
Hadoop zookeeper hbase spark phoenix (HA)搭建过程
环境介绍:
系统:centos7
软件包:
apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz 下载链接:http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-4.14.1-HBase-1.4/bin/apache-phoenix-4.14.1-HBase-1.4-bin.tar.gz
hadoop-3.1.1.tar.gz 下载链接:http://mirror.bit.edu.cn/apache/hadoop/core/hadoop-3.1.1/hadoop-3.1.1.tar.gz
hbase-1.4.8-bin.tar.gz 下载链接:http://mirror.bit.edu.cn/apache/hbase/1.4.9/hbase-1.4.9-bin.tar.gz
jdk-8u181-linux-x64.tar.gz 下载链接:https://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz
spark-2.1.0-bin-hadoop2.7.tgz 下载链接:http://mirror.bit.edu.cn/apache/spark/spark-2.1.3/spark-2.1.3-bin-hadoop2.7.tgz
zookeeper-3.4.13.tar.gz 下载链接:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
注:链接版本跟我现在使用的版本可能会有稍微差别,不过不影响,只是小版本号差那么一点,大版本号号还是一样的,这里使用最新的hadoop3.11版本。
资源关系:这里使用的主机名跟我待会使用的主机名不一样,毕竟生产环境,集群配置涉及到主机名和ip都会相应的变化。但是效果是一样的。
| 主机名 | ip | |||||||||||
| zk1 | 10.62.2.1 | jdk8 | zookeeper | namenode1 | journalnode1 | resourcemanager1 | Hmaster | |||||
| zk2 | 10.62.2.2 | jdk8 | zookeeper | namenode2 | journalnode2 | resourcemanager2 | Hmaster-back | |||||
| zk3 | 10.62.2.3 | jdk8 | zookeeper | namenode3 | journalnode3 | spark-master | phoenix | |||||
| yt1 | 10.62.3.1 | jdk8 | datanode1 | HRegenServer1 | ||||||||
| yt2 | 10.62.3.2 | jdk8 | datanode2 | HRegenServer2 | ||||||||
| yt3 | 10.62.3.3 | jdk8 | datanode3 | HRegenServer3 | ||||||||
| yt4 | 10.62.3.4 | jdk8 | datanode4 | |||||||||
| yt5 | 10.62.3.5 | jdk8 | datanode5 | spark-work1 | ||||||||
| yt6 | 10.62.3.6 | jdk8 | datanode6 | spark-work2 | ||||||||
| yt7 | 10.62.3.7 | jdk8 | datanode7 | spark-work3 | ||||||||
| yt8 | 10.62.3.8 | jdk8 | datanode8 | spark-work4 | ||||||||
| yt9 | 10.62.3.9 | jdk8 | datanode9 | nodemanager1 | ||||||||
| yt10 | 10.62.3.10 | jdk8 | datanode10 | nodemanager2 |
前期准备:1、配置ip,关闭防火墙或者设置相应的策略,关闭selinux,设置主机之间相互ssh免密,创建用户等,这里不在多说。以下操作全是非root用户
配置ssh免密需要注意一点:如果你的主机之间不是默认的22端口,那么在设置ssh免密的时候需要修改/etc/ssh/ssh_config配置文件
$ vim /etc/ssh/ssh_config
在文件最后添加
Port ssh的端口
比如我的ssh端口是9222
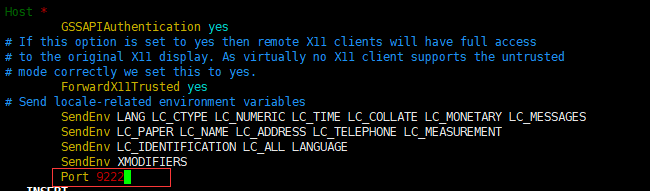
然后重新启动ssh服务
一、zookeeper安装
1、解压zookeeper包到相应的目录,进入到解压的目录
1、解压
$ tar zxvf zookeeper-3.4.13.tar.gz -C /data1/hadoop/hadoop/
$ mv zookeeper-3.4.13/ zookeeper
2、修改环境变量:
在~/.bashrc文件添加
export ZOOK=/data1/hadoop/zookeeper-3.4.13/
export PATH=$PATH:${ZOOK}/bin
$ source ~/.bashrc
3、修改配置文件
$ cd zookeeper/conf
$ cp zoo_sample.cfg zoo.cfg
修改成如下:
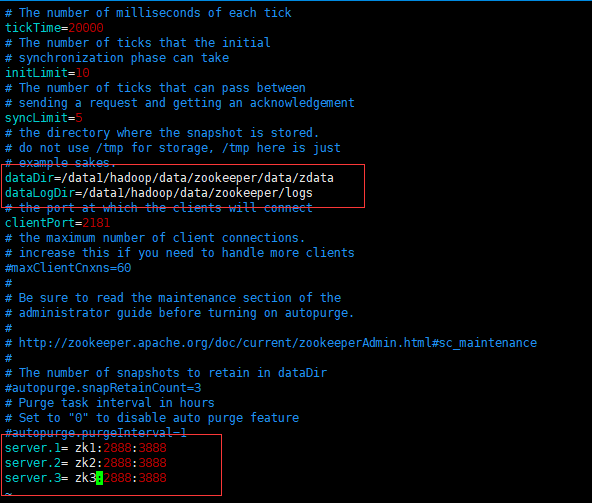
如果要自定义日志文件,仅仅在改配置文件修改并不好使,还得修改./bin/zkEnv.sh 这个文件,修改如下:

4、创建数据目录和日志目录
$ mkdir /data1/hadoop/data/zookeeper/data/zdata -p
$ mkdir /data1/hadoop/data/zookeeper/logs -p
5、创建myid文件
$ echo 1 > /data1/hadoop/data/zookeeper/data/zdata/myid
6、分发到另外的两台机器
$ scp -r zk2:/data1/hadoop/data/zookeeper/ (注意,这里已经做完免密了,不需要再输入密码)
