
03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)
接上一篇:https://www.cnblogs.com/yjm0330/p/10077076.html
一、下载安装scala
1、官网下载
2、spar01和02都建立/opt/scala目录,解压tar -zxvf scala-2.12.8.tgz
3、配置环境变量
vi /etc/profile 增加一行
export SCALA_HOME=/opt/scala/scala-2.12.8
同时把hadoop的环境变量增加进去,完整版是:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
然后source /etc/profile
4、验证
scala -version
5、同步spark02配置文件
scp /etc/profile spark02:/etc
二、下载安装spark
1、下载,解压,同scala,建立/opt/spark目录
2、配置环境变量
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
完整版更新:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
source /etc/profile
scp /etc/profile spark02:/etc
3、配置conf下文件
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vi spark-env.sh
export SCALA_HOME=/opt/scala/scala-2.12.8
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=spark01
export SPARK_EXECUTOR_MEMORY=2G
vi slaves
spark02
同步到spark02
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
三、测试spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。
在hadoop正常运行的情况下,在spark01(也就是hadoop的namenode,spark的marster节点)上执行命令:
cd /opt/spark/spark-2.4.0-bin-hadoop2.7/sbin
执行启动脚本:./start-all.sh
在浏览器里访问Mster机器,我的Spark集群里Master机器是spark01,IP地址是192.168.2.245,访问8080端口,URL是:http://192.168.2.245:8080/
用local模式运行一个计算圆周率的Demo。按照下面的步骤来操作。
第一步,进入到Spark的根目录,也就是执行下面的脚本:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.4.0.jar
yarn-client模式:
注意执行之前关闭010203的防火墙:
centos7.0(默认是使用firewall作为防火墙,如若未改为iptables防火墙,使用以下命令查看和关闭防火墙)
查看防火墙状态:firewall-cmd --state
关闭防火墙:systemctl stop firewalld.service
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.4.0.jar
四、遇到的问题
1、jps命令无法找到
[root@namenode ~]# jps
bash: jps: command not found...
[root@namenode ~]# find / -name jps
find: ‘/run/user/1001/gvfs’: Permission denied
[root@namenode ~]# rpm -qa |grep -i jdk
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
[root@namenode ~]# yum list *openjdk-devel*
需要安装openjdk-devel包
[root@namenode ~]# yum install java-1.8.0-openjdk-devel.x86_64
[root@namenode ~]# which jps
/usr/bin/jps
[root@namenode ~]# jps
12995 Jps
10985 ResourceManager
11179 NodeManager
10061 NameNode
10301 DataNode
10655 SecondaryNameNode
2、XShell上传文件到Linux服务器上
在学习Linux过程中,我们常常需要将本地文件上传到Linux主机上,这里简单记录下使用Xsheel工具进行文件传输
1:首先连接上一台Linux主机
2:输入rz命令,看是否已经安装了lrzsz,如果没有安装则执行 yum -y install lrzsz命令进行安装。
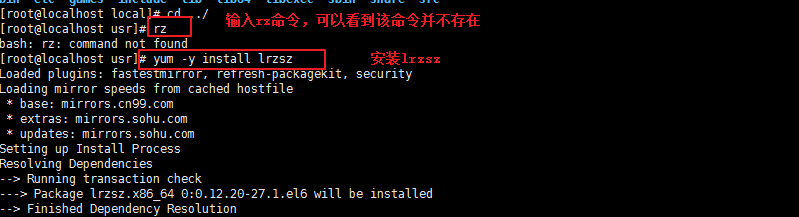
3:安装成功后,输入rpm命令确认是否正确安装

4: 使用 rz -y命令进行文件上传,此时会弹出上传的窗口:
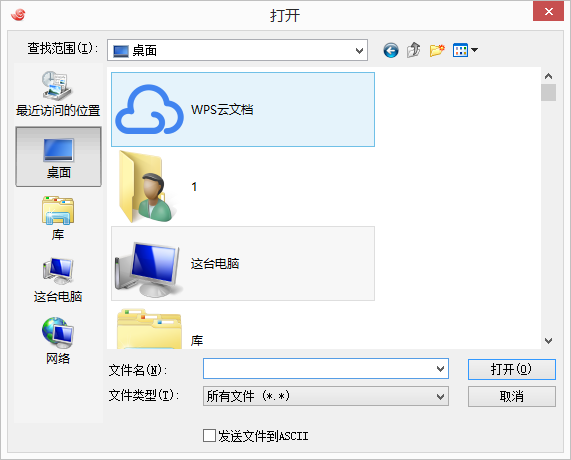
5:选择要上传的文件,点击确定即可将本地文件上传到Linux上,如图表示成功上传文件

6:使用ls命令可以看到文件已经上传到了当前目录下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号