Reactor 3 学习笔记(2)

接上篇继续学习各种方法:
4.9、reduce/reduceWith
@Test
public void reduceTest() {
Flux.range(1, 10).reduce((x, y) -> x + y).subscribe(System.out::println);
Flux.range(1, 10).reduceWith(() -> 10, (x, y) -> x + y).subscribe(System.out::println);
}
输出:
55 65
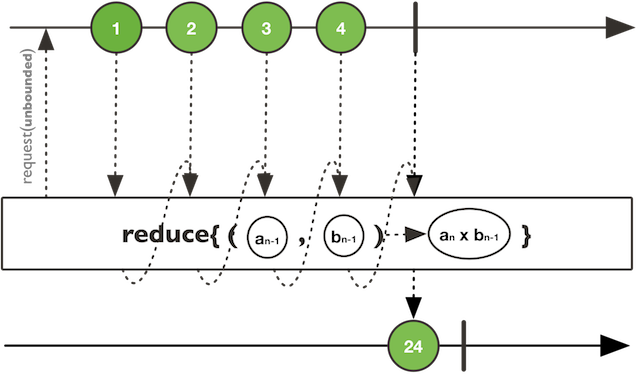
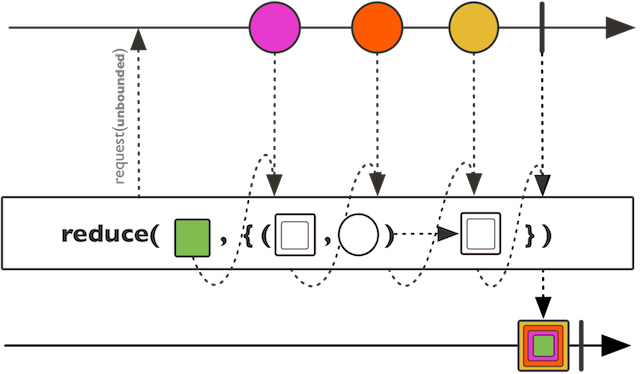
上面的代码,reduce相当于把1到10累加求和,reduceWith则是先指定一个起始值,然后在这个起始值基础上再累加。(tips: 除了累加,还可以做阶乘)
reduce示意图:
reduceWith示意图:
4.10、merge/mergeSequential/contact
@Test
public void mergeTest() {
Flux.merge(Flux.interval(Duration.of(500, ChronoUnit.MILLIS)).take(5),
Flux.interval(Duration.of(600, ChronoUnit.MILLIS), Duration.of(500, ChronoUnit.MILLIS)).take(5))
.toStream().forEach(System.out::println);
System.out.println("-----------------------------");
Flux.mergeSequential(Flux.interval(Duration.of(500, ChronoUnit.MILLIS)).take(5),
Flux.interval(Duration.of(600, ChronoUnit.MILLIS), Duration.of(500, ChronoUnit.MILLIS)).take(5))
.toStream().forEach(System.out::println);
}
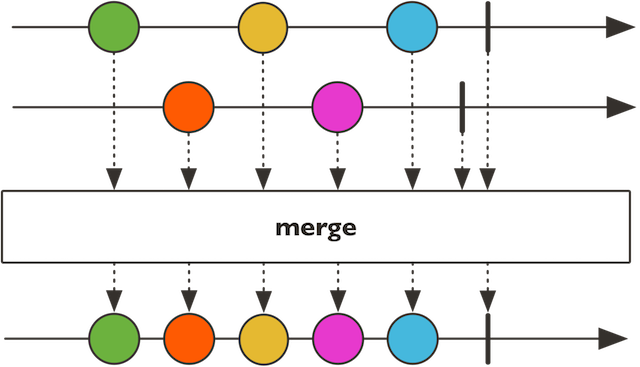
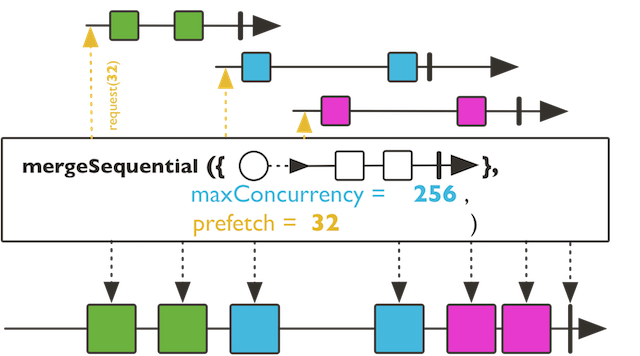
merge就是将把多个Flux"按元素实际产生的顺序"合并,而mergeSequential则是按多个Flux"被订阅的顺序"来合并,以上面的代码来说,二个Flux,从时间上看,元素是交替产生的,所以merge的输出结果,是混在一起的,而mergeSequential则是能分出Flux整体的先后顺序。
0 0 1 1 2 2 3 3 4 4 ----------------------------- 0 1 2 3 4 0 1 2 3 4
merge示意图:
mergeSequential示意图:
与mergeSequential类似的,还有一个contact方法,示意图如下:
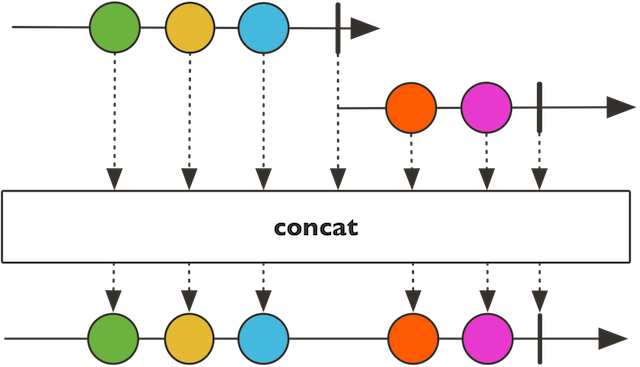
4.11、combineLatest
@Test
public void combineLatestTest() {
