UUID那些事
2018-05-16 12:25 轩脉刃 阅读(6334) 评论(3) 收藏 举报UUID那些事
UUID 是一个全局唯一的通用识别码。它使用某种规则,而不是某种中心化的自增方式,来保证这个识别码的全局唯一性。UUID 有非常多的使用场景,比如在分布式系统中,需要生成全局唯一 ID 来进行日志记录。UUID 的生成规则由 rfc4122 来进行定义。
UUID 和 GUID 的区别
其实是没有区别的,GUID 是微软按照 UUID 的规则实现的一套方法。它本质的目的也是为了保证全局唯一性。微软已经使用 GUID 在 Windows 的 COM,ActiveX 等技术上了。但是这里注意的一点是,UUID 本质是有多种版本的,GUID 也是在不同的使用场景实现的是不同的 UUID 版本,比如 COM 是使用 UUID 版本1 进行实现的。所以,在聊 UUID 和 GUID 是不是一样的时候,附带的信息应该了解清楚版本信息。
版本
UUID 是有不同的版本的,每个版本有不同的适用场景,比如,版本4 建议使用随机方式生成所有的可变因子。在很多场景下,这个其实是一个非常方便的实现方式。版本1 使用的是 时间戳+时钟序列+节点信息(机器信息)在一些分布式系统场景下是能严格保证全局唯一的。twitter 的 snowflake 可以看作是是 UUID 版本1 的简化版。
到现在为止,UUID 一共有5个实现版本:
- 版本1: 严格按照 UUID 定义的每个字段的意义来实现,使用的变量因子是时间戳+时钟序列+节点信息(Mac地址)
- 版本2: 基本和版本1一致,但是它主要是和 DCE( IBM 的一套分布式计算环境)。但是这个版本在 ietf 中也没有具体描述,反而在DCE 1.1: Authentication and Security Services这篇文档中说到了具体实现。所以这个版本现在很少使用到,并且很多地方的实现也都忽略了它。
- 版本3: 基于 name 和 namespace 的 hash 实现变量因子,版本3使用的是 md5 进行 hash 算法。
- 版本4: 使用随机或者伪随机实现变量因子。
- 版本5: 基于 name 和 namespace 的 hash 实现变量因子,版本5使用的是 sha1 进行 hash 算法。
不管是 UUID 的哪个版本,它的结构都是一样的,这个结构是按照版本1进行定义的,只是在其他版本中,版本1中的几个变量因子都进行了变化。
UUID 基本结构
UUID 长度是128bit,换算为16进制数值(每4位代表一个数值)就是有32个16进制数值组成,中间使用4个-进行分隔,按照8-4-4-4-12的顺序进行分隔。加上中间的横杆,UUID有36个字符。
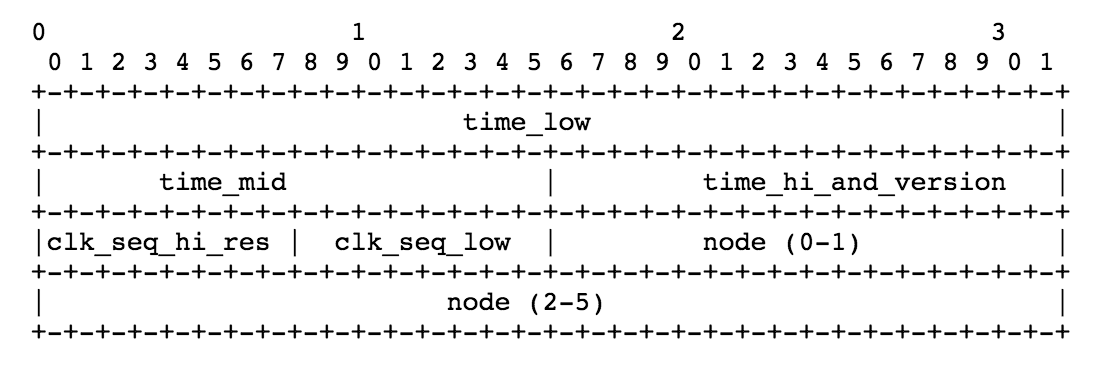
这个图是 UUID 的具体结构。它的可变因子有三个,Timestamp 时间戳,Clock Sequence时钟序列,node节点信息。然后由他们的不同部分组成这个 UUID。
Timestamp
时间戳是其中一个可变因子。时间戳有长度为 60bit。它代表现在当前UTC时间(必须使用UTC时间,这样就统一了时区)和1582-10-15 00:00:000000000,每100纳米加一。对于无法获取UTC时间的系统,由于获取不到UTC,那么你可以统一采用 localtime。(实际上一个系统时区相同就可以了)。
有了时间戳之后,结构图中的time_low,time_mid,time_hi就知道了
time_low
是 timestamp 60bit 中的 0~31bit,共32bit
time_mid
是 timestamp 60bit 中的 32~47bit,共16bit
time_hi_and_version
这个字段的意思很明确,就是包含两个部分,version 和 time_hi。version 占用 bit 数为4. 代表它最多可以支持31个版本。time_hi就是timestamp剩余的12bit,一共是16bit。
Clock Sequence
如果计算 UUID 的机器进行了时间调整,或者是 nodeId 变化了(主机更换网卡),和其他的机器冲突了。那么这个时候,就需要有个变量因子进行变化来保证再次生成的 UUID 的唯一性。
其实Clock Sequence的变化算法很简单,当时间调整,或者 nodeId 变化的时候,直接使用一个随机数,或者,在原先的Clock Sequence值上面自增加一也是可以的。
Clock Sequence 一共是14bit
clock_seq_low
是 Clock Sequence 中的 0~7 bit 共8bit
clock_seq_hi_and_reserved
包含两个部分,reserved 和 clock_seq_hi。其中 clock_seq_hi 为 Clock Sequence 中的 8~13 bit 共6个bit,reserved是2bit,reserved 一般设置为10。
node
node 这个变量因子由MAC地址组成,通常是IP地址。它有48bit大小。其中的 0-15填入node(0-1)的位置,16-47填入node(2-5)的位置。
不同版本
基本上,按照上节说的已经把 UUID 的结构构成说明清楚了。基本上这个结构构成是 UUID version1 的定义。我们可以看到,它有的变量因子是 timestamp, clock sequence, node。
在不同版本中,这几个变量因子的含义是不同的。
version4
在version4 中,timestamp,clock sequence, node都是随机或者伪随机的。
version3&5
version3和5 叫做基于 name 和 namesapce 的 hash 结构生成。其中的name 和namespace 基本上和我们很多语言的命名空间,类名一样,它的基本要求就是,name + namespace 才是唯一确定hash串的标准。换句话说,一样的namespace + name 使用的hash算法(比如version3的md5)计算出来的结果必须是一样的,但是不同的 namespace 中的同样的 name 生成的结果是不一样的。
version3 和 version5 中的三个变量因子都是由hash 算法保证的,version3是 md5, version5是sha1。
参考文档
实时了解作者更多技术文章,技术心得,请关注微信公众号“轩脉刃的刀光剑影”
本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名叶剑峰(包含链接http://www.cnblogs.com/yjf512/),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号