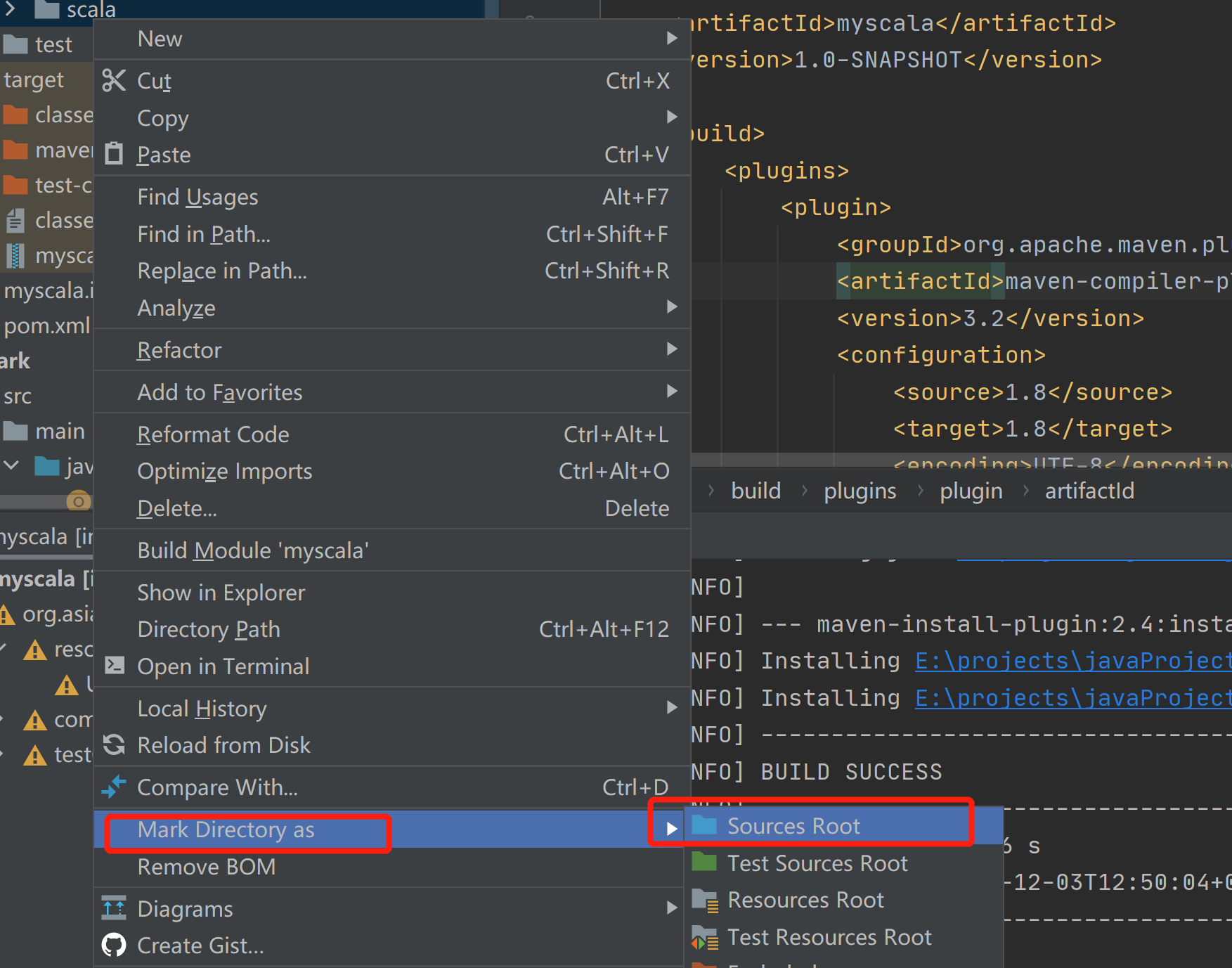
2.3 在scala目录下创建package,然后创建scala文件
具体的测试代码如下
package com.asiainfo.test
import org.apache.spark.{SparkConf, SparkContext}
/**
* ClassName: WordCound
* Description:
* date: 2020/12/3 10:36
*
* @author yjt
* @version
* @since JDK 1.8
*/
object WordCound {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" ")).map((_ ,1)).reduceByKey(_ + _,1).sortBy(_._2,false).saveAsTextFile(args(1));
