spark的sparkUI如何解读?
2017-11-01 07:44 轩脉刃 阅读(6957) 评论(0) 收藏 举报spark的sparkUI如何解读?
以spark2.1.4来做例子
Job - schedule mode
进入之后默认是进入spark job 页面
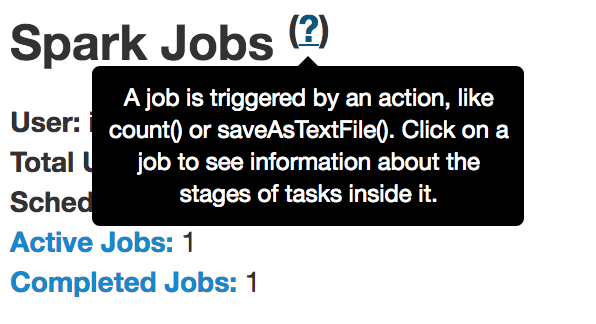
这个说明有很详细的解释,spark有两种操作算子:转换算子(transformation)和执行算子(Action)。当执行到行为算子的时候,就出发了一个Job作业,比如count()和saveAsTextFile()。
sparkJob页面头部有几个,最重要的是Schedule mode,表示的是Job的调度模型。如果多个线程调用多个并行的job,这些job就会被分配调用,这里就有个调度模型,一般是FIFO模型,先进先出模型。但是在spark0.8之后,就支持了一种FAIR模型,FAIR模型是一种公平模型,相当于每个任务轮换使用资源等,这样能使的小job能很快执行,而不用等大job完成才执行了。
Job - Event Timeline

这个就是用来表示调度job何时启动,何时结束,并且excutor何时加入。
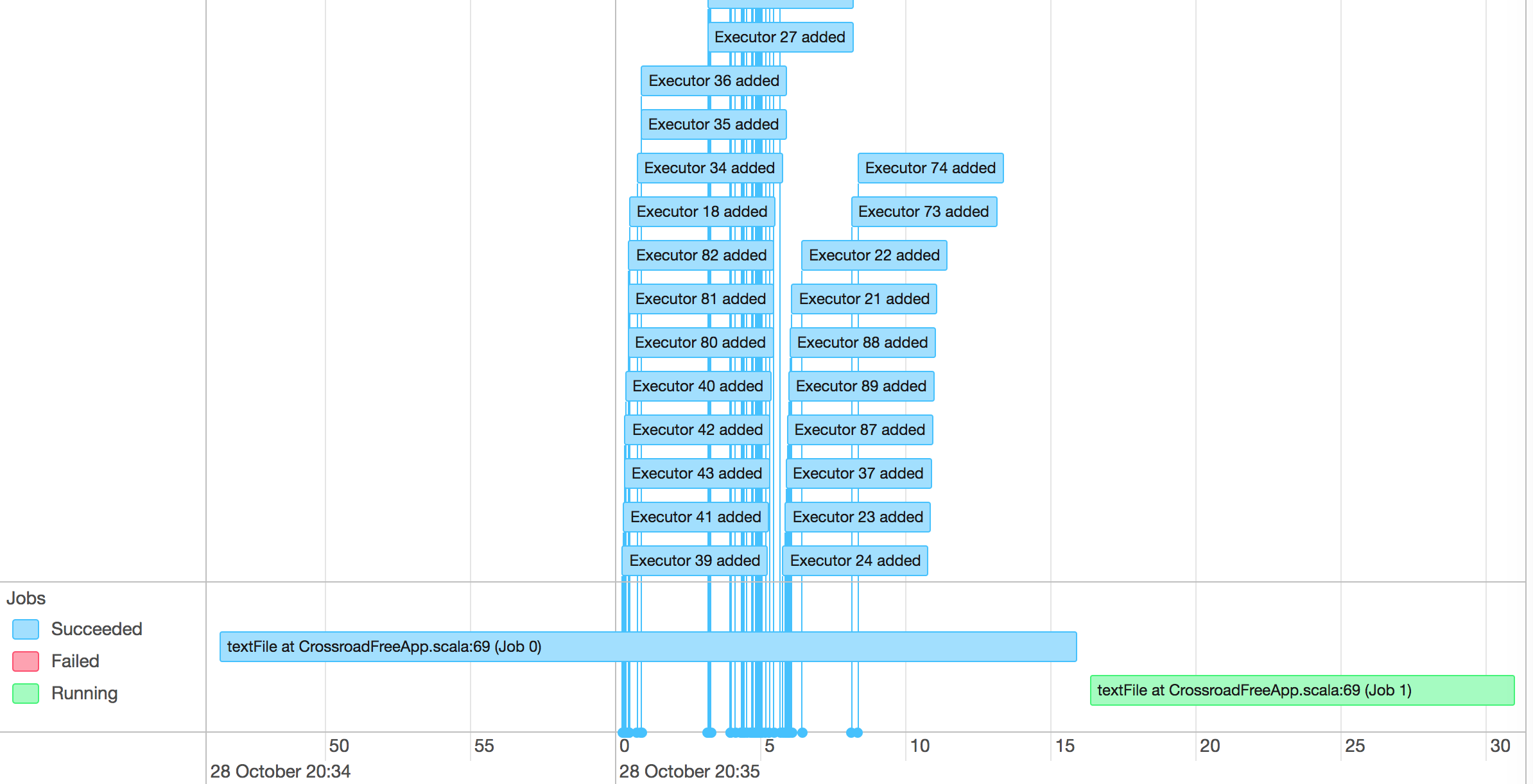
我们可以很方便看到哪些job已经运行完成,使用了多少excutor,哪些正在运行。
点击进入每个job,我们就可以看到每个job的detail
Details for Job
在这个页面我们能看到job的详情。一个job会被分为一个或者多个stage
这里也有event timeline,告诉我们这个job中每个stage执行时间。
这里多了一个DAG可视化的图
DAG
DAG图是有向无环图的意思。spark中使用有向无环图来显示流程。
DAG也是一种调度模型,在spark的作业调度中,有很多作业存在依赖关系,所以有的作业可以并行执行,有的作业不能并行执行。把这些作业的内部转向关系描绘清楚,就是一个DAG图。使用DAG图,就能很清晰看到我们的作业(RDD)哪些先执行,哪些后执行,哪些是并行执行的。
当调用了一个行为算子的时候,前面的所有转换算子也会一并提交给DAG调度器,DAG调度器把这些算子操作分为不同的stage,这个就是stage的由来。而DAG在画stage的时候也会产生出一个DAG图,就是这里的图了。