Flux.combineLatest(
Arrays::toString,
Flux.interval(Duration.of(10000, ChronoUnit.MILLIS)).take(3),
Flux.just("A", "B"))
.toStream().forEach(System.out::println);
System.out.println("------------------");
Flux.combineLatest(
Arrays::toString,
Flux.just(0, 1),
Flux.just("A", "B"))
.toStream().forEach(System.out::println);
System.out.println("------------------");
Flux.combineLatest(
Arrays::toString,
Flux.interval(Duration.of(1000, ChronoUnit.MILLIS)).take(2),
Flux.interval(Duration.of(10000, ChronoUnit.MILLIS)).take(2))
.toStream().forEach(System.out::println);
}
该操作会将所有流中的最新产生的元素合并成一个新的元素,作为返回结果流中的元素。只要其中任何一个流中产生了新的元素,合并操作就会被执行一次。
分析一下第一段输出:
第1个Flux用了延时生成,第1个数字0,10秒后才产生,这时第2个Flux中的A,B早就生成完毕,所以此时二个Flux中最新生在的元素,就是[0,B],类似的,10秒后,第2个数字1依次产生,再执行1次合并,生成[1,B]...
输出:
[0, B] [1, B] [2, B] ------------------ [1, A] [1, B] ------------------ [1, 0] [1, 1]
示意图如下:
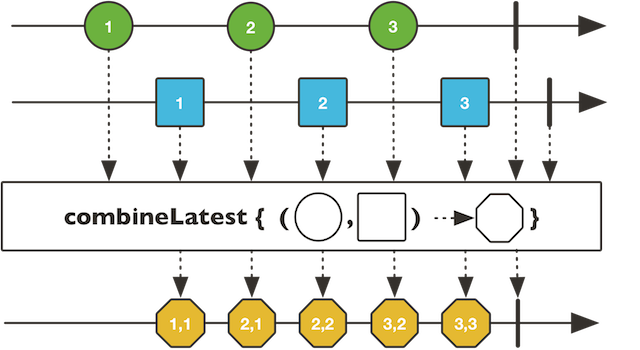
4.12、first
@Test
public void firstTest() {
Flux.first(Flux.fromArray(new String[]{"A", "B"}),
Flux.just(1, 2, 3))
.subscribe(System.out::println);
}
这个很简单理解,多个Flux,只取第1个Flux的元素。输出如下:
A B
示意图:
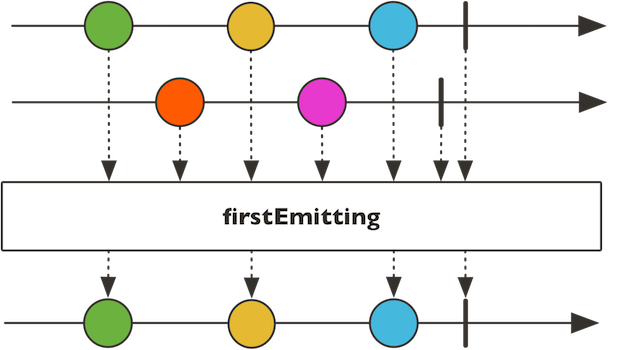
4.13、 map
@Test
public void mapTest() {
Flux.just('A', 'B', 'C').map(a -> (int) (a)).subscribe(System.out::println);
}
map相当于把一种类型的元素序列,转换成另一种类型,输出如下:
65 66 67
示意图:

五、消息处理
写代码时,难免会遇到各种异常或错误,所谓消息处理,就是指如何处理这些异常。
5.1 订阅错误消息
@Test
public void subscribeTest1() {
Flux.just("A", "B", "C")
.concatWith(Flux.error(new IndexOutOfBoundsException("下标越界啦!")))
