
RAG评估-ragas
RAG效果评估的必要性
可以有方向的优化RAG。通过评估出的各指标,可以知道RAG改善的方向和参数调整的程度。
RAG评估方法
人工评估
邀请专家或人工评估员对RAG生成的结果进行评估。他们可以根据预先定义的标准对生成的答案进行质量评估,如准确性、连贯性、相关性等。这种评估方法可以提供高质量的反馈,但会消耗大量的时间和人力资源
自动化评估
自动化评估肯定是RAG评估的主流和发展方向,以下是一些常用的评估工具。
Prompt+LLM
使用prompt+LLM实现对rag能力的评估,需要熟悉各评估指标的计算方式,并且需要很强的prompt能力,目前网上还没有成熟方案。
Trulens
Trulens-Eval 也是专门用于评估 RAG 指标的工具,它对 LangChain 和 Llama-Index 都有比较好的集成,可以方便地用于评估这两个框架搭建的 RAG 应用。
相关地址
RAGAS
Ragas 是专注于评估 RAG 应用的工具,通过简单的接口即可实现评估。只要把 RAG 过程中的question, contexts, answer, ground_truths,构建成一个 Dataset 实例,即可一键启动测评,非常方便。
Ragas 指标种类丰富多样,对 RAG 应用的框架无要求。也可以通过 langsmith 来监控每次评估的过程,帮助分析每次评估的原因和观察API key 的消耗。
相关地址
开源链接:https://github.com/explodinggradients/ragas
使用手册:https://docs.ragas.io/en/stable/getstarted/install.html
RAG评估指标
RAG 三元组
在RAG系统中主要包含三个流程:用户提问、向量数据库检索、大模型回答,我们能从三个流程中获取的信息有:用户提问(query)、RAG 系统召回的引用上下文(contexts)、RAG 系统的回答(answer)。可以通过检测这三元组之间两两元素的相关度,来评估一个 RAG 应用的效果。
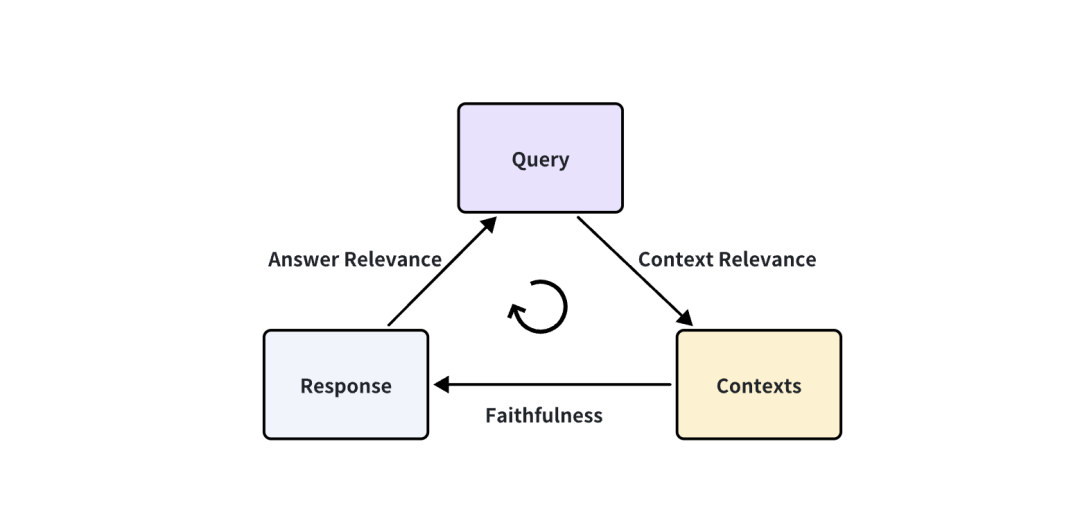
得出下面三个对应的指标:
-
Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与 Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。
-
Faithfulness: 这个指标衡量了生成的答案在给定的上下文中的事实一致性。它是根据答案和检索到的上下文计算出来的如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
-
Answer Relevance: 侧重于评估生成的答案与给定查询提示的相关性。对于不完整或包含冗余信息的答案,会分配较低的分数。
上面的指标不需要参考 Ground-truth(人类写好的可以回答对应提问的标准回答),如果有 ground-truth,评估指标就更加丰富,即可以从更多角度来衡量 RAG 应用的效果。但获得标准好 ground-truth 的数据集是很昂贵的,可能需要花大量的人力和时间来进行标注。
可以利用 LLM 根据知识文档来生成 query 和 answer,然后对answer进行修改和完善,也可以作为 ground-truth 使用。
ragas评估范围
ragas是作为rag应用(必须有知识库+大模型)能力评估的一个工具,输入必须有 用户提问(query)、向量数据库从知识库召回的引用上下文(contexts)、大模型的回答(answer),这是rag应用中必备的三个元素,ragas也是针对这三个元素进行评估。