//停止sc,结束该任务
sc.stop()
}
}
三 打包部署到集群
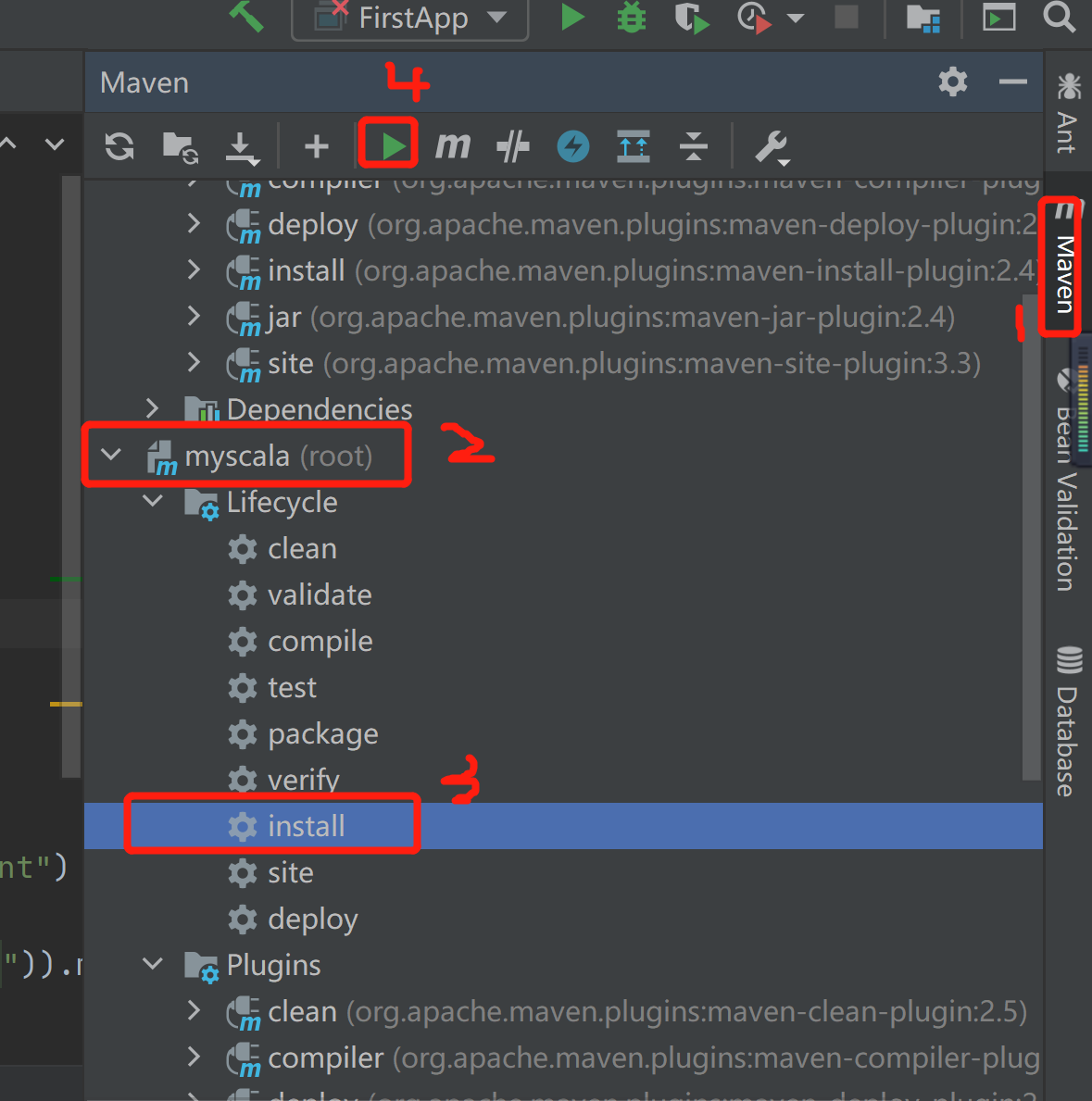
测试
./spark-submit --class com.asiainfo.test.WordCound --master spark://hadoop1:7077,hadoop2:7077 /home/hduser/ hdfs://yjt/input/a.log hdfs://yjt/output
结果
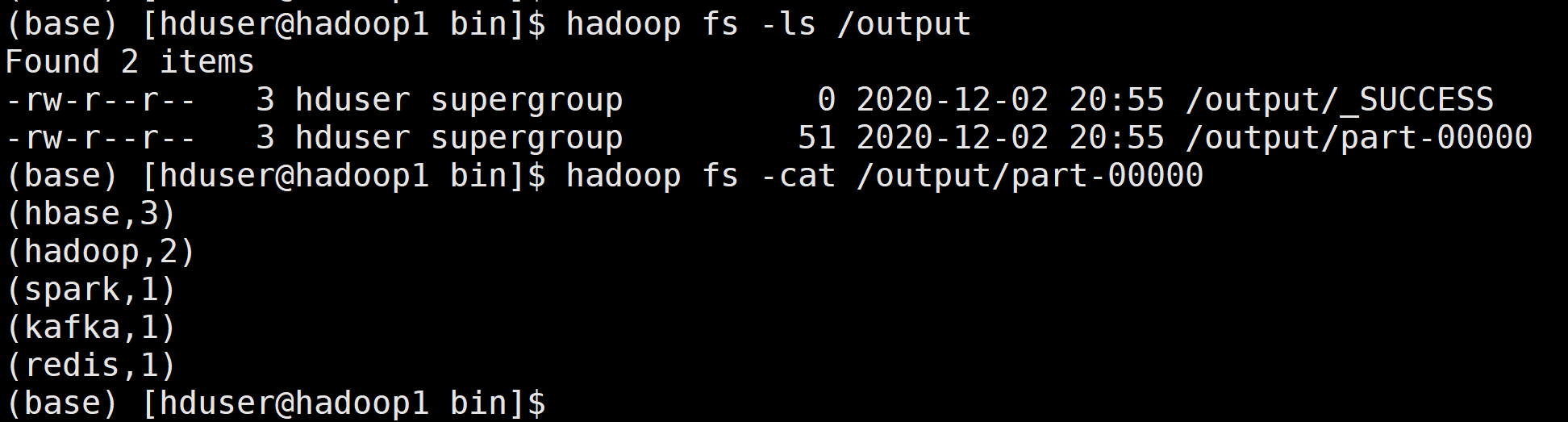
借鉴:
| https://blog.csdn.net/daqiang012/article/details/104561868
| https://www.cnblogs.com/biehongli/p/8462625.html
记录学习和生活的酸甜苦辣.....哈哈哈

