


Scrapy爬去哪儿~上海一日游门票并存入MongoDB数据库
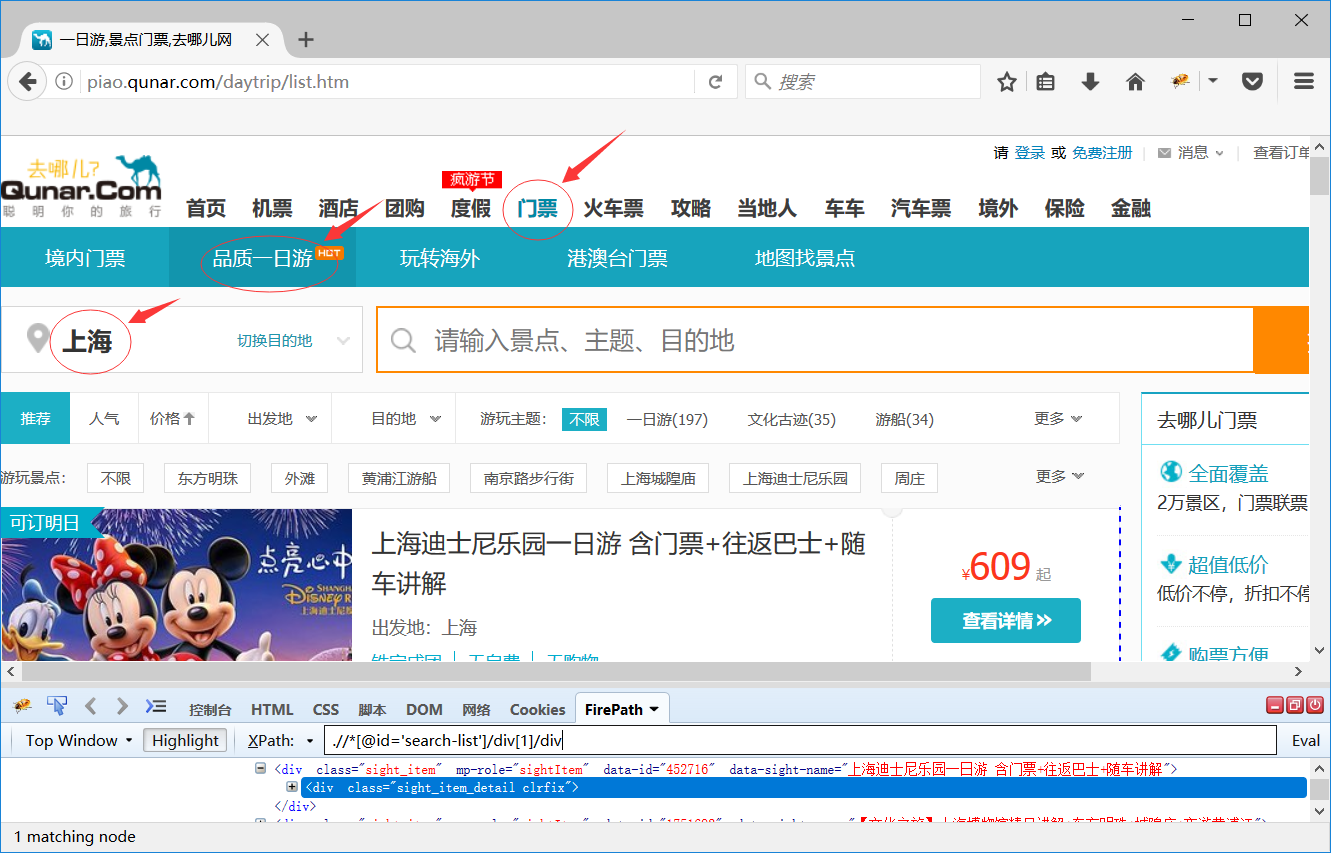

编辑qunaer.py:
# -*- coding: utf-8 -*-
import scrapy
from QuNaEr.items import QunaerItem
class QunaerSpider(scrapy.Spider):
name = 'qunaer'
allowed_domains = ['piao.qunar.com']
start_urls = ['http://piao.qunar.com/daytrip/list.htm']
def parse(self, response):
ticket_list = response.xpath(".//*[@id='search-list']/div/div")
for i_item in ticket_list:
ticket = QunaerItem()
ticket["picture_url"] = i_item.xpath(".//div[1]/div[2]/a/img/@data-original").extract_first()
ticket["name"] = i_item.xpath(".//div[2]/h3/a/text()").extract_first()
ticket["city"] = i_item.xpath(".//div[2]/div/div[1]/span/text()").extract_first()
ticket["money"] = i_item.xpath(".//div[3]/table/tr[1]/td/span/em/text()").extract_first()
# 当爬取table表格的内容时,浏览器会在table标签下添加tbody
# 使用scrapy时需要把xpath中的tbody去掉
ticket["volume"] = i_item.xpath(".//div[4]/span/span[1]/text()").extract_first()
ticket["score"] = i_item.xpath(".//div[4]/span/span[3]/text()").extract_first()
yield ticket
next_link = response.xpath(".//*[@id='pager-container']/div/a[9]/@href").extract_first()
if next_link is not None:
next_link = response.urljoin(next_link)
yield scrapy.Request(next_link, callback=self.parse)
编辑items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QunaerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
picture_url = scrapy.Field()
# 门票的图片地址
name = scrapy.Field()
# 门票的名称
city = scrapy.Field()
# 门票的出发地
money = scrapy.Field()
# 门票的价格
volume = scrapy.Field()
# 门票的销量
score = scrapy.Field()
# 用户点评分数
新建MongoPipeline.py:
import pymongo
class MongoPipeline(object):
def __init__(self):
host = "192.168.1.23" # 地址
port = 27017 # 端口号
dbname = "scrapy" # 数据库名称
sheetname = "qunaer" # 表
client = pymongo.MongoClient(host=host, port=port)
# 连接MongoDB
mydb = client[dbname]
# 连接数据库
self.post = mydb[sheetname]
# 连接表
def process_item(self, item, spider):
data = dict(item)
# 转换成字典
self.post.insert(data)
# 插入数据
return item
修改settings.py配置文件:
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'QuNaEr.pipelines.QunaerPipeline': 300,
'QuNaEr.MongoPipeline.MongoPipeline': 300,
}
# 启用pipeline
scrapy crawl qunaer
运行爬虫
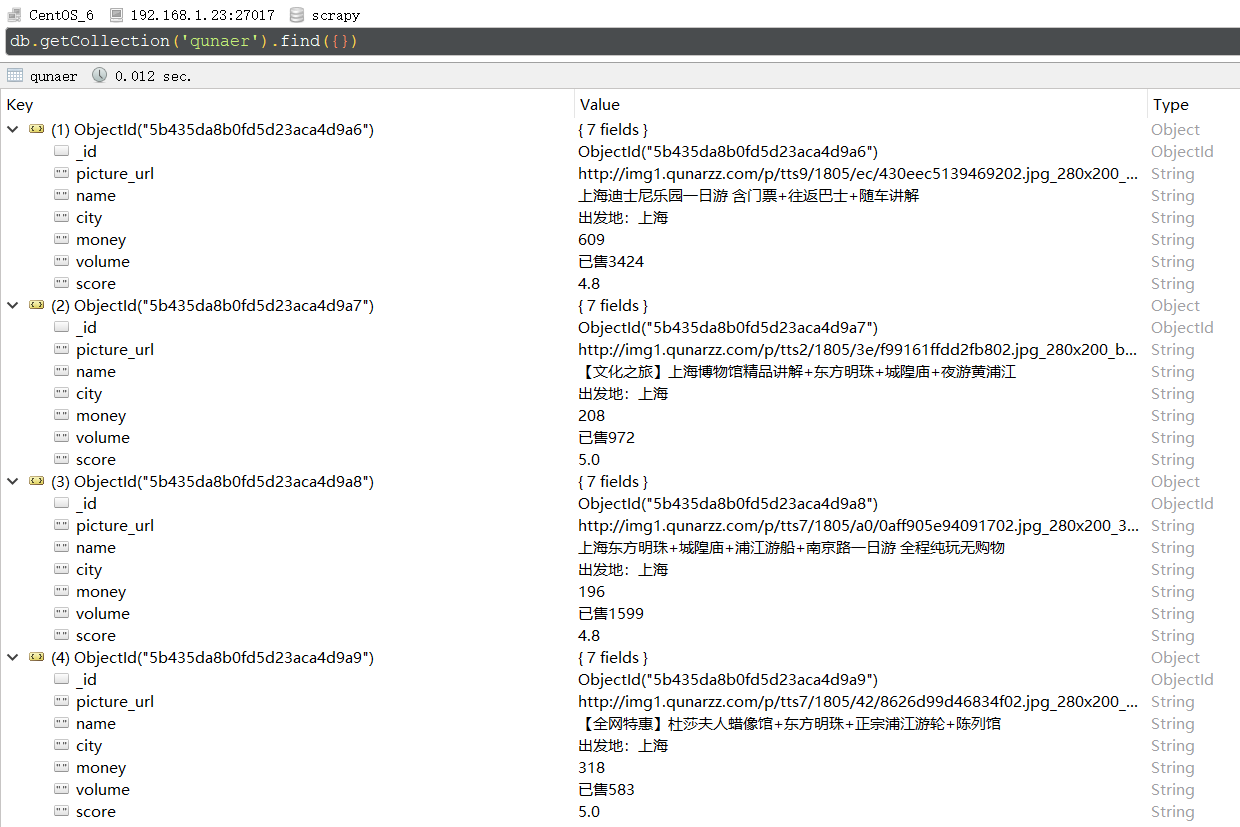
分类:
Scrapy(Python3)
标签:
scrapy



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构