

CCNet: Criss-Cross Attention for Semantic Segmentation 里的Criss-Cross Attention计算方法
论文地址:https://arxiv.org/pdf/1811.11721v1.pdf code address: https://github.com/speedinghzl/CCNet
相关论文:https://arxiv.org/pdf/1904.09229.pdf 《XLSor: A Robust and Accurate Lung Segmentor on ChestX-Rays Using Criss-Cross Attention and CustomizedRadiorealistic Abnormalities Generation》
扩展论文:https://github.com/NVlabs/MUNIT https://arxiv.org/abs/1804.04732 《Multimodal Unsupervised Image-to-Image Translation》
看第二个论文时,使用了论文一作为分割网路,论文三作为数据增强的手段。其实论文三是 style transform, pixel2pixel 最新工作,以后再看。
论文二中使用了CCNet这个新的网络结构,为了搞清楚CCA到底是怎么计算的,只能肯原始论文一:
 这就是CCA的计算方式
这就是CCA的计算方式
H是一个 C通道 宽高 W,H的特征图
从出发有四条路径,最上边的是 残差结构 或者叫shortcut path(高速通道) 目的地是和Aggregation相加 那么这里 Aggregrateion就必须和H通样的形状 C*H*W
残差结构就是公式(2)。 那个求和就是 符号部分就是Aggregation做的

要理解Aggregation就要看从H 分出的下三路
最下边一路V没什么好看的 直接对 H做1*1的卷积,输出还是 和H相同的形状 C*H*W
Q,K也是1*1卷积 只不过 通道数量是: C' < C 。
Q和K都是 C'*H*W 大小的特征图
下边就是高能的Affinity, 可以看到affinity后softmax得到A ,而A的结构是 (W+H-1)*W*H
A有 W+H-1个通道,所以Affinit后的结构也是 (W+H-1)*W*H
因为 A 和 Q K 的宽度和高度相同。每个位置u,u可以认为是二维特征图w,h上的一个像素。
由于CNN的对称性。只需要关注某一个位置u的计算方式即可。
这时候我们拿Q 上的一个位置 u ,我们知道在u这个位置看下去 是一个 C' 维度的向量。 记作Qu 维度 C‘
这时候要A中对应u的地方应该是由 Qu 和 K作用而来 ,由于A对应的维度是 (W+H-1)维
W+H-1 刚好是位置u 所在 行数+列数 方向的像元总数,自己算了两次减去一次。 就是下图中十字的形状。这个十字形状
就是H+W-1
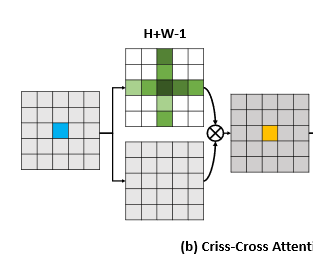
那么从向量 Qu 和 K中的 H+W-1个向量 需要得到一个 (H+w-1)的向量
因为 Qu 和 K中的向量维度相同 我们把K中的H+W-1个向量 编号为 Ku1 ku2, ku(h+w-1)
那么 Au= ((Qu* Ku1 , Qu*Ku2, Qu*Ku3, Qu*Ku4, ... ,... Qu*Ku(h+w-1)) 就是这样 Qu*Kui 表示 Qu和Kui的内积
其实这样算完之后还在通道方向做了个softmax。
这样就算把A算完了
A最终得到的形状是 (H+W-1)*H*W 每个通道表示attention 因为经过softmax了,就是概率了。
接下来就是A和V的结合 Aggregation ,就是公式2的 求和部分
V的通道数是 C
那么这个和上边的操作有点像,这次只不过从内积变成了 线性组合
这里方便起见以A为中心,
对应于位置u
从A看下去是 H+W-1维的向量
V中对应位置 u,同样找到过他的横竖两条线段,同样是个十字形状有 H+W-1个向量 每个向量是 C维
这时候 用A中的 向量作为系数, 作用到 V中的H+W-1个向量 加起来,就是线性组合啊。 得到一个 C维的向量,这个向量是V中十字领域向量的线性组合
这样Aggreation就是2是中的 求和一项做的完成 Aggreation。
以上就是CCA, 作者还证明了 两个CCA就能够获取全局视野。不看了我。
效果很好,取得很好的结果。
CNN发明以来,各种矩阵操作。
问题是Aggregation部分不就是个卷积吗,十字形状的卷积。
通常的卷积是同位置不同通道的卷积的参数不同。
这个整的是不同位置的卷积核不同,但是在通道上相同。
汗啊,CNN快要被玩坏了。