$ scp -r zk3:/data1/hadoop/data/zookeeper/
7、当然,还得去zk2上执行 $ echo 2 > /data1/hadoop/data/zookeeper/data/zdata/myid
去zk3上执行 $ echo 3 > /data1/hadoop/data/zookeeper/data/zdata/myid
8、接下来分别到这三台机器执行
$ zkServer.sh start (我已经添加了环境变量,如果未添加需要到bin目录下执行该脚本文件)
如果不出意外,执行成功是最好的
10、查看状态:zkServer.sh status
如果最后状态是一个leader,两个follower就代表成功。
11、启动失败原因(有可能全部没有启动成功,有可能启动其中一个或者两个)
(1)、防火墙没有停掉或者策略配置有问题
(2)、配置文件错误,尤其是myid文件
(3)、selinux没设置成disabled或者permissive
(4)、端口被占用
(5)、启动以后监听的是ipv6地址,如下:(这是最坑的,我在这里卡了好久)

正常情况下应该是tcp不是tcp6
解决办法就是关闭ipv6,然后重新启动zookeeper。
2、配置jdk,解压然后配置~/.source文件就可以,不在多说
3、hadoop(HA)(zk1机器操作)
1、解压
$ tar zxvf hadoop-3.1.1.tar.gz -C /data1/hadoop/
$ mv hadoop-3.1.1 hadoop
$ cd /data1/hadoop/hadoop/etc/hadoop/
2、配置环境变量~/.source
export HADOOP_HOME=/data1/hadoop/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
3、配置hadoop-env.sh,添加Java环境变量,文件最后添加:
export JAVA_HOME=/usr/local/jdk/
4、配置core-site.xml,如下:(具体配置还得根据自己实际情况,这里可以做一个参考)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://TEST</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp/</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
5、配置hdfs-site.xml,如下:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>TEST</value>
</property>
<property>
<name>dfs.ha.namenodes.TEST</name>
<value>nna,nns,nnj</value>
</property>
<property>
<name>dfs.namenode.rpc-address.TEST.nna</name>
<value>zk1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.TEST.nns</name>
<value>zk2:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.TEST.nnj</name>
<value>zk3:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.TEST.nna</name>
<value>zk1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.TEST.nns</name>
<value>zk2:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.TEST.nnj</name>
<value>zk3:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://zk1:8485;zk2:8485;zk3:8485/TEST</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.TEST</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hduser/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data1/hadoop/data/tmp/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data1/hadoop/data/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data2/hadoop/data/dn,/data3/hadoop/data/dn,/data4/hadoop/data/dn,/data5/hadoop/data/dn,/data6/hadoop/data/dn,/data7/hadoop/data/dn,/data8/hadoop/data/dn,/data9/hadoop/data/dn,/data10/hadoop/data/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
</configuration>
6、配置 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>zk1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>zk2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value> <!-- 这个值需要注意,分发到另外一台resourcemanager时,也就是resourcemanager备节点时需要修改成rm2(也许你那里不是) -->
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>GD-yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- 如下标红的在拷贝到另外一台resourcemanager时,需要修改成对应的主机名-->
