

ubuntu上搭建ChatGLM2-6b环境及ptuing微调训练的坑
清华大学的chatGLM2-6B可以说是目前亚洲唯一能打的对中文支持不错的LLM大模型,网上已经有很多介绍如何在本机搭建环境的文章,就不再重复了,这里记录下最近踩的一些坑:
1、为啥要使用ubuntu?
chatGLM2-6b项目里有很多.sh文件,在windows下正常运行通常要折腾一番,最后能不能全部通关,讲究1个“缘”字,还不如直接找个linux环境,能避免不少麻烦,如果不想安装双系统的同学们,也可以使用windows 10/11的WSL子系统(见:windows WSL2避坑指南)
2、没有GPU显卡能玩GLM大模型吗?
能!但体验极差,几乎只能跑个hello world,干不了啥正事儿,不久会被劝退,还是建议租个服务器,或者至少弄个8G显存的N卡,我用的就是RTX4060.
注:如果实在想在纯CPU环境跑,建议使用c++重构版本的chatglm
3、ubuntu上怎么安装cuda及cudnn?
这里有一个很坑的地方,网上几乎所有文章全是清一色的介绍怎么用命令行,一步步下载安装,巨复杂,关键还不一定好使,我的ubuntu 22.04 LTS参照这些方法,试了2次,每次安装到最后,把gdm3关闭后,安装完再重启,就黑屏进不去了,按网上的各种解救方法也没效果,最后只能把ubuntu重装,浪费我不少时间 。
后面发现,软件与更新里,点点鼠标就能完成的事儿
3.1 先把服务器源设置成中国或主服务器
强烈建议:先不要按网上说的,把源换成阿里云、清华 这些国内镜像站点,不是说它们不好,而是国内镜像站点或多或少,可能更新不及时,有些依赖包不全,导致最后各种其名其妙的问题。
我在安装gcc/g++/make时就因为这个源的问题,折腾了好久,一直提示依赖项不满足 ,最后换成主服务器,就解决了。
在3.2之前,建议先安装以下组件(可能并不需要)
sudo apt install gcc sudo apt install g++ sudo apt install make
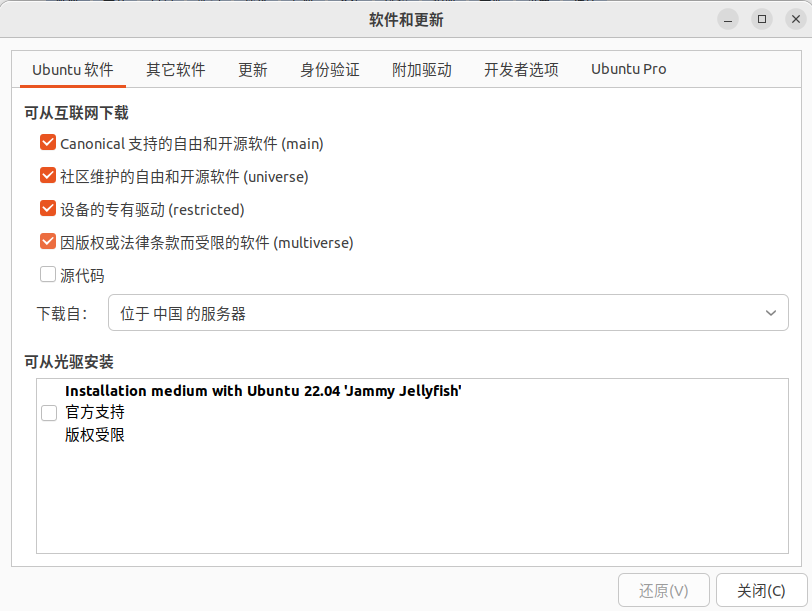
3.2 附加驱动,选择专有驱动(默认是带-open的)
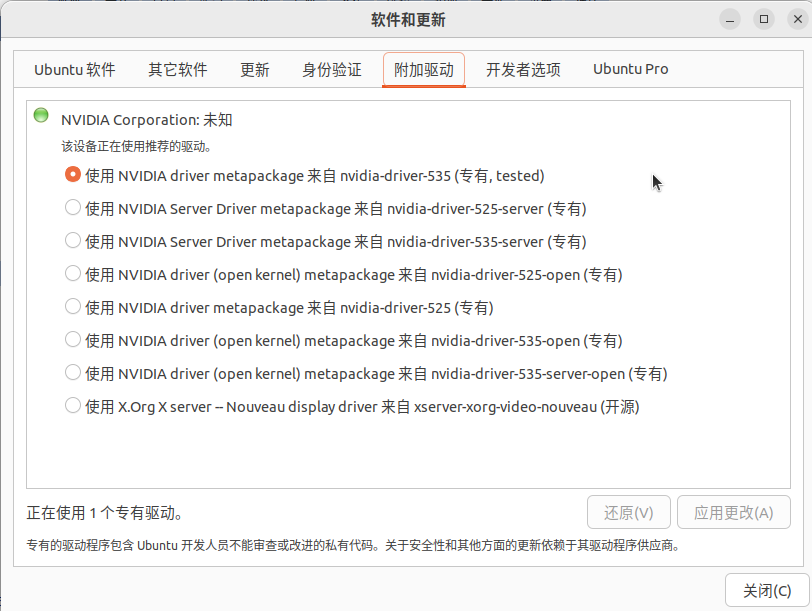
然后关闭,等着安装完成即可.
