

pandas速成笔记(3)-join/groupby/sort/行列转换
接上篇继续 ,这回看下一些常用的操作:
一、join 联表查询
有数据库开发经验的同学,一定对sql中的join ... on 联表查询不陌生,pandas也有类似操作
假设test.xlsx的sheet1, sheet2中分别有下面的数据(相当于2张表)
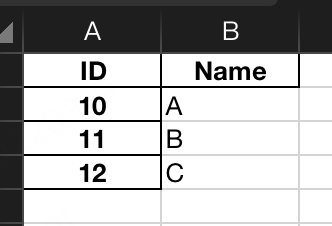
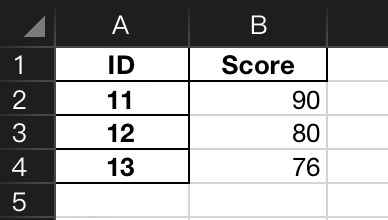
现在要以ID做为作为Key,将二张表join起来,可以这样写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import pandas as pdpd1 = pd.read_excel("./data/test.xlsx", sheet_name="sheet1", index_col="ID")pd2 = pd.read_excel("./data/test.xlsx", sheet_name="sheet2", index_col="ID")print("-----pd1--------")print(pd1)print("\n-----pd2--------")print(pd2)print("\n------default-------")pd3 = pd1.join(pd2)print(pd3)print("\n------left-------")pd3 = pd1.join(pd2, how="left")print(pd3)print("\n------right-------")pd3 = pd1.join(pd2, how="right")print(pd3)print("\n------inner-------")pd3 = pd1.join(pd2, how="inner")print(pd3)print("\n------outer-------")pd3 = pd1.join(pd2, how="outer")print(pd3) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | -----pd1-------- NameID 10 A11 B12 C-----pd2-------- ScoreID 11 9012 8013 76------default------- Name ScoreID 10 A NaN11 B 90.012 C 80.0------left------- Name ScoreID 10 A NaN11 B 90.012 C 80.0------right------- Name ScoreID 11 B 9012 C 8013 NaN 76------inner------- Name ScoreID 11 B 9012 C 80------outer------- Name ScoreID 10 A NaN11 B 90.012 C 80.013 NaN 76.0 |
是不是跟sql几乎一模一样?如果2个表格中的Key,名称不一样,比如第2个表格长这样,第1列不叫ID,而是stutent_id
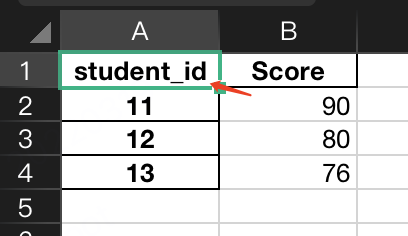
也不影响,只要在读取时设置了索引即可,默认join时就是用index列做为key关联
二、groupby分组统计
假设有一张表:
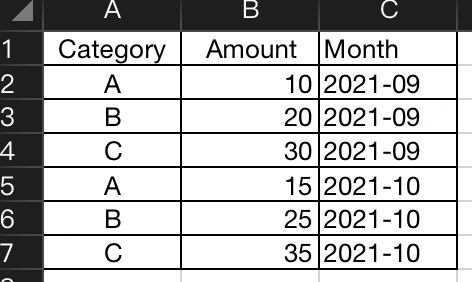
想按月汇总下Amount的总和,直接使用groupby("Month")
1 2 3 4 5 6 7 | import pandas as pddf = pd.read_excel("./data/test.xlsx")print(df)print("------------")df_month = df.groupby("Month").sum()print(df_month) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 | Category Amount Month0 A 10 2021-091 B 20 2021-092 C 30 2021-093 A 15 2021-104 B 25 2021-105 C 35 2021-10------------ AmountMonth 2021-09 602021-10 75 |
来个更复杂的,希望按Category看看,在本月当中该Category的Amount占"当月Amount总和"的占比,比如2021-09月,Amount总和为60,而9月之中,C类的Amount=30,即9月C类的Amount占9月总Amount的50%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | import pandas as pddf = pd.read_excel("./data/test.xlsx")print(df)print("------------")df_month = df.groupby("Month").sum()print(df_month)print("------------")# 插入2列df.insert(2, 'MonthTotal', 0)df.insert(3, 'MonthPercent', 0.0)# 计算每个月,各Category的Amount占比for idx2, data2 in df_month.iterrows(): for idx, data in df.iterrows(): if idx2 == data["Month"]: data["MonthTotal"] = data2["Amount"] data["MonthPercent"] = data["Amount"] / data2["Amount"] df.iloc[idx] = pd.Series(data)df["MonthPercent"] = df["MonthPercent"].apply(lambda x: format(x, '.2%'))print(df) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | Category Amount Month0 A 10 2021-091 B 20 2021-092 C 30 2021-093 A 15 2021-104 B 25 2021-105 C 35 2021-10------------ AmountMonth 2021-09 602021-10 75------------ Category Amount MonthTotal MonthPercent Month0 A 10 60 16.67% 2021-091 B 20 60 33.33% 2021-092 C 30 60 50.00% 2021-093 A 15 75 20.00% 2021-104 B 25 75 33.33% 2021-105 C 35 75 46.67% 2021-10 |
除了分组求和,当然还能求平均值,以及分组计算count