<roperty>
<name>yarn.resourcemanager.address.rm1</name>
<value>zk1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>zk1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>zk1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>zk1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>zk1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>zk1:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data1/hadoop/data/nm</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data1/hadoop/log/yarn</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
<property>
<!-- 以下资源情况请根据自己环境做调整 -->
<name>yarn.nodemanager.vcores-pcores-ratio</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>20</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>196608</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>196608</value>
</property>
</configuration>
7、配置mapred-site.xml,如下:资源情况根据自己环境做调整
<configuration>
<property>
<name>mapreduce.map.memory.mb</name>
<value>5120</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx4096M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>10240</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx8196M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.tasktracker.http.threads</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>100</value>
</property>
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>zk1:11211</value>
</property>
<property>
<name>mapreduce.job.queuename</name>
<value>hadoop</value>
</property>
8、配置capacity-scheduler.xml(自己测试可以不用配置),如下:
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hadoop,orc</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>0</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hadoop.capacity</name>
<value>65</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.orc.capacity</name>
<value>35</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hadoop.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.orc.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.orc.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hadoop.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>default</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hadoop.acl_submit_applications</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hadoop.acl_administer_queue</name>
<value>hadoop</value>
</property>
</configuration>
9、配置workers文件(注意:这是配置datanode节点的文件,以前是slaves,现在3.x变成了workers文件)
10、分发到所有的其他机器(注:整个集群所有机器),具体情况具体分发
$ scp -r /data1/hadoop/hadoop 其他所有机器:/data1/hadoop
10、格式化与启动
(1)、格式化zookeeper(zk1上格式化)
$ hdfs zkfc -formatZK
(2)、在zk这三台机器启动journalnode
$ hadoop-daemon.sh start journalnode
(3)、格式化namenode(zk1上格式化)
$ hdfs namenode -format
(4)、启动namenode(zk1执行)
$ hadoop-daemon.sh start namenode
