
zabbix(10)自动发现规则(low level discovery)
1、概念
在配置Iterms的过程中,有时候需要对类似的Iterms进行添加,这些Iterms具有共同的特征,表现为某些特定的参数是变量,而其他设置都是一样的,例如:一个程序有多个端口,而需要对端口配置Iterms。再如,磁盘分区,网卡的名称等等,由于具有不确定性,古配置固定的Items会出现无法通用的问题。
Low level discovery的Key可以对网卡、文件系统等进行自动发现,当然也支持自定义。
Low level discovery的使用过程分如下两步:
(1)自动发现特定变量的名称。
(2)添加对变量的Items。
Zabbix中Low level discovery的Key返回值是一个JSON格式。查看Low level discovery Key返回格式如下:

2、案列
使用Zabbix监控Hadoop集群的进程。每台机器启动的进程不一样,而这个时候想要监控每一台机器的hadoop进程,就需要自动发现规则了,如果配置通用的模板,把每一个监控项(监控每一个hadoop的进程)都配置上,会发现每一台主机对有些监控项是不支持的。
zabbix客户端配置如下:
EnableRemoteCommands=1 开启远程执行命令,默认是0,当监控到hadoop进程掉了以后,自动启动。
Timeout=30 超时
StartAgents=8 开启处理线程
编写自动发现脚本如下:
[root@manager1 script_py 19:20:09]#cat hadoopDiscovery.py #!/usr/bin/env python3 import os import json with open("/data1/zabbix_sh/jps.txt", "r") as f: text_lst = [i.split("\n")[0] for i in f.readlines()] hadoopProcess = [] for i in text_lst: hadoopProcess += [{'{#hadoopProcessName}':i}] print(json.dumps({'data':hadoopProcess},sort_keys=True,indent=7,separators=(',',':')))
[root@manager1 script_py 19:20:12]#cat /data1/zabbix_sh/jps.txt 这里面存储的是当前节点本应该启动的进程 DataNode Master
执行效果如下:
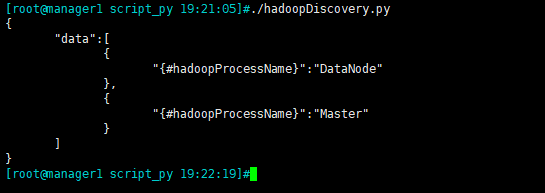
(1)自定义Key,如下:
# cat /etc/zabbix/zabbix_agentd.d/hadoop_process.conf UserParameter=hadoop_process[*],sudo /data1/zabbix_sh/hadoopProcess.py $1 UserParameter=hadoop_state,sudo /data1/zabbix_sh/hadoopState.py UserParameter=hadoop.process.discovery,sudo /data1/zabbix_sh/hadoopDiscovery.py
hadoopProcess.py脚本如下:
# cat hadoopProcess.py #!/usr/bin/env python3 'this is a system monitor scripts' __author__="yjt" import os import sys def hadoop_program(): with open("/data1/zabbix_sh/jps.txt", "r") as f: list_jps = [i.split("\n")[0] for i in f.readlines()] job_value = [] # hadoop_process = ['JournalNode','ResourceManager','HMaster','DataNode','DFSZKFailoverController','QuorumPeerMain','HQuorumPeerMain','JobHistory','Kfaka','NodeManager','Worker','Master','HRegionServer','NameNode','PrestoServer','RunJar'] job_lst = os.popen('/data1/jdk/bin/jps').readlines() for i in job_lst: value = i.split()[1] if value != 'Jps': job_value.append(value) if sys.argv[1] in job_value: print(1 ) elif sys.argv[1] in list_jps: print(0) # else: # print(2) if __name__ == "__main__": if len(sys.argv) > 1: hadoop_program()
配置完重启zabbix客户端
测试,是否可以从server端获取到数据:
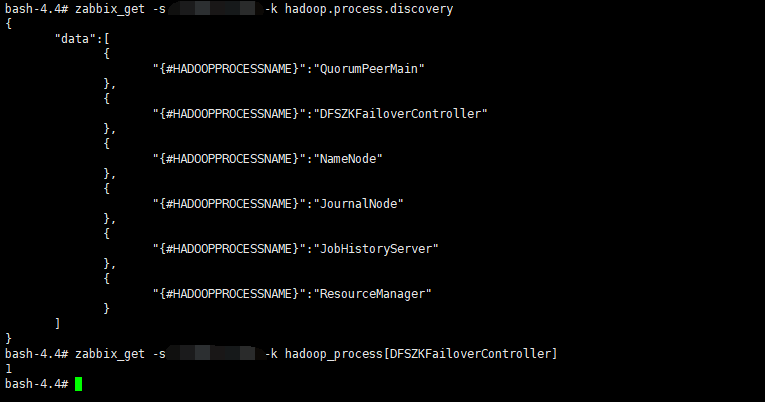
(2)web界面的配置:
1)创建一个模板:配置---> 模板--->创建模板
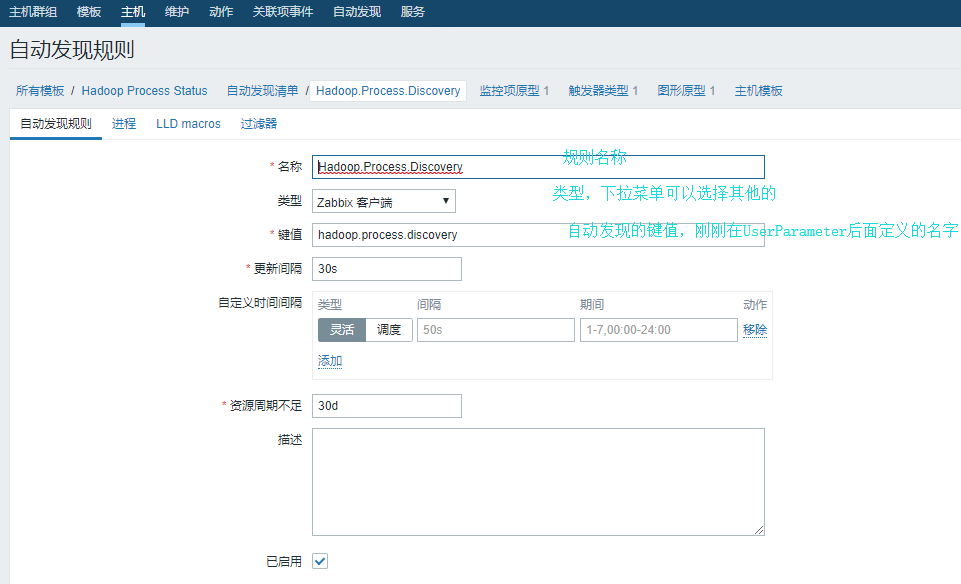
2)在改模板上创建自动发现规则:

3)自动发现规则配置
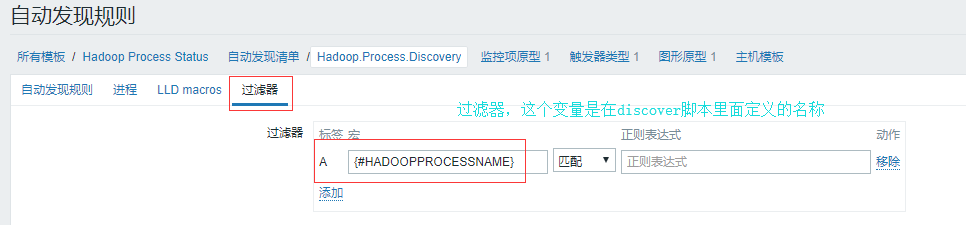
4)为这个模板创建原型的监控项

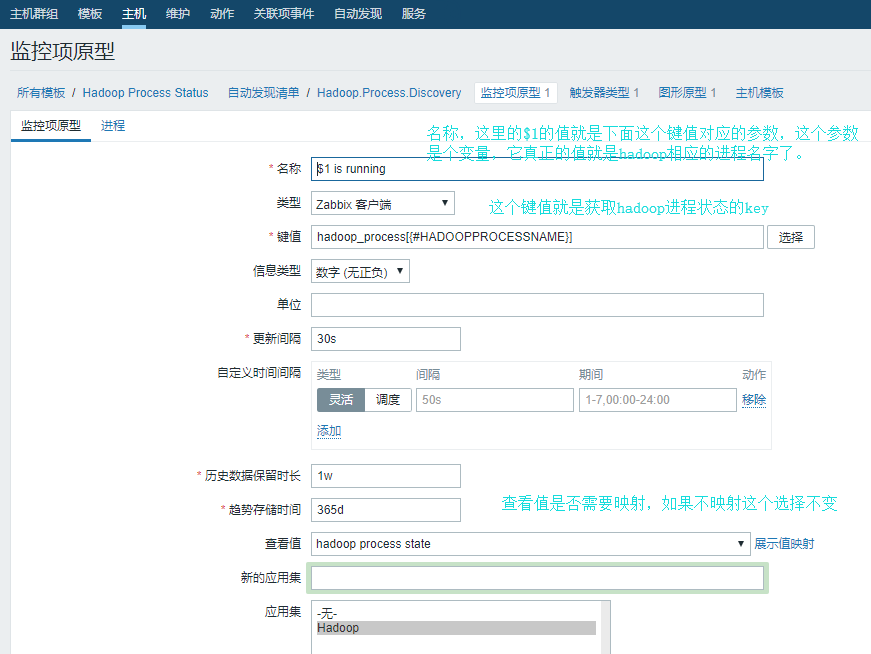
5)创建触发器:

6)创建图形:

到这里这个模板就创建好了。这个时候在创建主机的时候,关联这个模板看看效果,需要等待一段时间。效果如下:
第一台机器:
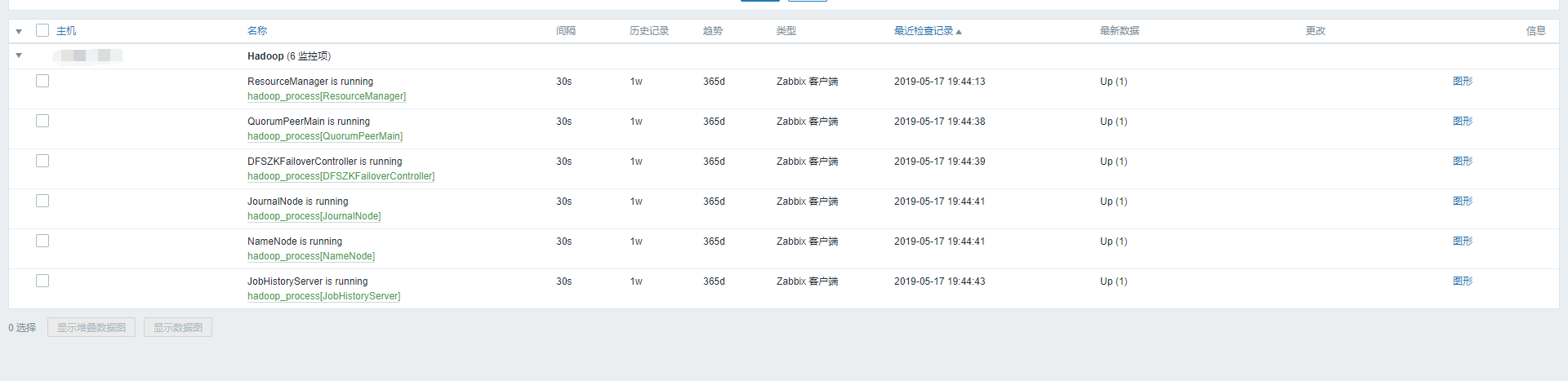
第二台机器:

OK