3.3 安装nvitop
这一步是可选的,推荐大家安装这个小工具 , 比nvidia-smi 好用太多,参见下面的截图, GPU的使用情况一目了然
conda install -c conda-forge nvitop

4、ptuning微调问题
按ptuing/readme.md的介绍,把AdvertiseGen训练了一把,量化8(其它核心参数没改)
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /home/jimmy/code/model/chatglm2-6b \
--output_dir /home/jimmy/code/model/output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 8
跑了15小时,下面是output目录里的结果汇总:
{
"epoch": 0.42,
"train_loss": 3.3751344401041665,
"train_runtime": 54080.5566,
"train_samples": 114599,
"train_samples_per_second": 0.888,
"train_steps_per_second": 0.055
}
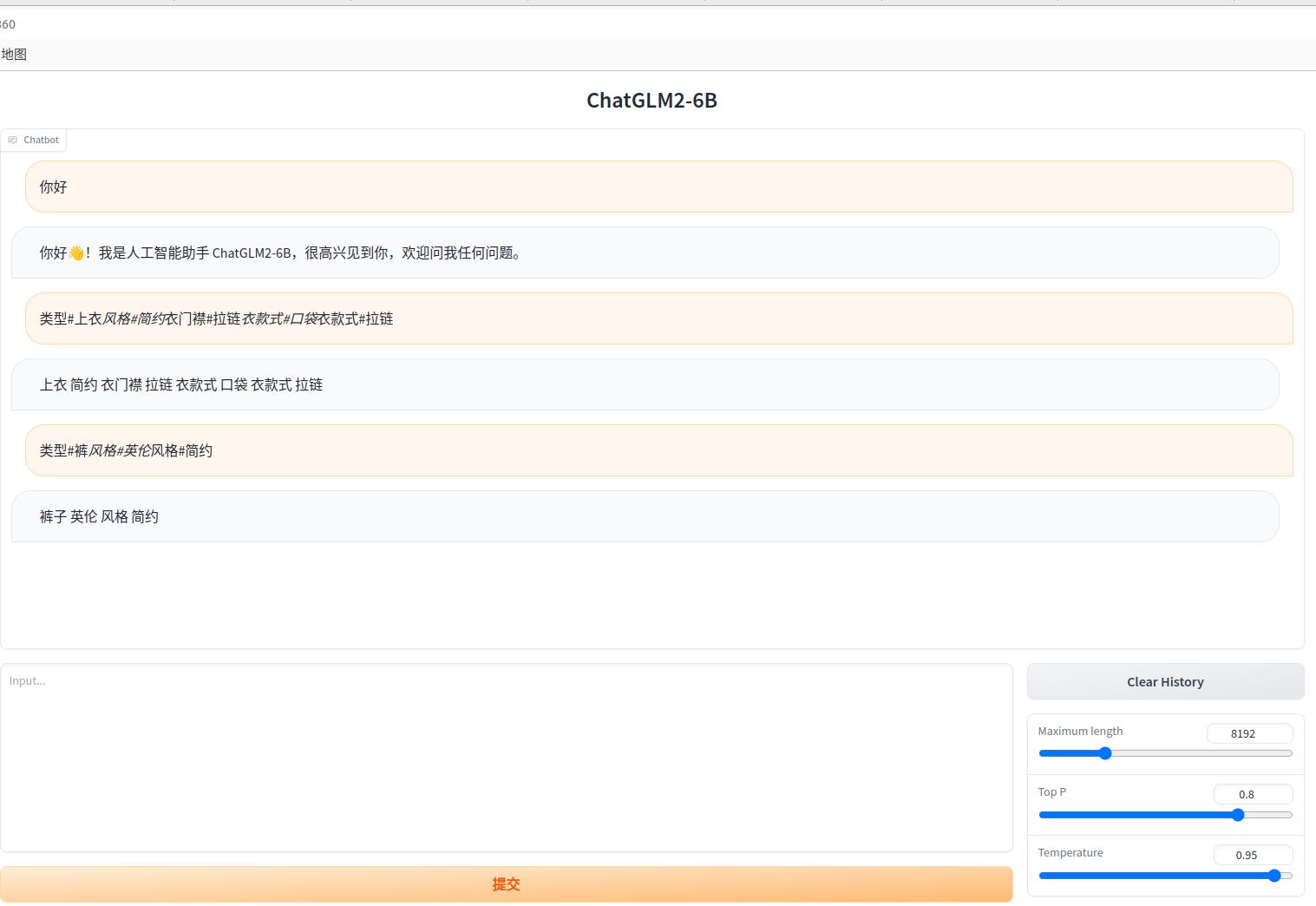
跑完之后,对比了下,对于服装类的问题,回答确实看上去更专业了 ,参考下图:
徾调前:
徾调后:
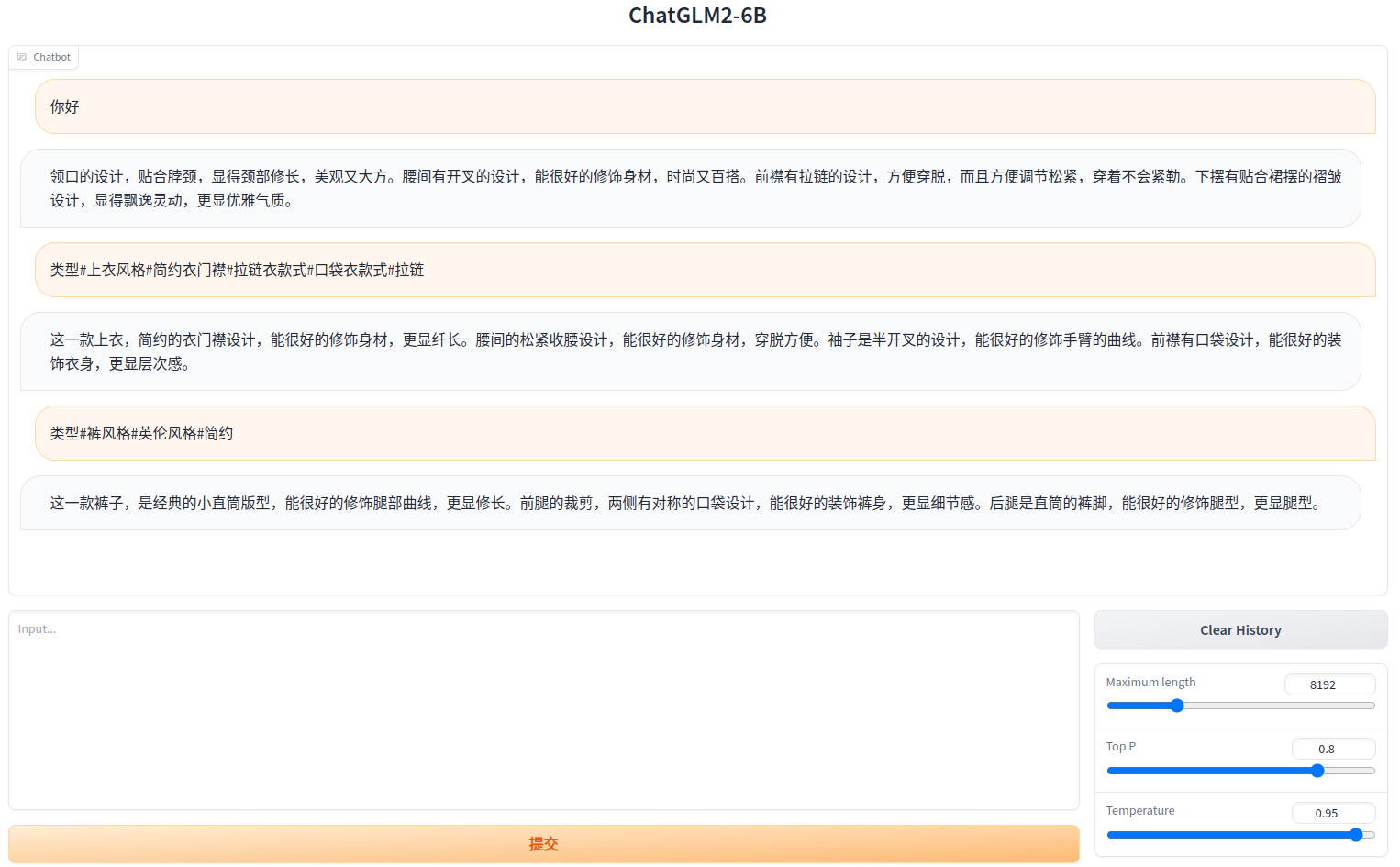
但也出现了1个严重的新问题:原来的通用对话能力退化了,问个“你好”都回答服装问题。在ChatGLM的微信交流群里问了下,发现不止我1个这样,大致原因是好比1个德智体美劳全面发展的学生,后面让他专门训练体育,到后来就成了体育生,只会运动,其它能力就退化了,解决办法是训练集中也加入其它通用知识一起训练,以保证其它能力依然可用;或者降低学习速率(即LR值),但是这样会导致专项能力的训练结果也跟着降低。看来微调训练是一门艺术!
出处:http://yjmyzz.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