(5)、在zk2、zk3两台机器分别执行:
$ hdfs namenode -bootstrapStandby
(6)、启动hdfs,执行命令 start-dfs.sh 因为我这里yt*这些机器都需要启动datanode,所以workers文件如下:
yt1
yt2
yt3
yt4
yt5
yt6
yt7
yt8
yt9
yt10
(7)、启动yarn,执行命令 start-yarn.sh ,因为我只启动了最后两条,所以workers文件修改如下(只需要修改zk1就行,毕竟这是主节点)
yjt9
yjt10
(8)、查看集群状态
$ hdfs haadmin -getAllServiceState (hdfs)
zk1:9000 active
zk2:9000 standby
zk3:9000 standby
$ yarn rmadmin -getAllServiceState (yarn)
zk1:8033 active
zk2:8033 standby
(9)、测试
kill掉活动的节点,看是否自动转移。(这里就不测试了)
4、hbase (HA)(zk2机器操作)
1、解压
tar zxvf hbase-1.4.8-bin.tar.gz -C /data1/hadoop/
2、配置hbase-env.sh,添加环境变量如下:
export HADOOP_HOME=/data1/hadoop/hadoop
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=false <!--不使用自带的zookeeper -->
3、配置hbase-site.xml,如下:(这里只是最简单的配置,不适合生成环境)
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://TEST/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/data1/hadoop/data/hbase/tmp/</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data1/hadoop/data/zookeeper/data/</value>
</property>
</configuration>
或者:(生成环境)
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/data2/hadoop/data/hbase/tmp/</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://TEST/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data2/hadoop/data/zookeeper/data/</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>10000</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
<property>
<name>data.tx.timeout</name>
<value>1800</value>
</property>
<property>
<name>ipc.socket.timeout</name>
<value>18000000</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>60</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>300000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>1800000</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>1800000</value>
</property>
<property>
<name>hbase.client.operation.timeout</name>
<value>1800000</value>
</property>
<property>
<name>hbase.lease.recovery.timeout</name>
<value>3600000</value>
</property>
<property>
<name>hbase.lease.recovery.dfs.timeout</name>
<value>1800000</value>
</property>
<property>
<name>hbase.client.scanner.caching</name>
<value>1000</value>
</property>
<property>
<name>hbase.htable.threads.max</name>
<value>5000</value>
</property>
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>1800000</value>
</property>
<property>
<name>phoenix.rpc.timeout</name>
<value>1800000</value>
</property>
<property>
<name>phoenix.coprocessor.maxServerCacheTimeToLiveMs</name>
<value>1800000</value>
</property>
<property>
<name>phoenix.query.keepAliveMs</name>
<value>120000</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
</configuration>
4、拷贝hadoop的hdfs-site.xml和core-site.xml文件到hbase的conf目录下,或者做软连接也可以
$ cat /data1/hadoop/hadoop/etc/hadoop/hdfs-site.xml . (点代表当前目录,因为我当前目录就是hbase的conf目录下)