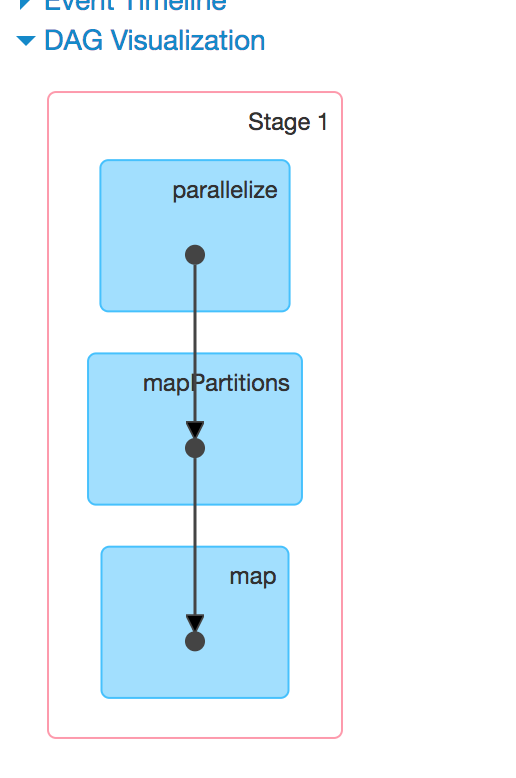
点击每个stage,我们就能看到这个stage执行的任务(Task)了。
Details for Stage
标题

标题代表这是第几号stage,第几次尝试。
Show Additional Metrics
Scheduler Delay
调度延迟时间,包含把任务从调度器输送给excutor,并且把任务的结果从excutor返回给调度器。如果调度时间比较久,则考虑降低任务的数量,并且降低任务结果大小
Task Deserialization Time
反序列化excutor的任务,也包含读取广播任务的时间
Shuffle Read Blocked Time
任务shuffle时间,从远端机器读取shuffle数据的时间
Shuffle Remote Reads
从远端机器读取shuffle数据的时间
Getting Result Time
从worker中获取结果的时间
// 这里应该还有一些其它的各种指标,等以后看代码的时候再补充。
在用图形表示完之后还有一个summary的时间统计,告诉你每个阶段的时间,所有任务的分布图。
Aggregated Metrics by Executor
这个矩阵告诉我们每个excutor的执行情况。
Tasks
告知每个任务的执行情况。
Environment
显示所有的环境变量
Excutors
显示每个excutor的统计情况
参考文章
http://www.csdn.net/article/2015-07-08/2825162
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-webui-StagePage.html
实时了解作者更多技术文章,技术心得,请关注微信公众号“轩脉刃的刀光剑影”
本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名叶剑峰(包含链接http://www.cnblogs.com/yjf512/),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号