ragas不能评估只有大模型的问答能力,原因:
1、只是大模型问答,流程中不包含向量数据库检索,没有 contexts 输入,ragas评估必须有 contexts 输入。
2、大模型问答的结果,跟大模型的训练数据和prompt有关,大模型评估和rag应用评估是两个不同的方向。
3、因为我们平台都是调用第三方大模型,去测试第三方大模型会花费巨大时间(人工标注),收益不高,而且也不能根据某个场景的问答去评估某个大模型的能力,太片面。
RAGAS指标
Ragas评估需要提供的输入:
-
用户提问 question:
list[str]
-
向量数据库召回的上下文 contextx:
list[str]
-
LLM回答 answer:
list[list[str]]
-
人类回答 ground_truths:
list[list[str]]
Ragas评估结果有以下几种指标:
-
忠实度(faithfulness)
-
答案相关性(Answer relevancy)
-
上下文精度(Context precision)
-
上下文召回率(Context recall)
-
上下文相关性(Context relevancy)
-
答案相似度answer_similarity
-
答案正确性 Answer Correctness
其中 忠实度(faithfulness)、答案相关性(Answer relevancy)、上下文精度(Context precision)是常用的三种指标。
上下文召回率、上下文相关性、答案相似度 和 答案正确性 需要有ground_truth才可以计算得出,上下文召回率、上下文相关性用以衡量检索系统的性能。
忠实度(faithfulness)
忠实度(faithfulness)衡量了生成的答案(answer)与给定上下文(context)的事实一致性。它是根据answer和检索到的context计算得出的。并将计算结果缩放到 (0,1) 范围且越高越好。如果得分较低,则表明LLM的响应不符合检索到的知识。
如果这里得分为0或者得分较低,但仍然获得了答案。就说明获得的答案全部或者部分由大模型自己“编造”生成(当然也可能是对的),而不是从上下文推理获得,这就是常见的大模型幻觉。
答案相关性(Answer relevancy)
答案相关性(Answer relevancy) 重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案将获得较低分数。该指标是通过计算question和answer获得的,它的取值范围在 0 到 1 之间,其中分数越高表示相关性越好。
这个指标说明生成的答案是否完整且简洁的,但不考虑答案是否正确。 指标较高,说明最后的输出答案还是涵盖了问题中需要回答的关键点, 尽管这些答案不一定是从context得出,也不一定正确。
上下文相关性(Context relevancy)
衡量检索到的上下文(Context)的相关性,根据用户问题(question)和上下文(Context)计算得到,并且取值范围在 (0, 1)之间,值越高表示相关性越好。理想情况下,检索到的Context应只包含解答question的信息。
上下文相关性是一个衡量检索质量的指标,主要评估检索到的上下文支持查询的程度。得分低表示检索到大量不相关的内容,这可能会影响LLM生成的最终答案。
上下文精度(Context precision)