$ cat /data1/hadoop/hadoop/etc/hadoop/core-site.xml .
或者
$ ln -s /data1/hadoop/hadoop/etc/hadoop/hdfs-site.xml hdfs-site.xml
$ ln -s /data1/hadoop/hadoop/etc/hadoop/core-site.xml core-site.xml
5、配置regionservers,文件内容如下
yt1
yt2
yt3
6、配置backup-masters(改文件需要自己创建,指定备Hmaster的节点),内容如下:
zk3
7、分发到其他节点
8、启动hbase(zk2执行命令就行)
$ start-hbase.sh
9、测试:命令行输入 hbase shell进入到hbase,执行list命令,如果不报错就成功,如下:
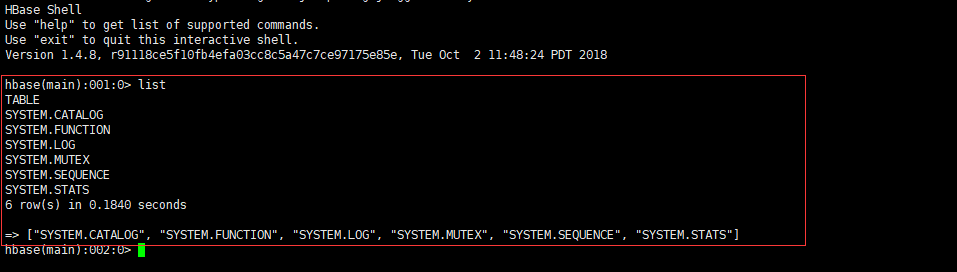
5、phoenix安装
1、解压
$ tar zxvf apache-phoenix-4.14.0-HBase-1.4-bin.tar.gz -C /data1/hadoop
2、把hbase配置文件hbase-site.xml拷贝到Phoenix的bin目录
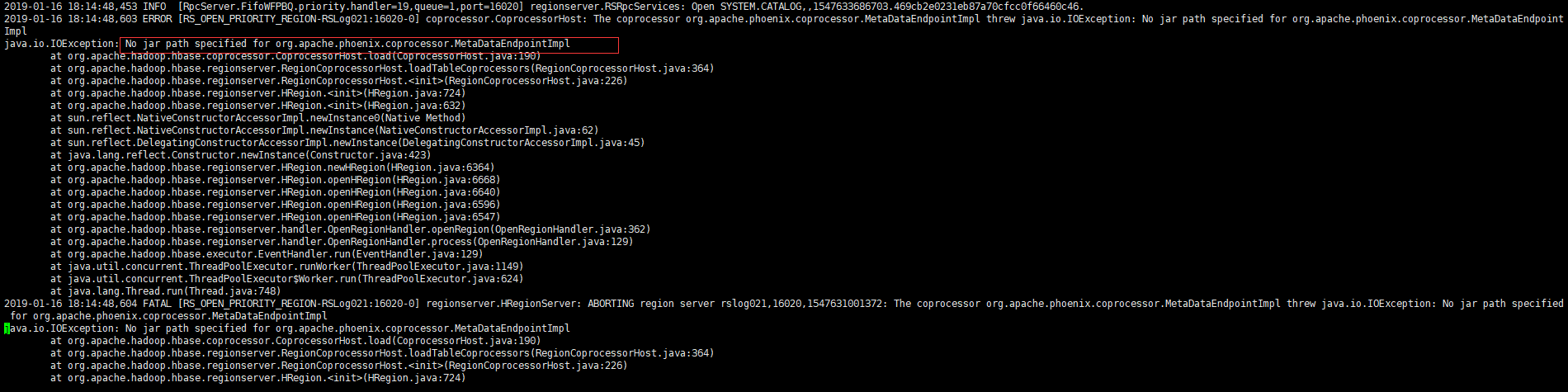
3、把Phoenix下的phoenix-core-4.14.0-HBase-1.4.jar 和phoenix-4.14.0-HBase-1.4-server.jar这两个包拷贝到hbase的lib目录下(主从节点都需要),最好把
phoenix-4.14.0-HBase-1.4-server.jar这个包拷贝到整个hbase集群(包括regisonserver服务端),否则在通过phoenix连接hbase的时候,导致regisonserver挂掉,挂掉时的信息如下:
4、测试
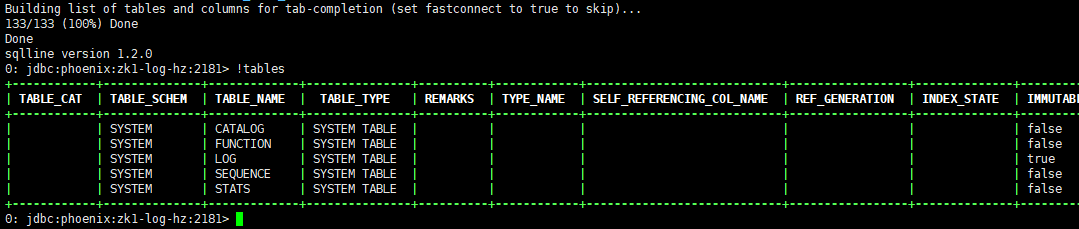
$ ./bin/sqlline.py zk1,zk2,zk3:2181 指定zookeeper集群节点
连接成功以后输入!tables查看(注意命令前面有感叹号)
6、配置spark(HA)
1、解压
$ tar zxvf spark-2.1.0-bin-hadoop2.7.tgz -C /data1/hadoop
2、配置~/.source环境变量
export SPARK_HOME=/data1/hadoop/spark
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
3、配置spark-env.sh,文件最后添加如下:
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/data1/hadoop/hadoop export HADOOP_CONF_DIR=/data1/hadoop/hadoop/etc/hadoop export SPARK_LOCAL_DIRS=/data1/hadoop/data/spark/local,/data1/hadoop/data/spark/local export SPARK_WORKER_CORES=20 export SPARK_WORKER_MEMORY=100g export SPARK_MASTER_WEBUI_PORT=8090 export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true" export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1:2181,zk2:2181,zk3:2181 -Dspark.deploy.zookeeper.dir=/spark"
4、配置slaves(指定worker节点),文件内容如下:
yjt5 yjt6 yjt7 yjt8
5、配置spark-defaults.conf文件
spark.master spark://zk2:7077,zk3:7077 -----指定spark master的地址 spark.submit.deployMode client -----指定spark任务提交时的模式。有standalone模式,yarn(client、cluster)、mesos spark.eventLog.enabled true -----是否开启事件日志 spark.eventLog.compress true -----日志是否压缩 spark.eventLog.dir hdfs://ns1/spark/eventLog ----指定路径,放在master节点的hdfs中,端口要跟hdfs设置的端口一致(默认为8020),否则会报错,并且在启动spark集群的时候,需要首先创建该目录,否则启动失败 spark.serializer org.apache.spark.serializer.KryoSerializer spark.io.compression.codec snappy spark.shuffle.consolidateFiles true spark.history.fs.logDirectory hdfs://ns1/spark/historyLog ---历史日志 spark.rpc.netty.dispatcher.numThreads 2 spark.driver.memory 10g ---driver内存 spark.driver.cores 2 ---driver使用cpu core spark.executor.memory 4g ---driver使用内存
5、分发到其他节点
6、启动spark (zk3机器执行命令)
$ ./sbin/start-all.sh (这里只会启动一个master和其他的工作节点)
启动另外一个master
$ star-master.sh
7、配置过程中的一些错误
错误(1):
2018-12-19 13:20:41,444 INFO org.apache.hadoop.security.authentication.server.AuthenticationFilter: Unable to initialize FileSignerSecretProvider, falling back to use random secrets.