.subscribe(System.out::println, System.err::println);
}
注意:这里subscribe第2个参数,指定了System.err::println ,即错误消息,输出到异常控制台上。
输出效果:

示意图:
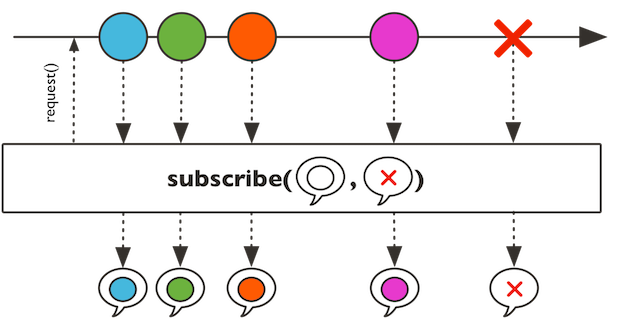
5.2 onErrorReturn
即:遇到错误时,用其它指定值返回
@Test
public void subscribeTest2() {
Flux.just("A", "B", "C")
.concatWith(Flux.error(new IndexOutOfBoundsException("下标越界啦!")))
.onErrorReturn("X")
.subscribe(System.out::println, System.err::println);
}
输出:
A B C X
示意图:

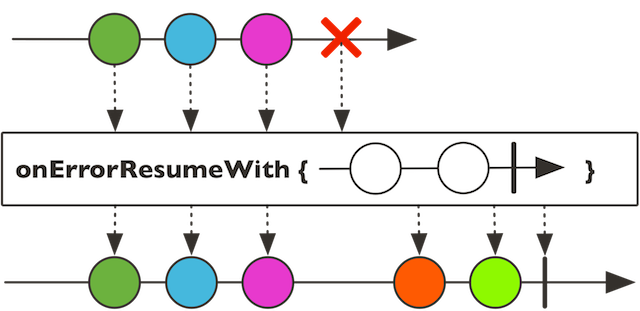
5.3 onErrorResume
跟onErrorReturn有点接近,但更灵活,可以根据异常的类型,有选择性的处理返回值。
@Test
public void subscribeTest3() {
Flux.just("A", "B", "C")
.concatWith(Flux.error(new IndexOutOfBoundsException("下标越界啦!")))
.onErrorResume(e -> {
if (e instanceof IndexOutOfBoundsException) {
return Flux.just("X", "Y", "Z");
} else {
return Mono.empty();
}
})
.subscribe(System.out::println, System.err::println);
}
输出:
A B C X Y Z
示意图:
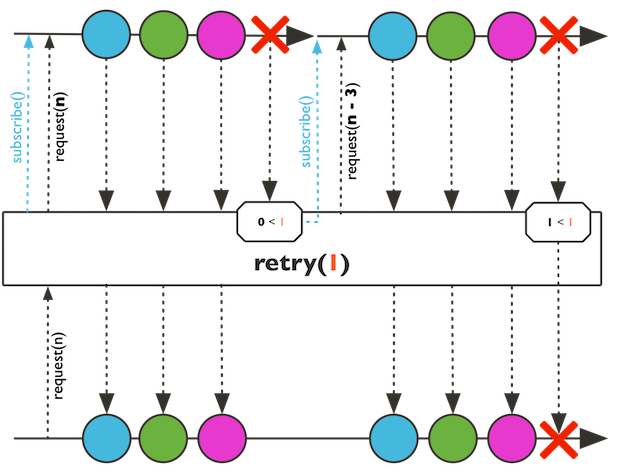
5.4 retry
即:遇到异常,就重试。
@Test
public void subscribeTest4() {
Flux.just("A", "B", "C")
.concatWith(Flux.error(new IndexOutOfBoundsException("下标越界啦!")))