评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。理想情况下,所有相关文档块(chunks)必须出现在顶层。该指标使用ground_truth和Context计算,值范围在 0 到 1 之间,其中分数越高表示精度越高。
得分低 通常说明导入知识库涵盖范围不足、或者虽然能够检索相关知识,但是却无法推导出正确答案,可能存在知识错误情况。
上下文精度的优势在于它能够感知排名效果。然而它的缺点是,如果相关召回很少,但都排名很高,那么分数也会很高。因此,有必要结合其他几个指标来考虑整体效果。
上下文召回率(Context recall)
上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出,取值范围在 0 到 1 之间,值越高表示性能越好。
在理想情况下,真实答案ground truth中的所有句子都应归因于检索到的Context。
答案相似度 answer_similarity
答案相似度是评估生成的答案answer与基本事实ground truth之间的相似性。此评估值范围在 0 到 1 。分数越高,表示生成的答案与基本事实之间的匹配程度越高。
答案正确性 Answer Correctness
答案正确性评估生成的答案answer与基本事实ground truth相比的准确性。此评估值范围在 0 到 1。分数越高,表示生成的答案与基本事实之间的一致性越高,正确性越高。
答案正确性包含两个关键方面:生成的答案与基本事实之间的语义相似性以及事实相似性。这些方面使用加权方案组合起来,以制定答案正确性分数。
LangSmith
LangSmith是LangChain 官方的 SaaS 服务,可以调试、测试、评估和监控构建在任何LLM框架上的链和智能代理,并与LangChain无缝集成。
平台入口:https://smith.langchain.com/
文档地址:https://python.langchain.com/docs/langsmith/walkthrough
参考博客:https://blog.csdn.net/Attitude93/article/details/136053834
登陆(需要VPN)后创建API KEY,要打通 LangChain 和 LangSmith 很简单,只需要在代码中配置
import os
# langsmith api key
os.environ["LANGCHAIN_API_KEY"] = "******"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com" #LangSmith的服务端点
os.environ["LANGCHAIN_TRACING_V2"]="true"
os.environ["LANGCHAIN_PROJECT"]="test-001"运行程序之后,可以在LangSmith平台看到当前程序的运行过程
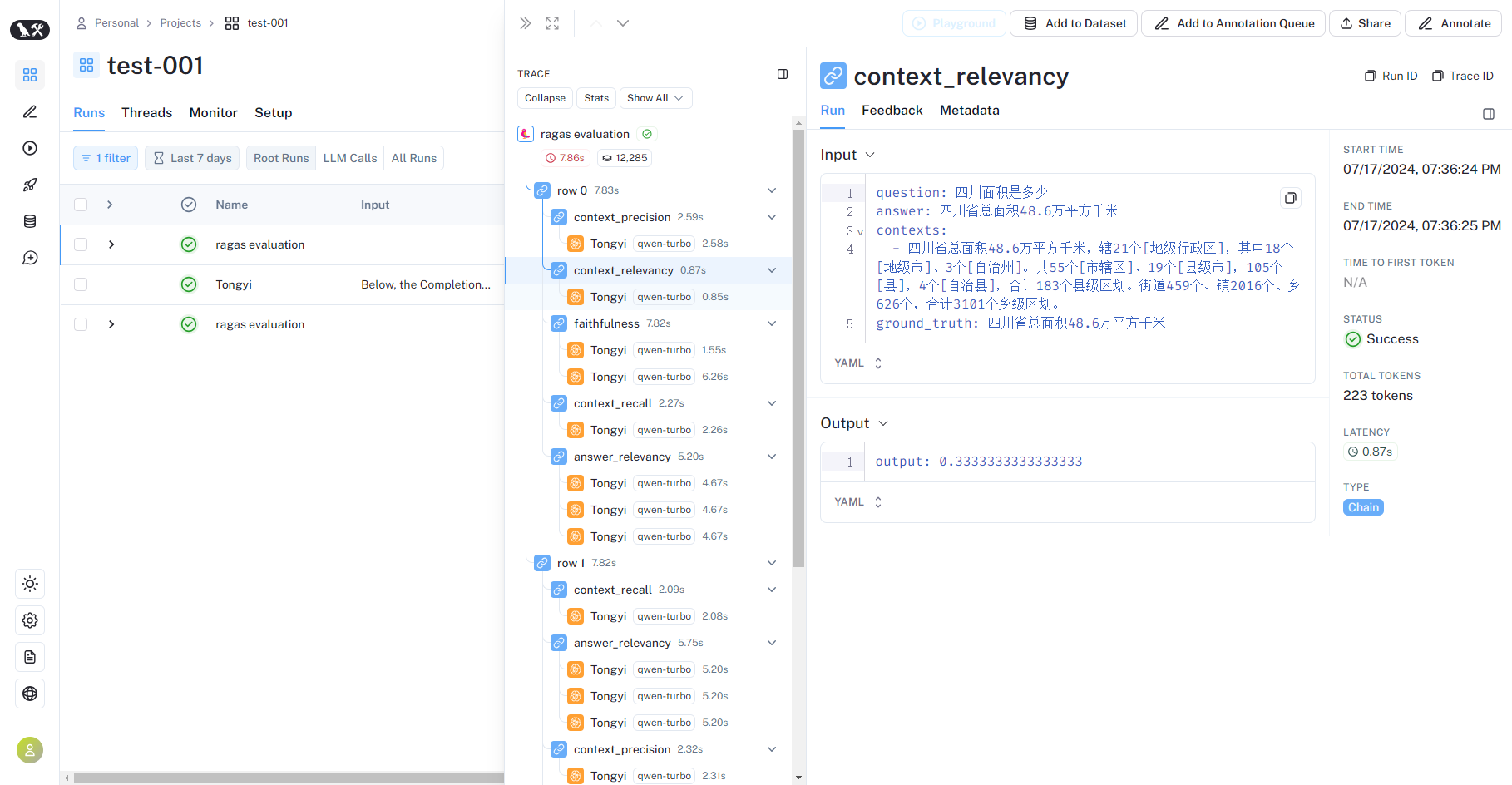
LangFuse
LangFuse是开源的AI应用维护平台,是LangSmith 的平替,并且它可集成 LangChain,同时也可直接对接 OpenAI API。
本地部署和使用参考:
https://blog.csdn.net/m0_63171455/article/details/139402830
https://www.dongaigc.com/a/langfuse-learning-resources-open-source-llm-platform


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)