2018-12-19 13:20:41,446 INFO org.apache.hadoop.http.HttpRequestLog: Http request log for http.requests.datanode is not defined
2018-12-19 13:20:41,450 INFO org.apache.hadoop.http.HttpServer2: Added global filter 'safety' (class=org.apache.hadoop.http.HttpServer2$QuotingInputFilter)
2018-12-19 13:20:41,452 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context datanode
2018-12-19 13:20:41,452 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
2018-12-19 13:20:41,452 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
2018-12-19 13:20:41,471 INFO org.apache.hadoop.http.HttpServer2: HttpServer.start() threw a non Bind IOException
java.net.BindException: Port in use: localhost:0
。。。。。。。
解决:在/etc/hosts文件添加如下两行(我在配置这个文件的时候删除了这两行,没想到居然报错了):
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
错误(2):
-ls: java.net.UnknownHostException: TEST
[hduser@ai2-log-hz logs]$ hadoop fs -ls /
2018-12-19 15:31:17,553 INFO ipc.Client: Retrying connect to server: TEST/125.211.213.133:8020. Already tried 0 time(s); maxRetries=45
2018-12-19 15:31:37,575 INFO ipc.Client: Retrying connect to server: TEST/125.211.213.133:8020. Already tried 1 time(s); maxRetries=45
我连这个ip是什么鬼都不知道,居然报这个错:
解决:在hdfs-site.xml文件添加下面这个配置,如果原本就有,还是报这个错,那说明这个配置你应该是配置错了;注意下面标红的地方,我最开始就配置失误了,这个该是你hdfs集群的名字
<property>
<name>dfs.client.failover.proxy.provider.TEST</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
错误(3):
当hdfs或者yarn集群的active节点挂掉以后,活动不能自动转移:
解决:
(1)查看系统是否有fuser命令,如果没有请执行下面这个命令安装:
$ sudo yum install -y psmisc
(2) 修改hdfs-site.xml配置文件,添加标红的配置,一般来说配置这个文件都没有配置这个值,当然,我前面配置hdfs-site.xml已经配置好了
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
注意:如果是root用户 操作,启动进程会报错,如下:
[root@master hadoop]# start-dfs.sh Starting namenodes on [master slave1] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting journal nodes [slave2 slave1 master] ERROR: Attempting to operate on hdfs journalnode as root ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. Starting ZK Failover Controllers on NN hosts [master slave1] ERROR: Attempting to operate on hdfs zkfc as root ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
启动yarn进程也同样会报错
解决:在start-dfs.sh,stop-dfs.sh 开始位置增加如下配置:
# 注意等号前后不要有空格 HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root
同样,在yarn的start-yarn.sh,stop-yarn.sh开始位置添加:
# 注意等号前后不要有空格 YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root
现在去启动就不会报错了。
ok!!!
一篇hadoop完全分布式搭建博客:https://blog.csdn.net/afgasdg/article/details/79277926#3-hdfs-%E5%90%AF%E5%8A%A8%E6%8A%A5%E9%94%99