.retry(1)
.subscribe(System.out::println, System.err::println);
}
输出:
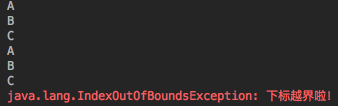
示意图:
六、(线程)调度器
reactor中到处充满了异步调用,内部必然有一堆线程调度,Schedulers提供了如下几种调用策略:
6.1 Schedulers.immediate() - 使用当前线程
6.2 Schedulers.elastic() - 使用线程池
6.3 Schedulers.newElastic("test1") - 使用(新)线程池(可以指定名称,更方便调试)
6.4 Schedulers.single() - 单个线程
6.5 Schedulers.newSingle("test2") - (新)单个线程(可以指定名称,更方便调试)
6.6 Schedulers.parallel() - 使用并行处理的线程池(取决于CPU核数)
6.7 Schedulers.newParallel("test3") - 使用并行处理的线程池(取决于CPU核数,可以指定名称,方便调试)
6.8 Schedulers.fromExecutorService(Executors.newScheduledThreadPool(5)) - 使用Executor(这个最灵活)
示例代码:
@Test
public void schedulesTest() {
Flux.fromArray(new String[]{"A", "B", "C", "D"})
.publishOn(Schedulers.newSingle("TEST-SINGLE", true))
.map(x -> String.format("[%s]: %s", Thread.currentThread().getName(), x))
.toStream()
.forEach(System.out::println);
}
输出:
[TEST-SINGLE-1]: A [TEST-SINGLE-1]: B [TEST-SINGLE-1]: C [TEST-SINGLE-1]: D
七、测试&调试
异步处理,通常是比较难测试的,reactor提供了StepVerifier工具来进行测试。
7.1 常规单元测试
@Test
public void stepTest() {
StepVerifier.create(Flux.just(1, 2)
.concatWith(Mono.error(new IndexOutOfBoundsException("test")))
.onErrorReturn(3))
.expectNext(1)
.expectNext(2)
.expectNext(3)
.verifyComplete();
}
上面的示例,Flux先生成1,2这两个元素,然后抛了个错误,但马上用onErrorReturn处理了异常,所以最终应该是期待1,2,3,complete这样的序列。
7.2 模拟时间流逝
Flux.interval这类延时操作,如果延时较大,比如几个小时之类的,要真实模拟的话,效率很低,StepVerifier提供了withVirtualTime方法,来模拟加快时间的流逝(是不是很体贴^_^)
@Test
public void stepTest2() {
StepVerifier.withVirtualTime(() -> Flux.interval(Duration.of(10, ChronoUnit.MINUTES),
Duration.of(5, ChronoUnit.SECONDS))
.take(2))
.expectSubscription()
.expectNoEvent(Duration.of(10, ChronoUnit.MINUTES))
.thenAwait(Duration.of(5, ChronoUnit.SECONDS))
.expectNext(0L)
.thenAwait(Duration.of(5, ChronoUnit.SECONDS))
.expectNext(1L)
.verifyComplete();
}
上面这个Flux先停10分钟,然后每隔5秒生成一个数字,然后取前2个数字。代码先调用
expectSubscription 期待流被订阅,然后 expectNoEvent(Duration.of(10, ChronoUnit.MINUTES)) 期望10分钟内,无任何事件(即:验证Flux先暂停10分钟),然后 thenAwait(Duration.of(5, ChronoUnit.SECONDS)) 等5秒钟,这时已经生成了数字0 expectNext(0L) 期待0L ... 后面的大家自行理解吧。
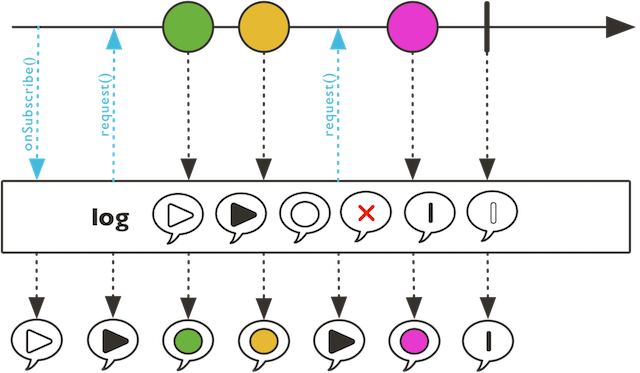
7.3 记录日志
@Test
public void publisherTest() {
Flux.just(1, 0)
.map(c -> 1 / c)
.log("MY-TEST")
.subscribe(System.out::println);
}
输出:
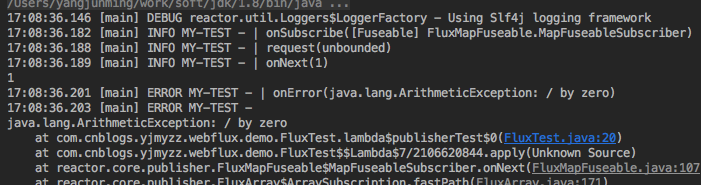
示意图:
7.4 checkpoint检查点
可以在一些怀疑的地方,加上checkpoint检查,参考下面的代码:
@Test
public void publisherTest() {
Flux.just(1, 0)
.map(c -> 1 / c)
.checkpoint("AAA")
.subscribe(System.out::println);
}
输出:

出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号