1 2 3 4 5 6 7 8 9 10 11 12 | import pandas as pddf = pd.read_excel("./data/test.xlsx")print(df)print("------------")category_amount_avg = df.groupby("Category").mean()print(category_amount_avg)print("------------")category_count = df.groupby("Month").count()print(category_count) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | Category Amount Month0 A 10 2021-091 B 20 2021-092 C 30 2021-093 A 15 2021-104 B 25 2021-105 C 35 2021-10------------ AmountCategory A 12.5B 22.5C 32.5------------ Category AmountMonth 2021-09 3 32021-10 3 3 |
三、sort排序
还是这张表,如果希望按Amount降序排列,可以这样:
1 2 3 4 5 6 7 8 9 | import pandas as pddf = pd.read_excel("./data/test.xlsx")print("-----before sort------")print(df)print("-----after sort------")df.sort_values("Amount", inplace=True, ascending=False)print(df) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | -----before sort------ Category Amount Month0 A 10 2021-091 B 20 2021-092 C 30 2021-093 A 15 2021-104 B 25 2021-105 C 35 2021-10-----after sort------ Category Amount Month5 C 35 2021-102 C 30 2021-094 B 25 2021-101 B 20 2021-093 A 15 2021-100 A 10 2021-09 |
如果需要多个字段排序 ,比如:先按Month升序,再按Amount降序
1 2 3 | print("-----after sort------")df.sort_values(by=["Month", "Amount"], ascending=[True, False], inplace=True)print(df) |
输出:
1 2 3 4 5 6 7 8 | -----after sort------ Category Amount Month2 C 30 2021-091 B 20 2021-090 A 10 2021-095 C 35 2021-104 B 25 2021-103 A 15 2021-10 |
四、行列转换
pandas有一个内置的transpose()方法,可以直接实现:
1 2 3 4 5 6 7 | import pandas as pddf = pd.read_excel("./data/test.xlsx", index_col="Category")print("------行转列(前)----------")print(df)print("------行转列(后)----------")print(df.transpose()) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 | ------行转列(前)---------- Amount MonthCategory A 10 2021-09B 20 2021-09C 30 2021-09A 15 2021-10B 25 2021-10C 35 2021-10------行转列(后)----------Category A B C A B CAmount 10 20 30 15 25 35Month 2021-09 2021-09 2021-09 2021-10 2021-10 2021-10 |
不过这个转换功能有点简单,如果要实现一些个性化的行列转换,比如希望达到下面的效果:
1 2 3 4 5 | 2021-09 2021-10Category A 10 15B 20 25C 30 35 |
就得自己写代码了,参考下面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import pandas as pdimport matplotlib.pyplot as pltdf = pd.read_excel("./data/test.xlsx")print("-------before-------")df.set_index("Month", inplace=True)print(df)print("-------after-------")# 先对Month求distinctmonths = df.index.unique()rows = []for month in months: # 遍历df for idx, data in df.iterrows(): if idx == month: # 生成新DataFrame中的每一行 row = pd.Series({"Category": data.Category, month: data.Amount}) found = 0 for d in rows: # 如果该分类的行存在,则填充缺的月份列 if d.Category == data.Category: found = 1 d[month] = data.Amount # 如果该分类的行不存在,直接放入rows数列 if found == 0: rows.append(row)# 构造新的DataFramedf_output = pd.DataFrame(rows)df_output.set_index("Category", inplace=True)print(df_output) |
参考:
1、官网 pandas.DataFrame.join 文档
2、官网 pandas.DataFrame.groupby 文档
作者:菩提树下的杨过
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
分类:
21.Others
, 18.Python/ML/AI



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· Open-Sora 2.0 重磅开源!
2010-03-19 再谈web开中几种经典的大文件上传组件
2009-03-19 Asp.Net MVC1.0正式版发布
2008-03-19 linq to sql的多条件动态查询(上)